В этой статье я расскажу о том, как я сжимал модель FastText для решения конкретной, локальной задачи, при этом основной целью, было именно то, чтобы результаты не отличались, от результатов исходной модели FastText.
Основная суть примененного мною метода, была в том, чтобы исключить из словаря модели FastText не используемые слова. Так как например модель «wiki_ru», содержит в своем корпусе 1,88 млн слов в словаре, и 2 млн n-грамм токенов, (300 мерных) векторов.
Для решения же локальной задачи, я сократил это количество до 80 тысяч слов, и 100 тысяч нграмм, и тем самым получил практически 80 кратное уменьшение размера модели. При этом решая данную задачу я не хотел уменьшать размерность векторов, и заниматься квантизацией, так как это неминуемо снижает качество, из за потери части несущей информации в векторах от такого сжатия.
Для создания собственного словаря, я воспользовался библиотекой gensim и механизмом тренировки FastText. Да, наверное это не самый лучший способ, но мне он показался достаточно гибки, для решения именно этой задачи, где я мог параметрами вроде min_count управлять размером своего полученного словаря.
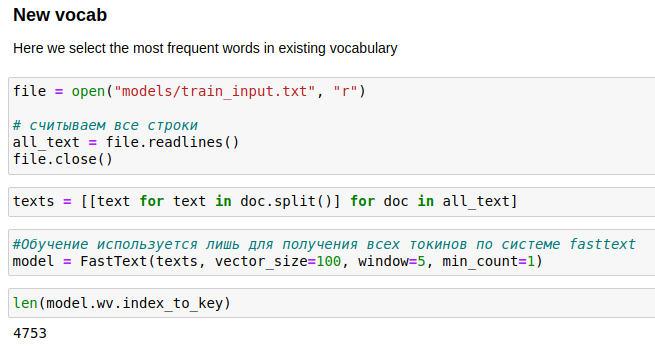
Следующей этапом, я хотел добиться, чтобы полученная модель выдавала аналогичные результаты запроса при похожих слов текста, поэтому кроме слов из своего корпуса, в будущий корпус текста своей модели, я так же добавил слова из TOP 10, похожих слов используя метод most_similar
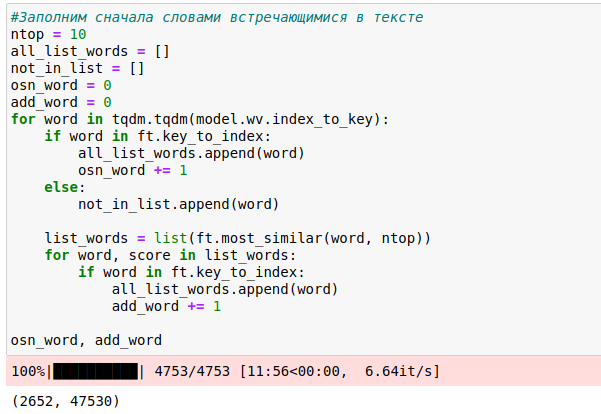
Но вероятно, и этого может показаться мало. Ведь мы знаем, что модель fastText хранит в себе не только слова но и n-граммы слов. Потому, как модель способна разбивать слова на n-граммы и в своей части хранит их в том числе и в словаре. Поэтому следующим этапом, каждое слово из полученного словаря, я разбил на n-граммы слов, и тоже добавил их в наш полученный словарь.

Таким образом я получил общий словарь, в котором получилось 32 тысячи слов и 50 тысяч n-грамм слов из словаря, что в сумме составило 72 тысячи слов. Однако я решил не ограничиваться только этим словарем, и в завершение добавил еще 8000 тысяч слов наиболее часто встречающихся из модели FastText «wiki_ru», как это рекомендуется из вышеуказанной статьи, чтобы модель была более устойчива, в том числе, к новым неизвестным ей словам.
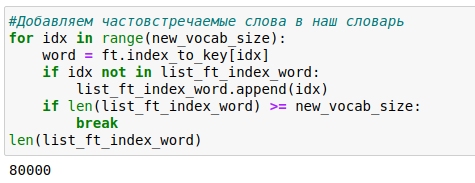
Далее из полученных слов, составлен итоговый словарь. При этом важным являлось, то, чтобы порядок слов не отличался от основной модели. Так как словарь составлен в порядке частоты встречаемости слов.
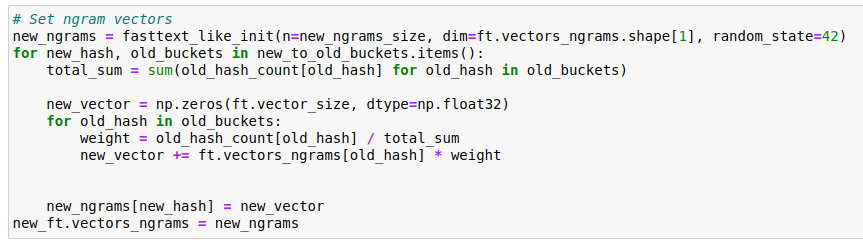
После генерации словаря, важным моментом в настройке новой модели FastText является переупаковка матриц хэшей n-грамм. Метод которой было описан в статье Андреем Васнецовым, в этой статье. Однако данный код так же пришлось немного видоизменить, в связи с обновлением библиотеки gensim.
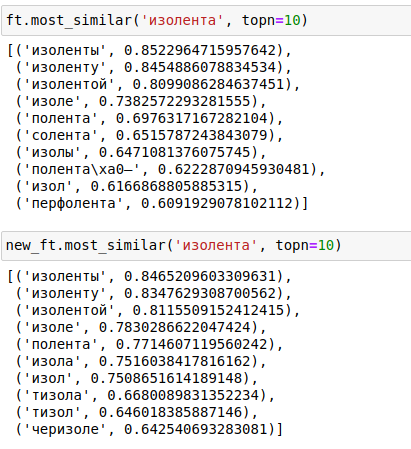
Получение векторных представлений слов, предложений, и таблицы результатов схожести, давали сопоставимые результаты.
Код для сжатия модели и его последующего применения доступен в моем репозитории на GitHub.
 habr.com
habr.com
Основная суть примененного мною метода, была в том, чтобы исключить из словаря модели FastText не используемые слова. Так как например модель «wiki_ru», содержит в своем корпусе 1,88 млн слов в словаре, и 2 млн n-грамм токенов, (300 мерных) векторов.
Для решения же локальной задачи, я сократил это количество до 80 тысяч слов, и 100 тысяч нграмм, и тем самым получил практически 80 кратное уменьшение размера модели. При этом решая данную задачу я не хотел уменьшать размерность векторов, и заниматься квантизацией, так как это неминуемо снижает качество, из за потери части несущей информации в векторах от такого сжатия.
Ход решения
Итак, первое что нужно было сделать, это взять из своего тренировочного корпуса текста список всех слов (токенов), что я собственно и сделал. Мой тренировочный текст хранился в файле train_input.txt.Для создания собственного словаря, я воспользовался библиотекой gensim и механизмом тренировки FastText. Да, наверное это не самый лучший способ, но мне он показался достаточно гибки, для решения именно этой задачи, где я мог параметрами вроде min_count управлять размером своего полученного словаря.
Следующей этапом, я хотел добиться, чтобы полученная модель выдавала аналогичные результаты запроса при похожих слов текста, поэтому кроме слов из своего корпуса, в будущий корпус текста своей модели, я так же добавил слова из TOP 10, похожих слов используя метод most_similar
Но вероятно, и этого может показаться мало. Ведь мы знаем, что модель fastText хранит в себе не только слова но и n-граммы слов. Потому, как модель способна разбивать слова на n-граммы и в своей части хранит их в том числе и в словаре. Поэтому следующим этапом, каждое слово из полученного словаря, я разбил на n-граммы слов, и тоже добавил их в наш полученный словарь.
Таким образом я получил общий словарь, в котором получилось 32 тысячи слов и 50 тысяч n-грамм слов из словаря, что в сумме составило 72 тысячи слов. Однако я решил не ограничиваться только этим словарем, и в завершение добавил еще 8000 тысяч слов наиболее часто встречающихся из модели FastText «wiki_ru», как это рекомендуется из вышеуказанной статьи, чтобы модель была более устойчива, в том числе, к новым неизвестным ей словам.
Далее из полученных слов, составлен итоговый словарь. При этом важным являлось, то, чтобы порядок слов не отличался от основной модели. Так как словарь составлен в порядке частоты встречаемости слов.
После генерации словаря, важным моментом в настройке новой модели FastText является переупаковка матриц хэшей n-грамм. Метод которой было описан в статье Андреем Васнецовым, в этой статье. Однако данный код так же пришлось немного видоизменить, в связи с обновлением библиотеки gensim.
В результате
В результате данных преобразований, мною была получена модель, которая по свои характеристикам для решения поставленной задачи, ни чуть не уступает в качестве предоставленных результатов её родительской модели. Что очень хорошо видно, при составлении запросов most_similar.
Получение векторных представлений слов, предложений, и таблицы результатов схожести, давали сопоставимые результаты.
Код для сжатия модели и его последующего применения доступен в моем репозитории на GitHub.
Как я сжимал модель fastText для реальной задачи в 80 раз в 2021 году
FastText — это отличное решение для предоставления готовых векторных представлений слов, для решения различных задач в области ML и NLP. Но основным недостатком данных моделей является, то что на...
habr.com