
Меня зовут Руслан, я релиз-инженер в Badoo и Bumble. Недавно я столкнулся с необходимостью оптимизировать механизм автомерджа в мобильных проектах. Задача оказалась интересной, поэтому я решил поделиться её решением с вами. В статье я расскажу, как у нас раньше было реализовано автоматическое слияние веток Git и как потом мы увеличили пропускную способность автомерджа и сохранили надёжность процессов на прежнем высоком уровне.«Отыщи всему начало, и ты многое поймёшь» (Козьма Прутков).
Свой автомердж
Многие программисты ежедневно запускают git merge, разрешают конфликты и проверяют свои действия тестами. Кто-то автоматизирует сборки, чтобы они запускались автоматически на отдельном сервере. Но решать, какие ветки сливать, всё равно приходится человеку. Кто-то идёт дальше и добавляет автоматическое слияние изменений, получая систему непрерывной интеграции (Continuous Integration, или CI).Например, GitHub предлагает полуручной режим, при котором пользователь с правом делать записи в репозиторий может поставить флажок «Allow auto-merge» («Разрешить автомердж»). При соблюдении условий, заданных в настройках, ветка будет соединена с целевой веткой. Bitbucket поддерживает большую степень автоматизации, накладывая при этом существенные ограничения на модель ветвления, имена веток и на количество мерджей.
Такой автоматизации может быть достаточно для небольших проектов. Но с увеличением количества разработчиков и веток, ограничения, накладываемые сервисами, могут существенно повлиять на производительность CI. Например, раньше у нас была система мерджа, при которой основная ветка всегда находилась в стабильном состоянии благодаря последовательной стратегии слияний. Обязательным условием слияния была успешная сборка при наличии всех коммитов основной ветки в ветке разработчика. Работает эта стратегия надёжно, но у неё есть предел, определяемый временем сборки. И этого предела оказалось недостаточно. При времени сборки в 30 минут на обработку 100 слияний в день потребовалось бы более двух суток. Чтобы исключить ограничения подобного рода и получить максимальную свободу выбора стратегий мерджа и моделей ветвления, мы создали собственный автомердж.
Итак, у нас есть свой автомердж, который мы адаптируем под нужды каждой команды. Давайте рассмотрим реализацию одной из наиболее интересных схем, которую используют наши команды Android и iOS.
Термины
Main. Так я буду ссылаться на основную ветку репозитория Git. И коротко, и безопасно. =)Сборка. Под этим будем иметь в виду сборку в TeamCity, ассоциированную с веткой Git и тикетом в трекере Jira. В ней выполняются как минимум статический анализ, компиляция и тестирование. Удачная сборка на последней ревизии ветки в сочетании со статусом тикета «To Merge» — это однo из необходимых условий автомерджа.
Пример модели ветвления
Испробовав разные модели ветвления в мобильных проектах, мы пришли к следующему упрощённому варианту: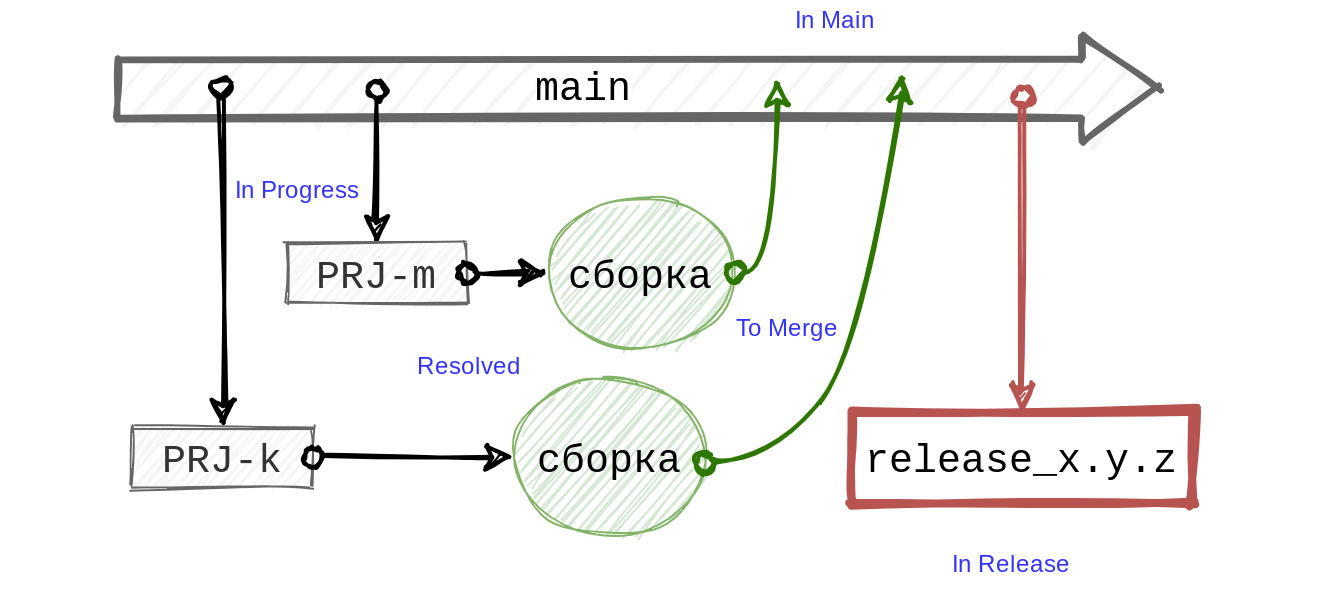
На основе ветки main разработчик создаёт ветку с названием, включающим идентификатор тикета в трекере, например PRJ-k. По завершении работы над тикетом разработчик переводит его в статус «Resolved». При помощи хуков, встроенных в трекер, мы запускаем для ветки тикета сборку. В определённый момент, когда изменения прошли ревью и необходимые проверки автотестами на разных уровнях, тикет получает статус «To Merge», его забирает автоматика и отправляет в main.
Раз в неделю на основе main мы создаём ветку релиза release_x.y.z, запускаем на ней финальные сборки, при необходимости исправляем ошибки и наконец выкладываем результат сборки релиза в App Store или Google Play. Все фазы веток отражаются в статусах и дополнительных полях тикетов Jira. В общении с Jira помогает наш клиент REST API.
Такая простая модель не только позволила нам построить надёжный автомердж, но и оказалась удобной для всех участников процесса. Однако сама реализация автомерджа менялась несколько раз, прежде чем мы добились высокой производительности и минимизировали количество побочных эффектов: конфликтов, переоткрытий тикетов и ненужных пересборок.
Первая версия: жадная стратегия
Сначала мы шли от простого и очевидного. Брали все тикеты, находящиеся в статусе «To Merge», выбирали из них те, для которых есть успешные сборки, и отправляли их в main командой git merge, по одной.Примечание: я немного упростил описание первой версии. В реальности между main и ветками разработчиков была ветка dev, где и происходили все проблемы, описанные выше. Перед слиянием main с dev мы добивались стабилизации сборок при помощи специальных веток «интеграции», создававшихся автоматически на основе dev с периодом в сутки.
Наличие в TeamCity актуальной успешной сборки мы проверяли при помощи метода REST API getAllBuilds примерно следующим образом (псевдокод):
haveFailed = False # Есть ли неудачные сборки
haveActive = False # Есть ли активные сборки
# Получаем сборки типа buildType для коммита commit ветки branch
builds = teamCity.getAllBuilds(buildType, branch, commit)
# Проверяем каждую сборку
for build in builds:
# Проверяем каждую ревизию в сборке
for revision in build.revisions:
if revision.branch is branch and revision.commit is commit:
# Сборка актуальна
if build.isSuccessful:
# Сборка актуальна и успешна
return True
else if build.isRunning or build.isQueued
haveActive = True
else if build.isFailed:
haveFailed = True
if haveFailed:
# Исключаем тикет из очереди, переоткрывая его
ticket = Jira.getTicket(branch.ticketKey)
ticket.reopen("Build Failed")
return False
if not haveActiveBuilds:
# Нет ни активных, ни упавших, ни удачных сборок. Запускаем новую
TriggerBuild(buildType, branch)
Ревизии — это коммиты, на основе которых TeamCity выполняет сборку. Они отображаются в виде 16-ричных последовательностей на вкладке «Changes» («Изменения») страницы сборки в веб-интерфейсе TeamCity. Благодаря ревизиям мы можем легко определить, требуется ли пересборка ветки тикета или тикет готов к слиянию.
Важно, что ревизию можно (а часто даже необходимо) указывать в запросе на добавление новой сборки в очередь в параметре lastChanges, потому что в противном случае TeamCity может выбрать устаревшую ревизию ветки при запуске сборки. Как будет показано ниже, указывать ревизию необходимо в тех случаях, если, например, логика вне TeamCity основана на поиске сборок на конкретных коммитах (наш случай).
Так как после перевода тикета в статус готовности (в нашем примере «Resolved») соответствующая ветка, как правило, не меняется, то и сборка, ассоциированная с тикетом, чаще всего остаётся актуальной. Кроме того, сам факт нахождения тикета в статусе «To Merge» говорит о высокой вероятности того, что сборка не упала. Ведь при падении сборки мы сразу переоткрываем тикет.
На первый взгляд, дальнейшие действия кажутся очевидными: взять все готовые тикеты с актуальными сборками и соединять main с ними по одному. В первой версии автомерджа мы так и сделали.
Всё работало быстро, но требовало внимания. То и дело возникали ситуации, когда изменения нескольких тикетов конфликтовали между собой. Конфликты при слияниях как явление достаточно распространённое поначалу ни у кого особых вопросов не вызывали. Их разрешали разработчики, дежурные по релизу. Но с увеличением количества разработчиков, задач и, соответственно, веток, приведение релиза в порядок требовало всё больше усилий. Задержки в разрешении конфликтов начали сказываться на новых задачах. Полагаю, не стоит продолжать эту цепочку — скорее всего, вы уже поняли, что я имею в виду. С конфликтами нужно было что-то делать, причём не допуская их попадания в релиз.
Конфликты слияния
Если изменить одну и ту же строку кода в разных ветках и попытаться соединить их в main, то Git попросит разрешить конфликты слияния. Из двух вариантов нужно выбрать один и закоммитить изменения.Это должно быть знакомо практически каждому пользователю системы контроля версий (VCS). Процессу CI, так же, как и любому пользователю VCS, нужно разрешать конфликты. Правда, делать это приходится немного вслепую, в условиях почти полного непонимания кодовой базы.
Если команда git merge завершилась с ошибкой и для всех файлов в списке git ls-files --unmerged заданы обработчики конфликтов, то для каждого такого файла мы выполняем парсинг содержимого по маркерам конфликтов <<<<<<<, ======= и >>>>>>>. Если конфликты вызваны только изменением версии приложения, то, например, выбираем последнюю версию между локальной и удалённой частями конфликта.
Конфликт слияния — это один из простейших типов конфликтов в CI. При конфликте с main CI обязан уведомить разработчика о проблеме, а также исключить ветку из следующих циклов автомерджа до тех пор, пока в ней не появятся новые коммиты.
Решение следующее: нарушаем как минимум одно из необходимых условий слияния. Так как ветка ассоциирована с тикетом трекера, можно переоткрыть тикет, изменив его статус. Таким образом мы одновременно исключим тикет из автомерджа и оповестим об этом разработчика (ведь он подписан на изменения в тикете). На всякий случай мы отправляем ещё и сообщение в мессенджере.
Логические конфликты
А может ли случиться так, что, несмотря на успешность сборок пары веток в отдельности, после слияния их с main сборка на основной ветке упадёт? Практика показывает, что может. Например, если сумма a и b в каждой из двух веток не превышает 5, то это не гарантирует того, что совокупные изменения a и b в этих ветках не приведут к большей сумме.Попробуем воспроизвести это на примере Bash-скрипта test.sh:
#!/bin/bash
get_a() {
printf '%d\n' 1
}
get_b() {
printf '%d\n' 2
}
check_limit() {
local -i value="$1"
local -i limit="$2"
if (( value > limit )); then
printf >&2 '%d > %d%s\n' "$value" "$limit"
exit 1
fi
}
limit=5
a=$(get_a)
b=$(get_b)
sum=$(( a + b ))
check_limit "$a" "$limit"
check_limit "$b" "$limit"
check_limit "$sum" "$limit"
printf 'OK\n'
Закоммитим его и создадим пару веток: a и b.
Пусть в первой ветке функция get_a() вернёт 3, а во второй — get_b() вернёт 4:
diff --git a/test.sh b/test.sh
index f118d07..39d3b53 100644
--- a/test.sh
+++ b/test.sh
@@ -1,7 +1,7 @@
#!/bin/bash
get_a() {
- printf '%d\n' 1
+ printf '%d\n' 3
}
get_b() {
git diff main b
diff --git a/test.sh b/test.sh
index f118d07..0bd80bb 100644
--- a/test.sh
+++ b/test.sh
@@ -5,7 +5,7 @@ get_a() {
}
get_b() {
- printf '%d\n' 2
+ printf '%d\n' 4
}
check_limit() {
В обоих случаях сумма не превышает 5 — и наш тест проходит успешно:
git checkout a && bash test.sh
Switched to branch 'a'
OK
git checkout b && bash test.sh
Switched to branch 'b'
OK
Но после слияния main с ветками тесты перестают проходить, несмотря на отсутствие явных конфликтов:
git merge a b
Fast-forwarding to: a
Trying simple merge with b
Simple merge did not work, trying automatic merge.
Auto-merging test.sh
Merge made by the 'octopus' strategy.
test.sh | 4 ++--
1 file changed, 2 insertions(+), 2 deletions(-)
bash test.sh
7 > 5
«Было бы проще, если бы вместо get_a() и get_b() использовались присваивания: a=1; b=2», — заметит внимательный читатель и будет прав. Да, так было бы проще. Но, вероятно, именно поэтому встроенный алгоритм автомерджа Git успешно обнаружил бы конфликтную ситуацию (что не позволило бы продемонстрировать проблему логического конфликта):
git merge a
Updating 4d4f90e..8b55df0
Fast-forward
test.sh | 2 +-
1 file changed, 1 insertion(+), 1 deletion(-)
git merge b
Auto-merging test.sh
CONFLICT (content): Merge conflict in test.sh
Recorded preimage for 'test.sh'
Automatic merge failed; fix conflicts and then commit the result.
Разумеется, на практике конфликты бывают менее явными. Например, разные ветки могут полагаться на API разных версий какой-нибудь библиотеки зависимости, притом что более новая версия не поддерживает обратной совместимости. Без глубоких знаний кодовой базы (читай: без разработчиков проекта) обойтись вряд ли получится. Но ведь CI как раз и нужен для решения таких проблем.
Конечно, от разрешения конфликта мы никуда не уйдём — кто-то должен внести правки. Но чем раньше нам удастся обнаружить проблему, тем меньше людей будет привлечено к её решению. В идеале потребуется озадачить лишь разработчика одной из конфликтующих веток. Если таких веток две, то одна из них вполне может быть соединена с main.
Превентивные меры
Итак, главное — не допустить попадания логического конфликта в main. Иначе придётся долго и мучительно искать источник ошибок, а затем — программиста, который проблему должен или может решить. Причём делать это нужно максимально быстро и качественно, чтобы, во-первых, не допустить задержки релиза и во-вторых, избежать в новых ветках логических конфликтов, основанных на уже выявленном конфликте. Такие конфликты часто приводят к неработоспособности большой части приложения или вовсе блокируют его запуск.Нужно синхронизировать ветки так, чтобы их совокупный вклад в main не приводил к падению сборки релиза. Ясно, что все готовые к слиянию ветки нужно так или иначе объединить и прогнать тесты по результату объединения. Путей решения много, давайте посмотрим, каким был наш путь.
Вторая версия: последовательная стратегия
Стало ясно, что существующих условий готовности к автомерджу для тикета недостаточно. Требовалось какое-то средство синхронизации между ветками, какой-то порядок.Git, по идее, как раз и является средством синхронизации. Но порядок попадания веток в main и, наоборот, main в ветки определяем мы сами. Чтобы определить точно, какие из веток вызывают проблемы в main, можно попробовать отправлять их туда по одной. Тогда можно выстроить их в очередь, а порядок организовать на основе времени попадания тикета в статус «To Merge» в стиле «первый пришёл — первым обслужен».
С порядком определились. А как дальше соединять ветки? Допустим, мы сольём в main первый тикет из очереди. Так как main изменилась, она может конфликтовать с остальными тикетами в очереди. Поэтому перед тем как сливать следующий тикет, нужно удостовериться, что обновлённая main по-прежнему совместима с ним. Для этого достаточно слить main в тикет. Но так как после соединения main с веткой её состояние отличается от того, которое было в сборке, необходимо перезапустить сборку. Для сохранения порядка все остальные тикеты в очереди должны ждать завершения сборки и обработки впередистоящих тикетов. Примерно такие рассуждения привели нас к последовательной стратегии автомерджа.
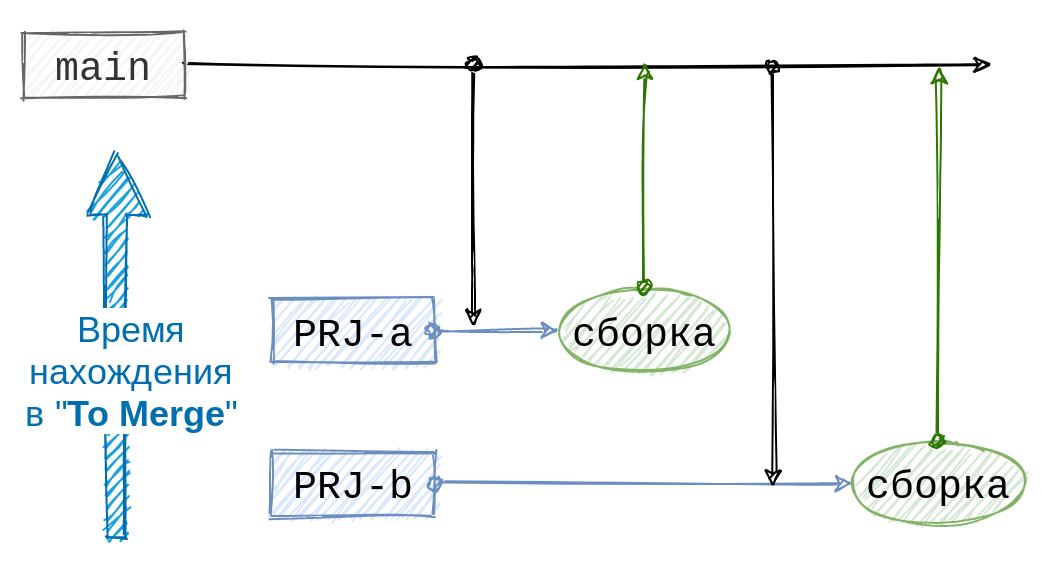
Работает схема надёжно и предсказуемо. Благодаря обязательной синхронизации с main и последующей пересборке конфликты между ветками удаётся выявлять сразу, до попадания их в main. Раньше же нам приходилось разрешать конфликт уже после слияния релиза со множеством веток, большая часть из которых к этому конфликту отношения не имела. Кроме того, предсказуемость алгоритма позволила нам показать очередь тикетов в веб-интерфейсе, чтобы можно было примерно оценить скорость попадания их веток в main.
Но есть у этой схемы существенный недостаток: пропускная способность автомерджа линейно зависит от времени сборки. При среднем времени сборки iOS-приложения в 25 минут мы можем рассчитывать на прохождение максимум 57 тикетов в сутки. В случае же с Android-приложением требуется примерно 45 минут, что ограничивает автомердж 32 тикетами в сутки, а это даже меньше количества Android-разработчиков в нашей компании.
На практике время ожидания тикета в статусе «To Merge» составляло в среднем 2 часа 40 минут со «всплесками», доходящими до 10 часов! Необходимость оптимизации стала очевидной. Нужно было увеличить скорость слияний, сохранив при этом стабильность последовательной стратегии.
Финальная версия: сочетание последовательной и жадной стратегий
Разработчик команды iOS Дамир Давлетов предложил вернуться к идее жадной стратегии, при этом сохранив преимущества последовательной.Давайте вспомним идею жадной стратегии: мы сливали все ветки готовых тикетов в main. Основной проблемой было отсутствие синхронизации между ветками. Решив её, мы получим быстрый и надёжный автомердж!
Раз нужно оценить общий вклад всех тикетов в статусе «To Merge» в main, то почему бы не слить все ветки в некоторую промежуточную ветку «Main Candidate» (MC) и не запустить сборку на ней? Если сборка окажется успешной, то можно смело сливать MC в main. В противном случае придётся исключать часть тикетов из MC и запускать сборку заново.
Как понять, какие тикеты исключить? Допустим, у нас n тикетов. На практике причиной падения сборки чаще всего является один тикет. Где он находится, мы не знаем — все позиции от 1 до n являются равноценными. Поэтому для поиска проблемного тикета мы делим n пополам.
Так как место тикета в очереди определяется временем его попадания в статус «To Merge», имеет смысл брать ту половину, в которой расположены тикеты с большим временем ожидания.
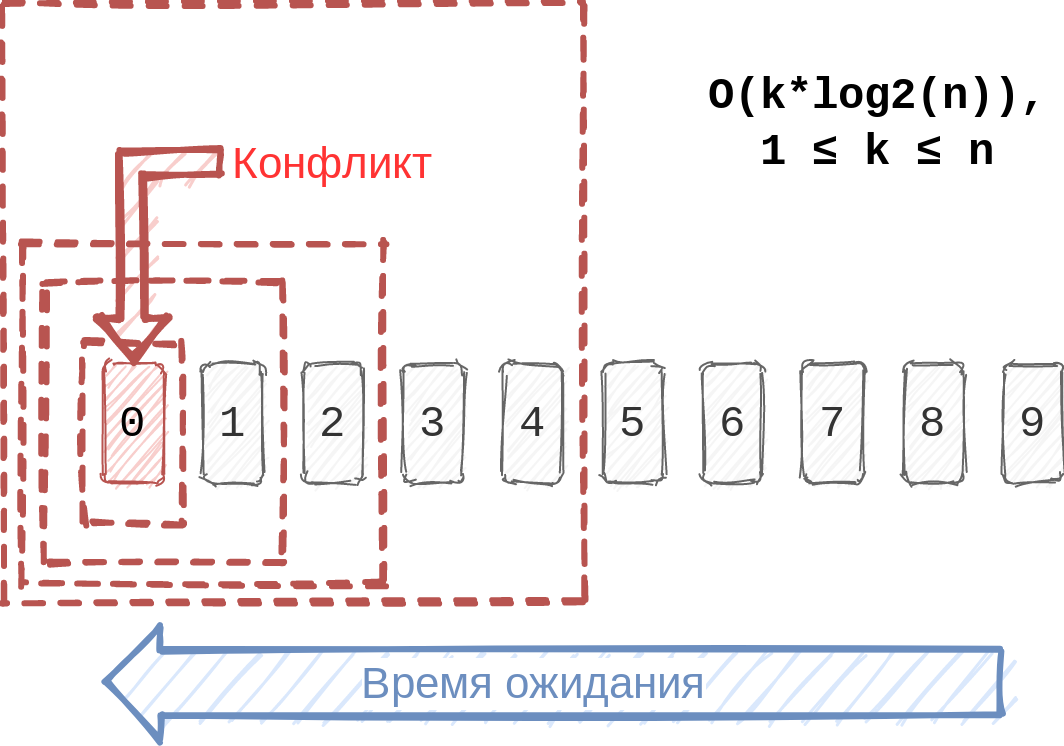
Следуя этому алгоритму, для k проблемных тикетов в худшем случае нам придётся выполнить O(k*log2
") ) сборок, прежде чем мы обработаем все проблемные тикеты и получим удачную сборку на оставшихся.
) сборок, прежде чем мы обработаем все проблемные тикеты и получим удачную сборку на оставшихся.Вероятность благоприятного исхода велика. А ещё в то время, пока сборки на ветке MC падают, мы можем продолжать работу при помощи последовательного алгоритма!
Итак, у нас есть две автономные модели автомерджа: последовательная (назовём её «Sequential Merge», или SM) и жадная (назовём её «Greedy Merge», или GM). Чтобы получить пользу от обеих, нужно дать им возможность работать параллельно. А параллельные процессы требуют синхронизации, которой можно добиться либо средствами межпроцессного взаимодействия, либо неблокирующей синхронизацией, либо сочетанием этих двух методов. Во всяком случае, мне другие методы неизвестны.
Сами процессы такого рода у нас реализованы в виде очереди команд-скриптов. Команды эти могут быть одноразовыми и периодически запускаемыми. Так как автомердж никогда не закончится, а с управлением повторными запусками лучше справится контроллер очереди, выберем второй тип.
Остаётся предотвратить все возможные случаи состояний гонки. Их много, но для понимания сути приведу несколько самых важных:
- SM-SM и GM-GM: между командами одного типа.
- SM-GM: между SM и GM в рамках одного репозитория.
Поясню, в чём заключается сложность второго случая. Если SM и GM будут действовать несогласованно, то может случиться так, что SM соединит main с первым тикетом из очереди, а GM этого тикета не заметит, то есть соберёт все остальные тикеты без учёта первого. Например, если SM переведёт тикет в статус In Master, а GM будет всегда выбирать тикеты по статусу To Merge, то GM может никогда не обработать тикета, соединённого SM. При этом тот самый первый тикет может конфликтовать как минимум с одним из других.
Во избежание логических конфликтов GM нужно обрабатывать все тикеты в очереди без исключения. По этой же причине алгоритм GM в связке с SM обязательно должен соблюдать тот же порядок тикетов в очереди, что и SM, так как именно этот порядок определяет, какая половина очереди будет выбрана в случае неудачной сборки в GM. При соблюдении этих условий тикет, обрабатываемый SM, будет всегда входить в сборку GM, что обеспечит нам нужную степень синхронизации.
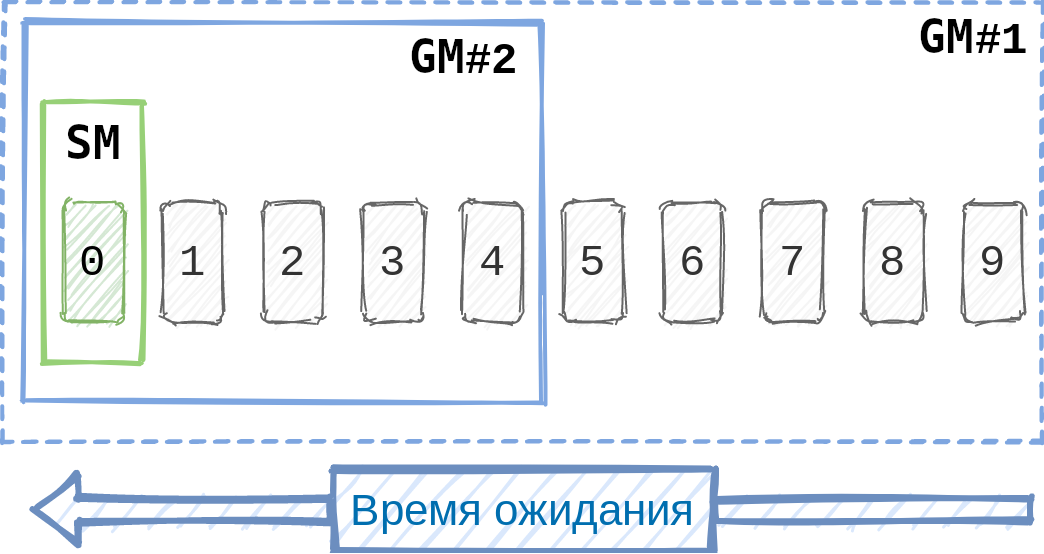
Таким образом, мы получили своего рода неблокирующую синхронизацию.
Немного о TeamCity
В процессе реализации GM нам предстояло обработать много нюансов, которыми я не хочу перегружать статью. Но один из них заслуживает внимания. В ходе разработки я столкнулся с проблемой зацикливания команды GM: процесс постоянно пересобирал ветку MC и создавал новую сборку в TeamCity. Проблема оказалась в том, что TeamCity не успел скачать обновления репозитория, в которых была ветка MC, созданная процессом GM несколько секунд назад. К слову, интервал обновления репозитория в TeamCity у нас составляет примерно 30 секунд.В качестве хотфикса я ввёл плавающий тег сборки, то есть создал в TeamCity тег с названием, похожим на automerge_ios_repo_git, и перемещал его от сборки к сборке, чтобы иметь представление о том, какая сборка является актуальной, в каком она состоянии и т. д. Но, понимая несовершенство этого подхода, я взялся за поиски способа донесения до TeamCity информации о новом состоянии ветки MC, а также способа прикрепления ревизии к сборке.
Кто-то посчитает решение очевидным, но я нашёл его не сразу. Оказывается, прикрепить ревизию к сборке при её добавлении в очередь можно при помощи параметра lastChanges метода addBuildToQueue:
<lastChanges>
<change
locator="version:{{revision}},buildType
id:{{build_type}})"/></lastChanges>
В этом примере {{revision}} заменяется на 16-ричную последовательность коммита, а {{build_type}} — на идентификатор конфигурации сборки. Но этого недостаточно, так как TeamCity, не имея информации о новом коммите, может отказать нам в запросе.
Для того чтобы новый коммит дошёл до TeamCity, нужно либо подождать примерно столько, сколько указано в настройках конфигурации корня VCS, либо попросить TeamCity проверить наличие изменений в репозитории («Pending Changes») при помощи метода requestPendingChangesCheck, а затем подождать, пока TeamCity скачает изменения, содержащие наш коммит. Проверка такого рода выполняется посредством метода getChange, где в changeLocator нужно передать как минимум сам коммит в качестве параметра локатора version. Кстати, на момент написания статьи (и кода) на странице ChangeLocator в официальной документации описание параметра version отсутствовало. Быть может, поэтому я не сразу узнал о его существовании и о том, что это 40-символьный 16-ричный хеш коммита.
Псевдокод:
teamCity.requestPendingChanges(buildType)
attempt = 1
while attempt <= 20:
response = teamCity.getChange(commit, buildType)
if response.commit == commit:
return True # Дождались
sleep(10)
return False
О предельно высокой скорости слияний
У жадной стратегии есть недостаток — на поиск ветки с ошибкой может потребоваться много времени. Например, 6 сборок для 20 тикетов у нас может занять около трёх часов. Можно ли устранить этот недостаток?Допустим, в очереди находится 10 тикетов, среди которых только 6-й приводит к падению сборки.

Согласно жадной стратегии, мы пробуем собрать сразу все 10 тикетов, что приводит к падению сборки. Далее собираем левую половину (с 1 по 5) успешно, так как тикет с ошибкой остался в правой половине.

Если бы мы сразу запустили сборку на левой половине очереди, то не потеряли бы времени. А если бы проблемным оказался не 6-й тикет, а 4-й, то было бы выгодно запустить сборку на четверти длины всей очереди, то есть на тикетах с 1 по 3, например.

Продолжая эту мысль, мы придём к выводу о том, что полностью избавиться от ожиданий неудачных сборок можно только при условии параллельного запуска сборок всех комбинаций тикетов:
Обратите внимание, во избежание конфликтов здесь необходимо соблюдать очерёдность, поэтому комбинации вроде «пятый и первый» недопустимы. Тогда можно было бы просто брать успешные сборки и соединять их тикеты в main. При этом неудачные сборки времени бы не отнимали.
Примерно такой же алгоритм реализован в премиум-функции GitLab под названием «Merge Trains». Перевода этого названия на русский язык я не нашёл, поэтому назову его «Поезда слияний». «Поезд» представляет собой очередь «запросов на слияние» с основной веткой («merge requests»). Для каждого такого запроса выполняется слияние изменений ветки самого запроса с изменениями всех запросов, расположенных перед ним (то есть запросов, добавленных в «поезд» ранее). Например, для трёх запросов на слияние A, B и С GitLab создаёт следующие сборки:
- Изменения из А, соединённые с основной веткой.
- Изменения из A и B, соединённые с основной веткой.
- Изменения из A, B и C, соединённые с основной веткой.
GitLab ограничивает количество параллельно работающих сборок двадцатью. Все остальные сборки попадают в очередь ожидания вне поезда. Как только сборка завершает работу, её место занимает очередная сборка из очереди ожидания.
Таким образом, запуск параллельных сборок по всем допустимым комбинациям тикетов в очереди позволяет добиться очень высокой скорости слияний. Избавившись от очереди ожидания, можно и вовсе приблизиться к максимальной скорости.
Но если преград человеческой мысли нет, то пределы аппаратных ресурсов видны достаточно отчётливо:
- Каждой сборке нужен свой агент в TeamCity.
- В нашем случае у сборки мобильного приложения есть порядка 15-100 сборок-зависимостей, каждой из которых нужно выделить по агенту.
- Сборки автомерджа мобильных приложений в main составляют лишь малую часть от общего количества сборок в TeamCity.
- Вся очередь.
- Левая половина очереди.
- Левая четверть очереди.
Что в итоге получилось
В результате применения комбинированной стратегии автомерджа нам удалось добиться следующего:- уменьшение среднего размера очереди в 2-3 раза;
- уменьшение среднего времени ожидания в 4-5 раз;
- мердж порядка 50 веток в день в каждом из упомянутых проектов;
- увеличение пропускной способности автомерджа при сохранении высокого уровня надёжности, то есть мы практически сняли ограничение на количество тикетов в сутки.
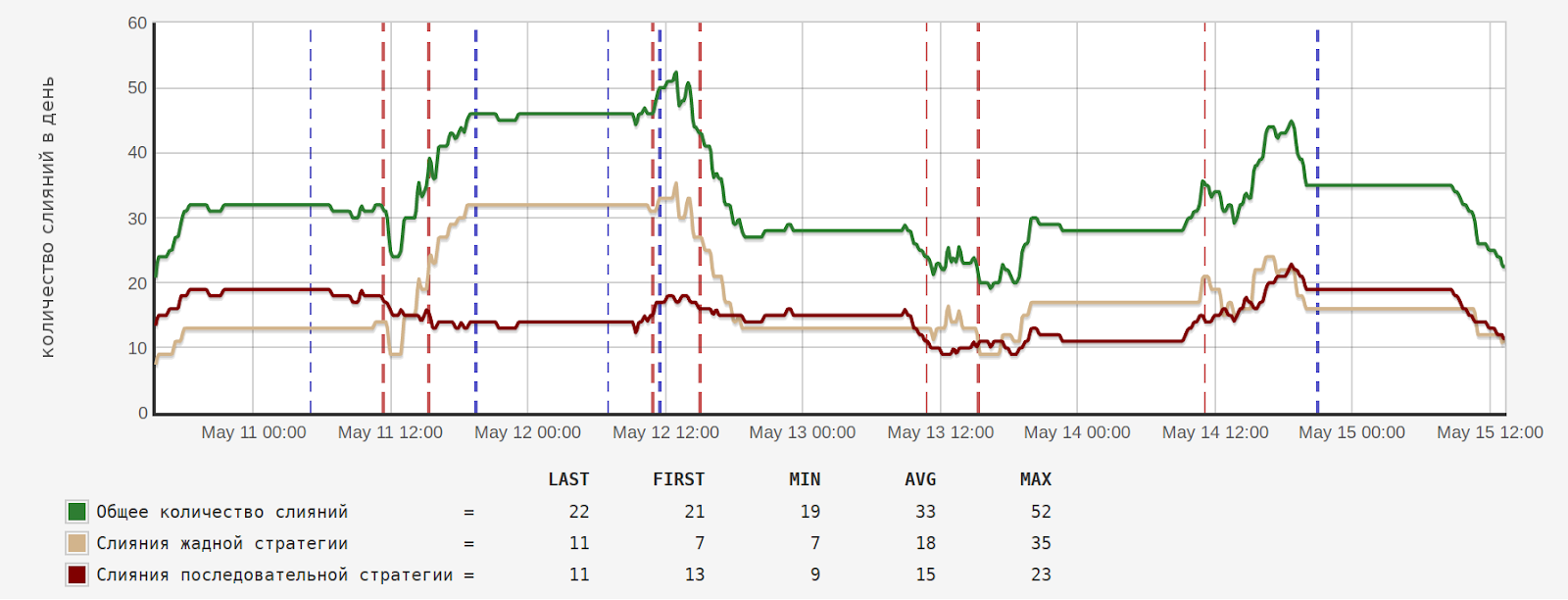
Количество тикетов в очереди до и после внедрения нового алгоритма:
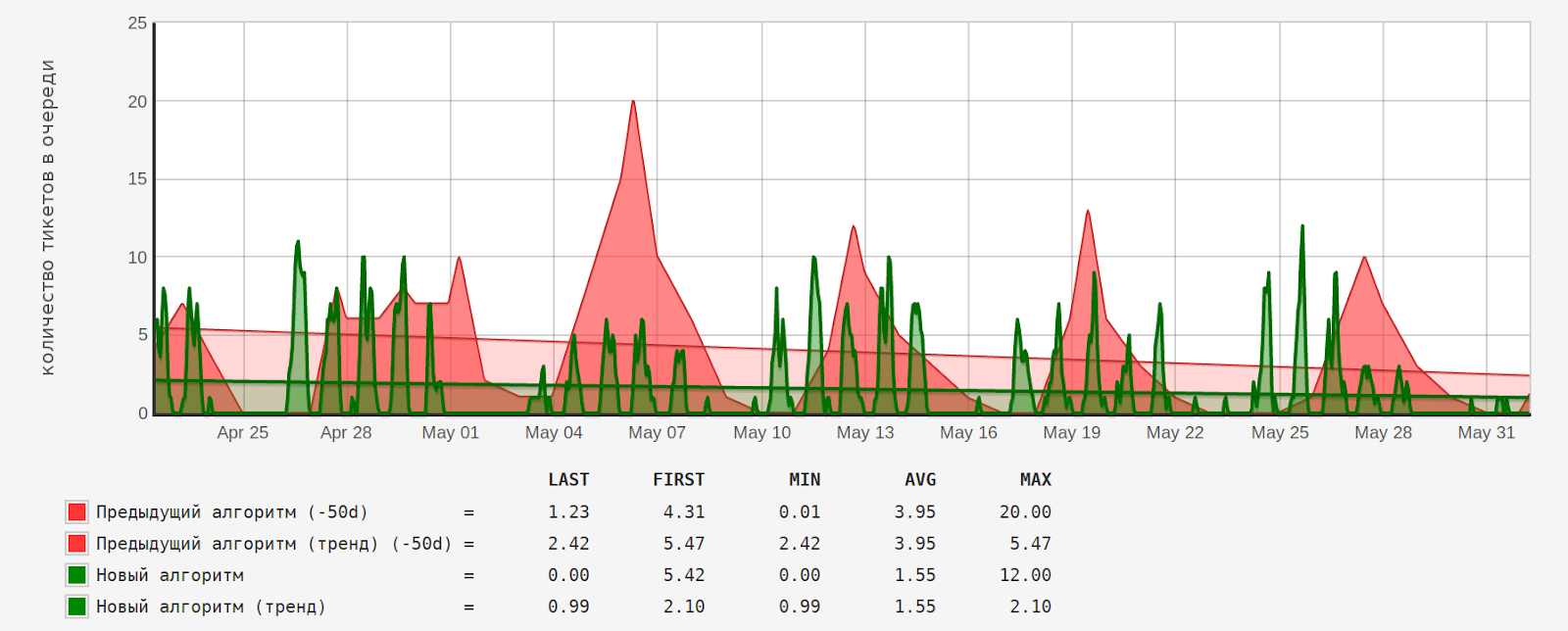
Среднее количество тикетов в очереди («AVG») уменьшилось в 2,5 раза (3,95/1,55).
Время ожидания тикетов в минутах:
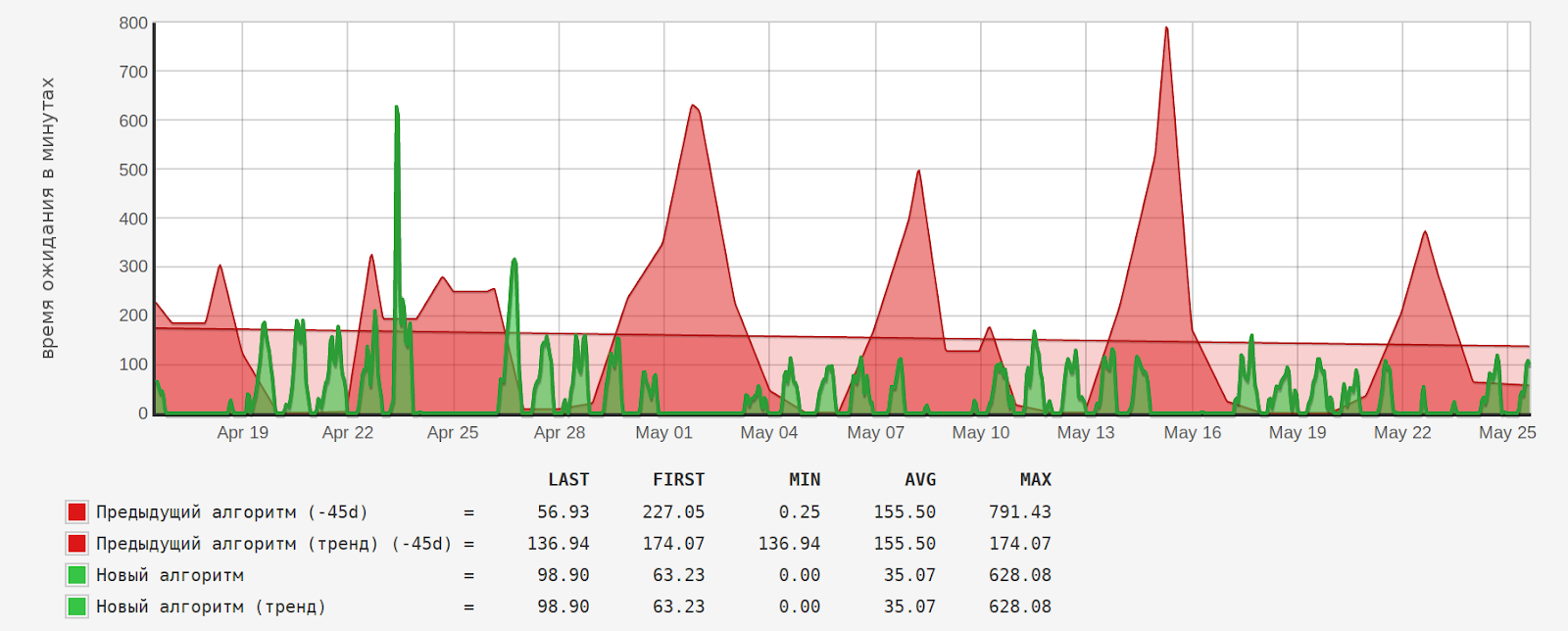
Среднее время ожидания («AVG») уменьшилось в 4,4 раза (155,5/35,07).
Источник статьи: https://habr.com/ru/company/badoo/blog/560228/