Не так часто удается написать что-то интересное про проблемы, связанные с параллельным программированием. В этот же раз "повезло". Из-за особенностей реализации стандартного метода TraceEvent произошла ошибка с блокировкой нескольких потоков. Хочется предупредить о существующем нюансе и рассказать об интересном случае из поддержки наших пользователей. Причем тут поддержка? Это вы узнаете из статьи. Приятного чтения.

Стандартный сценарий работы данной Windows утилиты очень простой, всего 3 шага:
И вот в один прекрасный момент описанный сценарий не заработал, анализ просто-напросто не запустился. Ну и чтобы было поинтереснее, возникла эта проблема не у нас, а у пользователя, который обратился к нам в поддержку. У него стабильно после запуска анализа происходило десятиминутное ожидание ответа от сервера с дальнейшим выходом из программы по timeout'у. В чём причина – непонятно. Проблема не воспроизводится. Да... беда. Пришлось запросить дампфайл для процесса нашей утилиты, чтобы посмотреть, что там происходит внутри.
Примечание. Проблема у пользователя возникла при использовании Windows утилиты CLMonitor.exe. Поэтому все дальнейшие примеры будут актуальны именно для Windows.
Весь исходный код, который вы здесь видите, был взят из мини проекта, симулирующего работу утилиты. Я его сделал специально для вас, чтобы было понагляднее. Весь исходный код приведен в конце статьи.
Поэтому, для того чтобы можно было использовать PVS-Studio независимо сборочной системы, даже самой экзотической, у нас и появилась утилита CLMonitor.exe. Она отслеживает все процессы во время сборки проекта и отлавливает вызовы компиляторов. А уже из вызовов компиляторов мы получаем всю необходимую информацию для дальнейшего препроцессирования и анализа. Теперь вы знаете, зачем нам нужно мониторить процессы.
С помощью класса *ServiceHost *создается именованный канал, по которому будет происходить обмен сообщениями между процессами клиента и сервера. Вот как это выглядит на стороне сервера:
static ErrorLevels PerformMonitoring(....)
{
using (ServiceHost host = new ServiceHost(
typeof(CLMonitoringContract),
new Uri[]{new Uri(PipeCredentials.PipeRoot)}))
{
....
host.AddServiceEndpoint(typeof(ICLMonitoringContract),
pipe,
PipeCredentials.PipeName);
host.Open();
....
}
}
Обратите тут внимание на две вещи: *CLMonitoringContract *и ICLMonitoringContract.
*ICLMonitoringContract *– это сервисный контракт. *CLMonitoringContract *– реализация сервисного контракта. Выглядит это так:
[ServiceContract(SessionMode = SessionMode.Required,
CallbackContract = typeof(ICLMonitoringContractCallback))]
interface ICLMonitoringContract
{
[OperationContract]
void StopMonitoring(string dumpPath = null);
}
[ServiceBehavior(InstanceContextMode = InstanceContextMode.Single)]
class CLMonitoringContract : ICLMonitoringContract
{
public void StopMonitoring(string dumpPath = null)
{
....
CLMonitoringServer.CompilerMonitor.StopMonitoring(dumpPath);
}
}
Когда мы запускаем клиент, нам нужно остановить работу сервера и забрать у него все необходимые данные. Благодаря данному интерфейсу мы это и делаем. Вот как выглядит остановка сервера со стороны клиента:
public void FinishMonitor()
{
CLMonitoringContractCallback сallback = new CLMonitoringContractCallback();
var pipeFactory = new DuplexChannelFactory<ICLMonitoringContract>(
сallback,
pipe,
new EndpointAddress(....));
ICLMonitoringContract pipeProxy = pipeFactory.CreateChannel();
((IContextChannel)pipeProxy).OperationTimeout = new TimeSpan(24, 0, 0);
((IContextChannel)pipeProxy).Faulted += CLMonitoringServer_Faulted;
pipeProxy.StopMonitoring(dumpPath);
}
Когда клиент выполняет метод StopMonitoring, он на самом деле выполняется у сервера и вызывает его остановку. А клиент получает данные для запуска анализа.
Всё, теперь вы, хоть немного, имеете представление о внутренней работе утилиты CLMonitor.exe.

**Интересный факт. **Откуда вообще взялись эти 10 минут? Дело в том, что мы задаем время ожидания ответа от сервера намного больше, а именно - 24 часа, как видно в примере кода, приведённом выше. Однако для некоторых операций фреймворк сам решает, что это слишком много и он успеет быстрее. Поэтому берет только часть от изначального значения.
Мы попросили у пользователя снять дамп с двух процессов (клиент и сервер) минуток через 5 после запуска клиента, чтобы посмотреть, что там происходит.
Тут небольшая пауза. Хочется быть честным по отношению к моему коллеге Павлу и упомянуть, что это именно он разобрался в данной проблеме. Я же ее просто чинил, ну и вот сейчас описываю") Конец паузы.
Конец паузы.
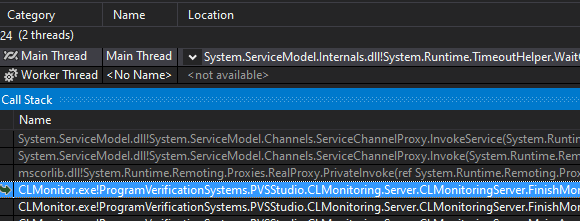
Нас интересует главный поток. Он висит на методе, отвечающем за запрос остановки сервера:
public void FinishMonitor()
{
....
ICLMonitoringContract pipeProxy = pipeFactory.CreateChannel();
((IContextChannel)pipeProxy).OperationTimeout = new TimeSpan(24, 0, 0);
((IContextChannel)pipeProxy).Faulted += CLMonitoringServer_Faulted;
pipeProxy.StopMonitoring(dumpPath); // <=
....
}
Получается, что клиент попросил сервер завершить работу, а ответа не последовало. И это странное поведение, так как обычно данная операция занимает доли секунды. А я напомню, что в данном случае дамп был снят спустя 5 минут от начала работы клиента. Что ж, давайте смотреть, что там на сервере происходит.

Воу-воу, откуда так много TraceEvent'ов? Кстати, на скриншоте не уместилось, но всего их более 50. Ну давайте подумаем. Данный метод у нас используется, чтобы логировать различную информацию. Например, если отловленный процесс является компилятором, который не поддерживается, произошла ошибка считывания какого-либо параметра процесса и т.д. Посмотрев стеки данных потоков, мы выяснили, что все они ведут в один и тот же метод в нашем коде. А метод этот смотрит, является ли отловленный нашей утилитой процесс компилятором или это нечто иное и неинтересное, и, если мы отловили такой неинтересный процесс, мы это логируем.
Получается, что у пользователя запускается очень много процессов, которые, конкретно для нас, являются 'мусором'. Ну допустим, что это так. Однако данная картина все равно выглядит очень подозрительно. Почему же таких потоков так много? Ведь, по идее, логирование должно происходить быстро. Очень похоже на то, что все эти потоки висят на какой-то точке синхронизации или критической секции и чего-то ждут. Давайте зайдем на ReferenceSource и посмотрим исходный код метода TraceEvent.
Открываем исходники и действительно видим в методе TraceEvent оператор lock:

Мы предположили, что из-за постоянной синхронизации и логирования накапливается большое количество вызовов методов TraceEvent, ждущих освобождения TraceInternal.critSec. Хм, ну допустим. Однако это пока не объясняет, почему сервер не может ответить клиенту. Посмотрим еще раз в дамп файл сервера и заметим один одинокий поток, который висит на методе DiagnosticsConfiguration.Initialize:

В данный метод мы попадаем из метода NegotiateStream.AuthenticateAsServer, выполняющего проверку подлинности со стороны сервера в соединении клиент-сервер:

В нашем случае клиент-серверное взаимодействие происходит с помощью WCF. Плюс напоминаю, что клиент ждет ответ от сервера. По этому стеку очень похоже, что метод DiagnosticsConfiguration.Initialize был вызван при запросе от клиента и теперь висит и ждет. Хм... а давайте-ка зайдем в его исходный код:

И тут мы замечаем, что в данном методе имеется критическая секция, да еще и на ту же самую переменную. Посмотрев, что вообще такое этот critSec, увидим следующее:

Собственно, у нас уже есть достаточно информации, чтобы подвести итоги.
Интересный факт. Изучая просторы интернета в поисках информации про данную проблему с TraceEvent была обнаружена интересная тема на GitHub. Она немного о другом, но есть один занимательный комментарий от сотрудника компании Microsoft:
"Also one of the locks, TraceInternal.critSec, is only present if the TraceListener asks for it. Generally speaking such 'global' locks are not a good idea for a high performance logging system (indeed we don't recommend TraceSource for high performance logging at all, it is really there only for compatibility reasons)".
Получается, что команда Microsoft не рекомендует использовать компонент трассировки выполнения кода для высоконагруженных систем, но при этом сама использует его в своём IPC фреймфорке, который, казалось бы, должен быть надёжным и устойчивым к большим нагрузкам...
Важно тут то, что объект в *критической секции *является статической переменной. Из-за этого ошибка будет повторяться до тех пор, пока экземпляры логгеров существуют в одном процессе. При этом неважно, что и у нас, и внутри WCF используются разные экземпляры логгеров – казалось бы, независимые друг от друга объекты создают взаимную блокировку из-за статической переменной в критической секции.
Теперь остается только воспроизвести и починить проблему.
private void CrazyLogging()
{
for (var i = 0; i < 30; i++)
{
var j = i;
new Thread(new ThreadStart(() =>
{
while (!Program.isStopMonitor)
Logger.TraceEvent(TraceEventType.Error, 0, j.ToString());
})).Start();
}
}
За работу сервера у нас отвечает метод Trace, поэтому добавляем наше логирование в него. Например, вот сюда:
public void Trace()
{
ListenersInitialization();
CrazyLogging();
....
}
Готово. Запускаем сервер (я буду это делать с помощью Visual Studio 2019), приостанавливаем секунд через 5 процесс и смотрим что у нас там с потоками:

Отлично! Теперь запускаем клиент (TestTraceSource.exe analyze), который должен установить связь с сервером и остановить его работу.
Запустив, мы увидим, что анализ не начинается. Поэтому опять останавливаем потоки в Visual Studio и видим ту же самую картину из дамп файла сервера. А именно – появился поток, который висит на методе DiagnosticsConfiguration.Initialize. Проблема воспроизведена.
Как же её чинить? Ну для начала стоит сказать, что TraceSource – это класс, который предоставляет набор методов и свойств, позволяющих приложениям делать трассировку выполнения кода и связывать сообщения трассировки с их источником. Используем мы его потому, что сервер может быть запущен не приаттаченным к консоли, и консольное логирование будет бессмысленно. В этом случае мы логировали всё в Event'ы операционной системы с помощью метода TraceSource.TraceEvent.
Проблему мы "решили" следующим образом. По умолчанию теперь вся информация логируется в консоль, используя метод Console.WriteLine. В большинстве случаев, даже если эта логируемая информация и будет потеряна из-за не приаттаченной консоли, она всё равно не требуется для решения задач в работе утилиты, а проблема исчезла. Плюс изменения заняли какие-то минуты. Однако мы оставили возможность старого способа логирования с помощью специального флага enableLogger.
Чтобы запустить имитирование работы сервера, запустите .exe с флагом trace. Чтобы запустить клиент, воспользуйтесь флагом analyze.
**Примечание: **количество потоков в методе CrazyLogging следует подбирать индивидуально. Если проблема у вас не воспроизводится, то попробуйте поиграться с этим значением. Также можете запустить данный проект в Visual Studio в режиме отладки.
Точка входа в программу:
using System.Linq;
namespace TestTraceSource
{
class Program
{
public static bool isStopMonitor = false;
static void Main(string[] args)
{
if (!args.Any())
return;
if (args[0] == "trace")
{
Server server = new Server();
server.Trace();
}
if (args[0] == "analyze")
{
Client client = new Client();
client.FinishMonitor();
}
}
}
}
Сервер:
using System;
using System.Diagnostics;
using System.ServiceModel;
using System.Threading;
namespace TestTraceSource
{
class Server
{
private static TraceSource Logger;
public void Trace()
{
ListenersInitialization();
CrazyLogging();
using (ServiceHost host = new ServiceHost(
typeof(TestTraceContract),
new Uri[]{new Uri(PipeCredentials.PipeRoot)}))
{
host.AddServiceEndpoint(typeof(IContract),
new NetNamedPipeBinding(),
PipeCredentials.PipeName);
host.Open();
while (!Program.isStopMonitor)
{
// We catch all processes, process them, and so on
}
host.Close();
}
Console.WriteLine("Complited.");
}
private void ListenersInitialization()
{
Logger = new TraceSource("PVS-Studio CLMonitoring");
Logger.Switch.Level = SourceLevels.Verbose;
Logger.Listeners.Add(new ConsoleTraceListener());
String EventSourceName = "PVS-Studio CL Monitoring";
EventLog log = new EventLog();
log.Source = EventSourceName;
Logger.Listeners.Add(new EventLogTraceListener(log));
}
private void CrazyLogging()
{
for (var i = 0; i < 30; i++)
{
var j = i;
new Thread(new ThreadStart(() =>
{
var start = DateTime.Now;
while (!Program.isStopMonitor)
Logger.TraceEvent(TraceEventType.Error, 0, j.ToString());
})).Start();
}
}
}
}
Клиент:
using System;
using System.ServiceModel;
namespace TestTraceSource
{
class Client
{
public void FinishMonitor()
{
TestTraceContractCallback сallback = new TestTraceContractCallback();
var pipeFactory = new DuplexChannelFactory<IContract>(
сallback,
new NetNamedPipeBinding(),
new EndpointAddress(PipeCredentials.PipeRoot
+ PipeCredentials.PipeName));
IContract pipeProxy = pipeFactory.CreateChannel();
pipeProxy.StopServer();
Console.WriteLine("Complited.");
}
}
}
Прокси:
using System;
using System.ServiceModel;
namespace TestTraceSource
{
class PipeCredentials
{
public const String PipeName = "PipeCLMonitoring";
public const String PipeRoot = "net.pipe://localhost/";
public const long MaxMessageSize = 500 * 1024 * 1024; //bytes
}
class TestTraceContractCallback : IContractCallback
{
public void JobComplete()
{
Console.WriteLine("Job Completed.");
}
}
[ServiceContract(SessionMode = SessionMode.Required,
CallbackContract = typeof(IContractCallback))]
interface IContract
{
[OperationContract]
void StopServer();
}
interface IContractCallback
{
[OperationContract(IsOneWay = true)]
void JobComplete();
}
[ServiceBehavior(InstanceContextMode = InstanceContextMode.Single)]
class TestTraceContract : IContract
{
public void StopServer()
{
Program.isStopMonitor = true;
}
}
}
Источник статьи: https://habr.com/ru/company/pvs-studio/blog/563832/
Предыстория
В дистрибутиве PVS-Studio есть одна утилита под названием CLMonitor.exe, или система мониторинга компиляции. Она предназначена для "бесшовной" интеграции статического анализа PVS-Studio для языков C и C++ в любую сборочную систему. Сборочная система должна использовать для сборки файлов один из компиляторов, поддерживаемых анализатором PVS-Studio. Например: gcc, clang, cl, и т.п.Стандартный сценарий работы данной Windows утилиты очень простой, всего 3 шага:
- Выполняем 'CLMonitor.exe monitor';
- Выполняем сборку проекта;
- Выполняем 'CLMonitor.exe analyze'.
И вот в один прекрасный момент описанный сценарий не заработал, анализ просто-напросто не запустился. Ну и чтобы было поинтереснее, возникла эта проблема не у нас, а у пользователя, который обратился к нам в поддержку. У него стабильно после запуска анализа происходило десятиминутное ожидание ответа от сервера с дальнейшим выходом из программы по timeout'у. В чём причина – непонятно. Проблема не воспроизводится. Да... беда. Пришлось запросить дампфайл для процесса нашей утилиты, чтобы посмотреть, что там происходит внутри.
Примечание. Проблема у пользователя возникла при использовании Windows утилиты CLMonitor.exe. Поэтому все дальнейшие примеры будут актуальны именно для Windows.
Как работает CLMonitor.exe
Чтобы лучше понять все мои дальнейшие рассуждения о проблеме пользователя, я советую не пропускать данный пункт. Здесь я расскажу о том, как происходит взаимодействие клиента и сервера.Весь исходный код, который вы здесь видите, был взят из мини проекта, симулирующего работу утилиты. Я его сделал специально для вас, чтобы было понагляднее. Весь исходный код приведен в конце статьи.
Зачем мы вообще отлавливаем процессы
Как вы поняли, история начинается с того, что нужно запустить сервер, который будет отлавливать все процессы. Делаем мы это не просто так. Вообще, более удобный способ проанализировать C++ проект — это прямой запуск анализатора через утилиту командной строки PVS-Studio_Cmd. У неё, однако, есть существенное ограничение – она может проверять только проекты для Visual Studio. Дело в том, что для анализа требуется вызывать компилятор, чтобы он препроцессировал проверяемые исходные файлы, – ведь анализатор работает именно с препроцессированными файлами. А чтобы вызвать препроцессор, нужно знать:- какой конкретно компилятор вызывать;
- какой файл препроцессировать;
- параметры препроцессирования.
Поэтому, для того чтобы можно было использовать PVS-Studio независимо сборочной системы, даже самой экзотической, у нас и появилась утилита CLMonitor.exe. Она отслеживает все процессы во время сборки проекта и отлавливает вызовы компиляторов. А уже из вызовов компиляторов мы получаем всю необходимую информацию для дальнейшего препроцессирования и анализа. Теперь вы знаете, зачем нам нужно мониторить процессы.
Как клиент запускает анализ
Для обмена данными между сервером и клиентом мы используем программный фреймворк WCF (Windows Communication Foundation). Давайте далее кратко опишем, как мы с ним работаем.С помощью класса *ServiceHost *создается именованный канал, по которому будет происходить обмен сообщениями между процессами клиента и сервера. Вот как это выглядит на стороне сервера:
static ErrorLevels PerformMonitoring(....)
{
using (ServiceHost host = new ServiceHost(
typeof(CLMonitoringContract),
new Uri[]{new Uri(PipeCredentials.PipeRoot)}))
{
....
host.AddServiceEndpoint(typeof(ICLMonitoringContract),
pipe,
PipeCredentials.PipeName);
host.Open();
....
}
}
Обратите тут внимание на две вещи: *CLMonitoringContract *и ICLMonitoringContract.
*ICLMonitoringContract *– это сервисный контракт. *CLMonitoringContract *– реализация сервисного контракта. Выглядит это так:
[ServiceContract(SessionMode = SessionMode.Required,
CallbackContract = typeof(ICLMonitoringContractCallback))]
interface ICLMonitoringContract
{
[OperationContract]
void StopMonitoring(string dumpPath = null);
}
[ServiceBehavior(InstanceContextMode = InstanceContextMode.Single)]
class CLMonitoringContract : ICLMonitoringContract
{
public void StopMonitoring(string dumpPath = null)
{
....
CLMonitoringServer.CompilerMonitor.StopMonitoring(dumpPath);
}
}
Когда мы запускаем клиент, нам нужно остановить работу сервера и забрать у него все необходимые данные. Благодаря данному интерфейсу мы это и делаем. Вот как выглядит остановка сервера со стороны клиента:
public void FinishMonitor()
{
CLMonitoringContractCallback сallback = new CLMonitoringContractCallback();
var pipeFactory = new DuplexChannelFactory<ICLMonitoringContract>(
сallback,
pipe,
new EndpointAddress(....));
ICLMonitoringContract pipeProxy = pipeFactory.CreateChannel();
((IContextChannel)pipeProxy).OperationTimeout = new TimeSpan(24, 0, 0);
((IContextChannel)pipeProxy).Faulted += CLMonitoringServer_Faulted;
pipeProxy.StopMonitoring(dumpPath);
}
Когда клиент выполняет метод StopMonitoring, он на самом деле выполняется у сервера и вызывает его остановку. А клиент получает данные для запуска анализа.
Всё, теперь вы, хоть немного, имеете представление о внутренней работе утилиты CLMonitor.exe.
Просмотр дамп файла и осознание проблемы
Возвращаемся к нашим баранам. Мы остановились на том, что пользователь отправил нам дамп файлы процессов. Напомню, что у пользователя происходило зависание при попытке запустить анализ – процессы клиента и сервера оставались висеть, закрытия сервера не происходило. Плюс ровно через 10 минут выводилось такое сообщение:
**Интересный факт. **Откуда вообще взялись эти 10 минут? Дело в том, что мы задаем время ожидания ответа от сервера намного больше, а именно - 24 часа, как видно в примере кода, приведённом выше. Однако для некоторых операций фреймворк сам решает, что это слишком много и он успеет быстрее. Поэтому берет только часть от изначального значения.
Мы попросили у пользователя снять дамп с двух процессов (клиент и сервер) минуток через 5 после запуска клиента, чтобы посмотреть, что там происходит.
Тут небольшая пауза. Хочется быть честным по отношению к моему коллеге Павлу и упомянуть, что это именно он разобрался в данной проблеме. Я же ее просто чинил, ну и вот сейчас описываю
Конец паузы.Дамп 'клиента'
Так вот, когда мы открыли дамп файл клиента, перед глазами предстал следующий список потоков:
Нас интересует главный поток. Он висит на методе, отвечающем за запрос остановки сервера:
public void FinishMonitor()
{
....
ICLMonitoringContract pipeProxy = pipeFactory.CreateChannel();
((IContextChannel)pipeProxy).OperationTimeout = new TimeSpan(24, 0, 0);
((IContextChannel)pipeProxy).Faulted += CLMonitoringServer_Faulted;
pipeProxy.StopMonitoring(dumpPath); // <=
....
}
Получается, что клиент попросил сервер завершить работу, а ответа не последовало. И это странное поведение, так как обычно данная операция занимает доли секунды. А я напомню, что в данном случае дамп был снят спустя 5 минут от начала работы клиента. Что ж, давайте смотреть, что там на сервере происходит.
Дамп 'сервера'
Открываем его и видим следующий список потоков:
Воу-воу, откуда так много TraceEvent'ов? Кстати, на скриншоте не уместилось, но всего их более 50. Ну давайте подумаем. Данный метод у нас используется, чтобы логировать различную информацию. Например, если отловленный процесс является компилятором, который не поддерживается, произошла ошибка считывания какого-либо параметра процесса и т.д. Посмотрев стеки данных потоков, мы выяснили, что все они ведут в один и тот же метод в нашем коде. А метод этот смотрит, является ли отловленный нашей утилитой процесс компилятором или это нечто иное и неинтересное, и, если мы отловили такой неинтересный процесс, мы это логируем.
Получается, что у пользователя запускается очень много процессов, которые, конкретно для нас, являются 'мусором'. Ну допустим, что это так. Однако данная картина все равно выглядит очень подозрительно. Почему же таких потоков так много? Ведь, по идее, логирование должно происходить быстро. Очень похоже на то, что все эти потоки висят на какой-то точке синхронизации или критической секции и чего-то ждут. Давайте зайдем на ReferenceSource и посмотрим исходный код метода TraceEvent.
Открываем исходники и действительно видим в методе TraceEvent оператор lock:
Мы предположили, что из-за постоянной синхронизации и логирования накапливается большое количество вызовов методов TraceEvent, ждущих освобождения TraceInternal.critSec. Хм, ну допустим. Однако это пока не объясняет, почему сервер не может ответить клиенту. Посмотрим еще раз в дамп файл сервера и заметим один одинокий поток, который висит на методе DiagnosticsConfiguration.Initialize:
В данный метод мы попадаем из метода NegotiateStream.AuthenticateAsServer, выполняющего проверку подлинности со стороны сервера в соединении клиент-сервер:
В нашем случае клиент-серверное взаимодействие происходит с помощью WCF. Плюс напоминаю, что клиент ждет ответ от сервера. По этому стеку очень похоже, что метод DiagnosticsConfiguration.Initialize был вызван при запросе от клиента и теперь висит и ждет. Хм... а давайте-ка зайдем в его исходный код:
И тут мы замечаем, что в данном методе имеется критическая секция, да еще и на ту же самую переменную. Посмотрев, что вообще такое этот critSec, увидим следующее:
Собственно, у нас уже есть достаточно информации, чтобы подвести итоги.
Интересный факт. Изучая просторы интернета в поисках информации про данную проблему с TraceEvent была обнаружена интересная тема на GitHub. Она немного о другом, но есть один занимательный комментарий от сотрудника компании Microsoft:
"Also one of the locks, TraceInternal.critSec, is only present if the TraceListener asks for it. Generally speaking such 'global' locks are not a good idea for a high performance logging system (indeed we don't recommend TraceSource for high performance logging at all, it is really there only for compatibility reasons)".
Получается, что команда Microsoft не рекомендует использовать компонент трассировки выполнения кода для высоконагруженных систем, но при этом сама использует его в своём IPC фреймфорке, который, казалось бы, должен быть надёжным и устойчивым к большим нагрузкам...
Итоги изучения дампов
Итак, что мы имеем:- Клиент общается с сервером с помощью фреймворка WCF.
- Клиент не может получить ответа от сервера. После 10 минут ожидания он падает по тайм-ауту.
- На сервере висит множество потоков на методе TraceEvent и всего один - на Initialize.
- Оба метода зависят от одной и той же переменной в критической секции, притом это статическое поле.
- Потоки, в которых выполняется метод TraceEvent, бесконечно появляются и из-за lock не могут быстро сделать свое дело и исчезнуть. Тем самым они долго не отпускают объект в lock.
- Метод Initialize возникает при попытке клиента завершить работу сервера и висит бесконечно на lock.
Важно тут то, что объект в *критической секции *является статической переменной. Из-за этого ошибка будет повторяться до тех пор, пока экземпляры логгеров существуют в одном процессе. При этом неважно, что и у нас, и внутри WCF используются разные экземпляры логгеров – казалось бы, независимые друг от друга объекты создают взаимную блокировку из-за статической переменной в критической секции.
Теперь остается только воспроизвести и починить проблему.
Воспроизведение проблемы
Само воспроизведение получается крайне простое. Все, что нам нужно, это сделать так, чтобы сервер постоянно что-то логировал. Потому создаем метод с говорящим названием CrazyLogging, который и будет это делать:private void CrazyLogging()
{
for (var i = 0; i < 30; i++)
{
var j = i;
new Thread(new ThreadStart(() =>
{
while (!Program.isStopMonitor)
Logger.TraceEvent(TraceEventType.Error, 0, j.ToString());
})).Start();
}
}
За работу сервера у нас отвечает метод Trace, поэтому добавляем наше логирование в него. Например, вот сюда:
public void Trace()
{
ListenersInitialization();
CrazyLogging();
....
}
Готово. Запускаем сервер (я буду это делать с помощью Visual Studio 2019), приостанавливаем секунд через 5 процесс и смотрим что у нас там с потоками:
Отлично! Теперь запускаем клиент (TestTraceSource.exe analyze), который должен установить связь с сервером и остановить его работу.
Запустив, мы увидим, что анализ не начинается. Поэтому опять останавливаем потоки в Visual Studio и видим ту же самую картину из дамп файла сервера. А именно – появился поток, который висит на методе DiagnosticsConfiguration.Initialize. Проблема воспроизведена.
Как же её чинить? Ну для начала стоит сказать, что TraceSource – это класс, который предоставляет набор методов и свойств, позволяющих приложениям делать трассировку выполнения кода и связывать сообщения трассировки с их источником. Используем мы его потому, что сервер может быть запущен не приаттаченным к консоли, и консольное логирование будет бессмысленно. В этом случае мы логировали всё в Event'ы операционной системы с помощью метода TraceSource.TraceEvent.
Проблему мы "решили" следующим образом. По умолчанию теперь вся информация логируется в консоль, используя метод Console.WriteLine. В большинстве случаев, даже если эта логируемая информация и будет потеряна из-за не приаттаченной консоли, она всё равно не требуется для решения задач в работе утилиты, а проблема исчезла. Плюс изменения заняли какие-то минуты. Однако мы оставили возможность старого способа логирования с помощью специального флага enableLogger.
Код, воспроизводящий проблему
Здесь я просто привожу весь исходный код, для того чтобы вы могли наглядно у себя попробовать воспроизвести проблему.Чтобы запустить имитирование работы сервера, запустите .exe с флагом trace. Чтобы запустить клиент, воспользуйтесь флагом analyze.
**Примечание: **количество потоков в методе CrazyLogging следует подбирать индивидуально. Если проблема у вас не воспроизводится, то попробуйте поиграться с этим значением. Также можете запустить данный проект в Visual Studio в режиме отладки.
Точка входа в программу:
using System.Linq;
namespace TestTraceSource
{
class Program
{
public static bool isStopMonitor = false;
static void Main(string[] args)
{
if (!args.Any())
return;
if (args[0] == "trace")
{
Server server = new Server();
server.Trace();
}
if (args[0] == "analyze")
{
Client client = new Client();
client.FinishMonitor();
}
}
}
}
Сервер:
using System;
using System.Diagnostics;
using System.ServiceModel;
using System.Threading;
namespace TestTraceSource
{
class Server
{
private static TraceSource Logger;
public void Trace()
{
ListenersInitialization();
CrazyLogging();
using (ServiceHost host = new ServiceHost(
typeof(TestTraceContract),
new Uri[]{new Uri(PipeCredentials.PipeRoot)}))
{
host.AddServiceEndpoint(typeof(IContract),
new NetNamedPipeBinding(),
PipeCredentials.PipeName);
host.Open();
while (!Program.isStopMonitor)
{
// We catch all processes, process them, and so on
}
host.Close();
}
Console.WriteLine("Complited.");
}
private void ListenersInitialization()
{
Logger = new TraceSource("PVS-Studio CLMonitoring");
Logger.Switch.Level = SourceLevels.Verbose;
Logger.Listeners.Add(new ConsoleTraceListener());
String EventSourceName = "PVS-Studio CL Monitoring";
EventLog log = new EventLog();
log.Source = EventSourceName;
Logger.Listeners.Add(new EventLogTraceListener(log));
}
private void CrazyLogging()
{
for (var i = 0; i < 30; i++)
{
var j = i;
new Thread(new ThreadStart(() =>
{
var start = DateTime.Now;
while (!Program.isStopMonitor)
Logger.TraceEvent(TraceEventType.Error, 0, j.ToString());
})).Start();
}
}
}
}
Клиент:
using System;
using System.ServiceModel;
namespace TestTraceSource
{
class Client
{
public void FinishMonitor()
{
TestTraceContractCallback сallback = new TestTraceContractCallback();
var pipeFactory = new DuplexChannelFactory<IContract>(
сallback,
new NetNamedPipeBinding(),
new EndpointAddress(PipeCredentials.PipeRoot
+ PipeCredentials.PipeName));
IContract pipeProxy = pipeFactory.CreateChannel();
pipeProxy.StopServer();
Console.WriteLine("Complited.");
}
}
}
Прокси:
using System;
using System.ServiceModel;
namespace TestTraceSource
{
class PipeCredentials
{
public const String PipeName = "PipeCLMonitoring";
public const String PipeRoot = "net.pipe://localhost/";
public const long MaxMessageSize = 500 * 1024 * 1024; //bytes
}
class TestTraceContractCallback : IContractCallback
{
public void JobComplete()
{
Console.WriteLine("Job Completed.");
}
}
[ServiceContract(SessionMode = SessionMode.Required,
CallbackContract = typeof(IContractCallback))]
interface IContract
{
[OperationContract]
void StopServer();
}
interface IContractCallback
{
[OperationContract(IsOneWay = true)]
void JobComplete();
}
[ServiceBehavior(InstanceContextMode = InstanceContextMode.Single)]
class TestTraceContract : IContract
{
public void StopServer()
{
Program.isStopMonitor = true;
}
}
}
Вывод
Будьте осторожны со стандартным методом TraceSource.TraceEvent. Если у вас теоретически возможно частое использование данного метода в программе, то вы можете столкнуться с подобной проблемой. Особенно если у вас высоконагруженная система. Сами разработчики в таком случае не рекомендуют использовать всё, что связано с классом TraceSource. Если вы уже сталкивались с чем-то подобным, то не стесняйтесь рассказать об этом в комментариях.Источник статьи: https://habr.com/ru/company/pvs-studio/blog/563832/