Разработчики программного обеспечения обожают абстракции, поскольку писать код только с помощью «1» и «0» довольно утомительно. Однако когда абстракции вводятся преждевременно, то есть до решения реальной, а не теоретической задачи, возникают проблемы. Если абстракций слишком много, снижается скорость разработки, а сложность восприятия кодовой базы возрастает.
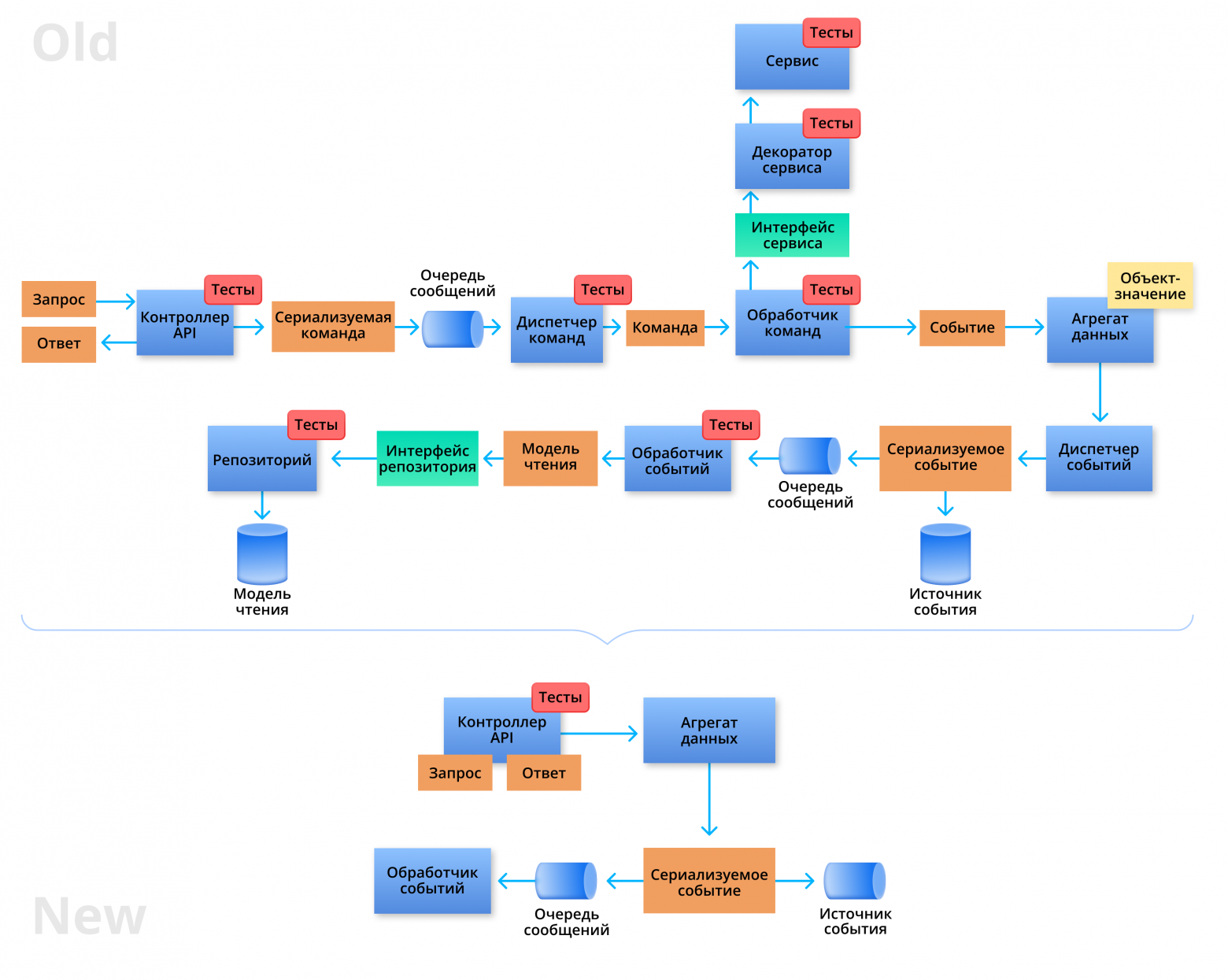
В этой статье я расскажу, как трансформировались взгляды моей команды на разработку микросервисов, и какую роль в этом сыграло избавление от излишних абстракций. Благодаря нашему новому подходу размер стандартного компонента бизнес-логики микросервиса — например, метода для чтения или изменения данных в новом микросервисе, — уменьшился с приблизительно 25 до всего 5 файлов, то есть на 80 %. При этом большая часть кода была просто удалена, что одновременно улучшило его удобочитаемость.
Параллельно с этим я рассмотрю некоторые конкретные случаи преждевременного применения абстракций, которые часто встречаются на практике. Все они основаны на реальных примерах из наших собственных кодовых баз.
Как правило, это делается для удовлетворения входящего в SOLID популярного принципа единственной ответственности — у каждого класса есть чётко сформулированное назначение и функциональность, соответственно, может быть только одна причина для изменения его кода. Если разделить все крошечные фрагменты логики на отдельные классы, каждый из них будет наделен очень четкими зонами ответственности, то есть будет иметь только одно назначение, и, следовательно, только одну причину для изменения. Отлично, не так ли? Проблема в том, что все эти мелкие фрагменты, как правило, по-прежнему обладают сильной связанностью (coupling) и зависят друг от друга. Если какая-либо связь между этими фрагментами меняется, это часто приводит к каскадному эффекту, требующему изменений во многих из этих фрагментов. Таким образом, хотя каждый из них имеет только одну причину для изменения, единственная ответственность теряет значение, поскольку одно изменение часто влечёт за собой переписывание многих фрагментов, делая модификацию кода чрезвычайно трудной задачей.
Кроме того, наличие классов, которые меняются только по одной причине, зачастую не имеет реальных практических преимуществ. Фактически внесение изменений в классы, которые выполняют несколько функций, часто предоставляет разработчику гораздо больше контекста, что значительно упрощает понимание изменения и его влияния на окружающий код.
Так когда же мы должны разделять области ответственности? Распространенный и очень верный случай — это когда бизнес-логика должна использоваться более чем в одном месте. Если один и тот же HTTP-запрос или запрос к базе данных происходит в нескольких местах кода, дублирование логики часто снижает удобство поддержки. В таком случае, вероятно, будет хорошей идеей перенести эту логику в общий и многократно используемый компонент. Главное — не делать этого до тех пор, пока это не потребуется. Другой допустимый случай — это когда бизнес-логика очень сложна и отрицательно влияет на удобочитаемость окружающего кода. Например, если фрагмент бизнес-логики занимает сразу 300 строк кода. Напротив, разделение ответственности для кода в несколько строк, вероятно, только ухудшит удобочитаемость и ориентирование по нему. Помните, что разделение ответственности всегда увеличивает структурную сложность кода.
Ниже показано, как изменение нашего подхода к разграничению зон ответственности между классами повлияло на исходную архитектуру, представленную в верхней части поста. В левой части видно, что логика класса HTTP-клиента к сервису переносится непосредственно в обработчик команд, которому нужна эта логика. Справа показано, что запрос к базе данных перемещается из репозитория непосредственно в обработчик событий, которому нужен этот запрос.
 В левой части рисунка логика класса HTTP-клиента к сервису переносится непосредственно в обработчик команд, которому эта логика нужна. Справа запрос к базе данных перемещается из репозитория непосредственно в обработчик событий, которому нужен этот запрос. Изображение предоставлено автором.
В левой части рисунка логика класса HTTP-клиента к сервису переносится непосредственно в обработчик команд, которому эта логика нужна. Справа запрос к базе данных перемещается из репозитория непосредственно в обработчик событий, которому нужен этот запрос. Изображение предоставлено автором.
Хорошим примером этого является шаблон «Декоратор». Он часто используется для добавления дополнительных функциональных возможностей к существующему компоненту бизнес-логики. Это может быть компонент, выполняющий HTTP-запрос, к которому необходимо добавить механизм повтора. Для этого можно, не изменяя исходный компонент, обернуть его в новый компонент с добавленной поверх логикой повторного выполнения запросов. Реализуя тот же интерфейс, исходный компонент можно заменить на новый непосредственно в коде или посредством внедрения зависимостей.
Поначалу это кажется отличной идеей. Не нужно изменять какой-либо существующий код, каждый его фрагмент можно легко понимать и тестировать по отдельности. Но огромный недостаток заключается в том, что снова теряется связность. Если позже разработчик посмотрит на исходный компонент или код, использующий этот компонент, он не сразу поймет, что происходит при выполнении кода, поскольку добавленная логика будет от него скрыта. Я видел реальные случаи, когда логика повторных запросов добавлялась непосредственно в класс, а позже выяснялось, что он уже обёрнут в декоратор, выполняющий повторные запросы. В результате при развертывании сервиса все заканчивалось множественными повторами вызова. Такое происходит только когда не сразу ясно, как ведет себя код.
Другими широко используемыми шаблонами проектирования являются паттерн «Команда» и паттерн «Издатель — Подписчик». В данном случае класс, вместо того, чтобы обрабатывать запрос напрямую, абстрагирует его в команду, которая обрабатывается где-то в другом месте. Примером может служить контроллер API, отображающий HTTP-запросы в команды и передающий их для обработки соответствующему обработчику, который подписан на эту конкретную команду. Это обеспечивает слабую связанность и четкое разделение между фрагментом кода, который получает и интерпретирует запросы, и фрагментом, который знает, как обрабатывать запрос конкретного типа. Конечно, существуют допустимые варианты использования этого шаблона. Однако стоит задуматься, не является ли он на практике просто лишним уровнем косвенности. Который, кроме того, затрудняет отслеживание путь исполнения программы, поскольку издатель, согласно определению шаблона, не знает, где заканчивается обработка команды.
Это всего лишь несколько примеров шаблонов проектирования, которые часто используются преждевременно. То же самое можно сказать практически о любом шаблоне. У каждого из них есть свои недостатки, поэтому используйте шаблоны только тогда, когда это действительно необходимо и польза перевешивает недостатки. Ниже вновь показано, как отказ от ненужных шаблонов проектирования повлиял на нашу исходную архитектуру. Слева удаляется паттерн «Декоратор», а справа исчезает весь командный поток, включая механизм публикации и подписки.
 Удаление преждевременно введенных шаблонов проектирования. Слева удален паттерн «Декоратор». Справа удалены паттерн «Команда» и паттерн «Издатель – Подписчик». Изображение предоставлено автором.
Удаление преждевременно введенных шаблонов проектирования. Слева удален паттерн «Декоратор». Справа удалены паттерн «Команда» и паттерн «Издатель – Подписчик». Изображение предоставлено автором.
Оптимизация также может выполняться на уровне архитектуры. Одним из примеров является шаблон разделения ответственности команд и запросов (CQRS). По сути, CQRS подразумевает, что у нас имеются две отдельные модели данных: одна для модификации данных, а другая для их чтения, что разделяет приложение на части чтения и записи. Это позволяет оптимизировать одну часть для эффективного чтения, а другую — для эффективной записи, а также масштабировать одну часть в зависимости от того, загружено ли приложение чтением или записью.
Огромным недостатком этой схемы является необходимость строить и поддерживать отдельную модель данных, что приводит к серьезным затратам ресурсов разработки. Если требуется производительность, такой компромисс может быть вполне приемлемым. Однако я редко вижу, чтобы повышение эффективности чтения или записи давало какое-либо измеримое преимущество даже для приложений с миллионами пользователей. Более разумный подход — использовать единственную модель и для чтения, и для записи, а оптимизированные модели чтения создавать только для отдельных случаев, когда известно, что простой подход не будет работать должным образом.
Ниже показано удаление отдельного тракта обработки запросов на чтение из потока выполнения нашего приложения. Теперь запросы, не изменяющие данные, извлекают их не из модели чтения, созданной поверх специальной таблицы СУБД, а напрямую из источника событий, который в нашем примере является местом изначальной записи данных.
[IMG alt="Удаление всей части приложения, выделенной для чтения с целью применения единой модели для чтения и записи. Изображение предоставлено автором.
"]https://habrastorage.org/r/w1560/ge...00dfe9a81eab2526c92f255f542.jpg[/IMG]Удаление всей части приложения, выделенной для чтения с целью применения единой модели для чтения и записи. Изображение предоставлено автором.
Низкая связанность обычно обеспечивается за счет реализации принципов инверсии зависимостей и открытости/закрытости из перечня SOLID. Они гласят, что сущности должны зависеть от абстракций, а не от конкретных реализаций, а также быть открытыми для расширения и закрытыми для модификаций. На практике это часто достигается путём абстрагирования классов в интерфейсы и внедрением зависимостей от этих интерфейсов, а не от конкретных классов.
В рамках отдельного изолированного компонента бизнес-логики не стоит стремиться к достижению низкой связанности и выделять интерфейсы у всех внутренних элементов этого компонента: обеспечение низкой связанности связано с высокими издержками. Низкая связанность, и в особенности интерфейсы, делают код менее «сфокусированным» и усложняют ориентирование в нем, поскольку с первого взгляда невозможно разобраться, какой именно код будет выполняться. Вместо этого сначала нужно выяснить, какие реализации интерфейса существуют, а затем понять, какая из них фактически используется во время исполнения. Кроме того, интерфейс — это еще один файл, который необходимо добавить в проект и поддерживать в актуальном состоянии при каждом изменении сигнатуры конкретной реализации.
Интерфейсы решают множество проблем, но вводить их следует, только когда они необходимы для решения реальной практической проблемы, а не просто для достижения низкой связанности. Обычно интерфейсы необходимы, если нужно иметь возможность заменить реализацию или создать внешние библиотеки для сторонних пользователей без возможности модифицировать кодовую базу конкретной библиотеки. Кроме того, если вы используете интерфейсы только для создания «моков» в юнит-тестах, серьезно задумайтесь о переходе на фреймворк тестирования, который позволяет создавать заглушки для конкретных классов без лишних накладных расходов.
Ниже показан пример удаления двух интерфейсов, в результате чего обработчик команд и обработчик событий получают прямые ссылки на конкретные реализации репозитория и класса сервиса.
 Удаление ненужных интерфейсов. Интерфейс для репозитория представлен слева, а интерфейс для класса обслуживания — справа. Изображение предоставлено автором.
Удаление ненужных интерфейсов. Интерфейс для репозитория представлен слева, а интерфейс для класса обслуживания — справа. Изображение предоставлено автором.
Важно, чтобы фрагменты кода, изменяемые совместно, были расположены как можно ближе друг к другу, чтобы эти изменения проходили без проблем. Обычно бывает, что изменение влияет сразу на несколько классов, поскольку они относятся к одному и тому же компоненту бизнес-логики, а не к определенному типу. По сути, в таком случае предпочтение отдается архитектуре вертикального среза (Vertical Slice Architecture), а не более классической «луковой» архитектуре, поскольку типичные изменения носят «вертикальный», а не «горизонтальный» характер. В такой ситуации полезно группировать классы в папках по признаку принадлежности к одному компоненту бизнес-логики, а не к одному типу.
В нашем примере архитектуры этот подход можно проиллюстрировать с помощью перемещения классов запроса и ответа непосредственно в тот же файл, где расположен и контроллер, который на входе принимает запрос, а на выходе возвращает ответ. Это хороший пример очень тесно связанных классов, которые часто изменяются вместе. Если разместить их в одном файле, то можно будет видеть компонент целиком, без необходимости переключаться между файлами. Здесь важно отметить, что каждому методу API-сервиса соответствует свой собственный контроллер. Таким образом, каждый файл оказывается связан только с одним компонентом бизнес-логики сервиса и ни с каким другим.
[IMG alt="Объединение в один файл тесно связанных классов, таких как запрос, ответ и контроллер. В этом файле будет содержаться вся логика обработки запросов. Другими словами, на один класс контроллера приходится только одна конечная точка. Изображение предоставлено автором.
"]https://habrastorage.org/r/w1560/ge...a5ae16a70992001f02c958f1.jpg[/IMG]Объединение в один файл тесно связанных классов, таких как запрос, ответ и контроллер. В этом файле будет содержаться вся логика обработки запросов. Другими словами, на один класс контроллера приходится только одна конечная точка. Изображение предоставлено автором.
С учетом всех этих улучшений, рефакторинг и перемещение фрагментов кода должны стать легкой задачей. Однако при частом рефакторинге по-прежнему остается одна проблема — наличие отдельных юнит-тестов для классов, все зависимости которых «мокаются». Этот тип автоматизированного тестирования заставляет каждый класс вести себя и взаимодействовать с другими классами очень специфичным образом, поскольку в данном случае, по сути, тестируется реализация, а не поведение. Это означает, что каждый раз, когда юнит-тесты класса меняются, часто приходится обновлять и другие юнит-тесты, в которых данный класс «замокан». Это не очень удобно, если изменение представляет собой чисто структурный рефакторинг, например, перенос некоторого фрагмента логики в переиспользуемый компонент, притом что внешнее поведение кодовой базы не меняется.
По этой причине мы полностью отказались от подобных юнит-тестов и выбрали совершенно другой подход к автоматизированному тестированию. Он позволяет нам быстро выполнять все виды внутреннего рефакторинга, не обновляя ни одного теста. Но это уже тема отдельного поста, который можно прочитать здесь.
Применение вышеупомянутых принципов и удалению преждевременных абстракций привело к улучшению нашей архитектуры.

Теперь взгляните на свой код. Содержит ли он преждевременные абстракции, которые можно удалить? В хорошей кодовой базе выполнять простые изменения и рефакторинг легко и очень быстро. Проверьте свои последние PR'ы и сопоставьте их размер с тем, что было реально достигнуто с их помощью.

 habr.com
habr.com
В этой статье я расскажу, как трансформировались взгляды моей команды на разработку микросервисов, и какую роль в этом сыграло избавление от излишних абстракций. Благодаря нашему новому подходу размер стандартного компонента бизнес-логики микросервиса — например, метода для чтения или изменения данных в новом микросервисе, — уменьшился с приблизительно 25 до всего 5 файлов, то есть на 80 %. При этом большая часть кода была просто удалена, что одновременно улучшило его удобочитаемость.
Параллельно с этим я рассмотрю некоторые конкретные случаи преждевременного применения абстракций, которые часто встречаются на практике. Все они основаны на реальных примерах из наших собственных кодовых баз.
Распространенные преждевременные абстракции
1. Слишком детальное разделение зон ответственности
Одна из основных причин появления сложного исходного кода — слишком детальное разделение ответственности. В качестве примера можно привести применение шаблона проектирования «Репозиторий» для абстрагирования запросов, выполняющих CRUD-операции над сущностями в базе данных. Нередко практикуется выделение в отдельный класс HTTP-клиента, выполняющего запросы к определённому сервису. В общем же случае речь идёт о перенесении некоторой части внутренней логики в отдельный компонент.Как правило, это делается для удовлетворения входящего в SOLID популярного принципа единственной ответственности — у каждого класса есть чётко сформулированное назначение и функциональность, соответственно, может быть только одна причина для изменения его кода. Если разделить все крошечные фрагменты логики на отдельные классы, каждый из них будет наделен очень четкими зонами ответственности, то есть будет иметь только одно назначение, и, следовательно, только одну причину для изменения. Отлично, не так ли? Проблема в том, что все эти мелкие фрагменты, как правило, по-прежнему обладают сильной связанностью (coupling) и зависят друг от друга. Если какая-либо связь между этими фрагментами меняется, это часто приводит к каскадному эффекту, требующему изменений во многих из этих фрагментов. Таким образом, хотя каждый из них имеет только одну причину для изменения, единственная ответственность теряет значение, поскольку одно изменение часто влечёт за собой переписывание многих фрагментов, делая модификацию кода чрезвычайно трудной задачей.
Кроме того, наличие классов, которые меняются только по одной причине, зачастую не имеет реальных практических преимуществ. Фактически внесение изменений в классы, которые выполняют несколько функций, часто предоставляет разработчику гораздо больше контекста, что значительно упрощает понимание изменения и его влияния на окружающий код.
Так когда же мы должны разделять области ответственности? Распространенный и очень верный случай — это когда бизнес-логика должна использоваться более чем в одном месте. Если один и тот же HTTP-запрос или запрос к базе данных происходит в нескольких местах кода, дублирование логики часто снижает удобство поддержки. В таком случае, вероятно, будет хорошей идеей перенести эту логику в общий и многократно используемый компонент. Главное — не делать этого до тех пор, пока это не потребуется. Другой допустимый случай — это когда бизнес-логика очень сложна и отрицательно влияет на удобочитаемость окружающего кода. Например, если фрагмент бизнес-логики занимает сразу 300 строк кода. Напротив, разделение ответственности для кода в несколько строк, вероятно, только ухудшит удобочитаемость и ориентирование по нему. Помните, что разделение ответственности всегда увеличивает структурную сложность кода.
Ниже показано, как изменение нашего подхода к разграничению зон ответственности между классами повлияло на исходную архитектуру, представленную в верхней части поста. В левой части видно, что логика класса HTTP-клиента к сервису переносится непосредственно в обработчик команд, которому нужна эта логика. Справа показано, что запрос к базе данных перемещается из репозитория непосредственно в обработчик событий, которому нужен этот запрос.
2. Использование шаблонов проектирования без реальной пользы
Еще одна распространенная ошибка — внедрение различных шаблонов проектирования до того, как это действительно необходимо. Шаблоны проектирования отлично подходят для решения конкретных проблем в кодовой базе и при определенных обстоятельствах могут снизить общую сложность. Тем не менее, почти все они имеют обратную сторону — повышение структурной сложности и понижение связности (cohesion/coherence) в кодовой базе проекта.Хорошим примером этого является шаблон «Декоратор». Он часто используется для добавления дополнительных функциональных возможностей к существующему компоненту бизнес-логики. Это может быть компонент, выполняющий HTTP-запрос, к которому необходимо добавить механизм повтора. Для этого можно, не изменяя исходный компонент, обернуть его в новый компонент с добавленной поверх логикой повторного выполнения запросов. Реализуя тот же интерфейс, исходный компонент можно заменить на новый непосредственно в коде или посредством внедрения зависимостей.
Поначалу это кажется отличной идеей. Не нужно изменять какой-либо существующий код, каждый его фрагмент можно легко понимать и тестировать по отдельности. Но огромный недостаток заключается в том, что снова теряется связность. Если позже разработчик посмотрит на исходный компонент или код, использующий этот компонент, он не сразу поймет, что происходит при выполнении кода, поскольку добавленная логика будет от него скрыта. Я видел реальные случаи, когда логика повторных запросов добавлялась непосредственно в класс, а позже выяснялось, что он уже обёрнут в декоратор, выполняющий повторные запросы. В результате при развертывании сервиса все заканчивалось множественными повторами вызова. Такое происходит только когда не сразу ясно, как ведет себя код.
Другими широко используемыми шаблонами проектирования являются паттерн «Команда» и паттерн «Издатель — Подписчик». В данном случае класс, вместо того, чтобы обрабатывать запрос напрямую, абстрагирует его в команду, которая обрабатывается где-то в другом месте. Примером может служить контроллер API, отображающий HTTP-запросы в команды и передающий их для обработки соответствующему обработчику, который подписан на эту конкретную команду. Это обеспечивает слабую связанность и четкое разделение между фрагментом кода, который получает и интерпретирует запросы, и фрагментом, который знает, как обрабатывать запрос конкретного типа. Конечно, существуют допустимые варианты использования этого шаблона. Однако стоит задуматься, не является ли он на практике просто лишним уровнем косвенности. Который, кроме того, затрудняет отслеживание путь исполнения программы, поскольку издатель, согласно определению шаблона, не знает, где заканчивается обработка команды.
Это всего лишь несколько примеров шаблонов проектирования, которые часто используются преждевременно. То же самое можно сказать практически о любом шаблоне. У каждого из них есть свои недостатки, поэтому используйте шаблоны только тогда, когда это действительно необходимо и польза перевешивает недостатки. Ниже вновь показано, как отказ от ненужных шаблонов проектирования повлиял на нашу исходную архитектуру. Слева удаляется паттерн «Декоратор», а справа исчезает весь командный поток, включая механизм публикации и подписки.
3. Преждевременная оптимизация производительности
Для любого разработчика очень важно, чтобы создаваемое им программное обеспечение отличалось хорошей производительностью. При этом самое четкое и простое решение проблемы зачастую оказывается наиболее эффективным. Однако иногда это не совсем так. В подобных случаях затраты на оптимизацию должны сопоставляться с реальной практической пользой, которую ожидают получить. Издержки, которые необходимо учитывать, включают время, затрачиваемое на анализ, внедрение и поддержку оптимизации, а также потенциальное снижение удобочитаемости кода из-за применения более сложного подхода для достижения эффективности. Не жертвуйте удобочитаемостью кода ради излишней эффективности и помните, что затраты времени разработчика зачастую намного превышают потенциальную выгоду от экономии вычислительных ресурсов за счет микрооптимизации кода.Оптимизация также может выполняться на уровне архитектуры. Одним из примеров является шаблон разделения ответственности команд и запросов (CQRS). По сути, CQRS подразумевает, что у нас имеются две отдельные модели данных: одна для модификации данных, а другая для их чтения, что разделяет приложение на части чтения и записи. Это позволяет оптимизировать одну часть для эффективного чтения, а другую — для эффективной записи, а также масштабировать одну часть в зависимости от того, загружено ли приложение чтением или записью.
Огромным недостатком этой схемы является необходимость строить и поддерживать отдельную модель данных, что приводит к серьезным затратам ресурсов разработки. Если требуется производительность, такой компромисс может быть вполне приемлемым. Однако я редко вижу, чтобы повышение эффективности чтения или записи давало какое-либо измеримое преимущество даже для приложений с миллионами пользователей. Более разумный подход — использовать единственную модель и для чтения, и для записи, а оптимизированные модели чтения создавать только для отдельных случаев, когда известно, что простой подход не будет работать должным образом.
Ниже показано удаление отдельного тракта обработки запросов на чтение из потока выполнения нашего приложения. Теперь запросы, не изменяющие данные, извлекают их не из модели чтения, созданной поверх специальной таблицы СУБД, а напрямую из источника событий, который в нашем примере является местом изначальной записи данных.
[IMG alt="Удаление всей части приложения, выделенной для чтения с целью применения единой модели для чтения и записи. Изображение предоставлено автором.
"]https://habrastorage.org/r/w1560/ge...00dfe9a81eab2526c92f255f542.jpg[/IMG]Удаление всей части приложения, выделенной для чтения с целью применения единой модели для чтения и записи. Изображение предоставлено автором.
4. Повсеместное внедрение слабой связанности
В кодовой базе со слабой связанностью каждая часть максимально независима от других частей. Благодаря слабой связанности изменения в одной части оказывают минимальное влияние на другие части, что упрощает замену фрагментов кода, поскольку они минимально зависят друг от друга. Хорошими примерами этого являются внешние библиотеки или модули, которые используются несколькими различными кодовыми базами. Нам не нужно, чтобы изменения в функциональности библиотеки затронули использующие ее кодовые базы больше, чем необходимо. При этом было бы удобно иметь возможность заменить эту библиотеку, если потребуется.Низкая связанность обычно обеспечивается за счет реализации принципов инверсии зависимостей и открытости/закрытости из перечня SOLID. Они гласят, что сущности должны зависеть от абстракций, а не от конкретных реализаций, а также быть открытыми для расширения и закрытыми для модификаций. На практике это часто достигается путём абстрагирования классов в интерфейсы и внедрением зависимостей от этих интерфейсов, а не от конкретных классов.
В рамках отдельного изолированного компонента бизнес-логики не стоит стремиться к достижению низкой связанности и выделять интерфейсы у всех внутренних элементов этого компонента: обеспечение низкой связанности связано с высокими издержками. Низкая связанность, и в особенности интерфейсы, делают код менее «сфокусированным» и усложняют ориентирование в нем, поскольку с первого взгляда невозможно разобраться, какой именно код будет выполняться. Вместо этого сначала нужно выяснить, какие реализации интерфейса существуют, а затем понять, какая из них фактически используется во время исполнения. Кроме того, интерфейс — это еще один файл, который необходимо добавить в проект и поддерживать в актуальном состоянии при каждом изменении сигнатуры конкретной реализации.
Интерфейсы решают множество проблем, но вводить их следует, только когда они необходимы для решения реальной практической проблемы, а не просто для достижения низкой связанности. Обычно интерфейсы необходимы, если нужно иметь возможность заменить реализацию или создать внешние библиотеки для сторонних пользователей без возможности модифицировать кодовую базу конкретной библиотеки. Кроме того, если вы используете интерфейсы только для создания «моков» в юнит-тестах, серьезно задумайтесь о переходе на фреймворк тестирования, который позволяет создавать заглушки для конкретных классов без лишних накладных расходов.
Ниже показан пример удаления двух интерфейсов, в результате чего обработчик команд и обработчик событий получают прямые ссылки на конкретные реализации репозитория и класса сервиса.
Дополнительные советы для искателей приключений
Если хочется пойти еще дальше, можно провести эксперимент и перенести отдельные классы в один файл. Если классы тесно связаны, созависимы и часто изменяются вместе, это может повысить как удобство поддержки, так и понимание контекста при внесении изменений. Тем не менее, если класс будет развиваться и увеличиваться в размере, будьте готовы переместить его в отдельный файл, чтобы не снижать читаемость кода.Важно, чтобы фрагменты кода, изменяемые совместно, были расположены как можно ближе друг к другу, чтобы эти изменения проходили без проблем. Обычно бывает, что изменение влияет сразу на несколько классов, поскольку они относятся к одному и тому же компоненту бизнес-логики, а не к определенному типу. По сути, в таком случае предпочтение отдается архитектуре вертикального среза (Vertical Slice Architecture), а не более классической «луковой» архитектуре, поскольку типичные изменения носят «вертикальный», а не «горизонтальный» характер. В такой ситуации полезно группировать классы в папках по признаку принадлежности к одному компоненту бизнес-логики, а не к одному типу.
В нашем примере архитектуры этот подход можно проиллюстрировать с помощью перемещения классов запроса и ответа непосредственно в тот же файл, где расположен и контроллер, который на входе принимает запрос, а на выходе возвращает ответ. Это хороший пример очень тесно связанных классов, которые часто изменяются вместе. Если разместить их в одном файле, то можно будет видеть компонент целиком, без необходимости переключаться между файлами. Здесь важно отметить, что каждому методу API-сервиса соответствует свой собственный контроллер. Таким образом, каждый файл оказывается связан только с одним компонентом бизнес-логики сервиса и ни с каким другим.
[IMG alt="Объединение в один файл тесно связанных классов, таких как запрос, ответ и контроллер. В этом файле будет содержаться вся логика обработки запросов. Другими словами, на один класс контроллера приходится только одна конечная точка. Изображение предоставлено автором.
"]https://habrastorage.org/r/w1560/ge...a5ae16a70992001f02c958f1.jpg[/IMG]Объединение в один файл тесно связанных классов, таких как запрос, ответ и контроллер. В этом файле будет содержаться вся логика обработки запросов. Другими словами, на один класс контроллера приходится только одна конечная точка. Изображение предоставлено автором.
Выполняйте рефакторинг только при необходимости
Теперь, когда мы больше не создаем абстракции преждевременно, важно рассмотреть рефакторинг как естественную причину внесения изменений в кодовую базу сервиса. Если внезапно потребовалась применить фрагмент бизнес-логики в нескольких местах, значит, нужно абстрагировать ее в отдельный многократно используемый компонент. Если возникла потребность в замене реализации некоторой бизнес-логики, значит, пора добавить интерфейс. Избегать преждевременных абстракций не значит отказаться от них вообще. Их просто нужно добавлять, когда возникает реальная необходимость. Это ни в коем случае не является оправданием для написания неуклюжего спагетти-кода.С учетом всех этих улучшений, рефакторинг и перемещение фрагментов кода должны стать легкой задачей. Однако при частом рефакторинге по-прежнему остается одна проблема — наличие отдельных юнит-тестов для классов, все зависимости которых «мокаются». Этот тип автоматизированного тестирования заставляет каждый класс вести себя и взаимодействовать с другими классами очень специфичным образом, поскольку в данном случае, по сути, тестируется реализация, а не поведение. Это означает, что каждый раз, когда юнит-тесты класса меняются, часто приходится обновлять и другие юнит-тесты, в которых данный класс «замокан». Это не очень удобно, если изменение представляет собой чисто структурный рефакторинг, например, перенос некоторого фрагмента логики в переиспользуемый компонент, притом что внешнее поведение кодовой базы не меняется.
По этой причине мы полностью отказались от подобных юнит-тестов и выбрали совершенно другой подход к автоматизированному тестированию. Он позволяет нам быстро выполнять все виды внутреннего рефакторинга, не обновляя ни одного теста. Но это уже тема отдельного поста, который можно прочитать здесь.
Применение вышеупомянутых принципов и удалению преждевременных абстракций привело к улучшению нашей архитектуры.
Заключение
Мы рассмотрели четыре распространенных типа преждевременных абстракций, которые часто встречаются в кодовых базах и привносят в них излишнюю сложность. Все эти абстракции имеют веские причины для использования, но если они вводятся преждевременно и не дают реальной пользы на практике, возникает проблема. Существует еще много примеров, подобных тем, которые перечислены в этом посте. Самый важный вывод, который можно сделать, — нужно изменить подход к разработке и приучить себя строго анализировать каждый фрагмент собственного кода. Каждый раз, когда вы собираетесь ввести еще одну абстракцию, спросите себя и коллег, действительно ли она обеспечит вам ту выгоду, которую вы ищете, или от абстракции можно без проблем отказаться. Увеличивать сложность кодовой базы только исходя из теоретических предпосылок, например, чтобы «разделить зоны ответственности» и «устранить зависимость от конкретных реализаций», просто необоснованно. Каждый раз увеличение сложности должно происходить исходя из конкретной, реальной, практической пользы.Теперь взгляните на свой код. Содержит ли он преждевременные абстракции, которые можно удалить? В хорошей кодовой базе выполнять простые изменения и рефакторинг легко и очень быстро. Проверьте свои последние PR'ы и сопоставьте их размер с тем, что было реально достигнуто с их помощью.
Зарубежный опыт: как избавиться от 80% кода, увеличить скорость разработки и уменьшить количество ошибок
Мы продолжаем знакомить читателей нашего блога с интересными международными публикациями. Ранее мы перевели материал с практическими советами по обучению для ИТ-специалистов , сегодня же коснемся темы...
habr.com