Данные — краеугольный камень любой большой компании, которая так или иначе работает с людьми. Чем больше компания, тем больше пользователей её услуг и сервисов, тем больше этих самых данных о клиентах можно собирать. Но мало просто их собрать — нужно их анализировать, нужно правильно их хранить и обрабатывать. То есть нужно активно применять возможности машинного обучения и привлекать специалистов по Data Science.
Меня зовут Александр Ошурков, и этот пост будет про машинное обучение внутри Московского кредитного банка (МКБ). Вы узнаете о том, как мы запустили новое для себя направление — практику машинного обучения.
Мой рассказ будет полезен тем, кто только задумывается над организацией такого подразделения у себя и не знает с чего начать или недавно ступил на этот путь.
Начнем по порядку.
Всё началось с того, что мы в МКБ осознали необходимость создания единого центра экспертизы, силами которого можно будет решать задачи, нерешаемые другими путями. И как только осознали это, возникла целая гора вопросов: какие задачи брать в работу, кто именно будет их решать, как вырастить внутри банка сильных экспертов, как и чем мы будем обеспечивать безопасность?
Project Jupyter — наш основной рабочий инструмент, самая популярная среда разработки для дата-сайентистов и людей, чья работа связана с машинным обучением, — почти 75% таких специалистов используют именно его.
Основной язык в нашем случае — Python. Python в среде Data Science уже стал стандартом. Да, существует вероятность найти человека, который знает, например, R, но таких специалистов гораздо меньше. Кроме самих дата-сайентистов нужно иметь людей, которые потом возьмут код модели на поддержку, и здесь тоже лучше использовать более популярный язык.
Всю документацию по работе мы ведём в Confluence, включая документацию по бизнес-валидации и данным, а так же протоколы наших рабочих встреч. Для деплоя наших сервисов используем набор девопс-инструментов, который уже устоялся в банке, и «добавки» из Open Source компонентов для организации MLOps.
Вариант самый популярный, при этом самый плохой с точки зрения любого enterprise. Де-факто тут разворачивается сервер, с которым на собственной машине работает один человек. Недостатков куча:
Поэтому есть второй вариант, получше.

Каждый пользователь заходит на сервер и создаёт свой инстанс Jupyter Notebook. И тут уже появляется набор ощутимых плюсов:

Этот компонент даст вам возможность управлять запуском Jupyter-ноутбуков на сервере и предоставит одинаковое настраиваемое окружение, контейнеризацию, общие настройки безопасности и общую точку доступа. Cо своей рабочей машины дата-сайентист по ссылке заходит на Jupyter Hub, который создаст для него инстанс Jupyter Notebook.
Компонент добавляет централизованное управление ноутбуками и пользователями, в достаточно широких пределах позволяя настраивать доступные «железные» ресурсы (CPU, RAM, HDD) и окружение.
Можно включить авторизацию по LDAP и при необходимости создать множество Jupyter-ноутбуков, несколько сотен или даже тысяч. Такое может пригодиться, если у вас в компании бывает практика по обучению студентов: людей обычно много, а вот задачи у них плюс-минус одинаковые. Так что сделать на 100 студентов 100 Jupyter-ноутбуков — вообще не проблема.
Если взять все задачи для бизнеса, которые мы делаем, то можно с уверенностью сказать, что 95% из них решаются пакетом Scikit-learn.

Для подготовки данных и визуализации используются библиотеки:
Не будем забывать про библиотеки, которые упрощают работу: UI-фишки, удобные инструменты разработчика и т. д.
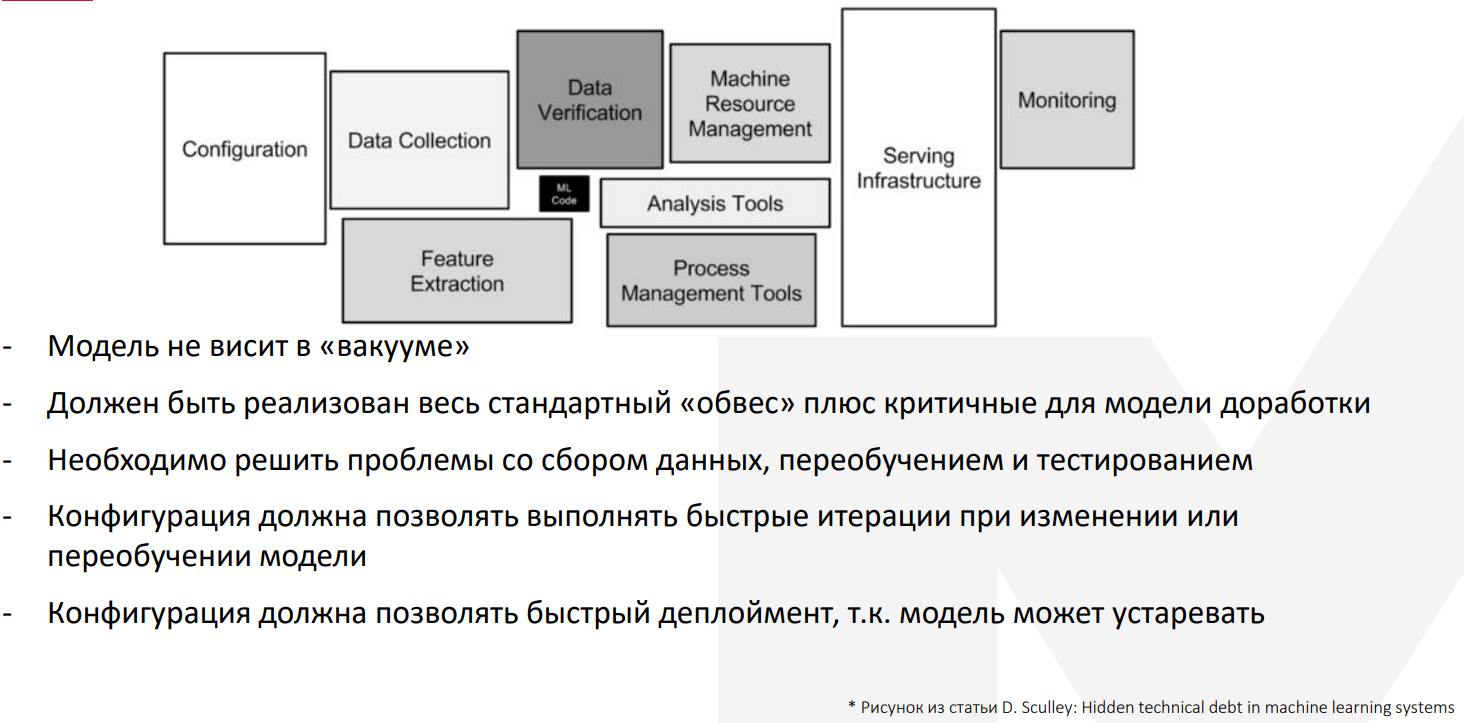
На этой картинке крупными блоками представлены наиболее стандартные части для любого приложения. Конфигурация, инфраструктура, мониторинг, data collection и прочее.
А небольшой чёрный прямоугольник в центре — это как раз нужный нам кусок, относящийся к ML-модели.
Что это за доработки?
Например, надо решить проблемы со сбором данных, переобучением и тестированием. В целом есть разные способы, но для каждой модели их необходимо решать в индивидуальном порядке. Конфигурация всего этого должна позволять выполнять быстрые итерации, потому что модель может очень быстро устаревать.
Первое и главное: нам нужно следить за точностью работы модели. Модели деградируют со временем. Эта деградация по времени для каждой модели разная, но нужно обязательно следить за тем, что модель работает в заданных параметрах.
На работу нашей модели критически влияют входящие данные. Может изменяться не только перечень данных, которые вливаются в модель со стороны системы поставщика, но и сами переменные, которые во время обучения имели одни параметры, а во время работы на проде почему-то поменяли свои значения.
Мониторинг должен настраиваться индивидуально по каждой модели. Важно понимать, что все модели работают в разных временных промежутках: есть модели, которые работают на пятиминутке, есть модели, которые потребляют данные за несколько лет. Так что мониторинг надо настраивать соответствующим образом.
Необходимо включать мониторинг для информационной безопасности. Сама модель является критической частью кодовой базы, и за ней необходимо смотреть в первую очередь с точки зрения утечек.
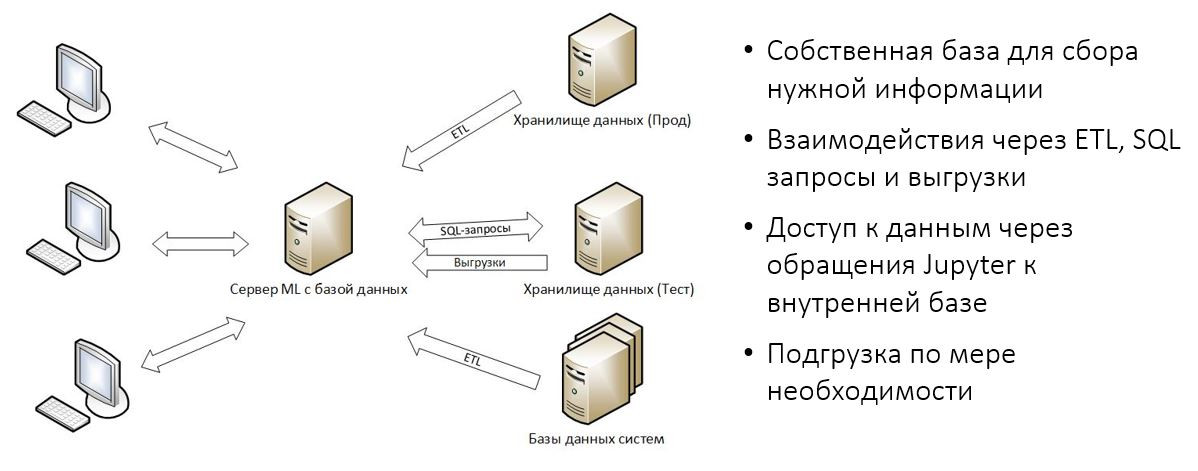
На картинке — наши варианты работы с данными в МКБ.
Сначала мы пытались выбрать свой основной источник данных. К сожалению, это не удалось и были приняты несколько попыток по поиску источников.
Первая попытка — сходить в хранилище данных, в продакшн. Увы, не взлетело. Во-первых, потому что на продакшн очень ограниченный доступ, ведь там лежат и личные данные клиентов, и транзакции, и много чего ещё важного. Во-вторых, категорически не рекомендуется создавать на продакшене дополнительный workload, это может привести к повышенной аварийности, что для прода тоже очень критично.
Соответственно, единственный канал, который мы рассматриваем на текущий момент — получать данные с продакшена через ETL в нашу внутреннюю базу данных.
Ещё в нашей компании есть тестовое хранилище данных, где копируются практически все те же самые данные, как и в продакшене, но с этим есть своя проблема: к сожалению, он достаточно слабый с точки зрения железа, поэтому регулярный запуск очень тяжёлых запросов на нём проблематичен. Тем не менее для разведочного анализа мы используем эту базу, делаем выгрузки.
Третий возможный вариант — базы данных всех систем банка, которые почему-то не попали в хранилище данных. Такое бывает, потребителям эти данные могут быть не нужны, но при работе модели мы всё равно хотим их учитывать, поэтому заказываем их получение.
Как идет работа с этими данными? У нас есть сервер для машинного обучения, там крутится база данных, которая выделена исключительно под наши нужды, наполняется она через средства ETL и вручную через выгрузки. Доступ к данным осуществляется исключительно через Jupyter к этой самой базе. Выполняется подгрузка по мере необходимости.
Когда проект стартует, мы черновым способом (простым текстом) пишем, какие именно данные нам могут понадобиться для реализации идеи. Это описание используется для следующего шага.
Есть такая диаграмма данных, она гигантская, как вы видите на картинке, но она содержит в себе все описания таблиц, поля и связи.
Для каждого проекта мы делаем отдельную диаграмму, которая достаточно легко формируется средствами Power Designer, то есть мы берём те сущности, которые нам необходимы (например, таблицы или view), и перетаскиваем их в новый проект. При этом сохраняются все связи — они помогают нам продвигаться вперёд, сразу дают какие-то дополнительные данные.
Описание таблиц и полей тоже заполняется через Power Designer, всё это потом выгружается через проектную диаграмму в Confluence.
Ещё мы в разрезе любого проекта ведем реестр SQL-запросов, но используется он всеми проектами, всеми сотрудниками, кто в нём заинтересован. Отмечу, что SQL-запросы очень часто находят применение повторно: например, если мы говорим про клиентскую информацию, то здесь практически на каждом проекте используются одни и те же запросы, поэтому создать реестр SQL-запросов — очень хорошая идея.
Вы спрашиваете: «И к клиентским?»
Он отвечает: «Особенно к ним!».
Вы:

Конечно, стартуя новое направление, вам придется объяснять, зачем вам данные, потому что все банки с особенным трепетом относятся к данным о клиентах.
Не тратьте время, создайте общие процедуры, чтобы ваша работа была прозрачна и понятна для всех участников. Обязательно надо обсудить функционал инструментария, потому что большая часть инструментария специфична для специалистов по DS и появляется в контуре организации впервые. Следовательно, на каждую библиотеку, на каждый компонент, особенно это касается Project Jupyter, необходимо завести отдельное описание и заранее согласовать его с информационной безопасностью.
Также необходимо выработать подход в DevOps. Как я раньше рассказывал, есть особенности, которые касаются именно моделей машинного обучения, соответственно, при вовлечении информационной безопасности в этот процесс необходимо вместе его прорабатывать.
Какие мы в МКБ используем подходы к информационной безопасности для сотрудников?
Так уж вышло, что большинство новых специалистов проходит обучение на специализированных ресурсах, делая задачки на Kaggle и участвуя в хакатонах, где они тоже могут развиваться как профессионалы, однако есть большое отличие от работы в организации. По нашим оценкам, порядка 80% времени ML-специалиста уходит на работу с данными: найти их, обсудить со знающими людьми, что значит каждое поле, сделать EDA, подготовить датасет.
Некоторых людей это отпугивает на старте, поэтому мы об этом честно предупреждаем.
Только около 20% времени занимает непосредственно моделирование.
Человек должен иметь представление об инструментах машинного обучения и обработке данных на основе библиотек Python.
Необходим SQL для формирования первичного датасета.
Неплохо было бы иметь английский на уровне чтения технических текстов (главным образом, для самообучения и поиска помощи по используемым библиотекам).

 habr.com
habr.com
Меня зовут Александр Ошурков, и этот пост будет про машинное обучение внутри Московского кредитного банка (МКБ). Вы узнаете о том, как мы запустили новое для себя направление — практику машинного обучения.
Мой рассказ будет полезен тем, кто только задумывается над организацией такого подразделения у себя и не знает с чего начать или недавно ступил на этот путь.
Начнем по порядку.
Всё началось с того, что мы в МКБ осознали необходимость создания единого центра экспертизы, силами которого можно будет решать задачи, нерешаемые другими путями. И как только осознали это, возникла целая гора вопросов: какие задачи брать в работу, кто именно будет их решать, как вырастить внутри банка сильных экспертов, как и чем мы будем обеспечивать безопасность?
Для начала мы определились с инструментами:
Project Jupyter — наш основной рабочий инструмент, самая популярная среда разработки для дата-сайентистов и людей, чья работа связана с машинным обучением, — почти 75% таких специалистов используют именно его.
Основной язык в нашем случае — Python. Python в среде Data Science уже стал стандартом. Да, существует вероятность найти человека, который знает, например, R, но таких специалистов гораздо меньше. Кроме самих дата-сайентистов нужно иметь людей, которые потом возьмут код модели на поддержку, и здесь тоже лучше использовать более популярный язык.
Всю документацию по работе мы ведём в Confluence, включая документацию по бизнес-валидации и данным, а так же протоколы наших рабочих встреч. Для деплоя наших сервисов используем набор девопс-инструментов, который уже устоялся в банке, и «добавки» из Open Source компонентов для организации MLOps.
Project Jupyter и как его готовить
Есть несколько вариантов работы с Jupyter, каждый из которых имеет право на существование:1. Запуск Jupyter Notebook на локальной машине.
Вариант самый популярный, при этом самый плохой с точки зрения любого enterprise. Де-факто тут разворачивается сервер, с которым на собственной машине работает один человек. Недостатков куча:
- Уникальное окружение.
- Недостаток мощности (вы всегда ограничены мощностью собственной машины).
- Проблемы с безопасностью.
- Проблемы с доступом к данным (особенно в рамках организации, когда необходима сетевая связанность, сложно получать доступы от машины к хранилищу данных).
- Проблемы с шарингом (приходится придумывать костыли, чтобы поделиться результатом работы с коллегами).
- На каждую новую машину всё надо ставить отдельно.
Поэтому есть второй вариант, получше.
2. Запуск Jupyter Notebook на выделенном сервере
Каждый пользователь заходит на сервер и создаёт свой инстанс Jupyter Notebook. И тут уже появляется набор ощутимых плюсов:
- Можно сделать консистентное окружение, и все библиотеки и ОС будут одинаковыми и будут так же одинаково себя вести.
- Общая мощность сервера, которую, правда, может "сожрать" один единственный сотрудник.
- Общие настройки безопасности в рамках ОС.
- Можно упростить доступ к данным, когда сетевой трафик регулируется от двух точек: первая — сервер с Jupyter Notebook, вторая — источник данных.
- Можно создать для сервера локальный репозиторий для ноутбуков, куда их удобно складывать.
3. Использовать Jupyter Hub
Этот компонент даст вам возможность управлять запуском Jupyter-ноутбуков на сервере и предоставит одинаковое настраиваемое окружение, контейнеризацию, общие настройки безопасности и общую точку доступа. Cо своей рабочей машины дата-сайентист по ссылке заходит на Jupyter Hub, который создаст для него инстанс Jupyter Notebook.
Компонент добавляет централизованное управление ноутбуками и пользователями, в достаточно широких пределах позволяя настраивать доступные «железные» ресурсы (CPU, RAM, HDD) и окружение.
Можно включить авторизацию по LDAP и при необходимости создать множество Jupyter-ноутбуков, несколько сотен или даже тысяч. Такое может пригодиться, если у вас в компании бывает практика по обучению студентов: людей обычно много, а вот задачи у них плюс-минус одинаковые. Так что сделать на 100 студентов 100 Jupyter-ноутбуков — вообще не проблема.
Библиотеки
На самом старте появляется также вопрос: а какие библиотеки использовать?Если взять все задачи для бизнеса, которые мы делаем, то можно с уверенностью сказать, что 95% из них решаются пакетом Scikit-learn.
Для подготовки данных и визуализации используются библиотеки:
- NumPy — библиотека, добавляющая поддержку больших многомерных массивов и матриц вместе с большой библиотекой высокоуровневых математических функций для операций с этими массивами.
- Pandas — библиотека, которая является мощным инструментом для анализа данных. Пакет дает возможность строить сводные таблицы, выполнять группировки, предоставляет удобный доступ к табличным данным и позволяет строить графики на полученных наборах данных при помощи библиотеки Matplotlib;
- Matplotlib — библиотека для построения качественных двухмерных графиков.
Не будем забывать про библиотеки, которые упрощают работу: UI-фишки, удобные инструменты разработчика и т. д.
Особенности развёртывания ML-сервисов
Модель не висит в вакууме, нам нужно реализовать весь стандартный для приложения обвес для того, чтобы его можно было мониторить, деплоить, то есть всё как обычно, плюс критичные для модели доработки.
На этой картинке крупными блоками представлены наиболее стандартные части для любого приложения. Конфигурация, инфраструктура, мониторинг, data collection и прочее.
А небольшой чёрный прямоугольник в центре — это как раз нужный нам кусок, относящийся к ML-модели.
Что это за доработки?
Например, надо решить проблемы со сбором данных, переобучением и тестированием. В целом есть разные способы, но для каждой модели их необходимо решать в индивидуальном порядке. Конфигурация всего этого должна позволять выполнять быстрые итерации, потому что модель может очень быстро устаревать.
Мониторинг
Во всём этом обвесе самые большие изменения вносятся именно в мониторинг, ведь системы машинного обучения имеют все стандартные проблемы обычного кода, а вишенкой сверху — дополнительный набор вещей, за которым нужно следить.Первое и главное: нам нужно следить за точностью работы модели. Модели деградируют со временем. Эта деградация по времени для каждой модели разная, но нужно обязательно следить за тем, что модель работает в заданных параметрах.
На работу нашей модели критически влияют входящие данные. Может изменяться не только перечень данных, которые вливаются в модель со стороны системы поставщика, но и сами переменные, которые во время обучения имели одни параметры, а во время работы на проде почему-то поменяли свои значения.
Мониторинг должен настраиваться индивидуально по каждой модели. Важно понимать, что все модели работают в разных временных промежутках: есть модели, которые работают на пятиминутке, есть модели, которые потребляют данные за несколько лет. Так что мониторинг надо настраивать соответствующим образом.
Необходимо включать мониторинг для информационной безопасности. Сама модель является критической частью кодовой базы, и за ней необходимо смотреть в первую очередь с точки зрения утечек.
А теперь про данные
На картинке — наши варианты работы с данными в МКБ.
Сначала мы пытались выбрать свой основной источник данных. К сожалению, это не удалось и были приняты несколько попыток по поиску источников.
Первая попытка — сходить в хранилище данных, в продакшн. Увы, не взлетело. Во-первых, потому что на продакшн очень ограниченный доступ, ведь там лежат и личные данные клиентов, и транзакции, и много чего ещё важного. Во-вторых, категорически не рекомендуется создавать на продакшене дополнительный workload, это может привести к повышенной аварийности, что для прода тоже очень критично.
Соответственно, единственный канал, который мы рассматриваем на текущий момент — получать данные с продакшена через ETL в нашу внутреннюю базу данных.
Ещё в нашей компании есть тестовое хранилище данных, где копируются практически все те же самые данные, как и в продакшене, но с этим есть своя проблема: к сожалению, он достаточно слабый с точки зрения железа, поэтому регулярный запуск очень тяжёлых запросов на нём проблематичен. Тем не менее для разведочного анализа мы используем эту базу, делаем выгрузки.
Третий возможный вариант — базы данных всех систем банка, которые почему-то не попали в хранилище данных. Такое бывает, потребителям эти данные могут быть не нужны, но при работе модели мы всё равно хотим их учитывать, поэтому заказываем их получение.
Как идет работа с этими данными? У нас есть сервер для машинного обучения, там крутится база данных, которая выделена исключительно под наши нужды, наполняется она через средства ETL и вручную через выгрузки. Доступ к данным осуществляется исключительно через Jupyter к этой самой базе. Выполняется подгрузка по мере необходимости.
Документирование
С самого начала проекта необходимо вести документирование данных.Когда проект стартует, мы черновым способом (простым текстом) пишем, какие именно данные нам могут понадобиться для реализации идеи. Это описание используется для следующего шага.
Есть такая диаграмма данных, она гигантская, как вы видите на картинке, но она содержит в себе все описания таблиц, поля и связи.
Для каждого проекта мы делаем отдельную диаграмму, которая достаточно легко формируется средствами Power Designer, то есть мы берём те сущности, которые нам необходимы (например, таблицы или view), и перетаскиваем их в новый проект. При этом сохраняются все связи — они помогают нам продвигаться вперёд, сразу дают какие-то дополнительные данные.
Описание таблиц и полей тоже заполняется через Power Designer, всё это потом выгружается через проектную диаграмму в Confluence.
Ещё мы в разрезе любого проекта ведем реестр SQL-запросов, но используется он всеми проектами, всеми сотрудниками, кто в нём заинтересован. Отмечу, что SQL-запросы очень часто находят применение повторно: например, если мы говорим про клиентскую информацию, то здесь практически на каждом проекте используются одни и те же запросы, поэтому создать реестр SQL-запросов — очень хорошая идея.
Так, а что там про информационную безопасность?
Представьте ситуацию: вы работаете в информационной безопасности, к вам приходит человек, который недавно в компании, и говорит: «А дайте мне, пожалуйста, доступ ко всем вашим данным».Вы спрашиваете: «И к клиентским?»
Он отвечает: «Особенно к ним!».
Вы:
Конечно, стартуя новое направление, вам придется объяснять, зачем вам данные, потому что все банки с особенным трепетом относятся к данным о клиентах.
Не тратьте время, создайте общие процедуры, чтобы ваша работа была прозрачна и понятна для всех участников. Обязательно надо обсудить функционал инструментария, потому что большая часть инструментария специфична для специалистов по DS и появляется в контуре организации впервые. Следовательно, на каждую библиотеку, на каждый компонент, особенно это касается Project Jupyter, необходимо завести отдельное описание и заранее согласовать его с информационной безопасностью.
Также необходимо выработать подход в DevOps. Как я раньше рассказывал, есть особенности, которые касаются именно моделей машинного обучения, соответственно, при вовлечении информационной безопасности в этот процесс необходимо вместе его прорабатывать.
Какие мы в МКБ используем подходы к информационной безопасности для сотрудников?
- Только то, что нужно: каждый сотрудник получает доступ только к тем данным, которые ему необходимы.
- Все данные скрыты. Практика показывает, что нет необходимости давать доступ к личным данным клиентов, это касается ФИО, email-адресов, телефонов — они, как правило, в моделях не используются.
- Доступ read — мы только забираем данные.
И про людей
Всё всегда зависит от людей, поэтому в конце поста расскажу, чем занимается специалист в большой организации, про поиск людей и про профили наших сотрудников, которых мы ищем и привлекаем к этой работе.Так уж вышло, что большинство новых специалистов проходит обучение на специализированных ресурсах, делая задачки на Kaggle и участвуя в хакатонах, где они тоже могут развиваться как профессионалы, однако есть большое отличие от работы в организации. По нашим оценкам, порядка 80% времени ML-специалиста уходит на работу с данными: найти их, обсудить со знающими людьми, что значит каждое поле, сделать EDA, подготовить датасет.
Некоторых людей это отпугивает на старте, поэтому мы об этом честно предупреждаем.
Только около 20% времени занимает непосредственно моделирование.
Как мы находим людей:
- Внутренний найм. У нас большая организация, в ней большой штат IT, поэтому в ней есть много людей, которые хотели бы себя попробовать на этой стезе. Таким образом, выдав информацию, что есть возможность взять коллег на part-time (30% времени или 20%), мы можем привлекать их к этой работе, кого-то даже приглашать на 100%, то есть перейти в наш департамент.
- Аутсорс — вариант быстрого старта, если вы (как и мы) стартуете с нуля. Это готовая возможность привлечь профессионалов на конкретные проекты и повысить экспертизу внутри компании.
- Внешний найм. Работы много, мы не можем закрыть все потребности внутренним наймом, потому что количество людей ограничено. А отдавать все проекты на аутсорс мы тоже не хотим, потому что это дорого, да и экспертизы не остаётся в компании. Поэтому мы также нанимаем людей с рынка и включаем их в общие команды с аутсорсом — таким образом, растим экспертизу.
Как выглядит профиль специалиста, когорого мы ищем?
В первую очередь, у специалиста должно быть знание методологии анализа данных и определенный опыт в работе с данными: это знание основ статистики и готовность самостоятельно искать данные.Человек должен иметь представление об инструментах машинного обучения и обработке данных на основе библиотек Python.
Необходим SQL для формирования первичного датасета.
Неплохо было бы иметь английский на уровне чтения технических текстов (главным образом, для самообучения и поиска помощи по используемым библиотекам).
Как работает машинное обучение в финтехе на примере МКБ
Данные — краеугольный камень любой большой компании, которая так или иначе работает с людьми. Чем больше компания, тем больше пользователей её услуг и сервисов, тем больше этих самых данных о...
habr.com