* Статья предназначена для молодых инженеров-исследователей, не знающих – где взять данные для проведения исследований в области машинного обучения.
Доброго времени суток!
Меня зовут Дмитрий.
Я инженер-программист в области автоматизации технологических процессов. Работаю в проектной компании и параллельно обучаюсь в аспирантуре, пишу диссертацию.
В общем случае, я бы описал машинное обучение как некий универсальный подход к численному моделированию тех или иных явлений окружающего мира (как общественных: рынок, демография и пр.; так и физических: движение автомобиля, управление аппаратами…)
Поделюсь также своим опытом инженера-исследователя. Сам не раз наблюдал на производствах Пермского края внедрение алгоритмов и моделей на базе ML при решении задач:
Также не факт, что получится по итогу исследования объекта сформировать добрый датасет. Базы данных на производствах не бесперебойно работают, пакеты данных теряются, ломаются, некоторые требуемые параметры не архивируются и т.д.
Все, кажется, так грустно для инженера-исследователя. Особенно если общаться с IT-шниками в области ML, которых данными снабжают целые отделы или отдельные компании.

И грустить бы мне до конца дней моих. Но пару месяцев назад, благодаря своему научному руководителю, я познакомился с одной свежей диссертацией на тему разработки алгоритмов кластеризации. В ней автор валидировал свои алгоритмы на открытых данных UCI, совершенно не заморачиваясь исследованием объекта и формированием датасетов.
Правда, тема была не совсем производственная, но инструмент очень удобен! Один клик – и у тебя набор данных для исследования своих алгоритмов ML.
Общаясь с товарищами по учебе, коллегами, я все больше убеждался в том, что проблема данных распространена среди инженеров-исследователей. В конце концов, появлялись мысли: а не собрать ли нам самим набор датасетов производственных процессов? Но эта тема пока требует дальнейших размышлений.
Для этого нужно определить ряд требований к датасетам и решить технические вопросы по организации открытой базы данных. Если тебе есть что сказать по этому поводу – пиши в комментариях.
Оговорюсь заранее: любой датасет так или иначе вполне вероятно будет содержать ошибки (пропуски данных, аномальные выбросы и пр.) Все эти ошибки обусловлены несовершенством алгоритмов сбора данных и ошибками человека при формировании датасета. Будьте к этому готовы.
Начал свой обзор я, конечно же, на просторах русскоязычных сайтов. Но ничего там пока не выросло в этой области. На англоязычных источниках обнаружился ряд наиболее близких к производственной теме датасетов:
На форумах пишут, что описание особо популярных датасетов выкладывают даже на wiki. В попытке облегчить задачу интерпретации выбранных мною данных воспользовался поиском Google. Google нашел кое-что получше wiki (в научном плане).
Существует Google сервис поиска датасетов, который итегрирован с сервисом Google Scholar.

Соответственно, можно посмотреть все научные статьи, цитирующие указанный датасет. В научных статьях авторы обычно максимально достоверно и лаконично описывают используемые источники.
В качестве подсказки использовал работу трудолюбивых китайцев:
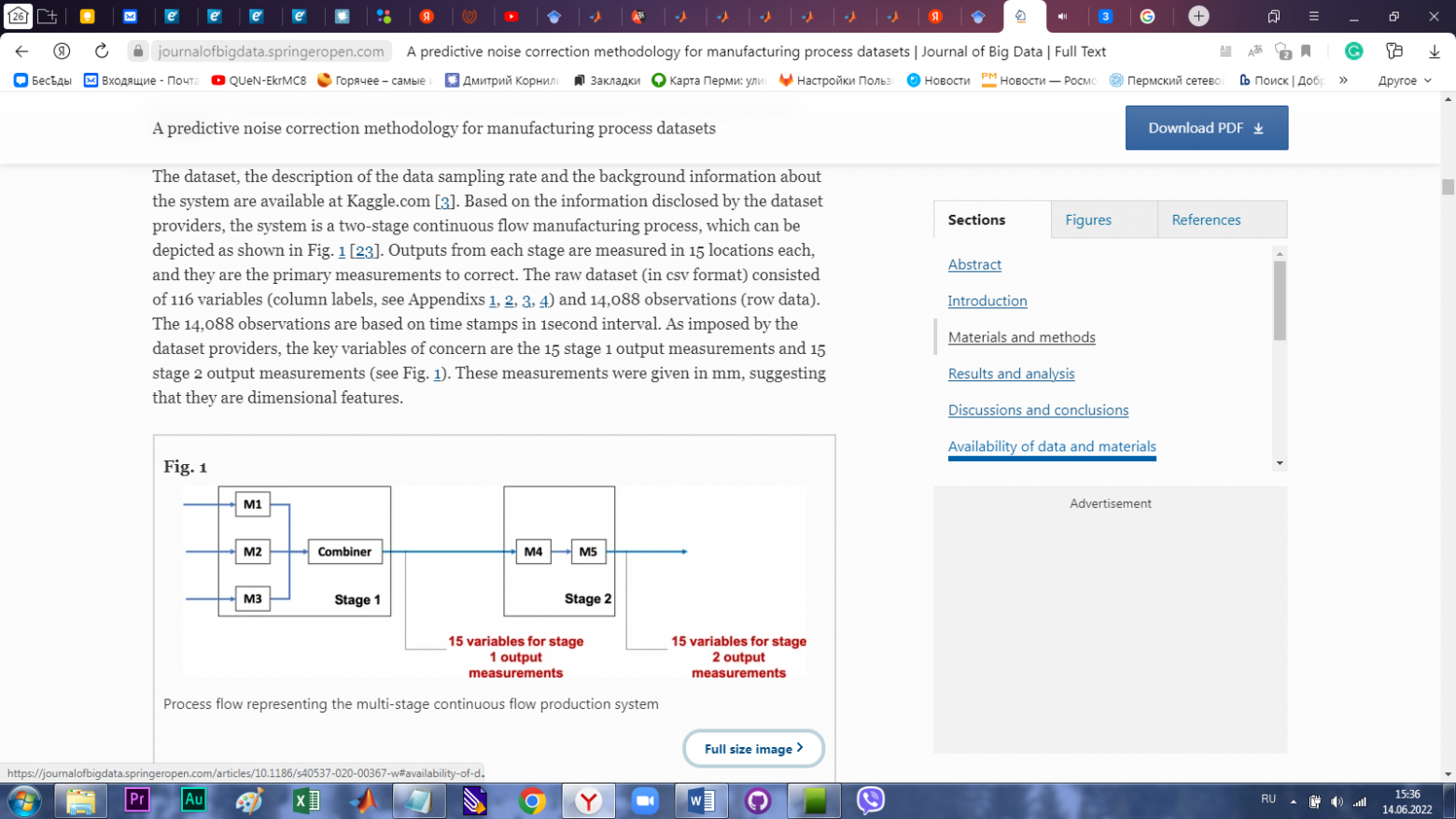
Чудо! Целый абзац описания сути датасета с визуализацией производственного процесса.

 habr.com
habr.com
Доброго времени суток!
Меня зовут Дмитрий.
Я инженер-программист в области автоматизации технологических процессов. Работаю в проектной компании и параллельно обучаюсь в аспирантуре, пишу диссертацию.
Введение
Машинное обучение (ML) сейчас является темой множества разговоров. Статьи о машинном обучении делятся на два типа: это либо фундаментальные тома с формулами и теоремами, которые больше похожи на китайские трактаты. Или сказки о супер способностях искусственного интеллекта.В общем случае, я бы описал машинное обучение как некий универсальный подход к численному моделированию тех или иных явлений окружающего мира (как общественных: рынок, демография и пр.; так и физических: движение автомобиля, управление аппаратами…)
Машинное обучение в производстве
Машинное обучение сегодня активно применяется в различных областях. Для понимания, содержательный обзор задач, решаемых ML: https://habr.com/ru/company/vk/blog/462769/Поделюсь также своим опытом инженера-исследователя. Сам не раз наблюдал на производствах Пермского края внедрение алгоритмов и моделей на базе ML при решении задач:
- Оптимизации показателей качества технологических процессов;
- Предиктивной диагностики состояния оборудования;
- Анализа состояния технологического процесса с помощью машинного зрения;
- Виртуального измерения показателей качества технологического процесса;
- И т.д.
Проблема: алгоритмов куча – данных мало
Значительную часть усилий инженер-исследователь в своей деятельности тратит на то, чтобы добыть данные с объекта исследования. В случае с производственным процессом это:- Организация программы исследования объекта производства;
- Поездка на объект, опрос персонала;
- Формирование набора требуемых для проведения исследований технологических параметров;
- Запрос датасетов;
- Обработка данных.
Также не факт, что получится по итогу исследования объекта сформировать добрый датасет. Базы данных на производствах не бесперебойно работают, пакеты данных теряются, ломаются, некоторые требуемые параметры не архивируются и т.д.
Все, кажется, так грустно для инженера-исследователя. Особенно если общаться с IT-шниками в области ML, которых данными снабжают целые отделы или отдельные компании.
И грустить бы мне до конца дней моих. Но пару месяцев назад, благодаря своему научному руководителю, я познакомился с одной свежей диссертацией на тему разработки алгоритмов кластеризации. В ней автор валидировал свои алгоритмы на открытых данных UCI, совершенно не заморачиваясь исследованием объекта и формированием датасетов.
Правда, тема была не совсем производственная, но инструмент очень удобен! Один клик – и у тебя набор данных для исследования своих алгоритмов ML.
Общаясь с товарищами по учебе, коллегами, я все больше убеждался в том, что проблема данных распространена среди инженеров-исследователей. В конце концов, появлялись мысли: а не собрать ли нам самим набор датасетов производственных процессов? Но эта тема пока требует дальнейших размышлений.
Для этого нужно определить ряд требований к датасетам и решить технические вопросы по организации открытой базы данных. Если тебе есть что сказать по этому поводу – пиши в комментариях.
Открытые базы данных?
Открытые базы данных – это наборы данных, собранных исследователями со всего мира. Стоит отметить, что набор данных – это не просто мешанина чисел и значений сигналов исследуемого явления. Это набор данных с содержательным описанием того, что и в каких условиях измерялось.Оговорюсь заранее: любой датасет так или иначе вполне вероятно будет содержать ошибки (пропуски данных, аномальные выбросы и пр.) Все эти ошибки обусловлены несовершенством алгоритмов сбора данных и ошибками человека при формировании датасета. Будьте к этому готовы.
Результаты обзора датасетов производственных процессов
Чтобы валидировать алгоритмы ML, инженеру-исследователю нужны более-менее независимые датасеты технологических процессов на производстве.Начал свой обзор я, конечно же, на просторах русскоязычных сайтов. Но ничего там пока не выросло в этой области. На англоязычных источниках обнаружился ряд наиболее близких к производственной теме датасетов:
- Флотационный процесс переработки руды.
- Работа парогазовой турбины.
- Набор данных о процессе производства полупроводников.
- Набор данных процесса добычи полезных ископаемых.
- Data.gov.com - сайт с датасетами различных производств США. Однако, чтобы им пользоваться на территории РФ, нужно использовать VPN. Значит, он не совсем открытый В исследованиях не получится сослаться.
- Data gov.in – открытый сайт с датасетами различных производств Индии. Но датасетов меньше чем в США и качество данных хуже.
- Сайт bigml.com содержит ряд датасетов на близкие к производствам темы.
- И ряд производственных датасетов.
Пример использования датасета
На Kaggle приводится описание датасетов. Рекомендую почаще заглядывать в раздел «Обсуждения» (Discussion) и посмотреть, что пишет о датасете народ, чтобы не изобретать велосипед при предварительной обработке данных.На форумах пишут, что описание особо популярных датасетов выкладывают даже на wiki. В попытке облегчить задачу интерпретации выбранных мною данных воспользовался поиском Google. Google нашел кое-что получше wiki (в научном плане).
Существует Google сервис поиска датасетов, который итегрирован с сервисом Google Scholar.
Соответственно, можно посмотреть все научные статьи, цитирующие указанный датасет. В научных статьях авторы обычно максимально достоверно и лаконично описывают используемые источники.
В качестве подсказки использовал работу трудолюбивых китайцев:
Чудо! Целый абзац описания сути датасета с визуализацией производственного процесса.
Вывод
Я понимаю, что сама идея использования открытых баз данных при обучении моделей машинного обучения – не нова и чего об этом писать? Но в области автоматизации технологических процессов я вижу значительный пробел. Надеюсь, материалы статьи помогут молодому поколению быстрее начать использовать такой удобный инструмент.
Где брать данные инженеру-исследователю?
* Статья предназначена для молодых инженеров-исследователей, не знающих – где взять данные для проведения исследований в области машинного обучения. Доброго времени суток! Меня зовут Дмитрий. Я...
habr.com