Начало работы с PromQL может быть непростым, если вы только начинаете свое путешествие в увлекательный мир Prometheus. Это руководство поможет понять принципы его работы, статья включает интересные и полезные советы, необходимые для начала работы.Скачать Cheatsheet по запросам PromQL
Поскольку Prometheus хранит данные в виде временных рядов (time-series data model), запросы PromQL радикально отличаются от привычного SQL. Понимание, как работать с данными в Prometheus, является ключом к тому, чтобы научиться писать эффективные запросы.
Не забудьте скачать Cheatsheet по запросам PromQL!
Как работают time-series databases
Временные ряды — это потоки значений, связанных с меткой времени.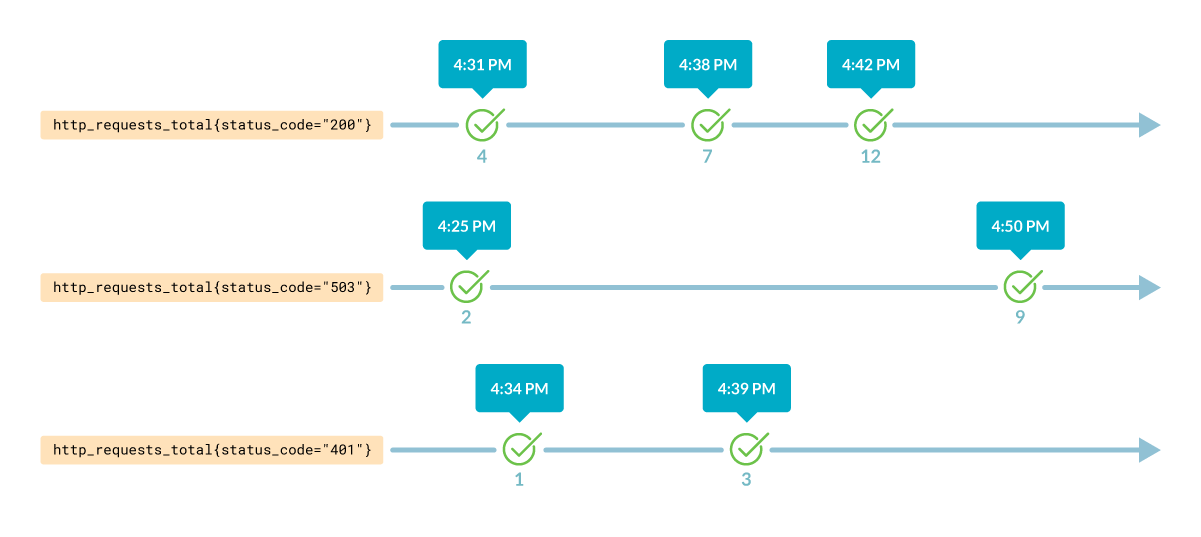
Каждый временной ряд можно идентифицировать по названию метрики и меткам, например:
mongodb_up{}
или
kube_node_labels{cluster="aws-01", label_kubernetes_io_role="master"}
В приведенном выше примере присутствует имя метрики (kube_node_labels) и метки (cluster и label_kubernetes_io_role). На самом деле, метрики тоже являются метками. Приведенный выше запрос можно записать так:
{__name__ = "kube_node_labels", cluster="aws-01", label_kubernetes_io_role="master"}
В Prometheus есть четыре типа метрик:
- Gauges (Измеритель) — значения, которые могут меняться. Например, метрика mongodb_up позволяет узнать, есть ли у exporter соединение с экземпляром MongoDB.
- Counters (Счетчик) показывают суммарные значения и обычно имеют суффикс _total. Например, http_requests_total.
- Histogram (Гистограмма) — это комбинация различных счетчиков, используется для отслеживания размерных показателей и их продолжительности, таких как длительность запросов.
- Summary (Сводка) работает как гистограмма, но также рассчитывает квантили.
Знакомство с выборкой данных PromQL
Выбрать данные в PromQL так же просто, как указать метрику, из которой вы хотите получить данные. В этом примере мы будем использовать метрику http_requests_total.Допустим, мы хотим узнать количество запросов по пути / api на хосте 10.2.0.4. Для этого мы будем использовать метки host и path из этой метрики:
http_requests_total{host="10.2.0.4", path="/api"}
Запрос вернет следующие значения:
| name | host | path | status_code | value |
| http_requests_total | 10.2.0.4 | /api | 200 | 98 |
| http_requests_total | 10.2.0.4 | /api | 503 | 20 |
| http_requests_total | 10.2.0.4 | /api | 401 | 1 |
Это называется instant vector, самое раннее значение для каждого потока на указанный в запросе момент времени. Поскольку семплы берутся в случайное время, Prometheus округляет результаты. Если длительность не указана, то возвращается последнее доступное значение.

Кроме того, вы можете получить instant vector из другого отрезка времени (например, день назад).
Для этого вам нужно добавить offset (смещение), например:
http_requests_total{host="10.2.0.4", path="/api", status_code="200"} offset 1d
Чтобы получить значение метрики в пределах указанного отрезка времени, необходимо указать его в скобках:
http_requests_total{host="10.2.0.4", path="/api"}[10m]
Запрос вернет следующие значения:
| name | host | path | status_code | value |
| http_requests_total | 10.2.0.4 | /api | 200 | 641309@1614690905.515 641314@1614690965.515 641319@1614691025.502 |
| http_requests_total | 10.2.0.5 | /api | 200 | 641319@1614690936.628 641324@1614690996.628 641329@1614691056.628 |
| http_requests_total | 10.2.0.2 | /api | 401 | 368736@1614690901.371 368737@1614690961.372 368738@1614691021.372 |
Это называется range vector — все значения для каждой серии в пределах указанного временного интервала.
Знакомство с агрегаторами и операторами PromQL
Как видите, селекторы PromQL помогают получить данные метрик. Но что, если вы хотите получить более сложные результаты?Представим, что у нас есть метрика node_cpu_cores с меткой cluster. Мы могли бы, например, суммировать результаты, объединяя их по определенной метке:
sum by (cluster) (node_cpu_cores)
Запрос вернет следующие значения:
| cluster | value |
| foo | 100 |
| bar | 50 |
Кроме того, мы можем использовать в запросах PromQL арифметические операторы. Например, используя метрику node_memory_MemFree_bytes, которая возвращает объем свободной памяти в байтах, мы могли бы получить это значение в мегабайтах с помощью оператора деления:
node_memory_MemFree_bytes / (1024 * 1024)
Мы также можем получить процент доступной свободной памяти, сравнив предыдущую метрику с node_memory_MemTotal_bytes, которая возвращает общий объем памяти, доступной на узле:
(node_memory_MemFree_bytes / node_memory_MemTotal_bytes) * 100
Теперь мы можем использовать этот запрос для создания оповещения, когда на узле остается менее 5% свободной памяти:
(node_memory_MemFree_bytes / node_memory_MemTotal_bytes) * 100 < 5
Знакомство с функциями PromQL
PromQL поддерживает большое количество функций, которые мы можем использовать для получения более сложных результатов. Например, в предыдущем примере мы могли бы использовать функцию topk, чтобы определить, какой из двух узлов имеет больший объем свободной памяти (в процентах):topk(2, (node_memory_MemFree_bytes / node_memory_MemTotal_bytes) * 100)
Prometheus позволяет не только получить информацию о прошедших событиях, но даже строить прогнозы. Функция pred_linear предсказывает, где будет временной ряд через заданный промежуток времени.
Представьте, что вы хотите узнать, сколько свободного места будет доступно на диске в следующие 24 часа. Вы можете применить функцию pred_linear к результатам за прошлую неделю из метрики node_filesystem_free_bytes, которая возвращает доступное свободное место на диске. Это позволяет прогнозировать объем свободного дискового пространства в гигабайтах в ближайшие 24 часа:
predict_linear(node_filesystem_free_bytes[1w], 3600 * 24) / (1024 * 1024 * 1024) < 100
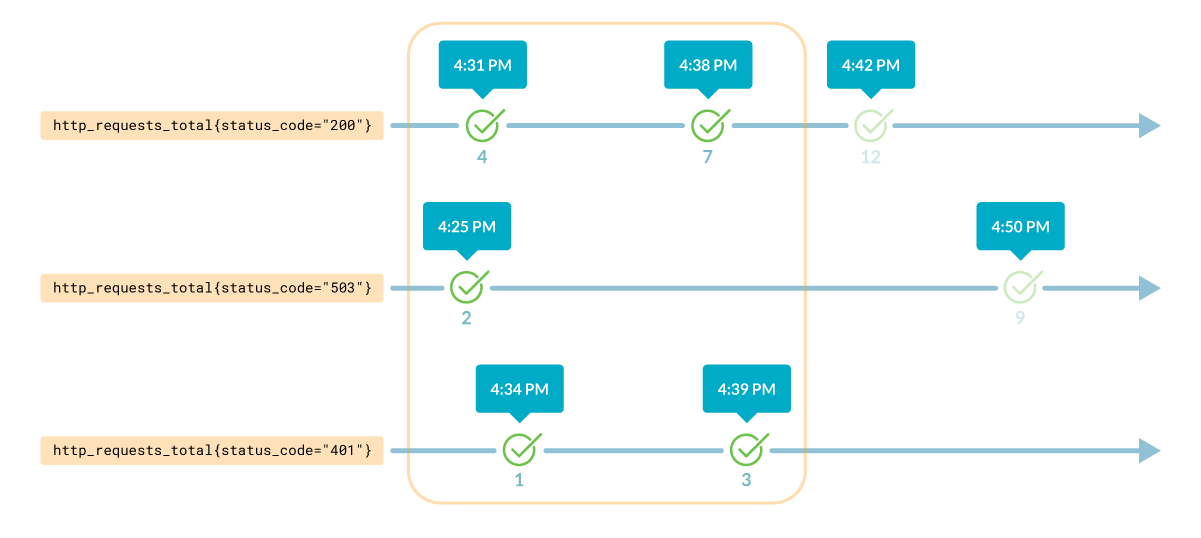
При работе со счетчиками Prometheus удобно использовать функцию rate. Она вычисляет среднюю скорость увеличения временного ряда в векторе диапазона в секунду, сбросы счетчика автоматически корректируются. Кроме того, вычисление экстраполируется к концам временного диапазона.
Что делать, если нам нужно создать оповещение, которое срабатывает, если мы не получали запрос в течение 10 минут. Мы не можем просто использовать метрику http_requests_total, потому что при сбросе счетчика в течение указанного временного диапазона результаты были бы неточными:
http_requests_total[10m]
| name | host | path | status_code | value |
| http_requests_total | 10.2.0.4 | /api | 200 | 100@1614690905.515 300@1614690965.515 50@1614691025.502 |
| name | host | path | status_code | value |
| http_requests_total | 10.2.0.4 | /api | 200 | 100@1614690905.515 300@1614690965.515 350@1614691025.502 |
| name | host | path | status_code | value |
| http_requests_total | 10.2.0.4 | /api | 200 | 0.83 |
rate(http_requests_total[10m]) = 0
Что дальше?
В этой статье мы узнали, как Prometheus хранит данные, рассмотрели примеры запросов PromQL для выборки и агрегирования данных.Вы можете скачать Cheatsheet по PromQL, чтобы узнать больше об операторах и функциях PromQL. Вы также можете проверить все примеры из статьи и Cheatsheet с нашим сервисом Prometheus playground.
Источник статьи: https://habr.com/ru/company/timeweb/blog/562378/