Всем привет! Меня зовут Алексей Половинкин, и я отвечаю за Python в AGIMA. За последние 2 года мне повезло запускать сразу 2 крупных MVP-проекта: классифайд автомобилей для Казахстана и проект в сфере телемедицины. За это время у меня и моей команды накопилось много опыта по запуску подобных проектов, и им хотелось бы поделиться. В этой статье рассказываю, как не допускать ошибок на этапе MVP и какие практики полезно внедрять сразу.

MVP должен быть качественным. На сайте проекта пользователь не должен увидеть потекшую верстку и миллион ошибок — иначе он навсегда покинет страницу. То же касается внутренних систем. Человек должен без проблем пройти все ключевые шаги в системе:
Поэтому в MVP и должно быть минимальное количество жизнеспособных функций. Вы быстро выводите качественный продукт с ограниченной функциональностью, который позволит бизнесу проверить теорию или захватить кусок рынка, а вам — не сгореть от 120-часовой рабочей недели.
А когда таких задач 30, вы потратите недели на то, что можно было бы сделать без нервов и горячки.
Важно сделать качественно, важно сделать быстро. Остальное можно наверстать.
На этапе MVP ваша основная концепция должна заключаться в грамотном разделении логики и создании модульного монолита, который в будущем будет достаточно легко растащить на сервисы. Там вы столкнетесь с такими же проблемами, о которых речь пойдет дальше.
При старте MVP на микросервисах стоит учитывать, что они всегда дороже в разработке, чем монолит. Связано это с количеством утилит, которые нужны для реализации: коммуникация между сервисами, стандартизация их работы, работа с SSO, стандартизации логов, настройка общих принципов общения через брокер, выстраивание унифицированных API, распределение и мониторинг трафика и т. д.
Вторая причина — более сложная инфраструктурная работа. Например, монолит мы можем запускать даже на Systemctl. С микросервисами — сложнее. Тут как минимум нужно больше времени на отладку, запуск и тестирование системы.
В этой простой коммуникации одна проблема: нам нужно сделать внутренний сетевой запрос. Для его реализации нужно учесть 2 фактора:
Для этого придется создать отдельный клиент, который будет вытаскивать токен пользователя, перекладывать его в новый запрос и отправлять в другой сервис. При этом мы должны знать, где лежит наш сервис корзины. Мы не можем жестко зашить его, ведь тогда при изменении настроек сети администраторами может поломаться логика системы.
Значит, наш пакет должен решать 3 проблемы:
Проксирование токена пользователя — задача достаточно простая. Нужно взять заголовок из запроса и переложить его в другой. Но что, если выполняется бэкграунд таска и нам нужно сделать межсервисный запрос без наличия токена пользователя? Тут сложнее. Можно просто настроить внутренние сети Кубера, которые будут доступны только при коммуникации между контейнерами, но вряд ли вам это позволит специалист по информационной безопасности.
Мы решили реализовать этот механизм следующим образом.
Определили клиента для коммуникации с сервисом — например, с SSO. Он наследуется от базового S2S Client, который требует при инициализации набор параметров, таких как логин и пароль сервиса, а также дополнительные настройки — логгер, таймауты и т. д.
Для оптимизации скорости работы мы также решили сохранять токен прямо в память и работать с ней напрямую. В случае, если токен протух или отсутствует в памяти, клиент заново авторизует сервис в SSO и обновляет токен. При этом мы оставляем возможность сохранить токен в кэше, а не в памяти.
Внутри S2S Client инкапсулируется логика получения токена у SSO, логика обновления токена, если он протух, ретраи, если сервис не ответил с первого раза. Также в этом же клиенте происходит логирование всех запросов — как успешных, так и с ошибкой.
Теперь всё, что нам остается, создать новый клиент для общения с соседним сервисом, отнаследовавшись от S2S-клиента. В нем мы можем расширить логику. В итоге на создание унифицированного клиента для общения с любым сервисом требуется кратно меньше времени, правила общения остаются общими, снижается количество ошибок и упрощается работа с системой.
Но мы не просто должны настроить стандартный логгер. В микросервисах хорошо бы иметь возможность смотреть трейсинг запросов от входа до выхода:
Но вернемся к логам. Это эффективный способ понять, где была совершена ошибка и с какими данными мы ее получили. Логи — это отдельная и большая тема, о которой можно говорить долго: как настроить мониторинги, Prometheus и т. д. Но в этой статье приведу лишь основные «аксиомы» логирования.
Логи должны складироваться в отдельной системе, которая по принципу веб-воркеров будет забирать логи из stdout. Это системы типа ELK, graylog и т. п. У всех этих систем есть одна общая черта — они индексируют логи. Для удобного и быстрого поиска логов необходимо, чтобы их формат был одинаковым. Иначе придется преобразовывать их внутри этой системы, а это дорого.
Иными словами, когда один сервис вам плюет в лог XML, другой — JSON, третий — просто текст без определенного форматирования, лучшим вариантом будет всегда записывать логи в JSON и выплевывать в stdout JSON-строки. В этом случае их легко будет сохранить, индекснуть и проводить по ним поиск.
Зачастую лог выглядит примерно так:
"Start integration. Time %%%%"
"Integration finished. Time %%%%"
"Integration error: %errors"
Это не плохо, что написаны какие-то отладочные сообщения. Но в них нет метаданных. В этом логе мы можем только увидеть, что началась какая-то интеграция; началась в N времени и закончилась в X. Но что было между этими засечками, непонятно.
Поэтому мы логируем все параметры запроса, результаты ответа, обязательно указываем, куда шел запрос. При этом логи обязательно разделяются на разные уровни сложности: Info, Error и т. д. Debug-логи, кстати, тоже весьма полезны.
Тот же принцип стоит использовать для обычных логов, которые вы реализуете. Замените стандартный логгер, чтобы он мог забирать больше метаданных и преобразовывать их в JSON-строки. Без логов отлаживать систему будет сложно.
Собственно, логи в наших системах пишутся всегда на всех межсервисных взаимодействиях. Это реализовано так же в отдельном клиенте, который является базовым компонентом наших SDK.
Если развернуть init в S2S-клиенте, то можно увидеть, что внутри S2S-клиента при инициализации создаются несколько клиентов: для общения с SSO и с сервисом. И это клиенты, унаследованные от BaseClient.
BaseClient, в свою очередь, отвечает за стандартное поведение запросов: сертификаты SSL, политику ретраев, таймаут и прочее. Это еще одна абстракция над запросами, которая позволяет унифицировать общение между сервисами. И еще одна немаловажная задача, которую он решает, это запись в лог сообщений.
Я описал один из вариантов, как можно обрамлять ваши запросы. При каждом запросе происходит запись, куда и какой запрос был отправлен. Также логируются все ошибки с исчерпывающей информацией о том, с какой информацией был совершен запрос. При этом логируется и запрос, и ответ.
Затем всё это выкладывается в stdout и сохраняется в ELK, а в будущем этот лог используется в отладке и мониторинге.
В Django-мире есть библиотека Pytest-Django. Она предоставляет удобный тулинг в первую очередь при работе с БД. Поскольку у Django своя ORM-ка, Pytest-Django позволяют глубоко интегрироваться внутрь, предоставлять разный удобный тулинг из коробки для работы с БД, в том числе и в случае запуска тестов с помощью Xdist.
Фреймворки типа Fastapi/Flask/aiohttp не диктуют нам инструменты и архитектуру и подразумевают самостоятельный выбор различных инструментов, из которых предстоит построить приложение. В отличие от Django, придется потратить немало времени, чтобы написать свой собственный каркас для тестов.
Мы делали свой каркас в первую очередь с оглядкой на Pytest-Django, поэтому пришлось реализовать следующий функционал:
Ключевые моменты, которых мы придерживаемся при написании тестов в микросервисной архитектуре:
В этом тесте all_routes — функция, которая вернет список кортежей вида (‘урл’, ‘метод’). Причем урлы она генерирует с корректными path_params: допустим, для урла вида «/payments/{payment_id:uuid}/» она сгенерирует рандомный UUID. Пусть даже объекта с таким ID не существует в системе, нам это не так важно. Важно лишь то, что это корректный существующий урл для фреймворка, на который у нас не будет ошибки 404.
Основные отличия Dramatiq и Celery:
Конечно, запустить его можно, но мы стали ловить разные трудноуловимые баги при работе с БД, редкие проблемы с транзакциями, фантомно закрывающиеся коннекты и т. д. К тому же оказалось, что логи нужного нам формата не очень легко прикрутить к Celery. Также непросто настроить корректный алертинг ошибок в Sentry согласно бизнес-логике. Бизнесовые эксепшены мы не хотим отправлять в Sentry, хотим только неожиданные от Python. Плюс конструкции для запуска асинхронного кода из синхронного выглядели ужасно.
Учитывая всё это, код наших тасок был монструозный, с разными костылями и трудно отлаживаемыми багами. Поэтому мы написали собственную реализацию продюсера-консьюмера на базе библиотеки Aiopika. Из кода исчезли костыли для запуска асинхронного кода, появилась возможность добавлять свои Middleware, но для воркера.
И поскольку теперь мы можем нативно работать с асинхронностью Python, наш воркер теперь умеет обрабатывать не строго одну таску, а сразу несколько за один момент времени. Выглядит это всё плюс-минус так же, как это было бы в Celery или Dramatiq.
Более того, в процессе разработки мы немного пересмотрели подход к общению между сервисами через брокер. В начале разработки MVP-системы сервисы-продюсеры знали о сервисах-консьюмерах и явно отсылали события в очереди друг друга. Поначалу это работало неплохо, но в процессе роста мы поняли, что сервисы-продюсеры стали слишком много знать о сервисах-консьюмерах и перенимать часть бизнес-логики в момент, когда решали, надо или не надо отправлять сообщение.
Поэтому мы перешли на другой подход: события сервисов-продюсеров стали просто бродкастами, то есть продюсеры перестали знать о своих консьюмерах, а сервисы-консьюмеры уже сами решали, надо ли им подписываться на эти события и сами, согласно бизнес-требованиям, стали проверять, надо ли обрабатывать это событие. Поскольку событие одно, а триггеров может быть сколько угодно, мы написали вдобавок простые классы-джобы такого вида:
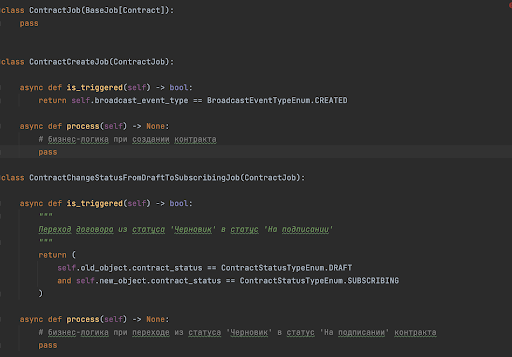
Здесь is_triggered — метод, который возвращает True/False в зависимости от того, должен ли он сработать на этом ивенте или нет. Метод process — бизнес-логика этой джобы.
Далее список джоб передается специальному экзекутора, который по методу is_triggered проверяет необходимость запуска джобы и запускает нужные. Возможно, это не самое красивое решение, но важнее другое: мы смогли красивее и понятнее описывать правила срабатывания джоб — не используя кучи IF’ов, запускать джобы в асинхронном режиме, легко добавлять/удалять новые по требованию бизнеса. А разработчикам стало легче понимать структуру кода и поддерживать логику.
В микросервисах этим пакетом является отдельный микросервис. А значит, вам придется агрегировать всю логику обработки файлов в нем. Это несет накладные расходы. Нам нужно знать, от какого сервиса файл был загружен, какие у него метаданные. Файл приходится грузить напрямую в сервис S3. То есть микросервис, по бизнес-логике которого требуется загрузить файл (фотографии, docx, excel и т. п.), ничего про файл не знает, у него есть только метаданные.
Следовательно, нам потребуется отдельная асинхронная процедура синхронизации данных: сообщить микросервису, где лежит файл (какой у него урл), какой у этого файла идентификатор, всё ли с ним вообще окей и т. д.

 habr.com
habr.com
Почему MVP — это важно
Задача любого MVP (Minimal Viable Product) — быстро вывести на рынок решение, охватить максимальную аудиторию, привлечь клиентов. И ключевые факторы в запуске MVP-продукта — именно скорость вывода продукта на рынок.MVP должен быть качественным. На сайте проекта пользователь не должен увидеть потекшую верстку и миллион ошибок — иначе он навсегда покинет страницу. То же касается внутренних систем. Человек должен без проблем пройти все ключевые шаги в системе:
- зарегистрироваться;
- авторизоваться;
- увидеть объявления или подобрать специалиста;
- увидеть интеграцию с CRM;
- получить СМС или пуш и т. п.
Поэтому в MVP и должно быть минимальное количество жизнеспособных функций. Вы быстро выводите качественный продукт с ограниченной функциональностью, который позволит бизнесу проверить теорию или захватить кусок рынка, а вам — не сгореть от 120-часовой рабочей недели.
Какие сложности ждут команду
- Расплывчатые требования к проекту на старте.
В самом начале заказчик, как правило, еще не вполне понимает, как будет выглядеть проект. И речь не про дизайн, а про бизнес-логику. Какой будет флоу оплат, какие разделы должны быть, что из изначального скоупа действительно важно. - Почти всегда на старте теряются нюансы, и финальный скоуп расширяется.
Дело в том, что бизнес тоже развивается. Первоначальные идеи не всегда доживают до финала. Они развиваются, меняют приоритетность. Поэтому периодически возникают новые важные фичи, без которых нельзя запускать проект. Бывает и наоборот: фича, над которой команда билась неделю, вдруг становится не нужна. - Ошибки в реализации интеграций или объектной модели.
Важно понимать, что решения, которые вы принимаете на старте, будут жить с проектом долго. А изменить объектную модель сложно, так как у вас нет времени переписывать все сервисы, завязанные на нее. То же касается и архитектуры. Если вы ошиблись, скорее всего, придется жить с ней до завершения работ. - Подводные камни: сетевые инфраструктурные проблемы, БД нельзя использовать в соответствии с политикой компании, санкции, сервер слабее, чем должен быть, и т. п.
Тут может быть много неочевидных проблем. Например, на проекте в Казахстане мы с удивлением узнали, что у местного облачного провайдера нет Кубера. Нам пришлось вместе с ними тестировать и поднимать его. На это ушло 2 недели. - Из-за проблем выше часто страдает изначальная архитектура решений.
Архитектура, наверно, ключевой фактор в вашем проекте. Как вы построите систему, какие базы выберете, кто будет брокером, как будут общаться сервисы, какие будут модули. Ошибка на этом этапе многократно увеличивает количество часов в будущем на отладку и рефакторинг. - Любая ошибка в CORE очень много стоит.
Под CORE я понимаю модули или сервисы вашей системы. MDM, IDM и прочие сокращения, на основе которых вы строите обвязку сервисов для тех или иных нужд, либо какие-то ключевые пакеты, которые интегрируются во все сервисы системы.
Проблемы выше выглядят как проблемы менеджера, тимлида или архитектора. Но на этом этапе закладывается фундамент будущих проблем разработчика, поэтому понимать все эти обстоятельства важно.
Главные ошибки в MVP
- Неправильно собирают скоуп работ.
Недавний пример из практики: на старте проекта мы договорились с заказчиком, что сервис отзывов не так важен на старте проекта, потому что там не будет большого трафика. Значит, отзывы можно отложить. Договорились, что мы оставим простую форму, где будет возможность оценить сеанс и написать комментарий.
- Не фиксируют скоуп работ.
В конце концов этот сервис расширился еще до выхода из MVP. В нем появилась возможность выбрать несколько вариантов фидбека. В каждом были свои варианты проблем в чекбоксе. В итоге мы сначала внедрили не самую важную фичу на MVP, а потом еще и расширили ее.
А когда таких задач 30, вы потратите недели на то, что можно было бы сделать без нервов и горячки.
- Неправильно выбирают архитектуру.
- Слишком много или слишком мало времени тратят на ТЗ.
Бывает, что на простую функциональность пишут огромное ТЗ. Оно не очень поможет разработке, но съест много времени. Бывает и наоборот, когда на простую функциональность не дают ТЗ вовсе, хотя эта функциональность влияет на логику соседних сервисов. В итоге у нас получается несогласованность данных.
Важно сделать качественно, важно сделать быстро. Остальное можно наверстать.
Пакеты и утилки
В основном в этой статье буду говорить про микросервисы, потому что у монолитных MVP всё проще. Монолитные платформы проще в реализации, особенно когда у вас урезанный функционал. Но рынок больших продуктов массово уходит к микросервисам. Это понятная тенденция — масштабировать и развивать монолит сложнее.На этапе MVP ваша основная концепция должна заключаться в грамотном разделении логики и создании модульного монолита, который в будущем будет достаточно легко растащить на сервисы. Там вы столкнетесь с такими же проблемами, о которых речь пойдет дальше.
При старте MVP на микросервисах стоит учитывать, что они всегда дороже в разработке, чем монолит. Связано это с количеством утилит, которые нужны для реализации: коммуникация между сервисами, стандартизация их работы, работа с SSO, стандартизации логов, настройка общих принципов общения через брокер, выстраивание унифицированных API, распределение и мониторинг трафика и т. д.
Вторая причина — более сложная инфраструктурная работа. Например, монолит мы можем запускать даже на Systemctl. С микросервисами — сложнее. Тут как минимум нужно больше времени на отладку, запуск и тестирование системы.
SSO и внутренние запросы
Возьмем два сервиса: сервис эквайринга и корзина магазина. Они должны коммуницировать друг с другом. При оформлении корзины на фронтенде пользователь отправляет запрос на оплату в эквайринг. Эквайрингу необходимо получить его и убедиться в корректности корзины — что стоимость верная и т. д. Значит, должен произойти внутренний сетевой запрос от сервиса эквайринга в сервис корзины. Корзина отвечает, что всё корректно, и эквайринг проводит оплату.В этой простой коммуникации одна проблема: нам нужно сделать внутренний сетевой запрос. Для его реализации нужно учесть 2 фактора:
- от чьего имени мы делаем запрос из корзины в эквайринг — от пользователя или от сервиса;
- где находится соседний сервис.
Для этого придется создать отдельный клиент, который будет вытаскивать токен пользователя, перекладывать его в новый запрос и отправлять в другой сервис. При этом мы должны знать, где лежит наш сервис корзины. Мы не можем жестко зашить его, ведь тогда при изменении настроек сети администраторами может поломаться логика системы.
Значит, наш пакет должен решать 3 проблемы:
- обеспечение проксирования токенов,
- обеспечение коммуникации между сервисами,
- инкапсулирование адресов сервисов.
Проксирование токена пользователя — задача достаточно простая. Нужно взять заголовок из запроса и переложить его в другой. Но что, если выполняется бэкграунд таска и нам нужно сделать межсервисный запрос без наличия токена пользователя? Тут сложнее. Можно просто настроить внутренние сети Кубера, которые будут доступны только при коммуникации между контейнерами, но вряд ли вам это позволит специалист по информационной безопасности.
Мы решили реализовать этот механизм следующим образом.
Определили клиента для коммуникации с сервисом — например, с SSO. Он наследуется от базового S2S Client, который требует при инициализации набор параметров, таких как логин и пароль сервиса, а также дополнительные настройки — логгер, таймауты и т. д.
Для оптимизации скорости работы мы также решили сохранять токен прямо в память и работать с ней напрямую. В случае, если токен протух или отсутствует в памяти, клиент заново авторизует сервис в SSO и обновляет токен. При этом мы оставляем возможность сохранить токен в кэше, а не в памяти.
Внутри S2S Client инкапсулируется логика получения токена у SSO, логика обновления токена, если он протух, ретраи, если сервис не ответил с первого раза. Также в этом же клиенте происходит логирование всех запросов — как успешных, так и с ошибкой.
Теперь всё, что нам остается, создать новый клиент для общения с соседним сервисом, отнаследовавшись от S2S-клиента. В нем мы можем расширить логику. В итоге на создание унифицированного клиента для общения с любым сервисом требуется кратно меньше времени, правила общения остаются общими, снижается количество ошибок и упрощается работа с системой.
Логирование
Тут же возникает второй вопрос — что, если что-то пошло не так? В этом случае нам нужен лог.Но мы не просто должны настроить стандартный логгер. В микросервисах хорошо бы иметь возможность смотреть трейсинг запросов от входа до выхода:
- через какие сервисы прошел запрос,
- сколько было запросов в соседние сервисы,
- сколько они выполнялись и т. д.
Но вернемся к логам. Это эффективный способ понять, где была совершена ошибка и с какими данными мы ее получили. Логи — это отдельная и большая тема, о которой можно говорить долго: как настроить мониторинги, Prometheus и т. д. Но в этой статье приведу лишь основные «аксиомы» логирования.
Логи должны складироваться в отдельной системе, которая по принципу веб-воркеров будет забирать логи из stdout. Это системы типа ELK, graylog и т. п. У всех этих систем есть одна общая черта — они индексируют логи. Для удобного и быстрого поиска логов необходимо, чтобы их формат был одинаковым. Иначе придется преобразовывать их внутри этой системы, а это дорого.
Иными словами, когда один сервис вам плюет в лог XML, другой — JSON, третий — просто текст без определенного форматирования, лучшим вариантом будет всегда записывать логи в JSON и выплевывать в stdout JSON-строки. В этом случае их легко будет сохранить, индекснуть и проводить по ним поиск.
Зачастую лог выглядит примерно так:
"Start integration. Time %%%%"
"Integration finished. Time %%%%"
"Integration error: %errors"
Это не плохо, что написаны какие-то отладочные сообщения. Но в них нет метаданных. В этом логе мы можем только увидеть, что началась какая-то интеграция; началась в N времени и закончилась в X. Но что было между этими засечками, непонятно.
Поэтому мы логируем все параметры запроса, результаты ответа, обязательно указываем, куда шел запрос. При этом логи обязательно разделяются на разные уровни сложности: Info, Error и т. д. Debug-логи, кстати, тоже весьма полезны.
Тот же принцип стоит использовать для обычных логов, которые вы реализуете. Замените стандартный логгер, чтобы он мог забирать больше метаданных и преобразовывать их в JSON-строки. Без логов отлаживать систему будет сложно.
Собственно, логи в наших системах пишутся всегда на всех межсервисных взаимодействиях. Это реализовано так же в отдельном клиенте, который является базовым компонентом наших SDK.
Если развернуть init в S2S-клиенте, то можно увидеть, что внутри S2S-клиента при инициализации создаются несколько клиентов: для общения с SSO и с сервисом. И это клиенты, унаследованные от BaseClient.
BaseClient, в свою очередь, отвечает за стандартное поведение запросов: сертификаты SSL, политику ретраев, таймаут и прочее. Это еще одна абстракция над запросами, которая позволяет унифицировать общение между сервисами. И еще одна немаловажная задача, которую он решает, это запись в лог сообщений.
Я описал один из вариантов, как можно обрамлять ваши запросы. При каждом запросе происходит запись, куда и какой запрос был отправлен. Также логируются все ошибки с исчерпывающей информацией о том, с какой информацией был совершен запрос. При этом логируется и запрос, и ответ.
Затем всё это выкладывается в stdout и сохраняется в ELK, а в будущем этот лог используется в отладке и мониторинге.
Автотесты
Мы прививаем любовь к автотестам всем нашим сотрудникам. В AGIMA практически нет питоновских проектов, где нет тестов.В Django-мире есть библиотека Pytest-Django. Она предоставляет удобный тулинг в первую очередь при работе с БД. Поскольку у Django своя ORM-ка, Pytest-Django позволяют глубоко интегрироваться внутрь, предоставлять разный удобный тулинг из коробки для работы с БД, в том числе и в случае запуска тестов с помощью Xdist.
Фреймворки типа Fastapi/Flask/aiohttp не диктуют нам инструменты и архитектуру и подразумевают самостоятельный выбор различных инструментов, из которых предстоит построить приложение. В отличие от Django, придется потратить немало времени, чтобы написать свой собственный каркас для тестов.
Мы делали свой каркас в первую очередь с оглядкой на Pytest-Django, поэтому пришлось реализовать следующий функционал:
- создание тестовой БД;
- установка миграций;
- корректная работа с транзакциями для откатки изменений каждого теста;
- клонирование БД для каждого воркера в случае запуска вместе с Xdist;
- различные удобные генераторы JWT-токенов с необходимыми пермишенами/ролями.
Ключевые моменты, которых мы придерживаемся при написании тестов в микросервисной архитектуре:
- Unitests на ключевые функции и классы системы.
Они нужны в первую очередь для уверенности, что лишние изменения не поломают все сервисы. - Тесты на API-эндпоинты.
Такой выбор обусловлен в первую очередь тем, что, тестируя API, мы тестируем максимально возможное количество слоев приложения. Далее, если позволяют финансы и время, можно тестировать каждый слой уже отдельно. - Детерменированность данных.
При тестировании API-эндпоинтов мы стараемся максимально детерминировать все входные данные, которые требуются в процессе обработки пользовательского запроса. - Сравнение с эталонными результатами.
Как следствие предыдущего пункта, в идеале надо сравнивать HTTP-статус и текст ответа полностью, один в один. Если тестируемые эндпоинты начнут выдавать больше или меньше полей или обнаружится несоответствие формата каких-то полей, тесты тут же нам об этом просигнализируют. - Моки.
Очень много моков ответов от различных сервисов. Причем мокать лучше не классы/функции, а именно ответы сервисов, чтобы протестировать то, как отрабатывают ваши клиенты.
Например, наш стандартный тест выглядит так: в него подгружаются основные фикстуры, где мокаются все внешние запросы. После этого мы имитируем запрос на создание контракта с определенными данными. Проверяем статус ответа и сравниваем полученные данные с ожидаемым контрактом.
Есть также пачка универсальных тестов, которые мы копипастим из сервиса в сервис:
- тесты для Healthcheck-эндпоинтов;
- тесты для проверки эндпоинтов с разной дебаг-информацией;
- тесты для эндпоинтов, которые всегда «падают» для проверки Sentry;
- тесты миграций лесенкой (идея подсмотрена у Александра Васина из Яндекс): накатываем одну миграцию, откатываем, накатываем 2 миграции, откатываем и т. д.;
- тесты для проверки корректности пермишенов у эндпоинтов.
- при запросе без jwt-токена;
- при запросе с некорректным форматом авторизационного хедера;
- при запросе с некорректным jwt-токеном (просрочен, несовпадающая подпись);
- при отсутствии прав доступа.
В этом тесте all_routes — функция, которая вернет список кортежей вида (‘урл’, ‘метод’). Причем урлы она генерирует с корректными path_params: допустим, для урла вида «/payments/{payment_id:uuid}/» она сгенерирует рандомный UUID. Пусть даже объекта с таким ID не существует в системе, нам это не так важно. Важно лишь то, что это корректный существующий урл для фреймворка, на который у нас не будет ошибки 404.
Асинхронные таски
Для межсервисного асинхронного взаимодействия мы использовали RabbitMQ. В нашем случае и Celery, и Dramatiq верхнеуровнево подходили для Background-обработки тасок. Изначально мы остановились на Celery. Однако после мы заметили Dramatiq и некоторое время работали с ним.Основные отличия Dramatiq и Celery:
- Dramatiq работает под Windows;
- для Dramatiq можно создавать Middleware;
- субъективно, но исходный код Dramatiq более понятный, чем у Celery;
- Dramatiq поддерживает перезагрузку при изменении кода.
Конечно, запустить его можно, но мы стали ловить разные трудноуловимые баги при работе с БД, редкие проблемы с транзакциями, фантомно закрывающиеся коннекты и т. д. К тому же оказалось, что логи нужного нам формата не очень легко прикрутить к Celery. Также непросто настроить корректный алертинг ошибок в Sentry согласно бизнес-логике. Бизнесовые эксепшены мы не хотим отправлять в Sentry, хотим только неожиданные от Python. Плюс конструкции для запуска асинхронного кода из синхронного выглядели ужасно.
Учитывая всё это, код наших тасок был монструозный, с разными костылями и трудно отлаживаемыми багами. Поэтому мы написали собственную реализацию продюсера-консьюмера на базе библиотеки Aiopika. Из кода исчезли костыли для запуска асинхронного кода, появилась возможность добавлять свои Middleware, но для воркера.
И поскольку теперь мы можем нативно работать с асинхронностью Python, наш воркер теперь умеет обрабатывать не строго одну таску, а сразу несколько за один момент времени. Выглядит это всё плюс-минус так же, как это было бы в Celery или Dramatiq.
Более того, в процессе разработки мы немного пересмотрели подход к общению между сервисами через брокер. В начале разработки MVP-системы сервисы-продюсеры знали о сервисах-консьюмерах и явно отсылали события в очереди друг друга. Поначалу это работало неплохо, но в процессе роста мы поняли, что сервисы-продюсеры стали слишком много знать о сервисах-консьюмерах и перенимать часть бизнес-логики в момент, когда решали, надо или не надо отправлять сообщение.
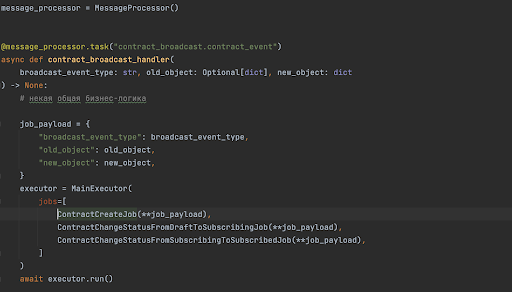
Поэтому мы перешли на другой подход: события сервисов-продюсеров стали просто бродкастами, то есть продюсеры перестали знать о своих консьюмерах, а сервисы-консьюмеры уже сами решали, надо ли им подписываться на эти события и сами, согласно бизнес-требованиям, стали проверять, надо ли обрабатывать это событие. Поскольку событие одно, а триггеров может быть сколько угодно, мы написали вдобавок простые классы-джобы такого вида:
Здесь is_triggered — метод, который возвращает True/False в зависимости от того, должен ли он сработать на этом ивенте или нет. Метод process — бизнес-логика этой джобы.
Далее список джоб передается специальному экзекутора, который по методу is_triggered проверяет необходимость запуска джобы и запускает нужные. Возможно, это не самое красивое решение, но важнее другое: мы смогли красивее и понятнее описывать правила срабатывания джоб — не используя кучи IF’ов, запускать джобы в асинхронном режиме, легко добавлять/удалять новые по требованию бизнеса. А разработчикам стало легче понимать структуру кода и поддерживать логику.
Рекомендации
Охватить все вопросы, которые приходится решать на MVP, в одной статье невозможно. Но вот несколько пунктов, которым точно стоит уделить особое внимание.- Проверка ИБ.
С ними всегда очень много проблем, нужно постоянно сканировать код, чтобы не позволить появиться критическим уязвимостям. - Нагрузочное тестирование.
- S3-хранилища.
В микросервисах этим пакетом является отдельный микросервис. А значит, вам придется агрегировать всю логику обработки файлов в нем. Это несет накладные расходы. Нам нужно знать, от какого сервиса файл был загружен, какие у него метаданные. Файл приходится грузить напрямую в сервис S3. То есть микросервис, по бизнес-логике которого требуется загрузить файл (фотографии, docx, excel и т. п.), ничего про файл не знает, у него есть только метаданные.
Следовательно, нам потребуется отдельная асинхронная процедура синхронизации данных: сообщить микросервису, где лежит файл (какой у него урл), какой у этого файла идентификатор, всё ли с ним вообще окей и т. д.
- Обязательно используйте авгоненерируемую документацию.
- Не пренебрегайте типизацией.
- Пишите автотесты.
- Просите помощи у коллег, если зависли на каком-то вопросе.
- Настройте Sentry.
- Фиксируйте версии библиотек.
Как избежать проблем при запуске MVP
Всем привет! Меня зовут Алексей Половинкин, и я отвечаю за Python в AGIMA . За последние 2 года мне повезло запускать сразу 2 крупных MVP-проекта: классифайд автомобилей для Казахстана и проект в...
habr.com