Привет! Хочу поделиться историей миграции сервисов логирования и трейсинга с компонентов Elastic Stack на Grafana Stack и тем, что из этого вышло. До миграции у нас в М2 использовались достаточно классические схемы:
В процессе поиска лучшего решения были перепробованы разные варианты компонентов, написаны Kubernetes-операторы и собрано два ведра шишек. В конечном итоге схемы приобрели следующий вид:
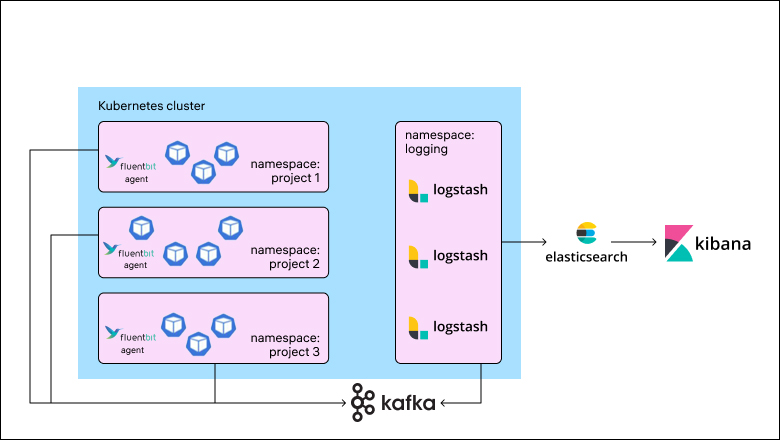
В сутки набегало порядка 1 ТБ логов. Кластер состоял примерно из 10 Elasticsearch data-нод, была приобретена лицензия X-Pack (главным образом, для доменной авторизации и алертинга). Приложения в основном были развернуты в кластере Kubernetes. Для их отправки использовался Fluent Bit, далее Kafka в качестве буфера и пул Logstash под каждый namespace. В процессе эксплуатации системы мы сталкивались с различными проблемами: некоторые решались достаточно просто, для части подходил только workaround, а какие-то решить и вовсе не удавалось. Совокупность второй и третьей групп проблем побудила нас к поиску другого решения. Прежде перечислю наиболее значимые из этих проблем.
{
"params":{
"aggType":"count",
"termSize":5,
"thresholdComparator":"<",
"timeWindowSize":15,
"timeWindowUnit":"m",
"groupBy":"all",
"threshold":[50],
"timeField" ",
",
"index":["app-common*"]
},
"consumer":"alerts",
"schedule":{
"interval":"5m"
},
"tags":[],
"name":"app-common",
"enabled":true,
"throttle":"1h",
"rule_type_id":".index-threshold",
"notify_when":"onActionGroupChange",
"actions":[
{
"group":"threshold met",
"id":"378045c0-2101-11ec-83cd-97f03e582f14",
"params":{
"level":"warning",
"message":"There is low log rate for 15 minutes in {{rule.name}}:\n\n- Value: {{context.value}}\n- Conditions Met: {{context.conditions}} over {{params.timeWindowSize}}{{params.timeWindowUnit}}\n- Timestamp: {{context.date}}"
}
}
]
}
Общим неудобством было также использование разных веб-интерфейсов под различные аспекты мониторинга:
С таких предпосылок начался наш поиск новых решений для логирования и трейсинга. Не то чтобы мы проводили какой-то сравнительный анализ различных систем. Сейчас на рынке из серьезных продуктов представлены в основном те, что требуют лицензирования, и с этим в любой момент могла возникнуть проблема. Поэтому мы решили взять opensource-проект Grafana Loki, который уже был успешно внедрен в ряде компаний, а затем очередь дошла и до Tempo.
В случае проблем с записью стоит обратить внимание на параметры:
limits_config.ingestrion_burst _size_mb
limits_config.rate_mb
Они отвечают за пропускную способность, и при приближении трафика к пороговым значениям сообщения будут отбиваться.
Для увеличения скорости поиска стоит использовать кэширование в Memcached или Redis. Также можно поиграть с параметрами:
limits.config.split_queries_by_interal
frontend_worker.parallelisim
В Loki может использоваться кэширование четырех типов данных:
После тюнинга настроек компонентов, масштабирования и включения кэша задержки записи логов исчезли, а поиск стал отрабатывать за приемлемое время (в пределах 10 секунд).
Что касается правил алертинга, пишутся они аналогично правилам Prometheus.
- alert: low_log_rate_common
expr: sum(count_over_time({namespace="common"}[15m])) < 50
for: 5m
labels:
severity: warning
annotations:
summary: Count is less than 50 from {{ $labels.namespace }}. Current VALUE = {{ $value }}
Для доступа к сообщениям используется язык запросов LogQL, который схож по синтаксису с PromQL. В части визуализации все выглядит примерно как в Kibana.
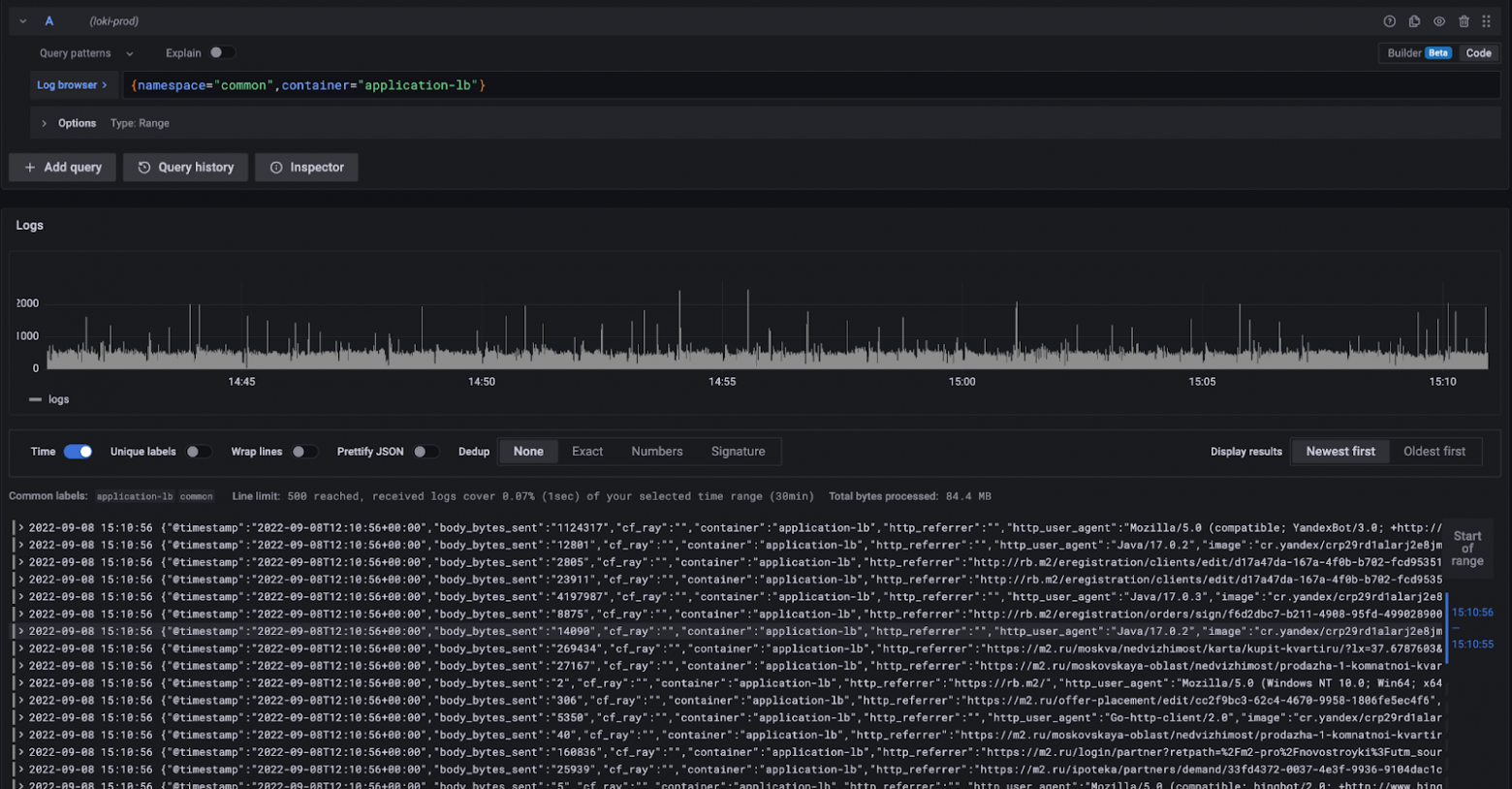
Очень удобной фичей является возможность настроить ссылки из лог-сообщений к соответствующим трейсам. В этом случае при нажатии на ссылку в правой половине рабочей области открывается трейс.
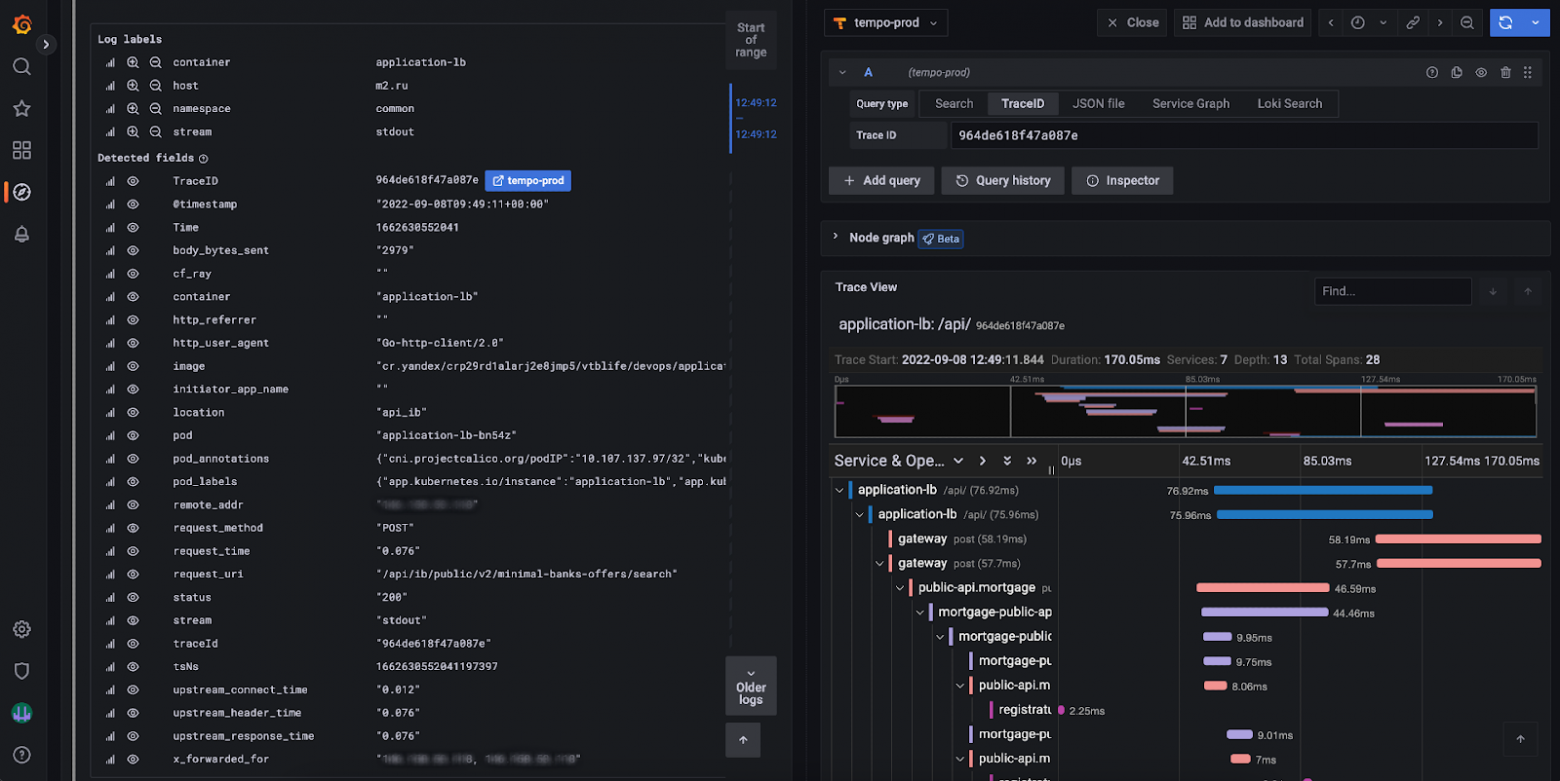
Дистрибьюторы имеют возможность подключаться к Kafka напрямую, но в таком виде не удалось добиться скорости вычитывания, соразмерной скорости записи. С использованием Grafana agent удалось эту проблему решить.
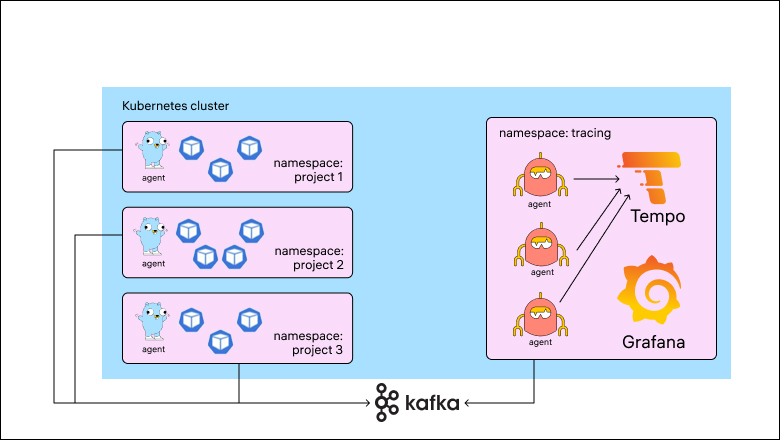
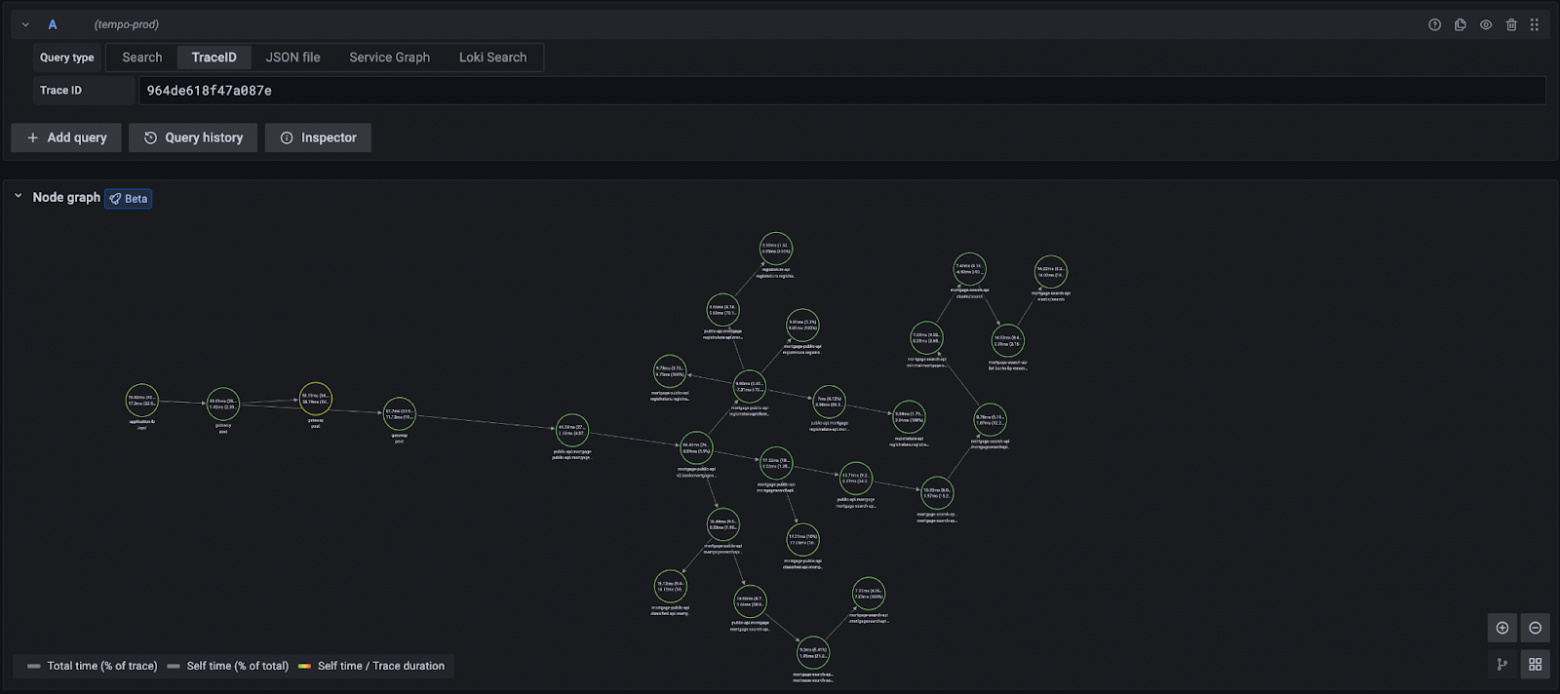
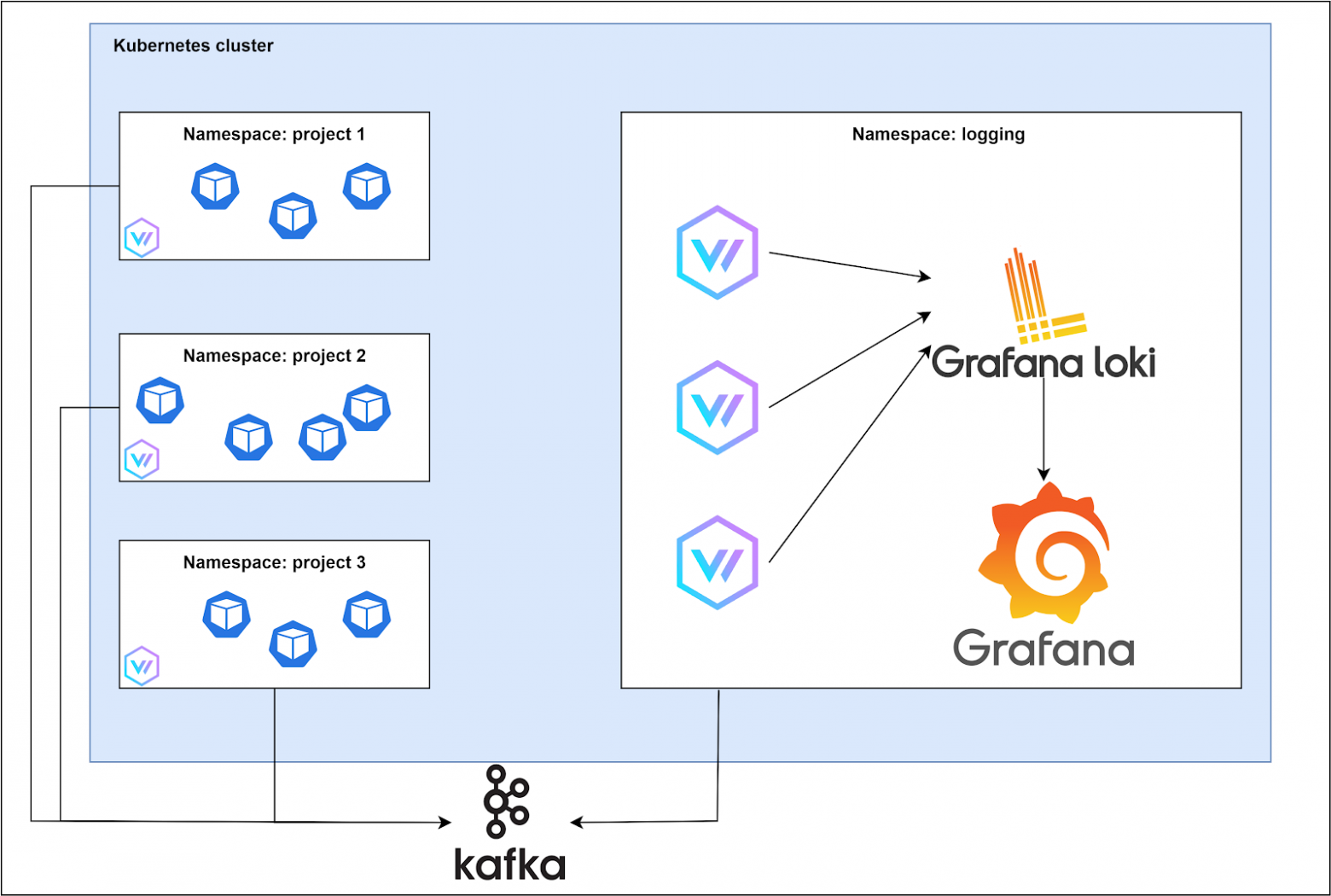
В итоге получилось:

 habr.com
habr.com
- Logstash → Elasticsearch → Kibana для логов;
- Jaeger → Elasticsearch → Kibana (Jaeger UI) для трейсов.
В процессе поиска лучшего решения были перепробованы разные варианты компонентов, написаны Kubernetes-операторы и собрано два ведра шишек. В конечном итоге схемы приобрели следующий вид:
- Vector → Loki → Grafana;
- Jaeger → Tempo → Grafana.
- сокращение объема дискового пространства при тех же объемах данных;
- сокращение объема вычислительных ресурсов для работы системы;
- отсутствие необходимости покупки лицензии;
- свободный доступ к продукту;
- достаточно простая настройка механизма автомасштабирования системы.
Предпосылки миграции. Logging
Шел 2021 год, и, как упоминалось выше, мы использовали достаточно стандартную схему централизованного логирования.
В сутки набегало порядка 1 ТБ логов. Кластер состоял примерно из 10 Elasticsearch data-нод, была приобретена лицензия X-Pack (главным образом, для доменной авторизации и алертинга). Приложения в основном были развернуты в кластере Kubernetes. Для их отправки использовался Fluent Bit, далее Kafka в качестве буфера и пул Logstash под каждый namespace. В процессе эксплуатации системы мы сталкивались с различными проблемами: некоторые решались достаточно просто, для части подходил только workaround, а какие-то решить и вовсе не удавалось. Совокупность второй и третьей групп проблем побудила нас к поиску другого решения. Прежде перечислю наиболее значимые из этих проблем.
1. Потери логов при сборе
Как ни странно, первым компонентом, с которым начались проблемы, стал Fluent Bit. Время от времени он просто переставал отправлять логи отдельных подов. Анализ дебаг-логов, тюнинг буферов и обновление версии к желаемому эффекту не приводили. В качестве замены был взят Vector, который, как позже выяснилось, тоже имел подобные проблемы. Но это было исправлено в версии 0.21.0.2. Костыли с DLQ
Следующей неприятностью стало вынужденное использование костылей при включении DLQ на Logstash. Дело в том, что Logstash не умеет сам ротировать логи, попадающие в эту очередь, и в качестве почти официального workaround предлагалось просто рестартовать инстанс после достижения порогового объема. Негативно на работу системы в целом это не влияло, так как в качестве input использовалась Kafka и сервис завершался в graceful-режиме. Но видеть постоянно растущее число рестартов подов было так себе, да и за рестартами иногда маскировались другие проблемы.3. Боли с написанием алертов
Не слишком удобное описание правил алертинга. Можно, конечно, накликать через веб-интерфейс Kibana, но удобней все же через описание через код, как, например, в Prometheus. Синтаксис достаточно неочевидный и вырвиглазный, вот пример:{
"params":{
"aggType":"count",
"termSize":5,
"thresholdComparator":"<",
"timeWindowSize":15,
"timeWindowUnit":"m",
"groupBy":"all",
"threshold":[50],
"timeField"
","index":["app-common*"]
},
"consumer":"alerts",
"schedule":{
"interval":"5m"
},
"tags":[],
"name":"app-common",
"enabled":true,
"throttle":"1h",
"rule_type_id":".index-threshold",
"notify_when":"onActionGroupChange",
"actions":[
{
"group":"threshold met",
"id":"378045c0-2101-11ec-83cd-97f03e582f14",
"params":{
"level":"warning",
"message":"There is low log rate for 15 minutes in {{rule.name}}:\n\n- Value: {{context.value}}\n- Conditions Met: {{context.conditions}} over {{params.timeWindowSize}}{{params.timeWindowUnit}}\n- Timestamp: {{context.date}}"
}
}
]
}
4. Потребление ресурсов
Но основные проблемы были связаны с увеличением стоимости потребляемых ресурсов и, как следствие, стоимости системы. Когда цена перевалила за полмиллиона в месяц, мы стали все чаще задумываться над поиском альтернатив. Самыми прожорливыми компонентами оказались Logstash и Elasticsearch, ведь JVM, как известно, неравнодушна к количеству памяти.5. Доступность продукта
Последней каплей стало ограничение доступа к продуктам Elastic и будущая невозможность покупки лицензии. Конечно, есть различные зеркала, но сколько они будут доступны и как часто там будут появлятся новые версии, неизвестно. Можно придумать и схему закупки лицензий через какой-нибудь параллельный импорт, но цена возрастет.Tracing
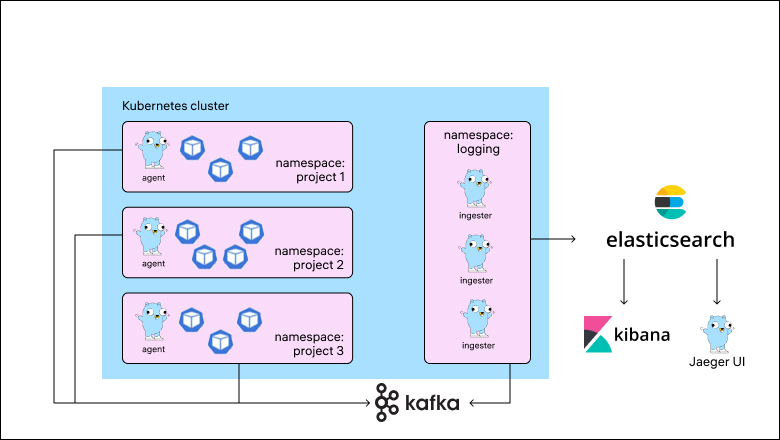
Для централизованного сбора трейсов использовался Jaeger, который через Kafka отправлял данные в отдельный кластер «Эластика». Трейсов меньше не становилось, и приходилось масштабировать систему под сотни гигабайт трейсов ежедневно. Схема выглядела следующим образом:
Общим неудобством было также использование разных веб-интерфейсов под различные аспекты мониторинга:
- Grafana — для метрик;
- Kibana — для логов;
- Jaeger UI — для трейсов.
С таких предпосылок начался наш поиск новых решений для логирования и трейсинга. Не то чтобы мы проводили какой-то сравнительный анализ различных систем. Сейчас на рынке из серьезных продуктов представлены в основном те, что требуют лицензирования, и с этим в любой момент могла возникнуть проблема. Поэтому мы решили взять opensource-проект Grafana Loki, который уже был успешно внедрен в ряде компаний, а затем очередь дошла и до Tempo.
Миграция в Loki
Итак, почему был выбран именно Loki:- это opensource-продукт, позволяющий реализовать все необходимые нам фичи;
- компоненты Loki потребляют ощутимо меньше ресурсов при тех же нагрузках;
- все компоненты могут быть запущены в кластере Kubernetes, можно использовать HPA или Keda для их автоматического масштабирования;
- данные занимают в несколько раз меньше места, так как хранятся в сжатом виде;
- построение запросов очень схоже с языком PromQL;
- описание алертов аналогично алертам в Prometheus;
- ну и конечно, система отлично интегрирована с Grafana для визуализации сообщений и построения графиков.
Тюнинг настроек
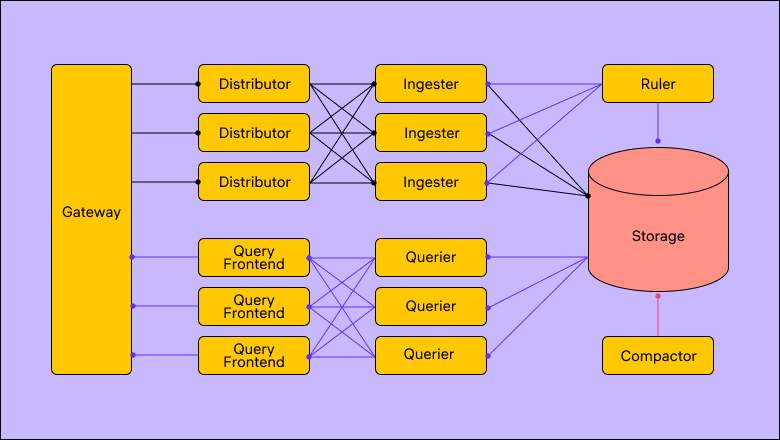
С увеличением нагрузки начинает страдать цепочка записи. То ingester, то distributor начинают дропать логи, возвращать таймауты и т. д. А при запросах данных, отсутствующих в кэше ingester-ов, ожидание ответа начинает приближаться к минуте или вовсе падать по таймауту. На всякий случай приведу схему того, как выглядит инсталляция Loki через Distributed chart.
В случае проблем с записью стоит обратить внимание на параметры:
limits_config.ingestrion_burst _size_mb
limits_config.rate_mb
Они отвечают за пропускную способность, и при приближении трафика к пороговым значениям сообщения будут отбиваться.
Для увеличения скорости поиска стоит использовать кэширование в Memcached или Redis. Также можно поиграть с параметрами:
limits.config.split_queries_by_interal
frontend_worker.parallelisim
В Loki может использоваться кэширование четырех типов данных:
- чанки;
- индексы;
- ответы на предыдущие запросы;
- кэширование данных для нужд дедупликации.
После тюнинга настроек компонентов, масштабирования и включения кэша задержки записи логов исчезли, а поиск стал отрабатывать за приемлемое время (в пределах 10 секунд).
Что касается правил алертинга, пишутся они аналогично правилам Prometheus.
- alert: low_log_rate_common
expr: sum(count_over_time({namespace="common"}[15m])) < 50
for: 5m
labels:
severity: warning
annotations:
summary: Count is less than 50 from {{ $labels.namespace }}. Current VALUE = {{ $value }}
Для доступа к сообщениям используется язык запросов LogQL, который схож по синтаксису с PromQL. В части визуализации все выглядит примерно как в Kibana.
Очень удобной фичей является возможность настроить ссылки из лог-сообщений к соответствующим трейсам. В этом случае при нажатии на ссылку в правой половине рабочей области открывается трейс.
Миграция в Tempo
Tempo — более молодой продукт (появился в 2020-м), имеющий очень схожую с Loki архитектуру (в целом, как и Mimir). В качестве способа развертывания был выбран Distributed helm-chart.Дистрибьюторы имеют возможность подключаться к Kafka напрямую, но в таком виде не удалось добиться скорости вычитывания, соразмерной скорости записи. С использованием Grafana agent удалось эту проблему решить.
Тюнинг настроек
В процессе конфигурирования следует уделить внимание следующим моментам:- Если используется Jaeger, то спаны от Grafana agent в Distributor будут отправляться по GRPC. В кластере Kubernetes равномерное распределение по дистрибьюторам потребует настройки балансировщика, например Envoy (как вариант, через Istio).
- В случае проблем со скоростью записи стоит увеличить параметры:
- overrides.ingestion_burst_size_bytes
- overrides.ingestion_rate_limit_bytes
- overrides.max_bytes_per_trace
- Также можно увеличить таймаут ожидания ответа от ingester — ingester_client.remote_timeout. Они не всегда успевают ответить за 5 секунд.
Заключение
От первичной инсталляции Loki в dev-среде до внедрения на production прошло около двух месяцев. Еще столько же потребовалось для Tempo.В итоге получилось:
- уменьшить стоимость систем примерно примерно в 7 раз;
- уйти от возможных проблем с лицензией;
- совместить визуализацию метрик, логов и трейсов в единой системе;
- организовать алертинг аналогичным Prometheus образом;
- настроить автомасштабирование системы в зависимости от объема поступающих данных.
- скорости отдачи логов, аналогичной Elastic, если данные не находятся в кэше. Частично это решается добавлением наиболее часто используемых полей в индекс;
- получения агрегированных значений за большой промежуток времени (больше суток), например, подсчет числа лог-сообщений функцией count_over_time;
- производительности в сохранении спанов как в схеме с Elasticsearch. Пока удалось решить горизонтальным масштабированием и увеличением числа партиций в Kafka.
Как мы перешли с Elastic на Grafana stack и сократили расходы в несколько раз
Привет! Хочу поделиться историей миграции сервисов логирования и трейсинга с компонентов Elastic Stack на Grafana Stack и тем, что из этого вышло. До миграции у нас в М2 использовались достаточно...
habr.com