Однообразный код писать неинтересно, нудно, но приходится. Испокон веков изворотливые программисты ищут Святой Грааль формализма, позволяющего переложить рутинные задачи на машину, писать только раз и переиспользовать код. Так появились структурное программирование, потом объектно-ориентированное, полиморфизм с параметризованными типами, кодогенерация на основе формальных грамматик, препроцессоры макроязыка и прочее… Под катом рассмотрим, как обстоят дела именно в Go.
В Go на сегодня generics нет (хоть третий год и обещают), а выписывать по шаблону GetMax([]MyType) для каждого MyType надоедает.
Параметрический полиморфизм можно реализовать генерацией частных форм обобщённого кода на стадии компиляции (или выполнения) и поддержкой таблиц соответствия на стадии выполнения. В Go поддерживаются таблицы методов для типов и интерфейсов и диспетчеризация этих таблиц — просто, зато эффективно реализовано.
Runtime-доступ к диспетчеру предоставлен пакетом reflect, что обеспечивает сильный, но дорогостоящий механизм интроспекции, позволяющий динамически оперировать статически заявленными типами. Вызовы reflect затратны, но, например, в C нет и этого, там на стадии выполнения данные не знают, какого они типа.
Стандартного препроцессора в Go тоже нет. Зато есть директива go:generate и есть доступ к потрохам компилятора, в частности к дереву разбора (Abstract Syntax Tree), в пакетах go/ стандартной библиотеки. Это в совокупности даёт инструментарий богаче, чем препроцессор макросов.
Идиоматическое применение интерфейсов реализовано в stdlib-пакете sort, интроспекция применяется в пакетах encoding и fmt, go:generate — в придворном пакете golang.org/x/tools/cmd/stringer.
Манипулирование AST исходного кода не очень распространено, потому что:
Go- и JS-разработчик Открытой мобильной платформы Дима Смотров рассказал, как писать кодогенераторы в Go и оптимизировать работу над микросервисами с помощью создания инструмента для генерации шаблонного кода. Статья составлена на основе выступления Димы на GopherCon Russia 2020.
Группа Дмитрия, в частности, работает над продуктом Аврора Маркет, который обеспечивает управление дистрибуцией приложений. Его бэкенд полностью написан на Go.
В Go принято отдавать предпочтение явному программированию (explicit) в противовес неявному (implicit). Это помогает новым разработчикам легче начинать работать над существующими проектами. Но по пути от неявного программирования к явному можно легко заблудиться и забрести в дебри дубляжа кода, а дубляж кода в дальнейшем превратит поддержку проекта в ад.
Чтобы этого избежать, код выносят в отдельные модули. Но как насчёт кода, который пишется специально для каждого микросервиса и не может быть вынесен в модуль? Например, код репозитория для работы с базой данных. Этот код есть в каждом микросервисе, выглядит примерно одинаково, но он разный и не дублируется. Не хочется писать шаблонный код, который потом придётся ещё и поддерживать во всех микросервисах.
И хотя в Go принято отдавать предпочтение явному программированию, разработчики предоставили инструменты для метапрограммирования, такие как кодогенерация ($go help generate) и Reflection API. Reflection API используется на этапе выполнения программы, кодогенерация — перед этапом компиляции. Reflection API увеличивает время работы программы. Пример: инструмент для кодирования и декодирования JSON из стандартной библиотеки Go использует Reflection API. Взамен ему сообществом были рождены такие альтернативы, как easyjson, который с помощью кодогенерации кодирует и декодирует JSON в 5 раз быстрее.
Так как кодогенерация — неявное программирование, она недооценивается сообществом Go, хотя и является официальным инструментом от создателей этого языка программирования. Поэтому в интернете немного информации о написании кодогенераторов на Go. Но всё же на Хабре примеры есть: 1 и 2.
При разработке микросервисов есть много похожего шаблонного кода, который нужно писать в каждом микросервисе. Например, код репозитория по работе с базой данных. Мы создали кодогенераторы для того, чтобы разработчики не тратили время на написание этого шаблонного кода и могли сфокусироваться на решении задач, относящихся к дизайну кода и предметной области бизнеса. Команда использует кодогенераторы и для сокращения времени на создание новых микросервисов. Это позволяет не ограничивать разработчика в принятии архитектурных решений, так как создание нового микросервиса не влияет на трудоёмкость выполнения задачи.
Пример дублирующего кода:
type UserRepository struct{ db *gorm.DB }
func NewRepository(db *gorm.DB) UserRepository {
return UserRepository{db: db}
}
func (r UserRepository) Get(userID uint) (*User, error) {
entity := new(User)
err := r.db.Limit(limit: 1).Where(query: "user_id = ?", userID).Find(entity).Error
return entity, err
}
func (r UserRepository) Create(entity *User) error {
return r.db.Create(entity).Error
}
func (r UserRepository) Update(entity *User) error {
return r.db.Model(entity).Update(entity).Error
}
func (r UserRepository) Delete(entity *User) error {
return r.db.Delete(entity).Error
}
В Java Spring разработчик описывает интерфейс репозитория, исходя из сигнатуры метода автоматически генерируется реализация в зависимости от того, какой бэкенд для базы данных используется: MySQL, PostgreSQL или MongoDB. Например, для метода интерфейса с сигнатурой FindTop10WhereNameStartsWith (prefix string) автоматически генерируется реализация метода репозитория, которая вернёт до 10 записей из базы данных, имя которых начинается с переданного в аргументе префикса.
Разработчик описывает интерфейс go-kit-сервиса, а кодогенератор генерирует сразу всё, что для сервиса нужно:
Позже наша команда работала над проектом, где нужно было больше заниматься адаптацией существующих Open-Source-продуктов под наши требования, чем разработкой новых микросервисов. Мы больше не могли заниматься кодогенератором, так как не использовали его активно в работе. А впоследствии мы тоже начали копировать сервисы вместе со всеми их недостатками.
Когда наша команда вернулась к разработке своего основного продукта, мы провели ретроспективу кодогенератора и поняли, в чём была основная проблема. Кодогенераторы, которые «генерируют ВСЁ», сложно внедрять и поддерживать.
И всё же для конвейерной обработки этого маловато: требует существенного вмешательства оператора.
Можно пойти по проторённому пути: gRPC, Protobuf, Swagger. Недостатки подхода:
Можно вытащить из AST параметры, вмонтировать в шаблон и всё. Недостаток — разрозненные обработки неудобно собирать в конвейер.
Поэтому выбран такой алгоритм кодогенерации:
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}
...выглядит вот так:
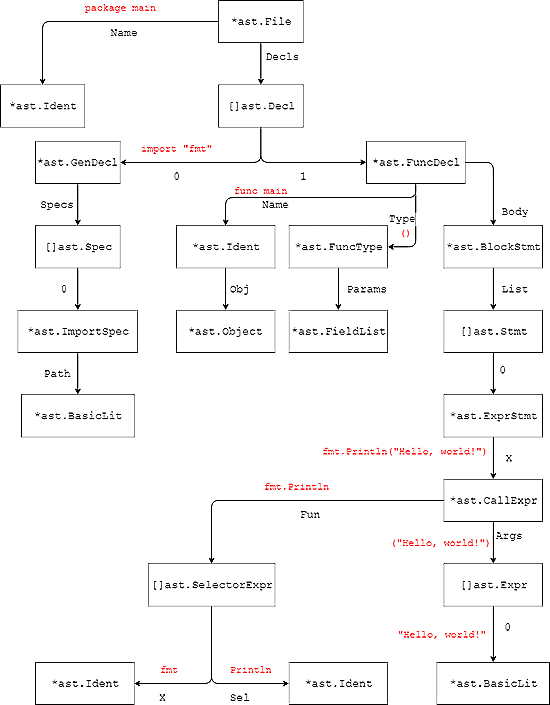
...или вот так, напечатанное специализированным принтером ast.Print():
ast.Print
//repogen:entity
type User struct {
ID uint `gorm:"primary_key"`
Email string
PasswordHash string
}
...запустить go generate и получить вот такой файл с готовой обвязкой для работы с DB, в котором прописаны методы именно для его типа данных User:
User
Напишем такой генератор прямо здесь и сейчас, не применяя готовых решений, а ограничившись стандартной библиотекой.
Кода потребовалось не очень много, поэтому он представлен одним листингом, чтобы не терялась общая картина. Пояснения даны в комментариях, в стиле literate programming.
Вот модель, для которой нам нужно сгенерировать методы работы с DB. В комментариях видны директивы:
//go:generate repogen
//repogen:entity
type User struct {
ID uint `gorm:"primary_key"`
Email string
PasswordHash string
}
Вот код, собственно, процессора repogen:
Процессор repogen
Источник статьи: https://habr.com/ru/company/omprussia/blog/558690/
В Go на сегодня generics нет (хоть третий год и обещают), а выписывать по шаблону GetMax([]MyType) для каждого MyType надоедает.
Параметрический полиморфизм можно реализовать генерацией частных форм обобщённого кода на стадии компиляции (или выполнения) и поддержкой таблиц соответствия на стадии выполнения. В Go поддерживаются таблицы методов для типов и интерфейсов и диспетчеризация этих таблиц — просто, зато эффективно реализовано.
Runtime-доступ к диспетчеру предоставлен пакетом reflect, что обеспечивает сильный, но дорогостоящий механизм интроспекции, позволяющий динамически оперировать статически заявленными типами. Вызовы reflect затратны, но, например, в C нет и этого, там на стадии выполнения данные не знают, какого они типа.
Стандартного препроцессора в Go тоже нет. Зато есть директива go:generate и есть доступ к потрохам компилятора, в частности к дереву разбора (Abstract Syntax Tree), в пакетах go/ стандартной библиотеки. Это в совокупности даёт инструментарий богаче, чем препроцессор макросов.
Идиоматическое применение интерфейсов реализовано в stdlib-пакете sort, интроспекция применяется в пакетах encoding и fmt, go:generate — в придворном пакете golang.org/x/tools/cmd/stringer.
Манипулирование AST исходного кода не очень распространено, потому что:
- кодогенерацию трудно верифицировать;
- дерево разбора кажется сложным, непонятным и пугает.
Go- и JS-разработчик Открытой мобильной платформы Дима Смотров рассказал, как писать кодогенераторы в Go и оптимизировать работу над микросервисами с помощью создания инструмента для генерации шаблонного кода. Статья составлена на основе выступления Димы на GopherCon Russia 2020.
О продуктах и компонентах на Go
Наша команда разрабатывает мобильную ОС Аврора, SDK и экосистему приложений под неё, доверенную среду исполнения Аврора ТЕЕ, систему по управлению корпоративной мобильной инфраструктурой Аврора Центр, включающую несколько «коробочных» продуктов и компонентов.Группа Дмитрия, в частности, работает над продуктом Аврора Маркет, который обеспечивает управление дистрибуцией приложений. Его бэкенд полностью написан на Go.
В Go принято отдавать предпочтение явному программированию (explicit) в противовес неявному (implicit). Это помогает новым разработчикам легче начинать работать над существующими проектами. Но по пути от неявного программирования к явному можно легко заблудиться и забрести в дебри дубляжа кода, а дубляж кода в дальнейшем превратит поддержку проекта в ад.
Чтобы этого избежать, код выносят в отдельные модули. Но как насчёт кода, который пишется специально для каждого микросервиса и не может быть вынесен в модуль? Например, код репозитория для работы с базой данных. Этот код есть в каждом микросервисе, выглядит примерно одинаково, но он разный и не дублируется. Не хочется писать шаблонный код, который потом придётся ещё и поддерживать во всех микросервисах.
Кодогенерация — официальный инструмент от авторов Go
Для решения шаблонных задач можно использовать метапрограммирование — это разработка программ, которые создают программы перед этапом компиляции или изменяют их во время выполнения. Этот метод относится к неявному программированию.И хотя в Go принято отдавать предпочтение явному программированию, разработчики предоставили инструменты для метапрограммирования, такие как кодогенерация ($go help generate) и Reflection API. Reflection API используется на этапе выполнения программы, кодогенерация — перед этапом компиляции. Reflection API увеличивает время работы программы. Пример: инструмент для кодирования и декодирования JSON из стандартной библиотеки Go использует Reflection API. Взамен ему сообществом были рождены такие альтернативы, как easyjson, который с помощью кодогенерации кодирует и декодирует JSON в 5 раз быстрее.
Так как кодогенерация — неявное программирование, она недооценивается сообществом Go, хотя и является официальным инструментом от создателей этого языка программирования. Поэтому в интернете немного информации о написании кодогенераторов на Go. Но всё же на Хабре примеры есть: 1 и 2.
При разработке микросервисов есть много похожего шаблонного кода, который нужно писать в каждом микросервисе. Например, код репозитория по работе с базой данных. Мы создали кодогенераторы для того, чтобы разработчики не тратили время на написание этого шаблонного кода и могли сфокусироваться на решении задач, относящихся к дизайну кода и предметной области бизнеса. Команда использует кодогенераторы и для сокращения времени на создание новых микросервисов. Это позволяет не ограничивать разработчика в принятии архитектурных решений, так как создание нового микросервиса не влияет на трудоёмкость выполнения задачи.
Пример дублирующего кода:
type UserRepository struct{ db *gorm.DB }
func NewRepository(db *gorm.DB) UserRepository {
return UserRepository{db: db}
}
func (r UserRepository) Get(userID uint) (*User, error) {
entity := new(User)
err := r.db.Limit(limit: 1).Where(query: "user_id = ?", userID).Find(entity).Error
return entity, err
}
func (r UserRepository) Create(entity *User) error {
return r.db.Create(entity).Error
}
func (r UserRepository) Update(entity *User) error {
return r.db.Model(entity).Update(entity).Error
}
func (r UserRepository) Delete(entity *User) error {
return r.db.Delete(entity).Error
}
Про удачные кодогенераторы
Из примеров написанных и удачно используемых в нашей команде кодогенераторов хотим подробнее рассмотреть генератор репозитория по работе с базой данных. Нам нравится переносить опыт из одного языка программирования в другой. Так, наша команда попыталась перенести идею генерации репозиториев по работе с базой данных из Java Spring (https://spring.io/).В Java Spring разработчик описывает интерфейс репозитория, исходя из сигнатуры метода автоматически генерируется реализация в зависимости от того, какой бэкенд для базы данных используется: MySQL, PostgreSQL или MongoDB. Например, для метода интерфейса с сигнатурой FindTop10WhereNameStartsWith (prefix string) автоматически генерируется реализация метода репозитория, которая вернёт до 10 записей из базы данных, имя которых начинается с переданного в аргументе префикса.
О нюансах и траблах внедрения кодогенератора
Существует парадигма Monolith First, когда пишут первую версию как монолит, а потом распиливают на микросервисы. На заре новой версии проекта, когда все команды должны были разбить монолит на микросервисы, мы решили написать свой генератор, который:- позволит вводить в систему новые микросервисы с меньшими усилиями, чем при его создании вручную (копируя предыдущий и удаляя лишнее);
- сократит время на код-ревью за счёт общего шаблона для генерируемых микросервисов;
- сократит время на будущие обновления одинакового кода микросервисов (main, инфрастуктура, etc…).
Разработчик описывает интерфейс go-kit-сервиса, а кодогенератор генерирует сразу всё, что для сервиса нужно:
- CRUD-эндпоинты и REST-, gRPC- и NATS-транспорты;
- репозиторий для работы с базой данных с возможностью расширять интерфейс репозитория;
- main для всех go-kit-сервисов.
Позже наша команда работала над проектом, где нужно было больше заниматься адаптацией существующих Open-Source-продуктов под наши требования, чем разработкой новых микросервисов. Мы больше не могли заниматься кодогенератором, так как не использовали его активно в работе. А впоследствии мы тоже начали копировать сервисы вместе со всеми их недостатками.
Когда наша команда вернулась к разработке своего основного продукта, мы провели ретроспективу кодогенератора и поняли, в чём была основная проблема. Кодогенераторы, которые «генерируют ВСЁ», сложно внедрять и поддерживать.
- Кодогенератор генерировал слишком много кода.
- Весь код нужно было ревьювить и перерабатывать.
- Только часть команд решила пользоваться кодогенератором.
- Получили сегментацию микросервисов.
Как же всё-таки генерировать Go-код
Можно просто использовать шаблоны. Можно написать шаблон и начинить его параметрами, на это вполне способны продвинутые редакторы текста. Можно использовать неинтерактивные редакторы — sed или awk, порог входа круче, зато лучше поддаётся автоматизации и встраивается в производственный конвейер. Можно использовать специфические инструменты рефакторинга Go из пакета golang.org/x/tools/cmd, а именно gorename или eg. А можно воспользоваться пакетом text/template из стандартной библиотеки — решение достаточно гибкое, человекочитаемое (в отличие от sed), удобно интегрируется в pipeline и позволяет оставаться в среде одного языка.И всё же для конвейерной обработки этого маловато: требует существенного вмешательства оператора.
Можно пойти по проторённому пути: gRPC, Protobuf, Swagger. Недостатки подхода:
- привязывает к gRPC, Protobuf;
- не заточен конкретно под Go, а, напротив, требует изучения и внедрения новых, сторонних абстракций и технологий.
- go/ast — декларирует типы дерева разбора;
- go/parser — разбирает исходный код в эти типы;
- go/printer — выливает AST в файл исходного кода;
- go/token — обеспечивает привязку дерева разбора к файлу исходного кода.
Можно вытащить из AST параметры, вмонтировать в шаблон и всё. Недостаток — разрозненные обработки неудобно собирать в конвейер.
Поэтому выбран такой алгоритм кодогенерации:
- Разбираем AST исходного файла.
- Создаём пустое AST для генерируемого файла.
- Генерируем код из шаблонов Go (template/text).
- Разбираем AST сгенерированного кода.
- Копируем узлы AST из сгенерированного кода в AST генерируемого файла.
- Печатаем и сохраняем AST генерируемого файла в файл.
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}
...выглядит вот так:
...или вот так, напечатанное специализированным принтером ast.Print():
ast.Print
Хватит трепаться, покажите код
В целом задача сводится к тому, чтобы разработчик микросервиса мог описать свои данные обычным образом в стандартном синтаксисе Go, только добавить в комментариях директивы процессинга://repogen:entity
type User struct {
ID uint `gorm:"primary_key"`
Email string
PasswordHash string
}
...запустить go generate и получить вот такой файл с готовой обвязкой для работы с DB, в котором прописаны методы именно для его типа данных User:
User
Напишем такой генератор прямо здесь и сейчас, не применяя готовых решений, а ограничившись стандартной библиотекой.
Кода потребовалось не очень много, поэтому он представлен одним листингом, чтобы не терялась общая картина. Пояснения даны в комментариях, в стиле literate programming.
Вот модель, для которой нам нужно сгенерировать методы работы с DB. В комментариях видны директивы:
- go:generate repogen — для команды go generate на запуск процессора repogen;
- repogen:entity — помечает цель для процессора repogen;
- и тег поля структуры gorm:"primary_key" для процессора gorm — помечает первичный ключ в таблице DB.
//go:generate repogen
//repogen:entity
type User struct {
ID uint `gorm:"primary_key"`
Email string
PasswordHash string
}
Вот код, собственно, процессора repogen:
Процессор repogen
Подводя итоги
Работа с деревом разбора в Go не требует сверхъестественных способностей. Язык предоставляет для этого вполне годный инструментарий. Кода получилось не слишком много, и он достаточно читаем и, надеемся, понятен. Высокой эффективности здесь добиваться нет нужды, потому что всё происходит ещё до стадии компиляции и на стадии выполнения издержек не добавляет (в отличие от reflect). Важнее валидность генерации и манипуляций с AST. Кодогенерация сэкономила нам достаточно времени и сил в написании и поддержке большого массива кода, состоящего из повторяющихся паттернов (микросервисов). В целом кодогенераторы оправдали затраты на своё изготовление. Выбранный pipeline показал себя работоспособным и прижился в производственном процессе. Из стороннего опыта можем рекомендовать к использованию:- dst (у которого лучше разрешение импортируемых пакетов и привязка комментариев к узлам AST, чем у go/ast из stdlib).
- kit (хороший toolkit для быстрой разработки в архитектуре микросервисов. Предлагает внятные, рациональные абстракции, методики и инструменты).
- jennifer (полноценный кодогенератор. Но его функциональность достигнута ценой применения промежуточных абстракций, которые хлопотно обслуживать. Генерация из шаблонов text/template на деле оказалась удобней, хоть и менее универсальной, чем манипулирование непосредственно AST с использованием промежуточных абстракций. Писать, читать и править шаблоны проще).
Источник статьи: https://habr.com/ru/company/omprussia/blog/558690/