
Кому не нравится LINQ в C#? Встроенная и уже достаточно старая фича языка C# и рантайма .NET.
Но можем ли мы сделать более эффективную версию этой фичи?
TL;DR (спойлер)
Можем сделать более эффективную, но намного менее универсальную. Github проекта.
Вкратце о том, как работает LINQ
Почти каждый метод LINQ обертывает предыдущую последовательность в новую (но ничего не делает сам). Например, метод Select создает и возвращает SelectEnumerableIterator. И так каждый метод - на основе предыдущего будет создавать новый итератор.Каждое активное действие - например, foreach - превращается в создание енумератора, который, пока может, делает "шаг" и выдает значение.

Более точно как разворачивается foreach можно проверить на замечательность шарплабе.
Теперь, так как это все - референс типы, то они, конечно, аллоцируются в куче. Более того, это все обмазано виртуальными вызовами, так как MoveNext, конечно, нельзя статически отрезолвить.
Начинаем творить!
Если в обычном LINQ каждый следующий итератор просто хранит поле типа IEnumerable<T> в себе, то у нас каждый следующий енумератор будет хранить всю цепочку итераторов до себя. И я не имею ввиду массив.Вместо этого, все итераторы будут структурами, а каждый следующий итератор будет точно знать тип предыдущего через generic-и. То есть у нас есть итератор TEnumerator, так вот следующий будет иметь один из type argument-ов - TEnumerator.
Для начала - обертка любого енумератора, это то, что будет возвращено любым нашим методом:

Теперь рассмотрим пример структуры, которую будет возвращать метод Select:
")
Тип предыдущего енумератора, а также тип значений им возвращаемый, нам известен. Еще там же передается тип функтора для отображения из типа T в тип U (это сделано для того, чтобы мы могли передавать более эффективные делегаты).
Заметьте, метод Select все так же почти ничего не делает - всего лишь создает структуру!

А значит, что все работает так же лениво, как и в LINQ.
Аналогично делаются другие итераторы. Например, после вызова Where, Select, SelectMany наш итератор будет выглядить примерно как SelectMany<..., Select<..., Where<..., >>>.
Более точно, вот пример вызова Select и Where, обратите внимание на тип переменной seq:

То есть самый "внутренний" тип - это ArrayEnumerator, и он включен в Select, который в свою очередь включен в Where.
Что получилось?
Таким образом, вместо виртуальных типов и методов, которые есть в обычном LINQ, мы создаем по сути новый тип, который отображает именно ту последовательность операций, которую мы хотим!А раз нет виртуальных методов, и нет нужды для референс типов, то все у нас хранится на стеке, а многие методы - заинлайнены, что дает неплохое преимущество по производительности и не производит аллокаций в куче.
Почему же так не сделали сам LINQ?
На самом деле, LINQ куда более универсальный чем то, что мы сделали. Давайте рассмотрим проблемы нашей имплементации.Проблема 1. Копирование неэффективно
Интерфейсы и классы - это референс типы, то есть передавая их туда-сюда мы передаем "указатель" - 4 или 8 байтовое число. А вот чтобы передать наш енумератор, нам придется копировать все его содержимое, все внутренние енумераторы.
Как видно на скрине, нам стоит очень много процессорного времени, чтобы скопировать такую огромную штуку.
Проблема 2. Отсутствие общего интерфейса
В LINQ неважно, какими операциями составлена последовательность - это все равно IEnumerable<T>. Мы можем легко докинуть сверху что-нибудь, если хотим: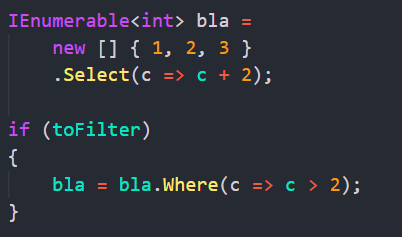
Но это не так в нашем случае. bla.Where вернет тип отличный от bla. Поэтому это невозможно в нашей реализации:

Проблема 3. Не все LINQ методы можно так реализовать
Например, SkipLast использует внутренный буффер для хранения элементов, чтобы посетить каждый элемент не более одного раза.Как такой метод сделать в нашем случае? Я не нашел способа и думаю его нет. Существует stackalloc, конечно, но он валиден только в скоупе, а значит, его придется вызывать пользователю, и, конечно, это обессмысливает все.
Проблема 4. Обжора стека
Помним, что это очень большая структура, особенно если много операций. Поэтому следует измерить количество потребляемой стековой памяти.Используя собственную тулзу CodegenAnalysis, меряю количество статически аллоцируемой стековой памяти:

288 байтов понадобилось всего лишь для двух операций! Для более длинных цепочек это могут быть килобайты (напомню, что это размер самого енумератора - это число не зависит от длины входной последовательности).
Надо ли это кому-то?
Да, но далеко не всем. Это может быть полезно геймдевам (кто хочет сэкономить на аллокациях в куче), системным разработчикам (опять же, вдруг вы хотите использовать LINQ на микроконтроллере), ну или просто тем, у кого именно такие юзкейсы.На самом деле, я не изобрел принципиально нового. До меня уже написали целый ряд похожих библиотек: NoAlloq, LinqFaster, Hyperlinq, ValueLinq, LinqAF, StructLinq. Немного разные, но идея та же.
Вывод
Я реализовал все и только те методы, которые могут быть сделаны без аллокаций в куче (и безобразного API). В секции Benchmarks можно увидеть сравнение с другими библиотеками по эффективности.Github проекта тут.
Таким образом, такая реализация не имеет виртуальных вызовов и аллокаций в куче и не имеет оверхеда с стейт-машинами, написанными вручную (но вручную написанные всякие for-ы все равно будут эффективнее).
Но у нее есть куча недостатков: отсутствие общего интерфейса, не все методы так можно сделать, дорогое копирование, и так далее.
LINQ все так же актуален. Заменить его можно лишь в некоторых нишевых ситуациях, где подобные библиотеки будут более эффективны.
Спасибо за внимание! Мой github/WhiteBlackGoose.
(для анализа эффективности использую BenchmarkDotNet и CodegenAnalysis)

Как LINQ, только быстрый и без аллокаций
Кому не нравится LINQ в C#? Встроенная и уже достаточно старая фича языка C# и рантайма .NET. Но можем ли мы сделать более эффективную версию этой фичи? TL;DR (спойлер) Можем сделать более...
 habr.com
habr.com