Решения Disaster Recovery восстанавливают работоспособность ИТ-инфраструктуры после сбоя или атаки. Объясняем, как использовать вместе с резервным копированием. Материал будет полезен специалистам, которые начинают работу с облаком и только знакомятся с его возможностями.
Но даже если компании удаётся выжить после утечки, она все равно несет репутационные риски. Затронутые аварией партнеры и клиенты начинают меньше доверять продуктам, которые предлагает пострадавший бизнес. Как показывает текущая ситуация, столкнуться с такими проблемами не так и сложно. Дело не только в киберпреступниках, которые постоянно разрабатывают новые инструменты и способы взлома — в том числе на базе систем искусственного интеллекта. Но и в том, что фреймворки вроде ISO 27001, NIST Cybersecurity Framework и другие методологии, связанные с информационной безопасностью, зачастую не успевают за изменениями и теряют актуальность для определенных организаций. Они отдаляются от реальных кейсов, с которыми приходится сталкиваться ИБ-специалистам. Плюс — на внедрение и реализацию подобных практик уходят достаточно ощутимые объемы корпоративных ресурсов.
При этом существенная часть компаний, конечно же, считает киберриски главной угрозой для бизнеса и вкладывается в кадры. Ресурсы направляют и на закупку систем киберзащиты. В 2021-м этот рынок оценивали в $165 млрд, но аналитики ожидают, что к 2028 году он вырастет до $366 млрд. Таким темпам роста способствует разнообразие аппаратных и программных средств борьбы с кражей данных и других атак: от инструментов защиты сетевого периметра до антивирусного программного обеспечения. Сегодня мы хотели бы поговорить о конкретных решениях.
На первый взгляд, эти инструменты решают одну и ту же задачу — позволяют бизнесу продолжить работу, если инфраструктура вышла из строя или из БД пропали данные. Но между ними все же есть отличия.
Частота копирования данных. BaaS подразумевает отправку копий образов виртуальных машин по расписанию — например, раз в день — в холодное хранилище облачного провайдера. Когда происходит потеря данных, они просто восстанавливаются из сохраненной копии. Если говорить о системах Disaster Recovery, то в облаке формируется дополнительная площадка с постоянно обновляемыми репликами виртуальных машин, корпоративных приложений и сервисов — при этом репликация происходит регулярно на протяжении дня. Так, при возникновении сложностей нагрузка переключается на «запасной аэродром».
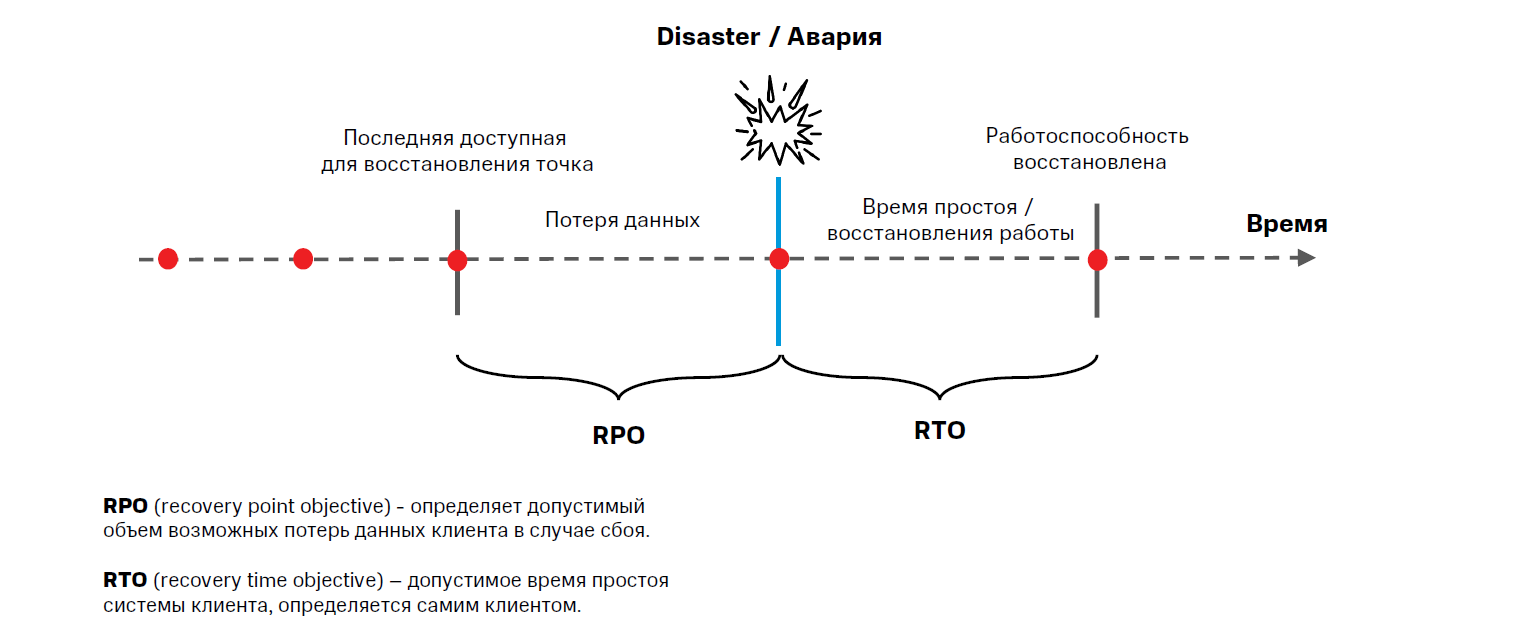
Актуальность данных — второе отличие, связанное с предыдущим пунктом. Дело в том, что бэкап подразумевает хранение множественных копий данных, и восстановить их можно до любой сохраненной версии. Но очевидно, что в этот момент часть информации будет утеряна — её объем зависит от расписания резервного копирования, определяющего параметр RPO (recovery point objective). В то же время восстановление данных из холодного хранилища занимает достаточно много времени, которое определяется параметром RTO (recovery time objective). На эту задачу может уйти от нескольких часов до дней — в зависимости от объемов информации. Все это время корпоративные сервисы простаивают.
Что касается систем аварийного восстановления, то их показатели RPO и RTO сильно меньше. Репликация проходит в фоновом режиме на протяжении дня, поэтому на резервной площадке всегда находится практически полная копия основной инфраструктуры, а переключение на «запасной аэродром» после ЧП происходит в течение нескольких минут. В результате бизнес не замечает последствий сбоя. Так, среди наших клиентов есть логистическая компания, для которой решение Disaster Recovery сократило время простоя систем на 20%.
Однако стоит заметить, что системы аварийного восстановления не позволяют «откатить» инфраструктуру к более ранним состояниям, так как на резервной площадке находится полная копия приложений и БД. В этом контексте имеет смысл использовать системы резервного копирования и аварийного восстановления в паре, чтобы исключить больший спектр рисков.
Отказоустойчивость. Наконец, резервное копирование не является инструментом обеспечения непрерывной работы. Но аварийное восстановление дает более устойчивый к различным рискам фундамент, дополнительно повышает безопасность инфраструктуры, помогает избежать убытков из-за простоя.
В этом ключе работа Disaster Recovery подразумевает два сценария. Первый — когда корпоративные сервисы запущены on-premise, а в качестве резерва выступает облако. Во втором случае роль основной и запасной площадки играет геораспределенная облачная инфраструктура провайдера. Какой вариант выбрать — зависит от нужд организации и необходимого плана восстановления.

Для этого достаточно проводить регулярные выборочные проверки и тестовые миграции на резервную площадку. Параллельно имеет смысл делать ревизию сохраняемых данных с целью исключить неактуальную информацию. Такой подход позволит сэкономить ресурсы и место на дисках с копиями.
Эти очевидные рекомендации позволят серьезно повысить отказоустойчивость инфраструктуры. Но к сожалению, следуют им далеко не все — по статистике, больше половины бэкапов находится в неработоспособном состоянии.
Чтобы повысить надежность инфраструктуры, стоит обращать не только на резервные копии и реплики, но и на сами приложения, которые подлежат защите. Во время разработки эксперты рекомендуют следовать практикам graceful degradation. Они определяют способность системы продолжать работу даже при отказе некоторых ее компонентов — это особенно важно в контексте инфраструктуры корпораций, включающей тысячи взаимосвязанных сервисов.

 habr.com
habr.com
Почему мы об этом говорим
Только за прошлый год количество кибератак увеличилось более чем в пять раз, однако ситуация набирает обороты. Вероятность крупных утечек увеличивается, и на практике с ними сталкиваются даже крупные ИТ-компании. Как отмечают специалисты из Техасского университета, половина организаций, допустивших потерю данных, прекращает работу в течение двух лет. Для малого бизнеса, который, очевидно, обладает меньшим запасом прочности, эта цифра возрастает до 70%, а срок остановки деятельности сокращается до одного года.Но даже если компании удаётся выжить после утечки, она все равно несет репутационные риски. Затронутые аварией партнеры и клиенты начинают меньше доверять продуктам, которые предлагает пострадавший бизнес. Как показывает текущая ситуация, столкнуться с такими проблемами не так и сложно. Дело не только в киберпреступниках, которые постоянно разрабатывают новые инструменты и способы взлома — в том числе на базе систем искусственного интеллекта. Но и в том, что фреймворки вроде ISO 27001, NIST Cybersecurity Framework и другие методологии, связанные с информационной безопасностью, зачастую не успевают за изменениями и теряют актуальность для определенных организаций. Они отдаляются от реальных кейсов, с которыми приходится сталкиваться ИБ-специалистам. Плюс — на внедрение и реализацию подобных практик уходят достаточно ощутимые объемы корпоративных ресурсов.
При этом существенная часть компаний, конечно же, считает киберриски главной угрозой для бизнеса и вкладывается в кадры. Ресурсы направляют и на закупку систем киберзащиты. В 2021-м этот рынок оценивали в $165 млрд, но аналитики ожидают, что к 2028 году он вырастет до $366 млрд. Таким темпам роста способствует разнообразие аппаратных и программных средств борьбы с кражей данных и других атак: от инструментов защиты сетевого периметра до антивирусного программного обеспечения. Сегодня мы хотели бы поговорить о конкретных решениях.
Суть Disaster Recovery
Среднестатистическая компания тратит до двух месяцев на закрытие уязвимости в инфраструктуре. В условиях текущего кризиса это время может увеличиваться, а в результате интенсивных атак — организации с большей вероятностью действуют в спешке и сталкиваются с серьезными сбоями. Минимизировать ущерб помогают бэкапы и решения Disaster Recovery. С их помощью можно восстановить данные и инфраструктуру при взломе, ошибке сотрудника или проблемах с железом.На первый взгляд, эти инструменты решают одну и ту же задачу — позволяют бизнесу продолжить работу, если инфраструктура вышла из строя или из БД пропали данные. Но между ними все же есть отличия.
Частота копирования данных. BaaS подразумевает отправку копий образов виртуальных машин по расписанию — например, раз в день — в холодное хранилище облачного провайдера. Когда происходит потеря данных, они просто восстанавливаются из сохраненной копии. Если говорить о системах Disaster Recovery, то в облаке формируется дополнительная площадка с постоянно обновляемыми репликами виртуальных машин, корпоративных приложений и сервисов — при этом репликация происходит регулярно на протяжении дня. Так, при возникновении сложностей нагрузка переключается на «запасной аэродром».
Актуальность данных — второе отличие, связанное с предыдущим пунктом. Дело в том, что бэкап подразумевает хранение множественных копий данных, и восстановить их можно до любой сохраненной версии. Но очевидно, что в этот момент часть информации будет утеряна — её объем зависит от расписания резервного копирования, определяющего параметр RPO (recovery point objective). В то же время восстановление данных из холодного хранилища занимает достаточно много времени, которое определяется параметром RTO (recovery time objective). На эту задачу может уйти от нескольких часов до дней — в зависимости от объемов информации. Все это время корпоративные сервисы простаивают.
Что касается систем аварийного восстановления, то их показатели RPO и RTO сильно меньше. Репликация проходит в фоновом режиме на протяжении дня, поэтому на резервной площадке всегда находится практически полная копия основной инфраструктуры, а переключение на «запасной аэродром» после ЧП происходит в течение нескольких минут. В результате бизнес не замечает последствий сбоя. Так, среди наших клиентов есть логистическая компания, для которой решение Disaster Recovery сократило время простоя систем на 20%.
Однако стоит заметить, что системы аварийного восстановления не позволяют «откатить» инфраструктуру к более ранним состояниям, так как на резервной площадке находится полная копия приложений и БД. В этом контексте имеет смысл использовать системы резервного копирования и аварийного восстановления в паре, чтобы исключить больший спектр рисков.
Отказоустойчивость. Наконец, резервное копирование не является инструментом обеспечения непрерывной работы. Но аварийное восстановление дает более устойчивый к различным рискам фундамент, дополнительно повышает безопасность инфраструктуры, помогает избежать убытков из-за простоя.
В этом ключе работа Disaster Recovery подразумевает два сценария. Первый — когда корпоративные сервисы запущены on-premise, а в качестве резерва выступает облако. Во втором случае роль основной и запасной площадки играет геораспределенная облачная инфраструктура провайдера. Какой вариант выбрать — зависит от нужд организации и необходимого плана восстановления.
Что еще можно сделать
Начиная работу с бэкапами и системами аварийного восстановления, следует помнить о ряде моментов. Нужно регулярно оценивать работоспособность бэкапов и инфраструктуры на резервных площадках, чтобы не оказаться в ситуации, когда восстановить систему после сбоя невозможно.Для этого достаточно проводить регулярные выборочные проверки и тестовые миграции на резервную площадку. Параллельно имеет смысл делать ревизию сохраняемых данных с целью исключить неактуальную информацию. Такой подход позволит сэкономить ресурсы и место на дисках с копиями.
Эти очевидные рекомендации позволят серьезно повысить отказоустойчивость инфраструктуры. Но к сожалению, следуют им далеко не все — по статистике, больше половины бэкапов находится в неработоспособном состоянии.
Чтобы повысить надежность инфраструктуры, стоит обращать не только на резервные копии и реплики, но и на сами приложения, которые подлежат защите. Во время разработки эксперты рекомендуют следовать практикам graceful degradation. Они определяют способность системы продолжать работу даже при отказе некоторых ее компонентов — это особенно важно в контексте инфраструктуры корпораций, включающей тысячи взаимосвязанных сервисов.
Что запомнить
Бэкапы позволяют сохранить копию данных, а затем восстановить в случае утери. Но Disaster Recovery создает работающую копию сервисов и восстанавливает их работоспособность при серьезных сбоях в течение нескольких минут — столько нужно на переключение трафика. Мы в #CloudMTS также предлагаем провести тестовое восстановление, чтобы оценить решение на практике.
Аварийное восстановление и резервное копирование в облаке
Решения Disaster Recovery восстанавливают работоспособность ИТ-инфраструктуры после сбоя или атаки. Объясняем, как использовать вместе с резервным копированием. Материал будет полезен специалистам,...
habr.com