В этой статье вы прочитаете о лучших практиках запуска Java-приложений в Kubernetes. Большинство из этих рекомендаций будут справедливы и для других языков.
Однако я рассматриваю все правила в рамках характеристик Java, а также показываю решения и инструменты, доступные для приложений на базе JVM. Некоторые из этих рекомендаций по Kubernetes навязаны дизайном при использовании самых популярных Java-фреймворков, таких, как Spring Boot или Quarkus.
Я покажу вам, как эффективно использовать их для упрощения жизни разработчиков.
Я много пишу на темы, связанные как с Kubernetes, так и с Java. Вы можете найти много практических примеров в моем блоге. Некоторое время назад я опубликовал статью, похожую на эту, но в основном посвященную лучшим практикам для приложений на основе микросервисов. Вы можете найти ее здесь.
Однако в сообществе ведутся «горячие дискуссии» по этому поводу. Вот интересная статья, в которой не рекомендуется устанавливать какие-либо ограничения на процессор. А вот другая статья, написанная в противовес предыдущей. В них рассматривают ограничения процессора, но мы могли бы также начать аналогичную дискуссию по ограничениям памяти. Особенно в контексте Java-приложений
Однако для управления памятью предложение выглядит совершенно иначе. Давайте прочитаем другую статью — на этот раз об ограничениях и запросах памяти. Вкратце, в ней рекомендуется всегда устанавливать лимит памяти. Более того, лимит должен быть таким же, как и запрос. В контексте Java-приложений также важно, чтобы мы могли ограничивать память с помощью таких параметров JVM, как -Xmx, -XX:MaxMetaspaceSize или -XX:ReservedCodeCacheSize. В любом случае, с точки зрения Kubernetes, под (pod) получает ресурсы, которые он запрашивает. Лимит не имеет к этому никакого отношения.
Все это подводит меня к первой сегодняшней рекомендации — не устанавливайте слишком низкие лимиты. Даже если вы установите лимит на процессор, это не должно повлиять на ваше приложение. Например, как вы, вероятно, знаете, даже если ваше Java-приложение не потребляет много ресурсов процессора при обычной работе, для его быстрого запуска требуется много ресурсов ЦП. Для моего простого приложения Spring Boot , которое подключает MongoDB на Kubernetes, разница между отсутствием лимита и даже 0,5 ядра существенна. Обычно оно запускается менее чем за 10 секунд:

При лимите процессора, установленным на 500 милиядер, он запускается примерно через 30 секунд:

Конечно, мы могли бы привести несколько примеров. Но мы обсудим их также в следующих разделах.
Прежде чем запускать приложение в Kubernetes, необходимо хотя бы измерить, сколько памяти оно потребляет при ожидаемой нагрузке. К счастью, существуют инструменты, которые могут оптимизировать конфигурацию памяти для Java-приложений , запускаемых в контейнерах. Например, Paketo Buildpacks поставляется со встроенным калькулятором памяти. Он рассчитывает флаг -Xmx JVM по формуле Heap = Total Container Memory - Non-Heap - Headroom. С другой стороны, значение Non-Heap вычисляется по следующей формуле: Non-Heap = Direct Memory + Metaspace + Reserved Code Cache + (Thread Stack * Thread Count).
Paketo Buildpacks в настоящее время является опцией по умолчанию для сборки Spring Boot приложений (с помощью команды mvn spring-boot:build-image). Давайте попробуем ее для нашего примера приложения. Предполагая, что мы установим лимит памяти в 512 МБ, она вычислит -Xmx на уровне 130 МБ.

Подходит ли это для моего приложения? Я должен, по крайней мере, выполнить несколько нагрузочных тестов, чтобы проверить, как работает мое приложение при интенсивном трафике. Но еще раз — не устанавливайте слишком низкие лимиты. Например, при лимите 1024M -Xmxравно 650M.

Как видите, мы управляем использование памяти с помощью параметров JVM. Это предотвращает нас от OOM-киллов, описанных в статье, упомянутой в первом разделе. Поэтому установка запроса на том же уровне, что и лимит не имеет особого смысла. Я бы рекомендовал установить его немного выше, чем при обычном использовании, скажем, на 20% больше.
Зонд живучести используется для принятия решения о том, перезапускать контейнер или нет. Если приложение по какой-либо причине недоступно, иногда имеет смысл перезапустить контейнер. С другой стороны, зонд готовности используется для определения того, может ли контейнер обрабатывать входящий трафик. Если под был признан не готовым, он удаляется из балансировщика нагрузки. Отказ зонда готовности не приводит к перезапуску пода. Наиболее типичный зонд живучести или готовности для веб-приложений реализуется через конечную точку HTTP.
Поскольку последующие сбои зонда живучести приводят к перезапуску пода, он не должен проверять доступность интеграций вашего приложения. Такие вещи должны проверяться с помощью зонда готовности.
management:
endpoint:
health:
probes:
enabled: true
Поскольку Spring Boot Actuator предоставляет несколько конечных точек (например, метрики, трассировки), рекомендуется открыть его на порту, отличном от порта по умолчанию (обычно 8080). Конечно, то же правило применимо и к другим популярным Java-фреймворкам. С другой стороны, хорошей практикой является проверка вашего основного порта приложения, особенно в зонде готовности. Поскольку он определяет, готово ли наше приложение обрабатывать входящие запросы, он также должен слушать и основной порт. С зондом живучести все выглядит прямо противоположным образом. Если, допустим, весь пул рабочих потоков занят, я не хочу перезапускать свое приложение. Я просто не хочу получать входящий трафик в течение некоторого времени.
Мы также можем настраивать другие аспекты зондов Kubernetes. Допустим, наше приложение подключается к внешней системе, но мы не проверяем эту интеграцию в нашем зонде готовности. Это не критично и не оказывает прямого влияния на наше операционное состояние. Вот конфигурация, которая позволяет нам включить в зонд только выбранный набор интеграций (1), а также выставлять готовность на основном порту сервера (2).
spring:
application:
name: sample-spring-boot-on-kubernetes
data:
mongodb:
host: ${MONGO_URL}
port: 27017
username: ${MONGO_USERNAME}
password: ${MONGO_PASSWORD}
database: ${MONGO_DATABASE}
authentication-database: admin
management:
endpoint.health:
show-details: always
group:
readiness:
include: mongo # (1)
additional-path: server:/readiness # (2)
probes:
enabled: true
server:
port: 8081
Вряд ли наше приложение способно существовать без каких-либо внешних решений, таких как базы данных, брокеры сообщений или просто другие приложения. При настройке зонда готовности следует тщательно продумать параметры подключения к этой системе. Прежде всего, вы должны рассмотреть ситуацию, когда внешний сервис недоступен. Как вы будете справляться с этим? Я предлагаю уменьшить эти тайм-ауты до меньших значений, как показано ниже.
spring:
application:
name: sample-spring-kotlin-microservice
datasource:
url: jdbc ostgresql://postgres:5432/postgres
ostgresql://postgres:5432/postgres
username: postgres
password: postgres123
hikari:
connection-timeout: 2000
initialization-fail-timeout: 0
jpa:
database-platform: org.hibernate.dialect.PostgreSQLDialect
rabbitmq:
host: rabbitmq
port: 5672
connection-timeout: 2000

Хорошо, давайте рассмотрим, какую альтернативу нам следует выбрать. Различные производители предоставляют несколько вариантов замены. Если вы ищете подробное сравнение между ними, вам следует обратиться на следующий сайт. Там рекомендуется использовать Eclipse Temurin версии 17.
С другой стороны, наиболее популярные инструменты сборки образов, такие как Jib или Cloud Native Buildpacks, автоматически выбирают поставщика за вас. По умолчанию Jib использует Eclipse Temurin, а Paketo Buildpacks использует реализацию Bellsoft Liberica. Конечно, вы можете легко переопределить эти настройки. Я думаю, это может иметь смысл, если вы, например, запускаете свое приложение в среде, соответствующей поставщику JDK, например AWS и Amazon Corretto.
Допустим, мы используем Paketo Buildpacks и Skaffold для развертывания Java-приложений в Kubernetes. Для того чтобы заменить пакет сборки Bellsoft Liberica по умолчанию на другой, нам просто нужно задать его буквально в разделе пакеты сборки (buildpacks). Ниже приведен пример использования пакета сборки Amazon Corretto.
apiVersion: skaffold/v2beta22
kind: Config
metadata:
name: sample-spring-boot-on-kubernetes
build:
artifacts:
- image: piomin/sample-spring-boot-on-kubernetes
buildpacks:
builder: paketobuildpacks/builder:base
buildpacks:
- paketo-buildpacks/amazon-corretto
- paketo-buildpacks/java
env:
- BP_JVM_VERSION=17
Мы также можем легко протестировать производительность наших приложений для различных поставщиков JDK. Если вы ищете пример такого сравнения, вы можете прочитать мою статью, описывающую такие тесты и результаты. Я измерил различную производительность JDK для приложения Spring Boot 3, которое взаимодействует с базой данных Mongo, используя несколько доступных пакетов сборки Java Paketo.
Java-фреймворки, такие как Quarkus или Micronaut, пытаются решить проблемы, связанные с нативной компиляцией. Например, они избегают использования рефлексии везде, где это возможно. Spring Boot также значительно улучшил поддержку нативной компиляции благодаря проекту Spring Native. Поэтому мой совет в этой области заключается в том, что если вы создаете новое приложение, подготовьте его таким образом, чтобы оно было готово к нативной компиляции. Например, с помощью Quarkus вы можете просто сгенерировать конфигурацию Maven, содержащую специальный профиль для сборки нативного исполняемого файла.
<profiles>
<profile>
<id>native</id>
<activation>
<property>
<name>native</name>
</property>
</activation>
<properties>
<skipITs>false</skipITs>
<quarkus.package.type>native</quarkus.package.type>
</properties>
</profile>
</profiles>
После того, как вы добавите его, вы можете просто собрать нативную сборку с помощью следующей команды:
$ mvn clean package -Pnative
Затем вы можете проанализировать, не возникло ли каких-либо проблем во время сборки. Даже если вы сейчас не запускаете нативные приложения в рабочей среде (например, ваша организация не одобряет это), вам следует включить компиляцию GraalVM в качестве одного из этапов в конвейер приемки. Вы можете легко собрать нативный образ Java для своего приложения с помощью самых популярных фреймворков. Например, для Spring Boot просто вам нужно указать следующую конфигурацию в Maven pom.xml, как показано ниже:
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>build-info</goal>
<goal>build-image</goal>
</goals>
</execution>
</executions>
<configuration>
<image>
<builder>paketobuildpacks/builder:tiny</builder>
<env>
<BP_NATIVE_IMAGE>true</BP_NATIVE_IMAGE>
<BP_NATIVE_IMAGE_BUILD_ARGUMENTS>
--allow-incomplete-classpath
</BP_NATIVE_IMAGE_BUILD_ARGUMENTS>
</env>
</image>
</configuration>
</plugin>
Fluentd — это популярный агрегатор журналов с открытым исходным кодом, который позволяет собирать журналы из кластера Kubernetes, обрабатывать их, а затем отправлять в выбранное вами хранилище данных. Он легко интегрируется с развертываниями Kubernetes. Fluentd пытается структурировать данные в виде JSON, чтобы унифицировать ведение журналов из разных источников и мест назначения. Исходя из этого, вероятно, лучшим способом будет подготовка журналов в этом формате. С форматом JSON мы также можем легко включать дополнительные поля для маркировки журналов с помощью тегов, а затем легко искать их в визуальном инструменте по различным критериям.
Для того чтобы отформатировать наши журналы в формате JSON, читаемом Fluentd, мы можем включить библиотеку Logstash Logback Encoder в зависимости Maven.
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>7.2</version>
</dependency>
Затем нам просто нужно установить по умолчанию вывод журнала в консоль (appender) для нашего приложения Spring Boot в файле logback-spring.xml.
<configuration>
<appender name="consoleAppender" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<logger name="jsonLogger" additivity="false" level="DEBUG">
<appender-ref ref="consoleAppender"/>
</logger>
<root level="INFO">
<appender-ref ref="consoleAppender"/>
</root>
</configuration>
Должны ли мы избегать использования дополнительных выводов для журналов и просто выводить журналы только на стандартный вывод? По моему опыту, ответ - нет. Вы все еще можете использовать альтернативные механизмы для вывода журналов. Особенно, если в вашей организации используется более одного инструмента для сбора логов — например, внутренний стек в Kubernetes и глобальный стек снаружи. Лично я использую инструмент, который помогает мне решать проблемы с производительностью, например, брокер сообщений в качестве прокси. В Spring Boot мы используем для этого RabbitMQ. Просто включите следующий стартер:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
Затем нам просто нужно предоставить аналогичную конфигурацию для вывода (appender) в logback-spring.xml:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<springProperty name="destination" source="app.amqp.url" />
<appender name="AMQP"
class="org.springframework.amqp.rabbit.logback.AmqpAppender">
<layout>
<pattern>
{
"time": "%date{ISO8601}",
"thread": "%thread",
"level": "%level",
"class": "%logger{36}",
"message": "%message"
}
</pattern>
</layout>
<addresses>${destination}</addresses>
<applicationId>api-service</applicationId>
<routingKeyPattern>logs</routingKeyPattern>
<declareExchange>true</declareExchange>
<exchangeName>ex_logstash</exchangeName>
</appender>
<root level="INFO">
<appender-ref ref="AMQP" />
</root>
</configuration>
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-container-image-jib</artifactId>
</dependency>
Затем мы должны включить сборку контейнера, установив для свойства quarkus.container-image.build значение true в файле application.properties. В тестовом классе мы можем использовать аннотации @TestHTTPResource и @TestHTTPEndpoint для внедрения URL-адреса тестового сервера. Затем мы создаем клиента с помощью RestClientBuilder и вызываем сервис, запущенный в контейнере. Название тестового класса неслучайно. Для того чтобы он автоматически определялся как интеграционный тест, он имеет суффикс IT.
@QuarkusIntegrationTest
public class EmployeeControllerIT {
@TestHTTPEndpoint(EmployeeController.class)
@TestHTTPResource
URL url;
@Test
void add() {
EmployeeService service = RestClientBuilder.newBuilder()
.baseUrl(url)
.build(EmployeeService.class);
Employee employee = new Employee(1L, 1L, "Josh Stevens",
23, "Developer");
employee = service.add(employee);
assertNotNull(employee.getId());
}
@Test
public void findAll() {
EmployeeService service = RestClientBuilder.newBuilder()
.baseUrl(url)
.build(EmployeeService.class);
Set<Employee> employees = service.findAll();
assertTrue(employees.size() >= 3);
}
@Test
public void findById() {
EmployeeService service = RestClientBuilder.newBuilder()
.baseUrl(url)
.build(EmployeeService.class);
Employee employee = service.findById(1L);
assertNotNull(employee.getId());
}
}
Более подробно об этом процессе вы можете прочитать в моей предыдущей статье о расширенном тестировании с помощью Quarkus. Конечный эффект виден на рисунке ниже. Когда мы запускаем тесты во время сборки с помощью команды mvn clean verify, наш тест выполняется после сборки образа контейнера.
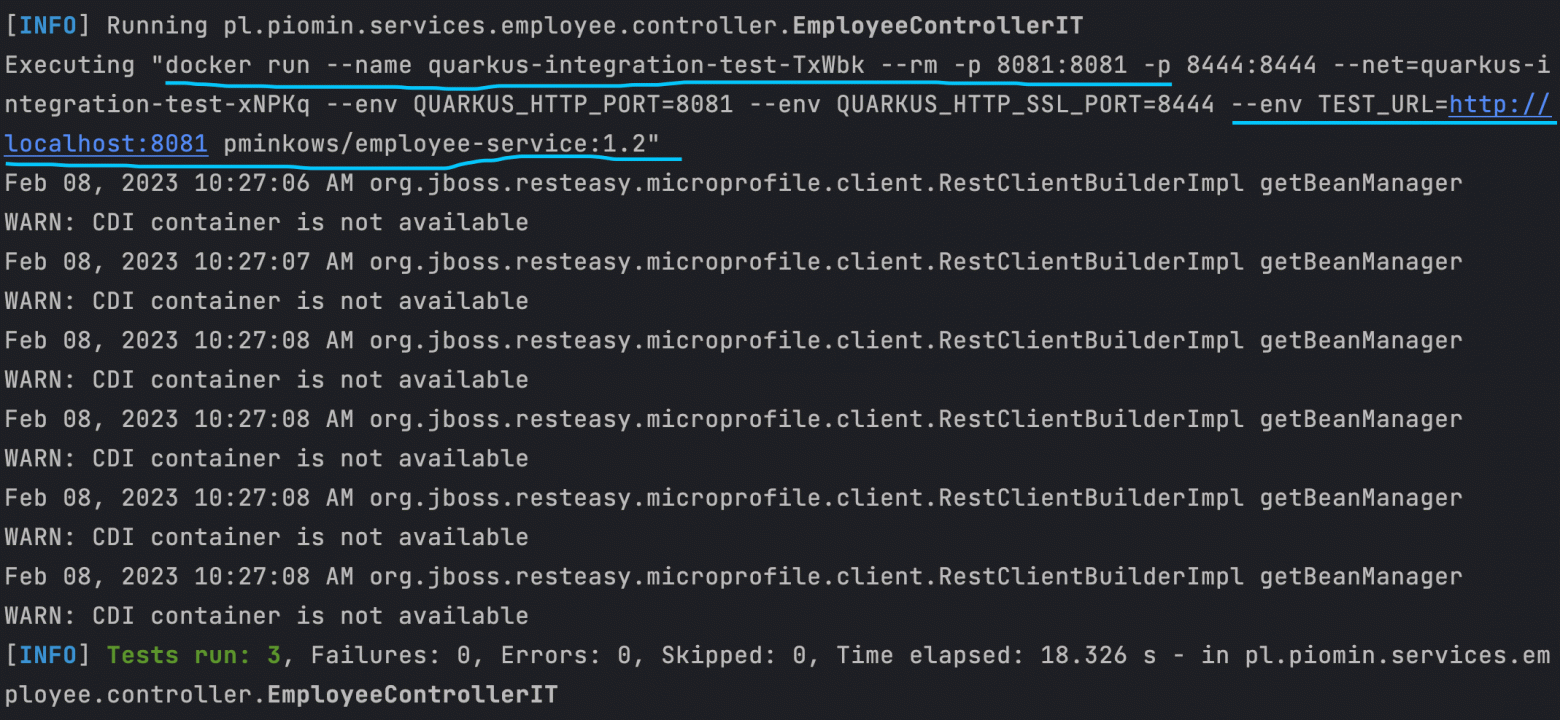
Эта функция Quarkus основана на фреймворке Testcontainers. Мы также можем использовать Testcontainers со Spring Boot. Вот пример теста приложения Spring REST и его интеграции с базой данных PostgreSQL.
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
@Testcontainers
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
public class PersonControllerTests {
@Autowired
TestRestTemplate restTemplate;
@Container
static PostgreSQLContainer<?> postgres =
new PostgreSQLContainer<>("postgres:15.1")
.withExposedPorts(5432);
@DynamicPropertySource
static void registerMySQLProperties(DynamicPropertyRegistry registry) {
registry.add("spring.datasource.url", postgres::getJdbcUrl);
registry.add("spring.datasource.username", postgres::getUsername);
registry.add("spring.datasource.password", postgres::getPassword);
}
@Test
@Order(1)
void add() {
Person person = Instancio.of(Person.class)
.ignore(Select.field("id"))
.create();
person = restTemplate.postForObject("/persons", person, Person.class);
Assertions.assertNotNull(person);
Assertions.assertNotNull(person.getId());
}
@Test
@Order(2)
void updateAndGet() {
final Integer id = 1;
Person person = Instancio.of(Person.class)
.set(Select.field("id"), id)
.create();
restTemplate.put("/persons", person);
Person updated = restTemplate.getForObject("/persons/{id}", Person.class, id);
Assertions.assertNotNull(updated);
Assertions.assertNotNull(updated.getId());
Assertions.assertEquals(id, updated.getId());
}
}

 habr.com
habr.com
Однако я рассматриваю все правила в рамках характеристик Java, а также показываю решения и инструменты, доступные для приложений на базе JVM. Некоторые из этих рекомендаций по Kubernetes навязаны дизайном при использовании самых популярных Java-фреймворков, таких, как Spring Boot или Quarkus.
Я покажу вам, как эффективно использовать их для упрощения жизни разработчиков.
Я много пишу на темы, связанные как с Kubernetes, так и с Java. Вы можете найти много практических примеров в моем блоге. Некоторое время назад я опубликовал статью, похожую на эту, но в основном посвященную лучшим практикам для приложений на основе микросервисов. Вы можете найти ее здесь.
Не устанавливайте слишком низкие лимиты
Нужно ли устанавливать лимиты для приложений Java в Kubernetes или нет? Ответ кажется очевидным. Существует множество инструментов, которые проверяют ваши YAML-манифесты Kubernetes, и наверняка они выведут предупреждение, если вы не установите ограничения процессора или памяти.Однако в сообществе ведутся «горячие дискуссии» по этому поводу. Вот интересная статья, в которой не рекомендуется устанавливать какие-либо ограничения на процессор. А вот другая статья, написанная в противовес предыдущей. В них рассматривают ограничения процессора, но мы могли бы также начать аналогичную дискуссию по ограничениям памяти. Особенно в контексте Java-приложений
Однако для управления памятью предложение выглядит совершенно иначе. Давайте прочитаем другую статью — на этот раз об ограничениях и запросах памяти. Вкратце, в ней рекомендуется всегда устанавливать лимит памяти. Более того, лимит должен быть таким же, как и запрос. В контексте Java-приложений также важно, чтобы мы могли ограничивать память с помощью таких параметров JVM, как -Xmx, -XX:MaxMetaspaceSize или -XX:ReservedCodeCacheSize. В любом случае, с точки зрения Kubernetes, под (pod) получает ресурсы, которые он запрашивает. Лимит не имеет к этому никакого отношения.
Все это подводит меня к первой сегодняшней рекомендации — не устанавливайте слишком низкие лимиты. Даже если вы установите лимит на процессор, это не должно повлиять на ваше приложение. Например, как вы, вероятно, знаете, даже если ваше Java-приложение не потребляет много ресурсов процессора при обычной работе, для его быстрого запуска требуется много ресурсов ЦП. Для моего простого приложения Spring Boot , которое подключает MongoDB на Kubernetes, разница между отсутствием лимита и даже 0,5 ядра существенна. Обычно оно запускается менее чем за 10 секунд:
При лимите процессора, установленным на 500 милиядер, он запускается примерно через 30 секунд:
Конечно, мы могли бы привести несколько примеров. Но мы обсудим их также в следующих разделах.
Сначала рассмотрим использование памяти
Давайте сосредоточимся только на лимите памяти. Если вы запускаете приложение Java-приложение на Kubernetes, у вас есть два уровня ограничения максимального использования: контейнер и JVM. Однако есть и некоторые настройки по умолчанию, если вы не укажете никаких параметров для JVM. JVM устанавливает максимальный размер кучи примерно в 25% доступной оперативной памяти, если вы не задали параметр -Xmx. Это значение рассчитывается на основе памяти, видимой внутри контейнера. Если вы не зададите ограничение на уровне контейнера, JVM будет видеть всю память узла.Прежде чем запускать приложение в Kubernetes, необходимо хотя бы измерить, сколько памяти оно потребляет при ожидаемой нагрузке. К счастью, существуют инструменты, которые могут оптимизировать конфигурацию памяти для Java-приложений , запускаемых в контейнерах. Например, Paketo Buildpacks поставляется со встроенным калькулятором памяти. Он рассчитывает флаг -Xmx JVM по формуле Heap = Total Container Memory - Non-Heap - Headroom. С другой стороны, значение Non-Heap вычисляется по следующей формуле: Non-Heap = Direct Memory + Metaspace + Reserved Code Cache + (Thread Stack * Thread Count).
Paketo Buildpacks в настоящее время является опцией по умолчанию для сборки Spring Boot приложений (с помощью команды mvn spring-boot:build-image). Давайте попробуем ее для нашего примера приложения. Предполагая, что мы установим лимит памяти в 512 МБ, она вычислит -Xmx на уровне 130 МБ.
Подходит ли это для моего приложения? Я должен, по крайней мере, выполнить несколько нагрузочных тестов, чтобы проверить, как работает мое приложение при интенсивном трафике. Но еще раз — не устанавливайте слишком низкие лимиты. Например, при лимите 1024M -Xmxравно 650M.
Как видите, мы управляем использование памяти с помощью параметров JVM. Это предотвращает нас от OOM-киллов, описанных в статье, упомянутой в первом разделе. Поэтому установка запроса на том же уровне, что и лимит не имеет особого смысла. Я бы рекомендовал установить его немного выше, чем при обычном использовании, скажем, на 20% больше.
Правильные зонды живучести и готовности
Введение
Очень важно понимать разницу между зондами живучести и готовности в Kubernetes. Если оба этих зонда реализованы неаккуратно, они могут ухудшить общую работу сервиса, например, вызывая ненужные перезапуски. Третий тип зонда, зонд запуска, является относительно новой функцией в Kubernetes. Он позволяет нам избежать установки initialDelaySeconds для зондов живости или готовности и поэтому особенно полезен, если запуск вашего приложения занимает много времени. Для получения более подробной информации о зондах Kubernetes в целом и лучших практиках могу порекомендовать эту очень интересную статью.Зонд живучести используется для принятия решения о том, перезапускать контейнер или нет. Если приложение по какой-либо причине недоступно, иногда имеет смысл перезапустить контейнер. С другой стороны, зонд готовности используется для определения того, может ли контейнер обрабатывать входящий трафик. Если под был признан не готовым, он удаляется из балансировщика нагрузки. Отказ зонда готовности не приводит к перезапуску пода. Наиболее типичный зонд живучести или готовности для веб-приложений реализуется через конечную точку HTTP.
Поскольку последующие сбои зонда живучести приводят к перезапуску пода, он не должен проверять доступность интеграций вашего приложения. Такие вещи должны проверяться с помощью зонда готовности.
Детали конфигурации
Хорошей новостью является то, что самые популярные Java-фреймворки, такие как Spring Boot или Quarkus, предоставляют автоконфигурируемую реализацию обоих зондов Kubernetes. Они следуют лучшим практикам, поэтому нам обычно не приходится задумываться об основах. Однако в Spring Boot помимо включения модуля Actuator вам необходимо включить их с помощью следующего свойства:management:
endpoint:
health:
probes:
enabled: true
Поскольку Spring Boot Actuator предоставляет несколько конечных точек (например, метрики, трассировки), рекомендуется открыть его на порту, отличном от порта по умолчанию (обычно 8080). Конечно, то же правило применимо и к другим популярным Java-фреймворкам. С другой стороны, хорошей практикой является проверка вашего основного порта приложения, особенно в зонде готовности. Поскольку он определяет, готово ли наше приложение обрабатывать входящие запросы, он также должен слушать и основной порт. С зондом живучести все выглядит прямо противоположным образом. Если, допустим, весь пул рабочих потоков занят, я не хочу перезапускать свое приложение. Я просто не хочу получать входящий трафик в течение некоторого времени.
Мы также можем настраивать другие аспекты зондов Kubernetes. Допустим, наше приложение подключается к внешней системе, но мы не проверяем эту интеграцию в нашем зонде готовности. Это не критично и не оказывает прямого влияния на наше операционное состояние. Вот конфигурация, которая позволяет нам включить в зонд только выбранный набор интеграций (1), а также выставлять готовность на основном порту сервера (2).
spring:
application:
name: sample-spring-boot-on-kubernetes
data:
mongodb:
host: ${MONGO_URL}
port: 27017
username: ${MONGO_USERNAME}
password: ${MONGO_PASSWORD}
database: ${MONGO_DATABASE}
authentication-database: admin
management:
endpoint.health:
show-details: always
group:
readiness:
include: mongo # (1)
additional-path: server:/readiness # (2)
probes:
enabled: true
server:
port: 8081
Вряд ли наше приложение способно существовать без каких-либо внешних решений, таких как базы данных, брокеры сообщений или просто другие приложения. При настройке зонда готовности следует тщательно продумать параметры подключения к этой системе. Прежде всего, вы должны рассмотреть ситуацию, когда внешний сервис недоступен. Как вы будете справляться с этим? Я предлагаю уменьшить эти тайм-ауты до меньших значений, как показано ниже.
spring:
application:
name: sample-spring-kotlin-microservice
datasource:
url: jdbc
ostgresql://postgres:5432/postgresusername: postgres
password: postgres123
hikari:
connection-timeout: 2000
initialization-fail-timeout: 0
jpa:
database-platform: org.hibernate.dialect.PostgreSQLDialect
rabbitmq:
host: rabbitmq
port: 5672
connection-timeout: 2000
Выберите правильный JDK
Если вы уже создали образы с помощью Dockerfile, возможно, вы использовали официальный базовый образ OpenJDK из Docker Hub. Однако в настоящее время в объявлении на сайте изображений говорится, что он официально устарел, и все пользователи должны найти подходящие замены. Я полагаю, что ситуация может быть довольно запутанной, так что подробное объяснение причин вы можете найти здесь.
Хорошо, давайте рассмотрим, какую альтернативу нам следует выбрать. Различные производители предоставляют несколько вариантов замены. Если вы ищете подробное сравнение между ними, вам следует обратиться на следующий сайт. Там рекомендуется использовать Eclipse Temurin версии 17.
С другой стороны, наиболее популярные инструменты сборки образов, такие как Jib или Cloud Native Buildpacks, автоматически выбирают поставщика за вас. По умолчанию Jib использует Eclipse Temurin, а Paketo Buildpacks использует реализацию Bellsoft Liberica. Конечно, вы можете легко переопределить эти настройки. Я думаю, это может иметь смысл, если вы, например, запускаете свое приложение в среде, соответствующей поставщику JDK, например AWS и Amazon Corretto.
Допустим, мы используем Paketo Buildpacks и Skaffold для развертывания Java-приложений в Kubernetes. Для того чтобы заменить пакет сборки Bellsoft Liberica по умолчанию на другой, нам просто нужно задать его буквально в разделе пакеты сборки (buildpacks). Ниже приведен пример использования пакета сборки Amazon Corretto.
apiVersion: skaffold/v2beta22
kind: Config
metadata:
name: sample-spring-boot-on-kubernetes
build:
artifacts:
- image: piomin/sample-spring-boot-on-kubernetes
buildpacks:
builder: paketobuildpacks/builder:base
buildpacks:
- paketo-buildpacks/amazon-corretto
- paketo-buildpacks/java
env:
- BP_JVM_VERSION=17
Мы также можем легко протестировать производительность наших приложений для различных поставщиков JDK. Если вы ищете пример такого сравнения, вы можете прочитать мою статью, описывающую такие тесты и результаты. Я измерил различную производительность JDK для приложения Spring Boot 3, которое взаимодействует с базой данных Mongo, используя несколько доступных пакетов сборки Java Paketo.
Рассмотрите возможность перехода на нативную компиляцию
Нативная компиляция — это настоящий прорыв в мире Java. Но могу поспорить, что немногие из вас используют его, особенно в продакшене. Конечно, существовали (и все еще существуют) многочисленные проблемы при переходе существующих приложений на нативную компиляцию. Статический анализ кода, выполняемый GraalVM во время сборки, может привести к таким ошибкам типа ClassNotFound, или MethodNotFound. Чтобы преодолеть эти проблемы, нам нужно предоставить несколько подсказок, чтобы сообщить GraalVM о динамических элементах кода. Количество этих подсказок обычно зависит от количества библиотек и общего количества языковых функций, используемых в приложении.Java-фреймворки, такие как Quarkus или Micronaut, пытаются решить проблемы, связанные с нативной компиляцией. Например, они избегают использования рефлексии везде, где это возможно. Spring Boot также значительно улучшил поддержку нативной компиляции благодаря проекту Spring Native. Поэтому мой совет в этой области заключается в том, что если вы создаете новое приложение, подготовьте его таким образом, чтобы оно было готово к нативной компиляции. Например, с помощью Quarkus вы можете просто сгенерировать конфигурацию Maven, содержащую специальный профиль для сборки нативного исполняемого файла.
<profiles>
<profile>
<id>native</id>
<activation>
<property>
<name>native</name>
</property>
</activation>
<properties>
<skipITs>false</skipITs>
<quarkus.package.type>native</quarkus.package.type>
</properties>
</profile>
</profiles>
После того, как вы добавите его, вы можете просто собрать нативную сборку с помощью следующей команды:
$ mvn clean package -Pnative
Затем вы можете проанализировать, не возникло ли каких-либо проблем во время сборки. Даже если вы сейчас не запускаете нативные приложения в рабочей среде (например, ваша организация не одобряет это), вам следует включить компиляцию GraalVM в качестве одного из этапов в конвейер приемки. Вы можете легко собрать нативный образ Java для своего приложения с помощью самых популярных фреймворков. Например, для Spring Boot просто вам нужно указать следующую конфигурацию в Maven pom.xml, как показано ниже:
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<executions>
<execution>
<goals>
<goal>build-info</goal>
<goal>build-image</goal>
</goals>
</execution>
</executions>
<configuration>
<image>
<builder>paketobuildpacks/builder:tiny</builder>
<env>
<BP_NATIVE_IMAGE>true</BP_NATIVE_IMAGE>
<BP_NATIVE_IMAGE_BUILD_ARGUMENTS>
--allow-incomplete-classpath
</BP_NATIVE_IMAGE_BUILD_ARGUMENTS>
</env>
</image>
</configuration>
</plugin>
Правильная настройка логирования
Логирование, вероятно, не первое, о чем вы думаете при написании своих Java-приложений. Однако в глобальном масштабе это становится очень важным, поскольку нам нужно иметь возможность собирать, хранить данные и, наконец, быстро искать и представлять конкретную запись. Лучшей практикой является запись журналов приложений в стандартный поток вывода (stdout) и стандартный поток ошибок (stderr).Fluentd — это популярный агрегатор журналов с открытым исходным кодом, который позволяет собирать журналы из кластера Kubernetes, обрабатывать их, а затем отправлять в выбранное вами хранилище данных. Он легко интегрируется с развертываниями Kubernetes. Fluentd пытается структурировать данные в виде JSON, чтобы унифицировать ведение журналов из разных источников и мест назначения. Исходя из этого, вероятно, лучшим способом будет подготовка журналов в этом формате. С форматом JSON мы также можем легко включать дополнительные поля для маркировки журналов с помощью тегов, а затем легко искать их в визуальном инструменте по различным критериям.
Для того чтобы отформатировать наши журналы в формате JSON, читаемом Fluentd, мы можем включить библиотеку Logstash Logback Encoder в зависимости Maven.
<dependency>
<groupId>net.logstash.logback</groupId>
<artifactId>logstash-logback-encoder</artifactId>
<version>7.2</version>
</dependency>
Затем нам просто нужно установить по умолчанию вывод журнала в консоль (appender) для нашего приложения Spring Boot в файле logback-spring.xml.
<configuration>
<appender name="consoleAppender" class="ch.qos.logback.core.ConsoleAppender">
<encoder class="net.logstash.logback.encoder.LogstashEncoder"/>
</appender>
<logger name="jsonLogger" additivity="false" level="DEBUG">
<appender-ref ref="consoleAppender"/>
</logger>
<root level="INFO">
<appender-ref ref="consoleAppender"/>
</root>
</configuration>
Должны ли мы избегать использования дополнительных выводов для журналов и просто выводить журналы только на стандартный вывод? По моему опыту, ответ - нет. Вы все еще можете использовать альтернативные механизмы для вывода журналов. Особенно, если в вашей организации используется более одного инструмента для сбора логов — например, внутренний стек в Kubernetes и глобальный стек снаружи. Лично я использую инструмент, который помогает мне решать проблемы с производительностью, например, брокер сообщений в качестве прокси. В Spring Boot мы используем для этого RabbitMQ. Просто включите следующий стартер:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
Затем нам просто нужно предоставить аналогичную конфигурацию для вывода (appender) в logback-spring.xml:
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<springProperty name="destination" source="app.amqp.url" />
<appender name="AMQP"
class="org.springframework.amqp.rabbit.logback.AmqpAppender">
<layout>
<pattern>
{
"time": "%date{ISO8601}",
"thread": "%thread",
"level": "%level",
"class": "%logger{36}",
"message": "%message"
}
</pattern>
</layout>
<addresses>${destination}</addresses>
<applicationId>api-service</applicationId>
<routingKeyPattern>logs</routingKeyPattern>
<declareExchange>true</declareExchange>
<exchangeName>ex_logstash</exchangeName>
</appender>
<root level="INFO">
<appender-ref ref="AMQP" />
</root>
</configuration>
Создание интеграционных тестов
Хорошо, я знаю — это не имеет прямого отношения к Kubernetes. Но поскольку мы используем Kubernetes для управления и оркестровки контейнеров, мы также должны запускать интеграционные тесты на контейнерах. К счастью, с помощью Java-фреймворков мы можем значительно упростить этот процесс. Например, Quarkus позволяет нам аннотировать тест с помощью @QuarkusIntegrationTest. Это действительно мощное решение в сочетании с функцией сборки контейнеров Quarkus. Мы можем запускать тесты на уже созданном образе, содержащем приложение. Сначала давайте включим модуль Quarkus Jib:<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-container-image-jib</artifactId>
</dependency>
Затем мы должны включить сборку контейнера, установив для свойства quarkus.container-image.build значение true в файле application.properties. В тестовом классе мы можем использовать аннотации @TestHTTPResource и @TestHTTPEndpoint для внедрения URL-адреса тестового сервера. Затем мы создаем клиента с помощью RestClientBuilder и вызываем сервис, запущенный в контейнере. Название тестового класса неслучайно. Для того чтобы он автоматически определялся как интеграционный тест, он имеет суффикс IT.
@QuarkusIntegrationTest
public class EmployeeControllerIT {
@TestHTTPEndpoint(EmployeeController.class)
@TestHTTPResource
URL url;
@Test
void add() {
EmployeeService service = RestClientBuilder.newBuilder()
.baseUrl(url)
.build(EmployeeService.class);
Employee employee = new Employee(1L, 1L, "Josh Stevens",
23, "Developer");
employee = service.add(employee);
assertNotNull(employee.getId());
}
@Test
public void findAll() {
EmployeeService service = RestClientBuilder.newBuilder()
.baseUrl(url)
.build(EmployeeService.class);
Set<Employee> employees = service.findAll();
assertTrue(employees.size() >= 3);
}
@Test
public void findById() {
EmployeeService service = RestClientBuilder.newBuilder()
.baseUrl(url)
.build(EmployeeService.class);
Employee employee = service.findById(1L);
assertNotNull(employee.getId());
}
}
Более подробно об этом процессе вы можете прочитать в моей предыдущей статье о расширенном тестировании с помощью Quarkus. Конечный эффект виден на рисунке ниже. Когда мы запускаем тесты во время сборки с помощью команды mvn clean verify, наш тест выполняется после сборки образа контейнера.
Эта функция Quarkus основана на фреймворке Testcontainers. Мы также можем использовать Testcontainers со Spring Boot. Вот пример теста приложения Spring REST и его интеграции с базой данных PostgreSQL.
@SpringBootTest(webEnvironment = SpringBootTest.WebEnvironment.RANDOM_PORT)
@Testcontainers
@TestMethodOrder(MethodOrderer.OrderAnnotation.class)
public class PersonControllerTests {
@Autowired
TestRestTemplate restTemplate;
@Container
static PostgreSQLContainer<?> postgres =
new PostgreSQLContainer<>("postgres:15.1")
.withExposedPorts(5432);
@DynamicPropertySource
static void registerMySQLProperties(DynamicPropertyRegistry registry) {
registry.add("spring.datasource.url", postgres::getJdbcUrl);
registry.add("spring.datasource.username", postgres::getUsername);
registry.add("spring.datasource.password", postgres::getPassword);
}
@Test
@Order(1)
void add() {
Person person = Instancio.of(Person.class)
.ignore(Select.field("id"))
.create();
person = restTemplate.postForObject("/persons", person, Person.class);
Assertions.assertNotNull(person);
Assertions.assertNotNull(person.getId());
}
@Test
@Order(2)
void updateAndGet() {
final Integer id = 1;
Person person = Instancio.of(Person.class)
.set(Select.field("id"), id)
.create();
restTemplate.put("/persons", person);
Person updated = restTemplate.getForObject("/persons/{id}", Person.class, id);
Assertions.assertNotNull(updated);
Assertions.assertNotNull(updated.getId());
Assertions.assertEquals(id, updated.getId());
}
}
Заключительные мысли
Я надеюсь, что эта статья поможет вам избежать некоторых распространенных подводных камней при запуске Java-приложений в Kubernetes. Рассматривайте ее как краткое изложение рекомендаций других людей, которые я нашел в подобных статьях, и моего личного опыта в этой области. Возможно, некоторые из этих правил покажутся вам весьма спорными. Не стесняйтесь делиться своими мнениями и отзывами в комментариях. Это также будет ценно для меня. Если вам понравилась эта статья, еще раз рекомендую прочитать еще одну из моего блога — больше ориентированную на запуск приложений на основе микросервисов в Kubernetes — Best Practices For Microservices on Kubernetes . Она также содержит несколько полезных (надеюсь) рекомендаций.
Лучшие практики для Java-приложений в Kubernetes
В этой статье вы прочитаете о лучших практиках запуска Java-приложений в Kubernetes. Большинство из этих рекомендаций будут справедливы и для других языков. Однако я рассматриваю все правила в...
habr.com