Меня зовут Александр Крот, я владелец продукта в центре аналитики СИБУР Диджитал. Сегодня я расскажу о проекте, связанном с цифровизацией процесса ценообразования, – прогнозировании ценовых котировок.
Если кратко, мы создали более 60 моделей, которые прогнозируют цены на наши продукты на разных рынках. Раньше маркетологи собирали эту информацию вручную, эти 60-70 прогнозов занимали у нас несколько дней. На результат влиял человеческий фактор – возникали неточности, прогнозы приходили не вовремя. Сейчас модели пересчитывают котировки автоматически. Польза от инструмента стала особенно очевидной в прошлом году, когда началась пандемия и связанные с ней карантинные ограничения: вставали и снова запускали целые предприятия, закрывались и открывались границы, цены на продукцию под влиянием большого количества внешних менялись круглосуточно, а нам надо было точно и, главное, быстро управлять материальными потоками.
Как прогнозирование цен позволяет компании получать дополнительные сотни миллионов рублей; как просчитать влияние множества событий на эти цены; почему даже при хорошем ML-фреймворке без человека всё равно никак. Все подробности – в посте.
Важный момент — процессы ценообразования оказывают существенное влияние на маржинальный доход. Это влияние не всегда просто оценить из-за постоянного вмешательства внешних факторов и усилий коммерческого блока, не связанных напрямую с инструментами ценообразования. Из бенчмарков и простых прикидок можно сделать вывод, что это сотни миллионов рублей.
Первым инструментом продвинутой аналитики стал проект динамического прогнозирования котировок для маркетинга и продаж. Эффект рассчитывался через повышение качества распределения материальных потоков — чем более точные прогнозы мы даем на вход, тем более качественные потоки получаем.
Давайте по порядку.
Чтобы спрогнозировать котировки, нужно учитывать следующие факторы из внешних источников:
Весь этот массив данных перерабатывается и мониторится в режиме онлайн. Прогноз на основе этих данных строится уже условно-онлайн — какие-то данные меняются в реальном времени, другие обновляются раз в неделю.
С помощью методов машинного обучения строятся прогнозные алгоритмы, включающие механизмы самообучения моделей. То есть со временем влияние одних факторов увеличивается, других уменьшается, меняются коэффициенты влияния, и модели самопереобучаются. Кроме этого предусмотрены механизмы обучения с учителем. Ведь какой бы хорошей ни была модель, если происходит что-то, принципиально новое на рынке, ей необходима помощь человека. Она просто не разберётся. Именно поэтому изначально мы разрабатывали дизайн этого решения как комбинацию работы человека и системы.
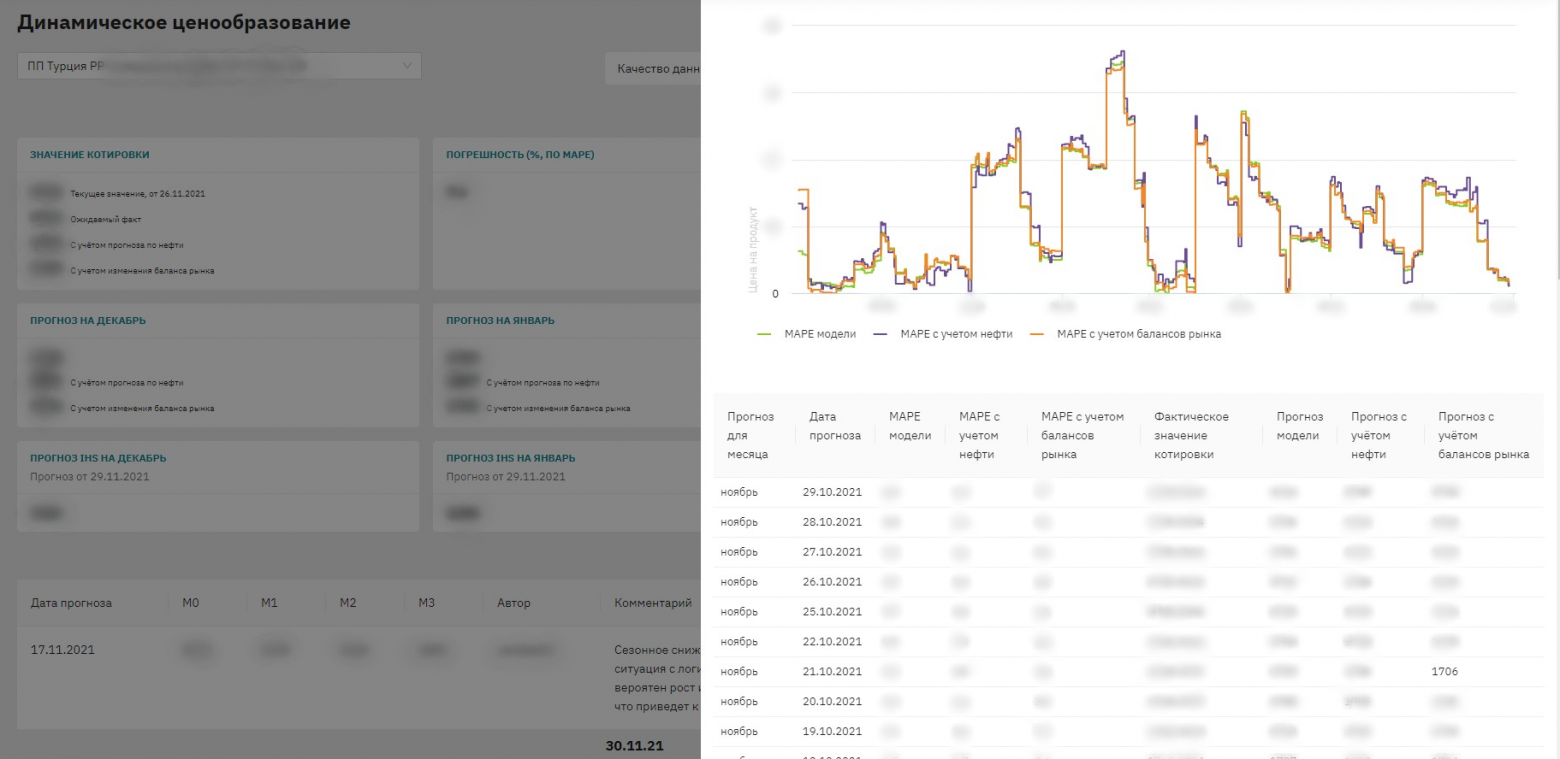
 Вот так выглядит интерфейс системы
Вот так выглядит интерфейс системы
Если эксперт — бизнес-аналитик или маркетолог — видит какие-то существенные изменения на рынке, он вносит их в виде дополнительного фактора в интерфейс. Этот фактор попадает в заявку к разработчику на дообучение модели. Разработчик пробует этот фактор, смотрит, насколько он системно повышает точность модели. И если повышает, то фактор входит в систему, в новую модель.
Что еще помимо формальных метрик дает нам этот инструмент? Он позволяет действительно быстро и в любой момент времени получать обновленный прогноз, исходя из того, что происходит во внешней среде. Да, он нуждается в валидации экспертом, но при этом у нас всегда есть некая опорная точка, с которой можно уже начинать работать.
Также в рамках интерфейса этой системы собраны основные информационные данные, которые помогают эксперту принимать решения, даже если они напрямую не учитываются в модели. В первую очередь это новости, связанные с продуктами и рынками. Одни новости мы умеем оцифровывать, другие выводятся информационной подсказкой, просто чтобы человек о них знал. Некоторые подсвечиваются дополнительно яркой цветовой легендой, чтобы эксперт точно обратил на них свое внимание.
Помимо новостей выводятся прогнозы других агентств. С их помощью можно сопоставить наши прогнозы с другими вариантами взгляда на мир. И здесь же есть механизмы анализа тех прогнозов, которые мы строим: разные точности на ретроспективном периоде, волатильности и тд
В сухом остатке это не просто модели. Это платформа, работа со сквозным построением прогнозов.
Весь набор факторов и данных, на основе которых строится прогноз, собирается в озере данных, где обеспечивается некая ролевая модель доступа к этим данным по требованиям информационной безопасности, и одновременно с этим используются API. В автоматическом режиме, фактически ежедневно, мы получаем большое количество данных, на основе которых строятся все наши будущие прогнозы, исходя из которых мы принимаем решения.
С этим озером данных интегрирован Machine Learning Framework. В рамках этого фреймворка, когда аналитик построил корреляции, обучил алгоритмы машинного обучения, используя современные методы нейронных систем и ансамблевых моделей, он загружает модель на эту платформу. Платформа, интегрированная с озером данных, позволяет разработчикам моделей оперативно использовать данные озера и иметь к ним доступ в соответствии с ролевой моделью.
Сервисы на основе этих моделей крутятся на платформе ML-фреймворка и ежедневно подсасывают свежие данные из озера. Затем делают необходимые расчеты и запускают прогноз, который потом заботливо складывают во внутреннее хранилище ML-фреймворка.
Дальше — интерфейс, который позволяет нам взять из этой платформы ML-фреймворк и все наши рассчитанные прогнозы, а потом наглядно их отобразить. На интерфейсе видны все рассчитанные прогнозные величины. Коллеги используют их при составлении плана производства и реализации, готовят прогноз котировок. Здесь же дополнительно подсвечивается большое количество факторов, которые не всегда напрямую заходят в модель, но тем не менее могут так или иначе влиять на цены.
Это и есть те самые неоцифрованные комментарии, о которых выше — различные новости, на которые стоит обратить внимание. Тут как раз были использованы технологии работы с естественным языком NLP (natural languages processing), которые позволяют проанализировать большой поток новостей, комментариев и событий и выделить из них только те, которые релевантны данному продукту, данному рынку. А затем подсветить их в интерфейсе нашей системы, чтобы пользователю не приходилось листать всю новостную ленту — вместо этого сразу показываем ему те новости и те комментарии, которые наиболее релевантны данному продукту, рынку и текущей рыночной ситуации.
Конечно же, можно при желании выгрузить прогнозы из этой системы, или интегрировать её с прочими инфосистемами для дальнейшего анализа или передачи в оптимизатор управления цепочками поставок.
Инструмент стал особенно полезным в прошлом году в период пандемии, когда процесс планирования управления цепями поставок превратился в еженедельный, а иногда – ежедневый. Было важно учесть каждое изменение – снижение цен на УВС в Европе, рост спроса цен на полимеры в Китае – и очень оперативно принимать решения. Каждый год динамическое ценообразование может приносить нам эффект в 540+ млн рублей.

 habr.com
habr.com
Если кратко, мы создали более 60 моделей, которые прогнозируют цены на наши продукты на разных рынках. Раньше маркетологи собирали эту информацию вручную, эти 60-70 прогнозов занимали у нас несколько дней. На результат влиял человеческий фактор – возникали неточности, прогнозы приходили не вовремя. Сейчас модели пересчитывают котировки автоматически. Польза от инструмента стала особенно очевидной в прошлом году, когда началась пандемия и связанные с ней карантинные ограничения: вставали и снова запускали целые предприятия, закрывались и открывались границы, цены на продукцию под влиянием большого количества внешних менялись круглосуточно, а нам надо было точно и, главное, быстро управлять материальными потоками.
Как прогнозирование цен позволяет компании получать дополнительные сотни миллионов рублей; как просчитать влияние множества событий на эти цены; почему даже при хорошем ML-фреймворке без человека всё равно никак. Все подробности – в посте.
Важный момент — процессы ценообразования оказывают существенное влияние на маржинальный доход. Это влияние не всегда просто оценить из-за постоянного вмешательства внешних факторов и усилий коммерческого блока, не связанных напрямую с инструментами ценообразования. Из бенчмарков и простых прикидок можно сделать вывод, что это сотни миллионов рублей.
Первым инструментом продвинутой аналитики стал проект динамического прогнозирования котировок для маркетинга и продаж. Эффект рассчитывался через повышение качества распределения материальных потоков — чем более точные прогнозы мы даем на вход, тем более качественные потоки получаем.
Давайте по порядку.
Динамическое прогнозирование котировок н/х продуктов на мировых рынках на основе ML
Как минимум раз в месяц в СИБУРе формируется ППР — план производства и реализации. Он строится на основе множества входных данных: прогнозов, предпосылок, ограничений и других. Но самые важные данные — это данные по прогнозным ценам на рынках, где мы уже что-то продаем или потенциально можем продавать. Цены формируются на основе прогнозов котировок на мировых рынках, а затем корректируются с учетом премий и скидок, определяемых маркетологами, исходя из нашего конкурентного положения, планов продаж и т.д.Чтобы спрогнозировать котировки, нужно учитывать следующие факторы из внешних источников:
- ряды данных на продукт,
- на сырье для него и связанные с ним продукты,
- субституты,
- показатели балансов рынка.
Весь этот массив данных перерабатывается и мониторится в режиме онлайн. Прогноз на основе этих данных строится уже условно-онлайн — какие-то данные меняются в реальном времени, другие обновляются раз в неделю.
С помощью методов машинного обучения строятся прогнозные алгоритмы, включающие механизмы самообучения моделей. То есть со временем влияние одних факторов увеличивается, других уменьшается, меняются коэффициенты влияния, и модели самопереобучаются. Кроме этого предусмотрены механизмы обучения с учителем. Ведь какой бы хорошей ни была модель, если происходит что-то, принципиально новое на рынке, ей необходима помощь человека. Она просто не разберётся. Именно поэтому изначально мы разрабатывали дизайн этого решения как комбинацию работы человека и системы.
Если эксперт — бизнес-аналитик или маркетолог — видит какие-то существенные изменения на рынке, он вносит их в виде дополнительного фактора в интерфейс. Этот фактор попадает в заявку к разработчику на дообучение модели. Разработчик пробует этот фактор, смотрит, насколько он системно повышает точность модели. И если повышает, то фактор входит в систему, в новую модель.
Что еще помимо формальных метрик дает нам этот инструмент? Он позволяет действительно быстро и в любой момент времени получать обновленный прогноз, исходя из того, что происходит во внешней среде. Да, он нуждается в валидации экспертом, но при этом у нас всегда есть некая опорная точка, с которой можно уже начинать работать.
Также в рамках интерфейса этой системы собраны основные информационные данные, которые помогают эксперту принимать решения, даже если они напрямую не учитываются в модели. В первую очередь это новости, связанные с продуктами и рынками. Одни новости мы умеем оцифровывать, другие выводятся информационной подсказкой, просто чтобы человек о них знал. Некоторые подсвечиваются дополнительно яркой цветовой легендой, чтобы эксперт точно обратил на них свое внимание.
Помимо новостей выводятся прогнозы других агентств. С их помощью можно сопоставить наши прогнозы с другими вариантами взгляда на мир. И здесь же есть механизмы анализа тех прогнозов, которые мы строим: разные точности на ретроспективном периоде, волатильности и тд
В сухом остатке это не просто модели. Это платформа, работа со сквозным построением прогнозов.
Техническая реализация
А теперь давайте уже о том, как всё работает.Весь набор факторов и данных, на основе которых строится прогноз, собирается в озере данных, где обеспечивается некая ролевая модель доступа к этим данным по требованиям информационной безопасности, и одновременно с этим используются API. В автоматическом режиме, фактически ежедневно, мы получаем большое количество данных, на основе которых строятся все наши будущие прогнозы, исходя из которых мы принимаем решения.
С этим озером данных интегрирован Machine Learning Framework. В рамках этого фреймворка, когда аналитик построил корреляции, обучил алгоритмы машинного обучения, используя современные методы нейронных систем и ансамблевых моделей, он загружает модель на эту платформу. Платформа, интегрированная с озером данных, позволяет разработчикам моделей оперативно использовать данные озера и иметь к ним доступ в соответствии с ролевой моделью.
Сервисы на основе этих моделей крутятся на платформе ML-фреймворка и ежедневно подсасывают свежие данные из озера. Затем делают необходимые расчеты и запускают прогноз, который потом заботливо складывают во внутреннее хранилище ML-фреймворка.
Дальше — интерфейс, который позволяет нам взять из этой платформы ML-фреймворк и все наши рассчитанные прогнозы, а потом наглядно их отобразить. На интерфейсе видны все рассчитанные прогнозные величины. Коллеги используют их при составлении плана производства и реализации, готовят прогноз котировок. Здесь же дополнительно подсвечивается большое количество факторов, которые не всегда напрямую заходят в модель, но тем не менее могут так или иначе влиять на цены.
Это и есть те самые неоцифрованные комментарии, о которых выше — различные новости, на которые стоит обратить внимание. Тут как раз были использованы технологии работы с естественным языком NLP (natural languages processing), которые позволяют проанализировать большой поток новостей, комментариев и событий и выделить из них только те, которые релевантны данному продукту, данному рынку. А затем подсветить их в интерфейсе нашей системы, чтобы пользователю не приходилось листать всю новостную ленту — вместо этого сразу показываем ему те новости и те комментарии, которые наиболее релевантны данному продукту, рынку и текущей рыночной ситуации.
Конечно же, можно при желании выгрузить прогнозы из этой системы, или интегрировать её с прочими инфосистемами для дальнейшего анализа или передачи в оптимизатор управления цепочками поставок.
Итоги
Проект динамического прогнозирования котировок в СИБУРе запустился в 2019 году, и на сегодняшний день он покрывает все 39 ключевых комбинаций продуктов-рынков. Им соответствуют примерно 60 цифровых моделей — на одних и тех же продуктах-рынках может быть несколько котировок.Инструмент стал особенно полезным в прошлом году в период пандемии, когда процесс планирования управления цепями поставок превратился в еженедельный, а иногда – ежедневый. Было важно учесть каждое изменение – снижение цен на УВС в Европе, рост спроса цен на полимеры в Китае – и очень оперативно принимать решения. Каждый год динамическое ценообразование может приносить нам эффект в 540+ млн рублей.
Как мы прогнозируем цены на наши продукты с помощью Machine Learning
Привет, Хабр! Меня зовут Александр Крот, я руководитель по разработке аналитических продуктов в СИБУР Диджитал. Сегодня я расскажу о проекте, связанном с цифровизацией процесса ценообразования, –...
habr.com