Меня зовут Кирилл Тобола, я Data Scientist и участник профессионального сообщества NTA.
Добро пожаловать в год 2912, где ваши DS навыки понадобятся для решения космической загадки. Мы получили сообщение с корабля на расстоянии 4 световых лет, и ситуация выглядит плохо.
Крейсер Титаник — межгалактический пассажирский лайнер отправился в путь около месяца назад. Почти 13 000 пассажиров находились на борту. Судно отправилось в свой маршрут, перевозя эмигрантов из нашей солнечной системы к трем новым недавно освоенным экзопланетам.
Следуя через Альфа Центавру на пути к первому пункту назначения жаркой 55 Кансри Е, крейсер Титаник столкнулся с пространственно‑временной аномалией, скрывшейся за облаком космической пыли. К сожалению, крейсер постигла та же участь, что и одноименный корабль ровно 1000 лет назад. В то время как корабль не пострадал, почти половина пассажиров переместились в альтернативное пространство.
Чтобы спасти команду и вернуть потерянных пассажиров, вам необходимо спрогнозировать кто из пассажиров переместился в альтернативную реальность используя данные из поврежденного журнала корабля. Задача помочь им спастись и не дать истории повториться вновь… Хотя может и не нужно и появится новый достаточно неплохой фильм.
Spaceship Titanic — это классическая задача машинного обучения, а именно задача бинарной классификации.

Сегодня я хочу рассказать об опыте применения EDA (Exploratory Data Analysis) для улучшения точности ML‑модели, на примере задачи из соревнования Spaceship Titanic. EDA (или разведочный анализ) — анализ основных свойств данных, используемый для нахождения общих зависимостей. Следствием качественного разведочного анализа является повышение качества модели машинного обучения.
Для начала рассмотрю набор исходных данных:
def split_feature(feature: str, new_features: list, sep: str) -> None:
X_train[new_features] = X_train[feature].str.split(sep, expand=True)
X_test[new_features] = X_test[feature].str.split(sep, expand=True)
def drop_features(features: list) -> None:
X_train.drop(features, axis=1, inplace=True)
X_test.drop(features, axis=1, inplace=True)
def cast_feature(feature: str, cast: str) -> None:
X_train[feature] = X_train[feature].astype(cast)
X_test[feature] = X_test[feature].astype(cast)
split_feature('PassengerId', ['GroupId', 'IdWithinGroup'], '_')
split_feature('Cabin', ['Deck', 'Num', 'Side'], '/')
drop_features(['Name', 'PassengerId', 'Cabin', 'IdWithinGroup', 'VIP', 'Num'])
for feature in ['GroupId']:
cast_feature(feature, 'float')
Я решил удалить следующие признаки:

На данном графике признаки упорядочены по важности. Можно заметить, что признак VIP практически не влияет на целевую функцию, поэтому исключу его.
Исходный набор данных содержит пропуски:
Для начала попробую не обращать внимания на данные пропуски. В качестве модели для решения задачи классификации буду использовать модель градиентного бустинга Catboost. Эта модель способна работать с данными, содержащими пропуски, поэтому для начала можно не заполнять пропущенные значения.
Закодирую категориальные переменные с помощью one‑hot кодирования:
X_train = pd.get_dummies(X_train)
X_test = pd.get_dummies(X_test)
Обучу модель и проверю результат: Score = 0.79 261 (топ 1262).
Улучшить результат можно несколькими способами. Например,
Для начала попробую заполнить пустые значения, не проводя анализ признаков. Для категориальных признаков заполню пропуски наиболее встречающимся значением, а для числовых признаков заполню пропуски медианами.
from sklearn.impute import SimpleImputer
numerical_columns = X_train.describe().columns
categorical_columns = set(X_train.columns) - set(numerical_columns)
for col in numerical_columns:
si = SimpleImputer(strategy='median')
X_train[col] = si.fit_transform(X_train[col].values.reshape(-1, 1))
X_test[col] = si.fit_transform(X_test[col].values.reshape(-1, 1))
for col in categorical_columns:
si = SimpleImputer(strategy='most_frequent')
X_train[col] = si.fit_transform(X_train[col].values.reshape(-1, 1))
X_test[col] = si.fit_transform(X_test[col].values.reshape(-1, 1))
Проверю результат: Score = 0.79 401. По сравнению с предыдущим — улучшение метрики на 0.0014.
Попробую улучшить результат, проанализировав данные.
Для начала посмотрю на распределения числовых признаков:
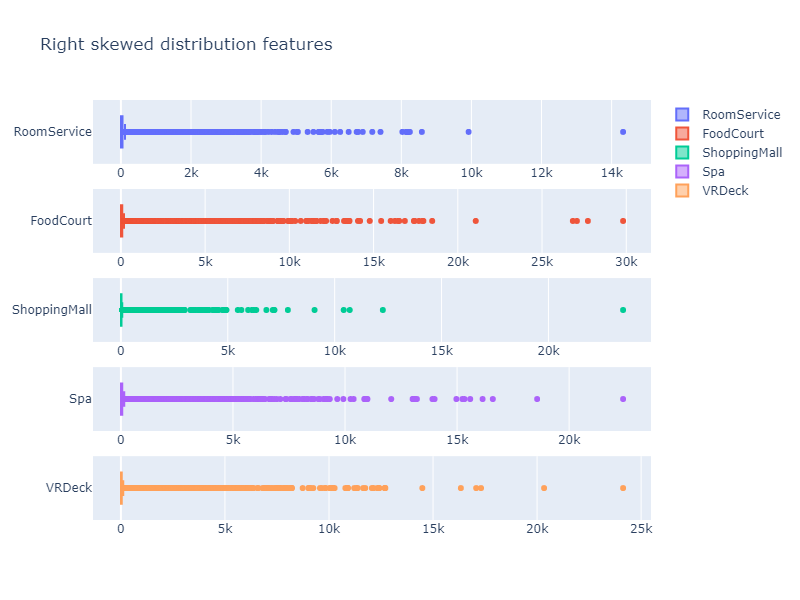
Стоит отметить, что методы градиентного бустинга слабо чувствительны к выбросам, поэтому можно оставить данные как есть.
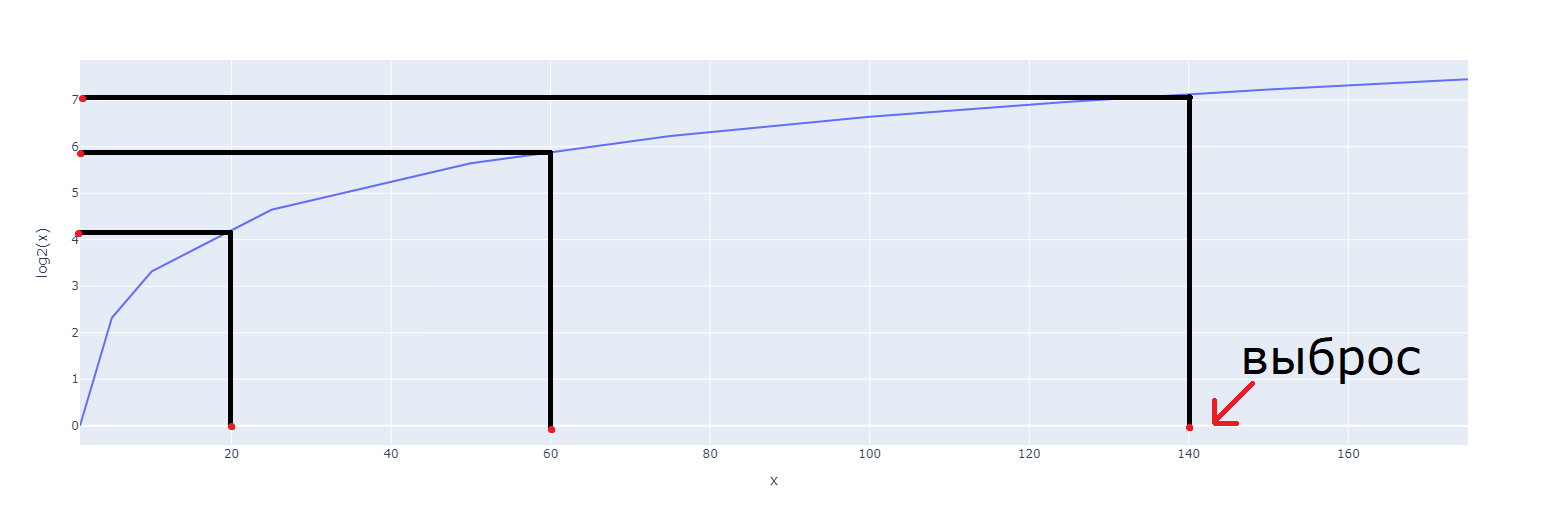
Забегая вперёд, скажу, что для борьбы с аномальными значениями я попытался применить следующие методы:
На графике показано, как с помощью данного метода можно нивелировать выбросы.
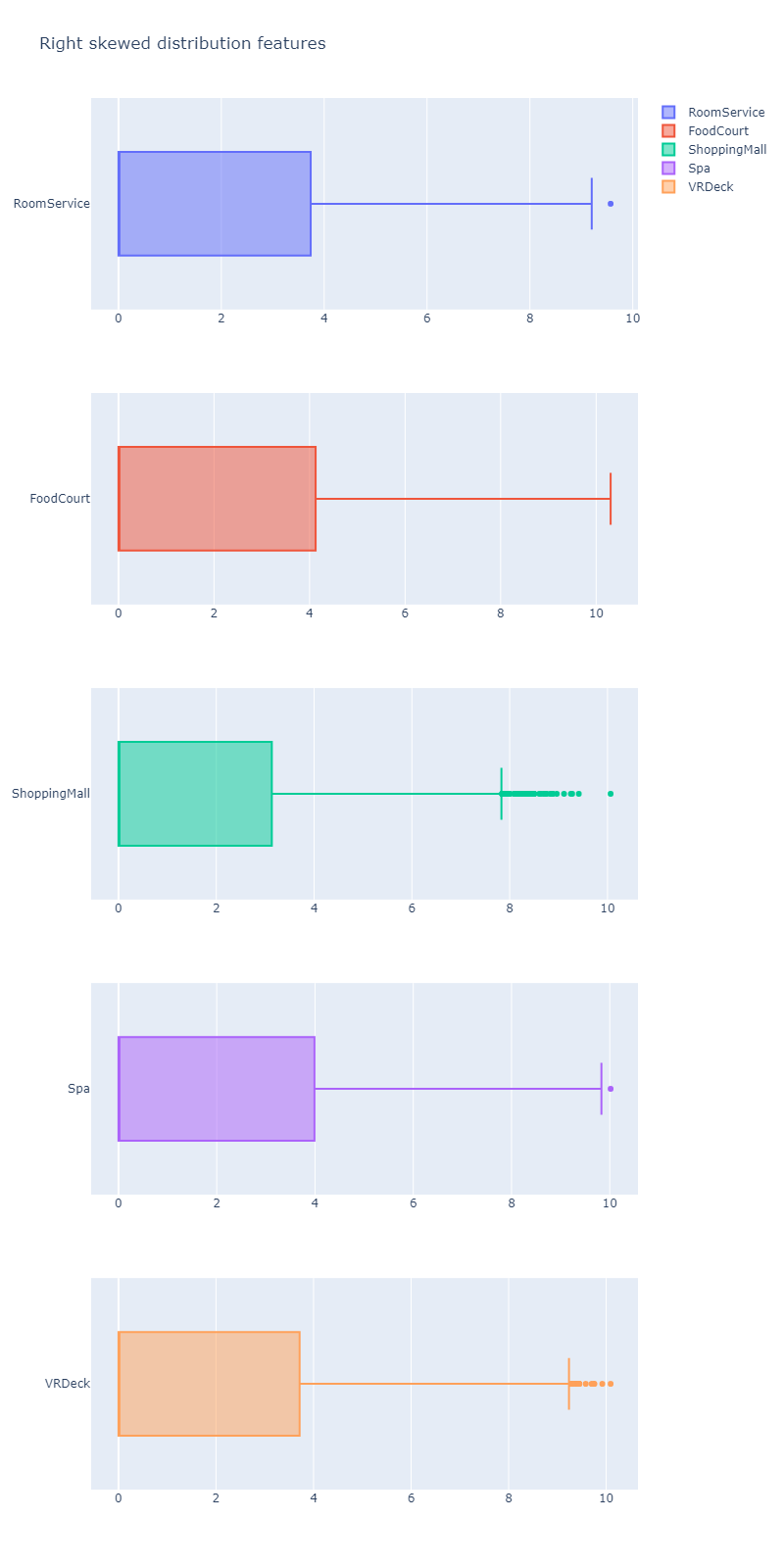
После применения логарифмирования распределения признаков стали иметь следующий вид:
Далее посмотрю на значения признаков при CryoSleep = True:
Можно сделать вывод о том, что если CryoSleep = True, то для всех записей значения признаков RoomService, FoodCourt, ShoppingMall, Spa, VRDeck = 0. Соответственно, если хотя бы одно из значений признаков RoomService, FoodCourt, ShoppingMall, Spa, VRDeck не равно нулю, то можно считать, что CryoSleep = False.
На основании этих утверждений, заполню пропуски в поле CryoSleep:
def impute_cryo_sleep(df: pd.DataFrame) -> None:
df.loc[
((df['RoomService'] == 0.0) | df['RoomService'].isnull()) &
((df['FoodCourt'] == 0.0) | df['FoodCourt'].isnull()) &
((df['ShoppingMall'] == 0.0) | df['ShoppingMall'].isnull()) &
((df['Spa'] == 0.0) | df['Spa'].isnull()) &
((df['VRDeck'] == 0.0) | df['VRDeck'].isnull()) &
(df['CryoSleep'].isnull()),
'CryoSleep'
] = True
df.loc[
((df['RoomService'] > 0.0) |
(df['FoodCourt'] > 0.0) |
(df['ShoppingMall'] > 0.0) |
(df['Spa'] > 0.0) |
(df['VRDeck'] > 0.0)) & (df['CryoSleep'].isnull()),
'CryoSleep'
] = False
impute_cryo_sleep(X_train)
impute_cryo_sleep(X_test)
Посмотрю на данные в разрезе признаков HomePlanet — Deck:
Можно заметить, что на палубах (Deck) A, B, C, T размещены только пассажиры с планеты Европа. А на палубе G только пассажиры с планеты Земля. Для пассажиров с Марса нельзя однозначно сказать, на какой палубе они размещены.
На основании этих данных заполню пропуски для признака HomePlanet:
def impute_home_planet_by_deck(df: pd.DataFrame) -> None:
df.loc[
(df['Deck'] == 'G') & (df['HomePlanet'].isnull()),
'HomePlanet'
] = 'Earth'
europa_decks = ['A', 'B', 'C', 'T']
df.loc[
(df['Deck'].isin(europa_decks)) & (df['HomePlanet'].isnull()),
'HomePlanet'
] = 'Europa'
impute_home_planet_by_deck(X_train)
impute_home_planet_by_deck(X_test)
Исходя из ранее приведенной таблицы в разрезе HomePlanet – Deck, можно заполнить значения Deck по значению HomePlanet, используя вероятностное распределение:
home_planet_deck = X_train.groupby(
['HomePlanet', 'Deck']
).size().unstack().fillna(0)
earth = home_planet_deck.loc['Earth']
earth_proba = list(earth / sum(earth))
europa = home_planet_deck.loc['Europa']
europa_proba = list(europa / sum(europa))
mars = home_planet_deck.loc['Mars']
mars_proba = list(mars / sum(mars))
decks = X_train['Deck'].unique()
deck_values = sorted(decks[~pd.isnull(decks)])
planet_proba = dict(
zip(['Earth', 'Mars', 'Europa'], [earth_proba, mars_proba, europa_proba])
)
# Idempotence
np.random.seed(0)
def impute_deck_by_home_planet(df: pd.DataFrame) -> None:
for planet in planet_proba.keys():
planet_null_decks_shape = df.loc[
(df['HomePlanet'] == planet) & (df['Deck'].isnull()),
'Deck'
].shape[0]
df.loc[
(df['HomePlanet'] == planet) & (df['Deck'].isnull()),
'Deck'
] = np.random.choice(
deck_values,
planet_null_decks_shape,
p=planet_proba[planet]
)
impute_deck_by_home_planet(X_train)
impute_deck_by_home_planet(X_test)
Посмотрю на распределения возрастов на планетах:
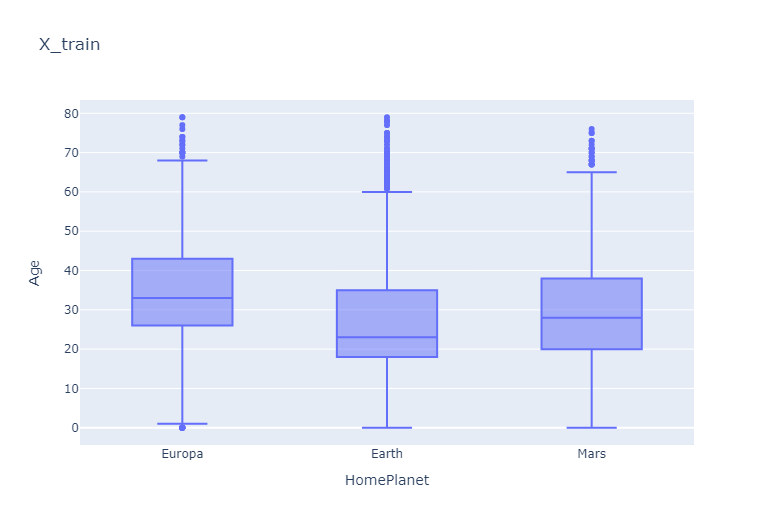
Заполню пропущенные значения признака Age медианными значениями по планетам:
def impute_age_by_planet(df: pd.DataFrame) -> None:
for planet in ['Europa', 'Earth', 'Mars']:
planet_median = df[df['HomePlanet'] == planet]['Age'].median()
df.loc[
(df['Age'].isnull()) & (df['HomePlanet'] == planet),
'Age'
] = planet_median
impute_age_by_planet(X_train)
impute_age_by_planet(X_test)
Проверю результат: Score = 0.79 775. В сравнении с первой попыткой — улучшение на 0.5 процента.
В результате только при помощи разведочного анализа и заполнения пустых значений на его основе удалось добиться улучшения на половину процента. Что, довольно, неплохо, учитывая тот факт, что в таких соревнованиях каждая десятая процента метрики может значительно повысить место в рейтинге.
Попробую улучшить модель при помощи подбора гиперпараметров модели. Для этого воспользуюсь фреймворком Optuna.
Optuna подобрал следующие параметры:
В результате при помощи подбора параметров получилось улучшить значение метрики более чем на один процент и перешагнуть значение итогового Score в 0.80.
Какие идеи для улучшения результата я на данный момент вижу:

 habr.com
habr.com
Добро пожаловать в год 2912, где ваши DS навыки понадобятся для решения космической загадки. Мы получили сообщение с корабля на расстоянии 4 световых лет, и ситуация выглядит плохо.
Крейсер Титаник — межгалактический пассажирский лайнер отправился в путь около месяца назад. Почти 13 000 пассажиров находились на борту. Судно отправилось в свой маршрут, перевозя эмигрантов из нашей солнечной системы к трем новым недавно освоенным экзопланетам.
Следуя через Альфа Центавру на пути к первому пункту назначения жаркой 55 Кансри Е, крейсер Титаник столкнулся с пространственно‑временной аномалией, скрывшейся за облаком космической пыли. К сожалению, крейсер постигла та же участь, что и одноименный корабль ровно 1000 лет назад. В то время как корабль не пострадал, почти половина пассажиров переместились в альтернативное пространство.
Чтобы спасти команду и вернуть потерянных пассажиров, вам необходимо спрогнозировать кто из пассажиров переместился в альтернативную реальность используя данные из поврежденного журнала корабля. Задача помочь им спастись и не дать истории повториться вновь… Хотя может и не нужно и появится новый достаточно неплохой фильм.
Spaceship Titanic — это классическая задача машинного обучения, а именно задача бинарной классификации.
Сегодня я хочу рассказать об опыте применения EDA (Exploratory Data Analysis) для улучшения точности ML‑модели, на примере задачи из соревнования Spaceship Titanic. EDA (или разведочный анализ) — анализ основных свойств данных, используемый для нахождения общих зависимостей. Следствием качественного разведочного анализа является повышение качества модели машинного обучения.
Для начала рассмотрю набор исходных данных:
- Размерность обучающей выборки (8693 x 13)
- Размерность тестовой выборки (4277 x 13)
- PassengerId — уникальный идентификатор для каждого пассажира. Состоит из номера группы и номера в этой группе.
- HomePlanet — планета, с которой отправился пассажир.
- CryoSleep — индикатор криосна.
- Cabin — номер кабины. Состоит из палубы/номера/стороны.
- Destination — планета, на которую летел пассажир.
- Age — возраст пассажира.
- VIP — индикатор, заплатил ли пассажир за ВИП сервисы.
- RoomService, FoodCourt, ShoppingMall, Spa, VRDeck — сумма, которую пассажир заплатил за удобства космического корабля.
- Name — имя и фамилия пассажира.
- Transported — целевая функция.
def split_feature(feature: str, new_features: list, sep: str) -> None:
X_train[new_features] = X_train[feature].str.split(sep, expand=True)
X_test[new_features] = X_test[feature].str.split(sep, expand=True)
def drop_features(features: list) -> None:
X_train.drop(features, axis=1, inplace=True)
X_test.drop(features, axis=1, inplace=True)
def cast_feature(feature: str, cast: str) -> None:
X_train[feature] = X_train[feature].astype(cast)
X_test[feature] = X_test[feature].astype(cast)
split_feature('PassengerId', ['GroupId', 'IdWithinGroup'], '_')
split_feature('Cabin', ['Deck', 'Num', 'Side'], '/')
drop_features(['Name', 'PassengerId', 'Cabin', 'IdWithinGroup', 'VIP', 'Num'])
for feature in ['GroupId']:
cast_feature(feature, 'float')
Я решил удалить следующие признаки:
- Name (не получится с помощью него заполнить пропуски);
- IdWithinGroup (идентификатор внутри группы, неинформативный);
- Num (не очень понимаю, по какому принципу заполнять пропуски).
На данном графике признаки упорядочены по важности. Можно заметить, что признак VIP практически не влияет на целевую функцию, поэтому исключу его.
Исходный набор данных содержит пропуски:
| Кол-во пропущенных значений | % пропущенных значений |
HomePlanet | 201 | 2.312205 |
CryoSleep | 217 | 2.496261 |
Destination | 182 | 2.093639 |
Age | 179 | 2.059128 |
RoomService | 181 | 2.082135 |
FoodCourt | 183 | 2.105142 |
ShoppingMall | 208 | 2.392730 |
Spa | 183 | 2.105142 |
VRDeck | 188 | 2.162660 |
GroupId | 0 | 0.000000 |
Deck | 199 | 2.289198 |
Side | 199 | 2.289198 |
Закодирую категориальные переменные с помощью one‑hot кодирования:
X_train = pd.get_dummies(X_train)
X_test = pd.get_dummies(X_test)
Обучу модель и проверю результат: Score = 0.79 261 (топ 1262).
Улучшить результат можно несколькими способами. Например,
- подкрутить параметры модели;
- проанализировать данные и попробовать увидеть зависимости. Заполнить пустые значения, чтобы не потерять информацию.
Для начала попробую заполнить пустые значения, не проводя анализ признаков. Для категориальных признаков заполню пропуски наиболее встречающимся значением, а для числовых признаков заполню пропуски медианами.
from sklearn.impute import SimpleImputer
numerical_columns = X_train.describe().columns
categorical_columns = set(X_train.columns) - set(numerical_columns)
for col in numerical_columns:
si = SimpleImputer(strategy='median')
X_train[col] = si.fit_transform(X_train[col].values.reshape(-1, 1))
X_test[col] = si.fit_transform(X_test[col].values.reshape(-1, 1))
for col in categorical_columns:
si = SimpleImputer(strategy='most_frequent')
X_train[col] = si.fit_transform(X_train[col].values.reshape(-1, 1))
X_test[col] = si.fit_transform(X_test[col].values.reshape(-1, 1))
Проверю результат: Score = 0.79 401. По сравнению с предыдущим — улучшение метрики на 0.0014.
Попробую улучшить результат, проанализировав данные.
Для начала посмотрю на распределения числовых признаков:
Стоит отметить, что методы градиентного бустинга слабо чувствительны к выбросам, поэтому можно оставить данные как есть.
Забегая вперёд, скажу, что для борьбы с аномальными значениями я попытался применить следующие методы:
- Удаление аномальных значений (в результате потерял информацию, из‑за чего значение метрики ухудшилось);
- Замена аномальных значений при помощи расчёта 1.5 межквартильного размаха (IQR) и замены аномальных значений на Q1 – 1.5*IQR и Q3 + 1.5*IQR. (метрика также снизилась).
На графике показано, как с помощью данного метода можно нивелировать выбросы.
После применения логарифмирования распределения признаков стали иметь следующий вид:
Далее посмотрю на значения признаков при CryoSleep = True:
| RoomService | FoodCourt | ShoppingMall | Spa | VRDeck |
count | 2969.0 | 2967.0 | 2941.0 | 2972.0 | 2975.0 |
mean | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
std | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
min | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
25% | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
50% | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
75% | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
max | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
На основании этих утверждений, заполню пропуски в поле CryoSleep:
def impute_cryo_sleep(df: pd.DataFrame) -> None:
df.loc[
((df['RoomService'] == 0.0) | df['RoomService'].isnull()) &
((df['FoodCourt'] == 0.0) | df['FoodCourt'].isnull()) &
((df['ShoppingMall'] == 0.0) | df['ShoppingMall'].isnull()) &
((df['Spa'] == 0.0) | df['Spa'].isnull()) &
((df['VRDeck'] == 0.0) | df['VRDeck'].isnull()) &
(df['CryoSleep'].isnull()),
'CryoSleep'
] = True
df.loc[
((df['RoomService'] > 0.0) |
(df['FoodCourt'] > 0.0) |
(df['ShoppingMall'] > 0.0) |
(df['Spa'] > 0.0) |
(df['VRDeck'] > 0.0)) & (df['CryoSleep'].isnull()),
'CryoSleep'
] = False
impute_cryo_sleep(X_train)
impute_cryo_sleep(X_test)
Посмотрю на данные в разрезе признаков HomePlanet — Deck:
Deck | A | B | C | D | E | F | G | T |
HomePlanet | | | | | | | | |
Earth | 0.0 | 0.0 | 0.0 | 0.0 | 395.0 | 1614.0 | 2498.0 | 0.0 |
Europa | 252.0 | 766.0 | 734.0 | 186.0 | 128.0 | 0.0 | 0.0 | 4.0 |
Mars | 0.0 | 0.0 | 0.0 | 282.0 | 330.0 | 1110.0 | 0.0 | 0.0 |
На основании этих данных заполню пропуски для признака HomePlanet:
def impute_home_planet_by_deck(df: pd.DataFrame) -> None:
df.loc[
(df['Deck'] == 'G') & (df['HomePlanet'].isnull()),
'HomePlanet'
] = 'Earth'
europa_decks = ['A', 'B', 'C', 'T']
df.loc[
(df['Deck'].isin(europa_decks)) & (df['HomePlanet'].isnull()),
'HomePlanet'
] = 'Europa'
impute_home_planet_by_deck(X_train)
impute_home_planet_by_deck(X_test)
Исходя из ранее приведенной таблицы в разрезе HomePlanet – Deck, можно заполнить значения Deck по значению HomePlanet, используя вероятностное распределение:
home_planet_deck = X_train.groupby(
['HomePlanet', 'Deck']
).size().unstack().fillna(0)
earth = home_planet_deck.loc['Earth']
earth_proba = list(earth / sum(earth))
europa = home_planet_deck.loc['Europa']
europa_proba = list(europa / sum(europa))
mars = home_planet_deck.loc['Mars']
mars_proba = list(mars / sum(mars))
decks = X_train['Deck'].unique()
deck_values = sorted(decks[~pd.isnull(decks)])
planet_proba = dict(
zip(['Earth', 'Mars', 'Europa'], [earth_proba, mars_proba, europa_proba])
)
# Idempotence
np.random.seed(0)
def impute_deck_by_home_planet(df: pd.DataFrame) -> None:
for planet in planet_proba.keys():
planet_null_decks_shape = df.loc[
(df['HomePlanet'] == planet) & (df['Deck'].isnull()),
'Deck'
].shape[0]
df.loc[
(df['HomePlanet'] == planet) & (df['Deck'].isnull()),
'Deck'
] = np.random.choice(
deck_values,
planet_null_decks_shape,
p=planet_proba[planet]
)
impute_deck_by_home_planet(X_train)
impute_deck_by_home_planet(X_test)
Посмотрю на распределения возрастов на планетах:
Заполню пропущенные значения признака Age медианными значениями по планетам:
def impute_age_by_planet(df: pd.DataFrame) -> None:
for planet in ['Europa', 'Earth', 'Mars']:
planet_median = df[df['HomePlanet'] == planet]['Age'].median()
df.loc[
(df['Age'].isnull()) & (df['HomePlanet'] == planet),
'Age'
] = planet_median
impute_age_by_planet(X_train)
impute_age_by_planet(X_test)
Проверю результат: Score = 0.79 775. В сравнении с первой попыткой — улучшение на 0.5 процента.
В результате только при помощи разведочного анализа и заполнения пустых значений на его основе удалось добиться улучшения на половину процента. Что, довольно, неплохо, учитывая тот факт, что в таких соревнованиях каждая десятая процента метрики может значительно повысить место в рейтинге.
Попробую улучшить модель при помощи подбора гиперпараметров модели. Для этого воспользуюсь фреймворком Optuna.
Optuna подобрал следующие параметры:
- objective (Функционал ошибки): Logloss
- colsample_bylevel (Процент признаков, используемых при каждом выборе разделения): 0.089
- depth (глубина дерева): 11
- boosting_type (схема бустинга): Ordered
- bootstrap_type (тип бустрапа): Bernoulli
В результате при помощи подбора параметров получилось улучшить значение метрики более чем на один процент и перешагнуть значение итогового Score в 0.80.
Какие идеи для улучшения результата я на данный момент вижу:
- попробовать выделить новые признаки на основе имеющихся;
- попытаться найти закономерности в других признаках;
- попробовать другие ML‑модели.
Как улучшить точность ML-модели используя разведочный анализ
Привет, Хабр! Меня зовут Кирилл Тобола, я Data Scientist и участник профессионального сообщества NTA. Добро пожаловать в год 2912, где ваши DS навыки понадобятся для решения космической...
habr.com