В научной работе NVIDIA 2019 года улучшенный дифференциальный рендерер — DIB-R представлен как инструмент решения одной из самых популярных сегодня задач Deep Learning: генерации 3D-объектов из одного двухмерного изображения. Статья на ArXiv содержала исходный код, но в ней не оказалось необходимой для его выполнения ML-модели. К старту курса «Machine Learning и Deep Learning», партнёр которого — компания NVIDIA, делимся переводом о том, как запустить руководство по работе с этой программой визуализации, как она работает, как обучить ML-модель рендеринга и проверить её в действии.
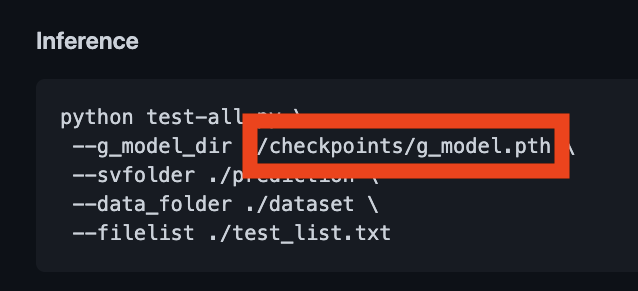
Хорошая новость заключается в том, что теперь мы можем попробовать DIB-R — Nvidia выпустила библиотеку PyTorch в составе Nvidia Kaolin, она содержит DIB-R — тот самый дифференциальный рендерер. Но лучше всего вот что: библиотека содержит демонстрирующее возможности DIB-R руководство.
Должен признаться, что не очень понял его, увидев впервые. Кроме того, я даже не был уверен, нужен ли дифференциальный рендерер как таковой; я даже перепутал дифференциальный рендерер с нейронной сетью, описанной в статье DIB-R и способной генерировать 3D-объект из одной 2D-фотографии. На самом деле это две разные вещи. Я собираюсь показать вам шаг за шагом, как попробовать DIB-R, а также поделиться с вами тем, что я узнал о DIB-R и области 3D Deep Learning.
conda activate kaolin
Для подготовки к настройке загрузим Nvidia Kaolin с Github.
git clone --recursive https://github.com/NVIDIAGameWorks/kaolin
cd kaolin
В инструкции по установке Kaolin сказано, что нужно переключить ветку git на последнюю Kaolin — это v0.9.0. К сожалению, 0.9.0 пока не содержит руководства по DIB-R, они есть только в основной ветке, поэтому настроим Kaolin напрямую из этой ветки.
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 -c pytorch
Нажмите APPS и найдите Kaolin; затем из местоположения Kaolin возможно загрузить и установить приложение Omniverse Kaolin App.
, DIB-R") Источник: Чен и др. Nvidia (2019), DIB-R
Источник: Чен и др. Nvidia (2019), DIB-R
Во второй части обсуждается, как работать с DIB-R — дифференциальным рендерером, решать сложные задачи 3D Deep Learning: обучить модель, способную спрогнозировать форму, текстуру и освещение 3D-объекта по одному изображению. Здесь модель обучалась на данных из наборов ShapeNet и CUB Bird.
, DIB-R") Сравнение результатов работы DIB-R с работой CMR — Чен и др. Nvidia (2019), DIB-R
Сравнение результатов работы DIB-R с работой CMR — Чен и др. Nvidia (2019), DIB-R
В работе GANVerse3D Nvidia поднимается на ступень выше. Вместо наборов ShapeNet и CUB они работают с наборами DatasetGAN, сгенерированными нейросетью StyleGAN-R и новым GAN.
, GanVerse3D") Источник: Чжан и др. Nvidia(2020), GanVerse3D
Источник: Чжан и др. Nvidia(2020), GanVerse3D
StyleGAN-R, он же StyleGAN Renderer, похож на обычную StyleGAN, за исключением того, что его первые четыре слоя замораживаются для получения изображений одного и того же класса объектов в разных ракурсах при известном положении камеры.
, GanVerse3D") Источник: Чжан и др. Nvidia(2020), GanVerse3D
Источник: Чжан и др. Nvidia(2020), GanVerse3D
, GanVerse3D") Источник: Чжан и др. Nvidia (2020), GanVerse3D
Источник: Чжан и др. Nvidia (2020), GanVerse3D
DatasetGAN, GAN, разработанный компанией Nvidia, затем используется для автоматического аннотирования всех сгенерированных изображений, вплоть до уровня пикселя (семантическая сегментация). Именно это позволяет Nvidia анимировать 3D-объекты, например автомобиль, после преобразования из 2D-фотографии.
, DatasetGAN") Источник: Чжан и др, Nvidia(2021), DatasetGAN
Источник: Чжан и др, Nvidia(2021), DatasetGAN
, DatasetGAN") Источник: Чжан и др., Nvidia(2021), DatasetGAN
Источник: Чжан и др., Nvidia(2021), DatasetGAN
Пиксели переднего плана
О пикселях переднего плана в статье DIB-R:
, DIB-R") Иллюстрация дифференцируемой растеризации — Чен и др. Nvidia (2019), DIB-R
Иллюстрация дифференцируемой растеризации — Чен и др. Nvidia (2019), DIB-R
Таким образом, пиксели переднего плана рассчитываются как интерполяция ближайших трёх соседних вершин с использованием веса для каждой вершины, где Ii — интенсивность пикселя.
, DIB-R") Чен и др. Nvidia (2019), DIB-R
Чен и др. Nvidia (2019), DIB-R
Фоновые пиксели
Для фоновых пикселей, то есть пикселей, которые не покрыты ни одной гранью 3D-объекта, значение рассчитывается на основе расстояния от пикселя до ближайшей грани.
Другие дифференциальные рендереры
Важно подчеркнуть, что DIB-R не является первым и единственным дифференциальным рендерером. Это улучшенный дифференциальный рендерер, основанный на идеях созданного в 2014 году OpenDR, а также SoftRas-Mesh, предлагающего аналогичный DIB-R дифференциальный рендерер.
, DIB-R") Сравнение дифференциальных рендеров — Чен и др. Nvidia (2019), DIB-R
Сравнение дифференциальных рендеров — Чен и др. Nvidia (2019), DIB-R
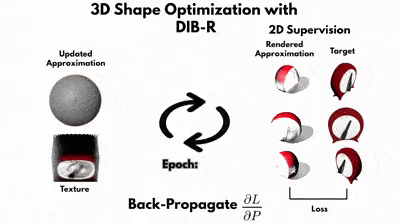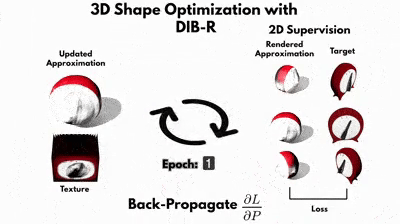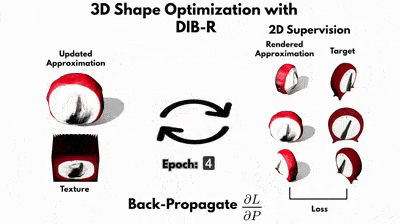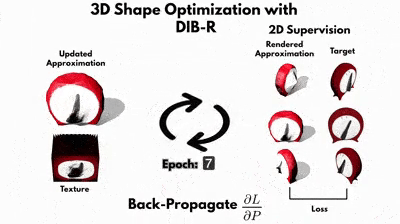
Цель руководства по DIB-R — показать, как использовать DIB-R, дифференциальный рендерер при попытке восстановить 3D-геометрию и текстуру 3D-объекта, часть набора Kitchen от Pixar. Этот набор представляет собой коллекцию 3D-объектов, которые обычно можно найти на кухне, и компания Pixar любезно открыла доступ к этому набору. Часы были выбраны потому, что это относительно простой объект без топологических отверстий.
 Пример изображения часов в сгенерированном Nvidia Kaolin наборе
Пример изображения часов в сгенерированном Nvidia Kaolin наборе
 Файлы одного ракурса
Файлы одного ракурса
Также для загрузки изображения в обучающем наборе мы используем метод kal.io.render.import_synthetic_view, кроме того, он загружает файл семантической маски для всех изображений и JSON с параметрами камеры.
num_views = len(glob.glob(os.path.join(rendered_path,'*_rgb.png')))
train_data = []
for i in range(num_views):
data = kal.io.render.import_synthetic_view(
rendered_path, i, rgb=True, semantic=True)
train_data.append(data)
dataloader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,shuffle=True, pin_memory=True)
 Фигура в Blender
Фигура в Blender
Во время обучения мы не будем менять топологию (к примеру добавлять отверстия).
image_loss * image_weight +
mask_loss * mask_weight +
laplacian_loss * laplacian_weight +
flat_loss * flat_weight
)
 Нейронный 3D-визуализатор сетки, Като и др.
Нейронный 3D-визуализатор сетки, Като и др.
 3D-реконструкция формы дельфина, с регуляризатором гладкости и без него. Слева: целевой дельфин. В центре: 3D-реконструкция с регуляризатором гладкости, справа — без него
3D-реконструкция формы дельфина, с регуляризатором гладкости и без него. Слева: целевой дельфин. В центре: 3D-реконструкция с регуляризатором гладкости, справа — без него
optim = torch.optim.Adam(params=[vertices, texture_map, vertice_shift],lr=lr)
scheduler = torch.optim.lr_scheduler.StepLR(optim, step_size=scheduler_step_size,=scheduler_gamma)
Как тренировочные параметры Adam использует вершины (vertices), texture_map и vertice_shift.
vertice_shift, по-видимому, является параметром, который используется для сдвига всех вершин сферы во время обучения.Здесь я предполагаю; мне кажется, что всякий раз, когда вы меняете форму сферы, то смещаете центр, и поэтому на всех этапах обучения вызывается метод recenter_vertices, принимающий на вход вершины и параметры vertices_shift.
def recenter_vertices(vertices, vertice_shift):
"""Recenter vertices on vertice_shift for better optimization"""
vertices_min = vertices.min(dim=1, keepdim=True)[0]
vertices_max = vertices.max(dim=1, keepdim=True)[0]
vertices_mid = (vertices_min + vertices_max) / 2
vertices = vertices - vertices_mid + vertice_shift
return vertices
В эпоху 0 мы начинаем с ранее загруженной в блокнот сферы. Вершины сферы хранятся в vertices,, а начальная карта текстуры для сферы — в texture_map.
Визуализируем формируемую сферу на кадлом шаге при помощи дифференциального рендерера DIB-R в 2D с наложенной на неё текстурой, используя то же положение камеры и те же параметры, что и у снимавшей истинное изображение часов камеры. В конце шага подсчитываем потери:
loss = (
image_loss * image_weight +
mask_loss * mask_weight +
laplacian_loss * laplacian_weight +
flat_loss * flat_weight
)
И обновляем сетку:
### Update the mesh ###
loss.backward()
optim.step()
Эти две строки кода очень важны:


На этом этапе должна быть возможность просматривать временной интервал тренировки через приложение Nvidia Kaolin App. Чтобы узнать, как получить эту возможность, посмотрите видео.
Источник статьи: https://habr.com/ru/company/skillfactory/blog/568218/

Хорошая новость заключается в том, что теперь мы можем попробовать DIB-R — Nvidia выпустила библиотеку PyTorch в составе Nvidia Kaolin, она содержит DIB-R — тот самый дифференциальный рендерер. Но лучше всего вот что: библиотека содержит демонстрирующее возможности DIB-R руководство.
Должен признаться, что не очень понял его, увидев впервые. Кроме того, я даже не был уверен, нужен ли дифференциальный рендерер как таковой; я даже перепутал дифференциальный рендерер с нейронной сетью, описанной в статье DIB-R и способной генерировать 3D-объект из одной 2D-фотографии. На самом деле это две разные вещи. Я собираюсь показать вам шаг за шагом, как попробовать DIB-R, а также поделиться с вами тем, что я узнал о DIB-R и области 3D Deep Learning.
Что такое Nvidia Kaolin
Nvidia Kaolin — это не только библиотека PyTorch. Nvidia Kaolin состоит из двух основных компонентов:- Nvidia Omniverse Kaolin App — это приложение, созданное компанией Nvidia, чтобы помочь исследователям 3D Deep Learning, дать инструмент визуализации 3D наборов данных, средство генерации синтетических наборов и даже возможность визуализации генерируемых моделью во время обучения 3D-результатов.
- Nvidia Kaolin Library, API PyTorch, поддерживает различные 3D-представления: облака точек, сетки и воксельные сетки, а также преобразующие эти представления функции (kaolin.ops). Библиотека также включает DIB-R, дифференциальный рендерер (kaolin.render), функции загрузки данных из популярных наборов, таких как Shapenet, загрузки 3D-моделей в разных форматах файлов, таких как obj и usd (kaolin.io). API для создания 3D контрольных точек (kaolin.visualize), а в будущем и многое другое.
Требования DIB-R
- GPU Nvidia;
- Windows или Linux.
- Python 3.7;
- Pytorch 1.7.0;
- CUDA 11.2 или выше;
- Nvidia Kaolin Library;
- Nvidia Omniverse Launcher.
Установка зависимостей
- Anaconda.
- CUDA
- Cреда Conda kaolin
conda activate kaolin
Для подготовки к настройке загрузим Nvidia Kaolin с Github.
git clone --recursive https://github.com/NVIDIAGameWorks/kaolin
cd kaolin
В инструкции по установке Kaolin сказано, что нужно переключить ветку git на последнюю Kaolin — это v0.9.0. К сожалению, 0.9.0 пока не содержит руководства по DIB-R, они есть только в основной ветке, поэтому настроим Kaolin напрямую из этой ветки.
- Pytorch 1.7.1
conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 -c pytorch
- Nvidia Kaolin
- Nvidia Omniverse Launcher
- Nvidia Kaolin из Nvidia Omniverse Launcher
Нажмите APPS и найдите Kaolin; затем из местоположения Kaolin возможно загрузить и установить приложение Omniverse Kaolin App.
Включаем DIB-R в контекст
Пробуем руководство DIB-R! Но сначала кратко поговорим о недавних работах GanVerse3D и DIB-R и об их взаимосвязи. В первой части статьи о DIB-R Nvidia подробно рассказывает о разработке улучшенного дифференциального рендерера — DIB-R.
Во второй части обсуждается, как работать с DIB-R — дифференциальным рендерером, решать сложные задачи 3D Deep Learning: обучить модель, способную спрогнозировать форму, текстуру и освещение 3D-объекта по одному изображению. Здесь модель обучалась на данных из наборов ShapeNet и CUB Bird.
В работе GANVerse3D Nvidia поднимается на ступень выше. Вместо наборов ShapeNet и CUB они работают с наборами DatasetGAN, сгенерированными нейросетью StyleGAN-R и новым GAN.
StyleGAN-R, он же StyleGAN Renderer, похож на обычную StyleGAN, за исключением того, что его первые четыре слоя замораживаются для получения изображений одного и того же класса объектов в разных ракурсах при известном положении камеры.
DatasetGAN, GAN, разработанный компанией Nvidia, затем используется для автоматического аннотирования всех сгенерированных изображений, вплоть до уровня пикселя (семантическая сегментация). Именно это позволяет Nvidia анимировать 3D-объекты, например автомобиль, после преобразования из 2D-фотографии.
Что представляет собой руководство DIB-R?
Руководство по DIB-R, которое сегодня есть на Github, показывает работу дифференциального рендерера DIB-R и то, как его можно использовать для восстановления структуры и текстуры 3D-модели из нескольких 2D-изображений в качестве чистой задачи оптимизации. Но важнее то, чем оно не является. Это не руководство о том, как можно генерировать 3D-модели из одного 2D-изображения с помощью нейронной сети, которая была описана во второй части статьи DIB-R. Позже, когда мы будем разбирать код, вы увидите, что в нём не используется нейронная сеть.Работа DIB-R
Подробнее поговорим о документе DIB-R — это поможет понять руководство. Проблема преобразования двухмерного изображения в его исходную трёхмерную сцену — обратная задача традиционной компьютерной графики, отсюда и название “инверсная графика”. Легче сказать, чем сделать, инверсная графика довольно сложна, поскольку традиционные конвейеры рендеринга, такие как OpenGL, DirectX, не разрабатывались для восстановления 3D-сцены, которая подвергается рендерингу. Эти конвейеры разрабатывались ради эффективности и содержат множество оптимизаций, что приводит к потере части информации о 3D-сцене.Что такое дифференциальный рендерер
Думаю, стоит поговорить о том, что такое дифференциальный рендерер и зачем он нужен. Давайте представим, что мы сами пытаемся решить эту проблему компьютерного зрения, но необязательно с помощью Machine Learning. Двухмерная фотография — это проекция трёхмерной сцены. 3D-сцена — это набор 3D-сеток, вершин, граней, текстурных карт и источника света, просматриваемых с камеры или точки обзора. Для простоты ограничим сцену одним 3D-объектом. Если получилось восстановить исходную 3D-сцену, на основе которой была создана 2D-фотография, мы должны быть способны проверить это, спроецировав 3D-объект на 2D с использованием той же точки зрения, что использовалась для создания входной 2D-фотографии.Грубая сила
Чтобы восстановить объект, необходимо вычислить все возможные комбинации вершин, граней, источников света и текстуры, которые, проецируясь в 2D, должны дать эквивалентное изображение в 2D, заданное входным, при условии, что положение камеры одинаково. По сути, это проблема поиска. Но проблема с перебором заключается в том, что имеется гигантское количество комбинаций вершин, граней, текстурных карт и освещения, которые можно создать, поэтому мы не можем решить эту проблему грубой силой.Градиентный подход
Попробуем найти способ разумнее! Как насчёт того, чтобы начать с исходной сетки, например сферы, топологически похожей на объект, который мы пытаемся восстановить, а затем попытаться внести изменения, чтобы сделать эту сферу похожей на часы? Вот, что возможно изменить:- геометрию входной сетки перемещением вершин;
- цвета в текстуре;
- входное освещение.
Растеризация
Но, Хьюстон, у нас проблема: для преобразования 3D-сцены в 2D нужно использовать конвейер рендеринга графики. В традиционном конвейере компьютерной графики для рендеринга 3D-сцены на 2D-сцену используется техника растеризации. В процессе проецирования трёхмерного изображения на двухмерную плоскость, растеризации треугольников и затенения пикселей из-за алгоритмов графического конвейера информация теряется — и эти потери вносят разрывы в изображения. Это означает, что часто внесение минутных изменений в геометрию может вообще не привести к изменению изображения. Или, что ещё хуже, изображение изменится внезапно и отдалит нас от целевого двухмерного изображения. Из-за этих проблем нельзя узнать направление поисков, восстановление оригинальной сцены становится очень сложным.Дифференциальный рендерер
Похоже, что нужно разработать собственный конвейер рендеринга, он же дифференциальный рендерер. Этот новый конвейер гарантирует, что при каждом изменении входного 3D-объекта изменяются пиксели проецируемого 2D-изображения, изменение будет постепенным для каждого пикселя. Более того, любой сгенерированный пиксель будет иметь производные, которые могут работать в определении, то есть обратном распространении исходных входов, которые внесли вклад в конечное значение каждого пикселя. К счастью, нам не нужно изобретать колесо — воспользуемся DIB-R!DIB-R — дифференциальный рендерер
DIB-R — это дифференциальный рендерер, который моделирует значения пикселей с помощью алгоритма дифференцируемой растеризации, в нём имеется два метода присвоения значений пикселей. Один для пикселей переднего плана, другой — для пикселей фона.Пиксели переднего плана
О пикселях переднего плана в статье DIB-R:
Здесь, в отличие от стандартного рендеринга, где значение пикселя присваивается по ближайшей покрывающей пиксель грани, растеризация переднего плана рассматривается как интерполяция атрибутов вершин[4]. На каждом пикселе переднего плана проводим тест z-буферизации [6] и присваиваем его ближайшей покрывающей грани. На каждый пиксель влияет исключительно эта грань.
Таким образом, пиксели переднего плана рассчитываются как интерполяция ближайших трёх соседних вершин с использованием веса для каждой вершины, где Ii — интенсивность пикселя.
Фоновые пиксели
Для фоновых пикселей, то есть пикселей, которые не покрыты ни одной гранью 3D-объекта, значение рассчитывается на основе расстояния от пикселя до ближайшей грани.
Другие дифференциальные рендереры
Важно подчеркнуть, что DIB-R не является первым и единственным дифференциальным рендерером. Это улучшенный дифференциальный рендерер, основанный на идеях созданного в 2014 году OpenDR, а также SoftRas-Mesh, предлагающего аналогичный DIB-R дифференциальный рендерер.
Как создать 3D-модель и текстуру из одного изображения
А как насчёт того, чего мы не видим? Конечно, если у меня есть только фотография передней части часов, как определить, что находится за изображением 2D? Решение — галлюцинация. Сегодня представлять себе такие вещи способна только GAN, поэтому не стоит удивляться, что мы также можем использовать GAN при генерации 3D-объектов и текстуры. Не вдаваясь в излишние подробности, во второй части статьи DIB-R описывается применение GAN с архитектурой “кодер — декодер” в прогнозировании положения вершин, геометрии, цветов/текстуры 3D-модели по одному изображению с помощью 2D-наблюдения с применением дифференциального рендерера.Вернёмся к руководству по DIB-R
Но в учебнике DIB-R не используется ни GAN, ни какая-либо другая нейронная сеть: это простая демонстрация того, как можно использовать дифференциальный рендерер DIB-R в сочетании с PyTorch, решая проблему оптимизации в отношении восстановления 3D геометрии и текстуры итеративно из нескольких точек обзора одного и того же объекта, в данном случае часов. Пора запускать учебник!
Цель руководства по DIB-R — показать, как использовать DIB-R, дифференциальный рендерер при попытке восстановить 3D-геометрию и текстуру 3D-объекта, часть набора Kitchen от Pixar. Этот набор представляет собой коллекцию 3D-объектов, которые обычно можно найти на кухне, и компания Pixar любезно открыла доступ к этому набору. Часы были выбраны потому, что это относительно простой объект без топологических отверстий.
Генерация обучающих данных
Во-первых, мы используем приложение Nvidia Kaolin для создания набора двумерных изображений часов со ста точек обзора. Для точки обзора генерируются изображение RGB, маска сегментации и дополнительный файл метаданных JSON, файл содержит параметры камеры, такие как фокусная точка, диафрагма, фокусное расстояние и т. д.
Загрузка обучающих данных
Для загрузки обучающих данных воспользуемся torch.utils.DataLoader — классом PyTorch для загрузки в память готовых к работе на GPU наборов данных. Обратите внимание: pin_memory мы установим в True, что автоматически загрузит набор данных в pinned memory, которая быстрее передаётся в память GPU, когда начнётся обучение.Также для загрузки изображения в обучающем наборе мы используем метод kal.io.render.import_synthetic_view, кроме того, он загружает файл семантической маски для всех изображений и JSON с параметрами камеры.
num_views = len(glob.glob(os.path.join(rendered_path,'*_rgb.png')))
train_data = []
for i in range(num_views):
data = kal.io.render.import_synthetic_view(
rendered_path, i, rgb=True, semantic=True)
train_data.append(data)
dataloader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,shuffle=True, pin_memory=True)
Загрузка шаблона сферы
Далее мы загружаем сферу в формате obj. Во время обучения она преобразуется таким образом, что окажется похожей на часы.
Во время обучения мы не будем менять топологию (к примеру добавлять отверстия).
Подготовка потерь и регуляризации
Настроим функции потерь, у которых две цели:- Это способ понять, насколько мы далеки от истины. Исходными данными будут изображения часов с камеры из разных мест.Воспользуемся Image L1 Loss — это абсолютная разница между спрогнозированным и реальным изображениями.Также рассчитаем потерю маски — измерение того, насколько спрогнозированное пересечение надо объединением soft_mask пересекается с наблюдаемой маской сегментации наших часов.
- Они работают как регуляризатор, штрафуют любую геометрию, имеющую самопересекающиеся грани и поощряет гладкость. Здесь используем потерю Лапласиана и плоскую потерю — это часто применяемые регуляризаторы гладкости.
image_loss * image_weight +
mask_loss * mask_weight +
laplacian_loss * laplacian_weight +
flat_loss * flat_weight
)
Настройка оптимизатора
Алгоритм оптимизации из руководства — Adam:optim = torch.optim.Adam(params=[vertices, texture_map, vertice_shift],lr=lr)
scheduler = torch.optim.lr_scheduler.StepLR(optim, step_size=scheduler_step_size,=scheduler_gamma)
Как тренировочные параметры Adam использует вершины (vertices), texture_map и vertice_shift.
vertice_shift, по-видимому, является параметром, который используется для сдвига всех вершин сферы во время обучения.Здесь я предполагаю; мне кажется, что всякий раз, когда вы меняете форму сферы, то смещаете центр, и поэтому на всех этапах обучения вызывается метод recenter_vertices, принимающий на вход вершины и параметры vertices_shift.
def recenter_vertices(vertices, vertice_shift):
"""Recenter vertices on vertice_shift for better optimization"""
vertices_min = vertices.min(dim=1, keepdim=True)[0]
vertices_max = vertices.max(dim=1, keepdim=True)[0]
vertices_mid = (vertices_min + vertices_max) / 2
vertices = vertices - vertices_mid + vertice_shift
return vertices
Обучение
В процессе обучения руководство проходит в общей сложности 40 эпох. Эпоха состоит из 100 шагов — это количество представлений часов.В эпоху 0 мы начинаем с ранее загруженной в блокнот сферы. Вершины сферы хранятся в vertices,, а начальная карта текстуры для сферы — в texture_map.
Визуализируем формируемую сферу на кадлом шаге при помощи дифференциального рендерера DIB-R в 2D с наложенной на неё текстурой, используя то же положение камеры и те же параметры, что и у снимавшей истинное изображение часов камеры. В конце шага подсчитываем потери:
loss = (
image_loss * image_weight +
mask_loss * mask_weight +
laplacian_loss * laplacian_weight +
flat_loss * flat_weight
)
И обновляем сетку:
### Update the mesh ###
loss.backward()
optim.step()
Эти две строки кода очень важны:
- loss.backward() вычисляет градиенты, то есть изменения значений каждого оптимизируемого параметра;
- optim.step() обновляет параметры в соответствии с этими градиентами. Под обратным распространением имеется в виду именно это.
Визуализация обучения
Последний блок кода показывает, как выглядит конечная форма сферы. Запустив код, вы должны получить аналогичный результат!
На этом этапе должна быть возможность просматривать временной интервал тренировки через приложение Nvidia Kaolin App. Чтобы узнать, как получить эту возможность, посмотрите видео.
Источник статьи: https://habr.com/ru/company/skillfactory/blog/568218/