Привет, коллеги! В этой статье я покажу свой подход к написанию многопоточного кода, который помогает избежать типовых ошибок, связанных с использованием базовых примитивов синхронизации.
Демонстрация идеи будет проходить на живых примерах кода на современном C++. Большинство описанных решений я применял сначала на собственных проектах, а теперь часть этих подходов уже используется в нашей собственной микроядерной операционной системе «Лаборатории Касперского» (KasperskyOS).
Сразу хочу оговориться, что тема многопоточности — очень большая и серьезная. И эта статья — не полноценный анализ проблем многопоточки, а только частНЫе (но довольно частЫе) кейсы, когда мы вынуждены использовать мьютексы.
Ну и также дополню, что концепция, о которой я буду говорить, в общих чертах уже описана вот в этой моей статье. Пришла пора поговорить про нее подробнее с чисто практической стороны.
Начнем с рассмотрения типичных ошибок многопоточного кода, с которыми часто встречаешься на код-ревью или где-нибудь в унаследованном коде. Так будет видно, в какой нише моя идея может быть применена на практике.
Общие данные, которые используются совместно разными потоками, обычно защищают мьютексами, которые создаются независимо от самих защищаемых данных. Поэтому достаточно распространены ситуации, когда:
С последствиями таких ошибок, думаю, сталкивались многие:
Все это большая боль, красные глаза и сеансы отладки. Чаще проблемы возникают из-за того, что мьютекс забыли залочить. В результате данные нарушаются другим потоком и приходят в несогласованное состояние. Где-то позже это выстреливает, и программа падает. При плохом сценарии развития событий можно получить коррапт базы данных.
Код ниже — иллюстрация того, что я имею в виду. Это не реальный пример, просто демонстрация.
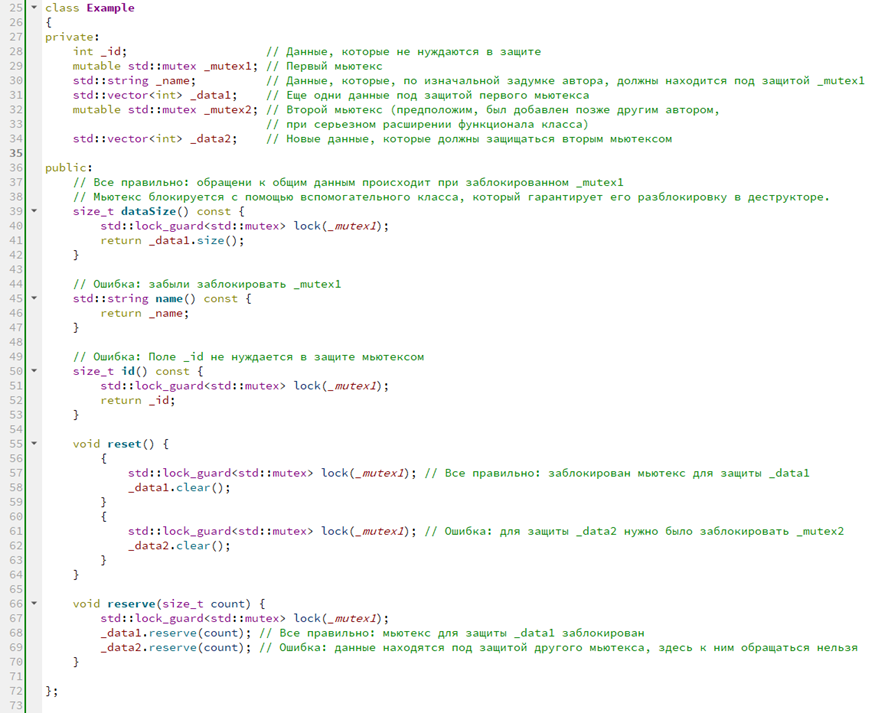
Здесь есть некий класс с полями данных, не все из которых нуждаются в защите. Например, _id — не нуждается. Есть первый мьютекс (_mutex1), который защищает _name и _data1, а также _mutex2, который защищает _data2. Возможно, он был добавлен уже позже другим человеком, который не разобрался во всех деталях. В приведенном выше коде сложно запутаться, но классы бывают довольно длинными. Когда нет возможности их переписать, приходится разбираться в чужой логике, и вот в этом случае запутаться с мьютексами очень легко.
Первый метод — dataSize. Здесь мы воспользовались lock_guard, залочили первый мьютекс и обратились к _data1. А вот в методе name про _mutex1 забыли, хотя предполагалось, что первый мьютекс будет защищать и _name.
А в следующем методе _mutex1 залочили, чтобы обратиться к _id (хотя _id и не предполагалось защищать). Получили проседание по производительности, поскольку другой поток в этот момент ждал.
В следующем блоке кода мы могли использовать копипаст для быстрого написания, но забыть, что во второй строке необходимо залочить _mutex2 (и по ошибке залочили _mutex1).
Ну и последний пример — мы сначала лочим один мьютекс, а потом обращаемся к данным, которые защищает другой мьютекс.
Поговорим о том, как эту проблему можно решить.
— Повысить качество инспекции кода. Это первое, что приходит в голову. Но человеческий фактор никто не отменял — всегда можно пропустить какие-то моменты, особенно в сложном коде с нетривиальной логикой. Поэтому метод не дает гарантии 100%.
— Использовать готовые библиотеки для распараллеливания. Это попытка уйти от прямого использования примитивов синхронизации. Например, Streams в Java 8 сделан удобно — достаточно добавить один вызов, и вся коллекция уже обрабатывается в параллели, а разработчику не нужно думать об этих низкоуровневых сущностях.
— Применять статические анализаторы / санитайзеры кода, которые умеют отлавливать подобные ситуации. Правда, они бывают довольно дорогие и не всегда есть возможность их применить. И, опять же, они не дают гарантии 100%.
— Использовать только неизменяемые общие данные. Это специфический подход, при котором риски просто отпадают, поскольку параллельно несколько потоков не могут поменять данные. Но существуют определенные ограничения в использовании такого подхода. Некоторые вещи мы просто не сможем с его помощью реализовать.
— Полностью запретить использование общих данных, например применить модель акторов в Scala, когда между потоками разрешен только обмен асинхронными сообщениями. Кстати, этот подход встроен в язык и можно свободно им пользоваться. Но аналоги есть не в любом языке. В С++ нам придется искать какой-то надежный фреймворк, и к нему останутся вопросы, насколько хорошо там все реализовано под капотом — нет ли ошибок, выживет ли под большой нагрузкой. То есть при внедрении методики придется проводить достаточно серьезные исследования. Плюс на такую абстракцию можно положить не любую многопоточную задачу.
— Использовать модель, при которой прямые вызовы методов класса возможны только из породившего его потока, остальные происходят опосредованно, например через очередь сообщений. В качестве примера есть довольно любопытная модель многопоточности в Qt. В рамках этой модели можно писать, как в однопоточном режиме, потому что из другого потока вызов не придет никогда. Но это тоже конвенция, которую нужно соблюдать (и все-таки это фишка Qt, а не стандарт языка).
— Использовать определенные языки. В некоторых языках компилятор в состоянии полностью проконтролировать любые обращения к общим данным и запретить некорректные попытки. Например, это доступно в языках программирования D или Rust и отчасти C#. В том же D есть ключевое слово shared, которым объявляются общие данные. Далее компилятор отслеживает все неправильные обращения к ним и подсказывает ошибки на этапе компиляции.
Я предлагаю альтернативный подход — попытку исправить ситуацию существующими возможностями языка без введения новых ключевых слов или использования сторонних фреймворков.
На мой взгляд, главная проблема в том, что мьютекс живет отдельно от защищаемых данных и связь с ними очень эфемерная. Автор, который писал код, предполагал, что мьютекс будет защищать именно эти данные, но со временем в ходе модификации класса это неявное соглашение могло потеряться. А из-за этого возникают ошибки. Нужно связать мьютексы и защищаемые ими данные так, чтобы у них был общий жизненный цикл. Более того, хочется вообще уйти от ручного управления мьютексами и четко регламентировать доступ к общим данным. И сделать это нужно средствами самого языка программирования без использования сторонних фреймворков и изменений в компиляторе.
Появилась идея ввести абстракцию — шаблонный класс SharedState, который будет инкапсулировать в себе и общие данные, к которым планируется обращаться из нескольких потоков, и средства для их защиты.
Таким образом, все общие данные помещаются в отдельный класс или структуру, которым, собственно, и специфицируется шаблонный класс SharedState. Объект общих данных создается в конструкторе SharedState, то есть все параметры, необходимые для его создания, передаются в класс SharedState. И извне объект общих данных недоступен, поскольку существует как приватное поле.
SharedState гарантирует четко регламентированный защищенный доступ к общим данным. Можно запросить доступ на чтение или модификацию данных, а также дожидаться их определенного состояния.
Для доступа к такой модели хорошо подходят лямбда-выражения, которые есть в С++.
На практике мы передаем в интерфейс SharedState все параметры, необходимые для создания объекта общих данных.
Шаблонный метод для просмотра данных называется view и принимает в качестве параметра std::function, которая будет вызвана с константной ссылкой на общие данные (то есть в этом вызове данные защищены — грубо говоря, мьютекс залочен внутри). Метод view можно специфицировать под любое возвращаемое значение. Возможно, в «боевом» коде вместо std::function лучше использовать шаблон (при обращении к динамической памяти std::function может вызывать снижение производительности), но для наглядности и прозрачности сигнатур здесь будет пример с использованием std::function.
Простой метод modify для изменения общих данных принимает std::function, которая будет вызвана с не константной ссылкой на общие данные. Внутри мы как-то модифицируем данные и выходим. Более сложный случай — это метод modify, который возвращает класс Action. Так можно реализовать более сложные вещи.
В интерфейсе Action есть методы для простой модификации общих данных без оповещения об их изменении access и extract, а также методы для модификации общих данных с одновременным оповещением об их изменении. notifyOne и notifyAll — они введены как раз для того, чтобы предоставить возможность одному или, соответственно, всем ожидающим потокам получать нотификации об изменениях. Также предусмотрен метод when, который принимает std::function, — предикат для определения подходящего состояния общих данных. Метод возвращает тот же экземпляр объекта Action, поэтому можно строить цепочки вызовов:

Здесь на основе SharedState я написал простую реализацию пула потоков. Внутри цикл, в котором каждый воркер из пула потоков ожидает появления новых задач и берет их на выполнение. Мы обращаемся к SharedState, который называется _state, запрашиваем modify(). Он возвращает Action, у которого мы вызываем метод when. Детально разбирать не буду, но смысл в том, что мы проверяем, есть ли в очереди новые задачи, и уже внутри пытаемся получить доступ к общим данным.
Этот код выглядит не идеально. Когда мы делаем экстракт, приходится использовать ключевое слово template — это требование С++. А еще приходится писать много скобок. Все это — минусы (впрочем, если пользоваться Cpp2/CppFront, эти недостатки нивелируются") ). Но когда та же функция была написана с использованием мьютексов и condition variables, выглядело это еще хуже. Сейчас мы ушли от общения с мьютексами, и код стал чище и понятнее.
). Но когда та же функция была написана с использованием мьютексов и condition variables, выглядело это еще хуже. Сейчас мы ушли от общения с мьютексами, и код стал чище и понятнее.
Посмотрим, что под капотом класса SharedState.
Он очень простой. Здесь есть некая оптимизация на стандарт языка — если используем 17-й стандарт, нам доступны shared-мьютексы, и мы можем позволить нескольким потокам обращаться к данным на чтение. В некоторых случаях, например когда данные часто читаются, но редко модифицируются, это может увеличить performance.
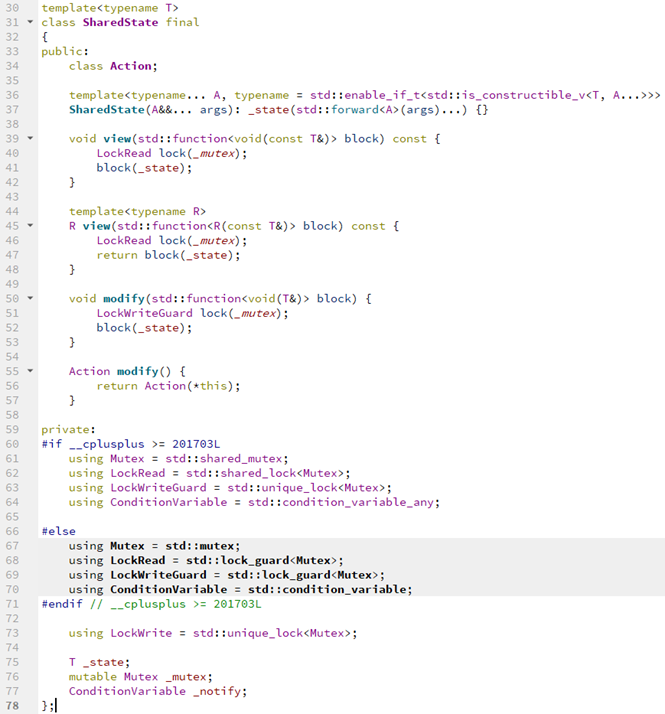
Здесь мы в конструкторе проверяем, что этот внутренний класс с общими данными может быть создан с теми параметрами, которые передали. Дальше описываем метод view, в который передаем std::function. Описанному там прототипу передается константная ссылка на общие данные. И здесь помогает компилятор — если мы запросили доступ на чтение, но пытаемся модифицировать данные, он будет ругаться.
В методе modify мы уже эксклюзивно лочим данные, поэтому ссылка туда передается не константная. Данный метод более сложный и возвращает Action.
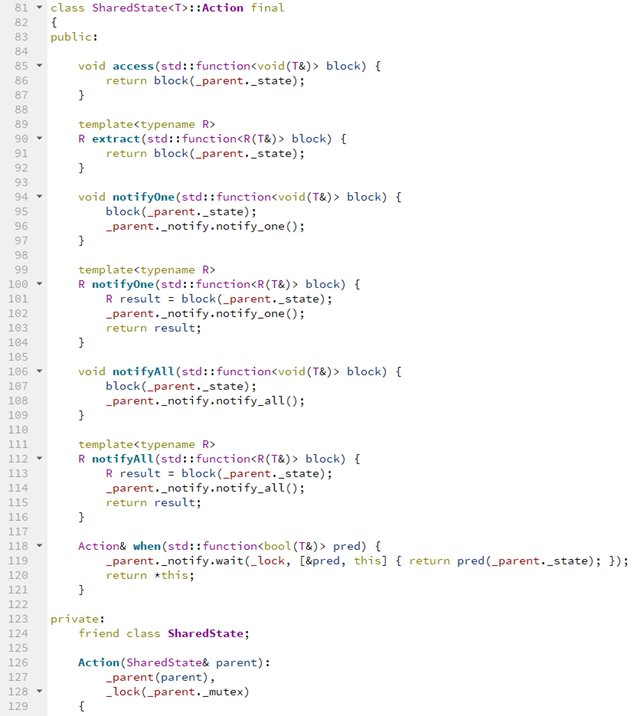
Здесь мы передали в приватный конструктор Action SharedState. Он лочится, и на время жизни Action общие данные заблокированы. Внутри мы делаем access — это простой способ модифицировать данные. Предусмотрены notifyOne и notifyAll. А when — метод condition variables, куда передается предикат. Он останавливает цепочку выполнения до тех пор, пока предикат не выполнится для общих данных.
Так будет выглядеть первый пример из начала статьи, если мы перепишем его с использованием SharedState.

Общие данные, которые предполагалось защищать первым мьютексом, помещаем в одну структуру, а данные, защищаемые вторым мьютексом, — в другую. Создаем два экземпляра SharedState, специфицируем их структурой Data1 и Data2. _id у нас лежат отдельно, потому что не нуждаются в защите.
Чтобы считать размер вектора, мы специфицируем view результатом, который хотим возвращать, в данном случае size_t, и получаем константную ссылку (здесь ее тип не пишем, пользуемся auto). Далее обращаемся к структуре, которая доступна по константной ссылке, и вызываем метод size(). Если мы попробуем вызвать модифицирующий метод (без спецификатора const), компилятор поможет найти эту ошибку.
По сути мы здесь исправляем проблему первого примера — не лочим _id. Явные блоки кода помогают понять, к каким именно общим данным мы обращаемся. Не приходится думать о том, каким мьютексом их надо залочить. Мы просто получаем доступ к данным, а защита осуществляется где-то под капотом.
Какие преимущества я вижу в использовании этого подхода:
Вместо итогов хотел бы также упомянуть, что определенные ошибки могут произойти и при использовании SharedState. Вот что нужно учитывать, чтобы с ними не сталкиваться:
Простая реализация Thread Pool: https://sourceforge.net/p/cpp-mate/code/ci/default/tree/src/main/public/CppMate/ThreadPool.hpp
https://cpp-mate.sourceforge.io/doc/classCppMate_1_1ThreadPool.html
Реализация абстрактного кэша: https://sourceforge.net/p/cpp-mate/code/ci/default/tree/src/main/public/CppMate/Cache.hpp
Впрочем, есть и альтернативные решения:
* В библиотеке Boost существуют Synchronized Data Structures и, в частности, Synchronized Values, однако их поддержка пока находится в экспериментальной стадии
* В библиотеке Folly существуют похожие механизмы, описанные вот тут: https://github.com/facebook/folly/blob/main/folly/docs/Synchronized.md
Если вам понравилась идея и вы хотите попробовать ее на C++, у меня готова полная реализация SharedState с документацией (Doxygen).
А в целом, если вы любите ковыряться в подобных вещах именно на С++, приходите к нам в «Лабораторию Касперского». Пройти все этапы собеседований можно за пару дней. «Плюсы» являются одним из ключевых языков в нашем технологическом стеке, так что спектр возможных задач огромен, как и список новых фич. И legacy там нет.
А здесь можно проверить свои знания C++ в нашей игре про умный город.

 habr.com
habr.com
Демонстрация идеи будет проходить на живых примерах кода на современном C++. Большинство описанных решений я применял сначала на собственных проектах, а теперь часть этих подходов уже используется в нашей собственной микроядерной операционной системе «Лаборатории Касперского» (KasperskyOS).
Сразу хочу оговориться, что тема многопоточности — очень большая и серьезная. И эта статья — не полноценный анализ проблем многопоточки, а только частНЫе (но довольно частЫе) кейсы, когда мы вынуждены использовать мьютексы.
Ну и также дополню, что концепция, о которой я буду говорить, в общих чертах уже описана вот в этой моей статье. Пришла пора поговорить про нее подробнее с чисто практической стороны.
Типичные ошибки многопоточного кода
Начнем с рассмотрения типичных ошибок многопоточного кода, с которыми часто встречаешься на код-ревью или где-нибудь в унаследованном коде. Так будет видно, в какой нише моя идея может быть применена на практике.
Общие данные, которые используются совместно разными потоками, обычно защищают мьютексами, которые создаются независимо от самих защищаемых данных. Поэтому достаточно распространены ситуации, когда:
- Мьютекс не был заблокирован при обращении к общим данным.
- Был заблокирован не тот мьютекс (предназначенный для защиты других данных).
- Мьютекс заблокирован без обращения к общим данным. Вероятно, это наименее критичная ситуация, но она может негативно влиять на производительность.
С последствиями таких ошибок, думаю, сталкивались многие:
- Начинаются неожиданные падения в разных непонятных местах. По бэктрейсам видно, что программа упала, но почему именно — понять можно не всегда.
- Падения происходят случайно, но могут зависеть от нагрузки на приложение и системного окружения.
- Трудно определить и воспроизвести сценарий сбоя.
- Происходит нарушение целостности данных.
- Падает производительность.
Все это большая боль, красные глаза и сеансы отладки. Чаще проблемы возникают из-за того, что мьютекс забыли залочить. В результате данные нарушаются другим потоком и приходят в несогласованное состояние. Где-то позже это выстреливает, и программа падает. При плохом сценарии развития событий можно получить коррапт базы данных.
Код ниже — иллюстрация того, что я имею в виду. Это не реальный пример, просто демонстрация.
Здесь есть некий класс с полями данных, не все из которых нуждаются в защите. Например, _id — не нуждается. Есть первый мьютекс (_mutex1), который защищает _name и _data1, а также _mutex2, который защищает _data2. Возможно, он был добавлен уже позже другим человеком, который не разобрался во всех деталях. В приведенном выше коде сложно запутаться, но классы бывают довольно длинными. Когда нет возможности их переписать, приходится разбираться в чужой логике, и вот в этом случае запутаться с мьютексами очень легко.
Первый метод — dataSize. Здесь мы воспользовались lock_guard, залочили первый мьютекс и обратились к _data1. А вот в методе name про _mutex1 забыли, хотя предполагалось, что первый мьютекс будет защищать и _name.
А в следующем методе _mutex1 залочили, чтобы обратиться к _id (хотя _id и не предполагалось защищать). Получили проседание по производительности, поскольку другой поток в этот момент ждал.
В следующем блоке кода мы могли использовать копипаст для быстрого написания, но забыть, что во второй строке необходимо залочить _mutex2 (и по ошибке залочили _mutex1).
Ну и последний пример — мы сначала лочим один мьютекс, а потом обращаемся к данным, которые защищает другой мьютекс.
Существующие методики решения проблемы
Поговорим о том, как эту проблему можно решить.
— Повысить качество инспекции кода. Это первое, что приходит в голову. Но человеческий фактор никто не отменял — всегда можно пропустить какие-то моменты, особенно в сложном коде с нетривиальной логикой. Поэтому метод не дает гарантии 100%.
— Использовать готовые библиотеки для распараллеливания. Это попытка уйти от прямого использования примитивов синхронизации. Например, Streams в Java 8 сделан удобно — достаточно добавить один вызов, и вся коллекция уже обрабатывается в параллели, а разработчику не нужно думать об этих низкоуровневых сущностях.
— Применять статические анализаторы / санитайзеры кода, которые умеют отлавливать подобные ситуации. Правда, они бывают довольно дорогие и не всегда есть возможность их применить. И, опять же, они не дают гарантии 100%.
— Использовать только неизменяемые общие данные. Это специфический подход, при котором риски просто отпадают, поскольку параллельно несколько потоков не могут поменять данные. Но существуют определенные ограничения в использовании такого подхода. Некоторые вещи мы просто не сможем с его помощью реализовать.
— Полностью запретить использование общих данных, например применить модель акторов в Scala, когда между потоками разрешен только обмен асинхронными сообщениями. Кстати, этот подход встроен в язык и можно свободно им пользоваться. Но аналоги есть не в любом языке. В С++ нам придется искать какой-то надежный фреймворк, и к нему останутся вопросы, насколько хорошо там все реализовано под капотом — нет ли ошибок, выживет ли под большой нагрузкой. То есть при внедрении методики придется проводить достаточно серьезные исследования. Плюс на такую абстракцию можно положить не любую многопоточную задачу.
— Использовать модель, при которой прямые вызовы методов класса возможны только из породившего его потока, остальные происходят опосредованно, например через очередь сообщений. В качестве примера есть довольно любопытная модель многопоточности в Qt. В рамках этой модели можно писать, как в однопоточном режиме, потому что из другого потока вызов не придет никогда. Но это тоже конвенция, которую нужно соблюдать (и все-таки это фишка Qt, а не стандарт языка).
— Использовать определенные языки. В некоторых языках компилятор в состоянии полностью проконтролировать любые обращения к общим данным и запретить некорректные попытки. Например, это доступно в языках программирования D или Rust и отчасти C#. В том же D есть ключевое слово shared, которым объявляются общие данные. Далее компилятор отслеживает все неправильные обращения к ним и подсказывает ошибки на этапе компиляции.
Я предлагаю альтернативный подход — попытку исправить ситуацию существующими возможностями языка без введения новых ключевых слов или использования сторонних фреймворков.
Суть идеи
На мой взгляд, главная проблема в том, что мьютекс живет отдельно от защищаемых данных и связь с ними очень эфемерная. Автор, который писал код, предполагал, что мьютекс будет защищать именно эти данные, но со временем в ходе модификации класса это неявное соглашение могло потеряться. А из-за этого возникают ошибки. Нужно связать мьютексы и защищаемые ими данные так, чтобы у них был общий жизненный цикл. Более того, хочется вообще уйти от ручного управления мьютексами и четко регламентировать доступ к общим данным. И сделать это нужно средствами самого языка программирования без использования сторонних фреймворков и изменений в компиляторе.
Появилась идея ввести абстракцию — шаблонный класс SharedState, который будет инкапсулировать в себе и общие данные, к которым планируется обращаться из нескольких потоков, и средства для их защиты.
Таким образом, все общие данные помещаются в отдельный класс или структуру, которым, собственно, и специфицируется шаблонный класс SharedState. Объект общих данных создается в конструкторе SharedState, то есть все параметры, необходимые для его создания, передаются в класс SharedState. И извне объект общих данных недоступен, поскольку существует как приватное поле.
SharedState гарантирует четко регламентированный защищенный доступ к общим данным. Можно запросить доступ на чтение или модификацию данных, а также дожидаться их определенного состояния.
Для доступа к такой модели хорошо подходят лямбда-выражения, которые есть в С++.
Интерфейс SharedState
На практике мы передаем в интерфейс SharedState все параметры, необходимые для создания объекта общих данных.
Шаблонный метод для просмотра данных называется view и принимает в качестве параметра std::function, которая будет вызвана с константной ссылкой на общие данные (то есть в этом вызове данные защищены — грубо говоря, мьютекс залочен внутри). Метод view можно специфицировать под любое возвращаемое значение. Возможно, в «боевом» коде вместо std::function лучше использовать шаблон (при обращении к динамической памяти std::function может вызывать снижение производительности), но для наглядности и прозрачности сигнатур здесь будет пример с использованием std::function.
Простой метод modify для изменения общих данных принимает std::function, которая будет вызвана с не константной ссылкой на общие данные. Внутри мы как-то модифицируем данные и выходим. Более сложный случай — это метод modify, который возвращает класс Action. Так можно реализовать более сложные вещи.
В интерфейсе Action есть методы для простой модификации общих данных без оповещения об их изменении access и extract, а также методы для модификации общих данных с одновременным оповещением об их изменении. notifyOne и notifyAll — они введены как раз для того, чтобы предоставить возможность одному или, соответственно, всем ожидающим потокам получать нотификации об изменениях. Также предусмотрен метод when, который принимает std::function, — предикат для определения подходящего состояния общих данных. Метод возвращает тот же экземпляр объекта Action, поэтому можно строить цепочки вызовов:
Здесь на основе SharedState я написал простую реализацию пула потоков. Внутри цикл, в котором каждый воркер из пула потоков ожидает появления новых задач и берет их на выполнение. Мы обращаемся к SharedState, который называется _state, запрашиваем modify(). Он возвращает Action, у которого мы вызываем метод when. Детально разбирать не буду, но смысл в том, что мы проверяем, есть ли в очереди новые задачи, и уже внутри пытаемся получить доступ к общим данным.
Этот код выглядит не идеально. Когда мы делаем экстракт, приходится использовать ключевое слово template — это требование С++. А еще приходится писать много скобок. Все это — минусы (впрочем, если пользоваться Cpp2/CppFront, эти недостатки нивелируются
). Но когда та же функция была написана с использованием мьютексов и condition variables, выглядело это еще хуже. Сейчас мы ушли от общения с мьютексами, и код стал чище и понятнее.Посмотрим, что под капотом класса SharedState.
Он очень простой. Здесь есть некая оптимизация на стандарт языка — если используем 17-й стандарт, нам доступны shared-мьютексы, и мы можем позволить нескольким потокам обращаться к данным на чтение. В некоторых случаях, например когда данные часто читаются, но редко модифицируются, это может увеличить performance.
Здесь мы в конструкторе проверяем, что этот внутренний класс с общими данными может быть создан с теми параметрами, которые передали. Дальше описываем метод view, в который передаем std::function. Описанному там прототипу передается константная ссылка на общие данные. И здесь помогает компилятор — если мы запросили доступ на чтение, но пытаемся модифицировать данные, он будет ругаться.
В методе modify мы уже эксклюзивно лочим данные, поэтому ссылка туда передается не константная. Данный метод более сложный и возвращает Action.
Здесь мы передали в приватный конструктор Action SharedState. Он лочится, и на время жизни Action общие данные заблокированы. Внутри мы делаем access — это простой способ модифицировать данные. Предусмотрены notifyOne и notifyAll. А when — метод condition variables, куда передается предикат. Он останавливает цепочку выполнения до тех пор, пока предикат не выполнится для общих данных.
Как выглядят примеры с SharedState
Так будет выглядеть первый пример из начала статьи, если мы перепишем его с использованием SharedState.
Общие данные, которые предполагалось защищать первым мьютексом, помещаем в одну структуру, а данные, защищаемые вторым мьютексом, — в другую. Создаем два экземпляра SharedState, специфицируем их структурой Data1 и Data2. _id у нас лежат отдельно, потому что не нуждаются в защите.
Чтобы считать размер вектора, мы специфицируем view результатом, который хотим возвращать, в данном случае size_t, и получаем константную ссылку (здесь ее тип не пишем, пользуемся auto). Далее обращаемся к структуре, которая доступна по константной ссылке, и вызываем метод size(). Если мы попробуем вызвать модифицирующий метод (без спецификатора const), компилятор поможет найти эту ошибку.
По сути мы здесь исправляем проблему первого примера — не лочим _id. Явные блоки кода помогают понять, к каким именно общим данным мы обращаемся. Не приходится думать о том, каким мьютексом их надо залочить. Мы просто получаем доступ к данным, а защита осуществляется где-то под капотом.
Преимущества подхода
Какие преимущества я вижу в использовании этого подхода:
- Мы уходим от явного создания таких примитивов синхронизации, как мьютексы, локеры и condition variables, а заодно и от ручного управления ими.
- Общие данные представляют собой отдельную сущность. Кажется, что это плохо — мы порождаем лишние сущности. Но если посмотреть немного под другим углом, раньше общие данные представляли собой отдельные поля, разбросанные по классу. Однако у них была какая-то логическая связь (мы же шарим их между потоками). И благодаря отдельной структуре мы эту связь материализуем. Концептуально так и должно быть — данные живут и управляются вместе.
- Концептуально мы уходим от категорий «заблокирован/разблокирован», а начинаем мыслить в терминах доступа к данным: «просмотр/модификация/ожидание».
- Автор кода явно выражает свои намерения по отношению к общим данным. Например, объявляет прямо с помощью кода, что в следующих строчках хочет посмотреть общие данные. Такое самодокументирование помогает другим людям в его поддержке.
- Благодаря использованию std::shared_mutex (C++ 17) несколько потоков могут одновременно читать одни и те же данные, что в отдельных случаях может повысить общую производительность. Мы ничего для этого не делаем специально — просто выражаем намерение именно читать данные.
- Все методы SharedState реализованы как inline и объявлены прямо в заголовочном файле, поэтому производительность не должна пострадать после перехода на SharedState.
Примечание: я проверял ассемблерный «выхлоп» clang на Linux, и было видно, что компилятор сумел эффективно встроить лямбда-выражения в место использования. Однако для внедрения в продакшен рекомендую более основательные, системные исследования производительности.
Правила использования SharedState
Вместо итогов хотел бы также упомянуть, что определенные ошибки могут произойти и при использовании SharedState. Вот что нужно учитывать, чтобы с ними не сталкиваться:
- Объект общих данных должен быть простым и не содержать сложной/неочевидной логики. Желательно обойтись без ссылок на внешние объекты. Основное назначение объекта общих данных — быть тривиальным контейнером, в С++ лучше всего подходит термин «структура».
- Для улучшения производительности необходимо минимизировать количество кода в лямбдах доступа к общим данным и ограничиться извлечением необходимой информации или ее модификацией. Не стоит вызывать внутри защищенных блоков какие-то тяжеловесные операции. Это верно и при любой работе с мьютексами. Но в данном случае не следует забывать, что все залочено. А поэтому лучше выполнять именно то, ради чего запросили доступ. Взяли доступ на чтение — прочитали, возможно, сохранили в локальную переменную, и уже с ней продолжаем работать. С модификацией аналогично: зашли, модифицировали, вышли. Вся сложная логика должна оставаться снаружи. Также нельзя обращаться к тому же экземпляру SharedState. Мьютексы используются не рекурсивно, поэтому иначе получится взаимоблокировка, deadlock.
- Сложные манипуляции с извлеченными данными лучше производить в локальных переменных за пределами блока лямбда-выражения. Однако не стоит забывать, что связь извлеченных данных с их источником в объекте общих данных сразу же теряется после выхода из лямбды, так как другой поток может их сразу же изменить.
- Нельзя сохранять ссылки на объект общих данных и работать с ним в обход регламента. Мы совершенно спокойно можем зайти в лямбду, сохранить указатели на общие данные и работать с ними снаружи. Но в этом случае контракт нарушается и ничего не гарантируется.
- Рекомендую не сохранять (например, в полях класса) экземпляр класса Action, который возвращает SharedState, потому что во время его существования внутренний мьютекс будет залочен. Лучше использовать его исключительно в цепочке вызовов (как в одном из приведенных выше примеров) или в крайнем случае как локальную переменную в ограниченном скопе (как, например, мьютекс в явно созданном для него блоке кода).
Примеры использования SharedState
Простая реализация Thread Pool: https://sourceforge.net/p/cpp-mate/code/ci/default/tree/src/main/public/CppMate/ThreadPool.hpp
https://cpp-mate.sourceforge.io/doc/classCppMate_1_1ThreadPool.html
Реализация абстрактного кэша: https://sourceforge.net/p/cpp-mate/code/ci/default/tree/src/main/public/CppMate/Cache.hpp
Впрочем, есть и альтернативные решения:
* В библиотеке Boost существуют Synchronized Data Structures и, в частности, Synchronized Values, однако их поддержка пока находится в экспериментальной стадии
* В библиотеке Folly существуют похожие механизмы, описанные вот тут: https://github.com/facebook/folly/blob/main/folly/docs/Synchronized.md
Если вам понравилась идея и вы хотите попробовать ее на C++, у меня готова полная реализация SharedState с документацией (Doxygen).
А в целом, если вы любите ковыряться в подобных вещах именно на С++, приходите к нам в «Лабораторию Касперского». Пройти все этапы собеседований можно за пару дней. «Плюсы» являются одним из ключевых языков в нашем технологическом стеке, так что спектр возможных задач огромен, как и список новых фич. И legacy там нет.
А здесь можно проверить свои знания C++ в нашей игре про умный город.
Вы все еще пишете многопоточку на C++ с ошибками синхронизации?
Привет, коллеги! В этой статье я покажу свой подход к написанию многопоточного кода, который помогает избежать типовых ошибок, связанных с использованием базовых примитивов синхронизации. Демонстрация...
habr.com