С чего началась наша компания? В первую очередь, конечно, с людей и с идеи. Как это обычно бывает, правильные люди абсолютно случайно познакомились друг с другом, и вот я здесь, сижу и пишу этот пост =) Была, однако, и ещё одна очень важная составляющая - данные...
Любой ML-проект начинается с анализа ландшафта доступных данных - что мы можем скачать, выгрузить, разметить, купить. За четыре года наша культура работы с данными, инструментарий, подходы, процесс разметки претерпели очень большие изменения. Сейчас у нас накоплено почти 100 терабайт медицинских исследований, но количество данных абсолютно не важно, если они плохого качества, и их неудобно изучать, понимать и использовать. Недавно я делал обзорный доклад про разные аспекты качества медицинских данных, а вот наше выступление про технические аспекты пути к качеству. Сегодня же я хочу поговорить об очень интересной концепции (или даже философии), которая в последнее время на слуху, но, судя по разным постам в интернете, её суть понятна далеко не всем. Это Data Mesh.
Впервые я столкнулся с этим понятием в докладе Леруа Мерлен на митапе LeanDS. Доклад любопытный, но суть дата меш мне из него была понятна не до конца, так что недавно я взялся за чтение книги от авторки этой концепции и термина - Data Mesh: Devlivering Data-Driven Value at Scale.
Книга мне очень понравилась - она концептуальная, почти не затрагивает конкретные инструменты и способы реализации, но раскрывает суть идеи целиком и полностью. Полный конспект я могу скинуть в комментариях, если кого-то заинтересует, а в этом посте я поговорю об основных принципах, моей интерпретации и самых интересных моментах для нашей компании.
 В книге очень прикольные и информативные иллюстрации, лайк
В книге очень прикольные и информативные иллюстрации, лайк
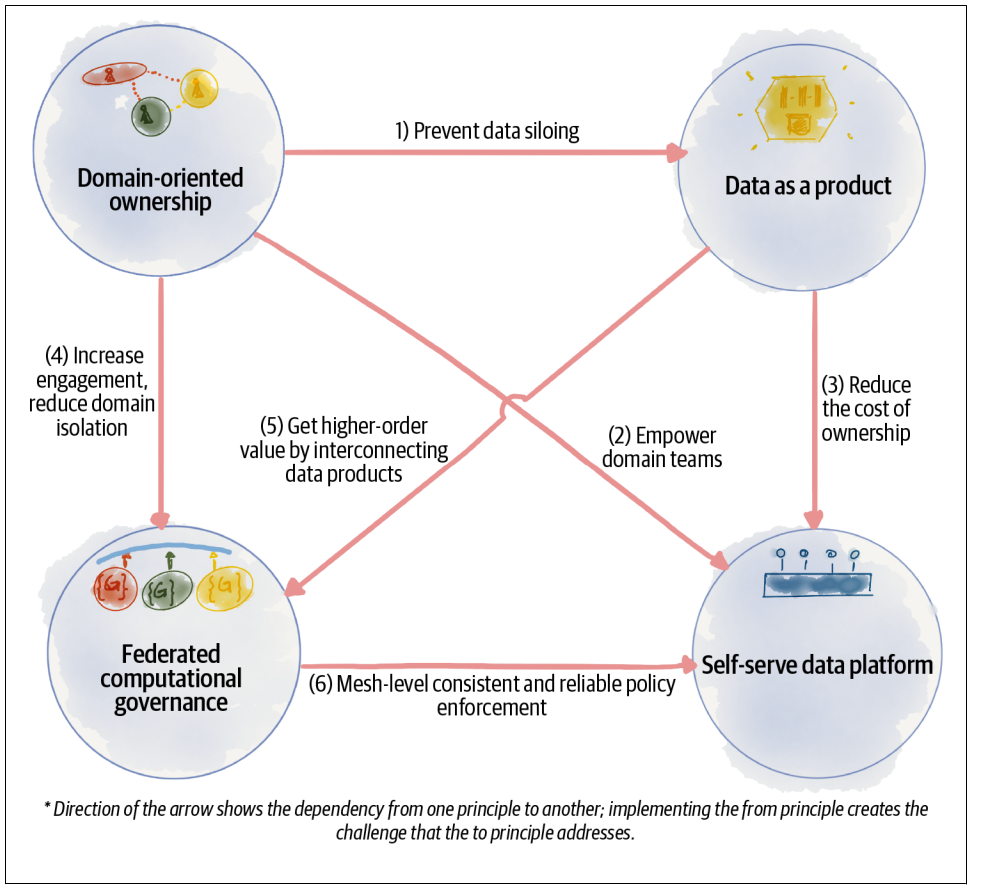
Дата меш родился как ответ на господствующие концепции работы с данными в data-driven организациях - Data Warehouse и Data Lake. Их объединяет идея централизованности. Все данные стекаются в некое центральное хранилище, откуда уже их могут забирать для своих целей разные команды. Безусловно, свои плюсы у этого есть - можно оптимизировать перфоманс, проще устранять дублирование, легко находить нужные данные, ведь они все находятся в одном месте. Но для поддержки всего этого добра нужна выделенная (и обычно немаленькая) команда дата-инженеров с особым набором скиллов, при росте количества источников и разнообразия данных становится всё сложнее обеспечивать их бизнес-качество, пайплайны по трансформации становятся всё сложнее и сложнее. Дата меш предлагает решать эти и другие проблемы на основе четырёх главных принципов:
1) Domain-oriented ownership - данными владеют доменные команды, а не централизованная дата-команда. Домен - это часть организации, выполняющяя определённую бизнес-функцию, например, в нашем случае это могут быть продуктовые домены (маммография, флюорография, КТ органов грудной клетки) или домен по работе с врачами-разметчиками.
2) Data as a product - данные воспринимаются не как статичный датасет, а как динамичный продукт со своими пользователями, метриками качества, бэклогом развития, за которым следит выделенный продакт оунер.
3) Self-serve data platform. Основная функция дата-платформы в дата меш - это устранять лишнюю когнитивную нагрузку. Она позволяет разрабам в доменных командах (data product developers и data product consumers), которые не являются спецами по работе с данными, удобно создавать дата-продукты, билдить, деплоить, тестить, обновлять их, получать к ним доступ и использовать в своих целях.
4) Federated computational governance - вместо централизованного управления данными создаётся специальный федеративный орган, состоящий из представителей доменных команд, дата-платформы и экспертов (например, юристов и врачей), который устанавливает глобальные политики в области работы с данными и обсуждает развитие дата-платформы.
 Упрощённая структура дата-продукта
Упрощённая структура дата-продукта
Да, на разработку и поддержку таких продуктов нужно больше усилий, чем просто на создание какого-то датасета, но он может принести значительно больше ценности. К тому же, дата-платформа как раз и направлена на упрощение процесса разработки и использования дата-продуктов.
Конечно, большинство примеров в книге и сама концепция дата-меш кажется больше ориентированной на крупные бизнесы с большим количеством доменов и большим разнообразием и объемом источников данных, которые генерятся в ходе разных бизнес-операций - например, взаимодействия клиентов с приложением. Тем не менее, многие идеи и подходы, описанные в книге мне кажутся достойными внимания - дата-продукты, доменное владение данными и вообще доменная ориентированность и кросс-функциональность, дата-платформа, федеративная команда, отказ от централизованных пайплайнов, документация и метрики качества, внедренные в сами данные.
1) Размеченные данные. Это наша главная ценность и ресурс. Дата-продукты, предоставляющие размеченные данные, могут быть ответственны за их перевод в нужные форматы, автоматический EDA, фильтрацию плохих данных и агрегацию информации о разметке.
2) Активное обучение. Эти дата-продукты могут реализовывать различные алгоритмы активного обучения и предоставлять команде разметке или ML-командам информацию об актуальности неразмеченных исследований для разных версий моделей.
3) Анализ качества работы врачей. Врачи - тоже люди, они обладают разными компетенциями, могут быть невнимательными или ошибаться. Такой дата-продукт автоматизирует часть работы по анализу качества работы разных разметчиков.
4) Shadow Models. Хорошая практика перед релизом новой версии модели или при сравнении кандидатов на релиз - погонять их на реальных данных с потока и проанализировать нюансы работы. Дата-продукт может автоматически деплоить нужные модели в тестовые среды, генерировать и агрегировать их предсказания.
5) Анализ качества изображений. ML-командам, команде разметки и аналиткам часто нужна информация о качестве самих медицинских изображений. Для их оценки можно использовать специальные ML-модели и эвристики.
В заключение хочу отметить, что я ни в коем случае не претендую на полное понимание дата меш, да и до полноценного внедрения нам ещё плясать и плясать.
 habr.com
habr.com
Любой ML-проект начинается с анализа ландшафта доступных данных - что мы можем скачать, выгрузить, разметить, купить. За четыре года наша культура работы с данными, инструментарий, подходы, процесс разметки претерпели очень большие изменения. Сейчас у нас накоплено почти 100 терабайт медицинских исследований, но количество данных абсолютно не важно, если они плохого качества, и их неудобно изучать, понимать и использовать. Недавно я делал обзорный доклад про разные аспекты качества медицинских данных, а вот наше выступление про технические аспекты пути к качеству. Сегодня же я хочу поговорить об очень интересной концепции (или даже философии), которая в последнее время на слуху, но, судя по разным постам в интернете, её суть понятна далеко не всем. Это Data Mesh.
Впервые я столкнулся с этим понятием в докладе Леруа Мерлен на митапе LeanDS. Доклад любопытный, но суть дата меш мне из него была понятна не до конца, так что недавно я взялся за чтение книги от авторки этой концепции и термина - Data Mesh: Devlivering Data-Driven Value at Scale.
Книга мне очень понравилась - она концептуальная, почти не затрагивает конкретные инструменты и способы реализации, но раскрывает суть идеи целиком и полностью. Полный конспект я могу скинуть в комментариях, если кого-то заинтересует, а в этом посте я поговорю об основных принципах, моей интерпретации и самых интересных моментах для нашей компании.
Основные принципы
Дата меш родился как ответ на господствующие концепции работы с данными в data-driven организациях - Data Warehouse и Data Lake. Их объединяет идея централизованности. Все данные стекаются в некое центральное хранилище, откуда уже их могут забирать для своих целей разные команды. Безусловно, свои плюсы у этого есть - можно оптимизировать перфоманс, проще устранять дублирование, легко находить нужные данные, ведь они все находятся в одном месте. Но для поддержки всего этого добра нужна выделенная (и обычно немаленькая) команда дата-инженеров с особым набором скиллов, при росте количества источников и разнообразия данных становится всё сложнее обеспечивать их бизнес-качество, пайплайны по трансформации становятся всё сложнее и сложнее. Дата меш предлагает решать эти и другие проблемы на основе четырёх главных принципов:
1) Domain-oriented ownership - данными владеют доменные команды, а не централизованная дата-команда. Домен - это часть организации, выполняющяя определённую бизнес-функцию, например, в нашем случае это могут быть продуктовые домены (маммография, флюорография, КТ органов грудной клетки) или домен по работе с врачами-разметчиками.
2) Data as a product - данные воспринимаются не как статичный датасет, а как динамичный продукт со своими пользователями, метриками качества, бэклогом развития, за которым следит выделенный продакт оунер.
3) Self-serve data platform. Основная функция дата-платформы в дата меш - это устранять лишнюю когнитивную нагрузку. Она позволяет разрабам в доменных командах (data product developers и data product consumers), которые не являются спецами по работе с данными, удобно создавать дата-продукты, билдить, деплоить, тестить, обновлять их, получать к ним доступ и использовать в своих целях.
4) Federated computational governance - вместо централизованного управления данными создаётся специальный федеративный орган, состоящий из представителей доменных команд, дата-платформы и экспертов (например, юристов и врачей), который устанавливает глобальные политики в области работы с данными и обсуждает развитие дата-платформы.
Мои мысли
Центральный и самый интересный концепт дата-меш для меня - это дата-продукт. Дата-продукт отличается от обычного датасета динамичностью и автономностью. В отличие от датасета дата-продукт по умолчанию инкапсулирует в себе всё, что нужно для понимания и использования данных:- Трансформационный код. Это может быть простая агрегация данных или сложная ML-модель.
- Источники данных. Дата-продукт трансформирует какие-то данные. Это могут быть данные от приложения или данные от других дата-продуктов. Он может их получать по pull-модели (например, раз в сутки) или асинхронно по мере их появления.
- Разные представления данных. Разные группы пользователей могут хотеть получать доступ к данным в разных формах - это зависит от их целей и компетенций. Например, дата-саентисты хотят датафреймы или JSON-структуры, а аналитики и менеджеры - дашборды и визуализации. За эти представления отвечает сам дата-продукт.
- Дата-тесты. Качество данных невозможно обеспечить без тестов - насколько данные полны, есть ли в них откровенно грязная разметка или технические ошибки.
- Документация. Это может быть текстовое описание, картинки или код с примерами использования.
- API с метриками. Пользователям интересно понимать состояние дата-продукта - когда он последний раз обновлялся, насколько свежие данные он использует, дескриптивные статистики. Дата-продукт предоставляет всю эту информацию с помощью стандартизированного API.
- Декларация необходимых ресурсов. Дата-продукту могут быть нужны особые ресурсы - GPU-инстансы, CPU-инстансы, хранилище и так далее. Разработчикам неохота париться и самим разбираться в нюансах инфраструктуры - за них это делает платформа (похожий подход используется, например, в кубере).
Да, на разработку и поддержку таких продуктов нужно больше усилий, чем просто на создание какого-то датасета, но он может принести значительно больше ценности. К тому же, дата-платформа как раз и направлена на упрощение процесса разработки и использования дата-продуктов.
Конечно, большинство примеров в книге и сама концепция дата-меш кажется больше ориентированной на крупные бизнесы с большим количеством доменов и большим разнообразием и объемом источников данных, которые генерятся в ходе разных бизнес-операций - например, взаимодействия клиентов с приложением. Тем не менее, многие идеи и подходы, описанные в книге мне кажутся достойными внимания - дата-продукты, доменное владение данными и вообще доменная ориентированность и кросс-функциональность, дата-платформа, федеративная команда, отказ от централизованных пайплайнов, документация и метрики качества, внедренные в сами данные.
Примеры дата-продуктов в Цельсе
Некоторые аспекты дата меш с недавних пор у нас уже существуют или находятся в процессе создания - например, федеративная команда с представителями разных доменов, дата-платформа, упрощающая работу с данными, ответственность за качество данных на доменных командах. Какие же дата-продукты мы можем создать на этом фундаменте?1) Размеченные данные. Это наша главная ценность и ресурс. Дата-продукты, предоставляющие размеченные данные, могут быть ответственны за их перевод в нужные форматы, автоматический EDA, фильтрацию плохих данных и агрегацию информации о разметке.
2) Активное обучение. Эти дата-продукты могут реализовывать различные алгоритмы активного обучения и предоставлять команде разметке или ML-командам информацию об актуальности неразмеченных исследований для разных версий моделей.
3) Анализ качества работы врачей. Врачи - тоже люди, они обладают разными компетенциями, могут быть невнимательными или ошибаться. Такой дата-продукт автоматизирует часть работы по анализу качества работы разных разметчиков.
4) Shadow Models. Хорошая практика перед релизом новой версии модели или при сравнении кандидатов на релиз - погонять их на реальных данных с потока и проанализировать нюансы работы. Дата-продукт может автоматически деплоить нужные модели в тестовые среды, генерировать и агрегировать их предсказания.
5) Анализ качества изображений. ML-командам, команде разметки и аналиткам часто нужна информация о качестве самих медицинских изображений. Для их оценки можно использовать специальные ML-модели и эвристики.
В заключение хочу отметить, что я ни в коем случае не претендую на полное понимание дата меш, да и до полноценного внедрения нам ещё плясать и плясать.
Концепция Data Mesh. Принципы, идеи, применение на практике
С чего началась наша компания? В первую очередь, конечно, с людей и с идеи. Как это обычно бывает, правильные люди абсолютно случайно познакомились друг с другом, и вот я здесь, сижу и пишу этот пост...
habr.com