Люди делятся на два типа: одни летают за тысячу рублей из Питера во Владивосток, другие сутками скрупулезно высчитывают маршруты через Казахстан, отказываются от багажа, соглашаются на микро-кресла и в итоге все равно получают космический ценник.Вы продаете билетов на самолеты? - Нет, только показываю. - Красивое…
Почему так происходит, как формируются цены на авиабилеты и как в итоге покупать их дешевле — рассказываю под катом.

Первые шаги.
Для анализа данных надо определиться с базовыми параметрами входной информации:- Летать свободно можно только в рамках страны. Можно, конечно, и зарубеж, но из-за эпидемиологической обстановки по спросу есть явные искажения и международные направления реальной картинки не дадут. Когда “пыль уляжется” можно будет попробовать включить в анализ и эти направления;
- Организовывать сбор информации о ценах по всем авиаперевозчикам не хочется — их много. Да и смысла особого нет, раз хочется дешево, то нас интересуют только лоукостеры, а точнее самый популярный. Что, кстати, явно видно из отчета по рынку авиаперевозок;
- Маршруты выберем только самые популярные — в основном это будут туристические (Москва, Санкт-Петербург, Сочи);
- Никаких пересадок, только прямые рейсы. Хочется ведь не только дешево, но и быстро.
С требованиями к данным определились, теперь надо эти данные собрать и структурировать. Сбор данных был осуществлен стандартным методом. Описывать его нет смысла, материала в сети предостаточно, хочется лишь отметить какие данные собирались и вот тут весь изюм.
Дело в том, что это будут не совсем классические временные ряды, это будет срез цен (далее пакет) с определенной глубиной на дату среза, чтобы было понятнее, то представлю эти данные.

В нашем случае это будет срез глубиной в 60 дней по каждому маршруту, начиная с 15 февраля 2021 года по 15 августа 2021 года.
Смысл пакета в следующем: обычно если хочется куда-то слетать, то дата “открытая”, есть лишь некоторый горизонт желания и вот пакет позволяет либо оперировать набором цен с глубиной x-дней, либо в любой момент выбрать определенное число дней до вылета и понять динамику.
Самое время определить маршруты. Прошу не судить строго, но вот выбранные мною направления:
.")
Подготовка и проверка данных
С направлениями определились, сбор данных организован, собрано порядка 130 тыс. цен. В принципе неплохая база для анализа. Сейчас надо определиться с типом распределения и можно ли будет опираться при анализе на описательные статистики (спойлер: да, распределение данных — нормальное, можно использовать меры центральной тенденции, если этот этап не интересен, то его можно пропустить).В качестве инструментария все стандартно: Python (pandas+mathplotlib+seaborn). Уровень владения у меня любительский, поэтому в анализе есть явный перекос в сторону идеи и подхода, нежели жонглирования пакетами для анализа.
Чтобы никого не смущать ценами вида 4999, округлим вверх до ближайшей 100, чтобы получить 5000, так “читать” данные будет проще, а рубль спишем на условность.
Исходный датасет:
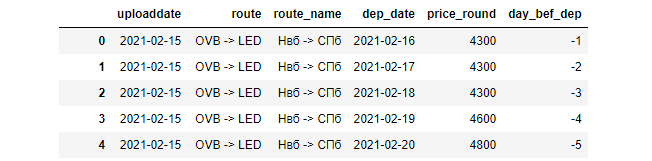
Весь анализ будет построен на основных статистических показателях и все так же будет анализировать пакет цен. Для этого потребуется сгруппировать данные по дате пакета и добавить в датасет базовые статистические показатели такие как: среднее арифметическое, медиана, 1-3 квартиль. А так как надо будет изобразить тип распределения, то сразу в датасет добавим среднеквадратическое отклонение для будущей стандартизации.
Код
def q1(x):
return x.quantile(0.25)
def q2(x):
return x.quantile(0.75)
df_agg = df_src.groupby(["uploaddate", "route", "route_name"]).agg({
"price_round": ["mean", "median","std", q1,q2]
}).sort_values(['route','uploaddate'], ascending=True).reset_index()
df_agg.columns = ["uploaddate","route", "route_name", "mean", "median", "std", "q1", "q2"]
df_agg
Результат выполнения — это новый датасет, который будем использовать после:

Для того, чтобы полноценно можно было оперировать описательными статистиками, необходимо определить тип распределения, вероятнее всего нормальное, но лучше убедиться в этом. Для этого надо стандартизировать данные в рамках пакетов. Стандартизация в данном случае нужна, чтобы избавиться от сезонного фактора. Итак следующий код стандартизирует данные и готовит новый датасет (для визуализации распределения).
Код
df_zsc = df_src.merge(df_agg, how = 'left', left_on=['uploaddate', 'route','route_name'], right_on=['uploaddate', 'route','route_name'])
df_zsc['z_score'] = (df_zsc['price_round']-df_zsc['mean'])/df_zsc['std']
df_zsc
Результат выполнения — стартовый датасет со стандартизацией:

Данные готовы для визуализации, можно строить гистограммы распределения, причем сразу в разрезе направлений (route). Чтобы визуально было легче воспринимать данные, добавлю на график вспомогательную линию нормального распределения.
Код
plt.figure(figsize=(12, 9))
N = 1500
y = np.linspace(-4, 4, N)
for i in ROUTES.index:
plt.subplot(3, 4, i+1)
df_0tmp = df_zsc.loc[df_zsc['route'] == ROUTES.iloc[i,1]]
plt.hist(df_0tmp["z_score"] ,bins = 120, alpha=0.8, label = ROUTES.iloc[i,2])
plt.plot(y, stats.norm.pdf
") *N, '--', alpha=0.8)
*N, '--', alpha=0.8)plt.ylim([0, N/3*2])
plt.yticks(np.arange(0, N/3*2+1, 300))
plt.xlim([-4, 4])
plt.legend(fontsize=8, loc='upper center')
plt.show()

Из диаграмм распределения видно, то имеем дело с нормальным распределением, а значит можно оперировать описательными статистиками для формирования выводов.
На этом этап подготовки и проверки данных подошел к концу. Самое скучное позади, теперь перейдем к поиску “интересностей”.
В поисках инсайдов
Начинаем искать ответы на вопросы: “а как ведут себя цены на билеты с течением времени? какие различия в ценообразовании между направлениями? Какая сезонность в модели формирования цен? Какие особенности есть?Весь анализ разбил на четыре раздела:
- Динамика стоимости пакета (медиана и среднее);
- Динамика стоимости 1 км по пакету;
- Динамика цен по дате вылета. Сезонность;
- За сколько дней до вылета оптимальнее всего покупать билеты.
После преобразования данных по каждому пакету есть динамика медианы и среднего, именно эти метрики представлены на визуализации ниже. Добавлю немного расшифровки по полученному результату:
- Синяя линия — это медиана;
- Оранжевая — это среднее;
- Серая заливка — это коридор цен между 1 и 3 квартилем в пакете цен, чтобы обозначить диапазон 50% всех цен в пакете.
plt.figure(figsize=(12, 9))
# визуализация результата, а именно: динамика стоимости пакета (медиана и средняя)
for i in ROUTES.index:
plt.subplot(3, 4, i+1)
df_1tmp = df_agg.loc[df_agg['route'] == ROUTES.iloc[i,1]]
# заливка области между 1 и 3 квартилем
plt.fill_between(df_1tmp['uploaddate'], df_1tmp['q1'], df_1tmp['q2'],
facecolor='r',
alpha = 0.3,
color = 'grey',
linewidth = 2,
linestyle = '--')
# основная часть визуализации
plt.plot(df_1tmp['uploaddate'],df_1tmp['median'],linewidth = 2, label = ROUTES.iloc[i,2])
plt.plot(df_1tmp['uploaddate'],df_1tmp['mean'],linewidth = 1)
plt.legend(fontsize=10, loc='upper center')
plt.xticks(['2021-04-01','2021-06-01','2021-08-01'],['01-apr','01-jun','01-aug'], fontsize=8)
plt.yticks(np.arange(0, 10000+100, 3000), fontsize=8)
plt.ylim([1000, 11000])
plt.grid()
plt.show()
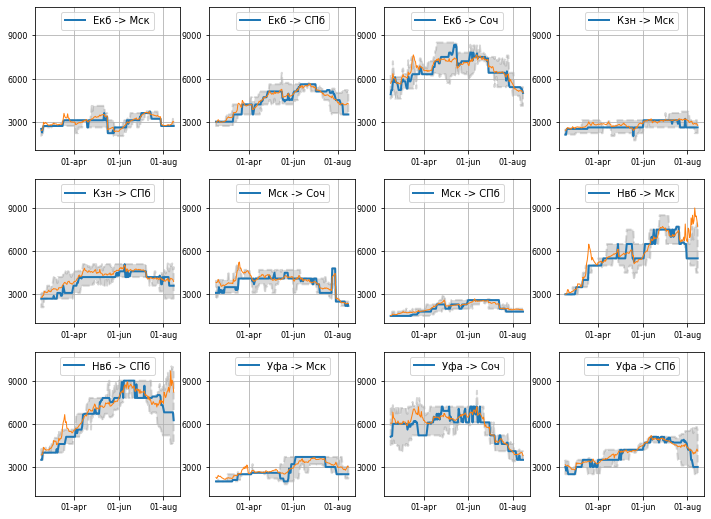
Картина получается весьма интересная: абсолютно разные динамики цен, видимо все направления получились уникальными в каком-то смысле. Но на две группы скорее всего их можно разбить: с выраженной летней сезонности и без нее.
Москва же в свою очередь не является преимущественно туристическим направлением, видимо за счет деловых поездок и за счет выполнения функции хаба. Жить надо в Москве, чтобы не читать подобные статьи
Динамика стоимости 1км по пакету.
Этот пункт не особо связан с ключевым вопросом, но пройти его мимо у меня не получилось, уж больно любопытно стало понять различия показателя по разным направлениям.
Смысл такой: динамика медианы по пакетам делится на расстояние из А в Б.
Код
# мержим датасеты (подтягиваем растояние из А в Б) и считаем стоимость одного км
df_q20 = df_agg.merge(ROUTES, how = 'left', left_on=['route'], right_on=['shot_name'])
df_q20['cost1km'] = df_q20['median'] / df_q20['distance']
df_q20 = df_q20.drop(['id', 'shot_name', 'full_name','route','median','mean','std','q1','q2','distance'], axis=1)
# преобразование даты в текст, чтобы на графике название тиков нормально вывести
df_q20['uploaddate']=df_q20.uploaddate.map(lambda t:t.strftime('%m-%b-%d'))
df_q20 = pd.pivot_table(df_q20, values='cost1km', index=['route_name'], columns=['uploaddate'], aggfunc=np.sum, fill_value=0)
# сортировка по строкам от большего к меньшему
df_q20['sum_cols'] = df_q20.sum(axis=1)
df_q20 = df_q20.sort_values('sum_cols' , ascending=False)
df_q20 = df_q20.drop(['sum_cols'],axis=1)
# визуализация результата
plt.figure(figsize=(12, 5))
sns.heatmap(df_q20, cmap='RdYlGn_r', annot=False)
plt.title('Динамика стоимости 1км')
plt.xlabel('Дата среза')
plt.ylabel('Направления')
plt.show()
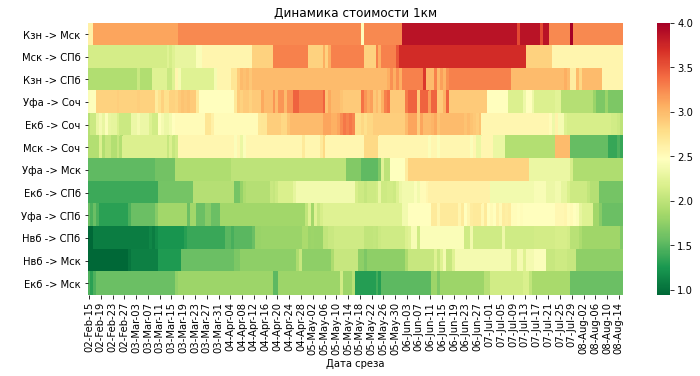
Основной вывод: перелеты по стоимости 1км все разные, причем что зависимости между аэропортом отправки или аэропортами приемниками никакой нет. Так же видно, что разница между самым дорогим километром и самым дешевым достаточно существенна. Если бы получить внутренние данные, то можно было бы понять почему так, но одна из версий, она же самая вероятная — затраты на перелет это всегда соотношение переменных и постоянных расходов, вероятнее всего по ряду направлений постоянные расходы сильно тянут вверх удельную стоимость 1км. Например, Казань — Москва (№1).
Динамика цен по дате вылета. Сезонность.
Не всегда желание улететь варьируется в диапазон дат, часто есть очень узкий диапазон в несколько дней, поэтому надо понять, как же ведут себя цены в конкретные даты вылета.
А именно есть ли ярко выраженная сезонность?
Но так просто нельзя выбрать дату вылета, цены то у нас с глубиной в 60 дней, значит на каждую дату вылета есть всегда 60 цен в зависимости от “а за сколько дней смотреть”. Для примера возьму цены за 15 дней до вылета (забегая вперед скажу, что не важно за сколько дней до вылета смотреть цены, сезонная модель не сильно зависит от длительности дней до вылета; кому особо интересно, можно будет исходник покрутить).
Код
# фильтр датасета на 15ый день до вылета
df_q30 = df_src[df_src['day_bef_dep'] == -15].reset_index()
# Визуализация результата
plt.figure(figsize=(12, 9))
for i in ROUTES.index:
plt.subplot(3, 4, i+1)
df_3tmp = df_q30.loc[df_q30['route'] == ROUTES.iloc[i,1]]
plt.plot(df_3tmp['dep_date'],df_3tmp['price_round'],linewidth = 2, alpha = 0.8, label = ROUTES.iloc[i,2])
plt.legend(fontsize=10, loc='upper center')
plt.xticks(['2021-04-15','2021-06-01','2021-07-15'],['15-apr','01-jun','15-jul'], fontsize=8)
plt.yticks(np.arange(0, 12000+500, 3000), fontsize=8)
plt.ylim([1000, 12500])
plt.grid()
plt.show()
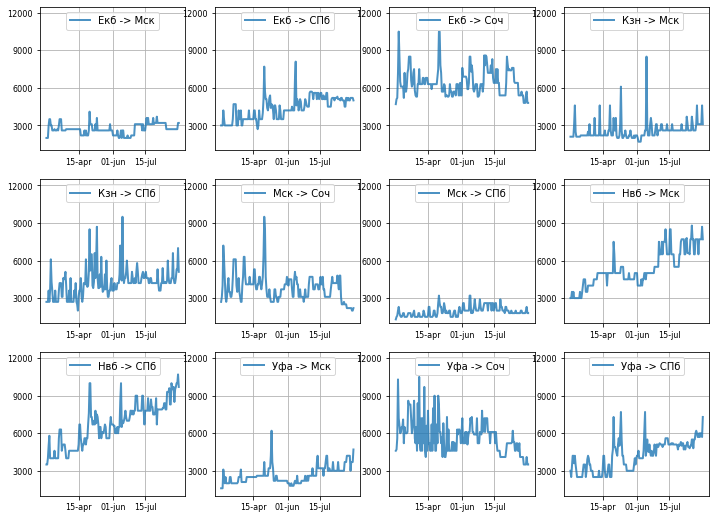
Так и что получилось?
Графики наглядно иллюстрируют, что:
- как и было отмечено ранее направления ведут себя крайне уникально, даже если смотреть под другим углом, есть мысль, что таким образом происходит в том числе корректировка цен на направлениях авиакомпанией;
- есть высокая волатильность внутри коротких диапазонов, т.е. есть недельная сезонность;
- присутствуют флуктуации — если хочешь полететь в длинные выходные(1 , 9 мая или 12 июня, то придется прямо хорошенько добавить к базовой цене).
Код
week_type = pd.Series(['К. сезонности внутринедельный','Неделя 1 Мая','Неделя 9 Мая','Неделя День России'])
# сдвиг +1 к дате вылета по вылетам из Казани, так как вылет ночью и надо уровнять с остальными.
df_q30 = df_src[df_src['day_bef_dep'] == -15].reset_index()
df_q30.loc[(df_q30['route'] == 'KZN -> LED') | (df_q30['route'] == 'KZN -> VKO'), 'dep_date'] += dt.timedelta(days=1)
# разметка недель, чтобы выделить праздничные.
df_q30.loc[(df_q30['dep_date'] >= '2021-04-26') & (df_q30['dep_date'] <= '2021-05-02'), 'wtype'] = week_type[1]
df_q30.loc[(df_q30['dep_date'] >= '2021-05-03') & (df_q30['dep_date'] <= '2021-05-09'), 'wtype'] = week_type[2]
df_q30.loc[(df_q30['dep_date'] >= '2021-06-07') & (df_q30['dep_date'] <= '2021-06-13'), 'wtype'] = week_type[3]
df_q30.wtype = df_q30.wtype.fillna(week_type[0])
# добавляю название дня недели. df_q30 этот кадр за 15 дней до вылета
df_q30['day_of_week'] = df_q30['dep_date'].dt.day_name()
df_q30['day_of_week_number'] = df_q30['dep_date'].dt.dayofweek
df_q30.reset_index()
plt.figure(figsize=(14, 10))
# формирование четырех тепловых карт по сезонности недельной (регулярная и праздничные недели)
for i in week_type.index:
plt.subplot(2, 2, i+1)
df_4tmp = df_q30.loc[df_q30['wtype'] == week_type]
# расчет внутринедельной сезонности
df_q31 = df_4tmp.groupby(["day_of_week", "route_name", "day_of_week_number"]).agg({
"price_round": ["mean"]
}).sort_values(['route_name','day_of_week_number'], ascending=True).reset_index()
df_q31.columns = ["day_of_week","route_name", "day_of_week_number", "price_round"]
df_q32 = df_4tmp.groupby(["route_name"]).agg({
"price_round": ["mean"]
}).sort_values(['route_name'], ascending=True).reset_index()
df_q32.columns = ["route_name", "price_round_mean"]
df_q33 = df_q31.merge(df_q32, how = 'left', left_on=['route_name'], right_on=['route_name'])
df_q33['seasonality'] = df_q33['price_round'] / df_q33['price_round_mean']
df_q33 = pd.pivot_table(df_q33, values='seasonality', index=['route_name'], columns=['day_of_week_number','day_of_week'], aggfunc=np.mean, fill_value=0)
df_q33.columns = ["Mon", "Tue", "Wed", "Thu", "Fri", "Sat", "Sun"]
# визуализация результата
sns.heatmap(df_q33, cmap='RdYlGn_r', annot=True, fmt ='.2g', vmin=0.8, vmax=1.2, center= 1, cbar=True)
plt.title(week_type)
plt.show()
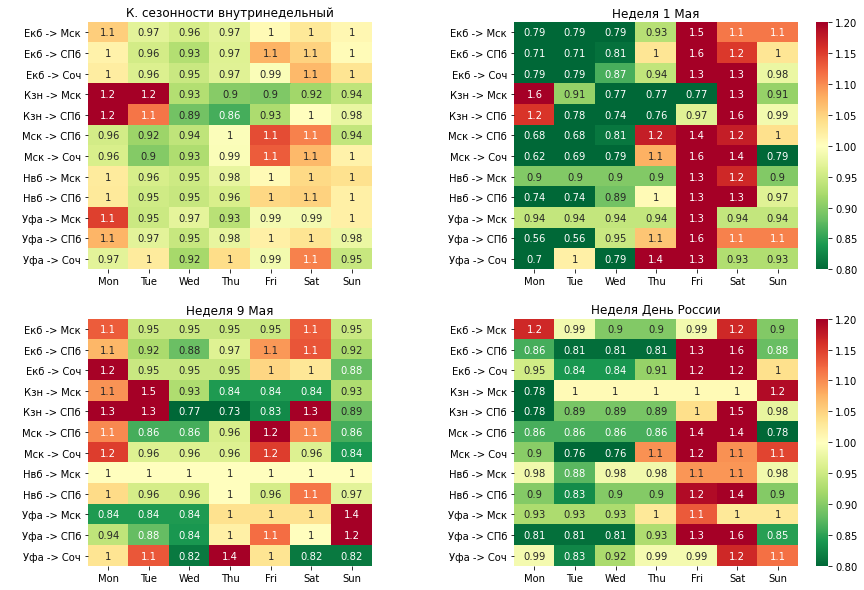
По итогу можно отметить следующее:
- есть явная недельная сезонность в стандартных неделях (без праздников), а именно улететь в точки Б в пятницу и субботу будет стоить дороже, чем в остальные дни; кроме двух направлений — это Казань—Москва и Казань—Санкт-Петербург, эти два направления почему-то дороже всего в понедельник и во вторник. Почему так — дискуссионный вопрос;
- далее хочется отметить, что изменение цен на вылет под праздники самый значительный, в особенности первомайские праздники и День России, а вот День Победы не совсем явная флуктуация, видимо основной спрос приходится на 1 Мая и плавно растягивается на неделю.
Для ответа на этот вопрос представлю тепловую карту. В качестве значений будет отклонение вверх и вниз от медианного значения в пакете.
Код
# формирование df_q40 - отклонение от медианного значения
# глубина данных слегка подфильтрована, а то если присутсвует корректировка модели
# ценообразования, то этот фактор испортит данные
df_q40 = df_src[df_src['uploaddate'] >= '2021-04-01'].reset_index()
df_q40 = pd.pivot_table(df_q40, values='price_round', index=['day_bef_dep'], columns=['route_name'], aggfunc=np.mean, fill_value=0)
df_q40 = (df_q40/df_q40.median(axis=0)-1).T
# визуализация результата
plt.figure(figsize=(12, 5))
sns.heatmap(df_q40, cmap='RdYlGn_r', annot=False,vmin=-0.2, vmax=0.2, center= 0)
plt.title('Лучшее время покупки билетов')
plt.xlabel('Дней до вылета')
plt.ylabel('Направления')
plt.show()
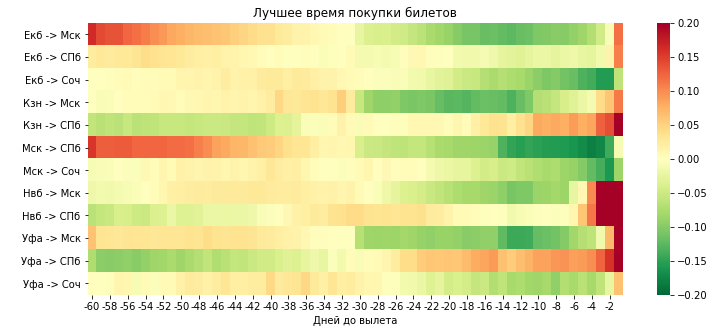
Интересно получается: выходит, что покупать билет заранее вроде как и нет смысла, более того по ряду направлений “заранее” стоит дороже, чем если купить за 15-30 дней до вылета. Ну и конечно не надо покупать билеты за 1-5 дней до вылета, это с большей долей вероятности обернется серьезной переплатой.
На этом все!
Еще раз перечислю основные выводы, которые отвечают на базовый вопрос:- единственного ответа на вопрос ценообразования нет, каждое направление ведет себя уникально;
- ряд направлений обладают летней сезонностью, что в принципе очевидно для всех, но все равно отмечу;
- если есть определенная дата вылета, то надо понимать, что в соседние даты цены могут сильно отличаться, потому что присутствует внутринедельная сезонность;
- вылет под длинные праздники — это всегда сильно дороже, надо запомнить это правило;
- лучшее время для покупки — это отдельные размышления, потому что правило сильно заранее — это не всегда сильно дешевле, но и за несколько дней до вылета лучше не мечтать об удачном приобретении.
P.S. если не надоест собирать цены, то через год будет вторая версия, где можно будет еще зацепить тему изменения цен год к году.

В шоке от цен на авиабилеты по России: как летать дешевле
Вы продаете билетов на самолеты? - Нет, только показываю. - Красивое… Люди делятся на два типа: одни летают за тысячу рублей из Питера во Владивосток, другие сутками скрупулезно высчитывают маршруты...
 habr.com
habr.com