Вместо введения
Для кого я решил написать? Данная статья, написана для моих коллег аналитиков или для тех, кто желал бы им стать. Если вы теперь захотели стать аналитиком, то подумайте хорошенько.
Микросервисы. С хайпом вокруг них, лучше быть разработчиком, архитектором, тестировщиком, проджект-менеджером, дизайнером. Хорошо быть кем угодно в микросервсиах, но только не аналитиком. Аналитик ведь всегда во всем виноват. Ни разу не слышал, чтобы в “факапе” и срыве сроков обвинили архитектора, ну или там разработку. Нет, господа, вина всегда лежала и будет лежать на плохой документации и нечетко поставленных задачах. Вот вся команда собралась и тычет в тебя пальцами. Дескать, это все он! Опытный архитектор спроектировал, хороший разработчик сделал, внимательный тестировщик протестировал, мотивированный проджект-менеджер обеспечил… а невнимательный аналитик все завалил. А меж тем, материалов по аналитике и как её вести на русском языке очень мало. И как “анализировать” эти самые микросервисы не совсем понятно. Более того, никто вам не скажет, чем “системный аналитик” теперь отличается от “солюшн архитектора”. Вот во всем этом я и захотел разобраться и поделиться. Поэтому, если вы не аналитик - не читайте. Вам не будет интересно. Ведь, нет в вас экзистенциального кризиса и вопросов “Кто я? и зачем я им нужен на проекте”.
Самая популярная задача для аналитика - пилим “монолит” на “микросервисы”.
Зачем был нужен аналитик? Писать документацию! Дело в том, что за последние 2 года в “энтерпрайсе” наметилась четкая тенденция - распил “монолита” на “микросервисы”. Часто причиной данного процесса называется угроза санкций, считается что “монолит” сопровождает вендор, лоббирующий интересы западных разработчиков программного обеспечения. Хотя я бы выделил основной причиной так называемые “гибкие методологии” или, как часто мы говорим, нарицательно, вольно и обощенно - Agile. Попробовали сопровождать “монолит” в условиях двухнедельных спринтов и поняли, что это проблематично - постоянно меняющиеся API, модель данных, интерфейсы затрагивают всю систему и слишком много ресурсов и нервов на её сопровождение уходит. Понятно стало, что нужен какой-то новый подход. Вот и обратились к описанному Мартином Фаулером уже лет 10 назад архитектурному стилю - микросервисам. Ведь действительно, очевидное преимущество микросервиса в том, что его вполне может сопровождать один человек. И конечно же, казалось бы, такую систему, на первый взгляд, будет проще масштабировать как горизонтально, так и вертикально.
Сначала идеи были революционными:
Гост 19, Гост 34, ITIL и COBIT все?
К сожалению, да. Хотя, наверное стоит сказать, что все практики, применявшиеся ранее в Agile потребовали скорее переосмысления, нежели отмены вообще. Почему так произошло? Неужели в старых методиках ничего хорошего не было?
Для чего мы пришли к гибким методологиям? Agile применяют тогда, когда не ясно что нам надо сделать и мы допускаем что цели и задачи, впрочем как и ИТ-стратегия (в том смысле этого термина, который указан в COBIT) будут меняться. А значит, в гибких методологиях, изменился и подход к написанию и ведению документации. И к роли аналитика, стало быть подход также должен измениться.
Каждый спринт рождает новые задачи и писать документ каждый раз, как этого требует ГОСТ 19 это безумие.
Как пример успешного применения “гибкой методологии” я привожу в пример историю созданию логотипа “Hello Kitty”. Дизайнер Юко Симитсу за год смог нарисовать логотип для магазина игрушек, который нравился всем. Секрет успеха данного логотипа прост - дизайнер каждый свой новый набросок показывал потенциальным покупателям данного магазина. Через год работы результат его работы был идеален. Вообще, подходы Юко Симитсу для Японии не новы. Стоит вспомнить, описанные в культовой книге “Дао Тойота” принципы бережливого производства. Да-да, знатоки SCRUM скажут, что идею Мартин Фаулер и компания взяли оттуда. Но что же это означает для нас?
Прежде всего то, что мы не пишем документ раз и навсегда. Каждый спринт у нас появляется задание на разработку, которое мы перед началом каждого спринта обновляем. И тут какого-то общего стандарта, правила хорошего тона быть не может. Такая документация может быть написана в JIRA, ASANA или в модном сейчас продукте компании Atlassian Confluence. Хотя, если в одном из проектов, где все было завязано на bitbucked, мы использовали документацию, написанную в формате markdown и хранили непосредственно в репозитории в ветке, соответствующей спринту. Но в целом, тренд таков - документация с подробным описанием это Confluence. Карточка с временем заведения задачи, ответственным за выполнение, кратким описанием и сроком это Jira, а материалы для доработки это git или bitbucked.
Для того, чтобы не запутаться в этом море различных артефактов, необходимо вести четкую их шифровку, для того, чтобы понимать к какой задаче артефакт относится. И очень удобно использовать для такой шифровки так называемый тикет в Jira, как “головную сущность”, к которой привязывают все остальные артефакты. Тикет также не существует сам по себе, а привязан к какому-либо git-эпику и agile-спринту. Причем у “эпика” и “спринта” также есть свои шифры. Где должен быть указан данный шифр: он должен фигурировать в названии страницы Confluence и в commit Git или Bitbucked. Кстати, в ветках git также необходимо вести порядок. Все изменения должны сливаться в мастер-ветку из ветки в названии которой фигурирует шифр задачи из тикета Jira. Только так возможно найти нужный артефакт по поиску в web-форме.
И многие по началу очень буквально восприняли фразу о том, что документация не столь важна, сколько работающий продукт. Спустя два года стал понятен истинный смысл этой фразы из манифеста Agile. Так, в начале пандемии в связи с тем, что количество платежей по картам возрасло в одном из ритейлеров карточные операции под неожиданно возросшей нагрузкой просто отказали. Начали разбираться. А документации и нет. Те разработчики, что делали уже уволились. От них осталось куча веток и непонятные комиты в git. Правда, остался архитектор. Но он в Пунта-Кане пьет ром и выключил телефон. Так вот, документация не так важна, если продукт работает и устойчив к “черным лебедям”.
Из вышесказанного следует, что документация не то что не становится необязательной, но и увеличивает свое значение. Меняется только система её производства. Она становится артефактом Agile. И должна быть вплетена в его систему. Документацию все также должен производить аналитик и должна она охватывать следующие категории:
А вот дальше начинаются доработки по "гибким методологиям". Конечно же, вносятся правки в исходную документацию. При этом создаётся новая на каждую доработку или "новую фичу".
Что такое “микросервис” технически и чем он отличается принципиально от “монолита”?
Хороший вопрос, не так ли? Вам ведь часто задавали его на интервью. Давайте попытаемся разобраться. Тут следует начать с того, что Мартин Фаулер в 2012 году говорил о так называемой “слабой связности”. И “слабая связность” становится в микросервсиной архитектуре центральным понятием. Если цитировать классика, это означает, что внесение изменений в один объект оказывает минимальное воздействие на остальные объекты системы.
Как это реализовано? Микросервисы укладываются в так называемые “контейнеры”, которые являются функциональными синонимами виртуальных машин. Правда в отличии от виртуальных машин, у них нет своей операционной системы, есть лишь базовые команды UNIX. Контейнеры оркестрируются через специальную платформу, которая распределяет нагрузку, координирует взаимодействие и масштабирует всю систему. Как правило, под такой платформой понимают хорошо известную систему Kubernetes.
К чему я все это рассказываю? Ведь аналитики пишут документацию и внутренняя начинка им вроде бы ни к чему.дело в том, что при микросервисном подходе, впрочем как и в "кастомной" ( от английского слова "custom" - “покупатель” . В данном котексте разработка своими силами без вендора) фантастически важно не только учитывать нефункциональные требования, но и уметь их описывать. И если раньше, они прописывались в верхнеуровневой документации, то с приходом "гибких методологий" их важно не забывать, учитывать и прописывать. Это требования касательно:
Разворот от бизнес-аналитики к системной аналитике
За последний год грань между системными аналитиком и солюшн архитектором стала практически неразличимой. От аналитиков все чаще требуют “предлагать решения”, для задач которые ставит бизнес. А это означает, что Agile и его подходы поставили под сомнение надобность методов бизнес-анализа. Лет 5 назад было абсолютно нормальным говорить бизнесу о том, что ему надо. Теперь это не так. Бизнес теперь диктует ИТ, что ему нужно и сам предоставляет аналитику. На проекте же, требования бизнеса продуктовая команда должна принять, и правильно оценить ресурсы, которые необходимы для реализации. И вот тут от аналитиков начинают требовать знания, которые мало требовали раньше. Когда-то жил такой Блаженный Августин, который рассуждал об “унивокальности”. То есть о суть вещей для Бога и для человека должна быть одна и таже. Давно пора всем уяснить, что Богом для нас является бизнес. Он создатель, он творец и не надо ему рассказывать, что ему нужно. Вот бизнес отдал “фидбек по фиче” и задачей анализа становится реализация замысла. Поэтому, за последнее время бизнес-логику приходилось строить все реже, а вот акцент в сторону нефункциональных требований в условиях микросервисного архитектурного стиля стал существенным. Ниже я попытался классифицировать решения, которые необходимо предлагать на бизнес-задачи. Тут ничего нового, все теже две “вечные темы” - интеграция, маршрутизация и базы данных.
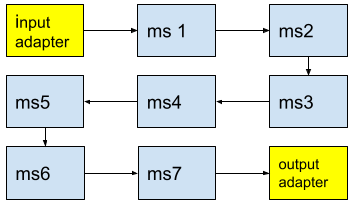
 Рисунок. Иллюстрация маршрутизации по паттерну “Хореография”. Сообщение попадает во входной адаптер, а от него в первый микросервис. Маршрутизация сообщения происходит происходит в самих микросервисах.
Рисунок. Иллюстрация маршрутизации по паттерну “Хореография”. Сообщение попадает во входной адаптер, а от него в первый микросервис. Маршрутизация сообщения происходит происходит в самих микросервисах.
 Рисунок. Иллюстрация маршрутизации по паттерну “Оркестрация”. Микросервисы не знают, в какой момент времени будут вызваны. Вызов осуществляется оркестратором, который по защитой в него логике определяет в какой момент, какой микросервис будет вызван.
Рисунок. Иллюстрация маршрутизации по паттерну “Оркестрация”. Микросервисы не знают, в какой момент времени будут вызваны. Вызов осуществляется оркестратором, который по защитой в него логике определяет в какой момент, какой микросервис будет вызван.
Я не хочу сказать, что бизнес-анализ больше не нужен. Он нужен, но происходит четкое разделение на бизнес-аналитиков и аналитиков системных. Интересно то, что бизнес-аналитики все чаще остаются на стороне заказчика, а в продуктовых командах остаются аналитики системные.
Микросервисы, это всерьез и на долго. Но не навсегда.
Когда меня просят провести аналогии, чтобы проиллюстрировать процессы, идущие в ИТ-системе в “энтерпрайсе”, мне нравится цитировать работу Metropolis, в которой сотрудники Microsoft сравнивают эту самую ИТ-систему с городом времен начала промышленной революции. Не буду пересказывать эту статью, её можно найти в открытом доступе. Однако, если уж мы сравниваем ИТ-систему с городом, то любой город рано или поздно стремился к централизации, укрупнению и наведению порядка. Как пример, можно привести процесс постепенного исчезновения вещевых рынков в российских городах и постепенным их вытеснением крупными торговыми центрами. Если вспомнить старика Ленина, который говорил что Новая Экономическая Политика,это всерьез и надолго, но не навсегда, то невольно напрашивается аналогия, о том, что новый микросервисный архитектурный стиль рано или поздно также должен показать свои недостатки. Вот теперь стало понятно, что нагромождение микросервисов плохо масштабируется и очевидно, микросервисы это не всегда хорошо. Так когда же нам стоит их использовать?
, которая содержит в себе основную часть приложения и форпосты (Outpost), являющиеся микросервисами, обеспечивающими вспомогательный функционал. Монолит с форпостами предлагалось связывать через Kafka.") Рисунок. Концептуальная схема паттерна “Цитадель”, созданная по материалам оригинального доклада DHH в 2020 году. Выделена монолитная часть (в оригинале Majestic Monolith), которая содержит в себе основную часть приложения и форпосты (Outpost), являющиеся микросервисами, обеспечивающими вспомогательный функционал. Монолит с форпостами предлагалось связывать через Kafka.
Рисунок. Концептуальная схема паттерна “Цитадель”, созданная по материалам оригинального доклада DHH в 2020 году. Выделена монолитная часть (в оригинале Majestic Monolith), которая содержит в себе основную часть приложения и форпосты (Outpost), являющиеся микросервисами, обеспечивающими вспомогательный функционал. Монолит с форпостами предлагалось связывать через Kafka.
Если уж мы заговорили о "Цитадели", то давайте вспомним те самые пресловутые автотесты. Часто ведь аналитиков подключают к разработке стратегии тестирования? И на моей памяти редко удавалось уложить в автотесты более четверти (25%) от всех процессов. Так вот, со временем обозначилась четкая корреляция между монолитной части цитадели и процессами, успешно подвергшимися автотестированию. Собственно, однозначного ответа на то, что в первую очередь покрыть автотестами ни у кого нет, но интуиция подсказывает - покрывайте то, что наиболее устоялось. В цитадели это монолитная часть. Хотя, наверное, тоже самое можно сказать про любой оркестратор.
Неожиданно возникшие трудности - Highload и проблемы с масштабированием.
Всегда ли микросервисная система будет хорошо масштабироваться? Вот в последнее время часто говорят о так называемом “хайлоаде”. “Хайлоад” это система, которая с определенного момента начинает масштабироваться плохо и традиционный подход с введением в эксплуатацию более производительного “железа” работать перестает. Мне нравится пример из физики ядерных реакторов и расследования причин аварии на чернобыльском реакторе РБМК-1000. Академики Долежаль и Александров фактически увеличили в размерах хорошо зарекомендовавшие себя реакторы, апробированные на подводных лодках и ледоколах. Они при проектировании промышленного реактора увеличили размер активной зоны в расчете получить нужную мощность. Как итог, активная зона стала настолько огромна, что каждая её часть начала жить своей собственной жизнью и в определенных режимах плохо поддавался контролю.
В поисках аналогии к вышеописанной ситуации давайте посмотрим, как у нас обычно решаются проблемы с нагрузкой. Если производительность резко возрастает, то есть универсальное средство - докупить железа. То есть совершается, как говорят в академической среде, горизонтальное масштабирование. И рано или поздно настает момент, когда оно больше не работает. Какие бы вы сервера производительные не ставили, и в каком бы количестве,это не важно. Система все равно не справляется с нагрузкой. Ситуацию возможно изменить вертикальным масштабированием (когда приходится пересматривать внутренние связи, координацию звеньев системы и прочее), хотя, впрочем, и оно не всегда помогает. Состояние высоконагруженной системы, при котором она слабо масштабируется называется “хайлоадом”.
Причин в отсутствии способности к масштабированию может быть сколько угодно. Но вот за последнее время все чаще такой причиной является “семантическое безумие”, котором я говорил в ряде своих предыдущих работ. В кратце поясню, что “семантическим безумием” в ИТ-системе называется ситуация, когда одно и туже сущность начинают называть по-разному, и наоборот - разные бизнес-сущности начинают называть одинаково. В итоге, происходит вырождение и расхождение моделей данных и размываются границы микросервисов. Это приводит к дублированию функционала, увеличению количества адаптеров и как следствие плохой способности к масштабированию. А что есть адаптеры в крупной системе? Адаптеры это время на преобразование и рассинхронизация по тому же времени с другой. В итоге, при наборе "критической массы" адаптеров система плохо поддается масштабированию и старый добрый способ "добавить железа" работать перестает.
 Рисунок. Кривая зависимости времени обработки заявки на платформе с хореографией от количества адаптеров в системе.
Рисунок. Кривая зависимости времени обработки заявки на платформе с хореографией от количества адаптеров в системе.
Чтобы стало понятно, давайте рассмотрим старую хорошо известную модель "потребитель-поставщик". В больших системах необходимо четко решить задачу тайминга. Потребитель должен запросить работу поставщика ровно в тот момент, когда он готов это сделать. В нашем случае это означает, что на стороне поставщика должны быть выполнены все подготовительные к запросу потребителя операции. То есть, все транзакции в базах данных выполнены, все бизнес-операции проделаны и все данные преобразованы в нужный формат. С большим количеством адаптеров, микросервисов и моделей данных данная задача в условиях хореографии становится сложно выполнимой и системе нужен оркестратор. Еще один аргумент в пользу "Цитадели" и маршрутизации сообщений в ней.
DDD и онтология как наиболее удобные подходы для проектирования микросервисных систем.
И так, что бывает, когда множество людей начинают творить? Самый главный эффект в том, что “разъезжаются” модели данных и возникает то самое “семантическое безумие”, о котором я говорил раньше. И проблема даже не в самом “семантическом безумии”, когда одну и туже сущность называют по-разному (я неоднократно приводил примеры со словосочетанием “номер счета”), сколько во времени, которое тратится на согласование модели данных. Как этого избежать? За время своего опыта аналитики я не нашел лучшего подхода, чем онтология, которая переходит в Domain Driven Design(DDD). Когда-то давно была еще методология EDF0. Все они, так или иначе крутятся вокруг установления субъектов и объектов предметной области и связей между ними. Жил в Ростове-на-Дону Б.Я. Шведин. Всем аналитикам советую ознакомиться с его монографией "Онтология предприятия". Так вот, если выделить такие субъекты и объекты и на их основе строить модель данных и определять границы микросервисов, то порядка в системе станет в разы больше. Почему? Ну данный подход строится на основании семантики, то есть бизнес-сути. И данная методика обычно противопоставляется подходам на основе декомпозиции бизнес-процессов.
Основной тезис подхода таков. Определяем пространство глобальных бизнес-объектов. Для него строим проекцию в пространстве объектов в модели данных. На основе проекции в модели данных строим классы в бековых системах (я тут имею ввиду data transfer object ), топологию сообщений xml или json, и в таблицах баз данных.
Обычно, в монолите, применялся подход аналитики бизнес-процессов, используя подходы описанные А.В. Шеером. Проводили анализ бизнес-процесса и модель данных строили исходя из бизнес-процесса. Таким образом, каждое новое требование регулятора, каждое новое требование рынка приводило к созданию новой модели данных. Аналогичная ситуация и с созданием микросервиса. Декомпозиция бизнес-процессов на моей памяти неоднократно приводила к дублированию функционала и возникновению семантически идентичных микросервисов. Поэтому, с данным подходом (через бизнес-процессы) надо быть осторожным. Тем более, что если мы им пользуемся, то нужно с самого начала закладывать четкие принципы хореографии микросервисов, чтобы не возникало путаницы.
Я же, исходя из своего опыта, предлагаю следующий подход. Давайте построим онтологию, выделив основные субъекты, объекты и связи между ними. Дальше каждому выделенному объекту или субъекту сопоставив домен, определив все возможные состояния объекта. Стало быть домен - суперпозиция всех состояний домена в концепции DDD. А дальше каждому такому состоянию ставим в соответвствие микросервис. Все микросервисы домена связаны между собой локальным оркестратором. Глобальный оркестратов также имеется на платформе в едиственном экземпляре.
 Рисунок. Иллюстрация объектно-ориентированного паттерна проектирования микросервисной системы с оркестратором.
Рисунок. Иллюстрация объектно-ориентированного паттерна проектирования микросервисной системы с оркестратором.
При объектно-ориентированном подходе хореография и вовсе не нужна. Нужна будет оркестрация. Кстати, если использовать шаблон проектирования "цитадель", о котором я писал выше, то роль оркестратора может играть та самая монолитная часть.
Давайте разберем эти два подхода подробнее. Принцип "атомарности" и "слабой связности" в микросервисах приводит к тому, что если идти по пути аналитики бизнес-процессов, каждая элементарная операция рождает свой микросервис. Теперь же, давайте представим что мы вместо декомпозиции бизнес-процессов пошли по пути выделения субъектов, объектов и связей между ними. Мало того, что мы их выделили, мы еще и определили их атрибуты и состояния. Кстати,понятие "класс" для микросервисов в данном случае очень даже применимо. Таким образом, мы разметили предметное поле и на основе этой разметки строим микросервисы по следующему принципу - каждый микросервис это состояние субъекта или объекта. Причем эти состояния объединены в кластер согласно семантике и общаются друг с другом через оркестратор.
И какие новые задачи встают перед аналитиком? Года два назад на одном из митапов мне сказали что корпоративные словари и классификаторы это порочная практика. Сейчас спустя два года стало понятно, что без них бороться с "семантическим безумием" стало проблематично. Ведение таких словарей хоть в каком-то виде - задача аналитика.
Важнейшим объектом для нас остаётся модель данных.
Давайте проведем мысленный эксперимент. Допустим у нас есть клиника для душевно больных. У нас есть пациент А, который обладает важными для пациента Б сведениями. Проблема заключается в том, что у пациентов А и Б разный бред и разные галлюцинации, вследствие этого, наладить контакт у них не получается. И вот тут появляется врач-психиатр, который для всех пациентов устанавливает единые правила общения. Вот аналитик на проектах и должен стать таким врачом-психиатром.
Еще три года назад аналитики только и занимались тем, что делали маппинги. Маппинги выглядят как электронные таблицы, в ячейки которых аккуратно заносили название атрибута и xpath для одной и другой системы. Вот в эпоху монолита только и занимались аналитики, что делали маппинги для построения адаптеров, фасадов и прочих "перекладчиков".
С появлением микросервисного подхода проблемы с моделями данных ушли на второй план. Когда все сервисы ИТ-системы взаимодействовали через корпоративную шину существовала "каноническая модель данных". Помните про фракийский язык? "Лингва франка"? Язык торговцев средиземного моря. Сейчас в крупных ИТ- системах также встаёт надобность говорить на понятном друг другу языке. Как это организовать?
Давайте вспомним модель трехзвенной архитектуры. У нас есть "фронт", есть "бек" и есть хранилище. Важно обеспечить во всех трех звеньях семантическое соответствие данных. Часто ведь бывает так, что с бизнесом согласуют доработку через демонстрацию так называемых "интерфейсов намерения" каким часто выставляют UI, то есть пользовательский интерфейс. Данная, по моему мнению, порочная практика приводит к тому, изменения в интерфейсе приводят к недопустимым изменениям в боковой части. И мое мнение, что согласовывать надо всегда состав и структуру предоставляемых во фронт данных.
Как обеспечить это согласование? Самым надежным способом является использование старого доброго API Gateway. И вот в этой единой точке входа мы складываем схемы (xsd или json). И вот по этим схемам должна осуществляться валидация данных. А внутри никаких адаптеров быть не должно. Все изменения касаются в первую очередь структуры и состава схем. И так,получается, что модель данных мы храним в схемах. И поддерживать ее актуальность также должны аналитики. Конечно, обращения в корпоративные хранилища через очередь не позволят везде использовать API Gateway, все равно расхождения будут. Но единая корпоративная модель данных, в которой если не весь набор атрибутов, то хотя бы топология данных идентична - это очень хорошая идея. Да и вообще, новая роль - архитектор модели данных. Мне кажется, в скором времени эта специальность будет очень востребована. В чем ее вести? Open Api, Swager, Git? Вопрос пока открытый.
Вместо выводов
Может кому-то не понравятся мои слова, но аналитика в ИТ - это чистая техносфера. Для того, чтобы стать успешным аналитиком, нужно научиться мыслить как инженер. Хорошо бы, конечно, иметь, пусть даже не профильное, но все-таки инженерное академическое образование. Мне часто наработанная на производстве интуиция давала правильные аналогии с “теорией машин и механизмов”, “теоретической механикой” и прочими сугубо техническими дисциплинами. Любой модуль в энтерпрайсе рукотворен, а значит он как-то и через что-то взаимодействует с другими модулями и о любом процессе можно узнать, запросив соответствующую метрику для контроля ситуации. Никакой метафизики и эзотерики тут нет. Все довольно приземленно и материально. И имея определенный бекграунд, вооружившись старым опытом и хорошими книгами, во всем всегда можно разобраться, читая документацию, которая всегда, как правило, находится в свободном доступе.
Часто же, попадая в ИТ тусовку обращаешь внимание, на лексику айтишников. Она полна различных диковинных терминов. “Бекграунд”, “Фича”, “Пофиксить”... Эти новые слова дают ощущение недосягаемости знаний по ИТ. Потом, погрузившись и во всем разобравшись, ты удивляешься - насколько все просто, и тому сколько раз ты подобное видел в других инженерных областях. А зачем тогда такая новая лексика? Данный феномен характерен для закрытых сообществ, претендующих на некую элитарность. Ну у меня лично напрашивается аналогия с криминальной средой начала 20 века, может потому что я из Ростова-на-Дону. Урки часто определяли своих по манере понимать блатную “феню”. Не говоришь на ней и не понимаешь, ну тогда тебе не место в криминальной среде. Так что часто, обучение в ИТ заключается только лишь в сопоставлении старым знаниям новых терминов.
Разномазов Валерий,© 2022
 habr.com
habr.com
Для кого я решил написать? Данная статья, написана для моих коллег аналитиков или для тех, кто желал бы им стать. Если вы теперь захотели стать аналитиком, то подумайте хорошенько.
Микросервисы. С хайпом вокруг них, лучше быть разработчиком, архитектором, тестировщиком, проджект-менеджером, дизайнером. Хорошо быть кем угодно в микросервсиах, но только не аналитиком. Аналитик ведь всегда во всем виноват. Ни разу не слышал, чтобы в “факапе” и срыве сроков обвинили архитектора, ну или там разработку. Нет, господа, вина всегда лежала и будет лежать на плохой документации и нечетко поставленных задачах. Вот вся команда собралась и тычет в тебя пальцами. Дескать, это все он! Опытный архитектор спроектировал, хороший разработчик сделал, внимательный тестировщик протестировал, мотивированный проджект-менеджер обеспечил… а невнимательный аналитик все завалил. А меж тем, материалов по аналитике и как её вести на русском языке очень мало. И как “анализировать” эти самые микросервисы не совсем понятно. Более того, никто вам не скажет, чем “системный аналитик” теперь отличается от “солюшн архитектора”. Вот во всем этом я и захотел разобраться и поделиться. Поэтому, если вы не аналитик - не читайте. Вам не будет интересно. Ведь, нет в вас экзистенциального кризиса и вопросов “Кто я? и зачем я им нужен на проекте”.
Самая популярная задача для аналитика - пилим “монолит” на “микросервисы”.
Зачем был нужен аналитик? Писать документацию! Дело в том, что за последние 2 года в “энтерпрайсе” наметилась четкая тенденция - распил “монолита” на “микросервисы”. Часто причиной данного процесса называется угроза санкций, считается что “монолит” сопровождает вендор, лоббирующий интересы западных разработчиков программного обеспечения. Хотя я бы выделил основной причиной так называемые “гибкие методологии” или, как часто мы говорим, нарицательно, вольно и обощенно - Agile. Попробовали сопровождать “монолит” в условиях двухнедельных спринтов и поняли, что это проблематично - постоянно меняющиеся API, модель данных, интерфейсы затрагивают всю систему и слишком много ресурсов и нервов на её сопровождение уходит. Понятно стало, что нужен какой-то новый подход. Вот и обратились к описанному Мартином Фаулером уже лет 10 назад архитектурному стилю - микросервисам. Ведь действительно, очевидное преимущество микросервиса в том, что его вполне может сопровождать один человек. И конечно же, казалось бы, такую систему, на первый взгляд, будет проще масштабировать как горизонтально, так и вертикально.
Сначала идеи были революционными:
- Убиваем традиционную ESB и заменяем её фриварным решением типа Kafka для обеспечения асинхронного взаимодействия. Там, где асинхронное взаимодействие не нужно, пользуемся REST API.
- Убиваем централизованное хранилище на основе СУБД Oracle и заменяем его фриварным на PosgtreSQL. Причем все говорили о том, что каждый микросервис имеет свою обособленную базу данных.
- Никаких стандартов больше не существует. Каждый в праве использовать собственную модель данных и собственный стек технологий.
- Большую микросервисную систему интегрально оказалось тяжело сопровождать. Если вспомнить манифест Agile, то в нем есть пункт о том, что “работающий продукт важнее документации”. Часто это выливалось в то, что документация отсутствовала вовсе. Да даже если она была, то вследствии написания различными командами сильно расходилась в терминологии. В своих предыдущих работах и выстплениях я называл этот феномен “семантическим безумием”. В случае возникновения “факапа” такая “безумная” документация требовала дополнительной оценки и сопоставления, что требовало дополнительного времени. Причем, если в “монолите”, сопровождаемом одним вендором и одной, пусть и большой, командой паттерны проектирования были одинаковы и сопоставимы, то в микросервисах каждая команда выбирает свой API и свой стек технологий.
- Вдруг вспомнили про так называемые нефункциональные требования. Оказалось что, время обработки и производительность микросервисных систем не такая высокая. Почему так произошло? Agile и плохая коммуникация команд, в условиях слабого архитектурного надзора, порождают большое количество точек интеграции. И вот их как-то надо синхронизировать по таймингу с одной стороны, а с другой помнить, что подключение к адаптеру (он же может быть “фасадом” или “маппером”) и отключение от адаптера происходит за конечное время. Кроме того, стоит сказать, что финтех подразумевает лавинообразный рост подключений пользователей (например, мы его наблюдали в начале пандемии, когда резко возросло количество покупателей в интернет-магазинах) и для того, чтобы его выдерживать, должны быть заранее продуманы аварийные и дублирующие механизмы. И вот кто должен был предложить эти решения? Архитектор? Нет, коллеги. Предложения решений на уровне команды начали ждать от аналитиков.
- Как таковые начали умирать бизнес-аналитики и приобретать вес люди с инженерным опытом, или как часто говорят “бековым”, их же называют “системными аналитиками”. Почему так происходит. Потому что возрасла зрелость бизнеса и в условиях Agile работой бизнес-аналитиков часто становится переписывание ежеспринтового фидбека заказчика в малопонятные команде схемы. Меж тем, ввиду отсутствия генерального стандарта, единой модели данных и плохой коммуникации техническая часть начала требовать более тщательного анализа и предварительной проработки.
- Произошло сращивание ролей и функциональных обязанностей архитектора, тестировщика и аналитика. Почему так происходит. Ну, во первых, Agile. В его рамках только разработчики не берут чужих обязанностей. Остальные же делят их между собой. Во вторых, ввиду малости временного промежутка, люди имеют разный опыт в работе с тем или иным стеком. Хотя, хотелось бы отметить один интересный факт. Несмотря на смешение ролей, в случае какой-то неудачи в ходе выполнения проекта, виноватым все равно оставался только лишь аналитик. Архитектор и тестировщик разводили руки и говорили, что они не при чем.
Гост 19, Гост 34, ITIL и COBIT все?
К сожалению, да. Хотя, наверное стоит сказать, что все практики, применявшиеся ранее в Agile потребовали скорее переосмысления, нежели отмены вообще. Почему так произошло? Неужели в старых методиках ничего хорошего не было?
Для чего мы пришли к гибким методологиям? Agile применяют тогда, когда не ясно что нам надо сделать и мы допускаем что цели и задачи, впрочем как и ИТ-стратегия (в том смысле этого термина, который указан в COBIT) будут меняться. А значит, в гибких методологиях, изменился и подход к написанию и ведению документации. И к роли аналитика, стало быть подход также должен измениться.
Каждый спринт рождает новые задачи и писать документ каждый раз, как этого требует ГОСТ 19 это безумие.
Как пример успешного применения “гибкой методологии” я привожу в пример историю созданию логотипа “Hello Kitty”. Дизайнер Юко Симитсу за год смог нарисовать логотип для магазина игрушек, который нравился всем. Секрет успеха данного логотипа прост - дизайнер каждый свой новый набросок показывал потенциальным покупателям данного магазина. Через год работы результат его работы был идеален. Вообще, подходы Юко Симитсу для Японии не новы. Стоит вспомнить, описанные в культовой книге “Дао Тойота” принципы бережливого производства. Да-да, знатоки SCRUM скажут, что идею Мартин Фаулер и компания взяли оттуда. Но что же это означает для нас?
Прежде всего то, что мы не пишем документ раз и навсегда. Каждый спринт у нас появляется задание на разработку, которое мы перед началом каждого спринта обновляем. И тут какого-то общего стандарта, правила хорошего тона быть не может. Такая документация может быть написана в JIRA, ASANA или в модном сейчас продукте компании Atlassian Confluence. Хотя, если в одном из проектов, где все было завязано на bitbucked, мы использовали документацию, написанную в формате markdown и хранили непосредственно в репозитории в ветке, соответствующей спринту. Но в целом, тренд таков - документация с подробным описанием это Confluence. Карточка с временем заведения задачи, ответственным за выполнение, кратким описанием и сроком это Jira, а материалы для доработки это git или bitbucked.
Для того, чтобы не запутаться в этом море различных артефактов, необходимо вести четкую их шифровку, для того, чтобы понимать к какой задаче артефакт относится. И очень удобно использовать для такой шифровки так называемый тикет в Jira, как “головную сущность”, к которой привязывают все остальные артефакты. Тикет также не существует сам по себе, а привязан к какому-либо git-эпику и agile-спринту. Причем у “эпика” и “спринта” также есть свои шифры. Где должен быть указан данный шифр: он должен фигурировать в названии страницы Confluence и в commit Git или Bitbucked. Кстати, в ветках git также необходимо вести порядок. Все изменения должны сливаться в мастер-ветку из ветки в названии которой фигурирует шифр задачи из тикета Jira. Только так возможно найти нужный артефакт по поиску в web-форме.
И многие по началу очень буквально восприняли фразу о том, что документация не столь важна, сколько работающий продукт. Спустя два года стал понятен истинный смысл этой фразы из манифеста Agile. Так, в начале пандемии в связи с тем, что количество платежей по картам возрасло в одном из ритейлеров карточные операции под неожиданно возросшей нагрузкой просто отказали. Начали разбираться. А документации и нет. Те разработчики, что делали уже уволились. От них осталось куча веток и непонятные комиты в git. Правда, остался архитектор. Но он в Пунта-Кане пьет ром и выключил телефон. Так вот, документация не так важна, если продукт работает и устойчив к “черным лебедям”.
Из вышесказанного следует, что документация не то что не становится необязательной, но и увеличивает свое значение. Меняется только система её производства. Она становится артефактом Agile. И должна быть вплетена в его систему. Документацию все также должен производить аналитик и должна она охватывать следующие категории:
- Описание API, протоколов и контрактов. То есть все маппинги, преобразования, модели данных. Правилом хорошего тона считается указание валидных примеров сообщений. Особое внимание следует уделить идемпотетности операций. Если, например, вы реализуете логику через REST API, надо понимать разницу в глаголах HTTP.
- Описание модели взаимодействующих систем. Модель остается классической - вызов типа “поставщик-потребитель”.
- Описание баз данных. Должны быть описаны таблицы, все ограничения и ключи. Особое внимание должно быть уделено кратности. Необходимо прописывать, с каким типом связи нужно работать "один-к-одному","один-ко-многим", "многие-ко-многим".
А вот дальше начинаются доработки по "гибким методологиям". Конечно же, вносятся правки в исходную документацию. При этом создаётся новая на каждую доработку или "новую фичу".
Что такое “микросервис” технически и чем он отличается принципиально от “монолита”?
Хороший вопрос, не так ли? Вам ведь часто задавали его на интервью. Давайте попытаемся разобраться. Тут следует начать с того, что Мартин Фаулер в 2012 году говорил о так называемой “слабой связности”. И “слабая связность” становится в микросервсиной архитектуре центральным понятием. Если цитировать классика, это означает, что внесение изменений в один объект оказывает минимальное воздействие на остальные объекты системы.
Как это реализовано? Микросервисы укладываются в так называемые “контейнеры”, которые являются функциональными синонимами виртуальных машин. Правда в отличии от виртуальных машин, у них нет своей операционной системы, есть лишь базовые команды UNIX. Контейнеры оркестрируются через специальную платформу, которая распределяет нагрузку, координирует взаимодействие и масштабирует всю систему. Как правило, под такой платформой понимают хорошо известную систему Kubernetes.
К чему я все это рассказываю? Ведь аналитики пишут документацию и внутренняя начинка им вроде бы ни к чему.дело в том, что при микросервисном подходе, впрочем как и в "кастомной" ( от английского слова "custom" - “покупатель” . В данном котексте разработка своими силами без вендора) фантастически важно не только учитывать нефункциональные требования, но и уметь их описывать. И если раньше, они прописывались в верхнеуровневой документации, то с приходом "гибких методологий" их важно не забывать, учитывать и прописывать. Это требования касательно:
- Нагрузки. Аналитику важно понимать, какую нагрузку выдержит инфраструктура. есть такая метрика как rps (request per second). Нужно уметь оценивать её и высчитывать. И помнить о том, что Ddos-атаки это не миф. Особенно в финтехе.
- Времени обработки. У каждого бизнеса есть свои требования. Например, в одном из проектов, в котором я участвовал время обработки розничной заявки ограничивалось 45 секундами. Так вот аналитику теперь следует понимать, какие процессы занимают время. Тайминговые диаграммы (“Диаграммы Ганта” и “seaquence”) могут стать хорошим украшением вашей документации.
- Количества одновременно подключенных пользователей. Фактически эта таже самая нагрузка, но подключение пользователя затрагивает такие аспекты как "авторизация" и "аутентификация". И если эти два процесса вынесены в отдельный микросервис, следует учитывать нагрузку на него.
- Безопасности данных. Этот пункт становится все более важным. С одной стороны дело касается личных данных и конфиденциальной информации, а с другой стороны возможности совершения операции. Аналитику важно понимать, где эти операции совершаются и где эти данные аккумулируются. Если раньше разницу между фронтом и беком аналитики не должны были чувствовать, то теперь они чувствовать ее обязаны. Я бы сказал, хорошо бы аналитикам начать понимать, что даёт экосистема языка javascript (фронт) и экосистема языка java (бек). Для чего? Перестать гонять во фронт данные, например.
- Возможных ошибках. По хорошему, необходимо создавать так называему “фабрику ошибок”, которая бы интерпретировала техничсекие сообщениия об ошибках в понятный пользователю текст.
Разворот от бизнес-аналитики к системной аналитике
За последний год грань между системными аналитиком и солюшн архитектором стала практически неразличимой. От аналитиков все чаще требуют “предлагать решения”, для задач которые ставит бизнес. А это означает, что Agile и его подходы поставили под сомнение надобность методов бизнес-анализа. Лет 5 назад было абсолютно нормальным говорить бизнесу о том, что ему надо. Теперь это не так. Бизнес теперь диктует ИТ, что ему нужно и сам предоставляет аналитику. На проекте же, требования бизнеса продуктовая команда должна принять, и правильно оценить ресурсы, которые необходимы для реализации. И вот тут от аналитиков начинают требовать знания, которые мало требовали раньше. Когда-то жил такой Блаженный Августин, который рассуждал об “унивокальности”. То есть о суть вещей для Бога и для человека должна быть одна и таже. Давно пора всем уяснить, что Богом для нас является бизнес. Он создатель, он творец и не надо ему рассказывать, что ему нужно. Вот бизнес отдал “фидбек по фиче” и задачей анализа становится реализация замысла. Поэтому, за последнее время бизнес-логику приходилось строить все реже, а вот акцент в сторону нефункциональных требований в условиях микросервисного архитектурного стиля стал существенным. Ниже я попытался классифицировать решения, которые необходимо предлагать на бизнес-задачи. Тут ничего нового, все теже две “вечные темы” - интеграция, маршрутизация и базы данных.
- Интеграция. Микросервисная архитектура, как явление, подразумевает некий плюрализм в области интеграционных решений. Лично я выделяю четыре способа интеграции:
- Через очередь (причем сюда же можно отнести транспорт на основе Kafka, который строго говоря, очередью не является)
- Через HTTP вызов. Это может быть REST API, а может быть по-старинке SOAP.
- Через базу данных, а почему нет?
- Через файл Да-да. Государственные органы часто используют протокол обмена файлами. И иногда это, правда, безопаснее.
- Базы данных. “Слабая связность” в микросервисном подходе позволяет каждому отдельному микросервису иметь свою базу данных. А это значит, что её во-первых нужно спроектировать, а во вторых доходчиво для разработчика описать. То есть, аналитику необходимо знать принципы работы СУБД. Когда говорим СУБД, чаще всего подразумеваем Posgres. Что же необходимо указать в документации:
- Описание таблиц со всеми атрибутами. То есть, это типы данных, допустимый объем данных в байтах, свойства NOT NULL и UNIQUE, ключи и индексы
- база данных принимает и отдает данные не в пустоту, а в API и ппосредством API. API, как правило, использует структурированный формат XML или JSON. Поэтому, аналитику необходимо напротив каждого столбца указывать xpath (для XML) или jsonpath (для JSON), по которому данные приходят или уходят.
- Таблицы базы данных связаны друг с другом отношениями “один-к-одному”, “один-ко-многим”, “многие-ко-многим”. Важно понимать, что для разработчика знать данные отношения крайне важно, так как понятие “многие” означает наличие массива.
- Маршрутизация. Тут традиционно есть два варианта. Оркестрация и хореография. Хореография, это когда каждый микросервис самостоятельно направляет сообщение по правильному маршруту, тем самым осуществляя вызов следующего микросервиса. Хореография, это способ организации платформы таким образом, что по окончанию процесса каждый микросервис возвращает сообдщение в маршрутизатор, который сам в свою очередь может являться микросервисом, и в котором происходит вызов следующего микросервиса.
Я не хочу сказать, что бизнес-анализ больше не нужен. Он нужен, но происходит четкое разделение на бизнес-аналитиков и аналитиков системных. Интересно то, что бизнес-аналитики все чаще остаются на стороне заказчика, а в продуктовых командах остаются аналитики системные.
Микросервисы, это всерьез и на долго. Но не навсегда.
Когда меня просят провести аналогии, чтобы проиллюстрировать процессы, идущие в ИТ-системе в “энтерпрайсе”, мне нравится цитировать работу Metropolis, в которой сотрудники Microsoft сравнивают эту самую ИТ-систему с городом времен начала промышленной революции. Не буду пересказывать эту статью, её можно найти в открытом доступе. Однако, если уж мы сравниваем ИТ-систему с городом, то любой город рано или поздно стремился к централизации, укрупнению и наведению порядка. Как пример, можно привести процесс постепенного исчезновения вещевых рынков в российских городах и постепенным их вытеснением крупными торговыми центрами. Если вспомнить старика Ленина, который говорил что Новая Экономическая Политика,это всерьез и надолго, но не навсегда, то невольно напрашивается аналогия, о том, что новый микросервисный архитектурный стиль рано или поздно также должен показать свои недостатки. Вот теперь стало понятно, что нагромождение микросервисов плохо масштабируется и очевидно, микросервисы это не всегда хорошо. Так когда же нам стоит их использовать?
- Прежде всего следует отделить те части которые обязательно потребуют изменений, причем часто бывает так, что не ясно какими эти изменения будут, от тех частей, что точно не изменятся. И те что будут меняться - выносим в микросервисе. те что меняться не будут - оставляем в монолите.
- Затем следует отделить те части, которые потребуют применения нового стека технологий. К примеру, допустим традиционным стеком была экосистема JAVA, а потом возникла идея что-то переделать на языке goleng. Однозначно - в микросервис.
- Если вдруг появился функционал, по которому часто приходят высокие инциденты и работоспособность которого критична для бизнеса, его также следует вынести в микросервис для более подробного изучения, изоляции и тестирования.
- Однозначно нужно вынести в микросервисы разного рода API, авторизацию, обработчики ошибок и функционал сбора метрик.
Если уж мы заговорили о "Цитадели", то давайте вспомним те самые пресловутые автотесты. Часто ведь аналитиков подключают к разработке стратегии тестирования? И на моей памяти редко удавалось уложить в автотесты более четверти (25%) от всех процессов. Так вот, со временем обозначилась четкая корреляция между монолитной части цитадели и процессами, успешно подвергшимися автотестированию. Собственно, однозначного ответа на то, что в первую очередь покрыть автотестами ни у кого нет, но интуиция подсказывает - покрывайте то, что наиболее устоялось. В цитадели это монолитная часть. Хотя, наверное, тоже самое можно сказать про любой оркестратор.
Неожиданно возникшие трудности - Highload и проблемы с масштабированием.
Всегда ли микросервисная система будет хорошо масштабироваться? Вот в последнее время часто говорят о так называемом “хайлоаде”. “Хайлоад” это система, которая с определенного момента начинает масштабироваться плохо и традиционный подход с введением в эксплуатацию более производительного “железа” работать перестает. Мне нравится пример из физики ядерных реакторов и расследования причин аварии на чернобыльском реакторе РБМК-1000. Академики Долежаль и Александров фактически увеличили в размерах хорошо зарекомендовавшие себя реакторы, апробированные на подводных лодках и ледоколах. Они при проектировании промышленного реактора увеличили размер активной зоны в расчете получить нужную мощность. Как итог, активная зона стала настолько огромна, что каждая её часть начала жить своей собственной жизнью и в определенных режимах плохо поддавался контролю.
В поисках аналогии к вышеописанной ситуации давайте посмотрим, как у нас обычно решаются проблемы с нагрузкой. Если производительность резко возрастает, то есть универсальное средство - докупить железа. То есть совершается, как говорят в академической среде, горизонтальное масштабирование. И рано или поздно настает момент, когда оно больше не работает. Какие бы вы сервера производительные не ставили, и в каком бы количестве,это не важно. Система все равно не справляется с нагрузкой. Ситуацию возможно изменить вертикальным масштабированием (когда приходится пересматривать внутренние связи, координацию звеньев системы и прочее), хотя, впрочем, и оно не всегда помогает. Состояние высоконагруженной системы, при котором она слабо масштабируется называется “хайлоадом”.
Причин в отсутствии способности к масштабированию может быть сколько угодно. Но вот за последнее время все чаще такой причиной является “семантическое безумие”, котором я говорил в ряде своих предыдущих работ. В кратце поясню, что “семантическим безумием” в ИТ-системе называется ситуация, когда одно и туже сущность начинают называть по-разному, и наоборот - разные бизнес-сущности начинают называть одинаково. В итоге, происходит вырождение и расхождение моделей данных и размываются границы микросервисов. Это приводит к дублированию функционала, увеличению количества адаптеров и как следствие плохой способности к масштабированию. А что есть адаптеры в крупной системе? Адаптеры это время на преобразование и рассинхронизация по тому же времени с другой. В итоге, при наборе "критической массы" адаптеров система плохо поддается масштабированию и старый добрый способ "добавить железа" работать перестает.
Чтобы стало понятно, давайте рассмотрим старую хорошо известную модель "потребитель-поставщик". В больших системах необходимо четко решить задачу тайминга. Потребитель должен запросить работу поставщика ровно в тот момент, когда он готов это сделать. В нашем случае это означает, что на стороне поставщика должны быть выполнены все подготовительные к запросу потребителя операции. То есть, все транзакции в базах данных выполнены, все бизнес-операции проделаны и все данные преобразованы в нужный формат. С большим количеством адаптеров, микросервисов и моделей данных данная задача в условиях хореографии становится сложно выполнимой и системе нужен оркестратор. Еще один аргумент в пользу "Цитадели" и маршрутизации сообщений в ней.
DDD и онтология как наиболее удобные подходы для проектирования микросервисных систем.
И так, что бывает, когда множество людей начинают творить? Самый главный эффект в том, что “разъезжаются” модели данных и возникает то самое “семантическое безумие”, о котором я говорил раньше. И проблема даже не в самом “семантическом безумии”, когда одну и туже сущность называют по-разному (я неоднократно приводил примеры со словосочетанием “номер счета”), сколько во времени, которое тратится на согласование модели данных. Как этого избежать? За время своего опыта аналитики я не нашел лучшего подхода, чем онтология, которая переходит в Domain Driven Design(DDD). Когда-то давно была еще методология EDF0. Все они, так или иначе крутятся вокруг установления субъектов и объектов предметной области и связей между ними. Жил в Ростове-на-Дону Б.Я. Шведин. Всем аналитикам советую ознакомиться с его монографией "Онтология предприятия". Так вот, если выделить такие субъекты и объекты и на их основе строить модель данных и определять границы микросервисов, то порядка в системе станет в разы больше. Почему? Ну данный подход строится на основании семантики, то есть бизнес-сути. И данная методика обычно противопоставляется подходам на основе декомпозиции бизнес-процессов.
Основной тезис подхода таков. Определяем пространство глобальных бизнес-объектов. Для него строим проекцию в пространстве объектов в модели данных. На основе проекции в модели данных строим классы в бековых системах (я тут имею ввиду data transfer object ), топологию сообщений xml или json, и в таблицах баз данных.
Обычно, в монолите, применялся подход аналитики бизнес-процессов, используя подходы описанные А.В. Шеером. Проводили анализ бизнес-процесса и модель данных строили исходя из бизнес-процесса. Таким образом, каждое новое требование регулятора, каждое новое требование рынка приводило к созданию новой модели данных. Аналогичная ситуация и с созданием микросервиса. Декомпозиция бизнес-процессов на моей памяти неоднократно приводила к дублированию функционала и возникновению семантически идентичных микросервисов. Поэтому, с данным подходом (через бизнес-процессы) надо быть осторожным. Тем более, что если мы им пользуемся, то нужно с самого начала закладывать четкие принципы хореографии микросервисов, чтобы не возникало путаницы.
Я же, исходя из своего опыта, предлагаю следующий подход. Давайте построим онтологию, выделив основные субъекты, объекты и связи между ними. Дальше каждому выделенному объекту или субъекту сопоставив домен, определив все возможные состояния объекта. Стало быть домен - суперпозиция всех состояний домена в концепции DDD. А дальше каждому такому состоянию ставим в соответвствие микросервис. Все микросервисы домена связаны между собой локальным оркестратором. Глобальный оркестратов также имеется на платформе в едиственном экземпляре.
При объектно-ориентированном подходе хореография и вовсе не нужна. Нужна будет оркестрация. Кстати, если использовать шаблон проектирования "цитадель", о котором я писал выше, то роль оркестратора может играть та самая монолитная часть.
Давайте разберем эти два подхода подробнее. Принцип "атомарности" и "слабой связности" в микросервисах приводит к тому, что если идти по пути аналитики бизнес-процессов, каждая элементарная операция рождает свой микросервис. Теперь же, давайте представим что мы вместо декомпозиции бизнес-процессов пошли по пути выделения субъектов, объектов и связей между ними. Мало того, что мы их выделили, мы еще и определили их атрибуты и состояния. Кстати,понятие "класс" для микросервисов в данном случае очень даже применимо. Таким образом, мы разметили предметное поле и на основе этой разметки строим микросервисы по следующему принципу - каждый микросервис это состояние субъекта или объекта. Причем эти состояния объединены в кластер согласно семантике и общаются друг с другом через оркестратор.
И какие новые задачи встают перед аналитиком? Года два назад на одном из митапов мне сказали что корпоративные словари и классификаторы это порочная практика. Сейчас спустя два года стало понятно, что без них бороться с "семантическим безумием" стало проблематично. Ведение таких словарей хоть в каком-то виде - задача аналитика.
Важнейшим объектом для нас остаётся модель данных.
Давайте проведем мысленный эксперимент. Допустим у нас есть клиника для душевно больных. У нас есть пациент А, который обладает важными для пациента Б сведениями. Проблема заключается в том, что у пациентов А и Б разный бред и разные галлюцинации, вследствие этого, наладить контакт у них не получается. И вот тут появляется врач-психиатр, который для всех пациентов устанавливает единые правила общения. Вот аналитик на проектах и должен стать таким врачом-психиатром.
Еще три года назад аналитики только и занимались тем, что делали маппинги. Маппинги выглядят как электронные таблицы, в ячейки которых аккуратно заносили название атрибута и xpath для одной и другой системы. Вот в эпоху монолита только и занимались аналитики, что делали маппинги для построения адаптеров, фасадов и прочих "перекладчиков".
С появлением микросервисного подхода проблемы с моделями данных ушли на второй план. Когда все сервисы ИТ-системы взаимодействовали через корпоративную шину существовала "каноническая модель данных". Помните про фракийский язык? "Лингва франка"? Язык торговцев средиземного моря. Сейчас в крупных ИТ- системах также встаёт надобность говорить на понятном друг другу языке. Как это организовать?
Давайте вспомним модель трехзвенной архитектуры. У нас есть "фронт", есть "бек" и есть хранилище. Важно обеспечить во всех трех звеньях семантическое соответствие данных. Часто ведь бывает так, что с бизнесом согласуют доработку через демонстрацию так называемых "интерфейсов намерения" каким часто выставляют UI, то есть пользовательский интерфейс. Данная, по моему мнению, порочная практика приводит к тому, изменения в интерфейсе приводят к недопустимым изменениям в боковой части. И мое мнение, что согласовывать надо всегда состав и структуру предоставляемых во фронт данных.
Как обеспечить это согласование? Самым надежным способом является использование старого доброго API Gateway. И вот в этой единой точке входа мы складываем схемы (xsd или json). И вот по этим схемам должна осуществляться валидация данных. А внутри никаких адаптеров быть не должно. Все изменения касаются в первую очередь структуры и состава схем. И так,получается, что модель данных мы храним в схемах. И поддерживать ее актуальность также должны аналитики. Конечно, обращения в корпоративные хранилища через очередь не позволят везде использовать API Gateway, все равно расхождения будут. Но единая корпоративная модель данных, в которой если не весь набор атрибутов, то хотя бы топология данных идентична - это очень хорошая идея. Да и вообще, новая роль - архитектор модели данных. Мне кажется, в скором времени эта специальность будет очень востребована. В чем ее вести? Open Api, Swager, Git? Вопрос пока открытый.
Вместо выводов
Может кому-то не понравятся мои слова, но аналитика в ИТ - это чистая техносфера. Для того, чтобы стать успешным аналитиком, нужно научиться мыслить как инженер. Хорошо бы, конечно, иметь, пусть даже не профильное, но все-таки инженерное академическое образование. Мне часто наработанная на производстве интуиция давала правильные аналогии с “теорией машин и механизмов”, “теоретической механикой” и прочими сугубо техническими дисциплинами. Любой модуль в энтерпрайсе рукотворен, а значит он как-то и через что-то взаимодействует с другими модулями и о любом процессе можно узнать, запросив соответствующую метрику для контроля ситуации. Никакой метафизики и эзотерики тут нет. Все довольно приземленно и материально. И имея определенный бекграунд, вооружившись старым опытом и хорошими книгами, во всем всегда можно разобраться, читая документацию, которая всегда, как правило, находится в свободном доступе.
Часто же, попадая в ИТ тусовку обращаешь внимание, на лексику айтишников. Она полна различных диковинных терминов. “Бекграунд”, “Фича”, “Пофиксить”... Эти новые слова дают ощущение недосягаемости знаний по ИТ. Потом, погрузившись и во всем разобравшись, ты удивляешься - насколько все просто, и тому сколько раз ты подобное видел в других инженерных областях. А зачем тогда такая новая лексика? Данный феномен характерен для закрытых сообществ, претендующих на некую элитарность. Ну у меня лично напрашивается аналогия с криминальной средой начала 20 века, может потому что я из Ростова-на-Дону. Урки часто определяли своих по манере понимать блатную “феню”. Не говоришь на ней и не понимаешь, ну тогда тебе не место в криминальной среде. Так что часто, обучение в ИТ заключается только лишь в сопоставлении старым знаниям новых терминов.
Разномазов Валерий,© 2022
Аналитика микросервисов. Практический опыт аналитика в enterprise
Вместо введения Для кого я решил написать? Данная статья, написана для моих коллег аналитиков или для тех, кто желал бы им стать. Если вы теперь захотели стать аналитиком, то подумайте...
habr.com