Соединение слиянием
Соединение слиянием работает для наборов данных, отсортированных по ключу соединения, и возвращает отсортированный же результат. Входной набор может получиться заранее отсортированным в результате индексного сканирования или он может быть отсортирован явно.Слияние отсортированных наборов
Вот пример соединения слиянием; оно представлено в плане выполнения узлом Merge Join:EXPLAIN (costs off) SELECT *
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
ORDER BY t.ticket_no;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Merge Join
Merge Cond: (t.ticket_no = tf.ticket_no)
−> Index Scan using tickets_pkey on tickets t
−> Index Scan using ticket_flights_pkey on ticket_flights tf
(4 rows)
Здесь оптимизатор предпочел именно этот способ соединения, поскольку он возвращает результат именно в том порядке, который указан в предложении ORDER BY. Работая с планами, оптимизатор учитывает порядок сортировки наборов данных и не выполняет явную сортировку, если в ней нет необходимости. В частности, полученный набор можно использовать для следующего соединения слиянием, если порядок сортировки сохраняется:
EXPLAIN (costs off) SELECT *
FROM tickets t
JOIN ticket_flights tf ON t.ticket_no = tf.ticket_no
JOIN boarding_passes bp ON bp.ticket_no = tf.ticket_no
AND bp.flight_id = tf.flight_id
ORDER BY t.ticket_no;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Merge Join
Merge Cond: (tf.ticket_no = t.ticket_no)
−> Merge Join
Merge Cond: ((tf.ticket_no = bp.ticket_no) AND (tf.flight_...
−> Index Scan using ticket_flights_pkey on ticket_flights tf
−> Index Scan using boarding_passes_pkey on boarding_passe...
−> Index Scan using tickets_pkey on tickets t
(7 rows)
Сначала соединяются таблицы перелетов (ticket_flights) и посадочных талонов (boarding_passes); обе имеют составной первичный ключ (ticket_no, flight_id) и результат отсортирован по этим двум столбцам. Полученный набор строк соединяется с билетами (tickets), отсортированными по ticket_no.
Соединение выполняется за один проход по обоим наборам данных и не требует дополнительной памяти. Используются два указателя на текущие (изначально — первые) строки внутреннего и внешнего наборов.
Если ключи двух текущих строк не совпадают, один из указателей — тот, что ссылается на строку с меньшим ключом — продвигается на одну позицию вперед до тех пор, пока не будет найдено совпадение. Соответствующие друг другу строки возвращаются вышестоящему узлу, а указатель внутреннего набора данных продвигается на одну позицию вперед. Алгоритм продолжается до тех пор, пока один из наборов не закончится.
Такой алгоритм справляется с дубликатами ключей во внутреннем наборе данных, но, поскольку дубликаты могут быть и во внешнем наборе, алгоритм приходится немного усложнить: если после продвижения внешнего указателя ключ остается прежним, внутренний указатель возвращается назад на первую строку с тем же значением ключа. Таким образом, каждой строке из внешнего набора данных будут сопоставлены все строки с тем же ключом из внутреннего набора данных.
Для внешнего соединения алгоритм еще немного меняется, но общая идея остается той же самой.
Единственный оператор, на который рассчитано соединение слиянием — равенство, то есть поддерживаются только эквисоединения (хотя работа над поддержкой других условий тоже ведется).
Оценка стоимости. Рассмотрим приведенный выше пример:
EXPLAIN SELECT *
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
ORDER BY t.ticket_no;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Merge Join (cost=0.99..822358.66 rows=8391852 width=136)
Merge Cond: (t.ticket_no = tf.ticket_no)
−> Index Scan using tickets_pkey on tickets t
(cost=0.43..139110.29 rows=2949857 width=104)
−> Index Scan using ticket_flights_pkey on ticket_flights tf
(cost=0.56..570975.58 rows=8391852 width=32)
(6 rows)
В начальную стоимость соединения входят как минимум начальные стоимости дочерних узлов.
В общем случае для нахождения первого соответствия может потребоваться прочитать некоторую долю внешнего или внутреннего наборов данных. Оценку этой доли можно дать, сравнив (с помощью гистограммы) минимальные значения ключа соединения в двух наборах. Но в данном случае диапазон номеров билетов в обоих таблицах совпадает.
Полная стоимость соединения складывается из стоимостей получения данных от дочерних узлов и стоимости вычислений.
Поскольку алгоритм соединения останавливается, когда заканчивается один из наборов данных (конечно, кроме случая внешнего соединения), другой набор может быть прочитан не полностью. Оценку этой доли можно получить, сравнив максимальные значения ключа в двух наборах. В нашем случае оба набора будут прочитаны до конца, так что в полную стоимость соединения войдет сумма полных стоимостей обоих дочерних узлов.
Кроме того, при наличии дубликатов часть строк внешнего набора может быть прочитана несколько раз. Количество повторных чтений оценивается разностью кардинальностей результата соединения и внутреннего набора.
В нашем запросе эти кардинальности совпадают, что говорит об отсутствии дубликатов.
Необходимые вычисления состоят из сравнений ключей соединения и выдачи результирующих строк. Количество сравнений можно оценить суммой кардинальностей обоих наборов и количества повторных чтений строк внешнего набора; одно сравнение оценивается значением параметра cpu_operator_cost. Стоимость обработки одной результирующей строки оценивается, как обычно, значением параметра cpu_tuple_cost.
Подытоживая, для нашего примера стоимость соединения вычисляется следующим образом:
SELECT 0.43 + 0.56 AS startup,
round((
139110.29 + 570975.58 +
current_setting('cpu_tuple_cost')::real * 8391852 +
current_setting('cpu_operator_cost')::real * (2949857 + 8391852)
)::numeric, 2) AS total;
startup | total
−−−−−−−−−+−−−−−−−−−−−
0.99 | 822358.66
(1 row)
Параллельный режим
Соединение слиянием может использоваться в параллельных планах.Сканирование внешнего набора строк выполняется рабочими процессами параллельно, но внутренний набор строк каждый рабочий процесс всегда читает самостоятельно.
Вот пример параллельного плана запроса, использующего соединение слиянием:
SET enable_hashjoin = off;
EXPLAIN (costs off)
SELECT count(*), sum(tf.amount)
FROM tickets t
JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Finalize Aggregate
−> Gather
Workers Planned: 2
−> Partial Aggregate
−> Merge Join
Merge Cond: (tf.ticket_no = t.ticket_no)
−> Parallel Index Scan using ticket_flights_pkey o...
−> Index Only Scan using tickets_pkey on tickets t
(8 rows)
Полные и правые внешние соединения слиянием в параллельных планах не поддерживаются.
Модификации
Соединение слиянием поддерживает любые типы соединений. Единственное ограничение для полного и правого внешних соединений — условие соединения должно содержать только выражения, подходящие для слияния (равенство столбцов из внешнего и внутреннего наборов или равенство столбца константе). В остальных случаях результат соединения просто фильтруется по таким дополнительным выражениям после соединения, но для полного и правого соединений это невозможно.Вот пример полного соединения, использующего алгоритм слияния:
EXPLAIN (costs off) SELECT *
FROM tickets t
FULL JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
ORDER BY t.ticket_no;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Sort
Sort Key: t.ticket_no
−> Merge Full Join
Merge Cond: (t.ticket_no = tf.ticket_no)
−> Index Scan using tickets_pkey on tickets t
−> Index Scan using ticket_flights_pkey on ticket_flights tf
(6 rows)
Внутреннее и левое внешнее соединения слиянием сохраняют порядок сортировки. Но для полного и правого внешних соединений это не верно, поскольку между упорядоченными значениями внешнего набора данных могут быть вставлены неопределенные значения — а это нарушает сортировку. Поэтому здесь появляется узел Sort, восстанавливающий нужный порядок. Это, конечно, увеличивает стоимость плана и делает хеш-соединение более привлекательным, и, чтобы показать этот план, хеш-соединения пришлось отключить.
Но в следующем примере хеш-соединение используется все равно, поскольку это единственный способ выполнить полное соединение, содержащее условия в виде, который не поддерживается соединением слияния:
EXPLAIN (costs off) SELECT *
FROM tickets t
FULL JOIN ticket_flights tf ON tf.ticket_no = t.ticket_no
AND tf.amount > 0
ORDER BY t.ticket_no;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Sort
Sort Key: t.ticket_no
−> Hash Full Join
Hash Cond: (tf.ticket_no = t.ticket_no)
Join Filter: (tf.amount > '0'::numeric)
−> Seq Scan on ticket_flights tf
−> Hash
−> Seq Scan on tickets t
(8 rows)
RESET enable_hashjoin;
Сортировка
Если какой-то из наборов строк (а возможно, и оба) не отсортирован по ключу соединения, перед выполнением слияния он должен быть переупорядочен. Такая явная сортировка представляется в плане выполнения узлом Sort:EXPLAIN (costs off)
SELECT *
FROM flights f
JOIN airports_data dep ON f.departure_airport = dep.airport_code
ORDER BY dep.airport_code;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Merge Join
Merge Cond: (f.departure_airport = dep.airport_code)
−> Sort
Sort Key: f.departure_airport
−> Seq Scan on flights f
−> Sort
Sort Key: dep.airport_code
−> Seq Scan on airports_data dep
(8 rows)
Такая же сортировка может применяться и вне контекста соединений при использовании предложения ORDER BY, как самого по себе, так и в составе оконных функций:
EXPLAIN (costs off)
SELECT flight_id,
row_number() OVER (PARTITION BY flight_no ORDER BY flight_id)
FROM flights f;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
WindowAgg
−> Sort
Sort Key: flight_no, flight_id
−> Seq Scan on flights f
(4 rows)
Здесь узел WindowAgg вычисляет оконную функцию по набору данных, предварительно отсортированному узлом Sort.
В арсенале планировщика имеется несколько способов сортировки данных. В примере, который я уже показывал, используется два из них (Sort Method). Как обычно, эти детали можно узнать, выполнив команду EXPLAIN ANALYZE:
EXPLAIN (analyze,costs off,timing off,summary off)
SELECT *
FROM flights f
JOIN airports_data dep ON f.departure_airport = dep.airport_code
ORDER BY dep.airport_code;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Merge Join (actual rows=214867 loops=1)
Merge Cond: (f.departure_airport = dep.airport_code)
−> Sort (actual rows=214867 loops=1)
Sort Key: f.departure_airport
Sort Method: external merge Disk: 17136kB
−> Seq Scan on flights f (actual rows=214867 loops=1)
−> Sort (actual rows=104 loops=1)
Sort Key: dep.airport_code
Sort Method: quicksort Memory: 52kB
−> Seq Scan on airports_data dep (actual rows=104 loops=1)
(10 rows)
Быстрая сортировка
Если сортируемый набор данных помещается в память, ограниченную значением параметра work_mem, применяется традиционная быстрая сортировка (quick sort). Этот алгоритм описан во всех учебниках и я не буду его повторять.С точки зрения реализации сортировка выполняется специальным компонентом, который выбирает наиболее подходящий алгоритм сортировки.
Оценка стоимости. Возьмем пример сортировки небольшой таблицы:
EXPLAIN SELECT *
FROM airports_data
ORDER BY airport_code;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Sort (cost=7.52..7.78 rows=104 width=145)
Sort Key: airport_code
−> Seq Scan on airports_data (cost=0.00..4.04 rows=104 width=...
(3 rows)
Известно, что сортировка n значений имеет вычислительную сложность O(n log2n). Одна операция сравнения оценивается удвоенным значением параметра cpu_operator_cost. Поскольку результат можно получить, только прочитав и отсортировав весь набор данных, стоимость операций сравнения вместе с полной стоимостью дочернего узла составляет начальную стоимость сортировки.
В полную стоимость сортировки добавляется обработка каждой строки результата, которая оценивается значением параметра cpu_operator_cost (а не cpu_tuple_cost, как обычно, поскольку для узла Sort накладные расходы невелики).
В нашем примере стоимость вычисляется так:
WITH costs(startup) AS (
SELECT 4.04 + round((
current_setting('cpu_operator_cost')::real * 2 *
104 * log(2, 104)
)::numeric, 2)
)
SELECT startup,
startup + round((
current_setting('cpu_operator_cost')::real * 104
)::numeric, 2) AS total
FROM costs;
startup | total
−−−−−−−−−+−−−−−−−
7.52 | 7.78
(1 row)
Частичная пирамидальная сортировка
Если нужно отсортировать не весь набор данных, а только его часть (что определяется предложением LIMIT), может применяться частичная пирамидальная сортировка (top-N heapsort). Точнее, этот алгоритм используется, если количество строк после сортировки уменьшается как минимум вдвое, или если входной набор строк не помещается целиком в отведенную оперативную память (но выходной набор при этом помещается).EXPLAIN (analyze, timing off, summary off) SELECT *
FROM seats
ORDER BY seat_no
LIMIT 100;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Limit (cost=72.57..72.82 rows=100 width=15)
(actual rows=100 loops=1)
−> Sort (cost=72.57..75.91 rows=1339 width=15)
(actual rows=100 loops=1)
Sort Key: seat_no
Sort Method: top−N heapsort Memory: 33kB
−> Seq Scan on seats (cost=0.00..21.39 rows=1339 width=15)
(actual rows=1339 loops=1)
(8 rows)
Чтобы найти k максимальных (минимальных) значений из n, в структуру данных, называемую кучей, добавляются k первых строк. Затем по одной добавляются и все остальные строки, но после добавления каждой следующей строки из кучи изымается одно наименьшее (наибольшее) значение. В результате в куче остаются k искомых значений.
Куча (heap), используемая в этот алгоритме, является структурой данных и не имеет ничего общего с таблицами базы данных, которые часто называют этим же термином.
Оценка стоимости. Сложность алгоритма оценивается как O(n log2k), однако каждая операция обходится дороже, чем в случае быстрой сортировки. Поэтому формула расчета стоимости использует n log22k.
WITH costs(startup) AS (
SELECT 21.39 + round((
current_setting('cpu_operator_cost')::real * 2 *
1339 * log(2, 2 * 100)
)::numeric, 2)
)
SELECT startup,
startup + round((
current_setting('cpu_operator_cost')::real * 100
)::numeric, 2) AS total
FROM costs;
startup | total
−−−−−−−−−+−−−−−−−
72.57 | 72.82
(1 row)
Внешняя сортировка
Если при чтении набора данных выясняется, что он слишком велик для сортировки в оперативной памяти, узел сортировки переключается на внешнюю сортировку слиянием (external merge).Уже прочитанные строки сортируются в памяти алгоритмом быстрой сортировки и записываются во временный файл.
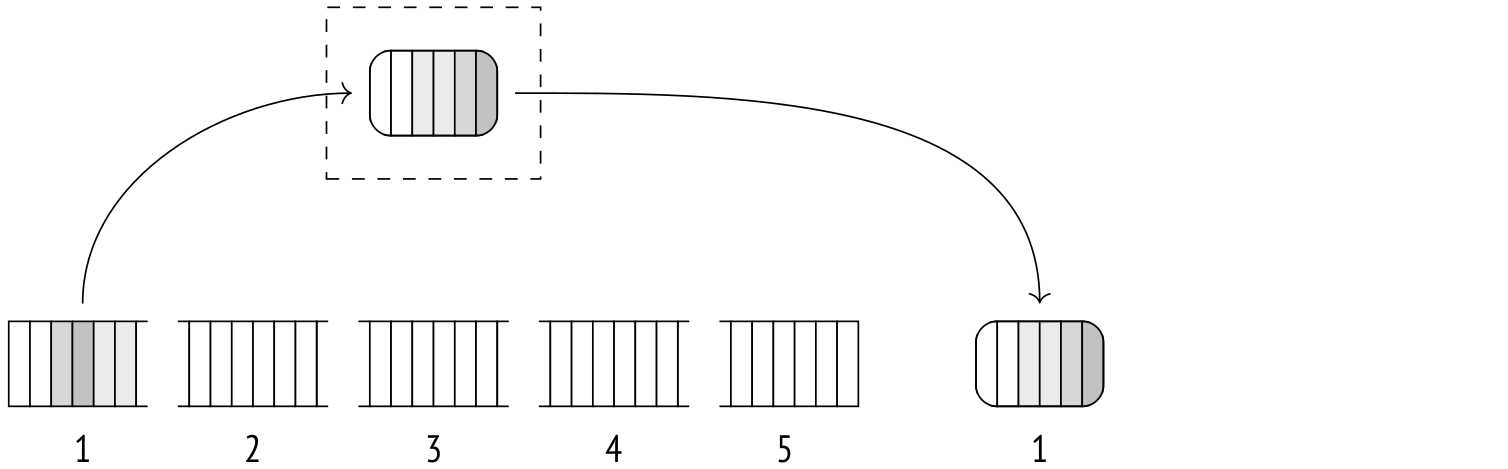
В освобожденную память читаются следующие строки и процедура повторяется до тех пор, пока все данные не будут записаны в несколько файлов, каждый из которых по отдельности отсортирован.
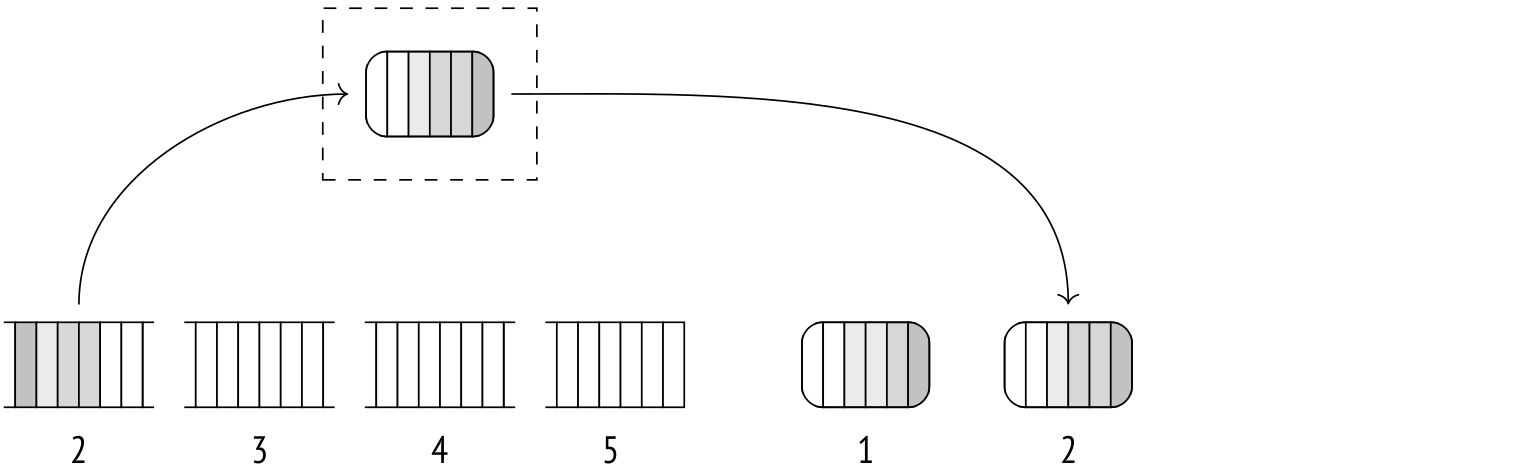
Далее несколько файлов объединяются в один примерно тем же алгоритмом, что используется и при соединении слиянием. Основное отличие состоит в том, что объединяться могут более двух файлов одновременно.
Для слияния не требуется много памяти. В принципе, достаточно располагать местом под одну строку для каждого файла. Из файлов читаются первые строки, среди них выбирается минимальная (или максимальная, в зависимости от направления сортировки) и возвращается как часть результата, а на ее место читается новая строка из соответствующего файла.
На практике строки читаются не по одной, а порциями по 32 страницы, чтобы уменьшить количество операций ввода-вывода. Количество файлов, которые объединяются за одну итерацию, определяется доступным местом в памяти, но меньше шести не используется никогда. Сверху это количество тоже ограничено (числом 500), поскольку при слишком большом числе файлов эффективность теряется.
Если объединить все отсортированные временные файлы за одну итерацию не получается, приходится выполнять слияние файлов по частям и записывать результат в новые временные файлы. Каждая такая итерация увеличивает объем записываемых и читаемых данных, поэтому чем больше оперативной памяти доступно, тем эффективнее будет выполняться внешняя сортировка.
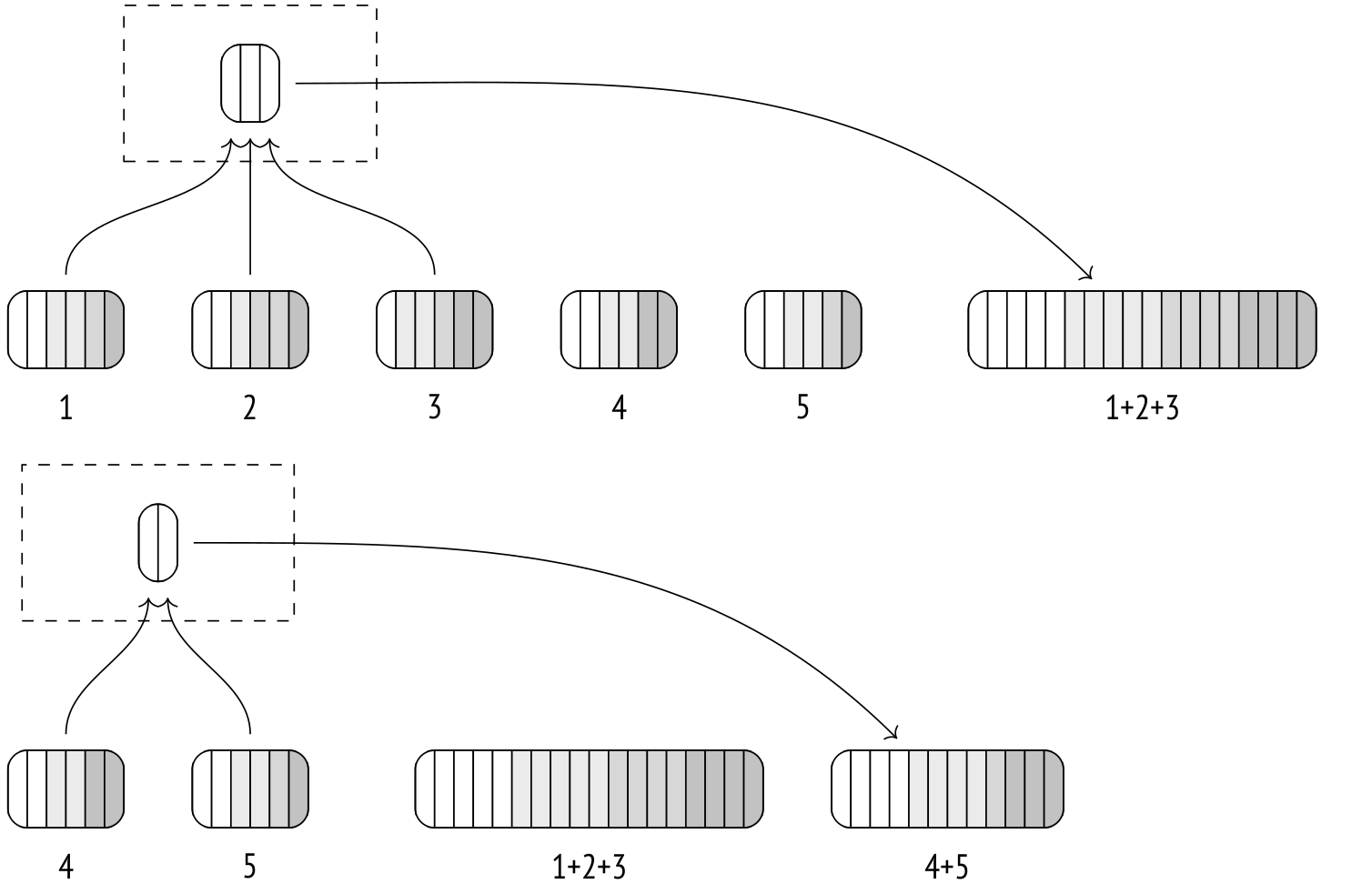
На следующей итерации слияние продолжается уже с новыми файлами.
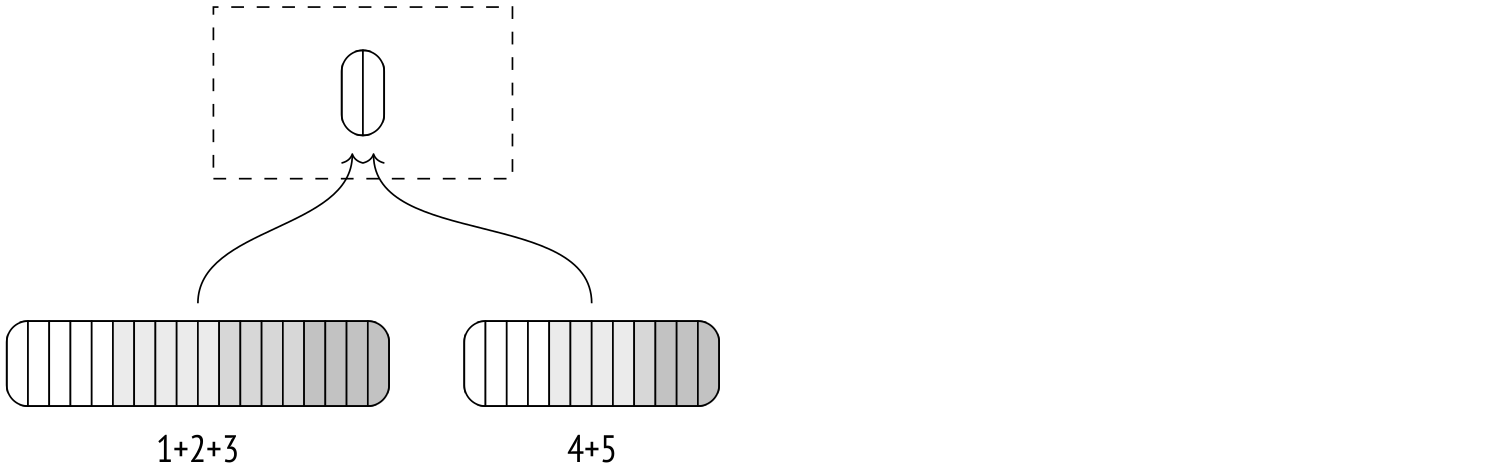
Финальное слияние обычно откладывается и выполняется на лету, когда вышестоящий узел плана запрашивает данные.
Команда EXPLAIN ANALYZE показывает объем дисковой памяти, который потребовался внешней сортировке. Добавив ключевое слово buffers, можно получить и статистику использования буферов временных файлов (temp read и written). Количество записанных буферов будет (примерно) равно количеству прочитанных, и именно это значение, пересчитанное в килобайты, показано в плане в позиции Disk:
EXPLAIN (analyze, buffers, costs off, timing off, summary off)
SELECT *
FROM flights
ORDER BY scheduled_departure;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Sort (actual rows=214867 loops=1)
Sort Key: scheduled_departure
Sort Method: external merge Disk: 17136kB
Buffers: shared hit=610 read=2017, temp read=2142 written=2150
−> Seq Scan on flights (actual rows=214867 loops=1)
Buffers: shared hit=607 read=2017
(6 rows)
Более подробную статистику использование временных файлов можно получить в журнале сообщений, установив параметр log_temp_buffers.
Оценка стоимости. В качестве примера возьмем тот же план с внешней сортировкой:
EXPLAIN SELECT *
FROM flights
ORDER BY scheduled_departure;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Sort (cost=31883.96..32421.12 rows=214867 width=63)
Sort Key: scheduled_departure
−> Seq Scan on flights (cost=0.00..4772.67 rows=214867 width=63)
(3 rows)
Здесь к обычной стоимости сравнений (количество которых остается таким же, как и в случае быстрой сортировки в памяти) добавляется стоимость ввода-вывода. Все входные данные придется сначала записать на диск во временные файлы, а затем прочитать с диска при слиянии (причем, возможно, несколько раз, если количество созданных файлов будет превышать количество одновременно объединяемых наборов).
Объем данных, попадающих на диск, определяется количеством и размером сортируемых строк. В данном случае запрос выводит все столбцы таблицы flights, поэтому объем почти равен размеру всей таблицы, за вычетом служебной информации в версиях строк и страницах (2309 страниц вместо 2624). В нашем примере на сортировку хватает одной итерации.
Обращение к диску (и запись, и чтение) оценивается как на три четверти последовательное и на одну четверть случайное.
Таким образом стоимость сортировки в нашем плане вычисляется так:
WITH costs(startup) AS (
SELECT 4772.67 + round((
current_setting('cpu_operator_cost')::real * 2 *
214867 * log(2, 214867) +
(current_setting('seq_page_cost')::real * 0.75 +
current_setting('random_page_cost')::real * 0.25) *
2 * 2309 * 1 -- одна итерация
)::numeric, 2)
)
SELECT startup,
startup + round(( current_setting('cpu_operator_cost')::real * 214867
)::numeric, 2) AS total
FROM costs;
startup | total
−−−−−−−−−−+−−−−−−−−−−
31883.96 | 32421.13
(1 row)
Инкрементальная сортировка
Если набор данных требуется отсортировать по ключам K1 ... Km ... Kn, и при этом известно, что набор уже отсортирован по первым нескольким из этих ключей K1 ... Km, то не обязательно пересортировывать весь набор заново. Можно разбить набор данных на группы, имеющие одинаковые значения начальных ключей K1 ... Km (значения таких групп следуют друг за другом), и затем отсортировать отдельно каждую из групп по оставшимся ключам Km+1 ... Kn. Такой способ называется инкрементальной сортировкой. Он доступен начиная с версии PostgreSQL 13.Инкрементальная сортировка уменьшает требования к памяти, разбивая весь набор на несколько меньших групп, а также позволяет начать выдавать результаты после обработки первой группы, не дожидаясь сортировки всего набора.
Реализация действует более тонко: отдельно обрабатываются только относительно крупные группы строк, а небольшие объединяются и сортируются полностью. Это уменьшает накладные расходы на запуск алгоритма сортировки.
В плане выполнения инкрементальная сортировка представлена узлом Incremental Sort:
EXPLAIN (analyze, costs off, timing off, summary off)
SELECT *
FROM bookings
ORDER BY total_amount, book_date;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Incremental Sort (actual rows=2111110 loops=1)
Sort Key: total_amount, book_date
Presorted Key: total_amount
Full−sort Groups: 2823 Sort Method: quicksort Average
Memory: 30kB Peak Memory: 30kB
Pre−sorted Groups: 2624 Sort Method: quicksort Average
Memory: 3152kB Peak Memory: 3259kB
−> Index Scan using bookings_total_amount_idx on bookings (ac...
(8 rows)
Как видно из плана, набор строк уже отсортирован по total_amount, поскольку получен сканированием индекса, построенного по этому столбцу (Presorted Key). Команда EXPLAIN ANALYZE показывает также статистику времени выполнения. Строка Full-sort Groups относится к строкам из небольших групп, которые были объединены и отсортированы полностью, а строка Pre-sorted Groups — к крупным группам, которые досортировывались по столбцу book_date. В обоих случаях использовалась быстрая сортировка в памяти. Наличие групп разного размера вызвано неравномерным распределением стоимости бронирований.
Начиная с версии 14 инкрементальная сортировка может использоваться и для оконных функций:
EXPLAIN (costs off)
SELECT row_number() OVER (ORDER BY total_amount, book_date)
FROM bookings;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
WindowAgg
−> Incremental Sort
Sort Key: total_amount, book_date
Presorted Key: total_amount
−> Index Scan using bookings_total_amount_idx on bookings
(5 rows)
Оценка стоимости. Расчет стоимости инкрементальной сортировки опирается на оценку количества групп и оценку сортировки группы среднего размера (которую мы уже рассмотрели).
Начальная стоимость отражает оценки сортировки одной (первой) группы, после чего узел уже может выдавать отсортированные строки, а полная стоимость учитывает сортировку всех групп:
EXPLAIN SELECT *
FROM bookings
ORDER BY total_amount, book_date;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Incremental Sort (cost=45.10..282293.40 rows=2111110 width=21)
Sort Key: total_amount, book_date
Presorted Key: total_amount
−> Index Scan using bookings_total_amount_idx on bookings (co...
(4 rows)
Подробно останавливаться на вычислении оценок я не буду.
Параллельный режим
Сортировка может выполняться параллельно. Но, хотя рабочие процессы выдают свою часть данных в отсортированном виде, узел Gather ничего не знает про упорядоченность и может объединять данные только в порядке поступления. Чтобы сохранить сортировку, применяется другой узел — Gather Merge.EXPLAIN (analyze, costs off, timing off, summary off)
SELECT *
FROM flights
ORDER BY scheduled_departure
LIMIT 10;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Limit (actual rows=10 loops=1)
−> Gather Merge (actual rows=10 loops=1)
Workers Planned: 1
Workers Launched: 1
−> Sort (actual rows=8 loops=2)
Sort Key: scheduled_departure
Sort Method: top−N heapsort Memory: 27kB
Worker 0: Sort Method: top−N heapsort Memory: 27kB
−> Parallel Seq Scan on flights (actual rows=107434 lo...
(9 rows)
Узел Gather Merge использует двоичную кучу для упорядочения строк, поступающих от нескольких процессов. По сути, выполняется слияние нескольких отсортированных наборов строк, как при внешней сортировке, но алгоритм рассчитан на другие условия работы: на небольшое фиксированное число источников и получение строк по одной, без блочного доступа.
Оценка стоимости. Начальная стоимость узла Gather Merge опирается на начальную стоимость дочернего узла. К ней (как и в случае узла Gather) добавляется стоимость запуска процессов, которая оценивается значением параметра parallel_setup_cost.
Сюда же добавляется оценка построения двоичной кучи, что требует сортировки n значений по числу параллельных процессов (то есть n log2n). Одна операция сравнения оценивается удвоенным значением параметра cpu_operator_cost, и общая сумма обычно пренебрежимо мала, поскольку n невелико.
В полную стоимость входит получение всех данных дочерним узлом, который выполняется несколькими параллельными процессами, и стоимость пересылки строк от этих процессов. Пересылка одной строки оценивается значением параметра parallel_tuple_cost, увеличенным на 5 %, чтобы учесть возможные потери при ожидании получения очередных значений.
В полную стоимость входит также обновление двоичной кучи. Для каждой входящей строки данных это требует log2n операций сравнения и определенных вспомогательных действий (которые оцениваются значением cpu_operator_cost).
Вот еще один пример плана с узлом Gather Merge:
EXPLAIN SELECT amount, count(*)
FROM ticket_flights
GROUP BY amount;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Finalize GroupAggregate (cost=123399.62..123485.00 rows=337 wid...
Group Key: amount
−> Gather Merge (cost=123399.62..123478.26 rows=674 width=14)
Workers Planned: 2
−> Sort (cost=122399.59..122400.44 rows=337 width=14)
Sort Key: amount
−> Partial HashAggregate (cost=122382.07..122385.44 r...
Group Key: amount
−> Parallel Seq Scan on ticket_flights (cost=0.00...
(9 rows)
Этот план интересен тем, что рабочие процессы выполняют частичную агрегацию с помощью хеширования, затем полученные результаты сортируются узлом Sort (это дешево, поскольку после агрегации остается немного строк) и передаются ведущему процессу, который собирает полный результат в узле Gather Merge. Окончательная же агрегация выполняется не хешированием, а по отсортированному списку значений.
В данном случае количество параллельных процессов равно трем (включая основной) и стоимость узла Gather Merge вычисляется так:
WITH costs(startup, run) AS (
SELECT round((
-- запуск процессов
current_setting('parallel_setup_cost')::real +
-- построение кучи
current_setting('cpu_operator_cost')::real * 2 * 3 * log(2, 3)
)::numeric, 2),
round((
-- передача строк
current_setting('parallel_tuple_cost')::real * 1.05 * 674 +
-- обновление кучи
current_setting('cpu_operator_cost')::real * 2 * 674 * log(2, 3) +
current_setting('cpu_operator_cost')::real * 674
)::numeric, 2)
)
SELECT 122399.59 + startup AS startup,
122400.44 + startup + run AS total
FROM costs;
startup | total
−−−−−−−−−−−+−−−−−−−−−−−
123399.61 | 123478.26
(1 row)
Группировка и уникальные значения
Как мы только что видели, группировка значений для агрегации (и устранения дубликатов) может выполняться не только хешированием, но и с помощью сортировки. В отсортированном списке группы повторяющихся значений элементарно выделяются за один проход.Выбор уникальных значений из отсортированного списка представляется в плане очень простым узлом Unique:
EXPLAIN (costs off) SELECT DISTINCT book_ref
FROM bookings
ORDER BY book_ref;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
Result
−> Unique
−> Index Only Scan using bookings_pkey on bookings
(3 rows)
Для агрегации используется другой узел, GroupAggregate:
EXPLAIN (costs off) SELECT book_ref, count(*)
FROM bookings
GROUP BY book_ref
ORDER BY book_ref;
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
GroupAggregate
Group Key: book_ref
−> Index Only Scan using bookings_pkey on bookings
(3 rows)
В параллельных планах такой узел будет называться Partial GroupAggregate, а узел, завершающий агрегацию, — Finalize GroupAggregate.
Начиная с версии PostgreSQL 10 обе стратегии — хеширование и сортировка — могут совмещаться в одном узле при группировке по нескольким наборам (в предложениях GROUPING SETS, CUBE или ROLLUP). Я не буду углубляться в весьма непростые детали алгоритма. Приведу лишь один пример, в котором группировка должна вычисляться по трем разным столбцам в условиях недостаточной памяти:
SET work_mem = '64kB';
EXPLAIN (costs off)
SELECT count(*)
FROM flights
GROUP BY GROUPING SETS (aircraft_code, flight_no, departure_airport);
QUERY PLAN
−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−−
MixedAggregate
Hash Key: departure_airport
Group Key: aircraft_code
Sort Key: flight_no
Group Key: flight_no
−> Sort
Sort Key: aircraft_code
−> Seq Scan on flights
(8 rows)
Вот что происходит при выполнении этого запроса. Узел агрегации, который обозначен в плане как MixedAggregate, получает набор данных, отсортированных по столбцу aircraft_code.
На первом этапе этот набор сканируется и значения группируются по aircraft_code (Group Key). По мере сканирования строки переупорядочиваются по столбцу flight_no (так, как это делает обычный узел Sort: либо быстрой сортировкой в памяти, если ее достаточно, либо внешней сортировкой на диске) и одновременно с этим записываются в хеш-таблицу с ключом departure_airport (так, как это делает агрегация хешированием: либо в памяти, либо с использованием временных файлов).
На втором этапе сканируется набор строк, отсортированный на предыдущем этапе по столбцу flight_no, и значения группируются по этому же столбцу (Sort Key и вложенный Group Key). Если бы требовалась группировка сортировкой по еще одному столбцу, на этом этапе строки бы пересортировались в том порядке, который был бы необходим дальше.
Наконец, сканируется хеш-таблица, подготовленная на первом этапе, и значения группируются по столбцу departure_airport (Hash Key).
Сравнение способов соединения
Итак, для соединения двух наборов данных могут использоваться три разных способа, каждый со своими достоинствами и недостатками.Соединение вложенным циклом не требует никакой подготовительной работы и начинает возвращать результирующие строки сразу же. Это единственный из способов соединения, которому не требуется просматривать внутренний набор полностью, если для него есть эффективный индексный доступ. Эти свойства делают алгоритм вложенного цикла (в сочетании с индексами) идеальным механизмом для коротких OLTP-запросов, которые строятся на небольшой выборке строк.
Недостаток вложенного цикла проявляется с ростом объема данных. Для декартова произведения этот алгоритм имеет квадратичную сложность — затраты пропорциональны произведению размеров соединяемых наборов данных. Декартово произведение нечасто встречается на практике; обычно для каждой строки внешнего набора данных с помощью индекса просматривается некоторое количество строк внутреннего набора, и это среднее количество не зависит от размера всего набора данных (например, среднее количество билетов в одном бронировании не меняется с ростом количества бронирований и купленных билетов). Поэтому часто рост сложности будет линейным, а не квадратичным, хотя и с большим коэффициентом.
Важная особенность вложенного цикла состоит в его универсальности: поддерживаются любые условия соединения, в то время как остальные способы работают только с эквисоединениями. Это дает возможность выполнять любые запросы с любыми условиями (кроме полного соединения, которое не реализуется вложенным циклом), но надо помнить о том, что не-эквисоединение больших объемов будет выполняться заведомо неэффективно.
Соединение хешированием очень эффективно для больших наборов данных. При наличии достаточного объема памяти оно требует однократного просмотра двух наборов данных, то есть имеет линейную сложность. В сочетании с последовательным сканированием таблиц, соединение хешированием часто встречается в OLAP-запросах, вычисляющих результат на основании большого объема данных.
Для ситуаций, в которых время отклика важнее пропускной способности, хеш-соединение подходит хуже, поскольку результирующие строки не могут возвращаться, пока хеш-таблица не построена полностью.
Применение хеш-соединения ограничено эквисоединениями. Кроме того, тип данных должен допускать хеширование (это выполняется почти всегда).
Начиная с версии 14 вложенный цикл может иногда составить конкуренцию соединению хешированием за счет кеширования строк внутреннего набора в узле Memoize (также основанного на хеш-таблице). Выигрыш может достигаться за счет того, что соединение хешированием всегда просматривает внутренний набор строк полностью, а алгоритм вложенного цикла — нет.
Соединение слиянием отлично подходит и для коротких OLTP-запросов, и для длинных запросов OLAP. Оно имеет линейную сложность (требуется однократный просмотр соединяемых наборов строк), не требовательно к памяти и выдает результаты без предварительной подготовки. Единственная сложность состоит в том, что наборы данных должны быть отсортированы в правильном порядке. Наиболее эффективный способ добиться этого — получать данные от индексного сканирования. Это естественный вариант для небольшого количества строк; при большом объеме данных индексный доступ тоже может быть эффективен, если это только индексное сканирование с минимальными обращениями к таблице или вовсе без них.
Если подходящих индексов нет, то наборы данных придется сортировать, а сортировка требует памяти и имеет сложность выше линейной: O(n log2n). В таком случае соединение слиянием почти всегда проигрывает соединению хешированием — за исключением ситуации, когда результат нужен отсортированным.
К приятным свойствам соединения слиянием относится равноценность внешнего и внутреннего наборов строк. Эффективность и вложенного цикла, и хеш-соединения сильно зависит от того, правильно ли планировщик выберет, какой из наборов данных поставить внешним, а какой — внутренним.
Применение соединения слиянием ограничено эквисоединениями. Кроме того, тип данных должен иметь класс операторов для B-дерева.
На графике показана примерная зависимость стоимостей различных способов соединений двух таблиц от доли соединяемых строк.
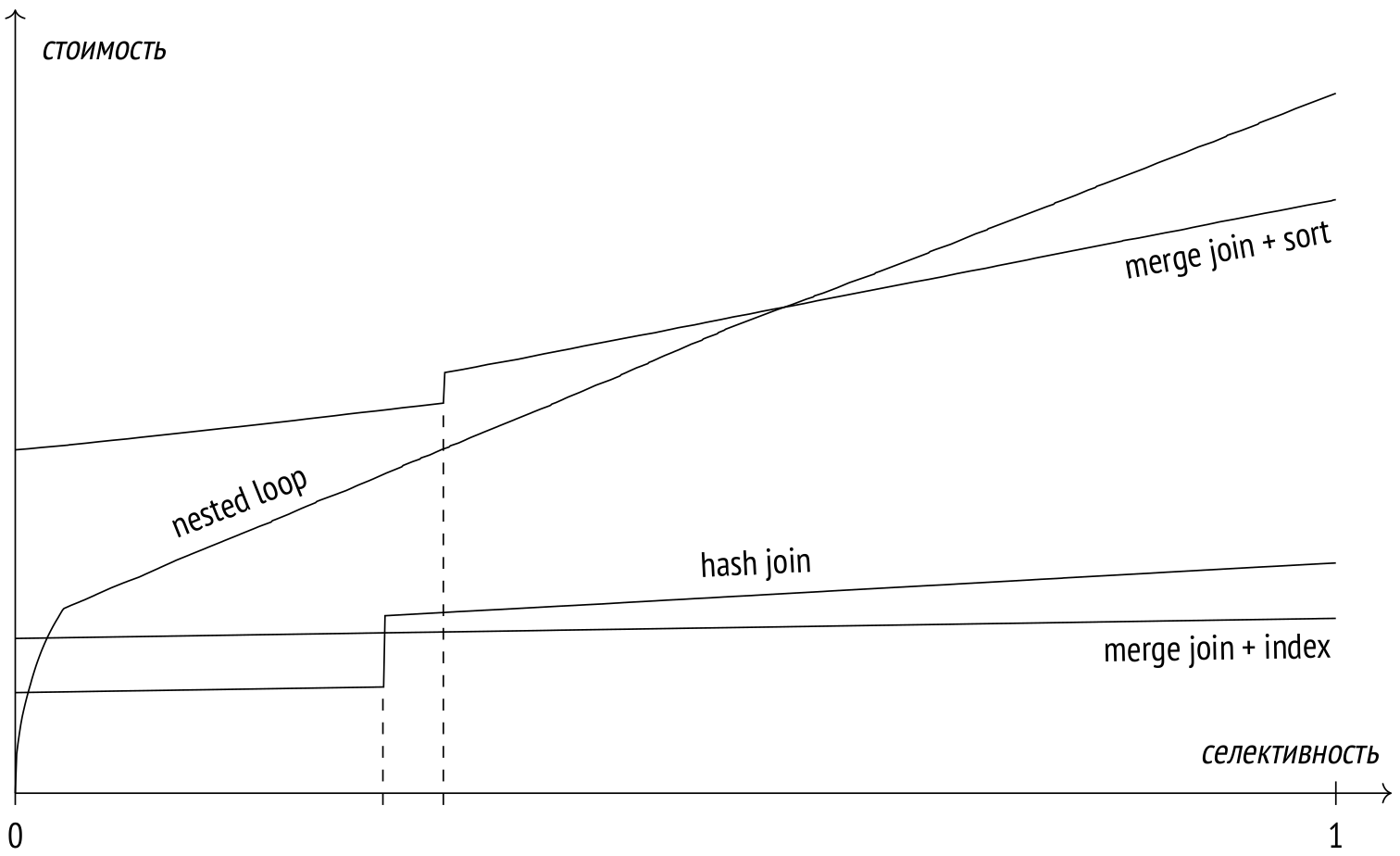
Соединение вложенным циклом при высокой селективности использует индексный доступ к обоим таблицам; затем планировщик переключается на полное сканирование внешней таблицы и график становится линейным.
Соединения хешированием использует в этом примере полное сканирование обоих таблиц. «Ступенька» на графике возникает в тот момент, когда хеш-таблица перестает помещаться в оперативной памяти и пакеты начинают сбрасываться на диск.
Соединение слиянием с использованием индекса показывает небольшой линейный рост стоимости. При достаточном объеме work_mem соединение хешированием обычно оказывается эффективнее, но, когда дело доходит до временных файлов, соединение слиянием выигрывает.
Верхний график соединения слиянием с сортировкой показывает рост стоимости в ситуации, когда индексы недоступны, и данные приходится сортировать. Как и в случае хеширования, «ступенька» на графике вызвана недостатком памяти и необходимостью использовать для сортировки временные файлы.
Это только пример; в каждом конкретном случае соотношения стоимостей, разумеется, будут отличаться.
Запросы в PostgreSQL: 7. Сортировка и слияние
В предыдущих статьях я писал про этапы выполнения запросов , про статистику , про два основных вида доступа к данным — последовательное сканирование и индексное сканирование , — и успел рассказать о...
 habr.com
habr.com