Когда-то я хотел сделать контест по парсингу для Codeforces. Придумал задания двух типов:
Проблема второго типа задания в ограниченности примеров. Можно "не уловить" как выглядит структура языка. А так же можно создать грамматику, которая просто содержит все приведенные примеры. Как такое апеллировать — непонятно.
В итоге я сделалигру программу CrateGram, в которой можно решать задания второго типа, при этом проверять строки на принадлежность угадываемому языку.
Введём три определения, которые пригодятся позже:
Язык L — множество строк.
Грамматика языка L — функция типа (input: string) -> bool, которая возвращает true, если input-строка входит в язык L, false иначе.
AST (Abstract syntax tree или абстрактное синтаксическое дерево) — это иерархическая структура в которую переводится строка после парсинга. Узлы дерева соответствуют правилам грамматики, а листья — частям из распаршенной строки.

Caterpillar logic
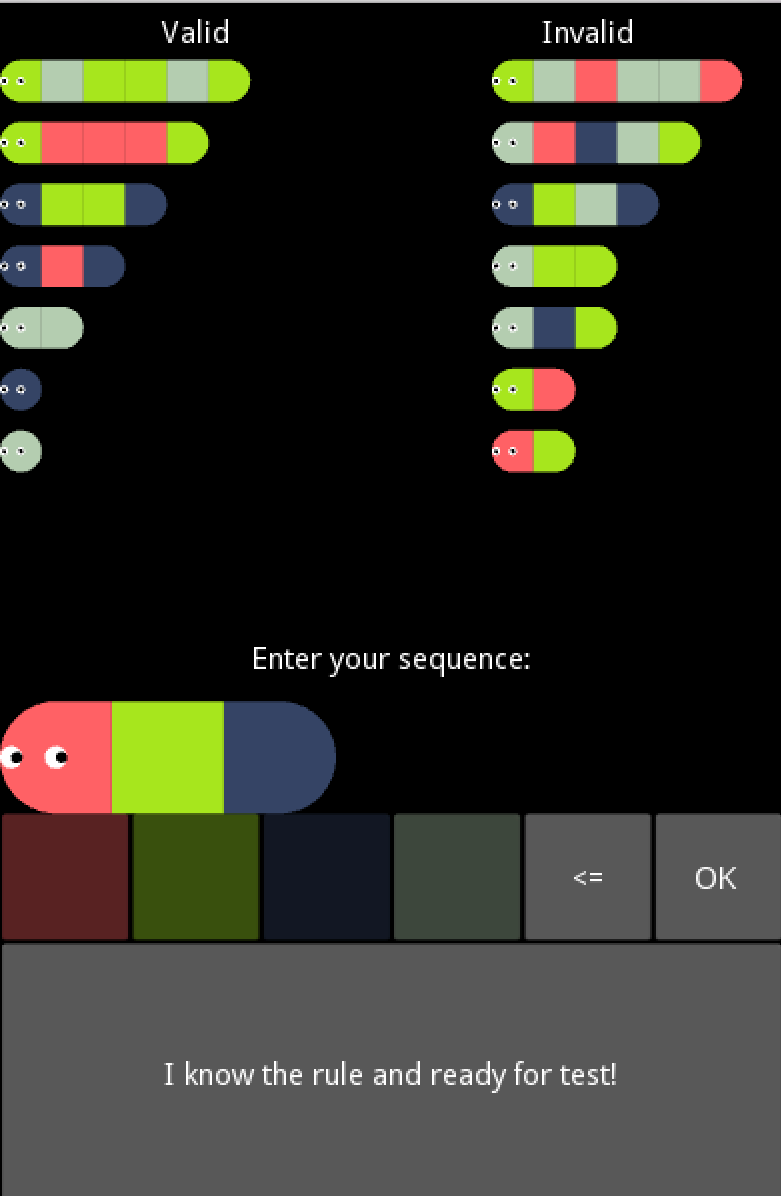
По сути caterpillar logic то же, что и черный ящик. В этом подходе мне нравится что игрок может проверять комбинации сегментов на соответствие правилу.
Однако есть небольшая вероятность угадать правило (
 ). Это мне не нравится, так что для прохождения уровня в CrateGram нужно не указать правильность 15 последовательностей, а формально описать правило через PEG. Это правило будет проверено на нескольких тестах.
). Это мне не нравится, так что для прохождения уровня в CrateGram нужно не указать правильность 15 последовательностей, а формально описать правило через PEG. Это правило будет проверено на нескольких тестах.
"abc" - точное совпадение строки abc
[abc] - совпадение одного из символов в скобках (или промежутка символов, если записаны через `-`)
e* - от 0 до бесконечности совпадений e
e+ - от 1 до бесконечности совпадений e
&e - e должно находиться далее
!e - e не должно находиться далее
e1 e2 - выражения e1 и e2 должны идти друг за другом
e1 / e2 - если выражение e1 не парсится, тогда парсим e2
r = ... - создание нового правила с названием r
Простой пример:
// в каждой грамматике должно быть стартовое правило, с которого начинается парсинг
// здесь оно названо `root`
root = "2" digit digit digit
digit = [0-9]
Это пример грамматики языка всех чисел от 2000 до 2999. Для соответствия правилу root нужно чтобы строка начиналась с двойки. Далее идут три повторения правила digit, которое описывает одну цифру.
Поправка
Вообще, чтобы грамматика была верной, нужно добавить !. в конец правила root. Это дополнение означает, что после четвертой цифры не должно быть символов (. - означает любой символ).
Есть более известный способ задания грамматик: EBNF или Extended Backus-Naur form (еще есть просто BNF). Его отличие от PEG в том, что одна строка может быть обработана по-разному (давать несколько AST). Существует известная dangling-else проблема. Суть в том, что для вложенных if-then-else последующий else может относиться как к внешнему if'у, так и к внутреннему.
Разбор случая для EBNF
Пусть дано выражение `if A then if B then C else D`. Для него возможны два варианта AST:
"root": [
"if ",
"A",
" then ",
[
"if ",
"B",
" then ",
"C",
" else ",
"D"
]
]
или
"root": [
"if ",
"A",
" then ",
[
"if ",
"B",
" then ",
"C",
],
" else ",
"D"
]
У PEG такого нет, парсинг грамматики и выражения однозначный.А еще PEG-парсер проще написать.
Разбор для PEG
Пусть
root = expr !.
expr = "if " ([A-Z] / expr) " then " ([A-Z] / expr) (" else " ([A-Z] / expr))?
// AST для `if A then if B then C else D`
{
"root": {
"expr": [
"if ",
"A",
" then ",
{
"expr": [
"if ",
"B",
" then ",
"C",
" else ",
"D"
]
},
""
]
}
}

Так выглядит интерфейс CrateGram
В CrateGram на каждом уровне нужно создать грамматику, которая будет принимать только валидные строки. Как и в Caterpillar logic, игрок может проверять валидность строк (кнопка add test, ниже можно написать тест).
Сделано это просто: есть скрытая грамматика, которая проверяет вводные данные пользователя. Для проверки ответа (грамматики игрока) есть несколько тестовых строк, которые проверяют грамматику пользователя. Тестовые строки сделаны так: рандомно генерируется строка, проверяется скрытой грамматикой, после чего кладется в valid или invalid в зависимости от проверки.
Изначально я хотел сделать генерацию валидных строк, но для этого надо избавиться от операторов ! и &. Есть алгоритм как это сделать (раздел 4), ноя не осилил пока тесты — довольно надежный способ проверки.
Недостаток в примитивных сообщениях об ошибке (и, скорее всего, в производительности). Если создать грамматику root = root, то PEG.js напишет Line 1, column 8: Possible infinite loop when parsing (left recursion: root -> root). CrateGram упадет уже при написании теста.
В дальнейшем для AST можно будет добавить раскрываемые/игнорируемые правила с нижним подчеркиванием как в Lark или унарный минус для удаления из AST как в better-parse.
 habr.com
habr.com
- Дается неформальное описание языка, по которому нужно создать грамматику (например, "язык с правильными скобочными последовательностями");
- Даны примеры строк в языке, по которым нужно восстановить грамматику.
Проблема второго типа задания в ограниченности примеров. Можно "не уловить" как выглядит структура языка. А так же можно создать грамматику, которая просто содержит все приведенные примеры. Как такое апеллировать — непонятно.
В итоге я сделал
Введём три определения, которые пригодятся позже:
Язык L — множество строк.
Грамматика языка L — функция типа (input: string) -> bool, которая возвращает true, если input-строка входит в язык L, false иначе.
AST (Abstract syntax tree или абстрактное синтаксическое дерево) — это иерархическая структура в которую переводится строка после парсинга. Узлы дерева соответствуют правилам грамматики, а листья — частям из распаршенной строки.
Caterpillar logic
Caterpillar logic — это игра, где нужно угадать правило, которому соответствуют змейки (именно этой игрой я вдохновился). "Правильные" змейки помещаются в колонку valid, а неправильные — в invalid. Змейки состоят из сегментов 4 цветов. Игра заключается в том, что мы составляем новые змейки из сегментов, а программа говорит, подходят они под правило или нет. Таким образом, можно понять закономерность. Чтобы пройти уровень, нужно распределить 15 змеек по колонкам (эти 15 змеек генерирует игра, когда мы нажимаем "I know the rule and ready for the test!").
Caterpillar logic
По сути caterpillar logic то же, что и черный ящик. В этом подходе мне нравится что игрок может проверять комбинации сегментов на соответствие правилу.
Однако есть небольшая вероятность угадать правило (
Что такое Parsing Expression Grammar?
Parsing Expression Grammar (или PEG) — это "формат" грамматики, использующий операторы регулярных выражений. Список операторов:"abc" - точное совпадение строки abc
[abc] - совпадение одного из символов в скобках (или промежутка символов, если записаны через `-`)
e* - от 0 до бесконечности совпадений e
e+ - от 1 до бесконечности совпадений e
&e - e должно находиться далее
!e - e не должно находиться далее
e1 e2 - выражения e1 и e2 должны идти друг за другом
e1 / e2 - если выражение e1 не парсится, тогда парсим e2
r = ... - создание нового правила с названием r
Простой пример:
// в каждой грамматике должно быть стартовое правило, с которого начинается парсинг
// здесь оно названо `root`
root = "2" digit digit digit
digit = [0-9]
Это пример грамматики языка всех чисел от 2000 до 2999. Для соответствия правилу root нужно чтобы строка начиналась с двойки. Далее идут три повторения правила digit, которое описывает одну цифру.
Поправка
Вообще, чтобы грамматика была верной, нужно добавить !. в конец правила root. Это дополнение означает, что после четвертой цифры не должно быть символов (. - означает любой символ).
Есть более известный способ задания грамматик: EBNF или Extended Backus-Naur form (еще есть просто BNF). Его отличие от PEG в том, что одна строка может быть обработана по-разному (давать несколько AST). Существует известная dangling-else проблема. Суть в том, что для вложенных if-then-else последующий else может относиться как к внешнему if'у, так и к внутреннему.
Разбор случая для EBNF
Пусть дано выражение `if A then if B then C else D`. Для него возможны два варианта AST:
"root": [
"if ",
"A",
" then ",
[
"if ",
"B",
" then ",
"C",
" else ",
"D"
]
]
или
"root": [
"if ",
"A",
" then ",
[
"if ",
"B",
" then ",
"C",
],
" else ",
"D"
]
У PEG такого нет, парсинг грамматики и выражения однозначный.
Разбор для PEG
Пусть
root = expr !.
expr = "if " ([A-Z] / expr) " then " ([A-Z] / expr) (" else " ([A-Z] / expr))?
// AST для `if A then if B then C else D`
{
"root": {
"expr": [
"if ",
"A",
" then ",
{
"expr": [
"if ",
"B",
" then ",
"C",
" else ",
"D"
]
},
""
]
}
}
Задачи по образу и подобию змеек
Так выглядит интерфейс CrateGram
В CrateGram на каждом уровне нужно создать грамматику, которая будет принимать только валидные строки. Как и в Caterpillar logic, игрок может проверять валидность строк (кнопка add test, ниже можно написать тест).
Сделано это просто: есть скрытая грамматика, которая проверяет вводные данные пользователя. Для проверки ответа (грамматики игрока) есть несколько тестовых строк, которые проверяют грамматику пользователя. Тестовые строки сделаны так: рандомно генерируется строка, проверяется скрытой грамматикой, после чего кладется в valid или invalid в зависимости от проверки.
Изначально я хотел сделать генерацию валидных строк, но для этого надо избавиться от операторов ! и &. Есть алгоритм как это сделать (раздел 4), но
Другие фичи CrateGram
Так же есть Playground, где можно просто создавать и проверять грамматики, как и в PEG.js. Преимущество перед PEG.js в подробном AST-дереве. В нем будут указаны названия правил.Недостаток в примитивных сообщениях об ошибке (и, скорее всего, в производительности). Если создать грамматику root = root, то PEG.js напишет Line 1, column 8: Possible infinite loop when parsing (left recursion: root -> root). CrateGram упадет уже при написании теста.
В дальнейшем для AST можно будет добавить раскрываемые/игнорируемые правила с нижним подчеркиванием как в Lark или унарный минус для удаления из AST как в better-parse.
Выводы
Когда я пользовался PEG-парсерами, мне казалось, что это сложная программа, в которой я не смогу разобраться. Когда я написал свой PEG-парсер это ощущение пропало, заодно пропало и слепое пятно в понимании алгоритмов парсинга.
Задачи про PEG-парсеры
Когда-то я хотел сделать контест по парсингу для Codeforces. Придумал задания двух типов: Дается неформальное описание языка, по которому нужно создать грамматику (например, "язык с правильными...
habr.com