На кого рассчитана данная статья
Данная статья рассчитана на всех интересующихся, т.к. по большей части материал будет повествоваться в упрощенном абстрактном виде (схемы, картинки) в угоду легкому пониманию, без кучи кода. Будет обсуждаться проблема, какие были способы её решить и какой выбрали мы. Любая конструктивная критика касательно принятых нами решений и предложения по улучшению материала приветствуется в комментариях.В чём собственно сложность
Не секрет, что разработка своей игры – желание многих разработчиков, именно с этого у некоторых появилось увлечение IT. А вот разработка онлайн игры – это уже посложнее сценарий и не до конца очевидный для всех, однако играть в игру, особенно в которой предусмотрен кооператив, всегда интересней, чем проходить её в соло. Даже самый скучный проект может засиять и подарить кучу положительных эмоций проходя это все с кем-то. Являясь любителем таких кооперативных PvE игр как Deep Rock Galactic, Remnant: From the Ashes, Helldivers и т.д., мне, как разработчику, всегда было интересно, как устроена их архитектура: как сервера организуют сессии, как справляются с обеспечением тысячи игроков ресурсами, как синхронизируют игроков друг с другом и тому подобное. Это и стало целью моего исследования.В чем ценность данного материала
Потратив почти полтора года на разработку нашей кооперативной real-time игры мы (программист, графический дизайнер и саунд дизайнер) наконец-то довели её до preproduction состояния. Проект начинался исключительно на энтузиазме, как способ доказать нам самим, что мы можем создать свою собственную онлайн кооперативную игру с нуля (в моем случае - не используя готовых решений для организации игры по сети). Сам проект не будет упоминаться в материале ввиду того, что в публичный доступ он ещё не вышел (в случае, если эта статья вызовет интерес у читателей, в будущем возможно будет отдельный материал уже про другие аспекты разработки проекта, такие как графика, музыка, работа в команде и сравнение платформ Itch.io и Game Jolt).Так как в ходе разработки проекта, а именно его бекенд части (создание архитектуры сервера, его оптимизация, развертывание в облаке с отказоустойчивостью) приходилось опираться на различные статьи, форумы и комментарии со всех уголков интернета, это подтолкнуло меня на написание данной статьи, в которой в структурированном виде будет рассказано обо всем опыте решения проблем при написании своего сервера, это может послужить полезным сборником опыта для начинающих интересоваться данной темой.
Немного теории: кто сервер, кто хост, а кто клиент

Начнём с самых основ, допустим у нас есть некая игра на одного игрока, мы управляем черным человечком, игра нам генерирует противников и обеспечивает физику объектов:
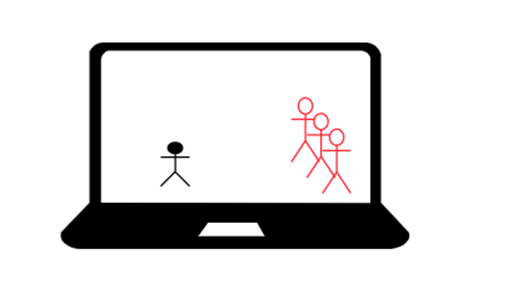
Мы хотим добавить в эту игру мультиплеер на два игрока, вдвоём играть всегда веселее, чем одному, но как нам это сделать? Имея исходный код проекта, немного изменим его: дублируем игру на второй компьютер, создаём второго человечка для второго игрока и программируем компы обмениваться координатами этих человечков:
Упс, что-то пошло не так. Дело в том, что первый компьютер, как и второй – оба генерируют противников, вместо 3-ех противников, у нас их теперь 6 в одном и том же месте и из-за этого они разлетаются по сторонам согласно физике, которую каждый компьютер, опять же, вычисляет отдельно.
Тут у нас возникает конфликт между двумя компьютерными «мозгами», каждый генерирует свой мир и вычисляет свою физику, из-за чего каждый игрок видит разную картину.
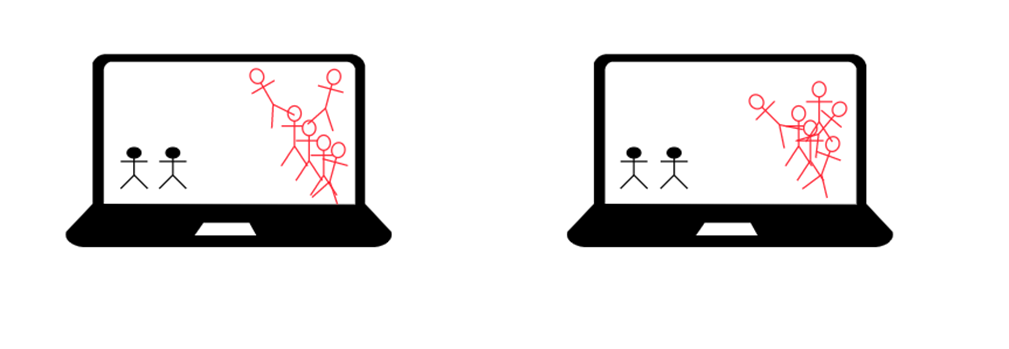
Как это решить? Нам нужен один источник правды, только один компьютер будет вычислять физику и генерировать противников, тратить на это свои вычислительные ресурсы, а второй компьютер будет просто повторять за первым, ему будут интересны лишь координаты всех объектов, чтобы их отрисовать:

Таким образом, 1-ый компьютер у нас становиться сервером (serve – обслуживать), он обслуживает остальных игроков (их компьютеры) своими ресурсами и отправляет им данные всех объектов, чтобы они за ним повторяли, а в ответ компьютеры игроков (клиенты) присылают данные движения своих персонажей (например, клавиши нажатия: влево, вправо, вниз, пробел и т.д.).
В итоге получаем, что игра, которая раньше была одной и целой делиться на две отдельные программы – серверная часть и клиентская часть. Компьютер, который тратит свои вычислительные мощности на серверную часть проекта именуется как хост.
По такой клиент-серверной архитектуре и работают наши любимые онлайн игры, как PvP, так и кооперативные.
То есть хост и сервер – это одно и тоже?
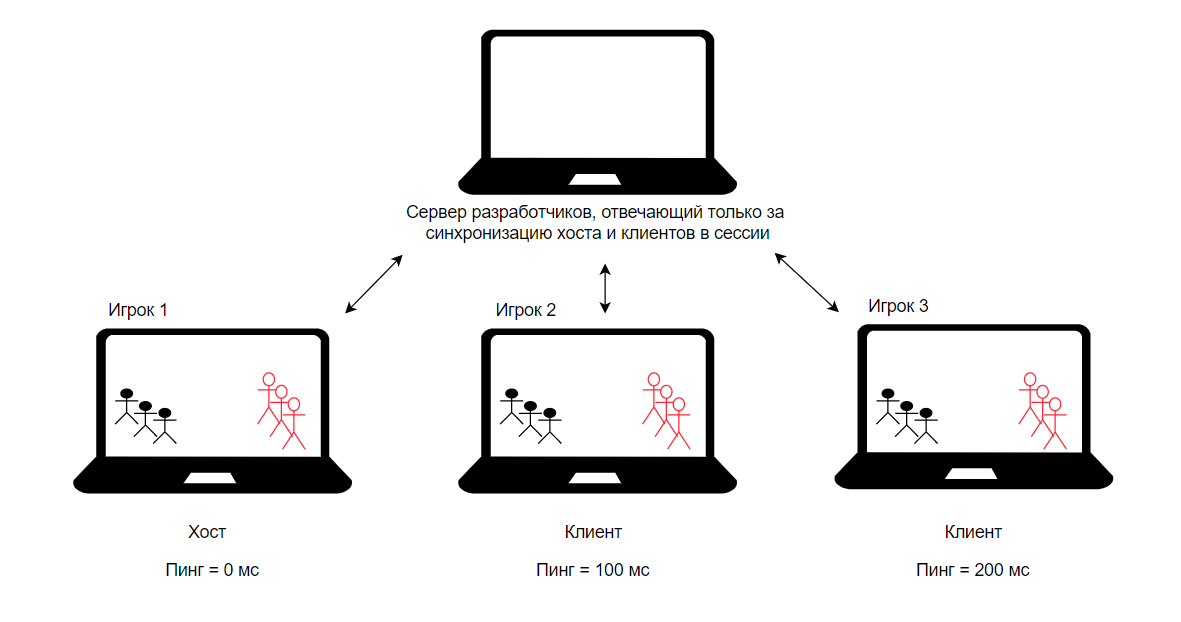
Не совсем, сервер – это доминирующая часть приложения, которой подчиняются клиенты, а хост – машина, на которой работает сервер, а вот кто будет этим самым хостом - это вопрос, в зависимости от ответа на который, мы получим две принципиально разные архитектуры со своими преимуществами и недостатками:1) Хост – компьютер одного из игроков в сессии
В данном случае у игрока данного компьютера будет настоящий экземпляр игры, т.к. это его компьютер будет отвечать за генерацию и физику (как в нашем примере выше).
Преимущества данного подхода:
- Разработчику онлайн игры не нужно тратить деньги на мощные сервера для игроков, ведь все вычисления будут на одном из игроков в сессии (машины разработчиков, как правило, будут просто заниматься синхронизацией хоста с клиентами и сбором данных, на это много мощностей не нужно)
- Игрок, являющийся хостом, будет иметь преимущество над остальными игроками, так как для него ping (задержка) будет 0 мс, поэтому данный подход не очень честен для PvP сессий, а скорее подходит для кооперативных игр
- Так как серверная часть игры находится под контролем одного из игроков, резко возрастает возможность для читерства со стороны данного игрока
- Если во время игровой сессии, хост перестанет справляться с нагрузкой (что довольно типично для игроков со слабым железом), или у хоста будут проблемы с сетью, то это скажется на всех остальных игроках вплоть до прекращения сессии
2) Хост – компьютер, принадлежащий разработчикам игры (авторитарный сервер)
В данной архитектуре подразумевается, что разработчики онлайн игры будут сами обслуживать игровые сессии для игроков. Делать они это могут несколькими способами, либо арендовать/покупать машины в дата центре, которые будут обслуживать игровые сессии, либо арендовать виртуальные машины у поставщиков облачных ресурсов по типу AWS, Google Cloud, Azure и т.д.

Преимущества данного подхода:
- Код серверной части не будет доступен игрокам, соответственно резко уменьшается пространство для читерства и поиска уязвимостей
- Разработчики, как правило, арендуют стабильные машины для запуска своих серверов, с достаточным железом и стабильной сетью, что гарантирует всем игрокам беспрерывную игровую сессию
- Ни у кого из игроков нет преимуществ над остальными, все в равных условиях и подчиняются одному, как его называют, авторитарному серверу, а поэтому данная архитектура хорошо подходит для PvP сессий
- Если игра подразумевает сложную генерацию мира, объектов, а также вычисление физики, то на обработку каждой сессии нужно немалое кол-во ресурсов (оперативной памяти, процессорного времени), поэтому покупка, как и аренда машин для таких игровых сессий могут сильно ударить по карману разработчика
Реализация архитектуры авторитарного сервера
Почему выбор пал на авторитарный сервер?
Несколько причин:- В игре хоть и присутствуют генерация мира и вычисление физики объектов, но это не сильно бьет по процессорному времени, так как игра 2D и действия проходят на одной не самой большой карте
- Хоть читерство и непрерывность игровой сессии более критичны в PvP игре, нежели чем в кооперативной PvE, так или иначе, иметь эти преимущества тоже приятно, когда ты полностью контролируешь сервер
- Сервер написан на Python, а с Python, к сожалению, очень сложно спрятать исходный код от игроков. Python - язык интерпретируемый, что означает, что ваша программа не компилируется в машинный код (.exe файлы в случае Windows), а просто представляет из себя текстовые файлы, которые все могут прочитать и которые запускает сам Python. Да, соглашусь, что этот момент немного спорный, так как все таки есть разные ухищрения, который затрудняют reverse engineering Python приложений, да и в-принципе от reverse engineering’a не защищен даже машинный код, но этот момент также сделал выбор авторитарного сервера более привлекательным.
Как в-принципе сочетаются Python и real-time игра с физикой
Понимаю, выбор языка может показаться странным, многие наслышаны о медленной производительности Python, однако трюк тут состоит в том, что зачастую Python не сам вычисляет сложные формулы и физику, а делегирует это Си-библиотекам, которые и работают под его капотом.Например для физики мы используем библиотеку pymunk, которая просто является питоновской надстройкой над библиотекой chipmunk, которая уже, в свою очередь, написана на C, а отсюда и быстродействие её работы.
Чем же реально Python занимается на сервере, так это бесконечным циклом (`while True:`, типичный код для любой игры, чтобы игра бесконечно обновлялась и не останавливалась, тут важно, чтобы игра обновлялась хотя бы 60 раз в секунду, что равно 60 FPS), созданием игровых объектов, событий и обработкой подключенных игроков. С этими задачами Python справляется на достаточном уровне.
Архитектура игровой сессии на сервере
Каждая сессия может содержать в себе до 3-ёх игроков в нашем проекте. А что такое игрок в нашем серверном понимании? Это подключение к нашему серверу, игрок нам шлёт нажатые клавиши (влево, вправо, вниз, пробел и т.д.), а мы ему в ответ состояние текущей игры. И подобное действие нам необходимо делать параллельно ещё с двумя другими подключенными игроками. Но и это ещё не всё, также параллельно со всем этим должна работать и сама игра данной игровой сессии, в которую игроки собственно и играют. Итого мы получаем 4 потока в игровой сессии (подключение 1-го игрока, 2-го, 3-го и сама игра), которые должны работать параллельно. Как такого достичь?
Пара слов о параллельном программировании: процессы и потоки
Когда вы запускаете приложение (будь-то игра, сервер, бразуер), для неё создается процесс в системе, вы их можете увидеть в диспетчере задач, сам процесс содержит внутри себя хотя бы 1 поток. Поток - это и есть способ выполнения процесса и выполняется он на одном ядре процессора. То есть, если у вашего процессора 8 ядер, то процесс с одним потоком сможет занять только 1 ядро вашего процессора (12,5%). Соответственно, если вы желаете отдать вашей программе всю мощность вашего процессора, вам необходимо создать 8 потоков внутри процесса вашей программы и тогда оно захватит все доступные ядра и забьёт процессор на 100%. То есть увеличение потоков - это способ распараллелить процесс программы, заставить ее делать несколько действий одновременно (многозадачность), или же просто увеличить производительность программы.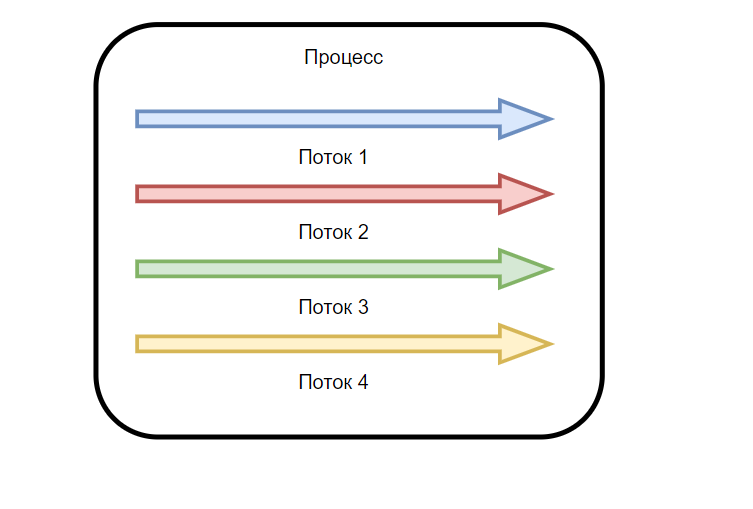
В нашем случае, нас интересует многозадачность, нам нужно параллельно обрабатывать подключение 1-го игрока, 2-го, 3-го и саму игру внутри одной игровой сессии, то есть для одного процесса с игровой сессией нам нужно 4 потока. Но, просто создать 4 потока недостаточно, нужно же сделать так, чтобы они общались между собой, как это устроить? Ответ - очереди.
Снова немного теории. Очередь - это некий контейнер, который позволяет нам наладить общение между потоками, пока одни потоки туда складывают информацию, другие оттуда её читают. Согласитесь, удобно, поток с 1-ым игроком кладет в очередь нажатые клавиши этого первого игрока, а поток с игрой эту очередь читает в порядке “что первым пришло, то первым и получил” (FIFO) и затем применяет входные данные (нажатые клавиши игрока) в действие, из-за чего персонаж, которым управляет 1-ый игрок действительно движется туда, куда приказал игрок.
Архитектура игровой сессии: общая картина

Есть поток с игрой (Game, самый верхний), мы видим что он читает (get - получить) три очереди user movements из трёх других потоков (1-го, 2-го и 3-го игрока), таким образом, игра (поток с игрой) успешно ловит нажатые клавиши всех 3-ёх игроков. Игра эти нажатые клавиши обрабатывает, двигает персонажей игроков и взамен отсылает (put - класть) состояние всей игры (координаты всех объектов) в очереди Objects для каждого потока игроков (1-ый, 2-ой и 3-ий).
Таким образом у нас получается простая, но рабочая система. Игроки присылают нажатые клавиши, игра это обрабатывает, учитывает и в ответ отсылает координаты всех объектов (состояние игры), всё это происходит каждый кадр игры, из-за чего игроки даже не подозревают обо всех этих процессах происходящих под капотом. Кажется, что игрок нажал влево и персонаж пошел влево, просто потому что его компьютер сказал ему пойти влево, но в реальности компьютер лишь передал нажатую клавишу игрока на удаленный сервер в поток с подключением данного игрока, тот его положил в очередь для нажатий данного игрока, игра с этой очереди прочитала нажатую клавишу, подвинула персонажа, отправила координаты (состояние игры) в поток с подключением этого игрока, тот поток уже отправил координаты компьютеру игрока и уже тот поправил картину по новым координатам. Вот такая магия.
Про Python и его проблему с потоками
Не секрет, что Python, к сожалению, не позволяет всем 4-ым потокам быть активными в один момент времени, только один поток в один момент времени может быть активным из-за известного всем Python разработчикам GIL. Из-за чего о росте производительности тут речи не идёт, однако мы добиваемся многозадачности, а производительности одного ядра (так как у нас только один поток работает в момент времени из-за Python) хватает на 3 подключения и саму игру.Как происходит создание и удаление игровых сессий
Архитектура, изложенная сверху, покрывает лишь саму игровую сессию, однако нужен ещё один процесс, который уже будет управлять созданием, отслеживанием и удалением этих самых игровых сессий (а вернее, их процессов), то есть это некий процесс, занимающийся оркестрацией других процессов. Это процесс, с которым игроки будут взаимодействовать до того, как они попадут в саму игровую сессию. Назовём этот процесс - main server, главный сервер. Игроки будут просить главный сервер дать список текущий сессий (чтобы подключиться к ним) или же создать новую сессию. Покажем как это выглядит на следующей схеме:
Оптимизация сервера (и немного клиента)
В связи с тем, что проект, в первую очередь, real-time (то есть необходимо как можно сильнее сократить время от того, как клиент получит нажатия игрока, до того, как клиент отобразит результат этих самых действий игрока) пришлось выполнить ряд оптимизаций, как на сервере, так и на клиенте, чтобы добится оптимальной производительности и стабильности.Оптимизации на сервере
1. Способ передачи данных
Изначально оба сервер и клиент были написаны на Python, а значит была возможность воспользоваться питоновским способом отправки объектов, а именно - pickle. Пример такого потока данных:[<network_classes.border.NetworkBorder object at 0x000001A44EF51070>,
<network_classes.border.NetworkBorder object at 0x000001A44EF51280>,
<network_classes.border.NetworkBorder object at 0x000001A44EF51040>,
<network_classes.border.NetworkBorder object at 0x000001A44EF83550>,
<network_classes.border.NetworkBorder object at 0x000001A44EF83520>,
<network_classes.border.NetworkBorder object at 0x000001A44EF834F0>,
<network_classes.border.NetworkBorder object at 0x000001A44EEAF790>,
<network_classes.player_ball.PlayerNetworkBall object at 0x000001A44EEAF6D0> ……..]
Преимущества такого подхода:
- Легко реализовать на Python
- Тяжелые объекты для real-time продукта
- Не кросс-платформенно (настроить общение таким способом можно только между Python процессами)
- Проблемы с безопасностью (в pickle довольно легко подсунуть вредоносный Python код для его выполнения получателем, поэтому pickle лучше использовать в частных приватных сетях, где вы точно можете доверять отправителю)
[
{x: 12, y: 10, id: 30, radius: 80, color: “red”, cls: “ball”},
{a_x: 22, a_y: 45, b_x: 122, b_y: 145, id: 45, color: “blue”, cls: “border”},
...
]
Преимущества такого подхода:
- Легко реализовать
- Кросс-платформенно
- Нет фундаментальных проблем с безопасностью, как в случае с pickle
- Все еще тяжелые объекты для real-time продукта (сервер будет отправлять состояние игры игрокам каждый проход цикла и каждый раз, вместе со значениями будут отправляться одни и те же ключи значений, что просто излишнее кол-во байт, также json нужно сериализовать перед отправкой и десериализовать при получении, что тратит процессорное время)
1.2.0.0.800.0.10.20.0.5;1.3.1200.0.2000.0.10.20.0.5;1.4.0.1200.2000.1200.10.20.0.5;1.5.0.0.0.640.10.20.0.5;1.6.0.960.0.1200.10.20.0.5;1.7.2000.0.2000.640.10.40.0.5;1.8.2000.960.2000.1200.10.40.0.5;3.11.400.100.90;3.12.1500.1100.90;3.13.1900.1000.120;3.14.300.1100.160;3.15.1200.600.50;3.16.700.1000.80;3.17.1600.700.170;3.18.800.900.170;2.1.832.1130.60.0.5.1.0.0;4.22.1832.1495.140;4.23.288.948.150;5.25.1855.531.60.7;5.26.1290.1130.60.7….
Теперь у нас нет никакой лишней информации, у нас только голые значения и разделители.
Аналогично и с клиентом, если раньше он отсылал данные о нажатых клавишах в виде такого вот json:
{“up”: true, “right”: true, “left”: false, “down”: false, “attack”: true, “accelerate”: true}
То теперь просто передает строку, содержащую ту же самую информацию, но будучи короче в ~10 раз:
110000
Преимущества такого подхода:
- Нет проблем с безопасностью
- Легковесный объект
- Кросс-плафтормено (нужно лишь реализовать логику по распаковке данной строки, что по-факту представляет из себя парочку `split`ов)
- Трудно реализовать и поддерживать
2. Следите за блокирующими операциями
В программе, в которой у вас несколько потоков и подключений, важно следить, чтобы не было такого, что один поток встал и из-за него встали все остальные.Как один из примеров, вот у нас в процессе с игровой сессией есть поток 1-го игрока, который кладет нажатые клавиши данного игрока в очередь, чтобы оттуда их прочитал поток с игрой, и тут важно сделать так, что если очередь пустая (допустим у игрока с сетью проблемы), то и ладно, нужно дальше продолжать работу. В том же Python это нужно явно указать, так как операция по получению чего-то (`.get()`) из очереди является блокирующей по-умолчанию.
То есть вот такой код:
player_move = player.move_queue.get()
player.move(player_move)
Следует заменить вот таким:
try:
player_move = player.move_queue.get(block=False)
except Empty:
player_move = previous_player_move
player.move(player_move)
Если нам ничего не пришло, то просто используем предыдущее данные, пакеты теряются часто и скорее всего игрок все еще нажимал предыдущие кнопки.
3. Уберите буфер в ваших сокетах (подключениях)
Дело в том, что по умолчанию сокеты отправляют данные (от клиента к серверу, или от сервера к клиенту), когда они достигают какого-то значения буфера. Для того, чтобы незамедлительно отсылать данные получателю, необходимо отключить алгоритм Nagle на сервере и клиенте:s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.setsockopt(socket.IPPROTO_TCP, socket.TCP_NODELAY, 1)
4. Используйте протокол TCP, а не UDP
Как известно, когда речь идет о стриминге данных, тут, как правило, на сцену выходит UDP, посколько он просто отправил данные и забыл, может дублировать какие-то пакеты, может и вовсе их не отправить, это делает его очень скоростным относительно TCP, который в свою очередь гарантирует, что все данные придут в целостности и по порядку. И TCP мог бы действительно внести много задержек при стриминге, если бы у нас была плохая сеть, но в сегодняшних реалий почти все обеспечены более менее хорошим интернетом и TCP не приходится по несколько раз бегать с одним и тем же пакетом, зато он нам гарантирует целостность и порядок данных. Если же мы будет использовать UDP, то перед процессингом полученных данных нам придется несколько раз их провалидировать, чтобы убедиться, что мы получили то, что хотели, по итогу получаем некую надстройку над UDP, хотя всё это уже есть в TCP.5. Добавляйте маркер начала и конца каждого сообщения
С TCP всё же есть небольшая проблема, хоть данный протокол и гарантирует порядок данных, он не гарантирует, что данные придут именно одним пакетом.То есть хотим мы отправить “Hello world” и “Hi all”, прийти они могут следующим образом: “Hell”, “o wor”, “ldHi all”. Поэтому важно добавить разделители между сообщениями, пусть '?' - начало сообщения, а '!' - конец сообщения, тогда отправив “?Hello world!” и “?Hi all!”, мы получим “?Hell”, “o wor”, “ld!?Hi all!”, можем спокойно соединить эти пакеты и по разделителям увидеть наши сообщения - “Hello world” и “Hi all”.
Отпимизации на клиенте
Алгоритм предсказания
Порой бывают моменты, когда сеть всё-таки становится нестабильной, порой на полсекунды, а иногда на 1-2. В этот момент клиент не получает никаких данных от сервера, соответственно для него игра остановилась, а если такие сбои происходят довольно часто, то игрок видит дергающуюся картину. Как исправить такой момент? Как правило, в течении 0.5-2 секунд ничего особенного не происходит, объекты, которые двигались в каком-то направлении, так в нём и движутся, поэтому при отсутствии данных сервера можно просто продолжать движение всех игроков в зависимости от их последней скорости с сервера. Например для какого-то объекта:Взять предыдущие координаты: (500, -403)
Взять текущие координаты: (503, -410)
Подсчитать теоретическую скорость:
speed_x = 503 – 500 = 3 pixels
speed_y = -410 + 403 = -7 pixels
Хочу обратить внимание, что данная скорость должна подсчитываться сервером, а не клиентом, так как клиент, в виду потерянных пакетов, может посчитать неверную скорость объекта.
Соответственно, пока сети нет, следующими теоретическими координатами будут: (506, -417), потом (509, -424), и т.д.
Динамическое автомасштабирование в AWS
Теперь, когда у нас есть работающая архитектура проекта с необходимой оптимизацией, можно поговорить о том, как мы будем это разворачивать.Что такое динамическое автомасштабирование?
Динамическое автомасштабирование - это способ автоматически изменять количество ресурсов в зависимости от нагрузки на эти ресурсы.В нашем случае это означает иметь столько виртуальных машин, сколько необходимо для обработки игровых сессий всех игроков и автоматически добавлять или удалять данные машины в зависимости от того, как изменяется спрос игроков.
Зачем маленькому инди-проекту инфраструктура с динамическим автомасштабированием?
Давайте посмотрим на простой способ развертывания нашего авторитарного сервера: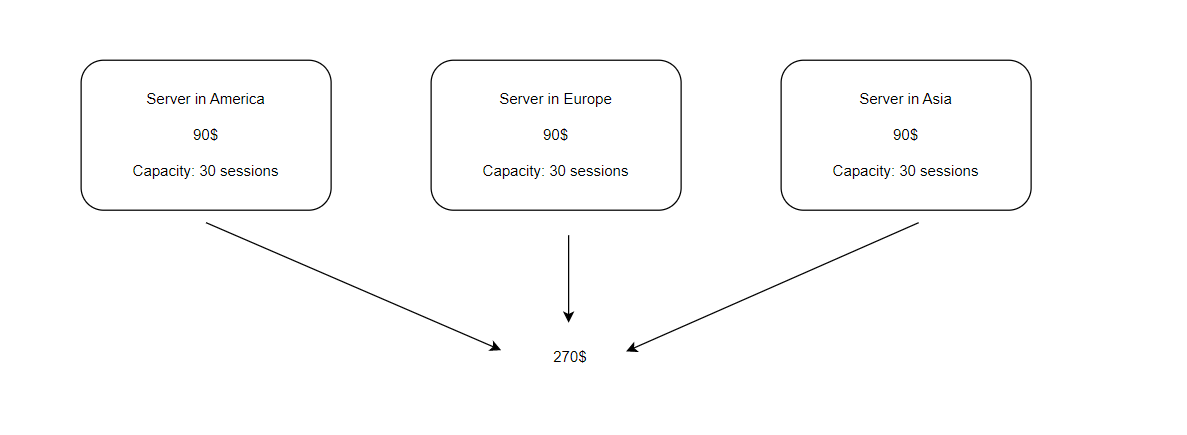
Чтобы покрыть большую часть планеты низким пингом, мы можем просто арендовать три более-менее мощные машины по одной в каждый регион, в моем случае сервер, оптимизированный на CPU, который может выдержать примерно 30 игровых сессий стоит 90 долларов в DigitalOcean.
Данный способ является очень простым, три машины, каждая в своем регионе, у каждой свои игровые сессии и за каждую ты платишь фиксированную сумму, как для инди-разработчика, это кажется вполне простым решением.
Однако данный способ всё-таки немного бьёт по карману, а игра никак не коммерческая. Соответственно было бы неплохо взять машины послабее, но тут сразу очень много “а что если?”: а что если игра выстрелит? А что если машина не выдержит и просто упадёт? А что если машины атакуют DDoS атакой? А что если и вправду все эти переживания зря, проект в-принципе будет никому не нужен и ресурсы машин за 300 долларов будут просто сгорать?
Вот бы был способ как-то динамически решить этот вопрос уже “в бою”, будут играть пару игроков, ну и будут машины крутиться за копейки, а придёт много - система сразу нарастит необходимые ресурсы и освободит их, когда они станут не нужны. С помощью крупных облачных поставщиков таких как AWS такие сценарии вполне можно реализовать:
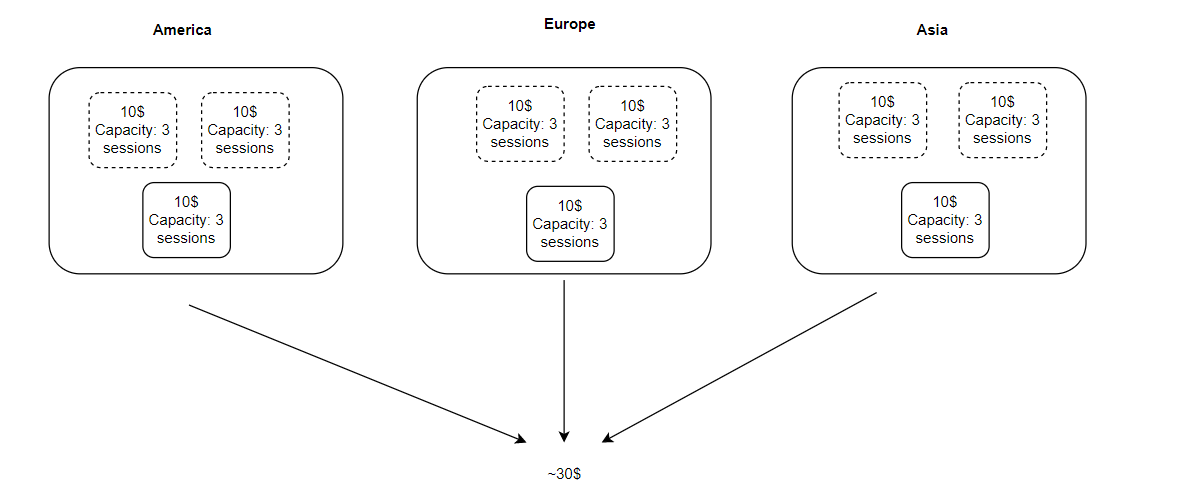
В данном случае у нас на каждый регион создается группа ресурсов, где всегда работает хотя бы одна виртуальная машина, в данном случае, это - машина, которая способна выдержать 3 игровые сессии и обходится она нам в 10 долларов в месяц каждая. Развернув такую группу в 3-х регионах мы получаем суммарно примерно 30 долларов в месяц, это при условии, что в игру почти никто не будет играть, что порой весьма реалистично для инди проектов, но в этом случае мы теряем всего 30 долларов, а не 300, как в случае описанном выше.
Почему AWS
У AWS есть всё необходимое для данной архитектуры, о чём будет написано ниже, само собой подобное можно сделать и в других крупных поставщиках, но у AWS огромное количество документации, коммьюнити, поэтому долго ломать голову над каждой мелочью не пришлось. Хотя если пренебречь данной динамической инфраструктурой и сделать всё по простому, то тут уже куда привлекательней смотрится DigitalOcean с его простой настройкой виртуальных машин и простой ценовой политикой.Как это все выглядит в AWS
На каждый регион, в котором мы хотим развернуть нашу инфраструктуру, у нас получается следующая картина:
Что здесь для чего нужно и зачем:
Target group
Представляет из себя группу виртуальных машин, которые хостят игровой сервер, вот так это выглядит в AWS: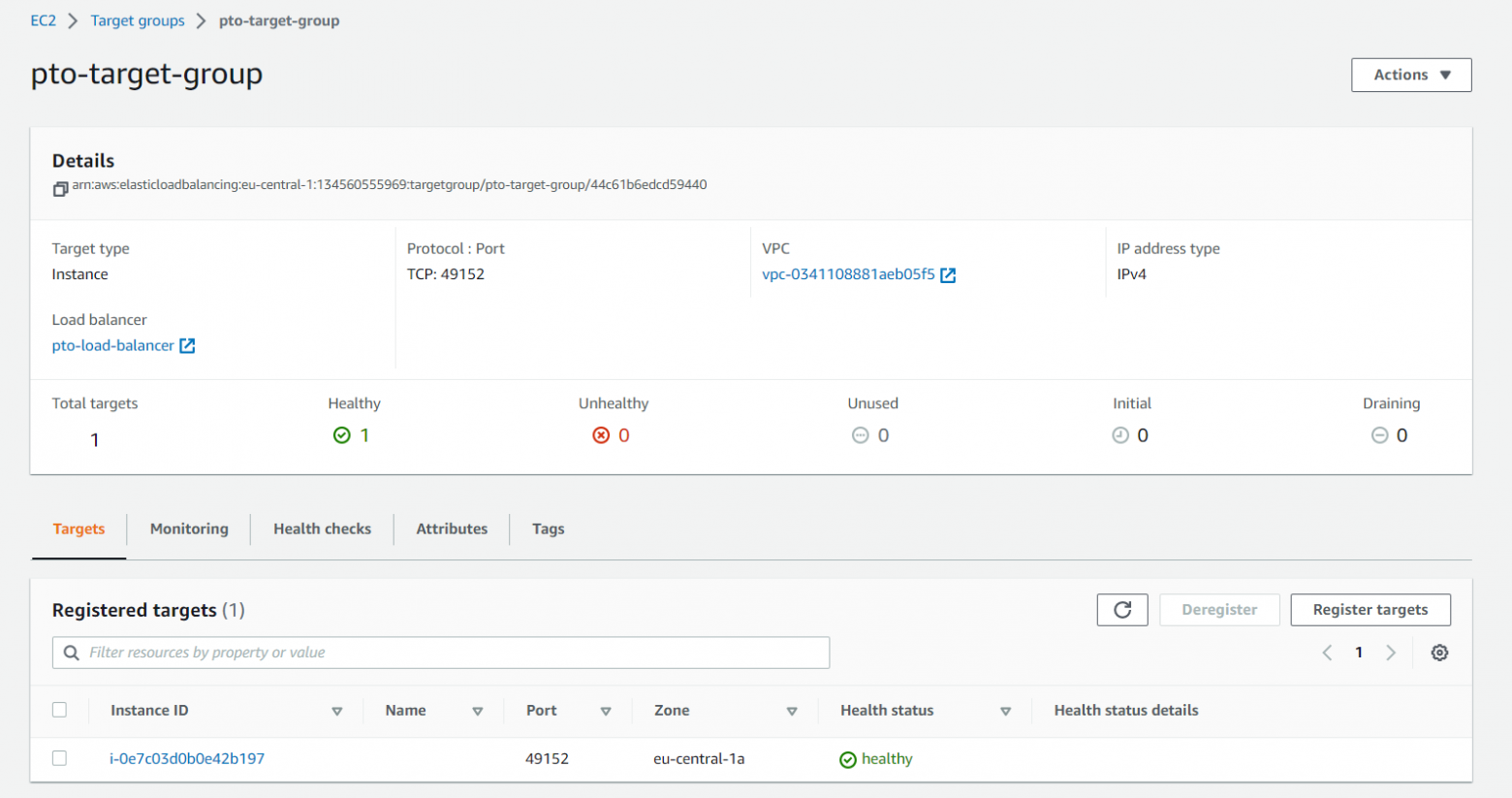
Видно, что в данной Target группе у нас только одна машина и она помечена как healthy. Как AWS это проверяет? Балансировщик нагрузки (о котором рассказано ниже) стучится на порт, на котором развернут сервер (раз в указанное количество секунд) и в случае хоть какого-то ответа помечает нашу машину живой и здоровой.
Elastic Load Balancer
Представляет из себя балансировщик нагрузки, который принимает подключение от игрока и перенаправляет его на одну из машин в Target группе по round robin схеме (круговому циклу), к сожалению, балансировщик в AWS не отслеживает такие характеристики как загруженность процессора, поэтому он не основывает свой выбор на том, какая машина загружена, а какая нет. На скриншоте вы можете видеть главный компонент балансировщика - Listener (на какому порту ждать запрос от игроков и в какую Target группу этот запрос потом перенаправить):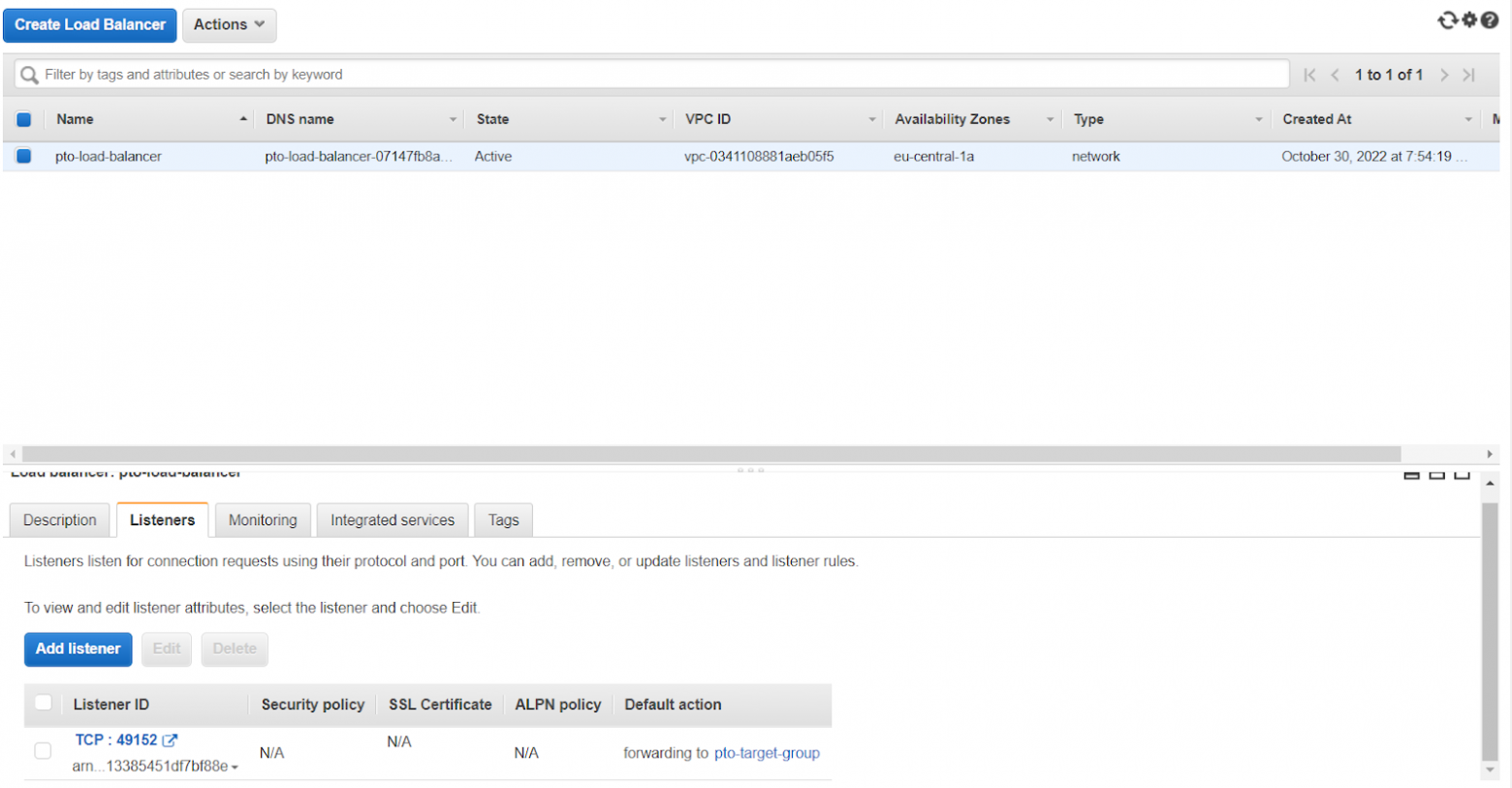
Auto Scaling
Занимается автомасштабированием. Следит за метриками машин в Target группе, а также устанавливает:- Минимальное кол-во машин в Target группе (Minimum capacity), это то кол-во машин, которое будет работать сразу со старта
- Желаемое кол-во машин (Desired capacity), это кол-во будет изменяться в зависимости от нагрузки
- Максимальное кол-во машин (Maximum capacity), это потолок, до которого мы разрешаем поднимать виртуальные машины (все-таки каждая машина стоит своих денег)

Также Auto Scaling содержит в себе Launch template, инструкция по тому, как поднимать машину, какое железо ей выбрать, какую ось ей поставить, что на ней запустить:
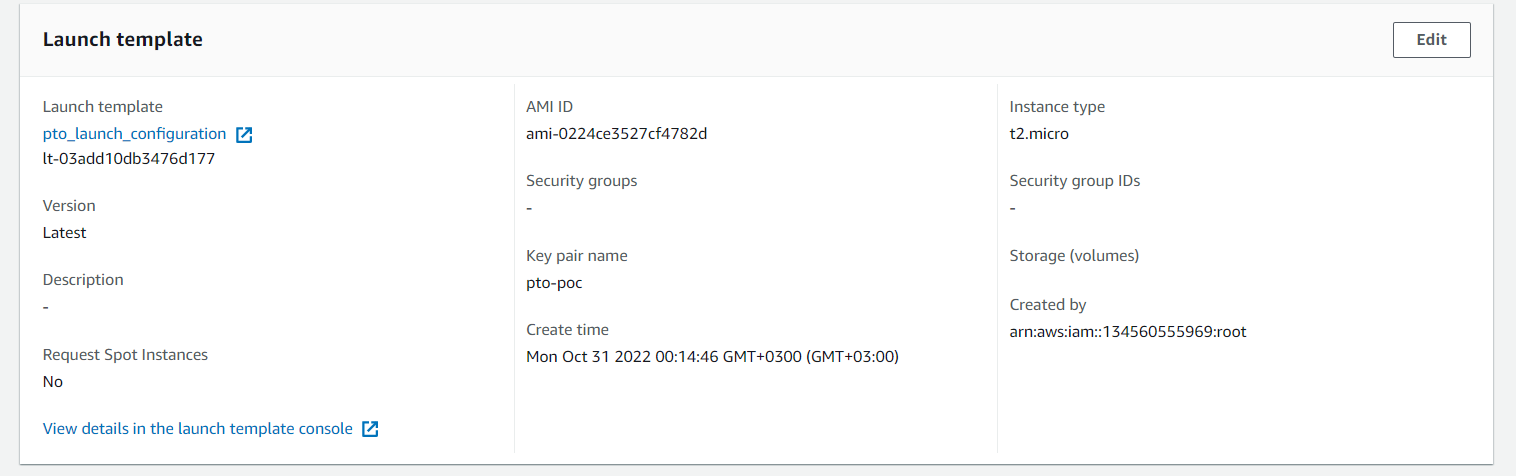
Также содержит в себе политику динамического масштабирования, в котором мы и говорим, когда нужно поднимать или удалять виртуальные машины:
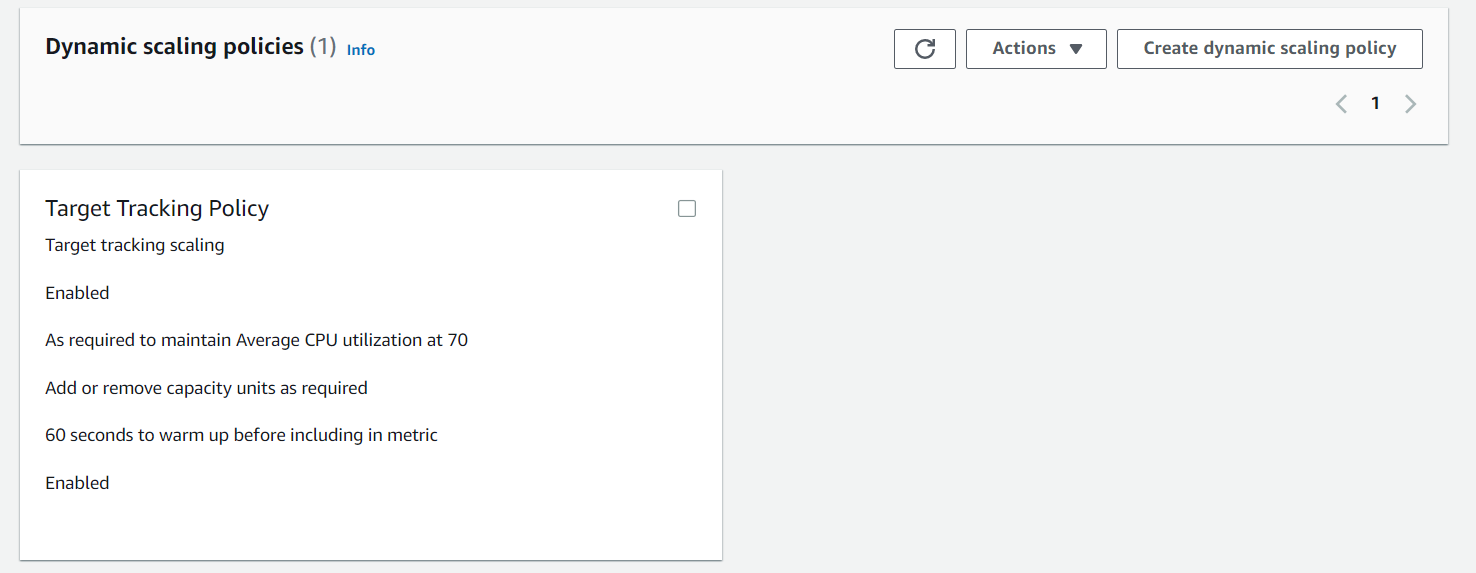
В данном случае на скриншоте сказано “Средний уровень загруженности процессора на каждой машине не должен превышать 70%, по необходимости добавлять/удалять машины, каждой машине дать 60 секунд на разогрев после старта прежде чем включать ее в подсчет метрик”.
DynamoDB
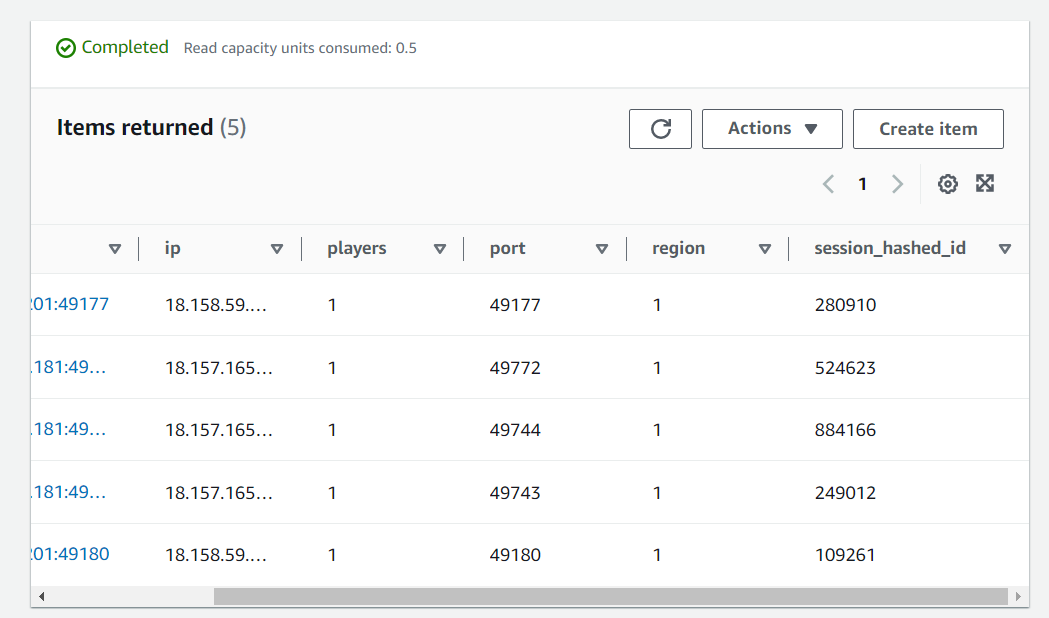
Данный сервис представляет из себя NoSQL базу данных и нужен только для одной цели - временное хранилище сессий. Для чего это нужно? Дело в том, что каждая виртуальная машина - это прежде всего отдельная машина и у каждой из них свой список игровых сессий. Допустим вы и ваш друг играете в одном регионе и вы хотите подключится к его сессии, но вот проблема, под капотом оказалось, что вы на самом деле сейчас на разных виртуальных машинах, соответственно, вам нужно как-то перепрыгнуть на его машину.В этом нам и помогает данная БД, все сервера складывают туда информацию о своих сессиях (IP адрес + порт + другая полезная метаинформация) и любой сервер даст вам список всех сессий просто попросив их в данной БД. Соответственно клиент вашей игры получает информацию о сессии от любого сервера, видит, что она находится по другому адресу, на другом сервере и переподключается. Таким образом несколько машин могут работать как единый механизм.
Пример того, как выглядят сессии в данной БД:
С кем теперь общается клиентская часть игры, с балансировщиком нагрузки или с самими серверами?
И то, и то. Можно попросить Auto Scaling, чтобы он каждой поднятой машине назначал свой публичный IP:
Таким образом через балансировщик нагрузки мы можем подключится к любому случайному серверу, чтобы попросить его дать нам список сессий, или создать для нас сессию, а когда мы уже получим в ответ IP адрес и порт этой сессии, мы напрямую подключимся к той машине, которая её хостит.
Эффективность данной инфраструктуры
AWS предоставляет две категории мониторинга виртуальных машин: базовую и детальную (за дополнительную плату). Базовый мониторинг (насколько загружен процессор, диск, сеть и т.д.) собирает метрики каждые 5 минут и соответственно это вносит свои задержки в работу Auto Scaling, который и принимает решения, основываясь на этих метриках. Тут могут быть два решения, либо подключить детальный мониторинг, который будет собирать метрики каждую минуту или уменьшить порог, когда нужно поднимать ещё одну машину (допустим вместо средней загруженности процессора в 70% поставить 50%, чтобы Auto Scaling мог среагировать заранее).Посмотрим на примере, забьем процессор нашей текущей виртуальной машины в target группе:
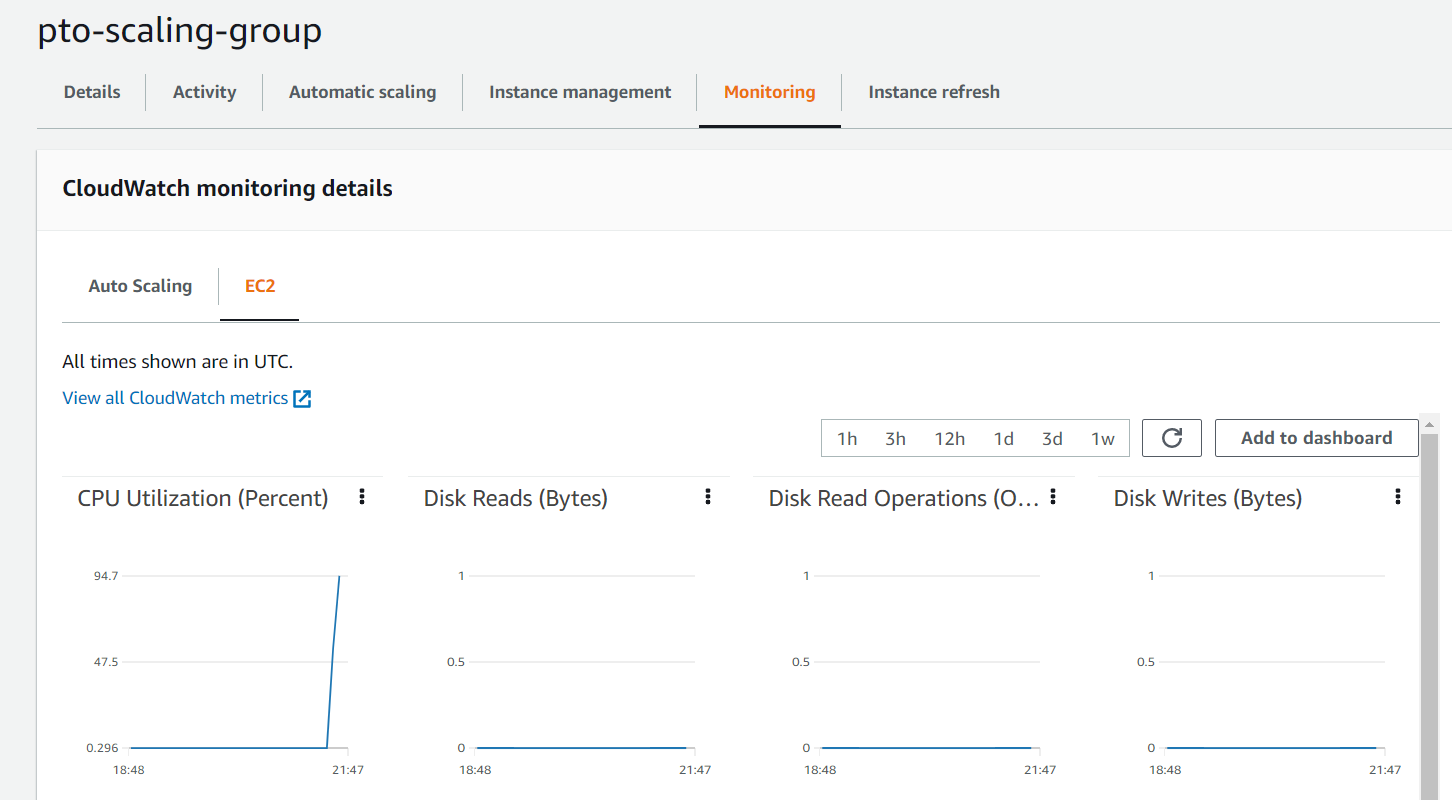
Auto Scaling устанавливает Desired Capacity (желаемое кол-во машин) с 1 на 2:
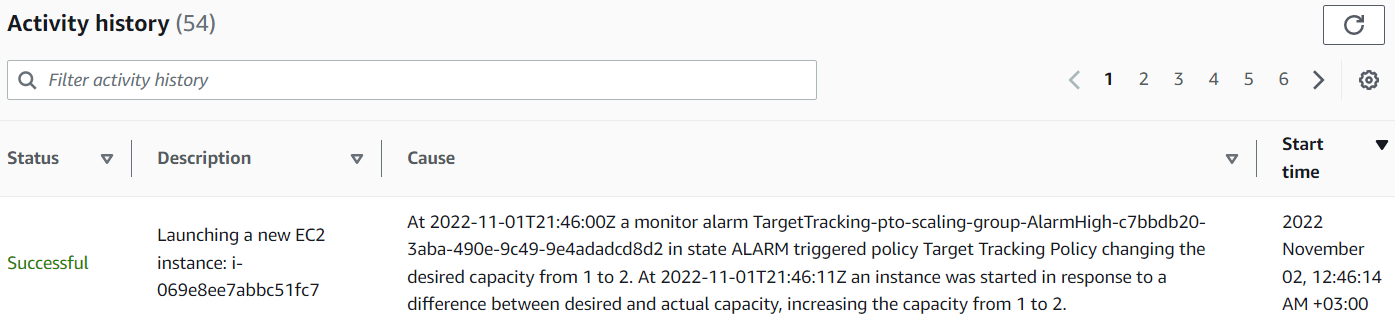
И мы видим её в Target группе:

Немного подождём и у нас две работающие виртуальные машины:
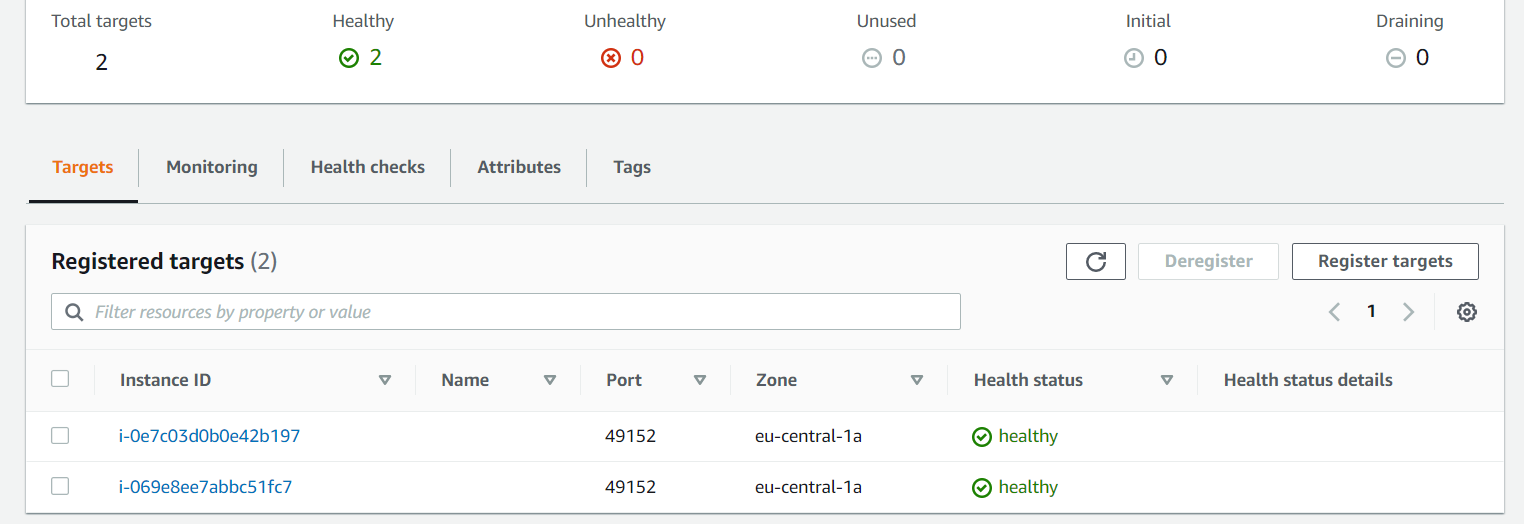
Отказоустойчивость (fault tolerance) при такой инфраструктуре
В случае если балансировщик нагрузки не смог достучаться до нашего сервера по указанному порту, машина данного сервера помечается как unhealthy, нездоровой. Auto Scaling это видит и спешит заменить эту машину на новую:
Защита от DDoS
Сервис AWS, представляющий защиту от DDoS, AWS Shield, доступен по подписке за 3000 долларов в месяц, такого увы, мы позволить себе не можем, но так или иначе, даже при DDoS атаке на сервера, даже в случае если они упадут, Auto Scaling через некоторое время их автоматически поднимет без нашего участия, так как балансировщик нагрузки просто не сможет достучаться до серверов на виртуальных машинах и пометит их нездоровыми. А новые сервера уже будут развернуты на новых IP адресах. То есть от самой атаки инфраструктура не защищена, но последствия более менее сглаживает, как минимум не придется бегать и руками что-то поднимать, разве что у игроков немного испортиться настроение из-за потерянной игровой сессии.Подводные камни такой инфраструктуры
Они есть, когда Auto Scaling начинает уменьшать количество машин (нагрузка на сервера снизилась), то данному сервису все-равно, что игроки возможно все еще играют на удаляемой машине и у них там игровая сессия, соответственно, она просто теряется и у игроков портится впечатление.Благо тут нашлось работающее решение, AWS позволяет заблокировать и разблокировать некоторые Auto Scaling процессы, нас интересует процесс Termination, который удаляет машины. Что мы делаем, мы при создании каждой машины даём ей разрешение (через роль в AWS) на выполнение командных строк в Auto Scaling сервисе:
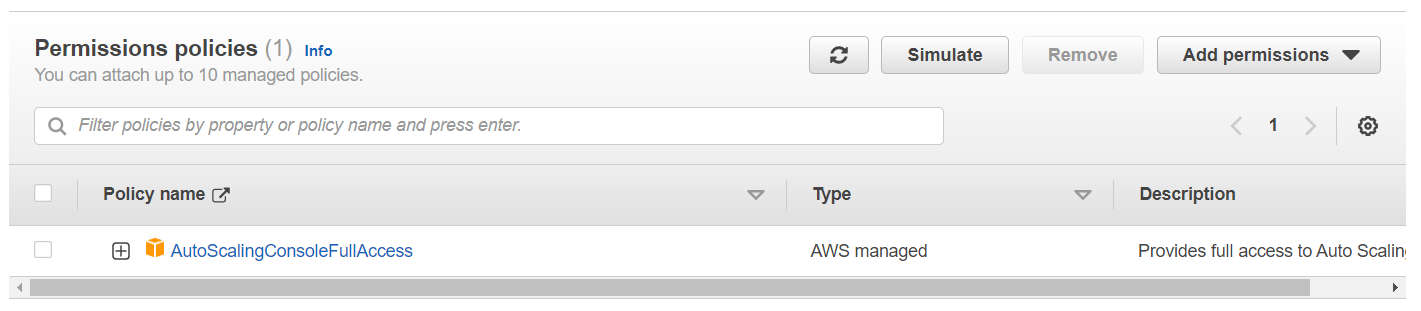
Каждая машина в Target группе периодически проверяет список сессий в DynamoDB и если она видит, что сейчас есть хотя бы одна сессия, то она блокирует Auto Scaling’у возможность удалять виртуальные машины, а если видит, что сессий нет, то наоборот разрешает:
# заблокировать возможность удаления машин
aws autoscaling suspend-processes --auto-scaling-group-name <scaling-group-name> --scaling-processes Terminate
# разблокировать возможность удаления машин
aws autoscaling resume-processes --auto-scaling-group-name <scaling-group-name> --scaling-processes Terminate
По итогу, если у нас есть хотя бы одна сессия, то процесс Terminate помечается как Suspended (Приостановленный) для Auto Scaling’а:
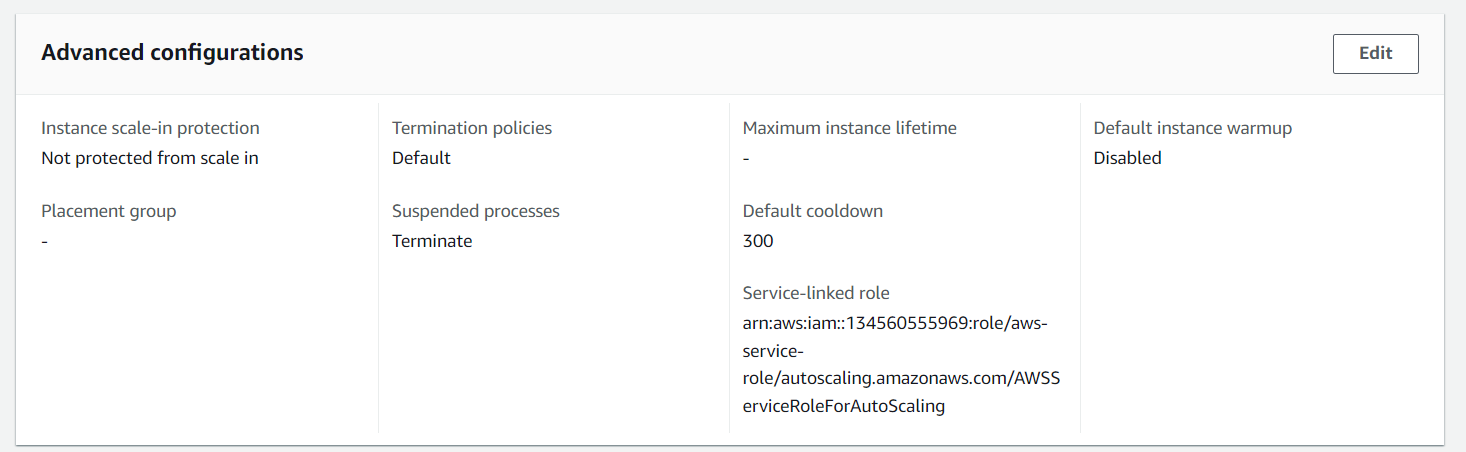
Сколько выходит по цене
Цена здесь будет варьироваться в зависимости от потребления игроков и от того, в скольких регионах вы выкладываете данную архитектуру. В моем случае, так как игра ещё не вышла, адекватной статистики у меня пока нет, но ситуация складывается следующая:- Виртуальные машины EC2 - по одной на каждый из 3-ёх регионов, t2.micro, стоят 10 долларов в месяц, однако AWS даёт одну t2.micro машину бесплатно на каждый месяц, поэтому в сумме выходит 20 долларов, это если Auto Scaling не будет поднимать больше никаких машин, т.е. если в игру никто не будет заходить
- DynamoDB - бесплатно, AWS даёт 25 ГБ памяти для сервиса DynamoDB как free tier, а для нашего временного хранилища сессий - это более, чем достаточно
- Балансировщик нагрузки - почасовая оплата за каждый гигабайт трафика, однако игроки не будут использовать его для прямого TCP подключения к игровой сессии, поэтому такой трафик вряд-ли удасться достичь
- Auto Scaling сервис - бесплатный
- Могут быть небольшие платежи за CloudWatch, которые собирает логи и метрики, а также за использование нескольких IP адресов поднятыми машинами
Заключение
Проникнуться тем, какие бывают игровые сервера, как устроена их архитектура, какие существуют приемы для их оптимизации, как их развертывать в облаке стали для меня настоящей страстью за эти полтора года. Я очень рад, что получилось довести серверную архитектуру проекта до такого состояния и надеюсь что начинающему интересоваться игровыми серверами разработчику поможет мой опыт изложенный в этих статьях. Всем спасибо, кто прочитал до конца!
Игровой real-time сервер простыми словами: теория, архитектура на Python, оптимизация, автомасштабирование в AWS
На кого рассчитана данная статья Данная статья рассчитана на всех интересующихся, т.к. по большей части материал будет повествоваться в упрощенном абстрактном виде (схемы, картинки) в угоду легкому...
 habr.com
habr.com