Чат-бот ChatGPT наделал много шума: люди задают ему вопросы и удивляются точности ответов, студенты с его помощью пишут дипломные работы, а копирайтеры публикуют статьи с названием типа «Сможет ли ChatGPT заменить копирайтеров?».
Мы решили проверить технологию, на которой основан ChatGPT, посмотреть актуальное состояние open-source GPT-3-like моделей и ответить на вопрос — можно ли обучить GPT-3-like модель в домашних условиях?
Для эксперимента выбрали GPT-J и не самый мощный ПК с видеокартой Nvidia GTX 1080TI с 11 GB VRAM. Оказалось, что этого достаточно не только, чтобы загрузить модель, но и дообучить ее (fine-tune). Рассказываем — как мы это сделали.
Понять преимущества модели GPT-J от команды EleutherAI проще всего, если взглянуть на таблицу, которую привели сами разработчики. Мы покажем ее в сокращенном виде. Полную версию можно посмотреть по ссылке [2].

Сравнение GPT-like моделей.
Насколько хороша модель, можно увидеть по значениям бенчмарков:
В качестве основного стека для дообучения GPT-J мы выбрали Python, transformers и pytorch lightning. GPT-J и другие достижения open source-сообщества можно найти на Hugging Face Hub [5].
Квантизованная модель GPT-J [3] доступна благодаря ребятам из Training Transformers Together [9] и занимает примерно 6 GB на GTX 1080 TI. Давайте с ней поздороваемся.
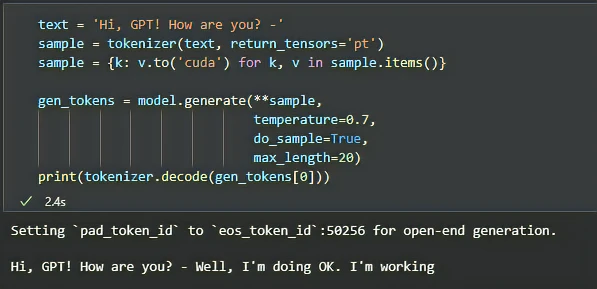
Первым делом нужно разобраться, что принимает и возвращает модель — input и output соответственно, и какая у этого размерность. Модель принимает последовательность слов и возвращает вероятности следующего слова для каждого из последовательности. GPT очень внимательный (привет, attention!) слушатель, который, услышав слово, сразу же пытается предсказать следующее.
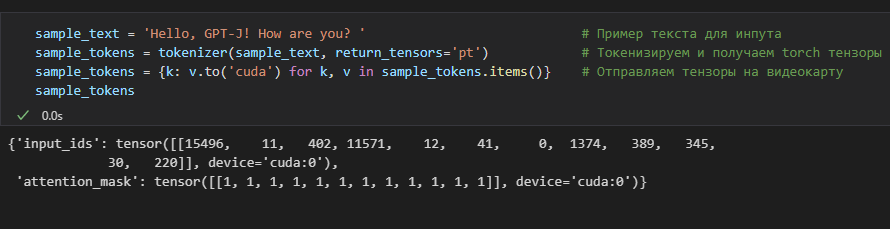
Модель принимает вектор токенов (input_ids) и attention mask. Оба элемента с максимальной длиной 2048.
На иллюстрации выше видно, как sample_text превращается в input_ids и attention_mask.
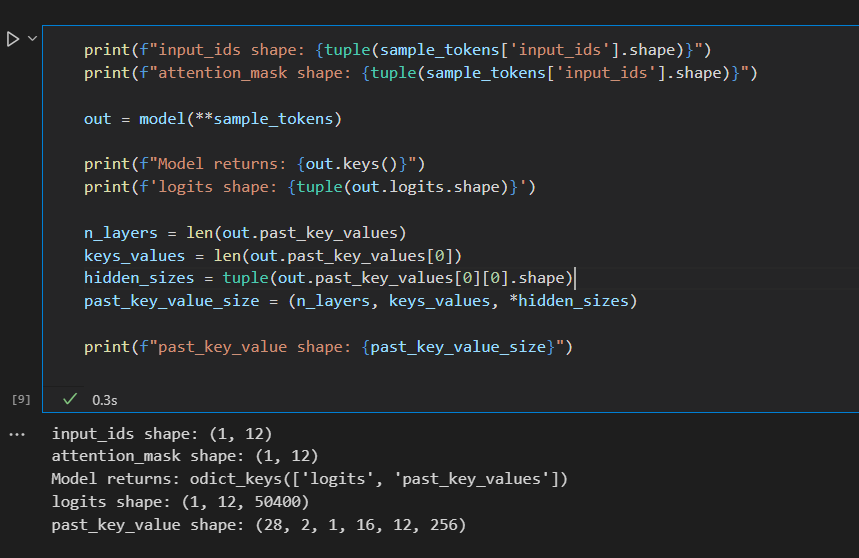
Размер тензора logits — (batch_size, sample_len, vocab_size). Наш исходный сэмпл 'Hello, GPT-J! How are you?' содержит 12 токенов, поэтому logits имеет форму (1, 12, 50400).
Для каждого токена в исходном сэмпле мы получаем вероятности для всех токенов в словаре модели. При генерации текста нас интересует только вероятность для последнего токена. В дообучении модели могут участвовать все или только избранные вероятности для входной последовательности.
Для этого будем использовать Hate Speech and Offensive Language Dataset [11]. Поскольку GPT уже много знает о языке и словах, мы уменьшим количество тренировочных данных и возьмем случайным образом лишь 1000 примеров, предварительно сбалансировав классы. Для валидации выберем 200 сбалансированных примеров. Нам предстоит обучить GPT-J-8bit генерировать нужную метку класса.
Подготовка входного сэмпла играет важную роль для обучения модели. В тренировочный сэмпл, кроме самого текста, который подлежит классификации, можно добавить дополнительную информацию: начиная от специальных разделителей блоков сэмпла и заканчивая целыми инструкциями. К важному можно отнести специальные токены, которые отделяют затравку от завершения (то есть от того, чему мы хотим обучить модель). С помощью токенов-разделителей мы как бы указываем – когда ждем от нашего GPT выполнения желаемого.
Нам удалось добиться одинаково хорошей точности как в случае с затравками-инструкциями, так и в случае затравок, состоящих только из целевого текста с разделителем.
Единственный минус инструкций состоит в том, что входные сэмплы получаются длиннее. Но зато, благодаря инструкциям, модель лучше научится понимать – чего мы от нее хотим: GPT видит инструкцию и, соотнося ее с результатом, понимает, что все варианты ответов перечислены в инструкции и ей нужно только выбрать правильный. Это дает возможность научить GPT решать другие классы задач, которые могут быть сформулированы в рамках той же структуры инструкций.
Авторы статьи LoRA: Low-Rank Adaption of Large Language Models [12] предлагают очень интересный и эффективный способ дообучения огромных моделей. Зачем тренировать все параметры модели? Давайте заморозим все слои и к каждому добавим тренируемый адаптер с низкой размерностью. Адаптер представляет собой два линейных слоя A и B размера (d, r) и (r, d). И вместо тренировки «родного» слоя модели W размера (d,d) (а у GPT-J d равен 4096) предлагается тренировать две матрицы поменьше. Авторы LoRA демонстрируют, что оптимальный r равен 2, чем оправдывают название своего подхода Low-Rank Adaption. Его логика отображена на схеме:

LoRA
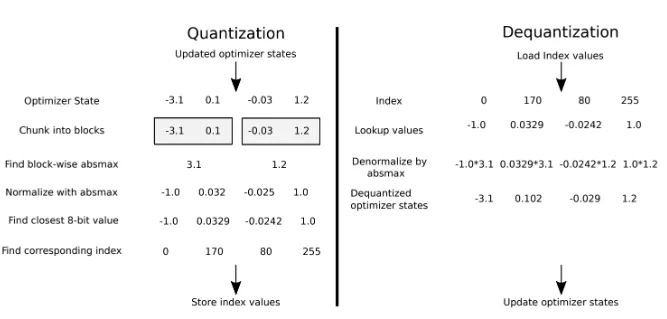
Стандартным инструментом обучения параметров модели является оптимизатор Adam. Нам же нужен какой-то экономный аналог. В статье 8-Bit Optimizers via Block-wise Quantization [13] авторы предлагают квантизовать оптимизатор, в частности, его состояния, которые включают статистику по градиентам (поправкам) для параметров модели. Более того, предлагается блочная (block-wise) квантизация, которая может выполняться параллельно. Картинка из оригинальной статьи прекрасно иллюстрирует суть этого:
Спасибо авторам за то, что они также опубликовали репозиторий bitsandbytes [14] с реализацией их подхода.
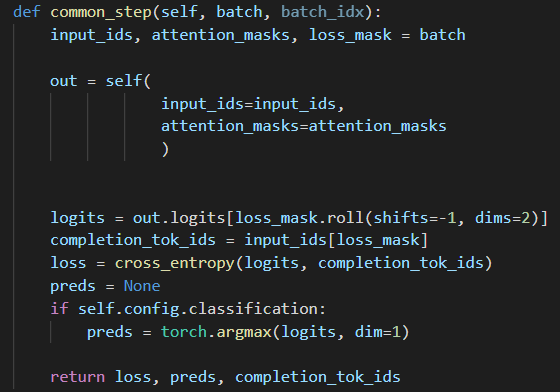
Вот так выглядит шаг обучения модели:
В зависимости от длины сэмплов и объема памяти видеокарты мы можем использовать батчи. Нам потребуется привести к одинаковой длине все сэмплы — сделать паддинг коротких сэмплов и обрезать длинные. Батчинг поможет ускорить процесс обучения.
После того, как архитектура GPT-J с адаптерами собрана, данные для обучения загружены и предобработаны, а оптимизатор Adam8bit наготове. Мы можем приступать к fine-tuning’у и валидации.
Будем обучать модель на протяжении трёх эпох. Также сравним четыре подхода:

GPT-J fine-tuning report
Теперь испытаем модели OpenAI через API в идентичных условиях. Вот отчет по fine-tuning’у GPT-3 Ada и GPT-3 Davinci [17]. Предположительно, значение loss отличаются на порядок от нашей модели из-за различия функций потерь. В нашем подходе мы использовали стандартную cross entropy.

OpenAI’s models fine-tuning report
Взглянем на таблицу точности предсказаний всех опробованных моделей и подходов:

Сравнение GPT-J и моделей OpenAI
Нам удалось превзойти точность моделей от OpenAI в тестовой задаче модерации при идентичных условиях. Адаптеры предлагают наилучшую точность, и чем их больше, тем точнее предсказания модели. Few-shot подход оставляет желать лучшего. А ChatGPT (GPT-3.5-turbo) дает весьма посредственную точность, хотя и лучше, чем GPT-J без дообучения.
Мы смогли обучить GPT-J в домашних условиях, причем так, что он не уступает разработкам больших компаний. Однако важно отметить, что если дообучать OpenAI GPT-3 модели предложенным в документации API способом — без инструкций, только сырой текст с разделителем — то Davinci демонстрирует идентичную точность — 84 %. С другой стороны, использование дообученных моделей OpenAI будет стоить денег: например, за генерацию приблизительно двух печатных страниц текста мы заплатим 12 центов для самой крутой модели, причем в стоимость входят и затравки.

Цена генерации дообученных моделей
Дообученная модель показывает, что благодаря инструкциям в затравках она научилась понимать, что мы от нее хотим, без дополнительного обучения на новых категориях.

Классификация заголовков новостей
Нам до сих пор нужно быть нянькой для искусственного интеллекта: готовить данные и придумывать все более эффективные способы дообучения. Одомашнить многообещающую открытую GPT помогли концепции тренируемых адаптеров и квантизуемого оптимизатора. Мы также предлагаем ознакомиться с репозиторием [18], который воспроизводит все полученные здесь результаты.
Ссылки

 habr.com
habr.com
Мы решили проверить технологию, на которой основан ChatGPT, посмотреть актуальное состояние open-source GPT-3-like моделей и ответить на вопрос — можно ли обучить GPT-3-like модель в домашних условиях?
Для эксперимента выбрали GPT-J и не самый мощный ПК с видеокартой Nvidia GTX 1080TI с 11 GB VRAM. Оказалось, что этого достаточно не только, чтобы загрузить модель, но и дообучить ее (fine-tune). Рассказываем — как мы это сделали.
Почему именно GPT-J
GPT (англ. Generative Pre-trained Transformer — генеративный предобученный трансформер) — это гигантская нейронная сеть, которая обучена на огромном количестве данных предсказывать следующее за последовательностью слово. GPT моделирует естественные языки, помнит контекст и генерирует тексты. Для тех, кто хочет узнать побольше про архитектуру GPT, мы оставим ссылки [1] и [15].Понять преимущества модели GPT-J от команды EleutherAI проще всего, если взглянуть на таблицу, которую привели сами разработчики. Мы покажем ее в сокращенном виде. Полную версию можно посмотреть по ссылке [2].
Сравнение GPT-like моделей.
Насколько хороша модель, можно увидеть по значениям бенчмарков:
- LAMBADA — это датасет, который используется как бенчмарк для предсказания слова по широкому контексту. Для этого бенчмарка в таблице приведены две метрики: перплексия PPl (меньше — лучше) и точность Acc (выше — лучше);
- Winorgande — это датасет с текстовыми задачами и вариантами ответов;
- Hellaswag — датасет с текстовыми задачами на здравый смысл;
- PIQA — также бенчмарк для оценки здравого смысла – нацелен на оценку физических знаний модели.
В качестве основного стека для дообучения GPT-J мы выбрали Python, transformers и pytorch lightning. GPT-J и другие достижения open source-сообщества можно найти на Hugging Face Hub [5].
8 bit GPT-J
Модель от EleutherAI с float16 параметрами требует около 21 GB VRAM — а это для нас проблема. Чтобы как-то уместить этого монстра на наш ПК, мы можем прибегнуть к квантизации [6, 7] — хитрым способом сопоставить оригинальные float16 параметры модели с int8 параметрами и уменьшить объем занимаемой памяти в два раза. Кажется, что будет потеря в точности, но судя по результатам сравнения GPT-J и GPT-J-8bit, разница в точности этих моделей в пределах погрешности [8].Квантизованная модель GPT-J [3] доступна благодаря ребятам из Training Transformers Together [9] и занимает примерно 6 GB на GTX 1080 TI. Давайте с ней поздороваемся.
Первым делом нужно разобраться, что принимает и возвращает модель — input и output соответственно, и какая у этого размерность. Модель принимает последовательность слов и возвращает вероятности следующего слова для каждого из последовательности. GPT очень внимательный (привет, attention!) слушатель, который, услышав слово, сразу же пытается предсказать следующее.
Input
Так выглядят входные данные:
Модель принимает вектор токенов (input_ids) и attention mask. Оба элемента с максимальной длиной 2048.
- Вектор токенов состоит из целых чисел: id токенов из словаря модели. Словарь модели содержит 50257 токенов;
- Attention mask: вектор с нулями и единицами, задача которого — сообщить модели – на какие токены обращать внимание (1), а на какие — нет (0).
На иллюстрации выше видно, как sample_text превращается в input_ids и attention_mask.
Output
Внимательный GPT постоянно пытается предсказать следующее слово, но кроме внимательности мы еще можем рассчитывать на его хорошую память. Модель по умолчанию возвращает вероятности следующих токенов (logits) и внутреннюю память модели (past_key_values). Так выглядят output нашей модели:
Размер тензора logits — (batch_size, sample_len, vocab_size). Наш исходный сэмпл 'Hello, GPT-J! How are you?' содержит 12 токенов, поэтому logits имеет форму (1, 12, 50400).
Для каждого токена в исходном сэмпле мы получаем вероятности для всех токенов в словаре модели. При генерации текста нас интересует только вероятность для последнего токена. В дообучении модели могут участвовать все или только избранные вероятности для входной последовательности.
- past_key_value — это и есть память нашей модели. Размер тензора: (n_layers, key_value, batch, n_attention_heads, sample_len, head_embedding_dimension);
- n_layers — это количество слоев GPT-J;
- key_value — кортеж из ключей и значений в контексте механизма внимания (Attention) [10];
- batch — размер батча;
- n_attention_heads — количество голов attention;
- sample_len — длина сэмпла;
- head_embedding_dimension — внутренний размер attention head;
- n_layers, key_value, n_attention_heads, head_embedding_dimension — размерности, которые относятся к конфигурации модели.
Тестовая задача
Представим, что мы хотим научить GPT модерировать чаты — модель будет классифицировать сообщения на 3 класса: hate (содержащее ненависть), offensive (содержащее угрозу), neutral (нейтральное).Для этого будем использовать Hate Speech and Offensive Language Dataset [11]. Поскольку GPT уже много знает о языке и словах, мы уменьшим количество тренировочных данных и возьмем случайным образом лишь 1000 примеров, предварительно сбалансировав классы. Для валидации выберем 200 сбалансированных примеров. Нам предстоит обучить GPT-J-8bit генерировать нужную метку класса.
Как подготовить данные?
Когда мы хотим чему-то научить GPT, нам нужно сказать ему начало фразы, а затем оценить его вариант завершения фразы, поэтому тренировочный сэмпл содержит две части — затравку и завершение.Подготовка входного сэмпла играет важную роль для обучения модели. В тренировочный сэмпл, кроме самого текста, который подлежит классификации, можно добавить дополнительную информацию: начиная от специальных разделителей блоков сэмпла и заканчивая целыми инструкциями. К важному можно отнести специальные токены, которые отделяют затравку от завершения (то есть от того, чему мы хотим обучить модель). С помощью токенов-разделителей мы как бы указываем – когда ждем от нашего GPT выполнения желаемого.
Нам удалось добиться одинаково хорошей точности как в случае с затравками-инструкциями, так и в случае затравок, состоящих только из целевого текста с разделителем.
Единственный минус инструкций состоит в том, что входные сэмплы получаются длиннее. Но зато, благодаря инструкциям, модель лучше научится понимать – чего мы от нее хотим: GPT видит инструкцию и, соотнося ее с результатом, понимает, что все варианты ответов перечислены в инструкции и ей нужно только выбрать правильный. Это дает возможность научить GPT решать другие классы задач, которые могут быть сформулированы в рамках той же структуры инструкций.
Что обучать? (Low-Rank Adapters)
В GPT-J-8bit параметры квантизованы. Тренировка квантизованных целочисленных параметров привычными алгоритмами не представляется разумным подходом хотя бы потому, что область значений функции потерь cross entropy loss лежит в [0, 1]. Но даже квантизация не избавляет нас от тренировки огромного количества параметров и затрат на вычисления.Авторы статьи LoRA: Low-Rank Adaption of Large Language Models [12] предлагают очень интересный и эффективный способ дообучения огромных моделей. Зачем тренировать все параметры модели? Давайте заморозим все слои и к каждому добавим тренируемый адаптер с низкой размерностью. Адаптер представляет собой два линейных слоя A и B размера (d, r) и (r, d). И вместо тренировки «родного» слоя модели W размера (d,d) (а у GPT-J d равен 4096) предлагается тренировать две матрицы поменьше. Авторы LoRA демонстрируют, что оптимальный r равен 2, чем оправдывают название своего подхода Low-Rank Adaption. Его логика отображена на схеме:
LoRA
Как обучать? (Adam8bit)
Загрузить модель в оперативную память видеокарты — это еще не приручить ее. Для дообучения GPT стандартными техниками требуется еще одна видеокарта, но мы обойдемся без нее и воспользуемся квантизованным оптимизатором.Стандартным инструментом обучения параметров модели является оптимизатор Adam. Нам же нужен какой-то экономный аналог. В статье 8-Bit Optimizers via Block-wise Quantization [13] авторы предлагают квантизовать оптимизатор, в частности, его состояния, которые включают статистику по градиентам (поправкам) для параметров модели. Более того, предлагается блочная (block-wise) квантизация, которая может выполняться параллельно. Картинка из оригинальной статьи прекрасно иллюстрирует суть этого:
Спасибо авторам за то, что они также опубликовали репозиторий bitsandbytes [14] с реализацией их подхода.
Последние приготовления и обучение
Мы описали ключевые способы, которые помогут нам приручить GPT-J. Но для того, чтобы научить GPT делать то, что нам нужно, необходимо как-то указывать ему на его ошибки. Мы используем loss mask в своем коде для того, чтобы взять из предсказаний модели только то, что должно быть сгенерировано, и сделать обратное распространение ошибки только по этим токенам. Так мы не будем считать ошибку на затравке, а посчитаем loss только на продолжении. И модель будет лучше понимать, что мы от нее хотим. Также если мы решаем задачу классификации, можно подсчитать точность предсказаний — это и будет метрикой оценки модели.Вот так выглядит шаг обучения модели:
В зависимости от длины сэмплов и объема памяти видеокарты мы можем использовать батчи. Нам потребуется привести к одинаковой длине все сэмплы — сделать паддинг коротких сэмплов и обрезать длинные. Батчинг поможет ускорить процесс обучения.
После того, как архитектура GPT-J с адаптерами собрана, данные для обучения загружены и предобработаны, а оптимизатор Adam8bit наготове. Мы можем приступать к fine-tuning’у и валидации.
Будем обучать модель на протяжении трёх эпох. Также сравним четыре подхода:
- Обучение 1D параметров модели (те слои, где использование адаптера бессмысленно) — 861 K обучаемых параметров;
- Адаптеры только для attention слоев — 2.7 M обучаемых параметров;
- Адаптеры для всех слоев — 5.2 М обучаемых параметров;
- Few-shot — без обучения.
Результаты
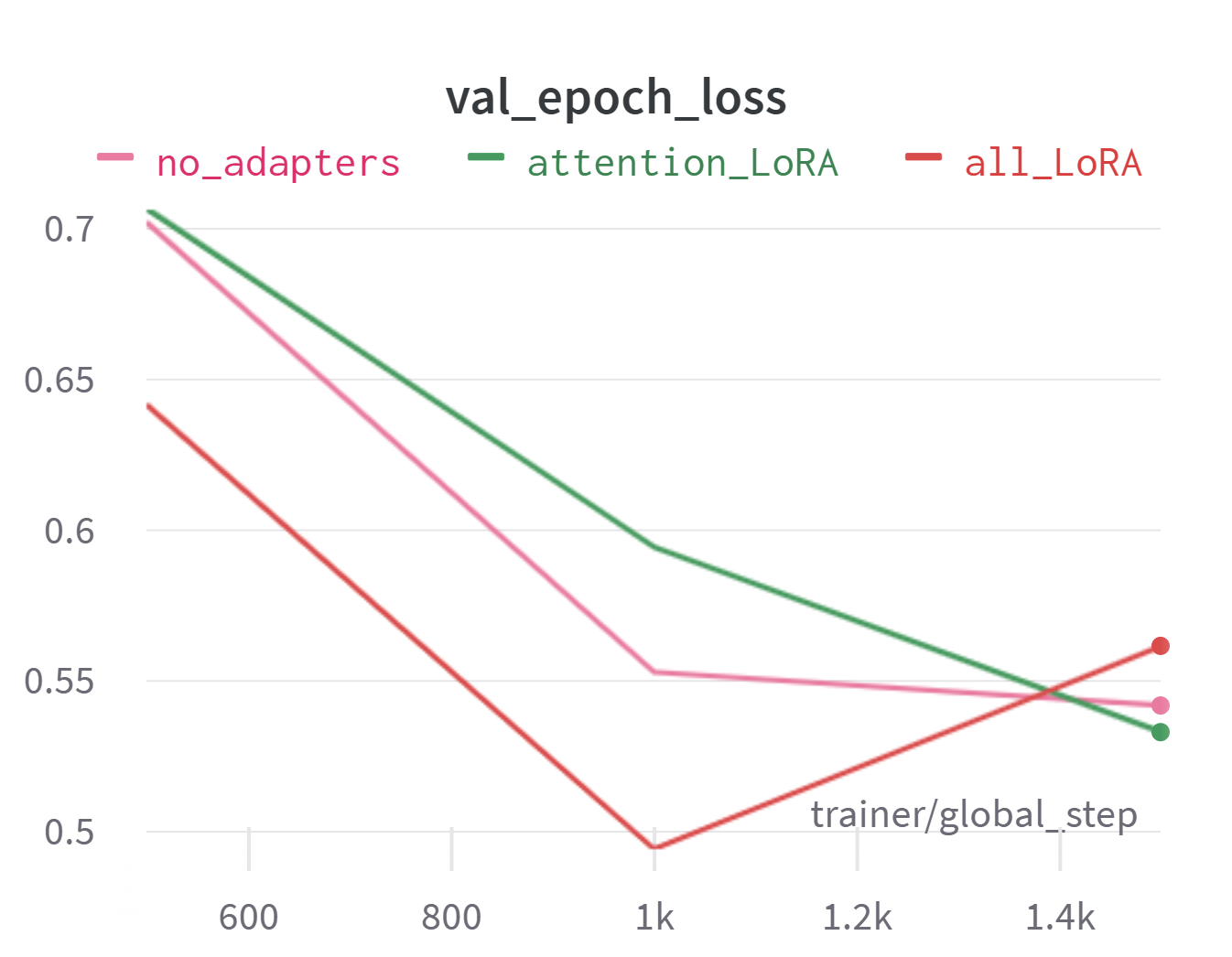
Для начала взглянем на отчет [16] по обучению для нашей GPT-J. График с loss нам нужен, чтобы убедиться, что модель обучается и loss уменьшается со временем от эпохи к эпохе. А от accuracy мы ожидаем, что она будет расти.
GPT-J fine-tuning report
Теперь испытаем модели OpenAI через API в идентичных условиях. Вот отчет по fine-tuning’у GPT-3 Ada и GPT-3 Davinci [17]. Предположительно, значение loss отличаются на порядок от нашей модели из-за различия функций потерь. В нашем подходе мы использовали стандартную cross entropy.
OpenAI’s models fine-tuning report
Взглянем на таблицу точности предсказаний всех опробованных моделей и подходов:
Сравнение GPT-J и моделей OpenAI
Нам удалось превзойти точность моделей от OpenAI в тестовой задаче модерации при идентичных условиях. Адаптеры предлагают наилучшую точность, и чем их больше, тем точнее предсказания модели. Few-shot подход оставляет желать лучшего. А ChatGPT (GPT-3.5-turbo) дает весьма посредственную точность, хотя и лучше, чем GPT-J без дообучения.
Мы смогли обучить GPT-J в домашних условиях, причем так, что он не уступает разработкам больших компаний. Однако важно отметить, что если дообучать OpenAI GPT-3 модели предложенным в документации API способом — без инструкций, только сырой текст с разделителем — то Davinci демонстрирует идентичную точность — 84 %. С другой стороны, использование дообученных моделей OpenAI будет стоить денег: например, за генерацию приблизительно двух печатных страниц текста мы заплатим 12 центов для самой крутой модели, причем в стоимость входят и затравки.
Цена генерации дообученных моделей
Преимущества инструкций в затравках
Чтобы подтвердить, что решение помещать в затравки инструкции действительно имеет преимущества, мы провели еще один эксперимент — предложили модели выбрать категорию для заголовков новостей с сайта BBC.Дообученная модель показывает, что благодаря инструкциям в затравках она научилась понимать, что мы от нее хотим, без дополнительного обучения на новых категориях.
Классификация заголовков новостей
Заключение
Когда мы заканчивали исследование, OpenAI предоставили доступ к API ChatGPT — gpt-3.5-turbo. Завышенные ожидания от технологии вызвали опасение, что gpt-3.5-turbo может обесценить это исследование. Но, как оказалось, чуда не произошло — результаты работы этой модели вы могли видеть в таблице выше. ChatGPT не может решить конкретную прикладную задачу так же хорошо, как дообученная модель.Нам до сих пор нужно быть нянькой для искусственного интеллекта: готовить данные и придумывать все более эффективные способы дообучения. Одомашнить многообещающую открытую GPT помогли концепции тренируемых адаптеров и квантизуемого оптимизатора. Мы также предлагаем ознакомиться с репозиторием [18], который воспроизводит все полученные здесь результаты.
Ссылки
- Building a GPT-like Model from Scratch with Detailed Theory and Code Implementation / Хабр (habr.com)
- EleutherAI/gpt-j-6B · Hugging Face
- hivemind/gpt-j-6B-8bit · Hugging Face
- The Pile (eleuther.ai)
- Models - Hugging Face
- How to accelerate and compress neural networks with quantization | by Tivadar Danka | Towards Data Science
- Achieving FP32 Accuracy for INT8 Inference Using Quantization Aware Training with NVIDIA TensorRT | NVIDIA Technical Blog
- Jupyter Notebook Viewer (nbviewer.org)
- https://training-transformers-together.github.io
- [1706.03762] Attention Is All You Need (arxiv.org)
- Hate Speech and Offensive Language Dataset | Kaggle
- [2106.09685] LoRA: Low-Rank Adaptation of Large Language Models (arxiv.org)
- [2110.02861] 8-bit Optimizers via Block-wise Quantization (arxiv.org)
- TimDettmers/bitsandbytes: 8-bit CUDA functions for PyTorch (github.com)
- [2005.14165] Language Models are Few-Shot Learners (arxiv.org)
-
GPT-J-8bit Finetuning for classification
https://github.com/vetka925/gpt-j-8bit-lightning-finetune api.wandb.ai
api.wandb.ai
- https://api.wandb.ai/links/vetka925/krtz93ul
- vetka925/gpt-j-8bit-lightning-finetune (github.com)
Как воспитать GPT модель в домашних условиях [LLaMA Update]
Чат-бот ChatGPT наделал много шума: люди задают ему вопросы и удивляются точности ответов, студенты с его помощью пишут дипломные работы, а копирайтеры публикуют статьи с названием типа «Сможет ли...
habr.com