Почти все знают, как написать простой драйвер под Linux. На эту тему много материалов в сети. Очень мало информации о том, что находится "под капотом" у процедуры загрузки драйверов. Это мало кому требуется на самом деле. Но автору было интересно, и это стало поводом для написания статьи. Тема достаточно объемная, поэтому в статье рассмотрен только узкий кусочек.
Статья не претендует на академичность и может содержать неточности. Автор исходит из подхода “лучше статья с неточностями сейчас поможет кому-то, чем абсолютно точная статья не поможет никому никогда”. Замечания по существу приветствуются. Обнаруженные неточности будут исправлены.
Гипотетически, все сведения, приведенные в статье, могут быть найдены из открытой документации или аналогичных статей в интернете. На практике, разобраться получилось только с активным ковырянием исходников, и то не до конца.
Лирическое отступление о документации на ядро
Cубъективное мнение автора, не претендующее на истинность.
Автор довольно давно занимается embedded вообще и embedded linux в частности. За все это время по пальцам можно пересчитать случаи, когда чтение документации по ядру само по себе помогло разобраться в чем бы то ни было. Разобраться удавалось в основном путем чтения исходников, экспериментов, раздумий, еще чтения и экспериментов. На этом пути документация была вспомогательной, важной, но не основной ступенькой.
У автора сформировалось стойкое ощущение, что документация на ядро написана для тех людей, которые написанное там уже и так знают, а письменно зафиксировано это исключительно для того, чтоб существовали гайдлайны, описывающие, каких концепций надо придерживаться при разработке новых драйверов и при применении существующих.
Это не хорошо и не плохо, просто документация решает именно эту задачу наилучшим образом, и этот факт желательно учитывать.
Это никоим образом не уменьшает значимость существующей документации и других материалов по ядру, которые возможно найти в интернете. Перечень использованных документов приведен в конце статьи чисто на всякий случай.
Buildroot в данном случае использует ядро версии 4.19.79. Современные версии ядра наверняка имеют отличия в деталях, но общий подход там не менялся.
Процедура сборки и загрузки тривиальна, но на всякий случай задокументируем и ее:
[ 0.268291] OMAP GPIO hardware version 0.1
Настало время пойти в исходники. Далее пути указаны относительно корневой директории с исходниками ядра.
Нас интересует файл init/main.c:
asmlinkage __visible void __init start_kernel(void)
Это, в общем-то, самая главная функция. Но она содержит очень много всего. Если поискать, то окажется, что нас интересует вот это место:
/*
* Ok, the machine is now initialized. None of the devices
* have been touched yet, but the CPU subsystem is up and
* running, and memory and process management works.
*
* Now we can finally start doing some real work..
*/
static void __init do_basic_setup(void)
{
cpuset_init_smp();
shmem_init();
driver_init();
init_irq_proc();
do_ctors();
usermodehelper_enable();
do_initcalls();
}
Если добавить в код немного дополнительных логов (или просто быть очень умным, но это не наш случай), то станет понятно – загрузка драйверов начинается после вызова do_initcalls(). Значит, будем смотреть на нее:
static void __init do_initcalls(void)
{
int level;
for (level = 0; level < ARRAY_SIZE(initcall_levels) - 1; level++)
do_initcall_level(level);
}
static void __init do_initcall_level(int level)
{
initcall_entry_t *fn;
strcpy(initcall_command_line, saved_command_line);
parse_args(initcall_level_names[level],
initcall_command_line, __start___param,
__stop___param - __start___param,
level, level,
NULL, &repair_env_string);
trace_initcall_level(initcall_level_names[level]);
for (fn = initcall_levels[level]; fn < initcall_levels[level+1]; fn++)
do_one_initcall(initcall_from_entry(fn));
}
То есть, у нас есть какой-то массив initcalls, который мы определенным образом перебираем. Он объявлен в этом же файле:
extern initcall_entry_t __initcall_start[];
extern initcall_entry_t __initcall0_start[];
extern initcall_entry_t __initcall1_start[];
extern initcall_entry_t __initcall2_start[];
extern initcall_entry_t __initcall3_start[];
extern initcall_entry_t __initcall4_start[];
extern initcall_entry_t __initcall5_start[];
extern initcall_entry_t __initcall6_start[];
extern initcall_entry_t __initcall7_start[];
extern initcall_entry_t __initcall_end[];
static initcall_entry_t *initcall_levels[] __initdata = {
__initcall0_start,
__initcall1_start,
__initcall2_start,
__initcall3_start,
__initcall4_start,
__initcall5_start,
__initcall6_start,
__initcall7_start,
__initcall_end,
};
/* Keep these in sync with initcalls in include/linux/init.h */
static char *initcall_level_names[] __initdata = {
"pure",
"core",
"postcore",
"arch",
"subsys",
"fs",
"device",
"late",
};
Выглядит как массив указателей на функции, которые мы каким-то сложным образом вызываем. Но откуда эти указатели берутся? Если попробовать поискать в исходниках название типа __initcall0_start, то найдем только это:
arch/arm/kernel/vmlinux.lds:
.init.data : AT(ADDR(.init.data) - 0) { KEEP(*(SORT(___kentry+*))) *(.init.data init.data.*) *(.meminit.data*) *(.init.rodata .init.rodata.*) . = ALIGN(8); __start_ftrace_events = .; KEEP(*(_ftrace_events)) __stop_ftrace_events = .; __start_ftrace_eval_maps = .; KEEP(*(_ftrace_eval_map)) __stop_ftrace_eval_maps = .; . = ALIGN(8); __start_kprobe_blacklist = .; KEEP(*(_kprobe_blacklist)) __stop_kprobe_blacklist = .; *(.meminit.rodata) . = ALIGN(8); __clk_of_table = .; KEEP(*(__clk_of_table)) KEEP(*(__clk_of_table_end)) . = ALIGN(8); __reservedmem_of_table = .; KEEP(*(__reservedmem_of_table)) KEEP(*(__reservedmem_of_table_end)) . = ALIGN(8); __timer_of_table = .; KEEP(*(__timer_of_table)) KEEP(*(__timer_of_table_end)) . = ALIGN(8); __cpu_method_of_table = .; KEEP(*(__cpu_method_of_table)) KEEP(*(__cpu_method_of_table_end)) . = ALIGN(8); __cpuidle_method_of_table = .; KEEP(*(__cpuidle_method_of_table)) KEEP(*(__cpuidle_method_of_table_end)) . = ALIGN(32); __dtb_start = .; KEEP(*(.dtb.init.rodata)) __dtb_end = .; . = ALIGN(8); __irqchip_of_table = .; KEEP(*(__irqchip_of_table)) KEEP(*(__irqchip_of_table_end)) . = ALIGN(8); __earlycon_table = .; KEEP(*(__earlycon_table)) __earlycon_table_end = .; . = ALIGN(16); __setup_start = .; KEEP(*(.init.setup)) __setup_end = .; __initcall_start = .; KEEP(*(.initcallearly.init)) __initcall0_start = .; KEEP(*(.initcall0.init)) KEEP(*(.initcall0s.init)) __initcall1_start = .; KEEP(*(.initcall1.init)) KEEP(*(.initcall1s.init)) __initcall2_start = .; KEEP(*(.initcall2.init)) KEEP(*(.initcall2s.init)) __initcall3_start = .; KEEP(*(.initcall3.init)) KEEP(*(.initcall3s.init)) __initcall4_start = .; KEEP(*(.initcall4.init)) KEEP(*(.initcall4s.init)) __initcall5_start = .; KEEP(*(.initcall5.init)) KEEP(*(.initcall5s.init)) __initcallrootfs_start = .; KEEP(*(.initcallrootfs.init)) KEEP(*(.initcallrootfss.init)) __initcall6_start = .; KEEP(*(.initcall6.init)) KEEP(*(.initcall6s.init)) __initcall7_start = .; KEEP(*(.initcall7.init)) KEEP(*(.initcall7s.init)) __initcall_end = .; __con_initcall_start = .; KEEP(*(.con_initcall.init)) __con_initcall_end = .; __security_initcall_start = .; KEEP(*(.security_initcall.init)) __security_initcall_end = .; . = ALIGN(4); __initramfs_start = .; KEEP(*(.init.ramfs)) . = ALIGN(8); KEEP(*(.init.ramfs.info)) }
То есть, мы выделяем место под этот массив в скрипте линковки, но как мы этот массив заполняем – непонятно.
Ок, тогда возвращаемся к комментарию, который отсылает нас в include/linux/init.h:
#define core_initcall(fn) __define_initcall(fn, 1)
#define core_initcall_sync(fn) __define_initcall(fn, 1s)
#define postcore_initcall(fn) __define_initcall(fn, 2)
#define postcore_initcall_sync(fn) __define_initcall(fn, 2s)
#define arch_initcall(fn) __define_initcall(fn, 3)
#define arch_initcall_sync(fn) __define_initcall(fn, 3s)
#define subsys_initcall(fn) __define_initcall(fn, 4)
#define subsys_initcall_sync(fn) __define_initcall(fn, 4s)
#define fs_initcall(fn) __define_initcall(fn, 5)
#define fs_initcall_sync(fn) __define_initcall(fn, 5s)
#define rootfs_initcall(fn) __define_initcall(fn, rootfs)
#define device_initcall(fn) __define_initcall(fn, 6)
#define device_initcall_sync(fn) __define_initcall(fn, 6s)
#define late_initcall(fn) __define_initcall(fn, 7)
#define late_initcall_sync(fn) __define_initcall(fn, 7s)
#define __initcall(fn) device_initcall(fn)
А чуть выше в этом же файле:
#ifdef CONFIG_HAVE_ARCH_PREL32_RELOCATIONS
#define ___define_initcall(fn, id, __sec) \
__ADDRESSABLE(fn) \
asm(".section \"" #__sec ".init\", \"a\" \n" \
"__initcall_" #fn #id ": \n" \
".long " #fn " - . \n" \
".previous \n");
#else
#define ___define_initcall(fn, id, __sec) \
static initcall_t __initcall_##fn##id __used \
__attribute__((__section__(#__sec ".init"))) = fn;
#endif
#define __define_initcall(fn, id) ___define_initcall(fn, id, .initcall##id)
Это очень важное место. Если поискать по исходникам штуки типа device_initcall – станет понятно, что именно они скрываются в большинстве драйверов под капотом таких дефайнов, как builtin_driver. Собственно, и сам этот дефайн используется во многих драйверах. А кое-где и более старый __initcall.
То есть, иными словами, инициализирующую функцию каждого драйвера система добавляет в список initcall-ов, и дергает ее при загрузке. Именно эта функция регистрирует драйвер в системе.
На этом можно закончить рассмотрение механизма initcalls в контексте данной статьи. Просто потому что его участие в теме загрузки драйверов на этом заканчивается. Меж тем, сам по себе механизм достаточно интересен. Он подробно рассмотрен здесь: https://proninyaroslav.gitbooks.io/linux-insides-ru/content/Concepts/linux-cpu-3.html
Отдельно стоит рассмотреть дефайн module_init. Вот как он определен в kernel/module.h:
#ifndef MODULE
/**
* module_init() - driver initialization entry point
* @x: function to be run at kernel boot time or module insertion
*
* module_init() will either be called during do_initcalls() (if
* builtin) or at module insertion time (if a module). There can only
* be one per module.
*/
#define module_init(x) __initcall(x);
/**
* module_exit() - driver exit entry point
* @x: function to be run when driver is removed
*
* module_exit() will wrap the driver clean-up code
* with cleanup_module() when used with rmmod when
* the driver is a module. If the driver is statically
* compiled into the kernel, module_exit() has no effect.
* There can only be one per module.
*/
#define module_exit(x) __exitcall(x);
#else /* MODULE */
/*
* In most cases loadable modules do not need custom
* initcall levels. There are still some valid cases where
* a driver may be needed early if built in, and does not
* matter when built as a loadable module. Like bus
* snooping debug drivers.
*/
#define early_initcall(fn) module_init(fn)
#define core_initcall(fn) module_init(fn)
#define core_initcall_sync(fn) module_init(fn)
#define postcore_initcall(fn) module_init(fn)
#define postcore_initcall_sync(fn) module_init(fn)
#define arch_initcall(fn) module_init(fn)
#define subsys_initcall(fn) module_init(fn)
#define subsys_initcall_sync(fn) module_init(fn)
#define fs_initcall(fn) module_init(fn)
#define fs_initcall_sync(fn) module_init(fn)
#define rootfs_initcall(fn) module_init(fn)
#define device_initcall(fn) module_init(fn)
#define device_initcall_sync(fn) module_init(fn)
#define late_initcall(fn) module_init(fn)
#define late_initcall_sync(fn) module_init(fn)
#define console_initcall(fn) module_init(fn)
#define security_initcall(fn) module_init(fn)
/* Each module must use one module_init(). */
#define module_init(initfn) \
static inline initcall_t __maybe_unused __inittest(void) \
{ return initfn; } \
int init_module(void) __copy(initfn) __attribute__((alias(#initfn)));
/* This is only required if you want to be unloadable. */
#define module_exit(exitfn) \
static inline exitcall_t __maybe_unused __exittest(void) \
{ return exitfn; } \
void cleanup_module(void) __copy(exitfn) __attribute__((alias(#exitfn)));
#endif
То есть, если мы собираем этот файл как внешний модуль (файл .ko) – у нас определен дефайн MODULE, и в массив initcalls наша функция не попадает. Функция init_module() вызывается при загрузке модуля (об этом чуть подробнее рассказано ниже). А вот если мы собираем этот файл как встроенный в ядро – дефайн MODULE не определен, и его функция init попадает в initcalls.
Пруф про MODULE
Утверждение про дефайн MODULE было не совсем очевидно из исходников. Самым дешевым способом проверить оказалось добавление в драйвер EEPROM AT24 таких строк:
#ifdef MODULE
printk("%s: module built with MODULE define\n", __func__);
#else
printk("%s: module built without MODULE define\n", __func__);
#endif
И, конечно, дальнейшая пересборка ядра в двух вариантах – с этим драйвером, вкомпилированным в ядро, и собранным как отдельный модуль. Что в конечном счете и подтвердило предположение.
busybox/modutils/insmod.c:
rc = bb_init_module(filename, parse_cmdline_module_options(argv, /*quote_spaces:*/ 0));
busybox/modutils/modutils.c:
int FAST_FUNC bb_init_module(const char *filename, const char *options)
{
…
/*
* First we try finit_module if available. Some kernels are configured
* to only allow loading of modules off of secure storage (like a read-
* only rootfs) which needs the finit_module call. If it fails, we fall
* back to normal module loading to support compressed modules.
*/
# ifdef __NR_finit_module
{
int fd = open(filename, O_RDONLY | O_CLOEXEC);
if (fd >= 0) {
rc = finit_module(fd, options, 0) != 0;
close(fd);
if (rc == 0)
return rc;
}
}
# endif
image_size = INT_MAX - 4095;
mmaped = 0;
image = try_to_mmap_module(filename, &image_size);
if (image) {
mmaped = 1;
} else {
errno = ENOMEM; /* may be changed by e.g. open errors below */
image = xmalloc_open_zipped_read_close(filename, &image_size);
if (!image)
return -errno;
}
errno = 0;
init_module(image, image_size, options);
Если пересказать коротко – код сводится к тому, что если ядро поддерживает системный вызов finit_module, то мы просто откроем файл, и дернем этот вызов, передав ему дескриптор файла. А если не поддерживает – то мы загрузим модуль в память, и дернем системный вызов init_module, передав ему указатель на начало образа в памяти.
Так или иначе, мы перейдем в файл ядра kernel/module.c. В зависимости от того, по какой ветке пойдет код выше, мы окажемся или тут:
SYSCALL_DEFINE3(finit_module, int, fd, const char __user *, uargs, int, flags)
{
struct load_info info = { };
loff_t size;
void *hdr;
int err;
err = may_init_module();
if (err)
return err;
pr_debug("finit_module: fd=%d, uargs=%p, flags=%i\n", fd, uargs, flags);
if (flags & ~(MODULE_INIT_IGNORE_MODVERSIONS
|MODULE_INIT_IGNORE_VERMAGIC))
return -EINVAL;
err = kernel_read_file_from_fd(fd, &hdr, &size, INT_MAX,
READING_MODULE);
if (err)
return err;
info.hdr = hdr;
info.len = size;
return load_module(&info, uargs, flags);
}
Или тут:
SYSCALL_DEFINE3(init_module, void __user *, umod,
unsigned long, len, const char __user *, uargs)
{
int err;
struct load_info info = { };
err = may_init_module();
if (err)
return err;
pr_debug("init_module: umod=%p, len=%lu, uargs=%p\n",
umod, len, uargs);
err = copy_module_from_user(umod, len, &info);
if (err)
return err;
return load_module(&info, uargs, 0);
}
Что характерно, в обоих случаях мы придем в итоге в функцию load_module(). В этой функции проводится очень много проверок и подготовок, но в итоге, если все хорошо, мы приходим вот к этому вызову:
return do_init_module(mod);
В свою очередь, функция do_init_module() сводится к обертке вокруг вот этих действий:
/* Start the module */
if (mod->init != NULL)
ret = do_one_initcall(mod->init);
if (ret < 0) {
goto fail_free_freeinit;
Иными словами, мы точно так же дергаем initcall, просто он в данном случае не встроен в цепочку тех initcall-ов, которые выполняются при инициализации системы.
Современная концепция драйверов в linux предполагает, что у платформы, на которой мы исполняемся, есть некоторый набор шин, и каждое из подключенных устройств – является экземпляром устройства на одной из шин. Примерно так:
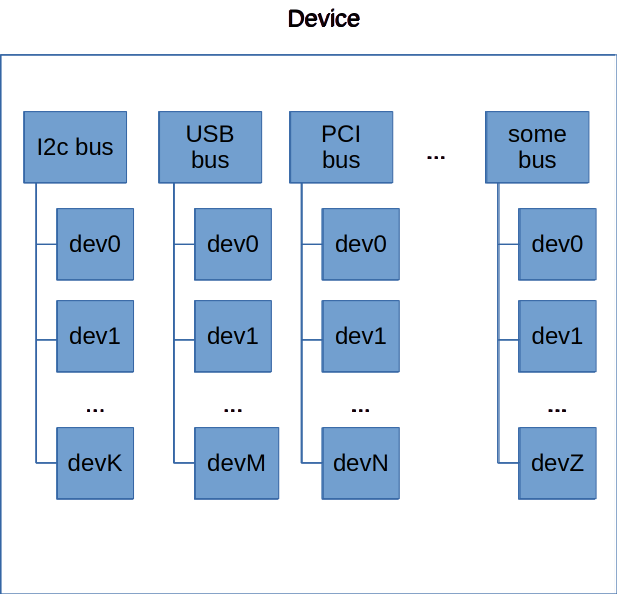
Как мы уже говорили выше, функция инициализации каждого драйвера регистрирует этот драйвер в системе. Теперь, если мы вернемся в функцию инициализации какого-нибудь драйвера, мы обнаружим там, что для регистрации драйвера мы создаем экземпляр структуры, содержащий в себе не только указатели на функции, но также и структуру с признаками конкретного устройства.
Например, для I2C-устройства мы можем обратиться к драйверу EEPROM AT24:
drivers/misc/eeprom/at24.c:
Регистрируем драйвер:
return i2c_add_driver(&at24_driver)
А вот структура:
static struct i2c_driver at24_driver = {
.driver = {
.name = "at24",
.of_match_table = at24_of_match,
.acpi_match_table = ACPI_PTR(at24_acpi_ids),
},
.probe_new = at24_probe,
.remove = at24_remove,
.id_table = at24_ids,
};
А вот и признак, например, для поиска девайса в device tree:
static const struct of_device_id at24_of_match[] = {
{ .compatible = "atmel,24c00", .data = &at24_data_24c00 },
{ .compatible = "atmel,24c01", .data = &at24_data_24c01 },
...
{ /* END OF LIST */ },
};
Примерно аналогично дела обстоят с устройствами на других шинах. Вот, например, драйвер Wifi-модуля RTL8xxxu:
drivers/net/wireless/realtek/rtl8xxxu/rtl8xxxu_core.c:
static int __init rtl8xxxu_module_init(void)
{
int res;
res = usb_register(&rtl8xxxu_driver);
if (res < 0)
pr_err(DRIVER_NAME ": usb_register() failed (%i)\n", res);
return res;
}
Вот структура, описывающая драйвер:
static struct usb_driver rtl8xxxu_driver = {
.name = DRIVER_NAME,
.probe = rtl8xxxu_probe,
.disconnect = rtl8xxxu_disconnect,
.id_table = dev_table,
.no_dynamic_id = 1,
.disable_hub_initiated_lpm = 1,
};
А вот и признаки поддерживаемых драйвером устройств:
static const struct usb_device_id dev_table[] = {
{USB_DEVICE_AND_INTERFACE_INFO(USB_VENDOR_ID_REALTEK, 0x8724, 0xff, 0xff, 0xff),
.driver_info = (unsigned long)&rtl8723au_fops},
{USB_DEVICE_AND_INTERFACE_INFO(USB_VENDOR_ID_REALTEK, 0x1724, 0xff, 0xff, 0xff),
.driver_info = (unsigned long)&rtl8723au_fops},
…
Видно, что здесь для идентификации устройства используются ID на шине, а не записи в Device Tree. Но сам факт наличия механизма остается неизменным.
То есть, ретроспективно, логика инициализации драйвера может пойти двумя путями:
1) Если в системе регистрируется новый драйвер.
- вызывается функция int bus_add_driver(struct device_driver *drv) из drivers/base/bus.c. Она сводится к:
if (driver_allows_async_probing(drv)) {
pr_debug("bus: '%s': probing driver %s asynchronously\n",
drv->bus->name, drv->name);
async_schedule(driver_attach_async, drv);
} else {
error = driver_attach(drv);
if (error)
goto out_unregister;
}
- функция driver_attach_async() сводится к вызову driver_attach():
static void driver_attach_async(void *_drv, async_cookie_t cookie)
{
struct device_driver *drv = _drv;
int ret;
ret = driver_attach(drv);
pr_debug("bus: '%s': driver %s async attach completed: %d\n",
drv->bus->name, drv->name, ret);
}
- функция driver_attach() перебирает каждое из устройств и “примеряет” его к новому драйверу:
/**
* driver_attach - try to bind driver to devices.
* @drv: driver.
*
* Walk the list of devices that the bus has on it and try to
* match the driver with each one. If driver_probe_device()
* returns 0 and the @dev->driver is set, we've found a
* compatible pair.
*/
int driver_attach(struct device_driver *drv)
{
return bus_for_each_dev(drv->bus, NULL, drv, __driver_attach);
}
EXPORT_SYMBOL_GPL(driver_attach);
- сама “примерка” происходит в функции __driver_attach() и сводится к вызову:
ret = driver_match_device(drv, dev);
- функция driver_match_device() имеет свою имплементацию для каждой шины:
drivers/base/base.h:
static inline int driver_match_device(struct device_driver *drv,
struct device *dev)
{
return drv->bus->match ? drv->bus->match(dev, drv) : 1;
}
2) Если на шине появляется устройство. Это может быть физическое событие, например, прерывание от PCI/USB/etc, а может быть просто очередная найденная запись device tree.
- вызывается функция из drivers/base/core.c (кстати, здесь же генерится uevent):
int device_add(struct device *dev)
{
…
kobject_uevent(&dev->kobj, KOBJ_ADD);
bus_probe_device(dev);
- вот что делает bus_probe_device():
/**
* bus_probe_device - probe drivers for a new device
* @dev: device to probe
*
* - Automatically probe for a driver if the bus allows it.
*/
void bus_probe_device(struct device *dev)
{
struct bus_type *bus = dev->bus;
struct subsys_interface *sif;
if (!bus)
return;
if (bus->p->drivers_autoprobe)
device_initial_probe(dev);
- drivers/base/dd.c:
void device_initial_probe(struct device *dev)
{
__device_attach(dev, true);
}
- а уже под капотом этой функции “примерка” драйвера к каждому из зарегистрированных устройств:
static int __device_attach(struct device *dev, bool allow_async)
{
...
ret = bus_for_each_drv(dev->bus, NULL, &data,
__device_attach_driver);
Все это в документации на ядро описано достаточно лаконично здесь, и по-настоящему становится понятно после ознакомления с соответствующим кодом:
“Платформенный драйвер” (platform driver) – драйвер устройства уровня “контроллер шины I2C” или “контроллер шины PCI”, или многих других общепринятых шин. Если смотреть на аппаратную составляющую – то как правило, эти контроллеры – это IP-блок микросхемы, подключенный по шине AXI или подобной. Эти шины, как правило, для программиста не видны, и нет необходимости (и возможности) учитывать в коде их существование. Кроме того, устройства на этой шине никак не могут объявить о своем подключении.
Для таких устройств в ядре есть сущность platform_driver.
Вероятно, будет не слишком большим отклонением от истины сказать, что platform в данном случае – это “виртуальная” шина, к которой подключены другие контроллеры шин. То есть, структурная схема начинает выглядеть примерно так:
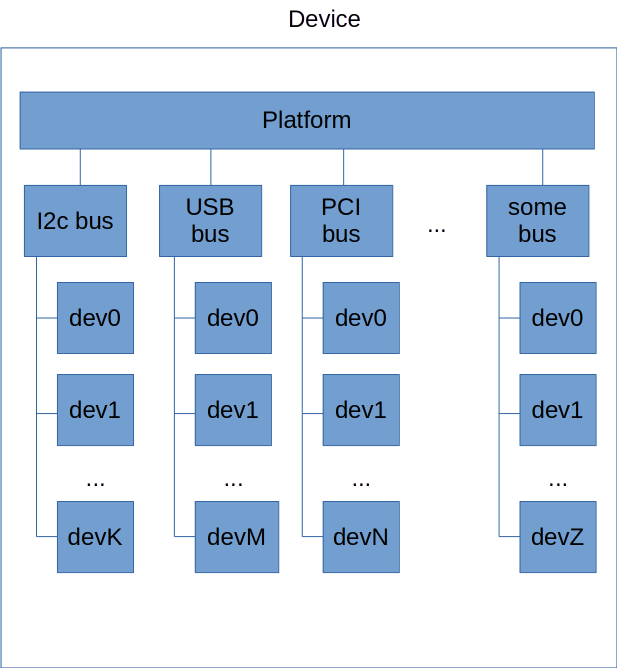
Если заглянуть в драйверы контроллеров того же I2C, можно увидеть, что там при инициализации чаще всего используется именно platform_driver_register().
За рамками рассмотрения остались механизмы, обеспечивающие обнаружение новых устройств (будь то физическое подключение или обнаружение записи в Device Tree), а также механизмы, обеспечивающие автоматическую загрузку соответствующих модулей ядра.
Также в рассмотрение не попали тонкости и коллизии описанного процесса, которых в нем, как и во всей операционной системе, хватает.
Рассмотрение других интересных "подкапотных" вещей запланировано в новых статьях. Остается надеяться, что их реализации ничто не воспрепятствует.
 habr.com
habr.com
Статья не претендует на академичность и может содержать неточности. Автор исходит из подхода “лучше статья с неточностями сейчас поможет кому-то, чем абсолютно точная статья не поможет никому никогда”. Замечания по существу приветствуются. Обнаруженные неточности будут исправлены.
Гипотетически, все сведения, приведенные в статье, могут быть найдены из открытой документации или аналогичных статей в интернете. На практике, разобраться получилось только с активным ковырянием исходников, и то не до конца.
Лирическое отступление о документации на ядро
Cубъективное мнение автора, не претендующее на истинность.
Автор довольно давно занимается embedded вообще и embedded linux в частности. За все это время по пальцам можно пересчитать случаи, когда чтение документации по ядру само по себе помогло разобраться в чем бы то ни было. Разобраться удавалось в основном путем чтения исходников, экспериментов, раздумий, еще чтения и экспериментов. На этом пути документация была вспомогательной, важной, но не основной ступенькой.
У автора сформировалось стойкое ощущение, что документация на ядро написана для тех людей, которые написанное там уже и так знают, а письменно зафиксировано это исключительно для того, чтоб существовали гайдлайны, описывающие, каких концепций надо придерживаться при разработке новых драйверов и при применении существующих.
Это не хорошо и не плохо, просто документация решает именно эту задачу наилучшим образом, и этот факт желательно учитывать.
Это никоим образом не уменьшает значимость существующей документации и других материалов по ядру, которые возможно найти в интернете. Перечень использованных документов приведен в конце статьи чисто на всякий случай.
Сетап для исследования
Мы использовали плату BeagleBone Black и Buildroot 2021.02. В этом сетапе нет ничего сакрального, это просто то, что было под рукой и с чем более-менее привычно работать автору.Buildroot в данном случае использует ядро версии 4.19.79. Современные версии ядра наверняка имеют отличия в деталях, но общий подход там не менялся.
Процедура сборки и загрузки тривиальна, но на всякий случай задокументируем и ее:
- распаковываем/выкачиваем Buildroot в подходящую нам директорию;
- переходим в консоли в эту директорию;
- собираем образ:
make beaglebone_defconfig
make linux-rebuild # если что-то меняли в ядре
make - переходим в директорию output/images, вставляем SD-карту в ридер, прошиваем ее:
sudo dd if=sdcard.img of=/dev/sda bs=4K # имя устройства отличается для конкретной системы, конечно
sync - подключаемся к порту UART платы, вставляем SD-карту, подаем питание на плату;
- смотрим логи ядра, понимаем, что информации недостаточно;
- добавляем логов в код ядра;
- повторяем, начиная с пересборки образа.
Процесс загрузки
После того, как система загрузится, посмотрим лог ядра (dmesg). Видно, что довольно рано начинается загрузка драйверов. Примерно где-то на этой строке:[ 0.268291] OMAP GPIO hardware version 0.1
Настало время пойти в исходники. Далее пути указаны относительно корневой директории с исходниками ядра.
Нас интересует файл init/main.c:
asmlinkage __visible void __init start_kernel(void)
Это, в общем-то, самая главная функция. Но она содержит очень много всего. Если поискать, то окажется, что нас интересует вот это место:
/*
* Ok, the machine is now initialized. None of the devices
* have been touched yet, but the CPU subsystem is up and
* running, and memory and process management works.
*
* Now we can finally start doing some real work..
*/
static void __init do_basic_setup(void)
{
cpuset_init_smp();
shmem_init();
driver_init();
init_irq_proc();
do_ctors();
usermodehelper_enable();
do_initcalls();
}
Если добавить в код немного дополнительных логов (или просто быть очень умным, но это не наш случай), то станет понятно – загрузка драйверов начинается после вызова do_initcalls(). Значит, будем смотреть на нее:
static void __init do_initcalls(void)
{
int level;
for (level = 0; level < ARRAY_SIZE(initcall_levels) - 1; level++)
do_initcall_level(level);
}
static void __init do_initcall_level(int level)
{
initcall_entry_t *fn;
strcpy(initcall_command_line, saved_command_line);
parse_args(initcall_level_names[level],
initcall_command_line, __start___param,
__stop___param - __start___param,
level, level,
NULL, &repair_env_string);
trace_initcall_level(initcall_level_names[level]);
for (fn = initcall_levels[level]; fn < initcall_levels[level+1]; fn++)
do_one_initcall(initcall_from_entry(fn));
}
То есть, у нас есть какой-то массив initcalls, который мы определенным образом перебираем. Он объявлен в этом же файле:
extern initcall_entry_t __initcall_start[];
extern initcall_entry_t __initcall0_start[];
extern initcall_entry_t __initcall1_start[];
extern initcall_entry_t __initcall2_start[];
extern initcall_entry_t __initcall3_start[];
extern initcall_entry_t __initcall4_start[];
extern initcall_entry_t __initcall5_start[];
extern initcall_entry_t __initcall6_start[];
extern initcall_entry_t __initcall7_start[];
extern initcall_entry_t __initcall_end[];
static initcall_entry_t *initcall_levels[] __initdata = {
__initcall0_start,
__initcall1_start,
__initcall2_start,
__initcall3_start,
__initcall4_start,
__initcall5_start,
__initcall6_start,
__initcall7_start,
__initcall_end,
};
/* Keep these in sync with initcalls in include/linux/init.h */
static char *initcall_level_names[] __initdata = {
"pure",
"core",
"postcore",
"arch",
"subsys",
"fs",
"device",
"late",
};
Выглядит как массив указателей на функции, которые мы каким-то сложным образом вызываем. Но откуда эти указатели берутся? Если попробовать поискать в исходниках название типа __initcall0_start, то найдем только это:
arch/arm/kernel/vmlinux.lds:
.init.data : AT(ADDR(.init.data) - 0) { KEEP(*(SORT(___kentry+*))) *(.init.data init.data.*) *(.meminit.data*) *(.init.rodata .init.rodata.*) . = ALIGN(8); __start_ftrace_events = .; KEEP(*(_ftrace_events)) __stop_ftrace_events = .; __start_ftrace_eval_maps = .; KEEP(*(_ftrace_eval_map)) __stop_ftrace_eval_maps = .; . = ALIGN(8); __start_kprobe_blacklist = .; KEEP(*(_kprobe_blacklist)) __stop_kprobe_blacklist = .; *(.meminit.rodata) . = ALIGN(8); __clk_of_table = .; KEEP(*(__clk_of_table)) KEEP(*(__clk_of_table_end)) . = ALIGN(8); __reservedmem_of_table = .; KEEP(*(__reservedmem_of_table)) KEEP(*(__reservedmem_of_table_end)) . = ALIGN(8); __timer_of_table = .; KEEP(*(__timer_of_table)) KEEP(*(__timer_of_table_end)) . = ALIGN(8); __cpu_method_of_table = .; KEEP(*(__cpu_method_of_table)) KEEP(*(__cpu_method_of_table_end)) . = ALIGN(8); __cpuidle_method_of_table = .; KEEP(*(__cpuidle_method_of_table)) KEEP(*(__cpuidle_method_of_table_end)) . = ALIGN(32); __dtb_start = .; KEEP(*(.dtb.init.rodata)) __dtb_end = .; . = ALIGN(8); __irqchip_of_table = .; KEEP(*(__irqchip_of_table)) KEEP(*(__irqchip_of_table_end)) . = ALIGN(8); __earlycon_table = .; KEEP(*(__earlycon_table)) __earlycon_table_end = .; . = ALIGN(16); __setup_start = .; KEEP(*(.init.setup)) __setup_end = .; __initcall_start = .; KEEP(*(.initcallearly.init)) __initcall0_start = .; KEEP(*(.initcall0.init)) KEEP(*(.initcall0s.init)) __initcall1_start = .; KEEP(*(.initcall1.init)) KEEP(*(.initcall1s.init)) __initcall2_start = .; KEEP(*(.initcall2.init)) KEEP(*(.initcall2s.init)) __initcall3_start = .; KEEP(*(.initcall3.init)) KEEP(*(.initcall3s.init)) __initcall4_start = .; KEEP(*(.initcall4.init)) KEEP(*(.initcall4s.init)) __initcall5_start = .; KEEP(*(.initcall5.init)) KEEP(*(.initcall5s.init)) __initcallrootfs_start = .; KEEP(*(.initcallrootfs.init)) KEEP(*(.initcallrootfss.init)) __initcall6_start = .; KEEP(*(.initcall6.init)) KEEP(*(.initcall6s.init)) __initcall7_start = .; KEEP(*(.initcall7.init)) KEEP(*(.initcall7s.init)) __initcall_end = .; __con_initcall_start = .; KEEP(*(.con_initcall.init)) __con_initcall_end = .; __security_initcall_start = .; KEEP(*(.security_initcall.init)) __security_initcall_end = .; . = ALIGN(4); __initramfs_start = .; KEEP(*(.init.ramfs)) . = ALIGN(8); KEEP(*(.init.ramfs.info)) }
То есть, мы выделяем место под этот массив в скрипте линковки, но как мы этот массив заполняем – непонятно.
Ок, тогда возвращаемся к комментарию, который отсылает нас в include/linux/init.h:
#define core_initcall(fn) __define_initcall(fn, 1)
#define core_initcall_sync(fn) __define_initcall(fn, 1s)
#define postcore_initcall(fn) __define_initcall(fn, 2)
#define postcore_initcall_sync(fn) __define_initcall(fn, 2s)
#define arch_initcall(fn) __define_initcall(fn, 3)
#define arch_initcall_sync(fn) __define_initcall(fn, 3s)
#define subsys_initcall(fn) __define_initcall(fn, 4)
#define subsys_initcall_sync(fn) __define_initcall(fn, 4s)
#define fs_initcall(fn) __define_initcall(fn, 5)
#define fs_initcall_sync(fn) __define_initcall(fn, 5s)
#define rootfs_initcall(fn) __define_initcall(fn, rootfs)
#define device_initcall(fn) __define_initcall(fn, 6)
#define device_initcall_sync(fn) __define_initcall(fn, 6s)
#define late_initcall(fn) __define_initcall(fn, 7)
#define late_initcall_sync(fn) __define_initcall(fn, 7s)
#define __initcall(fn) device_initcall(fn)
А чуть выше в этом же файле:
#ifdef CONFIG_HAVE_ARCH_PREL32_RELOCATIONS
#define ___define_initcall(fn, id, __sec) \
__ADDRESSABLE(fn) \
asm(".section \"" #__sec ".init\", \"a\" \n" \
"__initcall_" #fn #id ": \n" \
".long " #fn " - . \n" \
".previous \n");
#else
#define ___define_initcall(fn, id, __sec) \
static initcall_t __initcall_##fn##id __used \
__attribute__((__section__(#__sec ".init"))) = fn;
#endif
#define __define_initcall(fn, id) ___define_initcall(fn, id, .initcall##id)
Это очень важное место. Если поискать по исходникам штуки типа device_initcall – станет понятно, что именно они скрываются в большинстве драйверов под капотом таких дефайнов, как builtin_driver. Собственно, и сам этот дефайн используется во многих драйверах. А кое-где и более старый __initcall.
То есть, иными словами, инициализирующую функцию каждого драйвера система добавляет в список initcall-ов, и дергает ее при загрузке. Именно эта функция регистрирует драйвер в системе.
На этом можно закончить рассмотрение механизма initcalls в контексте данной статьи. Просто потому что его участие в теме загрузки драйверов на этом заканчивается. Меж тем, сам по себе механизм достаточно интересен. Он подробно рассмотрен здесь: https://proninyaroslav.gitbooks.io/linux-insides-ru/content/Concepts/linux-cpu-3.html
Отдельно стоит рассмотреть дефайн module_init. Вот как он определен в kernel/module.h:
#ifndef MODULE
/**
* module_init() - driver initialization entry point
* @x: function to be run at kernel boot time or module insertion
*
* module_init() will either be called during do_initcalls() (if
* builtin) or at module insertion time (if a module). There can only
* be one per module.
*/
#define module_init(x) __initcall(x);
/**
* module_exit() - driver exit entry point
* @x: function to be run when driver is removed
*
* module_exit() will wrap the driver clean-up code
* with cleanup_module() when used with rmmod when
* the driver is a module. If the driver is statically
* compiled into the kernel, module_exit() has no effect.
* There can only be one per module.
*/
#define module_exit(x) __exitcall(x);
#else /* MODULE */
/*
* In most cases loadable modules do not need custom
* initcall levels. There are still some valid cases where
* a driver may be needed early if built in, and does not
* matter when built as a loadable module. Like bus
* snooping debug drivers.
*/
#define early_initcall(fn) module_init(fn)
#define core_initcall(fn) module_init(fn)
#define core_initcall_sync(fn) module_init(fn)
#define postcore_initcall(fn) module_init(fn)
#define postcore_initcall_sync(fn) module_init(fn)
#define arch_initcall(fn) module_init(fn)
#define subsys_initcall(fn) module_init(fn)
#define subsys_initcall_sync(fn) module_init(fn)
#define fs_initcall(fn) module_init(fn)
#define fs_initcall_sync(fn) module_init(fn)
#define rootfs_initcall(fn) module_init(fn)
#define device_initcall(fn) module_init(fn)
#define device_initcall_sync(fn) module_init(fn)
#define late_initcall(fn) module_init(fn)
#define late_initcall_sync(fn) module_init(fn)
#define console_initcall(fn) module_init(fn)
#define security_initcall(fn) module_init(fn)
/* Each module must use one module_init(). */
#define module_init(initfn) \
static inline initcall_t __maybe_unused __inittest(void) \
{ return initfn; } \
int init_module(void) __copy(initfn) __attribute__((alias(#initfn)));
/* This is only required if you want to be unloadable. */
#define module_exit(exitfn) \
static inline exitcall_t __maybe_unused __exittest(void) \
{ return exitfn; } \
void cleanup_module(void) __copy(exitfn) __attribute__((alias(#exitfn)));
#endif
То есть, если мы собираем этот файл как внешний модуль (файл .ko) – у нас определен дефайн MODULE, и в массив initcalls наша функция не попадает. Функция init_module() вызывается при загрузке модуля (об этом чуть подробнее рассказано ниже). А вот если мы собираем этот файл как встроенный в ядро – дефайн MODULE не определен, и его функция init попадает в initcalls.
Пруф про MODULE
Утверждение про дефайн MODULE было не совсем очевидно из исходников. Самым дешевым способом проверить оказалось добавление в драйвер EEPROM AT24 таких строк:
#ifdef MODULE
printk("%s: module built with MODULE define\n", __func__);
#else
printk("%s: module built without MODULE define\n", __func__);
#endif
И, конечно, дальнейшая пересборка ядра в двух вариантах – с этим драйвером, вкомпилированным в ядро, и собранным как отдельный модуль. Что в конечном счете и подтвердило предположение.
Механизм загрузки модулей *.ko
Загрузка модуля ядра, собранного как отдельный файл, происходит, как правило, из пространства пользователя. Используется один из следующих механизмов:- Пользователь в консоли или в инит-скрипте вызывает утилиту insmod/modprobe.
- При обнаружении соответствующего устройства ядро формирует событие uevent, которое подхватывается демоном udev (или mdev, для встраиваемых систем). Демон в этом случае осуществляет те же самые действия, что и утилита modprobe.
busybox/modutils/insmod.c:
rc = bb_init_module(filename, parse_cmdline_module_options(argv, /*quote_spaces:*/ 0));
busybox/modutils/modutils.c:
int FAST_FUNC bb_init_module(const char *filename, const char *options)
{
…
/*
* First we try finit_module if available. Some kernels are configured
* to only allow loading of modules off of secure storage (like a read-
* only rootfs) which needs the finit_module call. If it fails, we fall
* back to normal module loading to support compressed modules.
*/
# ifdef __NR_finit_module
{
int fd = open(filename, O_RDONLY | O_CLOEXEC);
if (fd >= 0) {
rc = finit_module(fd, options, 0) != 0;
close(fd);
if (rc == 0)
return rc;
}
}
# endif
image_size = INT_MAX - 4095;
mmaped = 0;
image = try_to_mmap_module(filename, &image_size);
if (image) {
mmaped = 1;
} else {
errno = ENOMEM; /* may be changed by e.g. open errors below */
image = xmalloc_open_zipped_read_close(filename, &image_size);
if (!image)
return -errno;
}
errno = 0;
init_module(image, image_size, options);
Если пересказать коротко – код сводится к тому, что если ядро поддерживает системный вызов finit_module, то мы просто откроем файл, и дернем этот вызов, передав ему дескриптор файла. А если не поддерживает – то мы загрузим модуль в память, и дернем системный вызов init_module, передав ему указатель на начало образа в памяти.
Так или иначе, мы перейдем в файл ядра kernel/module.c. В зависимости от того, по какой ветке пойдет код выше, мы окажемся или тут:
SYSCALL_DEFINE3(finit_module, int, fd, const char __user *, uargs, int, flags)
{
struct load_info info = { };
loff_t size;
void *hdr;
int err;
err = may_init_module();
if (err)
return err;
pr_debug("finit_module: fd=%d, uargs=%p, flags=%i\n", fd, uargs, flags);
if (flags & ~(MODULE_INIT_IGNORE_MODVERSIONS
|MODULE_INIT_IGNORE_VERMAGIC))
return -EINVAL;
err = kernel_read_file_from_fd(fd, &hdr, &size, INT_MAX,
READING_MODULE);
if (err)
return err;
info.hdr = hdr;
info.len = size;
return load_module(&info, uargs, flags);
}
Или тут:
SYSCALL_DEFINE3(init_module, void __user *, umod,
unsigned long, len, const char __user *, uargs)
{
int err;
struct load_info info = { };
err = may_init_module();
if (err)
return err;
pr_debug("init_module: umod=%p, len=%lu, uargs=%p\n",
umod, len, uargs);
err = copy_module_from_user(umod, len, &info);
if (err)
return err;
return load_module(&info, uargs, 0);
}
Что характерно, в обоих случаях мы придем в итоге в функцию load_module(). В этой функции проводится очень много проверок и подготовок, но в итоге, если все хорошо, мы приходим вот к этому вызову:
return do_init_module(mod);
В свою очередь, функция do_init_module() сводится к обертке вокруг вот этих действий:
/* Start the module */
if (mod->init != NULL)
ret = do_one_initcall(mod->init);
if (ret < 0) {
goto fail_free_freeinit;
Иными словами, мы точно так же дергаем initcall, просто он в данном случае не встроен в цепочку тех initcall-ов, которые выполняются при инициализации системы.
Старт драйвера
Регистрация драйвера в системе – это необходимое, но не достаточное условие для его работы. Чтобы он заработал, должна быть выполнена функция probe(). Рассмотрим условия ее вызова поподробнее.Современная концепция драйверов в linux предполагает, что у платформы, на которой мы исполняемся, есть некоторый набор шин, и каждое из подключенных устройств – является экземпляром устройства на одной из шин. Примерно так:
Как мы уже говорили выше, функция инициализации каждого драйвера регистрирует этот драйвер в системе. Теперь, если мы вернемся в функцию инициализации какого-нибудь драйвера, мы обнаружим там, что для регистрации драйвера мы создаем экземпляр структуры, содержащий в себе не только указатели на функции, но также и структуру с признаками конкретного устройства.
Например, для I2C-устройства мы можем обратиться к драйверу EEPROM AT24:
drivers/misc/eeprom/at24.c:
Регистрируем драйвер:
return i2c_add_driver(&at24_driver)
А вот структура:
static struct i2c_driver at24_driver = {
.driver = {
.name = "at24",
.of_match_table = at24_of_match,
.acpi_match_table = ACPI_PTR(at24_acpi_ids),
},
.probe_new = at24_probe,
.remove = at24_remove,
.id_table = at24_ids,
};
А вот и признак, например, для поиска девайса в device tree:
static const struct of_device_id at24_of_match[] = {
{ .compatible = "atmel,24c00", .data = &at24_data_24c00 },
{ .compatible = "atmel,24c01", .data = &at24_data_24c01 },
...
{ /* END OF LIST */ },
};
Примерно аналогично дела обстоят с устройствами на других шинах. Вот, например, драйвер Wifi-модуля RTL8xxxu:
drivers/net/wireless/realtek/rtl8xxxu/rtl8xxxu_core.c:
static int __init rtl8xxxu_module_init(void)
{
int res;
res = usb_register(&rtl8xxxu_driver);
if (res < 0)
pr_err(DRIVER_NAME ": usb_register() failed (%i)\n", res);
return res;
}
Вот структура, описывающая драйвер:
static struct usb_driver rtl8xxxu_driver = {
.name = DRIVER_NAME,
.probe = rtl8xxxu_probe,
.disconnect = rtl8xxxu_disconnect,
.id_table = dev_table,
.no_dynamic_id = 1,
.disable_hub_initiated_lpm = 1,
};
А вот и признаки поддерживаемых драйвером устройств:
static const struct usb_device_id dev_table[] = {
{USB_DEVICE_AND_INTERFACE_INFO(USB_VENDOR_ID_REALTEK, 0x8724, 0xff, 0xff, 0xff),
.driver_info = (unsigned long)&rtl8723au_fops},
{USB_DEVICE_AND_INTERFACE_INFO(USB_VENDOR_ID_REALTEK, 0x1724, 0xff, 0xff, 0xff),
.driver_info = (unsigned long)&rtl8723au_fops},
…
Видно, что здесь для идентификации устройства используются ID на шине, а не записи в Device Tree. Но сам факт наличия механизма остается неизменным.
То есть, ретроспективно, логика инициализации драйвера может пойти двумя путями:
1) Если в системе регистрируется новый драйвер.
- вызывается функция int bus_add_driver(struct device_driver *drv) из drivers/base/bus.c. Она сводится к:
if (driver_allows_async_probing(drv)) {
pr_debug("bus: '%s': probing driver %s asynchronously\n",
drv->bus->name, drv->name);
async_schedule(driver_attach_async, drv);
} else {
error = driver_attach(drv);
if (error)
goto out_unregister;
}
- функция driver_attach_async() сводится к вызову driver_attach():
static void driver_attach_async(void *_drv, async_cookie_t cookie)
{
struct device_driver *drv = _drv;
int ret;
ret = driver_attach(drv);
pr_debug("bus: '%s': driver %s async attach completed: %d\n",
drv->bus->name, drv->name, ret);
}
- функция driver_attach() перебирает каждое из устройств и “примеряет” его к новому драйверу:
/**
* driver_attach - try to bind driver to devices.
* @drv: driver.
*
* Walk the list of devices that the bus has on it and try to
* match the driver with each one. If driver_probe_device()
* returns 0 and the @dev->driver is set, we've found a
* compatible pair.
*/
int driver_attach(struct device_driver *drv)
{
return bus_for_each_dev(drv->bus, NULL, drv, __driver_attach);
}
EXPORT_SYMBOL_GPL(driver_attach);
- сама “примерка” происходит в функции __driver_attach() и сводится к вызову:
ret = driver_match_device(drv, dev);
- функция driver_match_device() имеет свою имплементацию для каждой шины:
drivers/base/base.h:
static inline int driver_match_device(struct device_driver *drv,
struct device *dev)
{
return drv->bus->match ? drv->bus->match(dev, drv) : 1;
}
2) Если на шине появляется устройство. Это может быть физическое событие, например, прерывание от PCI/USB/etc, а может быть просто очередная найденная запись device tree.
- вызывается функция из drivers/base/core.c (кстати, здесь же генерится uevent):
int device_add(struct device *dev)
{
…
kobject_uevent(&dev->kobj, KOBJ_ADD);
bus_probe_device(dev);
- вот что делает bus_probe_device():
/**
* bus_probe_device - probe drivers for a new device
* @dev: device to probe
*
* - Automatically probe for a driver if the bus allows it.
*/
void bus_probe_device(struct device *dev)
{
struct bus_type *bus = dev->bus;
struct subsys_interface *sif;
if (!bus)
return;
if (bus->p->drivers_autoprobe)
device_initial_probe(dev);
- drivers/base/dd.c:
void device_initial_probe(struct device *dev)
{
__device_attach(dev, true);
}
- а уже под капотом этой функции “примерка” драйвера к каждому из зарегистрированных устройств:
static int __device_attach(struct device *dev, bool allow_async)
{
...
ret = bus_for_each_drv(dev->bus, NULL, &data,
__device_attach_driver);
Все это в документации на ядро описано достаточно лаконично здесь, и по-настоящему становится понятно после ознакомления с соответствующим кодом:
When a new device is added, the bus's list of drivers is iterated over to find one that supports it. In order to determine that, the device ID of the device must match one of the device IDs that the driver supports. The format and semantics for comparing IDs is bus-specific. Instead of trying to derive a complex state machine and matching algorithm, it is up to the bus driver to provide a callback to compare a device against the IDs of a driver. The bus returns 1 if a match was found; 0 otherwise.
int match(struct device * dev, struct device_driver * drv);
If a match is found, the device's driver field is set to the driver and the driver's probe callback is called. This gives the driver a chance to verify that it really does support the hardware, and that it's in a working state.
Платформенные драйверы и платформенные устройства
“Платформенное устройство” – довольно кривая собирательная калька с оригинальных терминов “platform device” и “platform driver”. Попробуем сложное описание.“Платформенный драйвер” (platform driver) – драйвер устройства уровня “контроллер шины I2C” или “контроллер шины PCI”, или многих других общепринятых шин. Если смотреть на аппаратную составляющую – то как правило, эти контроллеры – это IP-блок микросхемы, подключенный по шине AXI или подобной. Эти шины, как правило, для программиста не видны, и нет необходимости (и возможности) учитывать в коде их существование. Кроме того, устройства на этой шине никак не могут объявить о своем подключении.
Для таких устройств в ядре есть сущность platform_driver.
Вероятно, будет не слишком большим отклонением от истины сказать, что platform в данном случае – это “виртуальная” шина, к которой подключены другие контроллеры шин. То есть, структурная схема начинает выглядеть примерно так:
Если заглянуть в драйверы контроллеров того же I2C, можно увидеть, что там при инициализации чаще всего используется именно platform_driver_register().
Резюме
Мы рассмотрели самый базовый код и концепции, обеспечивающие инициализацию и загрузку драйверов в ядре Linux. Несмотря на довольно очевидную верхнеуровневую логику ("нашли девайс - подобрали драйвер к нему"), "под капотом" этот процесс оказался достаточно сложным и интересным.За рамками рассмотрения остались механизмы, обеспечивающие обнаружение новых устройств (будь то физическое подключение или обнаружение записи в Device Tree), а также механизмы, обеспечивающие автоматическую загрузку соответствующих модулей ядра.
Также в рассмотрение не попали тонкости и коллизии описанного процесса, которых в нем, как и во всей операционной системе, хватает.
Рассмотрение других интересных "подкапотных" вещей запланировано в новых статьях. Остается надеяться, что их реализации ничто не воспрепятствует.
Используемая литература
Основные сведения, помимо исходников, взяты отсюда:- https://docs.kernel.org/driver-api/index.html
- https://proninyaroslav.gitbooks.io/linux-insides-ru/content/
Загрузка драйверов в ядре Linux
Почти все знают, как написать простой драйвер под Linux. На эту тему много материалов в сети. Очень мало информации о том, что находится "под капотом" у процедуры загрузки драйверов. Это мало кому...
habr.com