Современный ритейл уже не может обходиться без построения прогнозных и рекомендательных систем на основе Big Data. Но при больших объемах данных, таких как у «Ашана», работа с большими данными на локальных мощностях неэффективна: это дорого, сложно в эксплуатации и может привести к гонке за ресурсы между подразделениями.
Поэтому некоторые компании приходят к облачной Big Data-платформе как к инструменту, который дает простую масштабируемость и управляемость для систем, работающих с Big Data. Переход на такую платформу не будет простым: недостаточно перенести рабочие системы в облако как они есть. Потребуется глобальная перестройка — причем не только в плане архитектуры и технологий, но и на уровне корпоративной культуры. Пользователям отчетов придется учить SQL, а разработке, тестированию и эксплуатации — дружить под флагом DevOps.
Я — Александр Дорофеев, ex Head of Big Data в компании «Ашан Ритейл Россия», в статье расскажу:
В «Ашане» подразделение Big Data строит рекомендательные и прогнозные системы на основе Machine Learning (ML) и Artificial Intelligence (AI). Системы такого рода уже давно must have для крупных ритейлеров, желающих оставаться конкурентоспособными.
Мы разрабатываем и планируем разрабатывать решения для самого широкого спектра задач: прогнозирование ключевых показателей магазинов (трафик, товарооборот, объем продаж), определение оптимальных цен (эластичность спроса), сегментация клиентов, повышение лояльности за счет персональных предложений, оценка эффективности маркетинговых кампаний и многое другое.
Разработку и запуск пилота для своих первых ML-решений мы провели на доступном на тот момент технологическом стеке — собственной инфраструктуре. Для этого развернули отдельную базу данных в СУБД Oracle Exadata, которая также параллельно использовалась в качестве OLTP-хранилища для других бизнес-приложений компании. Загрузили из наших информационных систем исторические данные по продажам, ценам и прочим показателям в базу, очистили их. Разработали алгоритмы для первого решения Demand Forecasting Engine, которое прогнозирует спрос понедельно на 3 месяца вперед для товаров в конкретных магазинах (в разрезе «товар — магазин — неделя») и в итоге позволяет планировать закупки и сокращать издержки. Провели тестирование и выпустили пилот.
Результаты пилотного внедрения нас впечатлили. По сравнению с прогнозами, которые формировались ранее с помощью Excel Enterprise, точность новых алгоритмов оказалась на 17,5% выше для регулярных продаж и на 21% — для промопродаж. Это внушительный прирост по меркам нашей отрасли.
Поскольку пилот оказался успешным, перед нами встала задача его переноса в промышленную эксплуатацию. И по целому ряду причин использовать в бою тот же стек технологий, что и в пилоте, было невозможно:
Для решения этих проблем нам требовалось создать специализированную единую Big Data-платформу, которая позволила бы:
Первый шаг к созданию Big Data-платформы — выбор подходящего стека технологий. Чтобы определиться с будущей архитектурой, мы с руководителями бизнес-подразделений предприняли следующее:
На основании проведенного анализа пришли к следующей концептуальной архитектуре будущей Big Data-платформы.
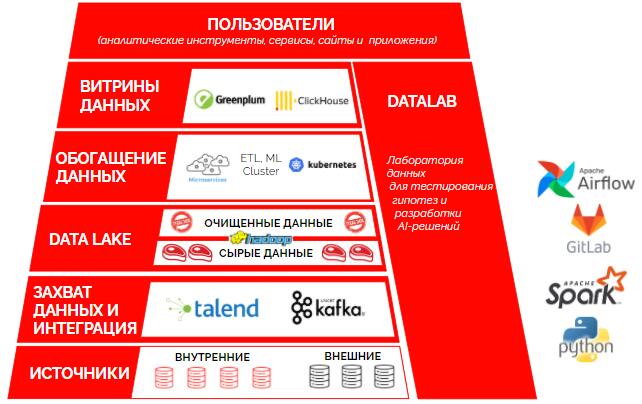
Целевая архитектура Big Data-платформы: базовые компоненты и их назначение
Компоненты, которые мы выбрали для построения платформы
Следующий вопрос, который мы решали при создании Big Data-платформы, — какой вариант развертывания выбрать: на своих мощностях (On-premise) или в публичном облаке. И здесь ключевое значение для нас — как, думаю, и для большинства компаний во время пандемии — имели финансовые затраты.
Оценив оба варианта развертывания, мы пришли к выводу: затраты на построение платформы в публичном облаке в первые два-три года будут существенно ниже по сравнению с On-premise-вариантом. Это благотворно скажется на ROI (Return on investment).
Были и другие аргументы в пользу облака:
Взвесив все за и против, мы выбрали развертывание платформы в публичном облаке. В качестве провайдера выбрали Mail.ru Cloud Solutions — за лучшее на тот момент соотношение цены, предлагаемых технологий, информационной безопасности, уровня поддержки и скорости развертывания. Пробный пилотный проект на MCS оказался успешным, при том что был был достаточно сложным: необходимо было за минимальный временной интервал создать определенное число ML-моделей, обеспечить их доступность, развернуть инфраструктуру и показать ее работоспособность. Облачная платформа Mail.ru Cloud Solutions соответствовала всем нашим требованиям.
Мы задействовали следующие сервисы Mail.ru Cloud Solutions:
На запуск платформы в облаке потребовалось около 4 недель, он включал следующие шаги:
На наш взгляд, все эти операции были выполнены в максимально короткие сроки, и ключевую роль здесь сыграли следующие факторы:
Разумеется, были и сложности, многие из которых невозможно было предусмотреть на этапе проектирования:
С большинством из этих сложностей мы справились, однако «культурные» изменения, связанные с перестройкой процессов внутри команды и внедрением DevOps-мышления, несомненно, потребуют большего времени.
Текущая архитектура Big Data-платформы «Ашана» с указанием основных потоков данных схематично приведена ниже.
Решение развернуто в защищенном контуре внутри публичного облака, установлен криптошлюз и межсетевой экран Check Point для организации VPN между облаком и On-premise-инфраструктурой.

Архитектура Big Data-платформы «Ашана» в облаке Mail.ru Cloud Solutions
Из компонентов платформы пока не развернуты:
Также завершена настройка Kubernetes-кластера, и мы постепенно приступаем к его активному использованию.
Схема взаимодействия развернутых компонентов платформы выглядит так:
В дополнение к описанным базовым компонентам мы применяем GitLab для поддержки процессов CI/CD и Apache Airflow — оркестратор, позволяющий управлять сложными цепочками последовательных ETL-процессов.
В итоге мы получили платформу, которая полностью удовлетворяет нашим требованиям. Она дает возможность обрабатывать аналитические запросы любой сложности, формировать ad hoc-отчеты, строить любые прогнозные модели и тестировать гипотезы.
Положительные эффект от платформы очевиден уже сейчас. Вот что произошло за полгода после ее внедрения:
Мы планируем и дальше расширять сотрудничество с Mail.ru Cloud Solutions и развивать Big Data-платформу в облачной инфраструктуре — добавлять в нее новые компоненты и сервисы. Условно наши стратегические планы можно разбить на четыре группы:
Источник статьи: https://habr.com/ru/company/mailru/blog/565664/
Поэтому некоторые компании приходят к облачной Big Data-платформе как к инструменту, который дает простую масштабируемость и управляемость для систем, работающих с Big Data. Переход на такую платформу не будет простым: недостаточно перенести рабочие системы в облако как они есть. Потребуется глобальная перестройка — причем не только в плане архитектуры и технологий, но и на уровне корпоративной культуры. Пользователям отчетов придется учить SQL, а разработке, тестированию и эксплуатации — дружить под флагом DevOps.
Я — Александр Дорофеев, ex Head of Big Data в компании «Ашан Ритейл Россия», в статье расскажу:
- почему для наших задач самым подходящим решением оказалась специализированная единая Big Data-платформа и какую целевую архитектуру мы выбрали;
- почему ее понадобилось делать на базе публичного облака и почему мы для этого выбрали облачную платформу Mail.ru Cloud Solutions;
- как происходил переезд в облако, с какими трудностями мы столкнулись и каких результатов удалось достичь.
Как мы пришли к необходимости Big Data-платформы и что было до нее
В «Ашане» подразделение Big Data строит рекомендательные и прогнозные системы на основе Machine Learning (ML) и Artificial Intelligence (AI). Системы такого рода уже давно must have для крупных ритейлеров, желающих оставаться конкурентоспособными.
Мы разрабатываем и планируем разрабатывать решения для самого широкого спектра задач: прогнозирование ключевых показателей магазинов (трафик, товарооборот, объем продаж), определение оптимальных цен (эластичность спроса), сегментация клиентов, повышение лояльности за счет персональных предложений, оценка эффективности маркетинговых кампаний и многое другое.
Разработку и запуск пилота для своих первых ML-решений мы провели на доступном на тот момент технологическом стеке — собственной инфраструктуре. Для этого развернули отдельную базу данных в СУБД Oracle Exadata, которая также параллельно использовалась в качестве OLTP-хранилища для других бизнес-приложений компании. Загрузили из наших информационных систем исторические данные по продажам, ценам и прочим показателям в базу, очистили их. Разработали алгоритмы для первого решения Demand Forecasting Engine, которое прогнозирует спрос понедельно на 3 месяца вперед для товаров в конкретных магазинах (в разрезе «товар — магазин — неделя») и в итоге позволяет планировать закупки и сокращать издержки. Провели тестирование и выпустили пилот.
Результаты пилотного внедрения нас впечатлили. По сравнению с прогнозами, которые формировались ранее с помощью Excel Enterprise, точность новых алгоритмов оказалась на 17,5% выше для регулярных продаж и на 21% — для промопродаж. Это внушительный прирост по меркам нашей отрасли.
Поскольку пилот оказался успешным, перед нами встала задача его переноса в промышленную эксплуатацию. И по целому ряду причин использовать в бою тот же стек технологий, что и в пилоте, было невозможно:
- Невысокая производительность. Используемые технологии (Oracle+Python на десктопах аналитиков данных) работали крайне медленно. Так, обучение прогнозных моделей для пилотных категорий (примерно 10% от всей продуктовой матрицы) занимало 2 недели.
Получается, в production-среде полный цикл обучения потребовал бы 20 недель. При том что скорость деградации точности моделей в условиях современного рынка высока: повторно обучать модели на основе последних данных нужно гораздо чаще, чем один раз в 20 недель. - Не хватало инструментов, которые специализируются на работе с Big Data. Реляционные базы вроде Oracle отлично справляются с OLTP-нагрузками и подходят в качестве надежного хранилища данных для бизнес-приложений. Но они не предназначены для обработки сложных аналитических запросов, построения витрин, ad hoc-отчетности (разовых уникальных запросов, которые объединяют разные данные) и других операций по обработке Big Data. Нам требовались современные инструменты, подходящие для OLAP-нагрузок, с помощью которых мы могли бы разрабатывать и запускать в прод аналитические продукты на базе ML и больших данных.
- Нужна отдельная платформа, которая не мешает основным бизнес-процессам. Аналитические операции на On-premise-базе Oracle Exadata влияли на производительность СУБД и стабильность других процессов, запущенных на ней. Это не устраивало бизнес — очевидно, что для аналитических задач необходим отдельный контур.
- Необходимость в масштабировании. Из-за невозможности параллельной обработки данных масштабирование не представлялось возможным. Кроме этого, наращивание мощностей хотелось автоматизировать, а не делать все вручную.
Для решения этих проблем нам требовалось создать специализированную единую Big Data-платформу, которая позволила бы:
- загружать, хранить и обрабатывать большие объемы данных;
- обеспечивать быструю разработку и вывод в production наших AI-решений;
- тестировать и тренировать модели машинного обучения;
- выполнять проверку гипотез: A/B-тестирование, U-тесты, Diff-тесты и так далее;
- строить ad hoc-отчеты;
- поддерживать лаборатории данных для бизнес-подразделений;
- гибко масштабироваться и автоматически реагировать на изменения в потреблении ресурсов — для оптимального баланса между ценой и производительностью.
Целевая архитектура
Первый шаг к созданию Big Data-платформы — выбор подходящего стека технологий. Чтобы определиться с будущей архитектурой, мы с руководителями бизнес-подразделений предприняли следующее:
- Составили список AI-продуктов, которые потребуются компании в ближайшие 3 года.
- Для каждого AI-продукта рассмотрели возможные методы реализации и выполнили оценку требуемых ресурсов: диски, RAM, CPU, сеть.
- Сформулировали перечень базовых требований, которым должна отвечать платформа:
- использование только Open Source-технологий;
- гибкое масштабирование всех компонентов;
- поддержка микросервисной архитектуры;
- соответствие корпоративным требованиям и требованиям законодательства РФ в области персональных данных.
На основании проведенного анализа пришли к следующей концептуальной архитектуре будущей Big Data-платформы.
Целевая архитектура Big Data-платформы: базовые компоненты и их назначение
Компоненты, которые мы выбрали для построения платформы
| Компонент | Целевое назначение |
|---|---|
| Talend | ETL-платформа для загрузки пакетных данных из систем-источников. Корпоративный стандарт «Ашана». |
| Apache Kafka | Система для загрузки потоковых данных из систем-источников в режиме реального времени (или максимально приближенном к нему). |
| Apache Hadoop | Платформа для распределенной обработки больших объемов данных в кластере машин. Мы выбрали ее для хранения, очистки и обработки холодных данных. |
| Apache Spark | Быстрый и универсальный фреймворк для обработки данных, хранимых в Hadoop. Поддерживает ETL, машинное обучение, потоковую обработку и построение графиков. Его планировали использовать в двух вариантах:
|
| Greenplum | MPP-система для построения комплексных тяжелых витрин. |
| ClickHouse | Колоночная OLAP СУБД, которая позволяет выполнять аналитические SQL-запросы в режиме реального времени. Мы выбрали ее для хранения очищенных горячих данных, на основе которых будет строиться аналитика, ad hoc-отчетность и витрины для сервисов. |
| Kubernetes | Оркестратор контейнерных приложений. Мы планировали использовать его для поддержки микросервисной архитектуры и автоматического масштабирования ресурсов, выделяемых под AI-решения. |
| Docker Private Registry | Репозиторий Docker-образов. |
| GitLab | Репозиторий кода и конвейер CI/CD-процессов. |
| Apache AirFlow | Оркестратор ETL-процессов. |
| S3 | Объектное хранилище для хранения обученных математических моделей (Pickle-файлов). |
Публичное облако vs On-premise: что выбрали и почему
Следующий вопрос, который мы решали при создании Big Data-платформы, — какой вариант развертывания выбрать: на своих мощностях (On-premise) или в публичном облаке. И здесь ключевое значение для нас — как, думаю, и для большинства компаний во время пандемии — имели финансовые затраты.
Оценив оба варианта развертывания, мы пришли к выводу: затраты на построение платформы в публичном облаке в первые два-три года будут существенно ниже по сравнению с On-premise-вариантом. Это благотворно скажется на ROI (Return on investment).
Были и другие аргументы в пользу облака:
- Большой выбор готовых сервисов. Многие облачные провайдеры предоставляют инструменты, которые были нам нужны для работы с Big Data, в виде готовых сервисов — aaS.
Среди таких сервисов следует выделить Kubernetes aaS. Преимущества работы с Big Data в Kubernetes — это автомасштабирование и изоляция сред. Первое обеспечивает автоматическое выделение ресурсов в зависимости от меняющихся нагрузок, второе отвечает за совместимость различных версий библиотек и приложений в Big Data-кластере. - Посекундная оплата. В облаке оплачиваются только фактически потребленные ресурсы: не нужно платить за RAM и CPU остановленных виртуальных машин.
- Гибкая масштабируемость. В облаке можно изменить объем вычислительных ресурсов в один клик — от пары до сотен серверов и обратно. И чаще всего подобные операции выполняются на лету — не нужно останавливать существующие виртуальные машины и диски.
- Техническая поддержка. Инженеры провайдера оказывают всестороннюю поддержку вашей команде как на старте проекта, так и во время дальнейшей эксплуатации.
Взвесив все за и против, мы выбрали развертывание платформы в публичном облаке. В качестве провайдера выбрали Mail.ru Cloud Solutions — за лучшее на тот момент соотношение цены, предлагаемых технологий, информационной безопасности, уровня поддержки и скорости развертывания. Пробный пилотный проект на MCS оказался успешным, при том что был был достаточно сложным: необходимо было за минимальный временной интервал создать определенное число ML-моделей, обеспечить их доступность, развернуть инфраструктуру и показать ее работоспособность. Облачная платформа Mail.ru Cloud Solutions соответствовала всем нашим требованиям.
Мы задействовали следующие сервисы Mail.ru Cloud Solutions:
- Cloud Big Data на основе Hadoop и Spark. Хранилище сырых и холодных данных, в которое будет поступать необработанная информация из различных источников для последующей тренировки ML-моделей и построения отчетов.
- СУБД ClickHouse. Хранилище горячих данных, где будут размещаться продуктовые витрины для наших AI-решений и витрины для аналитиков, с возможностью подключения BI-инструментов.
- Kubernetes aaS. Решение, которое позволит автоматически масштабировать выделяемые под обучение ML-моделей вычислительные ресурсы, не оплачивая время их простоя. Причем cluster autoscaler у данного провайдера имеется «из коробки». Подробнее о Kubernetes aaS в исполнении MCS на «Хабре» есть отдельная статья.
- GitLab. Конвейер CI/CD. Доступен в Marketplace Mail.ru Cloud Solutions.
- AirFlow. Оркестратор ETL-процессов, тоже есть в Marketplace Mail.ru Cloud Solutions.
Как проходил запуск платформы
На запуск платформы в облаке потребовалось около 4 недель, он включал следующие шаги:
- Развертывание в облаке базовых компонентов, необходимых для запуска AI-сервисов: Hadoop+Spark и ClickHouse в виде PaaS (то есть управляемых сервисов), GitLab и AirFlow.
- Настройка криптошлюза Check Point для организации VPN.
- Миграция исторических данных (с глубиной в несколько лет) на новую Big Data-платформу. Данные переносили наши дата-инженеры самостоятельно, используя Talend и Apache Sqoop. Последний инструмент входит в сборку Hadoop от Mail.ru Cloud Solutions и предназначен для транспортировки в Hadoop данных из классических реляционных баз данных: Oracle, MySQL, PostgreSQL и других.
- Проектирование и запуск первых 14 ETL-потоков для загрузки минимально необходимого объема данных.
- Разработка и запуск основных процедур Data Quality (DQ), проверяющих качество данных, то есть их соответствие всем требованиям для дальнейшей обработки и анализа.
На наш взгляд, все эти операции были выполнены в максимально короткие сроки, и ключевую роль здесь сыграли следующие факторы:
- Высокий уровень экспертности нашей команды — в частности, в области миграции данных из реляционных баз в Hadoop.
- Запуск компонентов поэтапно, от одного к другому — это позволило уделять больше внимания каждому инструменту, избегая типичных ошибок в развертывании и настройке.
- Высокий уровень поддержки со стороны инженеров и архитекторов Mail.ru Cloud Solutions. Все вопросы решали очень быстро и качественно, будь то банальная консультация по работе компонента или установка необходимой нам версии ClickHouse, отсутствовавшей на тот момент.
Разумеется, были и сложности, многие из которых невозможно было предусмотреть на этапе проектирования:
- Требовалось переписать большой объем кода. Нам было важно не только развернуть все необходимые компоненты и заполнить их данными, но и максимально быстро получить отдачу от новой платформы. Поэтому в планы по запуску проекта также включили работы по установке и настройке первого AI-сервиса, выполняющего прогнозирование спроса, — Demand Forecasting Engine.
На его запуск потребовалось около 9 недель, хотя изначально мы рассчитывали на 4 недели. Узким местом оказались работы по переписыванию кода, который отвечает за построение витрин для обучения ML-моделей, само обучение и формирование прогнозов. - Дефицит DevOps-инженеров с опытом работы в K8s. Казалось бы, Kubernetes давно стал общепризнанным стандартом в области оркестрации контейнерных приложений. Однако поиск специалистов, умеющих работать с ним, оказался не самой простой задачей.
- Обучение языку SQL аналитиков из бизнес-подразделений. Многие сотрудники не знали SQL даже на базовом уровне. Поэтому прежде чем предоставить им доступ для построения витрин, мы организовали для них внутренние курсы по обучению SQL и работе в ClickHouse.
- Внедрение культуры DevOps. Как оказалось, недостаточно освоить новые инструменты и технологии: значительные изменения требуются внутри самой команды, на уровне мышления каждого ее участника. Мы только начинаем внедрение Kubernetes и CI/CD, но даже первые шаги в этом направлении показывают, что программистам, системным администраторам и тестировщикам нужно тесно сотрудничать на всех этапах разработки.
С большинством из этих сложностей мы справились, однако «культурные» изменения, связанные с перестройкой процессов внутри команды и внедрением DevOps-мышления, несомненно, потребуют большего времени.
Особенности реализации Big Data-платформы в облаке Mail.ru Cloud Solutions
Текущая архитектура Big Data-платформы «Ашана» с указанием основных потоков данных схематично приведена ниже.
Решение развернуто в защищенном контуре внутри публичного облака, установлен криптошлюз и межсетевой экран Check Point для организации VPN между облаком и On-premise-инфраструктурой.
Архитектура Big Data-платформы «Ашана» в облаке Mail.ru Cloud Solutions
Из компонентов платформы пока не развернуты:
- Greenplum — тяжелые витрины пока строим в Spark, его производительности достаточно для большинства наших задач. Если же это понадобится, мы сможем использовать облачный вариант Arenadata DB Cloud на основе Greenplum. Это аналитическая база данных, в которой можно будет работать с SQL, строить ad hoc-запросы и комплексные витрины, что не очень удобно делать в Hadoop, а в ClickHouse практически невозможно.
- Apache Kafka — острой необходимости в загрузке потоковых данных в режиме real-time пока нет. Внедрение запланировано примерно через год на стороне On-premise инфраструктуры самого «Ашана», откуда данные будут поступать в облако для последующей обработки.
Также завершена настройка Kubernetes-кластера, и мы постепенно приступаем к его активному использованию.
Схема взаимодействия развернутых компонентов платформы выглядит так:
- Необработанные данные из On-premise-источников (пока только в пакетной форме) в инкрементном виде ежедневно загружаются в Hadoop — с использованием Apache Sqoop и Talend. Для загрузки выбираются только те данные, что необходимы для наших ML-решений.
- В Hadoop проводится очистка данных и дата-аудит при помощи настроенных процедур Data Quality. Они не только проверяют соответствие между источником и получателем данных, но и выполняют первичный анализ данных с точки зрения заложенной бизнес-логики.
- По итогам проверок в Hadoop:
- данные, успешно прошедшие процедуры Data Quality, загружаются в детальный слой очищенных данных Hadoop;
- данные, не прошедшие процедуры Data Quality, удаляются. Они будут загружены повторно только после устранения проблемы на источнике. Иначе алгоритмы будут формировать неверные прогнозы и рекомендации.
- Очищенные данные из Hadoop попадают в Spark. Сейчас он работает на тех же виртуальных машинах, что и Hadoop, но в будущем мы планируем перенести его на Kubernetes. С помощью Spark строятся витрины данных для аналитиков.
- При помощи внутренних ETL-процедур данные из Spark передаются в ClickHouse. Это касается наиболее часто используемых витрин, так как ClickHouse ориентирован в первую очередь на быстрый вывод горячих данных. На базе кластера ClickHouse развернута наша собственная лаборатория данных, доступ к которой предоставляется бизнес-аналитикам, которые умеют работать с SQL.
В дополнение к описанным базовым компонентам мы применяем GitLab для поддержки процессов CI/CD и Apache Airflow — оркестратор, позволяющий управлять сложными цепочками последовательных ETL-процессов.
Результаты внедрения облачной Big Data-платформы
В итоге мы получили платформу, которая полностью удовлетворяет нашим требованиям. Она дает возможность обрабатывать аналитические запросы любой сложности, формировать ad hoc-отчеты, строить любые прогнозные модели и тестировать гипотезы.
Положительные эффект от платформы очевиден уже сейчас. Вот что произошло за полгода после ее внедрения:
- Ускорился вывод AI-решений в production. 2 решения полностью введены в промышленную эксплуатацию. Первое — прогнозирование спроса, второе — анализ эластичности спроса, то есть влияния на спрос скидок, промоакций и так далее. Еще 2 новых решения находятся в разработке.
- Улучшение бизнес-показателей. Запуск решения для прогнозирования спроса позволил на 2% увеличить выручку от продаж и на 5% сократить излишние запасы товаров в магазинах. Для нашей отрасли, учитывая обороты, это отличный результат.
- Стабилизация основных бизнес-процессов за счет снятия дополнительной нагрузки с Oracle Exadata. СУБД Oracle Exadata сейчас осталась исключительно для OLTP-нагрузок: OLAP-задачи с нее полностью сняты.
- Неограниченный объем хранимых данных. Общий объем данных, загруженных в Hadoop, уже сейчас превышает 40 ТБайт. По нашим оценкам объем данных в облаке к концу 2022 г будет порядка 120 ТБайт.
- Гибкое масштабирование инфраструктуры. Облачная платформа от Mail.ru Cloud Solutions позволяет выделять нужные ресурсы для разработки и развертывания ML-моделей по запросу. Кластерные технологии и возможность параллельных вычислений обеспечивают практически безграничное масштабирование наших решений. Использование Kubernetes в будущем добавит дополнительной гибкости инфраструктуре и позволит снизить затраты на владение ею.
- Конвейер для всех уровней работы с Big Data. На единой платформе сейчас доступны лаборатория данных, разработка и развертывание ML-решений. Компоненты платформы легко добавляются и убираются подобно элементам конструктора.
- Удобный и быстрый доступ бизнес-подразделений к данным. Использование ClickHouse и построенной на его основе лаборатории данных позволяет бизнес-аналитикам строить эффективные прогнозы и принимать взвешенные решения.
- Постепенная перестройка бизнес-процессов в компании. Я уже упоминал о внедрении DevOps-культуры в нашей IT-команде. Однако постепенно начинают перестраиваться и процессы внутри бизнес-подразделений. Если раньше наши прогнозы обрабатывались аналитиками вручную, то сейчас мы активно работаем над их автоматическим учетом в ERP-процессах — на всех этапах принятия решений от планирования закупок до формирования цен. Конечно, это непростой процесс, требующий в первую очередь изменения мышления сотрудников и преодоления их недоверия к автоматизации и принятию решений без участия человека. Тем не менее он необходим.
Планы на будущее
Мы планируем и дальше расширять сотрудничество с Mail.ru Cloud Solutions и развивать Big Data-платформу в облачной инфраструктуре — добавлять в нее новые компоненты и сервисы. Условно наши стратегические планы можно разбить на четыре группы:
- Разработка и вывод в промышленную эксплуатацию новых AI-решений. Среди них: рекомендательные системы по оптимизации цен, сегментация клиентов «Ашана», сервис персональных предложений, прогнозирование поставок для службы Supply Chain, прогнозирование доступности товаров на полках (On Shelf Availability), сервисы Anti-Fraud.
- Запуск платформы для A/B-тестирования веб-сайта и мобильного приложения «Ашан». Конкретные технологии пока не выбраны, но в будущем хотелось бы иметь в облаке единое хранилище для накопления и аналитики тестовых данных.
- Развитие процессов CI/СD и DevOps-культуры в целом. Мы приступили к активному переносу микросервисов в Kubernetes-кластер и настройке автотестов. Используя связку GitLab и Kubernetes, планируем дальнейшее развитие конвейеров CI/CD для автоматического выпуска релизов.
- Дальнейшая оптимизация архитектуры Big Data-платформы:
- Перевод AI-решений, которые работают в Spark поверх Hadoop, на связку Spark+Kubernetes. Spark отлично себя чувствует на тех же ВМ, что и Hadoop. Но если несколько аналитиков одновременно строят витрины, то уже сейчас им становится тесновато в кластере. А с ростом количества ML-моделей ситуация будет ухудшаться. Автомасштабирование, доступное в Kubernetes, позволит предотвратить подобные проблемы. Кстати, вот статья о том, зачем нужно засовывать Spark в Kubernetes.
- Использование Arenadata DB Cloud для построения комплексных витрин. Пока мы экономим на MPP-системе, создавая «тяжелые» витрины в Spark и сохраняя их в ClickHouse. Текущей производительности для наших задач вполне достаточно. Но не исключаем, что в будущем развернем Greenplum-кластер. Все-таки эта система позиционируется как лучшее решение для построения витрин и ad hoc-запросов, объединяющих несколько источников данных.
- Использование Apache Kafka для загрузки потоковых данных в Hadoop в режиме реального времени. Пока что это не самая приоритетная задача, и внедрение Kafka запланировано на следующий год.
- Использование Kubernetes для построения ETL-потоков и тренировки моделей машинного обучения. Одновременное обучение десятков тысяч ML-моделей требует немалых вычислительных ресурсов. Но происходит такое обучение примерно раз в сутки. Kubernetes с помощью функции автоскейлинга позволит выделять ресурсы по мере необходимости, не переплачивая за простаивающие мощности.
Источник статьи: https://habr.com/ru/company/mailru/blog/565664/