В этой статье я расскажу, как мы внедряли сервис Apache Airflow для использования различными командами в нашей компании, какие задачи мы хотели решить этим сервисом, опишу архитектуру деплоя и наш IaC (Infrastructure as Code).
До того как у нас в data платформе появился Airflow регламентные процессы запускались или вручную, или настраивался регулярный запуск задач через NiFi, что вызывало определенные неудобства: невозможно было отслеживать state задач, логи работы задач не были недоступны через интерфейс, да и в целом, NiFi как инструмент предназначен для задач потоковой обработки данных.
Поэтому было принято решение внедрить более специализированный инструмент от которого требовалось запускать задачи по расписанию с возможностью перезапуска, контролем статуса и уведомлением всех заинтересованных сторон. Также нужно было обеспечить разделение доступов для пользователей по выполняемым задачам, поскольку на кластере работают разные команды.
При выборе мы рассматривали Oozie и Airflow. И выбрали Apache Airflow по причине наличия у нас в команде практик по работе с этим инструментом, и как одно из самых используемых и развивающихся open source решений для оркестрации процессов работы с данными.

Сервисы Airflow развёрнуты в Docker контейнерах на VM в облаке. В качестве базы данных используется PostgreSQL и Redis как MQ (мы используем Airflow CeleryExecutor).
Логи DAGов сохраняются на S3 через настройки Airflow, логи самих сервисов (Docker контейнеров) через Fluentd пересылаются в Elasticsearch.
Пользователи обращаются через reverse proxy (Nginx) к развёрнутым инстансам Airflow Webserver.
Репозитории в общем случае имеют следующую структуру:
├── dags/
├── tests/
├── Dockerfile
├── Jenkinsfile
└── requirements.txt
Стоит заметить, что тесты запускаются на нашем базовом образе Apache Airflow, чтобы проверить логику импорта python зависимостей. Поскольку зависимости у каждого модуля свои и находятся только в образе Worker, то необходимо проверить, что Airflow сможет корректно импортировать такие DAGи на базовых образах. Для этого все импорты кастомных библиотек разработчики выполняют внутри PythonOperator.
Например:
from airflow.operators.python_operator import PythonOperator
dag = DAG(
# ...
)
def myfunc():
import hvac
# Code with hvac lib goes here...
my_task = PythonOperator(
task_id='my_task_id',
python_callable=myfunc,
dag=dag)
my_task
У deploy-репозитория есть свой pipeline, который в результате публикует в наш Docker Registry образ с необходимыми ansible конфигурациями для деплоя. На основе этого образа производится запуск docker container, из которого производится выполнения установок (как через pipeline, так и локально).
Репозиторий с Ansible конфигурацией в общем случае имеет следующую структуру:
├── group_vars
│ ├── all/
│ ├── stage/
│ ├── prod/
├── playbooks/
├── plugins/
├── roles/
│ ├── requirements.yml
├── Dockerfile
├── ansible.cfg
├── inventory.stage
└── inventory.prod
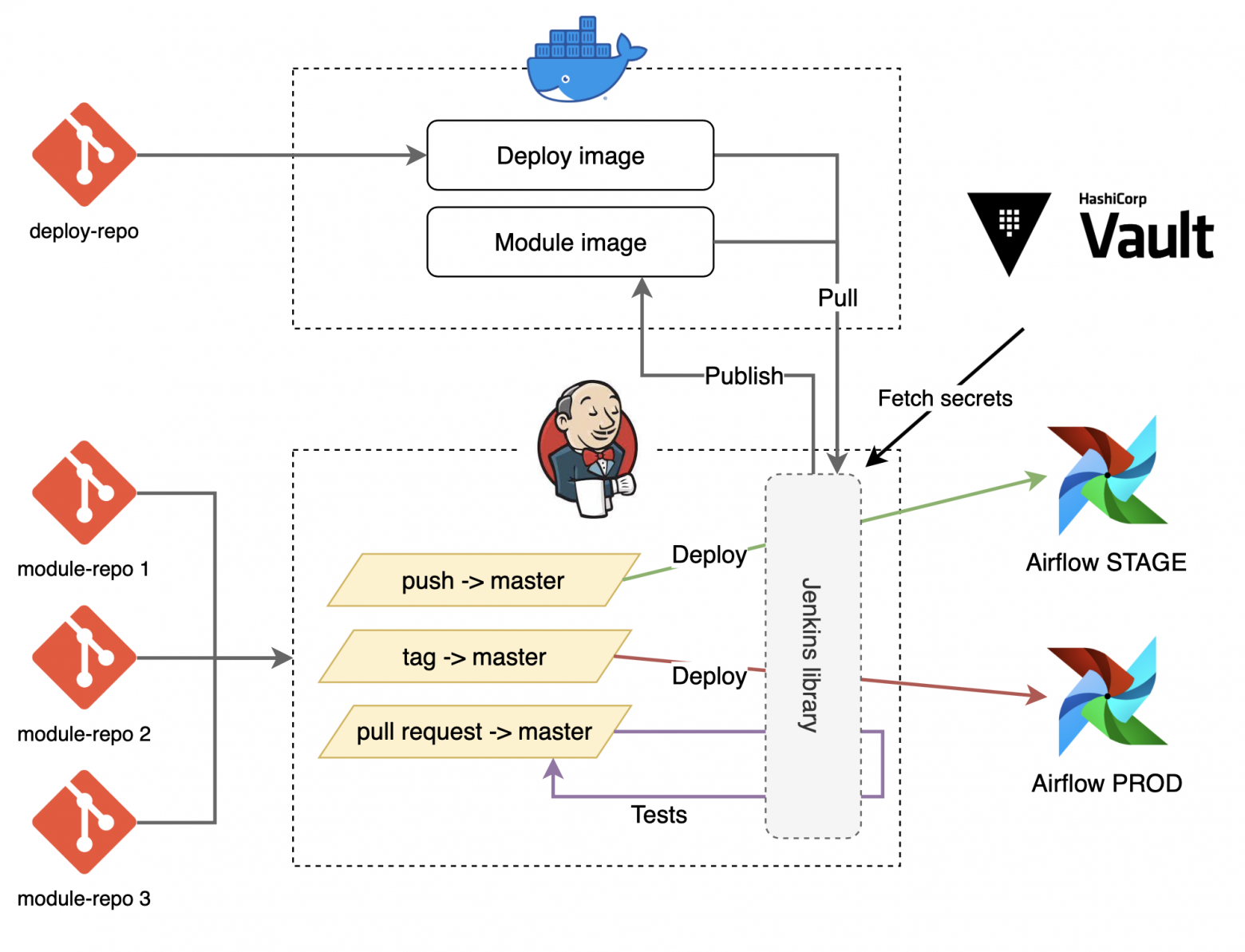
В каждом отдельном module-репозитории по различным событиям GIT запускаются соответствующие pipeline. На схеме ниже приведён самый распространённый из всех:
@Library(['dp--jenkins-pipe-libs@main']) _
AirflowPipeline()
Причём настройки уникальные для module-репозитория всегда можно передать параметром в функцию вызова pipeline. Например, в следующем Jenkinsfile указано, что DAGи нужно будет устанавливать сразу на два кластера:
@Library(['dp--jenkins-pipe-libs@main']) _
AirflowPipeline(deployClusters: ['communal', 'hi42'])
Весь код pipeline храниться и обновляется отдельно от репозиториев модулей. Это позволяет легко модифицировать deploy pipeline централизованно, без обновлений в module-репозиториях.
Для каждого модуля так же существует конфигурация, в которой мы указываем какие worker для этого модуля нужно развернуть, на каких хостах, с какими переменными или секретами внутри.
Т.к. кластер коммунальный, а в Airflow нет гибкого RBAC для разграничения доступа на создание и изменение подключений, настройки подключений производятся администраторами кластера по запросам пользователей.
Пример для конфигурации одного модуля, для которого деплоятся два Airflow Worker с разными очередями и конфигами:
raw_to_ods:
- id: raw_to_ods
# Название группы ansible куда нужно установить Worker.
hosts_group: airflow_worker_raw2ods_tpnet
# Celery очереди которые будет обслуживать Worker.
queues: "raw_to_ods__tpnet,raw_to_ods__nav"
# Hostname для красивого отображения в Airflow Flower.
hostname: "{{ inventory_hostname_short }}"
# Expose порты Worker для отображения логов online в UI Airflow.
ports: ["8793:8793"]
# Секреты и подключения для работы DAG.
env:
AIRFLOW_CONN_GP_DUMMY1_ETLBOT: "..."
- id: raw_to_ods
hosts_group: airflow_worker_default
container_name: raw_to_ods_dr
queues: "raw_to_ods__other_dr"
hostname: "{{ inventory_hostname_short }}"
env:
AIRFLOW_CONN_GP_DUMMY2_ETLBOT: "..."
Все yaml файлы находятся в репозитории GIT и пользователи кластера контрибьютят в соответствующие yaml конфигурации для изменения общих параметров кластера.
В самом Airflow присутствуют технические даги, которые синхронизируют мету, указанную пользователями, в роли, переменные и пулы Airflow.
Сам DAG не выполняет никакой работы, просто запускает dummy задачи каждые 15 минут.
Код DAGа:
import os
import time
import airflow
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
MODULE_NAME = "tech"
DAG_ID = (
MODULE_NAME
+ "__"
+ os.path.basename(__file__).replace(".pyc", "").replace(".py", "")
)
dag = DAG(
dag_id=DAG_ID,
description="Canary Ariflow dag for monitoring",
default_args={
"email_on_failure": True,
"email_on_retry": False,
"start_date": airflow.utils.dates.days_ago(1),
"queue": MODULE_NAME,
"retries": 1,
},
max_active_runs=1,
schedule_interval="*/15 * * * *",
catchup=False,
is_paused_upon_creation=True,
tags=["tech", "airflow"],
access_control={"dataplatform": {"can_dag_edit"}},
)
def sleep10():
time.sleep(10)
def sleep20():
time.sleep(20)
def sleep30():
time.sleep(30)
t1 = PythonOperator(
task_id="t1",
python_callable=sleep10,
dag=dag,
)
t2 = PythonOperator(
task_id="t2",
python_callable=sleep20,
dag=dag,
)
t3 = PythonOperator(
task_id="t3",
python_callable=sleep30,
dag=dag,
)
t1 >> t2 >> t3
Работу этого DAG’а анализирует Airflow Exporter (см. главу про мониторинг ниже) и отдаёт метрику airflow_dag_task_lag, которая показывает средний лаг между dummy-задачами. Эта метрика позволяет нам выявить проблемы взаимодействия компонент сервиса.

В используемой нами версии Airflow 1.10.14 отсутствует rest api по управлению доступом, поэтому мы написали плагин для grant и revoke Airflow ролей у пользователей через rest api и используем его для автоматизаций.
Exporter содержит общие метрики по состоянию кластера для SRE платформы. Например:
Мы считаем, что выбор и использование Apache Airflow как инструмента оправдало себя. Сервис стабилен и успешно справляется с выполняемыми задачами, и возлагаемой на него нагрузкой.
Стоит заметить, что в большинстве случаев мы используем Airflow в основном как оркестратор процессов. Основные операционные нагрузки на текущий момент находятся на стороне Greenplum и сервисах-источниках.
AIRFLOW__CORE__DAG_CONCURRENCY: "200"
AIRFLOW__CORE__PARALLELISM: "200"
AIRFLOW__SCHEDULER__PARSING_PROCESSES: "40"
AIRFLOW__SCHEDULER__JOB_HEARTBEAT_SEC: "5"
AIRFLOW__SCHEDULER__SCHEDULER_HEARTBEAT_SEC: "5"
AIRFLOW__SCHEDULER__SCHEDULER_HEALTH_CHECK_THRESHOLD: "120"
AIRFLOW__SCHEDULER__DAG_DIR_LIST_INTERVAL: "300"
AIRFLOW__SCHEDULER__PRINT_STATS_INTERVAL: "0"
AIRFLOW__SCHEDULER__SCHEDULER_ZOMBIE_TASK_THRESHOLD: "300"
# Restart scheduler every 8 hours
AIRFLOW__SCHEDULER__RUN_DURATION: "28800"
AIRFLOW__WEBSERVER__DEFAULT_DAG_RUN_DISPLAY_NUMBER: "5"
AIRFLOW__WEBSERVER__PAGE_SIZE: "25"
AIRFLOW__WEBSERVER__WEB_SERVER_WORKER_TIMEOUT: "300"
AIRFLOW__WEBSERVER__WEB_SERVER_MASTER_TIMEOUT: "300"

 habr.com
habr.com
До того как у нас в data платформе появился Airflow регламентные процессы запускались или вручную, или настраивался регулярный запуск задач через NiFi, что вызывало определенные неудобства: невозможно было отслеживать state задач, логи работы задач не были недоступны через интерфейс, да и в целом, NiFi как инструмент предназначен для задач потоковой обработки данных.
Поэтому было принято решение внедрить более специализированный инструмент от которого требовалось запускать задачи по расписанию с возможностью перезапуска, контролем статуса и уведомлением всех заинтересованных сторон. Также нужно было обеспечить разделение доступов для пользователей по выполняемым задачам, поскольку на кластере работают разные команды.
При выборе мы рассматривали Oozie и Airflow. И выбрали Apache Airflow по причине наличия у нас в команде практик по работе с этим инструментом, и как одно из самых используемых и развивающихся open source решений для оркестрации процессов работы с данными.
Структура сервиса
Ниже приведена текущая схема деплоя и связей компонентов платформенного кластера Apache Airflow:
Сервисы Airflow развёрнуты в Docker контейнерах на VM в облаке. В качестве базы данных используется PostgreSQL и Redis как MQ (мы используем Airflow CeleryExecutor).
Логи DAGов сохраняются на S3 через настройки Airflow, логи самих сервисов (Docker контейнеров) через Fluentd пересылаются в Elasticsearch.
Пользователи обращаются через reverse proxy (Nginx) к развёрнутым инстансам Airflow Webserver.
Модули
Набор DAG’ов, который относится к одной команде разработки или имеет общие библиотеки-зависимости, мы называем модулем и для каждого такого модуля разработчики создают отдельный репозиторий GIT (module-репозиторий).Репозитории в общем случае имеют следующую структуру:
├── dags/
├── tests/
├── Dockerfile
├── Jenkinsfile
└── requirements.txt
- dags/ — в этот каталог, как вы уже догадались, мы помещаем все разработанные DAGи.
- tests/ — опциональный каталог, в который разработчики могут поместить свои тесты, которые запустятся во время pipeline.
- requirements.txt — здесь разработчики указывают свои Python зависимости для установки в Docker образ.
- Dockerfile — инструкции для сборки образа. В общем случае он почти всегда один и тот-же, и наследуется с нашего базового образа Apache Airflow.
- Jenkinsfile — инструкции для самого pipeline, который у нас запускается через Jenkins.
Стоит заметить, что тесты запускаются на нашем базовом образе Apache Airflow, чтобы проверить логику импорта python зависимостей. Поскольку зависимости у каждого модуля свои и находятся только в образе Worker, то необходимо проверить, что Airflow сможет корректно импортировать такие DAGи на базовых образах. Для этого все импорты кастомных библиотек разработчики выполняют внутри PythonOperator.
Например:
from airflow.operators.python_operator import PythonOperator
dag = DAG(
# ...
)
def myfunc():
import hvac
# Code with hvac lib goes here...
my_task = PythonOperator(
task_id='my_task_id',
python_callable=myfunc,
dag=dag)
my_task
Для интересующихся, советую к прочтению статью об опыте наших data-инженеров по разработке самогенерирующихся DAGов на основе метаданных - DAG’и без напрягов: наш опыт использования метаданных при работе с Apache Airflow.
Deploy репозиторий
Доставку и настройку компонентов Airflow мы производим через Ansible, конфигурации которого хранятся в отдельном deploy-репозитории.У deploy-репозитория есть свой pipeline, который в результате публикует в наш Docker Registry образ с необходимыми ansible конфигурациями для деплоя. На основе этого образа производится запуск docker container, из которого производится выполнения установок (как через pipeline, так и локально).
Репозиторий с Ansible конфигурацией в общем случае имеет следующую структуру:
├── group_vars
│ ├── all/
│ ├── stage/
│ ├── prod/
├── playbooks/
├── plugins/
├── roles/
│ ├── requirements.yml
├── Dockerfile
├── ansible.cfg
├── inventory.stage
└── inventory.prod
- group_vars — переменные для разных окружений.
- playbooks — ansible playbooks файлы.
- roles/requirements.yml — конфиг с используемыми ansible ролями и их версиями (устанавливаем через ansible-galaxy).
- Dockerfile — инструкция для сборки образа с установленным ansible и всеми конфигурациями для него.
- аnsible.cfg — конфигурация ansible.
- inventory.* — inventory файлы ansible для разных окружений.
Modules deploy pipeline
У каждого module-репозитория есть свой pipeline, результатом которого является опубликованный (в Docker Registry) образ со всеми конфигурациями Ansible (roles, playbooks, vars, plugins и т.д.) для запуска. Этот образ используется для запуска контейнера, в котором и выполняется ansible-playbook.В каждом отдельном module-репозитории по различным событиям GIT запускаются соответствующие pipeline. На схеме ниже приведён самый распространённый из всех:
- Pull request в main/master ветки запускает только проверку сборки Docker образа и тесты.
- Push в main/master ветку запускает сборку и публикацию Docker образа (в Docker Registry) с latest версией, и следом деплой на Stage кластер Airflow.
- Установка тега запускает сборку и публикацию Docker образа и релиз модуля на Airflow Prod.
@Library(['dp--jenkins-pipe-libs@main']) _
AirflowPipeline()
Причём настройки уникальные для module-репозитория всегда можно передать параметром в функцию вызова pipeline. Например, в следующем Jenkinsfile указано, что DAGи нужно будет устанавливать сразу на два кластера:
@Library(['dp--jenkins-pipe-libs@main']) _
AirflowPipeline(deployClusters: ['communal', 'hi42'])
Весь код pipeline храниться и обновляется отдельно от репозиториев модулей. Это позволяет легко модифицировать deploy pipeline централизованно, без обновлений в module-репозиториях.
Airflow cluster configuration
Всю конфигурацию для Airflow мы передаём через environment variables для запускаемых Docker контейнеров. Конфигурация содержится в deploy-репозитории, в который обычные пользователи не контрибьютят.Для каждого модуля так же существует конфигурация, в которой мы указываем какие worker для этого модуля нужно развернуть, на каких хостах, с какими переменными или секретами внутри.
Т.к. кластер коммунальный, а в Airflow нет гибкого RBAC для разграничения доступа на создание и изменение подключений, настройки подключений производятся администраторами кластера по запросам пользователей.
Пример для конфигурации одного модуля, для которого деплоятся два Airflow Worker с разными очередями и конфигами:
raw_to_ods:
- id: raw_to_ods
# Название группы ansible куда нужно установить Worker.
hosts_group: airflow_worker_raw2ods_tpnet
# Celery очереди которые будет обслуживать Worker.
queues: "raw_to_ods__tpnet,raw_to_ods__nav"
# Hostname для красивого отображения в Airflow Flower.
hostname: "{{ inventory_hostname_short }}"
# Expose порты Worker для отображения логов online в UI Airflow.
ports: ["8793:8793"]
# Секреты и подключения для работы DAG.
env:
AIRFLOW_CONN_GP_DUMMY1_ETLBOT: "..."
- id: raw_to_ods
hosts_group: airflow_worker_default
container_name: raw_to_ods_dr
queues: "raw_to_ods__other_dr"
hostname: "{{ inventory_hostname_short }}"
env:
AIRFLOW_CONN_GP_DUMMY2_ETLBOT: "..."
Pools, variables and roles
Для предоставления пользователям возможности задавать на кластерах необходимые переменные, пулы или роли у нас используется разработанный в компании сервис metadata. Сервис представляет собой приложение, которое преобразует загруженные yaml файлы и отдаёт их в JSON формате через REST API.Все yaml файлы находятся в репозитории GIT и пользователи кластера контрибьютят в соответствующие yaml конфигурации для изменения общих параметров кластера.
В самом Airflow присутствуют технические даги, которые синхронизируют мету, указанную пользователями, в роли, переменные и пулы Airflow.
Технические DAG
Помимо дагов, которые синхронизируют некоторые параметры кластеров (см. главу Pools, variables and roles) нами написан canary DAG для мониторинга задержек между запусками task внутри DAGов.Сам DAG не выполняет никакой работы, просто запускает dummy задачи каждые 15 минут.
Код DAGа:
import os
import time
import airflow
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
MODULE_NAME = "tech"
DAG_ID = (
MODULE_NAME
+ "__"
+ os.path.basename(__file__).replace(".pyc", "").replace(".py", "")
)
dag = DAG(
dag_id=DAG_ID,
description="Canary Ariflow dag for monitoring",
default_args={
"email_on_failure": True,
"email_on_retry": False,
"start_date": airflow.utils.dates.days_ago(1),
"queue": MODULE_NAME,
"retries": 1,
},
max_active_runs=1,
schedule_interval="*/15 * * * *",
catchup=False,
is_paused_upon_creation=True,
tags=["tech", "airflow"],
access_control={"dataplatform": {"can_dag_edit"}},
)
def sleep10():
time.sleep(10)
def sleep20():
time.sleep(20)
def sleep30():
time.sleep(30)
t1 = PythonOperator(
task_id="t1",
python_callable=sleep10,
dag=dag,
)
t2 = PythonOperator(
task_id="t2",
python_callable=sleep20,
dag=dag,
)
t3 = PythonOperator(
task_id="t3",
python_callable=sleep30,
dag=dag,
)
t1 >> t2 >> t3
Работу этого DAG’а анализирует Airflow Exporter (см. главу про мониторинг ниже) и отдаёт метрику airflow_dag_task_lag, которая показывает средний лаг между dummy-задачами. Эта метрика позволяет нам выявить проблемы взаимодействия компонент сервиса.
Плагины
Мы собрали базовый Docker образ на основе официально образа от Apache Airflow (c этого образа наследуют все module-репозитории). В этот образ, в том числе, входят несколько написанных нами плагинов.Modules view plugin
Чтобы пользователи могли увидеть, какая версия их DAG’ов установлена на кластер, мы разработали плагин, который отображает модули и установленные версию на кластер.
RBAC API plugin
В нашей команде есть сервис по централизованному управлению доступами к сервисам платформы и нам требовалось выдавать доступы на кластера Airflow через API.В используемой нами версии Airflow 1.10.14 отсутствует rest api по управлению доступом, поэтому мы написали плагин для grant и revoke Airflow ролей у пользователей через rest api и используем его для автоматизаций.
Мониторинг
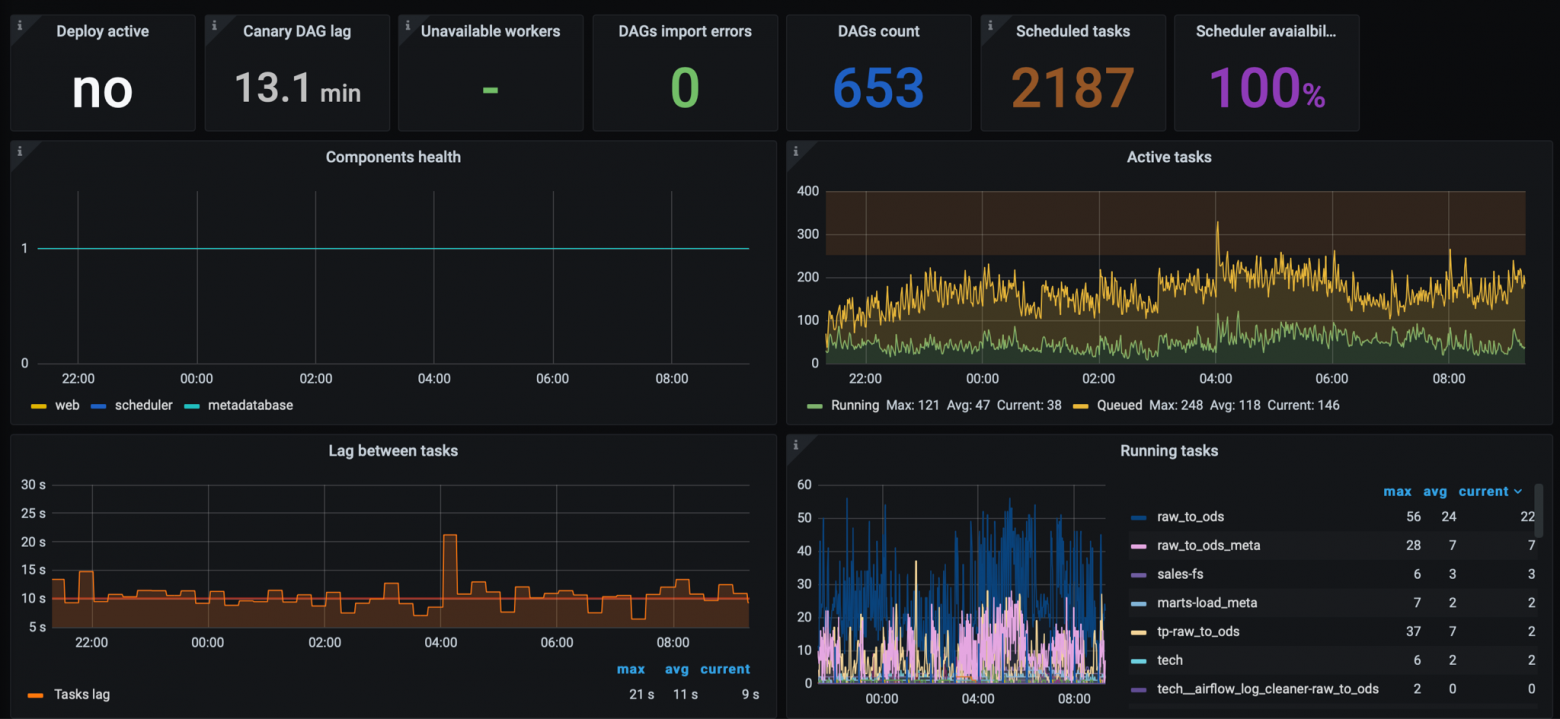
В команде используется Prometheus, как хранилище метрик и для мониторинга кластеров мы разработали свой собственный Prometheus Exporter с нужными нам метриками.Exporter содержит общие метрики по состоянию кластера для SRE платформы. Например:
- Состояние компонент кластера (webserver/scheduler/metadatabase);
- Состояние запущенных Celery Worker (через Flower API);
- Кол-во запущенных задач на кластере;
- Лаг между задачами внутри DAG (см. Главу Технические DAG);
- Размеры и использование Airflow Pool;
- Кол-во XCOM;
- Кол-во ошибок импорта DAGов;
- и т.п.
Заключение
На текущий момент по описанным выше методам и конфигурациям у нас установлены и успешно используются и сопровождаются три кластера: коммунальные кластера (stage и prod окружения) и кластер для отдельного проекта.Мы считаем, что выбор и использование Apache Airflow как инструмента оправдало себя. Сервис стабилен и успешно справляется с выполняемыми задачами, и возлагаемой на него нагрузкой.
Стоит заметить, что в большинстве случаев мы используем Airflow в основном как оркестратор процессов. Основные операционные нагрузки на текущий момент находятся на стороне Greenplum и сервисах-источниках.
Но так же на Airflow выполняются и задачи, несущие ресурсную нагрузку типа MLOps, которые выполняются на отдельных Airflow Worker.Узнать больше о нашем хранилище и в целом об архитектуре платформы можно здесь
Немного статистики:Подробнее про то как наши data scientist’ы строят свои data-pipeline можно посмотреть здесь.
- На прод окружении коммунального кластера создано ~ 700 DAGов;
- В среднем ~100 одновременно работающих DAG (~70 одновременно запущенных DAG task, ~65000 DAG tasks за день;
- В базе хранится ~300K XCOM;
- Порядка 100 пользователей в Airflow Webserver;
- VM (Airflow Scheduler) - 8 vCPU 8 GB RAM;
- VM (Airflow Webserver) - 4 vCPU 6 GB RAM;
- Postgres 12 - 8 vCPU, 32 GB RAM (на этом кластере живут два прод кластера Airflow; Сама БД Airflow текущим размером в 45 GB);
- Redis 5 - 2 vCPU, 8 GB RAM;
AIRFLOW__CORE__DAG_CONCURRENCY: "200"
AIRFLOW__CORE__PARALLELISM: "200"
AIRFLOW__SCHEDULER__PARSING_PROCESSES: "40"
AIRFLOW__SCHEDULER__JOB_HEARTBEAT_SEC: "5"
AIRFLOW__SCHEDULER__SCHEDULER_HEARTBEAT_SEC: "5"
AIRFLOW__SCHEDULER__SCHEDULER_HEALTH_CHECK_THRESHOLD: "120"
AIRFLOW__SCHEDULER__DAG_DIR_LIST_INTERVAL: "300"
AIRFLOW__SCHEDULER__PRINT_STATS_INTERVAL: "0"
AIRFLOW__SCHEDULER__SCHEDULER_ZOMBIE_TASK_THRESHOLD: "300"
# Restart scheduler every 8 hours
AIRFLOW__SCHEDULER__RUN_DURATION: "28800"
AIRFLOW__WEBSERVER__DEFAULT_DAG_RUN_DISPLAY_NUMBER: "5"
AIRFLOW__WEBSERVER__PAGE_SIZE: "25"
AIRFLOW__WEBSERVER__WEB_SERVER_WORKER_TIMEOUT: "300"
AIRFLOW__WEBSERVER__WEB_SERVER_MASTER_TIMEOUT: "300"
Как мы развернули коммунальный Apache Airflow для 30+ команд и сотни разработчиков
Всем привет! В этой статье я расскажу, как мы внедряли сервис Apache Airflow для использования различными командами в нашей компании, какие задачи мы хотели решить этим сервисом, опишу архитектуру...
habr.com