Мануалов о том, как парсить при помощи Python полно, как по всему интернету, так и на Хабре, и прежде чем забрасывать меня камнями, сразу оговорюсь, что в теме будет затронут способ с применением ревёрсинга траффика Android-устройства для обнаружения endpoints, по которым можно взять то, что лежит в более приятной форме, нежели получаемое через парсинг HTML-дерева.

Задача следующая: реализовать парсер для товаров великого международного китайского маркетплейса с красным логотипом. Почему-то в моей голове никаких вариантов, кроме Selenium и X-Path на тот момент не появилось. Я написал простую реализацию на библиотеке lxml и движка для тестирования веб-приложений Selenium.
Мне хотелось сделать всё прямо-таки по красоте и поэтому я решил развернуть у себя Selenium Grid используя данный docker-compose файл, предварительно выкинув из него все браузеры кроме Chrome и продублируя instance'ы, чтобы всё работало ещё лучше. В процессе тестирования своего решения было обнаружено, что маркетплейс в некоторых случаях предлагает провести серую стрелочку вправо несколько раз, когда подозревает ваш скрипт в том, что тот является не совсем-то достоверной копией обычного покупателя. Ещё полчаса работы напильником и скрипт отрабатывал в 100 случаях из 100. Но вот проблема - время одного такого парсинга занимала 10-17 секунд, что заставило меня немного погрустить.
Новое решение не заставило себя долго ждать и я обнаружил что маркетплейс использует SSR и вываливает весь JSON в конце своего html.
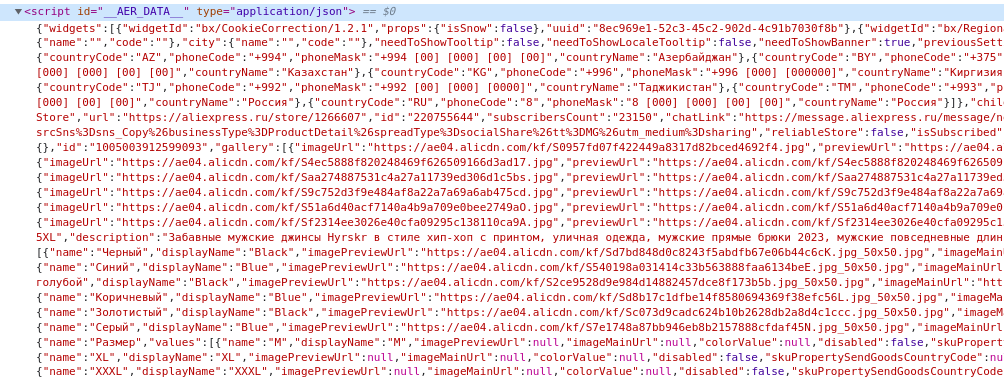
"Вот оно, решение" - подумал я тогда. И побежал выкидывать Selenium, и переписывать всё на requests, не убирая из головы тот факт, что я иногда получал окно капчи, вместо заветной страницы. Для того, чтобы сэкономить я даже попробовал написать парсер, который бы собирал прокси с открытых источников. Я написал для этого специальный класс, но такое решение долго не продержалось и оказалось что эти прокси вообще никаким образом не пригодны к использованию. Я даже написал некоторую абстракцию для работы с такими глубокими деревьями:
Скрытый код для работы с объектами
import re
class DictSearch:
def __init__(self, data: dict):
self.input_item = data
# Для поиска по значению. Можно искать по ключу или значению, а так же с частичным совпадением или нет
def search(
self,
search_value: str,
search_by_key: bool = False,
partial: bool = False
):
results = []
def process(data, path: str):
if not isinstance(data, dict):
return None
for key, value in data.items():
if search_by_key:
if key == search_value:
results.append(f'{path}.{key}')
prefix = '.' if path != '' else ''
if isinstance(value, dict):
process(data.get(key), f'{path}{prefix}{key}')
if isinstance(value, list):
for index, i in enumerate(value):
process(i, f'{path}{prefix}{key}[{index}]')
else:
if partial and isinstance(value, str):
if search_value in value:
results.append(f'{path}{prefix}{key}')
if search_value == value:
results.append(f'{path}{prefix}{key}')
process(self.input_item, '')
return results[0] if len(results) == 1 else results
# Для получения значения по пути вида value.items[0].name
def get_value(self, path: str):
path_iter = path.split('.')
def process(current, item):
lists = re.findall(r'[\d+]+', current)
key = re.findall('[a-zA-Z]+', current)[0]
if len(lists):
return item.get(key)[int(lists[0])]
else:
return item.get(current)
res = self.input_item
for i in path_iter:
res = process(i, res)
return res
# Для того чтобы срезать count глубины с конца пути
@staticmethod
def cut_path(path: str, count: int):
process = path.split('.')[:-count]
return '.'.join(process)
Использовал этот класс я примерно следующим образом:
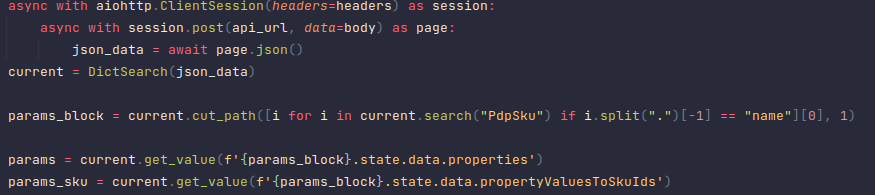
Данное решение проработало не больше недели, потому что мне пришла в голову новая мысль. О ней уже было сказано в предисловии, поэтому повторяться не буду.
Первым делом наткнулся на софтину под названием Charles Proxy. Коротко, суть программы в том, чтобы перехватить весь HTTP трафик устройств, которые указали в качестве proxy-сервера IP-адрес вашего компьютера (делается это в настройках сети). Предварительно необходимо было установить сертификат, для того, чтобы можно было слушать HTTPS трафик. И конкретно с этим пунктом у меня возникли серьёзные проблемы, которые я благополучно решил установив специальный Magisk-модуль на свой Android-девайс. И даже когда всё завелось (в браузере у меня открывались все HTTPS ресурсы), половина приложений всё равно отказывалось "видеть интернет". В поисках решения я наткнулся на программу HTTP Toolkit. Принцип её действия аналогичен предыдущей, только документация к ней по-лучше. С её помощью у меня-таки получилось увидеть нужные урлы и их содержимое. Однако, root на устройстве и в этом случае понадобился для того чтобы поставить сертификат. Инструкция для Android-устройств.
Запрос у меня получился следующего вида:
Секретные данные
Сам URL, который мне удалось достать:

А так же заголовки:
headers = {
'User-Agent': 'ali-android-13-567-8.20.341.823566',
'x-aer-client-type': 'android',
'x-aer-lang': 'en_RU',
'x-aer-currency': 'RUB',
'x-aer-ship-to-country': 'RU',
'x-appkey': 'XXXXXXXX',
'accept': 'application/json',
'x-aer-device-id': 'X0XXxX+Xxx0XXX0XxxXXxx0X'
}
Т.к. это должен был быть POST-запрос, то в теле я отправлял следующее содержимое:
# Здесь доставались нужные циферки из URL детальной страницы товара
body = {
'productId': re.findall(r'\d+.html', url)[0].split('.')[0]
}
На этот запрос, маркетплейс послушно отдавал правильный JSON из которого можно было достать абсолютно всё о выбранном товаре.
Благодаря данному подходу я получил ещё больший прирост в производительности, при этом теперь капчи было намного меньше и соответственно качество прокси больше не имело такого большого значения, а их кол-во можно было уменьшить. Библиотеку lxml я выкинул, сэкономив заветные пару мегабайт на размере зависимостей")
Для загрузки картинок я объединял их в массив и закидывал в asyncio.gather([...]), сэкономив ещё парочку сотен миллисекунд на загрузке данных. Так же, как было видно выше, я использую библиотеку aiohttp вместо requests, потому что так быстрее и асинхроннее.
Это статья создана для того, чтобы показать, что необходимо смотреть по сторонам при решении той или иной проблемы, пытаться идти до конца и бороть себя на поиски новых решений, когда что-то внутри подсказывает, что код работает не идеально. Это очень интересно!

 habr.com
habr.com
Задача следующая: реализовать парсер для товаров великого международного китайского маркетплейса с красным логотипом. Почему-то в моей голове никаких вариантов, кроме Selenium и X-Path на тот момент не появилось. Я написал простую реализацию на библиотеке lxml и движка для тестирования веб-приложений Selenium.
Мне хотелось сделать всё прямо-таки по красоте и поэтому я решил развернуть у себя Selenium Grid используя данный docker-compose файл, предварительно выкинув из него все браузеры кроме Chrome и продублируя instance'ы, чтобы всё работало ещё лучше. В процессе тестирования своего решения было обнаружено, что маркетплейс в некоторых случаях предлагает провести серую стрелочку вправо несколько раз, когда подозревает ваш скрипт в том, что тот является не совсем-то достоверной копией обычного покупателя. Ещё полчаса работы напильником и скрипт отрабатывал в 100 случаях из 100. Но вот проблема - время одного такого парсинга занимала 10-17 секунд, что заставило меня немного погрустить.
Новое решение не заставило себя долго ждать и я обнаружил что маркетплейс использует SSR и вываливает весь JSON в конце своего html.
"Вот оно, решение" - подумал я тогда. И побежал выкидывать Selenium, и переписывать всё на requests, не убирая из головы тот факт, что я иногда получал окно капчи, вместо заветной страницы. Для того, чтобы сэкономить я даже попробовал написать парсер, который бы собирал прокси с открытых источников. Я написал для этого специальный класс, но такое решение долго не продержалось и оказалось что эти прокси вообще никаким образом не пригодны к использованию. Я даже написал некоторую абстракцию для работы с такими глубокими деревьями:
Скрытый код для работы с объектами
import re
class DictSearch:
def __init__(self, data: dict):
self.input_item = data
# Для поиска по значению. Можно искать по ключу или значению, а так же с частичным совпадением или нет
def search(
self,
search_value: str,
search_by_key: bool = False,
partial: bool = False
):
results = []
def process(data, path: str):
if not isinstance(data, dict):
return None
for key, value in data.items():
if search_by_key:
if key == search_value:
results.append(f'{path}.{key}')
prefix = '.' if path != '' else ''
if isinstance(value, dict):
process(data.get(key), f'{path}{prefix}{key}')
if isinstance(value, list):
for index, i in enumerate(value):
process(i, f'{path}{prefix}{key}[{index}]')
else:
if partial and isinstance(value, str):
if search_value in value:
results.append(f'{path}{prefix}{key}')
if search_value == value:
results.append(f'{path}{prefix}{key}')
process(self.input_item, '')
return results[0] if len(results) == 1 else results
# Для получения значения по пути вида value.items[0].name
def get_value(self, path: str):
path_iter = path.split('.')
def process(current, item):
lists = re.findall(r'[\d+]+', current)
key = re.findall('[a-zA-Z]+', current)[0]
if len(lists):
return item.get(key)[int(lists[0])]
else:
return item.get(current)
res = self.input_item
for i in path_iter:
res = process(i, res)
return res
# Для того чтобы срезать count глубины с конца пути
@staticmethod
def cut_path(path: str, count: int):
process = path.split('.')[:-count]
return '.'.join(process)
Использовал этот класс я примерно следующим образом:
Плюсы решения:
- объем ресурсов сократился в десятки раз за счёт выкидывания двух контейнеров Chrome и ещё одного Selenium/Hub
- скорость выполнения одного такого запроса уменьшилась в среднем в 5 раз
Минусы:
- пришлось покупать качественные прокси, для того чтобы это хорошо работало
Данное решение проработало не больше недели, потому что мне пришла в голову новая мысль. О ней уже было сказано в предисловии, поэтому повторяться не буду.
Первым делом наткнулся на софтину под названием Charles Proxy. Коротко, суть программы в том, чтобы перехватить весь HTTP трафик устройств, которые указали в качестве proxy-сервера IP-адрес вашего компьютера (делается это в настройках сети). Предварительно необходимо было установить сертификат, для того, чтобы можно было слушать HTTPS трафик. И конкретно с этим пунктом у меня возникли серьёзные проблемы, которые я благополучно решил установив специальный Magisk-модуль на свой Android-девайс. И даже когда всё завелось (в браузере у меня открывались все HTTPS ресурсы), половина приложений всё равно отказывалось "видеть интернет". В поисках решения я наткнулся на программу HTTP Toolkit. Принцип её действия аналогичен предыдущей, только документация к ней по-лучше. С её помощью у меня-таки получилось увидеть нужные урлы и их содержимое. Однако, root на устройстве и в этом случае понадобился для того чтобы поставить сертификат. Инструкция для Android-устройств.
Запрос у меня получился следующего вида:
Секретные данные
Сам URL, который мне удалось достать:
А так же заголовки:
headers = {
'User-Agent': 'ali-android-13-567-8.20.341.823566',
'x-aer-client-type': 'android',
'x-aer-lang': 'en_RU',
'x-aer-currency': 'RUB',
'x-aer-ship-to-country': 'RU',
'x-appkey': 'XXXXXXXX',
'accept': 'application/json',
'x-aer-device-id': 'X0XXxX+Xxx0XXX0XxxXXxx0X'
}
Т.к. это должен был быть POST-запрос, то в теле я отправлял следующее содержимое:
# Здесь доставались нужные циферки из URL детальной страницы товара
body = {
'productId': re.findall(r'\d+.html', url)[0].split('.')[0]
}
На этот запрос, маркетплейс послушно отдавал правильный JSON из которого можно было достать абсолютно всё о выбранном товаре.
Благодаря данному подходу я получил ещё больший прирост в производительности, при этом теперь капчи было намного меньше и соответственно качество прокси больше не имело такого большого значения, а их кол-во можно было уменьшить. Библиотеку lxml я выкинул, сэкономив заветные пару мегабайт на размере зависимостей
Для загрузки картинок я объединял их в массив и закидывал в asyncio.gather([...]), сэкономив ещё парочку сотен миллисекунд на загрузке данных. Так же, как было видно выше, я использую библиотеку aiohttp вместо requests, потому что так быстрее и асинхроннее.
Это статья создана для того, чтобы показать, что необходимо смотреть по сторонам при решении той или иной проблемы, пытаться идти до конца и бороть себя на поиски новых решений, когда что-то внутри подсказывает, что код работает не идеально. Это очень интересно!
От парсинга к Private API. В гонке за производительностью
В статье будет затронут способ с применением ревёрсинга траффика Android-устройства для обнаружения endpoints, по которым можно взять то, что лежит в более приятной форме, нежели получаемое через...
habr.com