Привет! Меня зовут Василий Копытов, я руковожу группой разработки рекомендаций в Авито. Мы занимается системами, которые предоставляют пользователю персонализированные объявления на сайте и в приложениях. На примере нашего основного сервиса покажу, когда стоит переходить с Python на Go, а когда нужно оставить всё как есть. В конце дам несколько советов по оптимизации сервисов на Python.

 Так выглядят рекомендации в приложении и на сайте
Так выглядят рекомендации в приложении и на сайте
Сервис representation выбирает самые подходящие объявления из 100 миллионов активных объявлений (айтемов) под каждого пользователя. Рекомендации формируются на основе всех действий человека за последний месяц.
Representation работает по такому алгоритму:
 Алгоритм, по которому формируется лента рекомендаций
Алгоритм, по которому формируется лента рекомендаций
 Карта взаимодействия сервисов Авито. Размер круга показывает, сколько CPU потребляет сервис
Карта взаимодействия сервисов Авито. Размер круга показывает, сколько CPU потребляет сервис
Одновременно с ростом потребления ресурсов росло и время ответа сервиса. Во время пиковых нагрузок пользователь мог ждать свои рекомендации до 1,6 секунды — это 8-ми кратный рост за последние 2 года. Все это могло заблокировать дальнейшую разработку и улучшение рекомендаций.
Причины всего этого достаточно очевидны:
В representation мы изначально использовали ProcessPoolExecutor, чтобы разделить CPU-bound и IO-bound нагрузки. Помимо основного питонячьего процесса, которые обслуживает запросы и ходит по сети (IO-bound) мы выделили три воркера для ML-модели (CPU-bound).
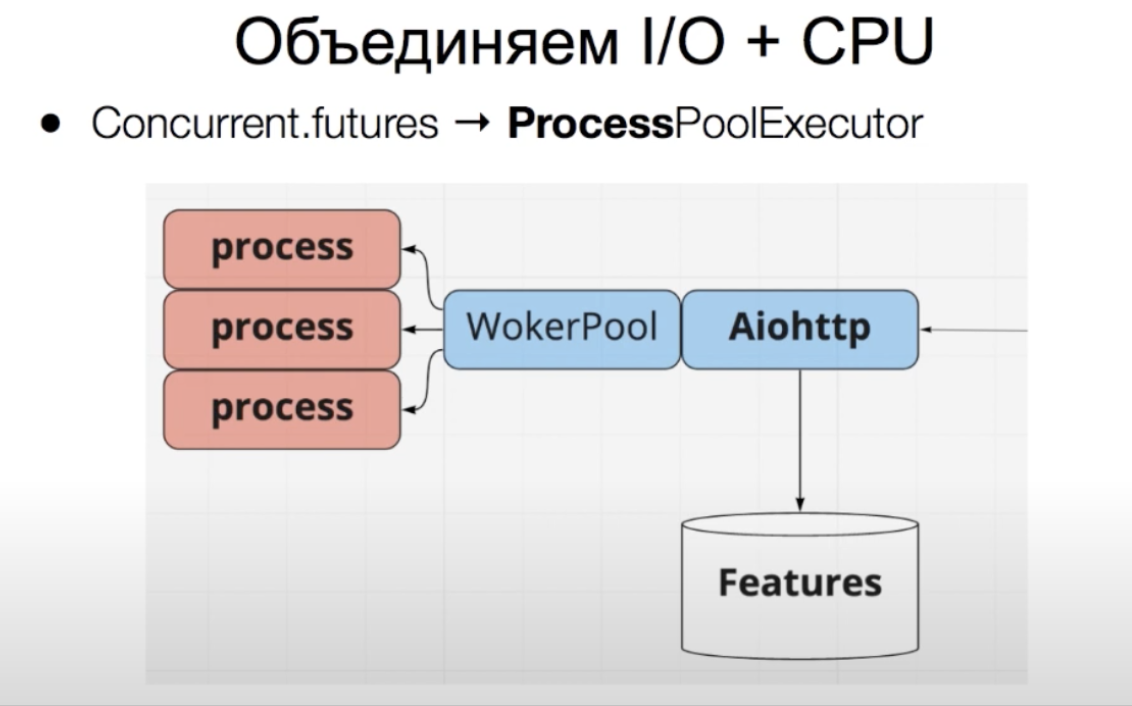
У нас есть асинхронный сервис на aiohttp, который обслуживает запросы и успешно справляется с IO-bound нагрузкой. ProcessPoolExecutor создает пул из ядер процессора — воркеров. Это отдельные процессы, которые будут выполняться на отдельном ядре. В такой воркер можно передать CPU-bound нагрузку, чтобы она не тормозила корутины в основном процессе сервиса и влияла на latency всего сервиса.
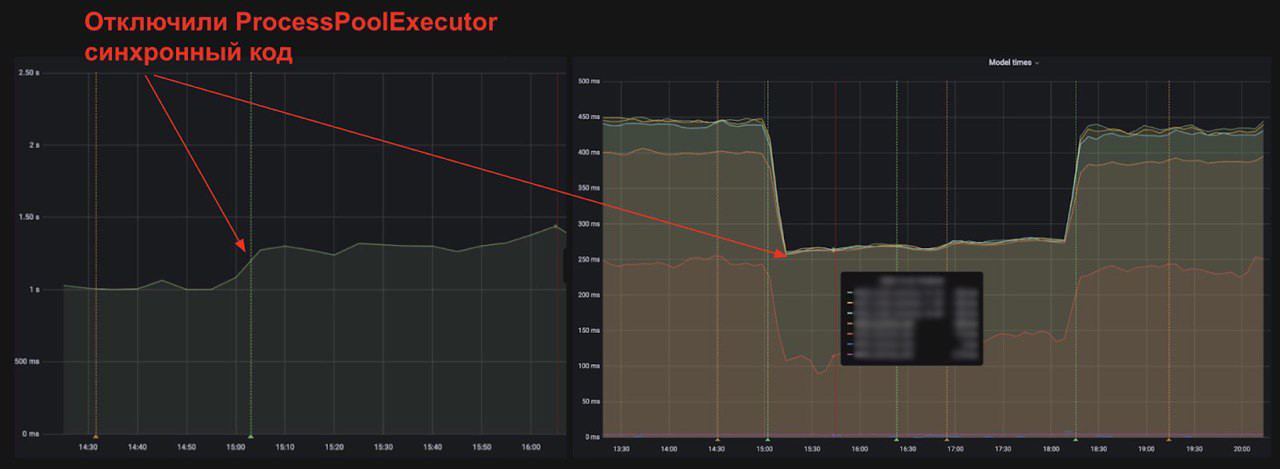
Выигрыш по времени от использования ProcessPoolExecutor около 35%. Для эксперимента мы решили сделать код синхронным и отключили ProcessPoolExecutor. То есть IO-bound и CPU-bound нагрузка стала выполняться в одном процессе.
 Без ProcessPoolExecutor время ответа сервиса выросло на 35%, тут и ниже все графики на 95 perc.
Без ProcessPoolExecutor время ответа сервиса выросло на 35%, тут и ниже все графики на 95 perc.
Как это выглядит в коде:
async def process_request(user_id):
# I/O task
async with session.post(feature_service_url,
json={'user_id': user_id}) as resp:
features = await resp.json()
return features
У нас есть асинхронный хэндлер который обрабатывает запрос. Для тех кто не знаком с async await - служебные слова, которые означают точки переключения корутин.
То есть на строчке 5 у нас корутина засыпает и отдает выполнение другой корутине в сервисе, которой уже пришли данные — тем самым мы экономим процессорное время. В питоне таком образом реализована кооперативная многозадачность.
def predict(features)
preprocessed_features = processor.preprocess(features)
return model.infer(preprocessed_features)
async def process_request(user_id):
# I/O task
async with session.post(feature_service_url,
json={'user_id': user_id}) as resp:
features = await resp.json()
# blocking CPU task
return predict(features)
Вдруг нам понадобилось выполнить cpu-bound нагрузку от ml модели. Функция predict. И вот на строчке 12 наша корутина заблокирует питонячий процесс пока не выполнится, соответственно все запросы на сервис встанут в очередь и время ответа сервиса вырастет как мы видели ранее.
executor = concurrent.futures.ProcessPoolExecutor(man_workers=N)
def predict(features):
preprocessed_features = processor.preprocess(features)
return model.infer(preprocessed_features)
async def process_request(user_id):
# I/O task
async with session.post(feature_service_url,
json={'user_id': user_id}) as resp:
features = await resp.json()
# Non blocking CPU task
return await loop.run_in_executor(executor, predict(features))
Тут появляется ProcessPoolExecutor со своим пулом воркеров, который решает эту проблему. На строке 1 мы создаем пул. На строке 15 берем оттуда воркер и перекидываем CPU-bound задачу на отдельное ядро, таким образом функция predict будет исполнятся асинхронно по отношению к родительскому процессу и не блокировать его. Самое приятное, что все это будет обернуто в обычный синтаксис async-await и CPU-bound задачи будут выполняться асинхронно наравне с IO-bound задачами, но под капотом будет дополнительная магия с процессами.
Видео, в котором подробнее рассказывается про CPU-bound задачи в Python.
ProcessPoolExecutor позволил нам уменьшить оверхед от realtime ml модели, но даже с ним в какой-то момент стало плохо. Первым делом начали с самого очевидного - профилирование и поиск узких мест.
Профайлер строит диаграмму, на которой горизонтальные полосы означают, сколько процентов процессорного времени тратит участок кода. Первое, что увидели — это 3 столбика справа. Это как раз наши дочерние процессы для скоринга фичей ml моделью.
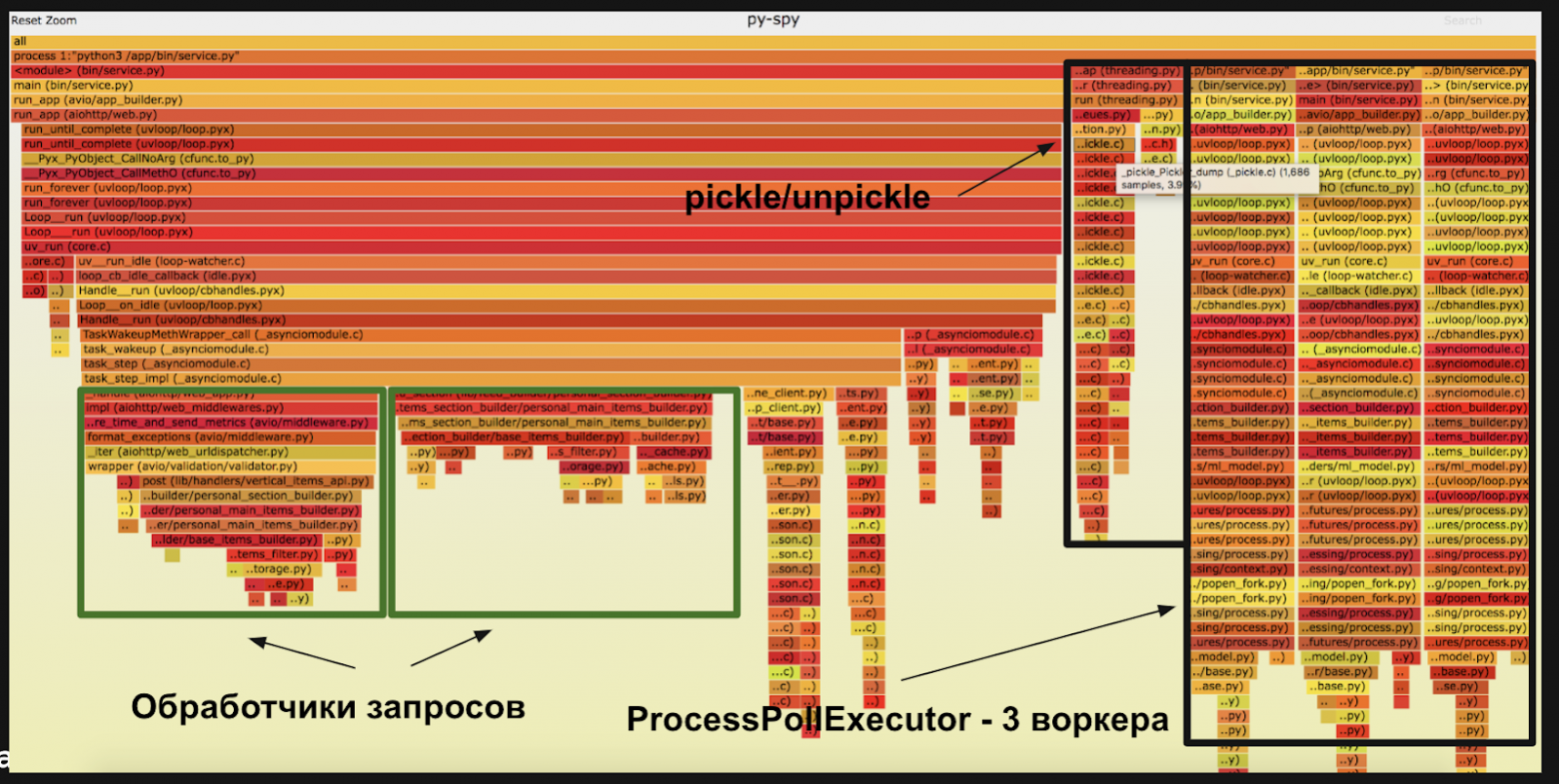
По flame графу мы увидели интересные детали:
") Без ProcessPoolExecutor ранжирование проходит быстрее, потому что всё процессорное время занимает только подготовка фичей и скоринг ML-моделью, нет оверхеда на pickle/unpickle и IO-wait (время на ожидание между переключением корутин)
Без ProcessPoolExecutor ранжирование проходит быстрее, потому что всё процессорное время занимает только подготовка фичей и скоринг ML-моделью, нет оверхеда на pickle/unpickle и IO-wait (время на ожидание между переключением корутин)
Но выросло время ответа самого сервиса по причинам описанным выше. Конкретный участок кода стал быстрее, но сам сервис медленнее.
После экспериментов выяснили:
Эксперимент показал: мы экономим время на работе модели, но получаем задержку в 270 миллисекунд при передаче данных по сети и json.loads/json.dumps. На один запрос нужно пересылать примерно 4 Мб, а для очень активных пользователей — до 12 Мб данных для ml модели. После масштабирования реплик rec-ranker стало не намного меньше, чем у старого representation, а время ответа тоже самое, был mvp не с самой удачной архитектурой для проверки гипотезы. Для нашего кейса разделение на сервисы оказалось неудачным решением, поэтому мы вернулись к предыдущей реализации representation.
По максимальным оценкам можно выиграть примерно 70 миллисекунд на сериализации и еще примерно на такое же время - 70 миллисекунд уменьшается время выполнения запроса, так как pickle/unpickle - CPU-bound нагрузка и она лочила основной python процесс, который обрабатывал запросы от пользователей, то есть всего 140 миллисекунд. Этот вывод мы сделали на основе профайла: pickle/unpickle занимает всего 7% процессорного времени, большого профита от shared memory мы не получили бы.
Фичи в сервисе рекомендация — это данные айтема. Например, название объявления, цена, информация о показах и кликах. Всего около 60 параметров, которые влияют на результат работы ML-модели, то есть мы подготавливаем все эти данные для 3000 айтемов и отправляем в модель, она отдает скор для каждого по которому мы ранжируем ленту.
Чтобы связать код на Go для подготовки фичей с остальным кодом сервиса на Python, мы использовали ctypes.
def get_predictions(
raw_data: bytes,
model_ptr: POINTER(c_void_p),
size: int,
) -> list:
raw_predictions = lib.GetPredictionsWithModel(
GoString(raw_data, len(raw_data)),
model_ptr,
)
predictions = [raw_predictions for i in range(size)]
return predictions
Так выглядит подготовка фичей внутри Python. Модуль lib это скомпилированный гошный пакет в котором есть функция GetPredictionsWithModel в которую мы передаем байты с данными об айтемах и указатель на ML модель. Все фичи подготавливаются для модели гошным кодом.
Результаты нас впечатлили:
 Подготовка фичей на Go ускорила загрузку главной страницы сайта с 1060 до 680 миллисекунд
Подготовка фичей на Go ускорила загрузку главной страницы сайта с 1060 до 680 миллисекунд
 Время на ранжирование рекомендаций ml моделью с подготовкой фичей. Тут еще нужно еще учитывать что в случае с Go у нас синхронный код и мы не используем ProcessPoolExecutor
Время на ранжирование рекомендаций ml моделью с подготовкой фичей. Тут еще нужно еще учитывать что в случае с Go у нас синхронный код и мы не используем ProcessPoolExecutor
Ниже кусочек кода в Go, подробно на этом останавливаться не буду, отмечу только, что это работает и инференс дает такие же результаты как в питоне. Можно загуглить и вы увидите в официальной документации что-то подобное. C — псевдопакет, который предоставляет Go интерфейс для взаимодействия с библиотеками на C.
if !C.CalcModelPrediction(
model.Handler,
C.size_t(nSamples),
floatsC,
C.size_t(floatFeaturesCount),
catsC,
C.size_t(categoryFeaturesCount),
(*C.double)(&results[0]),
C.size_t(nSamples),
) {
return nil, getError()
}
Есть проблема в том, что обучение ml модели по прежнему на питоне. И чтобы она обучалась и скорилась на одних и тех же фичах, важно, чтобы они не разъехались.
Подготавливать их мы стали с помощью кода Go сервиса. Обучение происходит на отдельных машинах, туда скачивается код сервиса на Go, фичи подготавливаются этим кодом, сохраняются в файл, потом Python скрипт скачивает этот файл и обучает на них модель. Как бонус обучение тоже стало в 20-30 раз быстрее.
Representation-go показал отличные результаты:

Время ответа сервисов
Разблокировали дальнейшую разработку рекомендаций - можем дальше внедрять тяжелые фичи.
Если в сервисе используются обе нагрузки, но по сети передаётся не так много данных как у нас, есть два варианта:
Запуск py-spy в не блокирующем режиме:
record -F -o record.svg -s --nonblocking -p 1
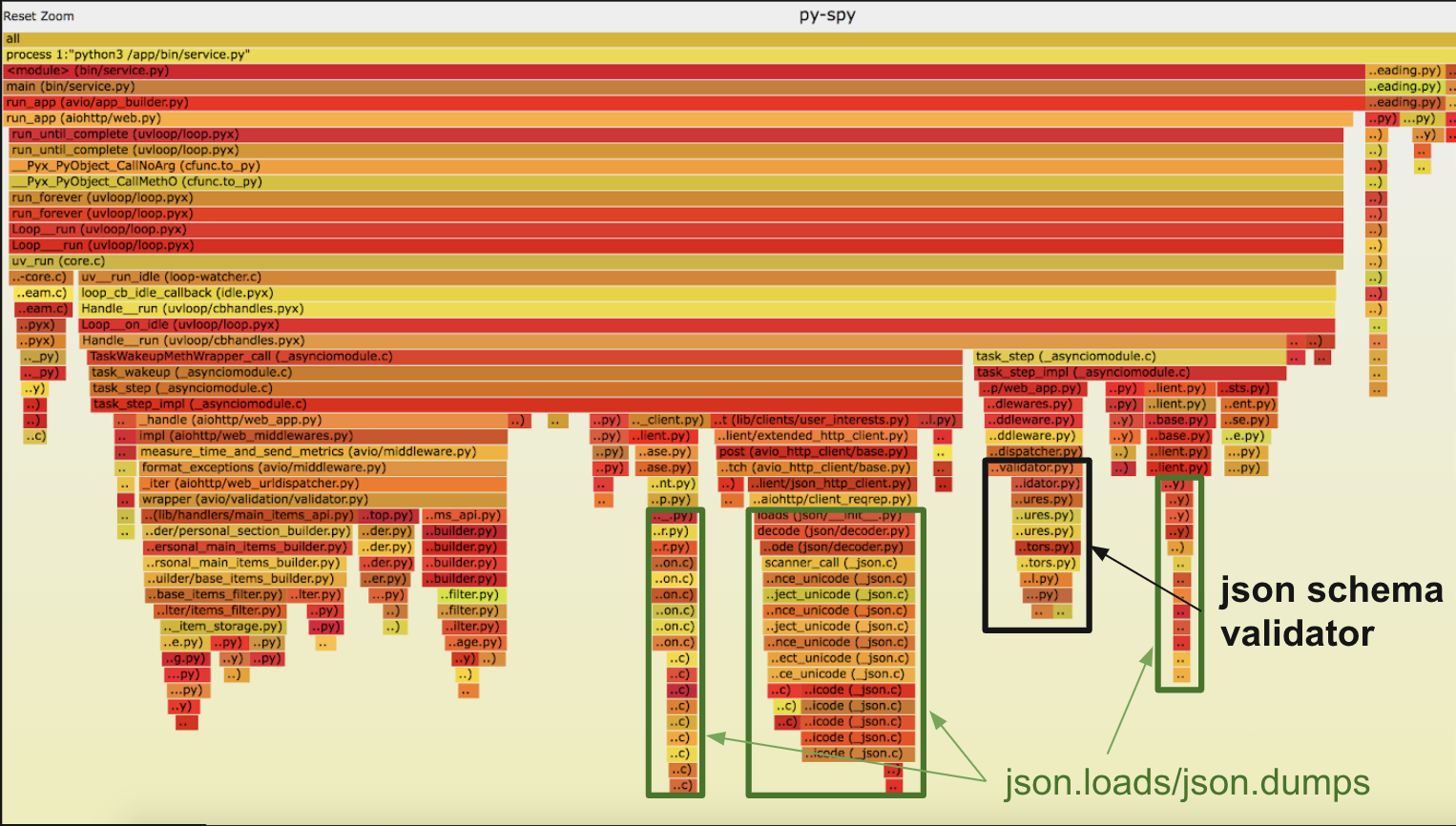
Это первый flame, который мы получили без всяких оптимизаций. Что первое тут бросилось в глаза — заметный кусок времени тратится на json валидацию запроса, которая в нашем случае не очень нужна, поэтому мы её убрали. Еще больше времени тратилось json loads/dumps всех сетевых запросов, заменили на orjson.
Ну и в завершении дам несколько советов:

 habr.com
habr.com
Как работают рекомендации на главной Авито
Любой человек, который зашёл на главную страницу сайта или приложения, видит персональную ленту объявлений — рекомендации. Нагрузка на наш основной сервис рекомендаций representation, который отвечает за формирование бесконечной ленты айтемов на главной, порядка 200 000 запросов в минуту. Весь трафик за рекомендациями — порядка 500 000 запросов в минуту.
Сервис representation выбирает самые подходящие объявления из 100 миллионов активных объявлений (айтемов) под каждого пользователя. Рекомендации формируются на основе всех действий человека за последний месяц.
Representation работает по такому алгоритму:
- Сервис обращается к хранилищу истории пользователя и забирает из него агрегированную историю и интересы.
- Затем передаёт историю и интересы, как набор параметров, нескольким ML-моделям первого уровня
- Фильтруем id на основе истории пользователя. В итоге получается примерно 3000 айтемов на один аккаунт.
- И самое интересное — representation внутри себя использует ML-модель второго уровня на основе CatBoost для ранжирования объявлений от ML-моделей первого уровня в realtime.
- Из данных готовятся фичи — параметры для ранжирования рекомендаций. Для этого по id айтема идем за данными в хранилище (1 TB шардированный Redis). Данные айтема — title, цена и много еще чего, порядка 50 полей.
- Сервис передает фичи и айтемы в ML-модель второго уровня на основе библиотеки CatBoost. На выходе получаем отранжированную ленту объявлений.
- Далее representation выполняет бизнес-логику. Например, поднимает в ленте те объявления, для которых оплачено премиум-размещение (boost VAS).
- Отдаём сформированную ленту рекомендаций пользователю, в ленте около 3000 объявлений.
Почему мы решили переписать сервис рекомендаций
Representation — один из самых высоконагруженных сервисов в Авито. Он обрабатывает 200 000 запросов в минуту. Сервис стал таким не сразу: мы постоянно внедряли что-то новое и улучшали качество рекомендаций. В какой-то момент он начал потреблять почти столько же ресурсов, сколько и остаток монолита Avito. Нам стало тяжело выкатывать сервис днём, в часы пик, из-за нехватки ресурсов в кластере — в это время большинство разработчиков деплоило свои сервисы.
Одновременно с ростом потребления ресурсов росло и время ответа сервиса. Во время пиковых нагрузок пользователь мог ждать свои рекомендации до 1,6 секунды — это 8-ми кратный рост за последние 2 года. Все это могло заблокировать дальнейшую разработку и улучшение рекомендаций.
Причины всего этого достаточно очевидны:
- Большая IO-bound нагрузка. В representation каждый запрос состоит из примерно 20 корутин — блоков кода, которые работают асинхронно во время обработки сетевых запросов.
- CPU-bound нагрузка от realtime вычислений ML-моделью, которые полностью занимает CPU, пока происходит ранжирование объявлений.
- GIL - representation изначально был написан на однопоточном Python. На этом языке невозможно совместить IO-bound и CPU-bound нагрузки так, чтобы сервис использовал ресурсы эффективно.
Как мы решали проблемы с сервисом рекомендаций
Давайте расскажу, что нам помогло жить под нашими нагрузками на Python:1. ProcessPoolExecutor
ProcessPoolExecutor создает пул из ядер процессора — воркеров. Каждый воркер представляет собой отдельный процесс, который будет выполняться на отдельном ядре. В такой воркер можно передать CPU-bound нагрузку, чтобы она не тормозила другие процессы в сервисе.В representation мы изначально использовали ProcessPoolExecutor, чтобы разделить CPU-bound и IO-bound нагрузки. Помимо основного питонячьего процесса, которые обслуживает запросы и ходит по сети (IO-bound) мы выделили три воркера для ML-модели (CPU-bound).
У нас есть асинхронный сервис на aiohttp, который обслуживает запросы и успешно справляется с IO-bound нагрузкой. ProcessPoolExecutor создает пул из ядер процессора — воркеров. Это отдельные процессы, которые будут выполняться на отдельном ядре. В такой воркер можно передать CPU-bound нагрузку, чтобы она не тормозила корутины в основном процессе сервиса и влияла на latency всего сервиса.
Выигрыш по времени от использования ProcessPoolExecutor около 35%. Для эксперимента мы решили сделать код синхронным и отключили ProcessPoolExecutor. То есть IO-bound и CPU-bound нагрузка стала выполняться в одном процессе.
Как это выглядит в коде:
async def process_request(user_id):
# I/O task
async with session.post(feature_service_url,
json={'user_id': user_id}) as resp:
features = await resp.json()
return features
У нас есть асинхронный хэндлер который обрабатывает запрос. Для тех кто не знаком с async await - служебные слова, которые означают точки переключения корутин.
То есть на строчке 5 у нас корутина засыпает и отдает выполнение другой корутине в сервисе, которой уже пришли данные — тем самым мы экономим процессорное время. В питоне таком образом реализована кооперативная многозадачность.
def predict(features)
preprocessed_features = processor.preprocess(features)
return model.infer(preprocessed_features)
async def process_request(user_id):
# I/O task
async with session.post(feature_service_url,
json={'user_id': user_id}) as resp:
features = await resp.json()
# blocking CPU task
return predict(features)
Вдруг нам понадобилось выполнить cpu-bound нагрузку от ml модели. Функция predict. И вот на строчке 12 наша корутина заблокирует питонячий процесс пока не выполнится, соответственно все запросы на сервис встанут в очередь и время ответа сервиса вырастет как мы видели ранее.
executor = concurrent.futures.ProcessPoolExecutor(man_workers=N)
def predict(features):
preprocessed_features = processor.preprocess(features)
return model.infer(preprocessed_features)
async def process_request(user_id):
# I/O task
async with session.post(feature_service_url,
json={'user_id': user_id}) as resp:
features = await resp.json()
# Non blocking CPU task
return await loop.run_in_executor(executor, predict(features))
Тут появляется ProcessPoolExecutor со своим пулом воркеров, который решает эту проблему. На строке 1 мы создаем пул. На строке 15 берем оттуда воркер и перекидываем CPU-bound задачу на отдельное ядро, таким образом функция predict будет исполнятся асинхронно по отношению к родительскому процессу и не блокировать его. Самое приятное, что все это будет обернуто в обычный синтаксис async-await и CPU-bound задачи будут выполняться асинхронно наравне с IO-bound задачами, но под капотом будет дополнительная магия с процессами.
Видео, в котором подробнее рассказывается про CPU-bound задачи в Python.
ProcessPoolExecutor позволил нам уменьшить оверхед от realtime ml модели, но даже с ним в какой-то момент стало плохо. Первым делом начали с самого очевидного - профилирование и поиск узких мест.
2. Профилирование сервиса и поиск узких мест
Даже если сервис пишут опытные программисты — в нём есть, что улучшать. Чтобы понять, какие участки кода работают медленно, а какие быстро, мы профилировали сервис с помощью профайлера py-spy.Профайлер строит диаграмму, на которой горизонтальные полосы означают, сколько процентов процессорного времени тратит участок кода. Первое, что увидели — это 3 столбика справа. Это как раз наши дочерние процессы для скоринга фичей ml моделью.
По flame графу мы увидели интересные детали:
- 7% времени процессор тратит на сериализацию данных между процессами. Сериализация — это перекодирование данных в байты. В Python этот процесс называется pickle, а обратный ему — unpickle.
- 3% времени уходит на накладные расходы ProcessPoolExecutor — подготовку пула воркеров и распределение нагрузки между ними.
- 6,7% времени занимает сериализация данных для сетевых запросов в json.loads и json.dumps.
Но выросло время ответа самого сервиса по причинам описанным выше. Конкретный участок кода стал быстрее, но сам сервис медленнее.
После экспериментов выяснили:
- Накладные расходы ProcessPoolExecutor составляют примерно 100 миллисекунд.
- IO-bound запросы от корутин ожидают 80 миллисекунд, то есть корутина уснула и EventLoop до нее добирается вновь через 80 ms, чтобы возобновить ее выполнение. В representation три больших группы IO-bound запросов — итого 240 миллисекунд уходит на IO-wait.
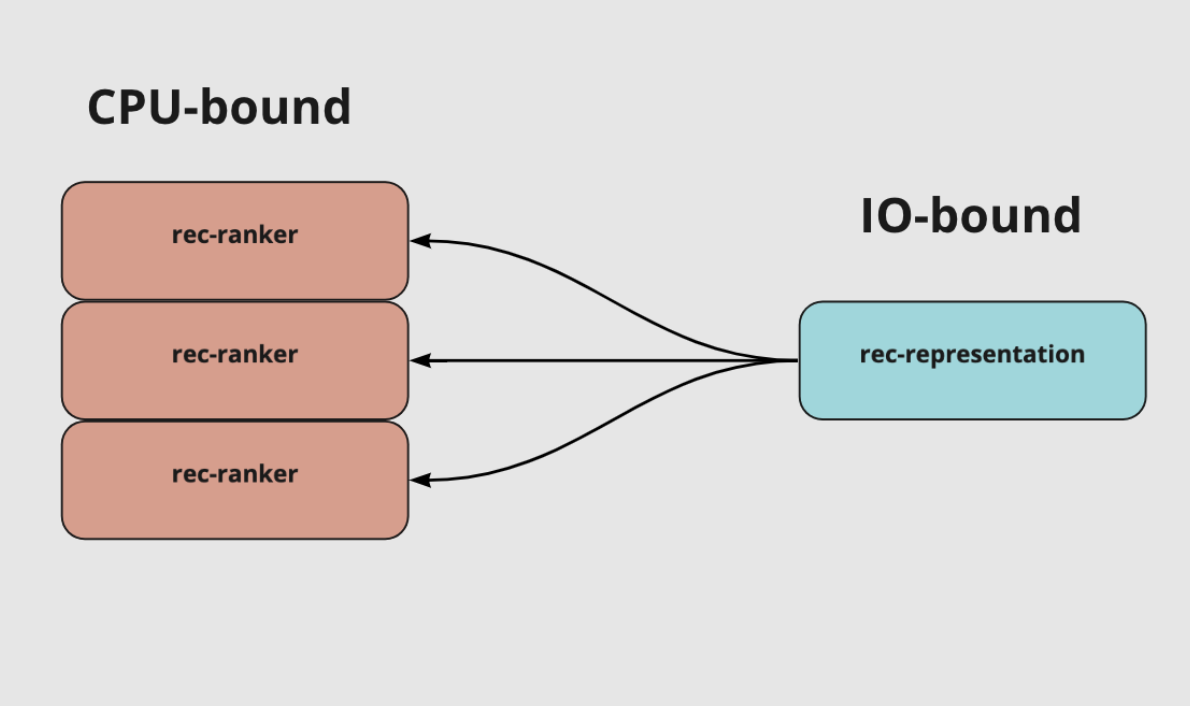
3. Разделили cpu-bound и io-bound нагрузку на 2 отдельных сервиса
Одно из крупных изменений, которое мы попробовали, — убрать ML-модель в отдельный сервис rec-ranker. То есть остался наш сервис representation в котором только сетевые запросы, а скоринг ml модели был на отдельном сервисе rec-ranker в который мы передавали все необходимые данные и возвращали скоры для ранжирования. Казалось что чуть снизим latency и будем раздельно масштабировать обе части.
Эксперимент показал: мы экономим время на работе модели, но получаем задержку в 270 миллисекунд при передаче данных по сети и json.loads/json.dumps. На один запрос нужно пересылать примерно 4 Мб, а для очень активных пользователей — до 12 Мб данных для ml модели. После масштабирования реплик rec-ranker стало не намного меньше, чем у старого representation, а время ответа тоже самое, был mvp не с самой удачной архитектурой для проверки гипотезы. Для нашего кейса разделение на сервисы оказалось неудачным решением, поэтому мы вернулись к предыдущей реализации representation.
4. Оценили Shared Memory
В сервисе representation данные между процессами передаются через pickle/unpickle. Вместо этого в процессах, которые делятся данными, можно указать на общий участок памяти. Так экономится время на сериализации.По максимальным оценкам можно выиграть примерно 70 миллисекунд на сериализации и еще примерно на такое же время - 70 миллисекунд уменьшается время выполнения запроса, так как pickle/unpickle - CPU-bound нагрузка и она лочила основной python процесс, который обрабатывал запросы от пользователей, то есть всего 140 миллисекунд. Этот вывод мы сделали на основе профайла: pickle/unpickle занимает всего 7% процессорного времени, большого профита от shared memory мы не получили бы.
5. Сделали подготовку фичей на Go
Мы решили проверить эффективность Go сначала на части сервиса. Для эксперимента выбрали самую тяжелую cpu-bound задачу в сервисе — подготовку фичей.Фичи в сервисе рекомендация — это данные айтема. Например, название объявления, цена, информация о показах и кликах. Всего около 60 параметров, которые влияют на результат работы ML-модели, то есть мы подготавливаем все эти данные для 3000 айтемов и отправляем в модель, она отдает скор для каждого по которому мы ранжируем ленту.
Чтобы связать код на Go для подготовки фичей с остальным кодом сервиса на Python, мы использовали ctypes.
def get_predictions(
raw_data: bytes,
model_ptr: POINTER(c_void_p),
size: int,
) -> list:
raw_predictions = lib.GetPredictionsWithModel(
GoString(raw_data, len(raw_data)),
model_ptr,
)
predictions = [raw_predictions for i in range(size)]
return predictions
Так выглядит подготовка фичей внутри Python. Модуль lib это скомпилированный гошный пакет в котором есть функция GetPredictionsWithModel в которую мы передаем байты с данными об айтемах и указатель на ML модель. Все фичи подготавливаются для модели гошным кодом.
Результаты нас впечатлили:
- фичи на go считаются в 20-30 раз быстрее;
- весь шаг ранжирования ускорился в 3 раза учитываю лишнюю сериализаю десиарилизацию данных в байты;
- ответ главной упал на 35 процентов.
Итоги
После всех экспериментов сделали три вывода:- Фичи на Go для 3000 айтемов на запрос считаются в 20-30 раз быстрее, экономия 30% времени.
- ProcessPoolExecutor тратит около 10% времени;
- Три группы io-bound-запросов занимают 25% времени на пустое ожидание.
- После перехода на Go сэкономим примерно 65% времени.
Переписали все на Go
В representation-go есть ML-модель. Нативно кажется что ml дружит только с питоном, но в нашем случае ml модель на CatBoost и у нее есть С API, которое можно вызывать из Go. Этим мы и воспользовались.Ниже кусочек кода в Go, подробно на этом останавливаться не буду, отмечу только, что это работает и инференс дает такие же результаты как в питоне. Можно загуглить и вы увидите в официальной документации что-то подобное. C — псевдопакет, который предоставляет Go интерфейс для взаимодействия с библиотеками на C.
if !C.CalcModelPrediction(
model.Handler,
C.size_t(nSamples),
floatsC,
C.size_t(floatFeaturesCount),
catsC,
C.size_t(categoryFeaturesCount),
(*C.double)(&results[0]),
C.size_t(nSamples),
) {
return nil, getError()
}
Есть проблема в том, что обучение ml модели по прежнему на питоне. И чтобы она обучалась и скорилась на одних и тех же фичах, важно, чтобы они не разъехались.
Подготавливать их мы стали с помощью кода Go сервиса. Обучение происходит на отдельных машинах, туда скачивается код сервиса на Go, фичи подготавливаются этим кодом, сохраняются в файл, потом Python скрипт скачивает этот файл и обучает на них модель. Как бонус обучение тоже стало в 20-30 раз быстрее.
Representation-go показал отличные результаты:
- Ответ главной страницы упал в 3 раза с 1280 до 450 миллисекунд;
- Потребление CPU упало в 5 раз;
- Потребление RAM снизилось в 21 раз.
Время ответа сервисов
Разблокировали дальнейшую разработку рекомендаций - можем дальше внедрять тяжелые фичи.
Когда стоит переписывать сервис с Python на Go
В нашем случае переход на Go дал нужный результат. На опыте сервиса рекомендаций мы вывели три условия при одновременном выполнении которых стоит переходить на Go:- в сервисе много CPU-bound-нагрузки;
- при этом также много IO-bound нагрузки;
- нужно передавать по сети большой объем данных, например для подготовки фичей.
Если в сервисе используются обе нагрузки, но по сети передаётся не так много данных как у нас, есть два варианта:
- Использовать ProcessPoolExecutor. Накладные расходы времени будут не очень большими, пока сервис не гигант.
- Как нагрузка станет большой - разбить на 2 сервиса, для раздельного масштабирования.
Оптимизации сервиса, c чего нужно начать
Профилируйте ваш сервис. Используйте py-spy, как мы, или другой профайлер Python. Скорее всего, в вашем коде нет огромных неоптимальных участков. Но нужно внимательнее посмотреть все небольшие участки, из которых собирается приличный объём для улучшения. Возможно, переписывать весь код вам не понадобится.Запуск py-spy в не блокирующем режиме:
record -F -o record.svg -s --nonblocking -p 1
Это первый flame, который мы получили без всяких оптимизаций. Что первое тут бросилось в глаза — заметный кусок времени тратится на json валидацию запроса, которая в нашем случае не очень нужна, поэтому мы её убрали. Еще больше времени тратилось json loads/dumps всех сетевых запросов, заменили на orjson.
Ну и в завершении дам несколько советов:
- Используйте request validator с умом.
- Для парсинга используйте orjson для Python или jsoniter для Golang.
- Уменьшайте нагрузку на сеть — жмите данные(zstd). Оптимизируйте хранение, чтение/запись данных в БД (Protobuf/MessagePack). Иногда быстрее сжать, отправить и разжать, чем отправлять несжатые данные.
- Смотрите на участки кода, которые выполняются дольше всего.
Как и почему перешли с Python на Go в основном сервисе рекомендаций Авито
Привет! Меня зовут Василий Копытов, я руковожу группой разработки рекомендаций в Авито. Мы занимается системами, которые предоставляют пользователю персонализированные объявления на сайте и в...
habr.com