Что, если бизнес компании заключается в приеме и обработке платежей во множестве стран в режиме 365/24/7? В этом случае одной из ключевых целей ее сотрудников является доступность сервисов 99,999%. А к CI/CD в таких условиях предъявляются особые требования.
Заместитель директора департамента эксплуатации и разработки сервисных систем ECOMMPAY IT Федор Васильев на конференции HighLoad++ Весна 2021 рассказал об эволюции подходов его компании к деплою нового кода. А мы сделали на основе его доклада полезную статью, которую вы найдете под катом.

Мы работаем с финансовыми транзакциями, и мы параноики, потому что любой даунтайм для нас — это прямые финансовые потери.
Сервисы у нас деплоятся последовательно, и это принципиальная позиция. Конечно, технически можно деплоить хоть все сразу. Но если деплой идет параллельно, энтропия, которая вносится в продакшен, очень большая. И потом очень сложно разобраться, что пошло не так. Тяжело смотреть логи, потому что их много. Кроме того, компоненты связаны друг с другом очень тесно и хитрым образом. Деплоить все сразу в финтехе, по нашему опыту, опасно.
Деплой каждого сервиса тщательно проверяется в режиме реального времени.
Раньше, до конца 2019 года, процесс выглядел так: куча людей (деплой-инженеры, системные администраторы, инженеры мониторинга) в течение многих часов напряженно деплоят и проверяют сервисы по заранее составленному расписанию. И как-то, под новогодний фриз, мы поняли, что надо что-то менять (деплой в тот день длился 12 часов!).
О том, что мы поменяли и как углубили автоматизацию я расскажу ниже.
Кроме того, у нас используется и канареечный релиз, и обычно это происходит одновременно с Blue\Green.
Выглядит это так: трафик на офлайн-линию с новым кодом мы запускаем маленькими порциями — 2%, 5%, 20%, потом доходит до 100%. Это делается для того, чтобы финансовые потери, в случае чего, были меньше. Обычно мы начинаем с 2%, и, если что-то случится, потеряем только их.
Подробный письменный регламент проверки каждого сервиса при деплое должен быть обязательно. По этому регламенту опытный инженер отдела мониторинга проверяет сервис по пунктам. В качестве инструментов мониторинга и проверки мы используем Kibana, Grafana, Zabbix. Но есть вещи, которые нужно проверять руками: заходить в интерфейсы, учитывать функциональность. Помимо пунктов из регламента, разумеется, рассматриваются аномалии в графиках/мониторах/дашбордах.
В регламенте проверки сервиса всегда есть бизнес-проверки и бизнес-метрики. Бизнес-проверка — это проверка основного функционала (она осуществляется на каждом шаге деплоя). При малейших подозрениях на проблемы происходит максимально быстрый откат. В случае с blue/green — это секунды. Трафик скачком переводится обратно на стабильную линию.

А были у нас три замечательных богатыря:

Если посмотреть на картину внимательно, то на заднем фоне виден пароход. В век, когда уже есть паровая тяга, бурлаки тащат против течения корабль. Это не кажется вам странным? Илья Репин специально нарисовал пароход, чтобы подчеркнуть, что несмотря на наличие паровой тяги, бурлаки еще при деле.
Бурлаки деплоя для меня — это две категории людей. Первые — деплой-инженеры, которые переливают трафик, и нажимают кнопки в Jenkins/AWX, чтобы деплой начался. Вторые — инженеры мониторинга, которые по сигналу деплой-инженера проверяют такой-то сервис на новой линии в таком-то ДЦ.
Когда мы начали создавать систему, о которой я буду говорить ниже, мы хотели автоматизировать прежде всего работу деплой-инженера и инженера мониторинга.

Наверное, все знают эти инструменты. Как я уже упоминал, три из них у нас уже использовались. Мы решили, что хватит.
Принципиально у нас выходило следующее:
Но что же должно быть в центре? Что будет оркестровать?
До разработки новой системы в центре был человек. Я полагаю, если бы на моем месте был бы инженер, который по призванию админ, то оркестратором бы стал Jenkins. Но я-то программист, поэтому у меня получился велосипед")

Когда очертания и функциональность будущей системы в целом понятны, я считаю, что очень важно правильно выбрать ее название. Поэтому задумался, как мне назвать этот велосипед?
И мне пришел в голову образ Lurker-а:

Это Близзардовское творение — зерговский юнит из игры StarCraft, в переводе соглядатай, тайный наблюдатель. В игре он закапывается под землю и атакует оттуда своими страшными щупальцами.
Смысл будущей системы был именно в том, что она, с одной стороны, будет невидимой. А с другой сможет вовремя дергать своими щупальцами: Jenkins, AWX и Fabric. Поэтому образ Lurker-а мне показался удачным.
Кроме того, если речь идет об интерфейсном проекте, у которого есть фронт, бот заходит, кликает по кнопкам по определенному алгоритму и проверяет, все ли там нормально: отображаются ли новые транзакции, обновляется ли таблица, можно ли выгрузить файл. Для этого у нас есть тесты на Codeception и Selenium WebDriver — это интерфейсные бизнес проверки.
Это та часть, которую пишут профессиональные QA-шники. Они занимаются автотестами, и для Lurker они пишут специальные тесты, которые мы называем Lurker-Smoke-тестами. Это не регресс и не обычный QA-шный Smoke на стейдже, а именно специально написанные тесты, проверяющие только самый критичный бизнес функционал. К ним предъявляются определенные требования, основное из которых — скорость исполнения.
Lurker выглядит так:

Это точка входа в расписание. Она общедоступна — любой работник компании может зайти и посмотреть актуальное расписание деплоев компонентов.
Очень важный момент: QA сами подают заявку на продовый деплой. У них есть специальные права для своих компонентов, и они лично указывают теги, артефакты, выбирают время из свободных слотов.
Расписание ведется прямо в Lurker. Деплои запускаются автоматически и последовательно.
Несколько примеров интерфейсов:

*Фотки со стейджа, но на проде то же самое.
Здесь ничего особенного: мониторинги, HeartBeat сервисов (трафик. ошибки).
Так выглядит лог джобы, когда она запускается:
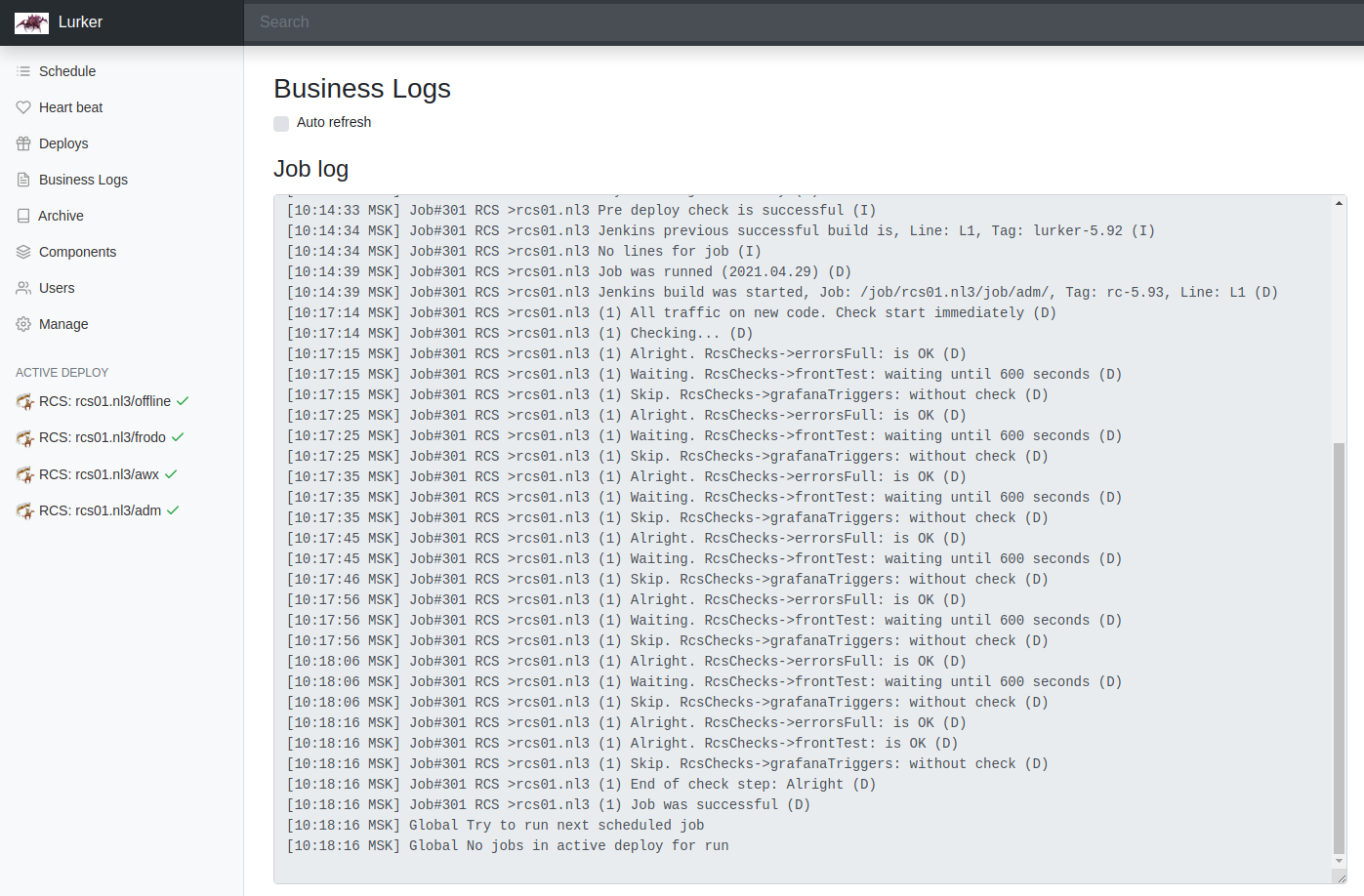
Здесь подробно логируются проверки, этапы переливание трафика, и т.д.
Пример управляющего интерфейса. Если вдруг бездушная машина что-то не так делает, можно это поправить прямо на лету:


Все надо тестировать силами QA!
Видео доклада можно посмотреть здесь.

 habr.com
habr.com
Заместитель директора департамента эксплуатации и разработки сервисных систем ECOMMPAY IT Федор Васильев на конференции HighLoad++ Весна 2021 рассказал об эволюции подходов его компании к деплою нового кода. А мы сделали на основе его доклада полезную статью, которую вы найдете под катом.
Мы работаем с финансовыми транзакциями, и мы параноики, потому что любой даунтайм для нас — это прямые финансовые потери.
Сервисы у нас деплоятся последовательно, и это принципиальная позиция. Конечно, технически можно деплоить хоть все сразу. Но если деплой идет параллельно, энтропия, которая вносится в продакшен, очень большая. И потом очень сложно разобраться, что пошло не так. Тяжело смотреть логи, потому что их много. Кроме того, компоненты связаны друг с другом очень тесно и хитрым образом. Деплоить все сразу в финтехе, по нашему опыту, опасно.
Деплой каждого сервиса тщательно проверяется в режиме реального времени.
Раньше, до конца 2019 года, процесс выглядел так: куча людей (деплой-инженеры, системные администраторы, инженеры мониторинга) в течение многих часов напряженно деплоят и проверяют сервисы по заранее составленному расписанию. И как-то, под новогодний фриз, мы поняли, что надо что-то менять (деплой в тот день длился 12 часов!).
О том, что мы поменяли и как углубили автоматизацию я расскажу ниже.
Какой CI/CD нам нужен?
Обычно всем нужен быстрый, надежный и дешевый CI/CD. Для нас, конечно, это тоже все актуально. Но гораздо важнее:- чтобы все работало (понятно — кому нужен деплой, который не работает);
- не было финансовых потерь во время и после деплоя;
- если потери все-таки есть, они должны быть минимальными и происходить в короткий промежуток времени.
Blue\Green Deployment
Естественно, для нас это α, ω, θ, γ и т.д. — в общем, весь греческий алфавит. Blue\Green Deployment у нас используется практически на всех сервисах.Кроме того, у нас используется и канареечный релиз, и обычно это происходит одновременно с Blue\Green.
Выглядит это так: трафик на офлайн-линию с новым кодом мы запускаем маленькими порциями — 2%, 5%, 20%, потом доходит до 100%. Это делается для того, чтобы финансовые потери, в случае чего, были меньше. Обычно мы начинаем с 2%, и, если что-то случится, потеряем только их.
Как проверять?
Это индивидуальная история. Сервисы очень разные, и их много (от 20 до 100, смотря как считать).Подробный письменный регламент проверки каждого сервиса при деплое должен быть обязательно. По этому регламенту опытный инженер отдела мониторинга проверяет сервис по пунктам. В качестве инструментов мониторинга и проверки мы используем Kibana, Grafana, Zabbix. Но есть вещи, которые нужно проверять руками: заходить в интерфейсы, учитывать функциональность. Помимо пунктов из регламента, разумеется, рассматриваются аномалии в графиках/мониторах/дашбордах.
В регламенте проверки сервиса всегда есть бизнес-проверки и бизнес-метрики. Бизнес-проверка — это проверка основного функционала (она осуществляется на каждом шаге деплоя). При малейших подозрениях на проблемы происходит максимально быстрый откат. В случае с blue/green — это секунды. Трафик скачком переводится обратно на стабильную линию.
Инструменты деплоя
Что же у нас было в тот момент когда мы поняли, что необходима более глубокая автоматизация?
А были у нас три замечательных богатыря:
- AWX (Ansible) -> 49 jobs templates;
- Jenkins (Groovy) -> 41 jobs;
- Fabric (Python) -> 5 scripts.
Что еще автоматизировать?
Если посмотреть на картину внимательно, то на заднем фоне виден пароход. В век, когда уже есть паровая тяга, бурлаки тащат против течения корабль. Это не кажется вам странным? Илья Репин специально нарисовал пароход, чтобы подчеркнуть, что несмотря на наличие паровой тяги, бурлаки еще при деле.
Бурлаки деплоя для меня — это две категории людей. Первые — деплой-инженеры, которые переливают трафик, и нажимают кнопки в Jenkins/AWX, чтобы деплой начался. Вторые — инженеры мониторинга, которые по сигналу деплой-инженера проверяют такой-то сервис на новой линии в таком-то ДЦ.
Когда мы начали создавать систему, о которой я буду говорить ниже, мы хотели автоматизировать прежде всего работу деплой-инженера и инженера мониторинга.
Как автоматизировать?
Наверное, все знают эти инструменты. Как я уже упоминал, три из них у нас уже использовались. Мы решили, что хватит.
Принципиально у нас выходило следующее:
Но что же должно быть в центре? Что будет оркестровать?
До разработки новой системы в центре был человек. Я полагаю, если бы на моем месте был бы инженер, который по призванию админ, то оркестратором бы стал Jenkins. Но я-то программист, поэтому у меня получился велосипед
Когда очертания и функциональность будущей системы в целом понятны, я считаю, что очень важно правильно выбрать ее название. Поэтому задумался, как мне назвать этот велосипед?
И мне пришел в голову образ Lurker-а:
Это Близзардовское творение — зерговский юнит из игры StarCraft, в переводе соглядатай, тайный наблюдатель. В игре он закапывается под землю и атакует оттуда своими страшными щупальцами.
Смысл будущей системы был именно в том, что она, с одной стороны, будет невидимой. А с другой сможет вовремя дергать своими щупальцами: Jenkins, AWX и Fabric. Поэтому образ Lurker-а мне показался удачным.
Что у нас получилось:
- Отдельная система (оркестратор).
- PHP 7.4, MySQL 5.7, Bootstrap.
- Jenkins API — для деплоев (включает fabric).
- AWX API — для манипуляций с трафиком.
- Мониторит состояние сервисов по логам в ELK (Elasticsearch API).
- Grafana API (считывает триггеры).
- Zabbix API (считывает триггеры).
- Запускает бизнесовые проверки сервисов (кастомные, PHP).
- Запускает Lurker-Smoke-тесты (Codeception, Selenium WebDriver).
- Web-интерфейс, Telegram-bot.
Кроме того, если речь идет об интерфейсном проекте, у которого есть фронт, бот заходит, кликает по кнопкам по определенному алгоритму и проверяет, все ли там нормально: отображаются ли новые транзакции, обновляется ли таблица, можно ли выгрузить файл. Для этого у нас есть тесты на Codeception и Selenium WebDriver — это интерфейсные бизнес проверки.
Это та часть, которую пишут профессиональные QA-шники. Они занимаются автотестами, и для Lurker они пишут специальные тесты, которые мы называем Lurker-Smoke-тестами. Это не регресс и не обычный QA-шный Smoke на стейдже, а именно специально написанные тесты, проверяющие только самый критичный бизнес функционал. К ним предъявляются определенные требования, основное из которых — скорость исполнения.
Lurker выглядит так:
Это точка входа в расписание. Она общедоступна — любой работник компании может зайти и посмотреть актуальное расписание деплоев компонентов.
Очень важный момент: QA сами подают заявку на продовый деплой. У них есть специальные права для своих компонентов, и они лично указывают теги, артефакты, выбирают время из свободных слотов.
Расписание ведется прямо в Lurker. Деплои запускаются автоматически и последовательно.
Несколько примеров интерфейсов:
*Фотки со стейджа, но на проде то же самое.
Здесь ничего особенного: мониторинги, HeartBeat сервисов (трафик. ошибки).
Так выглядит лог джобы, когда она запускается:
Здесь подробно логируются проверки, этапы переливание трафика, и т.д.
Пример управляющего интерфейса. Если вдруг бездушная машина что-то не так делает, можно это поправить прямо на лету:
Что еще важно? Или некоторые выводы
- Пропагандируйте и поддерживайте «Zero Tolerance» к ошибкам уровней ERROR+ (перманентный процесс) — очень помогает мониторить деплои.
- Постоянно тестируйте совместимость разных версий сервисов друг с другом силами QA.
- Не используйте линии для DBMS. База для обеих линий компонента в blue/green должна быть единой, а 2-3 последних версии апликейшена должны уметь работать с новой структурой базы, так как она никогда не откатывается.
- Не бойтесь велосипедов. Иногда они неплохо работают
Все надо тестировать силами QA!
Видео доклада можно посмотреть здесь.
Бурлаки деплоя. Или автоматизация проверок финтех-систем
Что, если бизнес компании заключается в приеме и обработке платежей во множестве стран в режиме 365/24/7? В этом случае одной из ключевых целей ее сотрудников является доступность сервисов 99,999%. А...
habr.com