В мире программирования часто встречаются две структуры данных: массивы, или списки; и мапы — словари или объекты. В этой статье рассмотрим, как устроены мапы в языке Go и как это реализовано в коде. Мапа в Go — это хэш-таблица, она нужна для хранения пар «ключ-значение».

Хэш-функция преобразует входные данные в числовое значение. Затем оно используется в качестве индекса для доступа к соответствующей ячейке в таблице. Заполняется хэш-таблица путём применения хэш-функции к каждому элементу данных и размещения его в соответствующей ячейке.
Предположим, у нас есть пары, и мы хотим записать их в хэш-таблицу. Чтобы это сделать, мы пропускаем ключи через хэш-функцию и получаем индекс, куда записывать нашу пару.
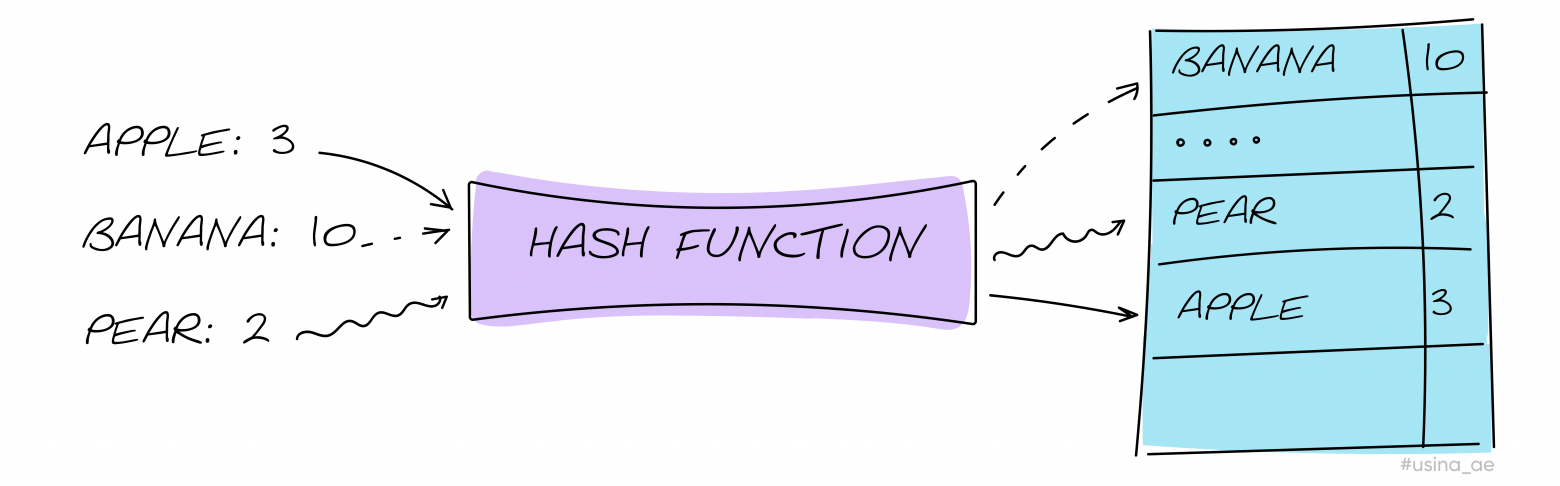
Если применить хэш-функцию к двум разным ключам, можно получить один и тот же индекс. Это называется коллизией. Её можно разрешить с помощью метода открытой адресации и метода цепочек
При открытой адресации мы помещаем ключ в свободную ячейку, следующую за текущей или с определённым шагом. Не забываем, что при работе с хэш-таблицей надо не только записывать в неё, но и выполнять по ней поиск. Он будет происходить в том же порядке, что и при вставке, и до тех пор, пока не будет найден элемент с искомым ключом или свободная ячейка. Последнее означает отсутствие элемента в хэш-таблице.
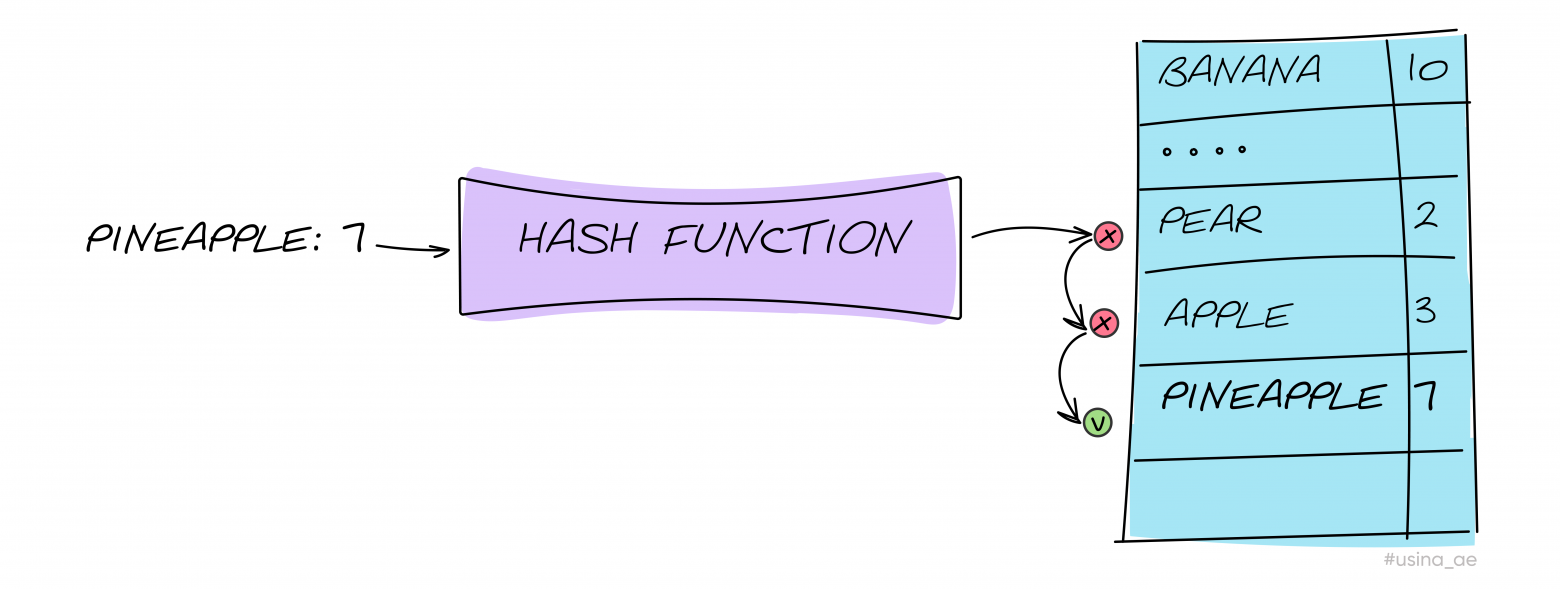
При использовании метода цепочек мы добавляем элементу в текущей ячейке ссылку на новый. Так появляются связь между предыдущим и новым элементами, образуется цепочка элементов с одинаковыми хэшами (двусвязный список).
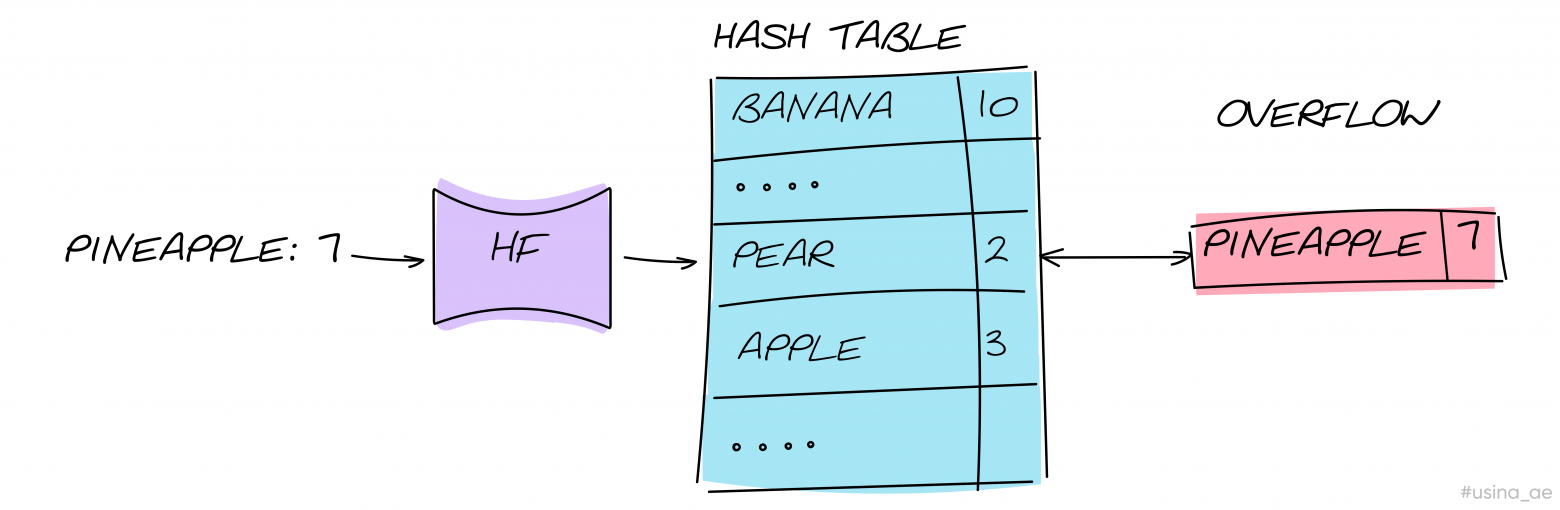
Если плохо распределить хэши, может возникнуть ситуация «мы поместили N элементов в одну и ту же ячейку, и получился связанный список длиной N». Поиск элементов по такому списку в худшем случае будет иметь сложность O(N), а это не эффективнее, чем поиск по массиву.
В обоих случаях нам всё равно приходится выполнять поиск по нашей хэш-таблице — ассоциативному массиву. Чтобы искать эффективнее, хэш-таблицу можно немного модернизировать. Предположим, что мы записываем товар в хэш-таблицу и его можно разделить по какому-то признаку: например, фрукты или овощи. Тогда хэш-таблицу нужно разбить на составляющие «бакеты» ограниченной длины. Например, 10 элементов в бакете с фруктами и 10 элементов в бакете с овощами.
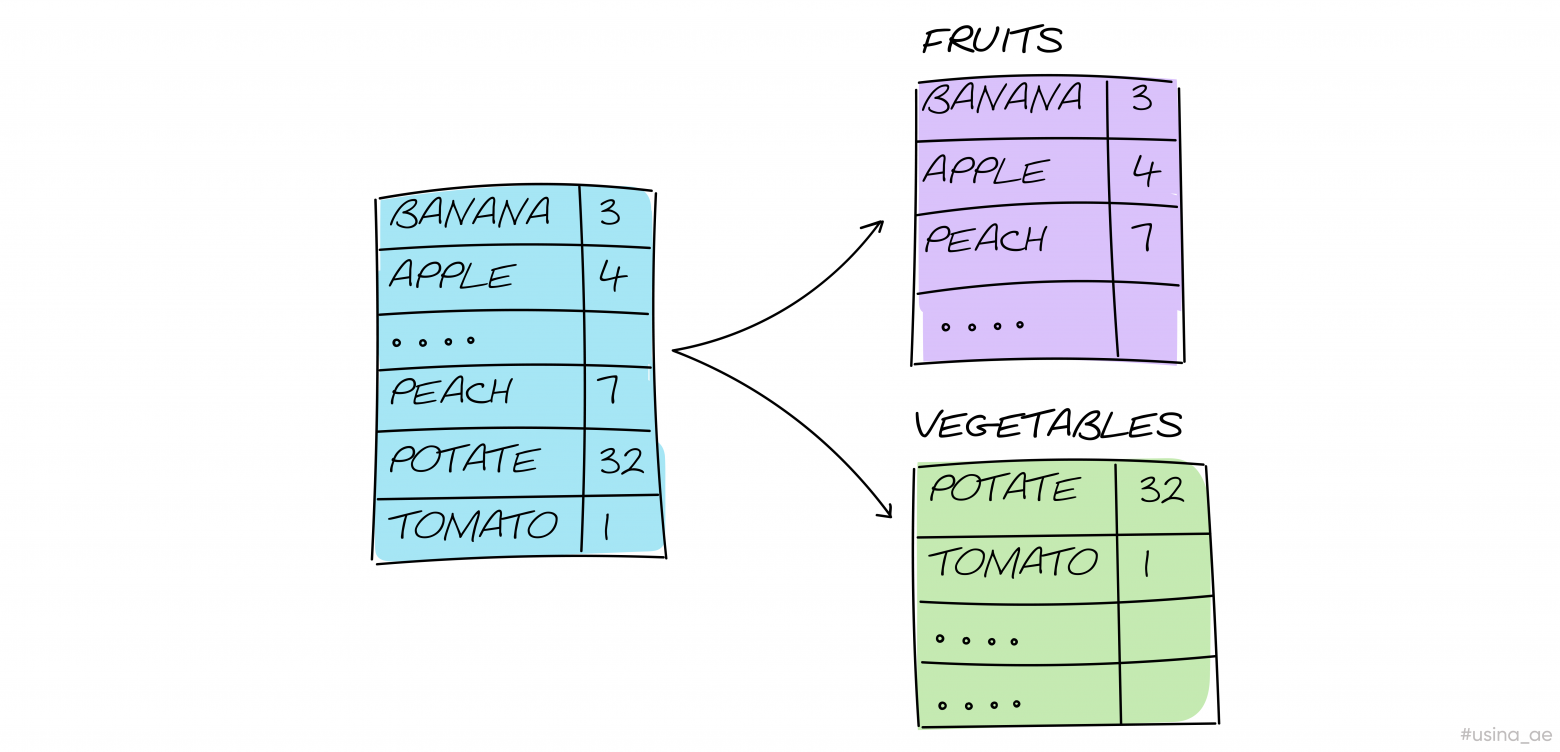
Теперь на первом шаге поиска мы проверяем признак — фрукт или овощ. После перебираем 10 ключей и находим нужный. Так мы в среднем получаем константную сложность поиска, но при условии, что внутри бакета не образуются длинные цепочки.
Ещё часто бывает нужно расширить хэш-таблицу, потому что реальное количество элементов превышает предполагаемое. Если её не расширять, то возникнет множество связанных списков и поиск станет неэффективным. Чтобы определить, когда пора увеличить таблицу или количество бакетов, вводится коэффициент заполняемости таблицы, или load factor.
Коэффициент заполняемости таблицы, или load factor — это отношение количества хранимых пар «ключ-значение» к размеру таблицы. Если они достигают пограничного значения, то хэш-мапу расширяют, а индексы пар пересчитывают и перераспределяют.
Структуры для работы с мапой:
// go/src/runtime/map.go
type hmap struct {
// ...more code
count int
B uint 8
noverflow uint 16
hash0 uint 32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
}
count — количество пар «ключ-значение».
B — количество бакетов, выраженное через log2. Такое выражение через логарифм упрощает работу с битовыми операциями.

noverflow — приблизительное количество переполненных бакетов.
hash0 — величина для добавления большего разнообразия и случайности в хэш-функцию, позволяет достичь устойчивости к коллизиям.
buckets — это указатель на массив бакетов. В Go это ячейка памяти, где хранятся бакеты.
oldbuckets — это также указатель на массив бакетов, из которых происходит эвакуация данных, когда бакетов становится больше. Является ячейкой памяти.
// go/src/runtime/type.go
type MapType struct {
// ...more code
Hasher func(unsafe.Pointer, uintptr) uintptr
}
Hasher — это хэш-функция, которая принимает аргументы key, hash0 и возвращает hash. Пример кода:
hash := t.Hasher(noescape(unsafe.Pointer(&s)), uintptr(h.hash0))
//go/src/runtime/map.go
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket.
tophash [bucketCnt]uint8
}
tophash — массив, содержит 8 верхних байт хэшей каждого ключа в бакете.
Количество элементов в бакете — одна из важных констант
const bucketCnt = 8
Рассмотрим создание map с использованием функции make. При создании map через make используется функция makemap.
func makemap(t *maptype, hint int, h *hmap) *hmap {
//...more code
1 // initialize Hmap
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
2 B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
3 if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
//...more code
}
return h
}
Блок 1. Проверяем наличие h *hmap. Если его нет, то инициализируем. Затем получаем hash0.
Блок 2. Рассчитываем количество бакетов B в формате log на основе hint. hint — второй аргумент в функции make(map[string]string, hint).
Блок 3. Если количество бакетов не равно 1 (log 1 = 0 = B), то выделяется память для наших бакетов.
m["apple"] = "fruit"
При записи в мапу вызывается метод (для строки):
func mapassign_faststr(t *maptype, h *hmap, s string) unsafe.Pointer {
1 if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// ...more code
2 key := stringStructOf(&s)
3 hash := t.Hasher(noescape(unsafe.Pointer(&s)), uintptr(h.hash0))
// ...more code
if h.buckets == nil {
h.buckets = newobject(t.Bucket) // newarray(t.bucket, 1)
}
// ...more code
}
Шаг 1. Проверяем, была ли инициализирована наша hmap. Если нет, вызываем панику. Частая ошибка у новичков — объявлять переменную без использования make и пытаться записать в неё ключ/значение.
Шаг 2. Получаем key — указатель на структуру, в которой хранится адрес ключа "apple".
// go/SDK/cmd/runtime/string.go
type stringStruct struct {
str unsafe.Pointer
len int
}
func stringStructOf(sp *string) *stringStruct {
return (*stringStruct) (unsafe.Pointer(sp))
}
unsafe.Pointer используется как указатель на данные любого типа.
Шаг 3. Получаем hash ключа "apple" и выделяем память для нашего бакета, если не делали этого в makemap.
Переходим в следующий блок, который начинается с лейбла goto — again.
func mapassign_faststr(t *maptype, h *hmap, s string) unsafe Pointer {
// ...more code
again:
1 bucket := hash & bucketMask(h. B)
// ...more code
2 b := (*bmap) (add(h.buckets, bucket*uintptr(t.BucketSize)))
3 top := tophash(hash)
4 var insertb *bmap
var inserti uintptr
var insertk unsafe.Pointer
// ...more code
}
Шаг 1. Рассчитываем, в какой бакет будем записывать данные. В основе большинства расчетов лежат битовые операции.
// bucketMask returns 1<<b - 1, optimized for code generation.
func bucketMask(b uint8) uintptr {
return bucketShift(b) - 1
}
Функция возвращает результат операции 1 << b - 1.
Оператор << осуществляет битовый сдвиг влево. К примеру, у нас есть выражение 5 << 3. Это означает, что мы хотим сдвинуть число 5 на 3 бита влево. В этом случае:
Шаг 2. Переходим к получению *bmap.
h.buckets — это ячейка памяти, от которой начинается бакет.
bucket — индекс бакета.
t.BucketSize=272 — размер бакета в байтах.
Функция add представляет собой простое сложение с приведением типов.
// runtime/stubs.go
func add(p unsafe.Pointer, x uintptr) unsafe.Pointer {
return unsafe.Pointer(uintptr(p) + x)
}
Если проигнорировать приведение типов и подставить значения, получим упрощенное выражение:
(add(h.buckets, bucket} \cdot \text{uintptr(t.BucketSize))) =} \\= \text {h.buckets + bucket} \cdot \text{t.BucketSize} =\\ = \text {h.buckets + bucket} \cdot \text{t.BucketSize} =\\= \text {h.buckets + bucket} \cdot \text{272};")
После выполнения следующего кода мы получим ячейку памяти. В ней хранится структура со списком верхних байтов хэша для ключей текущего бакета.
Шаг 3. Рассчитываем верхний байт по hash от "apple".
func tophash(hash uintptr) uint8 {
top := uint8(hash >> (goarch.PtrSize*8 - 8))
if top < minTopHash { // minTopHash = 5
top += minTopHash
}
return top
}
Рассмотрим работу tophash.
Для ключа "apple" значение hash=3661323553996174279, а goarch.PtrSize равно 8 для 64-битной системы. Получаем следующий код:
 \\ 3661323553996174279>>(64−8) \\ 3661323553996174279>>56")
Здесь >> обозначает побитовый сдвиг вправо.
Число 3661323553996174279 в двоичной системе равно 11001011001111101000100101111110110011101101100111001111000111.
Делаем сдвиг на 56 бит вправо: 11001011001111101000100101111110110011101101100111001111000111. Получаем 110010 и переводим в десятичную систему, получаем значение верхнего байта хэша — 50.
Шаг 4. Инициализируем переменные для вставки. insertb — это ячейка в памяти, с которой начинается список верхних байтов. inserti — указывает, под каким индексом добавлять верхний байт, ключ и значение. insertk — это ячейка в памяти, с которой начинается список ключей.
После инициализации переходим к следующему блоку, который начинается с лейбла bucketloop. В этом блоке определяются insertb и inserti (пока рассмотрим без переполнения):
func mapassign_faststr(t *maptype, h *hmap, s string) unsafe.Pointer {
// ...more code
bucketloop:
for {
1 for i := uintptr(0); i < bucketCnt; i++ {
2 if b.tophash != top {
3 if isEmpty(b.tophash) && insertb == nil {
insertb = b
inserti = i
}
4 if b.tophash == emptyRest {
break bucketloop
}
continue
}
5 k := (*stringStruct)(add(unsafe.Pointer(b), dataOffset+i*2*goarch.PtrSize))
if k.len != key.len {
continue
}
if k.str != key.str && !memequal(k.str, key.str, uintptr(key.len)) {
continue
}
inserti = i
insertb = b
k.str = key.str
goto done
}
//...more code
}
//...more code
done:
//...more code
}
Для определения индекса свободной ячейки мы проходимся в цикле от 0 до длины бакета (шаг 1). На каждой итерации (шаг 2) мы проверяем наличие верхнего байта хэша.
Если такой байт существует и b.tophash == top, мы переходим к шагу 5, где сравниваем текущий ключ с ключом, уже находящимся в бакете. Если они не равны, продолжаем поиск свободной ячейки для вставки и переходим к следующей итерации. Если ключи равны, мы получаем inserti и insertb и выходим из цикла с помощью goto done.
Если условие на шаге 2 выполняется, мы переходим к шагу 3 и проверяем, является ли ячейка по индексу i пустой или нет. Если она пустая, сохраняем insertb и inserti и переходим к шагу 4, где проверяем, пустые следующие ячейки или нет. Если остальные ячейки пустые, то мы прерываем наш поиск через break bucketloop и переходим к следующему этапу.
Отличие шага 3 от шага 4 — в том, что на шаге 3 мы проверяем пустоту только текущей ячейки, а на шаге 4 мы проверяем и остальные ячейки. Это нужно, чтобы убедиться, что в бакете нет ключа с таким же значением.
Далее мы переходим к сохранению нашего верхнего байта хэш ключа, ключа и увеличению счётчика элементов в мапе:
func mapassign_faststr(t *maptype, h *hmap, s string) unsafe.Pointer {
// ...more code
bucketloop:
for {...}
// ...more code
1 insertb.tophash[inserti&(bucketCnt-1)] = top
2 insertk = add(unsafe.Pointer(insertb), dataOffset+inserti*2*goarch.PtrSize)
// store new key at insert position
3 *((*stringStruct)(insertk)) = *key
h.count++
// ...more code
done:
4 elem := add(unsafe.Pointer(insertb), dataOffset+bucketCnt*2*goarch.PtrSize+inserti*uintptr(t.ValueSize))
// ...more code
5 return elem
}
На шаге 1 мы также видим логическое сравнение «И», через которое определяем, куда сохранить наш верхний байт хэша. После этого переходим к шагу 2, где вычисляем ячейку для вставки ключа.
unsafe.Pointer(insertb) — начальная ячейка, от которой выполняется расчёт ячейки для вставки.
dataOffset — это размер списка верхних байтов хэшей, равный 8 байтам (1 байт на каждый верхний байт хэша).
goarch.PtrSize — 8 для 64-битной системы.
Если отбросить приведение типов и подставить значения, получаем упрощённое выражение:
, dataOffset+inserti}\cdot\text{2}\cdot\text{goarch.PtrSize)} =\\ = \text {add(unsafe.Pointer(insertb), 8 + inserti} \cdot \text{2} \cdot \text{8)} = \\ = \text {add(unsafe.Pointer(insertb), 8 + inserti} \cdot \text{16)} = \\ = \text{insertb + 8 + inserti} \cdot \text{16};")
Далее переходим к сохранению ключа (шаг 3) в соответствующую ячейку insertk.
После выполняем аналогичные шаги для получения ячейки вставки значения (шаг 4).
t.ValueSize=16 — размер значения в байтах.
Если отбросить приведение типов и подставить значения, получаем упрощённое выражение:
, dataOffset+bucketCnt}\cdot\text {2}\cdot\text {goarch.PtrSize+inserti}\cdot\text {uintptr(t.ValueSize))} = \\ = \text {add(unsafe.Pointer(insertb), 8 + 8} \cdot \text {2} \cdot \text {8 + inserti} \cdot \text {16)} = \\ = \text {add(unsafe.Pointer(insertb), 8 + 128 + inserti} \cdot \text {16)} = \\ = \text {add(unsafe.Pointer(insertb), 136 + inserti} \cdot \text {16)} = \\ = \text {insertb + 136 + inserti} \cdot \text {16};")
В конце (шаг 5) возвращается место в памяти, где будет лежать наше значение.
Наши выражения:
 + 8 + inserti} \cdot \text {16} \\ \text {elem = }insertb\text { + 136 + inserti} \cdot \text {16 = (h.buckets + bucket} \cdot \text {272) + 136 + inserti} \cdot \text {16} \\")
Получается, что ячейка для верхнего байта хэша, значения и ключа зависит от ячейки памяти, с которой начинается наш бакет. h.buckets. inserti указывает, под каким индексом мы будем добавлять верхний байт, ключ и значение. bucket — номер бакета.
Давайте рассмотрим, как выглядят бакеты в Go на практике, задав начальные условия:
h.buckets=1000 — начальный адрес, где располагаются бакеты. Количество бакетов — 1 (bucket=0). t.BucketSize=272 — размер бакета в байтах.
Тогда наши выражения приобретают такой вид:
 + 8 + inserti} \cdot \text {16 = 1008 + inserti} \cdot \text {16}\\ \text {elem = (1000 + bucket} \cdot \text {272) + 136 + inserti} \cdot \text {16 = 1136 + inserti} \cdot \text {16 }\\")
Обратим внимание, что insertb и h.buckets совпадают. Это означает, что наш список верхних байт находится в начале бакета.
У нас есть inserti в диапазоне от 0 до 7. Размер массива верхних байт хэшей составляет 8 байт, а размер ключа и значения — 16 байт.
Тогда для inserti = 0 получаем:


Тогда для inserti = 1 получаем:


После проведения расчёта для 8 элементов мы обнаружили, что массив верхних байтов хэшей расположен в начале бакета, за которым следуют ключи, а затем значения. Также в конце бакета находится блок overflow — о нём мы поговорим подробнее в следующем разделе. Таким образом, размер нашего бакета составляет 272 байта.

Такая структура используется для упрощения поиска по бакету и получения наших значений с помощью битовых операций.
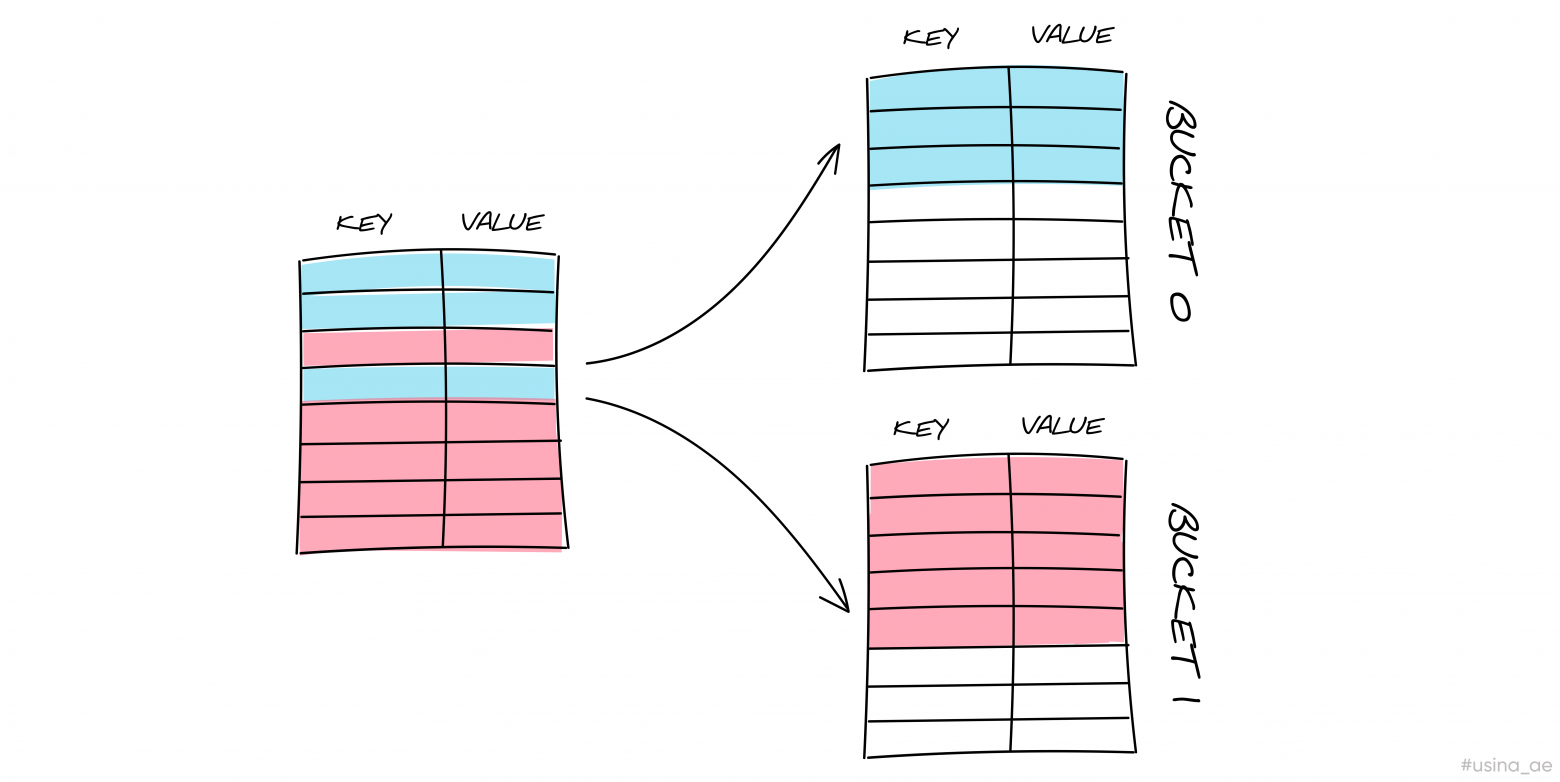
1. Увеличение общего количества бакетов и перераспределение пар по этим бакетам.
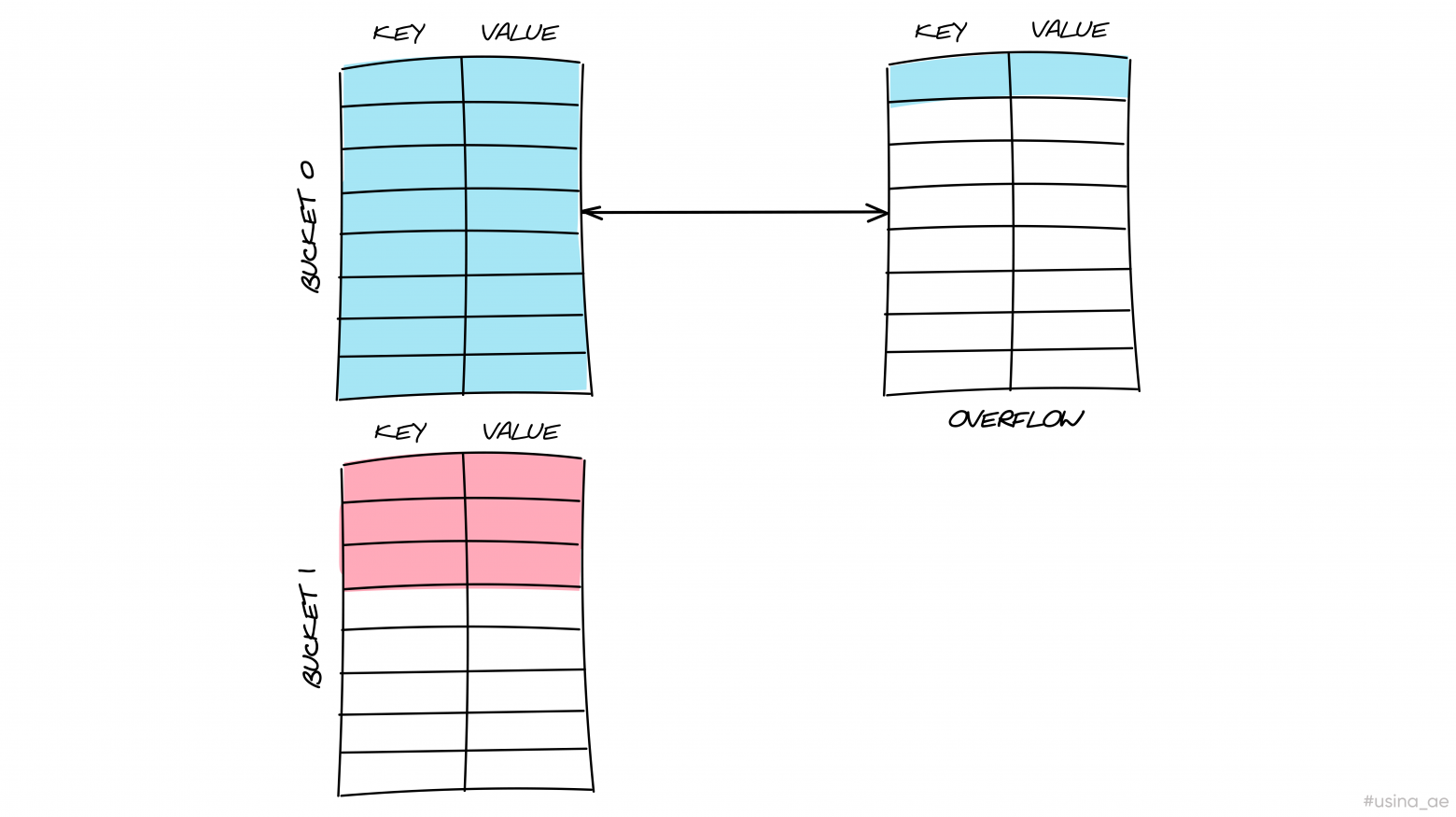
2. Создание бакета, на который даём ссылку в заполненный бакет. Если понадобится записать в заполненный, то мы запишем в тот, на который есть ссылка.
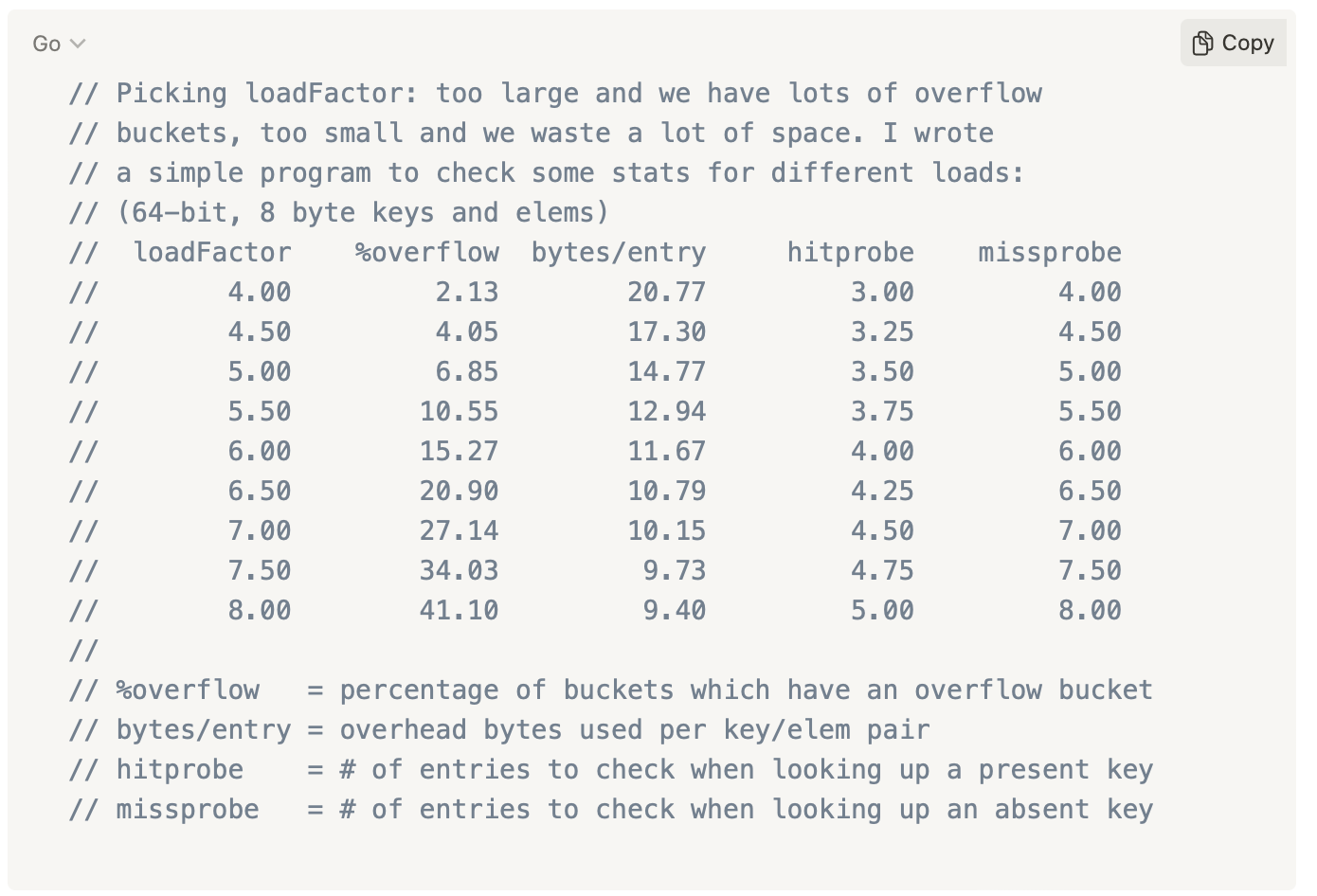
Увеличение количества бакетов в Go и распределение существующих пар называется эвакуацией. Принятие решения о выполнении эвакуации зависит от значения load factor, — это среднее заполнение бакетов. В Go значение loadFactor равно 6.5, — это означает, что процесс эвакуации начинается, когда средняя заполняемость бакетов достигает 6.5 или 80% для бакета с размером 8. Также на выполнение эвакуации в Go влияет количество связанных бакетов.
Разработчики Go оставили в комментариях результаты вычислений, по которым выбрали 6,5.
При эвакуации количество бакетов увеличивается в два раза. Текущие пары с топхэшами распределяются по этим бакетам.
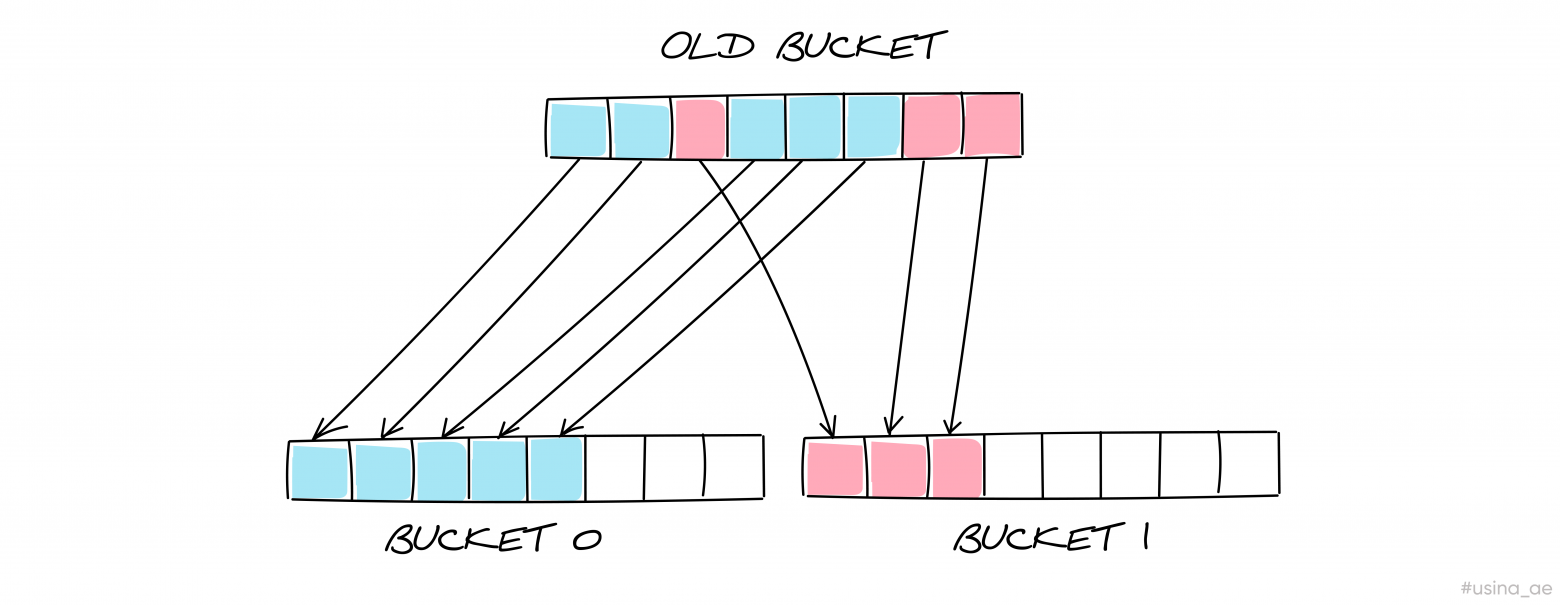
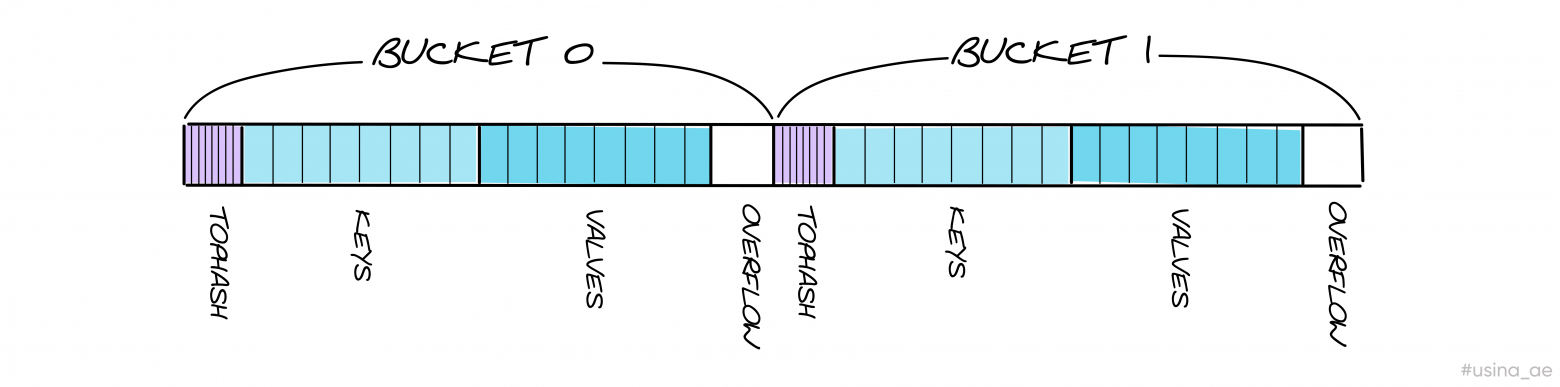
Чтобы понять, как расположены бакеты в памяти, можно воспользоваться нашими упрощёнными формулами и произвести расчет для двух бакетов.

Мы увидим, что бакеты хранятся один за другим:
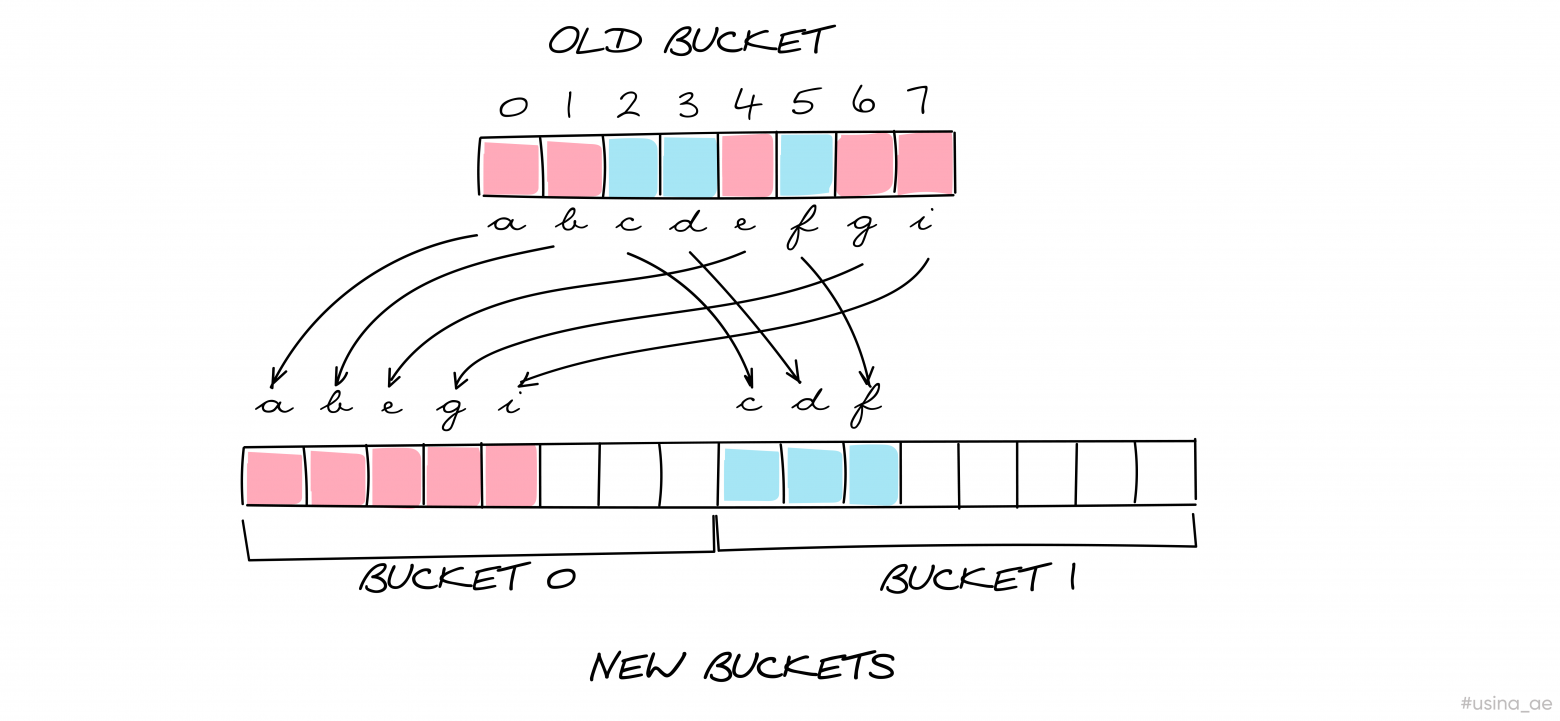
А эвакуация будет происходить так:
Но что, если наше распределение неравномерное? Например, у нас есть 4 бакета: в первом бакете — 5 элементов, во втором — 8, в третьем — 4 и в четвёртом — 1. Тогда мы получаем load factor = (5 + 8 + 4 + 1) / 4 = 4,5. Но мы хотим записать элемент и согласно нашим вычислениям он должен быть во втором бакете. Тогда нам поможет создание связанного бакета — overflow в Go.
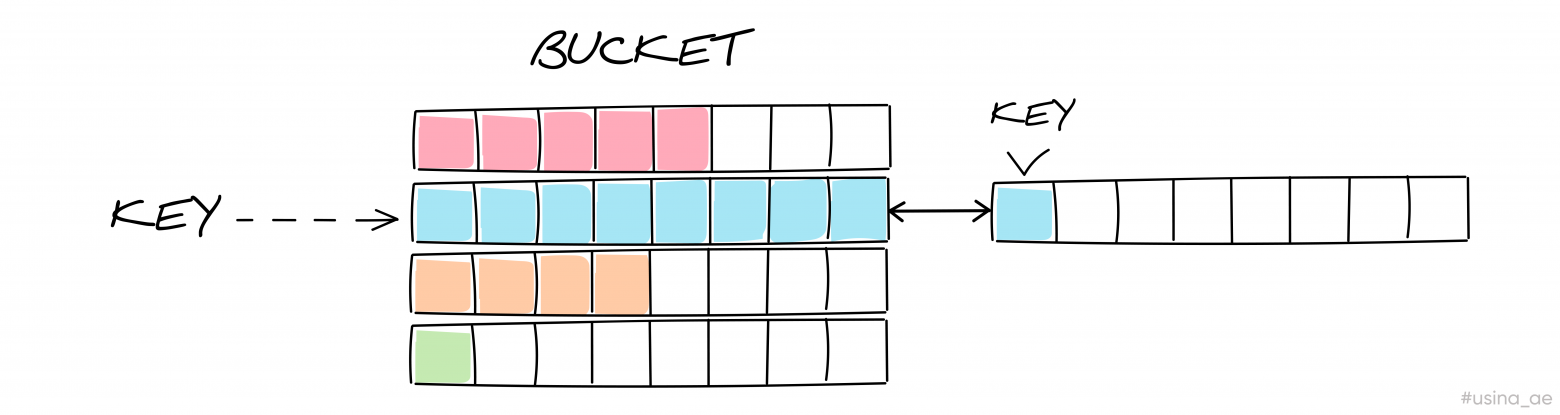
Создаём новый бакет и даём на него ссылку в заполненный второй бакет. Так мы сформируем связанный список.
Теперь перейдем к записи нашей пары с переполнением. Часть кода мы уже разобрали ранее.
// ...more code
again:
bucket := hash & bucketMask(h.B)
1 if h.growing() {
growWork_faststr(t, h, bucket)
}
b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))
top := tophash(hash)
var insertb *bmap
var inserti uintptr
var insertk unsafe.Pointer
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
2 if b.tophash != top {
if isEmpty(b.tophash) && insertb == nil {
insertb = b
inserti = i
}
if b.tophash == emptyRest {
break bucketloop
}
continue
}
k := (*stringStruct)(add(unsafe.Pointer(b), dataOffset+i*2*goarch.PtrSize))
if k.len != key.len {
continue
}
if k.str != key.str && !memequal(k.str, key.str, uintptr(key.len)) {
continue
}
inserti = i
insertb = b
k.str = key.str
goto done
}
3 ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
4 if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again
}
5 if insertb == nil {
insertb = h.newoverflow(t, b)
inserti = 0
}
6 insertb.tophash[inserti&(bucketCnt-1)] = top
insertk = add(unsafe.Pointer(insertb), dataOffset+inserti*2*goarch.PtrSize)
//...more code
done:
//...more code
У нас есть пара «ключ-значение», которую мы хотим записать в заполненный бакет.
Мы получили bucket, bmap и верхний байт хэша (top) в блоке again. Функция h.growing() на шаге 1 возвращает нам статус — растёт бакет в данный момент или нет. Пока мапа у нас не растёт и h.growing() вернёт false. После этого мы переходим к if b.tophash != top (шаг 2). Для лучшего понимания предполагаем, что все наши верхние байты хэшей разные, это условие верно и мы выполняем его. Но внутренние проверки будут ложными, потому что бакет полный. В результате итерация прерывается при continue, и мы переходим к шагу 3.
На нём получаем адрес нашего overflow бакета:
func (b *bmap) overflow(t *maptype) *bmap {
return *(**bmap)(add(unsafe.Pointer(b), uintptr(t.BucketSize)-goarch.PtrSize))
}
// uintptr(t.BucketSize)-goarch.PtrSize = 272 - 8 = 264
Мы видим, что overflow занимает последние 8 байт в бакете. В этот момент у нас нет связанного бакета, поэтому ovf=nil, и мы выходим из цикла с помощью break.
Затем переходим к шагу 4, где проверяем, что наша мапа не растёт и выполняется одно из условий: превышение коэффициента заполнения или наличие большого количества связанных бакетов.
С этого шага начинается разветвление: создание связанного списка или начало эвакуации.
Здесь проверка возвращает значение true, так как на шаге 2 мы не записали insertb. Далее создаём новый бакет в функции newoverflow (метод упростил для лучшего понимания):
func (h *hmap) newoverflow(t *maptype, b *bmap) *bmap {
var ovf *bmap
ovf = (*bmap)(newobject(t.Bucket))
b.setoverflow(t, ovf)
return ovf
}
func (b *bmap) setoverflow(t *maptype, ovf *bmap) {
*(**bmap)(add(unsafe.Pointer(b), uintptr(t.BucketSize)-goarch.PtrSize)) = ovf
}
После создания бакета заполняем верхний байт хэша, key и value согласно тому же алгоритму, что и при обычной записи (шаге 6 и далее см. Запись в мапу).
Если в следующий раз захотим найти адрес и индекс вставки, то проходимся по первому заполненному бакету, понимаем, что весь бакет заполнен, переходим к шагу 3. На нём получаем ссылку на связанный бакет, переприсваиваем значение b=ovf и ищем место для вставки в этом связанном бакете.
func hashGrow(t *maptype, h *hmap) {
// ... more code
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
// ... more code
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
// ... more code
}
После hashGrow(t, h) переходим к инструкции goto again, которая переводит нас в блок again. Здесь на шаге 1 условие истинно, так как на прошлом шаге мы записали в oldbuckets предыдущий бакет.
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}
Внутри условия вызывается метод growWork_faststr(t, h, bucket), в котором начинается перераспределение верхних байтов хэшей, ключей и значений в новый бакет. За один вызов growWork_faststr может происходить перераспределение до двух бакетов. Они перераспределяются вместе с overflow. Эвакуация происходит инкрементально и выполняется при записи и удалении ключей. Реальный пример:
Эвакуация становится одной из причин, почему мы не можем обратиться к ключу по адресу, так как мы не можем предсказать, в каком месте будет находиться наша пара. Возможно, она уже находится в новом бакете, а возможно, еще в старом. Кроме того, ясно, что процесс эвакуации данных не является бесплатным, и чтобы избежать его, можно заранее определить количество элементов в нашей мапе.
myMap := make(map[string]string, 1000)
Если вы скажете, сколько элементов будет на этапе создания мапы, выделится нужное количество бакетов под это количество элементов и тогда вы избежите эвакуации.
func mapaccess1_faststr(t *maptype, h *hmap, ky string) unsafe.Pointer {
// ...more code
1 if h == nil || h.count == 0 {
return unsafe.Pointer(&zeroVal[0])
}
// ...more code
2 key := stringStructOf(&ky)
if h.B == 0 {
// ...more code
return unsafe.Pointer(&zeroVal[0])
}
dohash:
3 hash := t.Hasher(noescape(unsafe.Pointer(&ky)), uintptr(h.hash0))
m := bucketMask(h.B)
4 b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize)))
5 if c := h.oldbuckets; c != nil {
// ...more code
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.BucketSize)))
if !evacuated(oldb) {
b = oldb
}
}
top := tophash(hash)
6 for ; b != nil; b = b.overflow(t) {
for i, kptr := uintptr(0), b.keys(); i < bucketCnt; i, kptr = i+1, add(kptr, 2*goarch.PtrSize) {
7 k := (*stringStruct)(kptr)
if k.len != key.len || b.tophash != top {
continue
}
if k.str == key.str || memequal(k.str, key.str, uintptr(key.len)) {
return add(unsafe.Pointer(b), dataOffset+bucketCnt*2*goarch.PtrSize+i*uintptr(t.ValueSize))
}
}
}
8 return unsafe.Pointer(&zeroVal[0])
}
На шаге 1 мы проверяем, инициализирована ли хэшмапа и содержит ли она записи. Если нет, то просто возвращаем нулевое значение для нашего типа.
На втором шаге получаем адрес структуры ключа. Как она устроена, можно посмотреть ранее в функции assign. Затем переходим к проверке количества бакетов. Если h.B = 0, это означает, что у нас 1 бакет (помним про логарифм). Если условие верно, ищем ключ в единственном бакете. Если не находим, возвращаем нулевое значение для нашего типа.
Рассмотрим подробнее поиск по двум бакетам.
У нас есть два бакета, поэтому h.B = 1. Ниже представлены ключи, которые находятся в каждом бакете и их хэш:
Предположим, что мы хотим получить значение по ключу "apple 7":
а := ourMap["apple 7"]
Начнём с шага 3. Таким же образом, как и при assign’е, мы получаем хэш нашего ключа. Дальше переходим к битовой маске (подробнее можно посмотреть при assign):
 = bucketMask(1) = 1}")
На шаге 4 на основе битовой маски определяем, в каком бакете находится наш хэш.
m=1 , t.BucketSize=272 , h.buckets=1000 , hash для “apple 7” = 7760656414049467263.
(add(h.buckets, (hash&m})\cdot \text{uintptr(t.BucketSize)))} =\\ = \text {h.buckets + (hash&m)} \cdot \text {t.BucketSize } =\\ = \text {1000 + 1} \cdot \text {272 = 1272}\\")
После получения нужного бакета, на шаге 5 проверяем, есть ли бакеты, из которых происходила эвакуация. Если есть h.oldbuckets — это означает, что эвакуация мапы = всех старых бакетов еще не завершена. Тогда надо проверить, эвакуировался ли бакет, полученный на прошлом шаге. Если нет, то продолжаем искать значение по нему.
На следующем шаге мы вычисляем верхний байт хэша. Это цикл, который сначала выполняет поиск по текущему бакету и если есть связанные — ещё и по ним:
for i, kptr := uintptr(0), b.keys(); i < bucketCnt; i, kptr = i+1, add(kptr, 2*goarch.PtrSize) {
// ...more code
}
Его можно упростить в следующий:
kptr := b.keys()
for i := uintptr(0); i < bucketCnt; i = i+1 {
// ...more code
kptr = add(kptr, 2*goarch.PtrSize)
}
b.key() — получение адреса в памяти, где находятся ключи для пар. Адрес ключей совпадает с адресом первого ключа. Если бакет начинается с ячейки 1000, то b.key() вернет 1008, пропуская верхние байты хэшов.
kptr = add(kptr, 2goarch.PtrSize) — сдвиг на следующий ключ
 = kptr + 2} \cdot \text{8 = kptr + 16}")
Фактически, этот цикл сводится к перебору всех ключей в бакете.
Внутри цикла мы приводим указатель на адрес ключа к нужному типу (шаг 7). Затем сравниваем длину ключа, для которого ищем значение, с длиной ключа из бакета, и сравниваем наши топ хэши.
После этого либо находим нужный ключ и возвращаем нужное значение, либо переходим к другому ключу из бакета или связанного бакета. Если в результате нужный ключ не нашёлся, возвращаем нулевое значение для нашего типа (шаг 8).

 habr.com
habr.com
Теория хэш-таблиц
Хэш-таблица — это структура данных, ассоциативный массив. Она позволяет хранить пары «ключ-значение» и выполнять три операции:- поиск значения по ключу,
- добавление пары,
- удаление пары.
Хэш-функция преобразует входные данные в числовое значение. Затем оно используется в качестве индекса для доступа к соответствующей ячейке в таблице. Заполняется хэш-таблица путём применения хэш-функции к каждому элементу данных и размещения его в соответствующей ячейке.
Предположим, у нас есть пары, и мы хотим записать их в хэш-таблицу. Чтобы это сделать, мы пропускаем ключи через хэш-функцию и получаем индекс, куда записывать нашу пару.
Если применить хэш-функцию к двум разным ключам, можно получить один и тот же индекс. Это называется коллизией. Её можно разрешить с помощью метода открытой адресации и метода цепочек
При открытой адресации мы помещаем ключ в свободную ячейку, следующую за текущей или с определённым шагом. Не забываем, что при работе с хэш-таблицей надо не только записывать в неё, но и выполнять по ней поиск. Он будет происходить в том же порядке, что и при вставке, и до тех пор, пока не будет найден элемент с искомым ключом или свободная ячейка. Последнее означает отсутствие элемента в хэш-таблице.
При использовании метода цепочек мы добавляем элементу в текущей ячейке ссылку на новый. Так появляются связь между предыдущим и новым элементами, образуется цепочка элементов с одинаковыми хэшами (двусвязный список).
Если плохо распределить хэши, может возникнуть ситуация «мы поместили N элементов в одну и ту же ячейку, и получился связанный список длиной N». Поиск элементов по такому списку в худшем случае будет иметь сложность O(N), а это не эффективнее, чем поиск по массиву.
В обоих случаях нам всё равно приходится выполнять поиск по нашей хэш-таблице — ассоциативному массиву. Чтобы искать эффективнее, хэш-таблицу можно немного модернизировать. Предположим, что мы записываем товар в хэш-таблицу и его можно разделить по какому-то признаку: например, фрукты или овощи. Тогда хэш-таблицу нужно разбить на составляющие «бакеты» ограниченной длины. Например, 10 элементов в бакете с фруктами и 10 элементов в бакете с овощами.
Теперь на первом шаге поиска мы проверяем признак — фрукт или овощ. После перебираем 10 ключей и находим нужный. Так мы в среднем получаем константную сложность поиска, но при условии, что внутри бакета не образуются длинные цепочки.
Ещё часто бывает нужно расширить хэш-таблицу, потому что реальное количество элементов превышает предполагаемое. Если её не расширять, то возникнет множество связанных списков и поиск станет неэффективным. Чтобы определить, когда пора увеличить таблицу или количество бакетов, вводится коэффициент заполняемости таблицы, или load factor.
Коэффициент заполняемости таблицы, или load factor — это отношение количества хранимых пар «ключ-значение» к размеру таблицы. Если они достигают пограничного значения, то хэш-мапу расширяют, а индексы пар пересчитывают и перераспределяют.
Реализация map в Go 1.21.1
В коде я пропустил некоторые участки, чтобы уделить больше внимания ключевым блокам. Все примеры рассматривались для 64-битной системы, для которой переменная goarch.PtrSize=8.Структуры для работы с мапой:
// go/src/runtime/map.go
type hmap struct {
// ...more code
count int
B uint 8
noverflow uint 16
hash0 uint 32
buckets unsafe.Pointer
oldbuckets unsafe.Pointer
}
count — количество пар «ключ-значение».
B — количество бакетов, выраженное через log2. Такое выражение через логарифм упрощает работу с битовыми операциями.
noverflow — приблизительное количество переполненных бакетов.
hash0 — величина для добавления большего разнообразия и случайности в хэш-функцию, позволяет достичь устойчивости к коллизиям.
buckets — это указатель на массив бакетов. В Go это ячейка памяти, где хранятся бакеты.
oldbuckets — это также указатель на массив бакетов, из которых происходит эвакуация данных, когда бакетов становится больше. Является ячейкой памяти.
// go/src/runtime/type.go
type MapType struct {
// ...more code
Hasher func(unsafe.Pointer, uintptr) uintptr
}
Hasher — это хэш-функция, которая принимает аргументы key, hash0 и возвращает hash. Пример кода:
hash := t.Hasher(noescape(unsafe.Pointer(&s)), uintptr(h.hash0))
//go/src/runtime/map.go
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket.
tophash [bucketCnt]uint8
}
tophash — массив, содержит 8 верхних байт хэшей каждого ключа в бакете.
Количество элементов в бакете — одна из важных констант
const bucketCnt = 8
Создание мапы
Мы можем объявить переменную с типом map[string]string двумя способами:- var m map[string]string
- m := make(map[string]string)
Рассмотрим создание map с использованием функции make. При создании map через make используется функция makemap.
func makemap(t *maptype, hint int, h *hmap) *hmap {
//...more code
1 // initialize Hmap
if h == nil {
h = new(hmap)
}
h.hash0 = fastrand()
2 B := uint8(0)
for overLoadFactor(hint, B) {
B++
}
h.B = B
3 if h.B != 0 {
var nextOverflow *bmap
h.buckets, nextOverflow = makeBucketArray(t, h.B, nil)
//...more code
}
return h
}
Блок 1. Проверяем наличие h *hmap. Если его нет, то инициализируем. Затем получаем hash0.
Блок 2. Рассчитываем количество бакетов B в формате log на основе hint. hint — второй аргумент в функции make(map[string]string, hint).
Блок 3. Если количество бакетов не равно 1 (log 1 = 0 = B), то выделяется память для наших бакетов.
Запись в мапу
Теперь запишем в мапу первую пару:m["apple"] = "fruit"
При записи в мапу вызывается метод (для строки):
func mapassign_faststr(t *maptype, h *hmap, s string) unsafe.Pointer {
1 if h == nil {
panic(plainError("assignment to entry in nil map"))
}
// ...more code
2 key := stringStructOf(&s)
3 hash := t.Hasher(noescape(unsafe.Pointer(&s)), uintptr(h.hash0))
// ...more code
if h.buckets == nil {
h.buckets = newobject(t.Bucket) // newarray(t.bucket, 1)
}
// ...more code
}
Шаг 1. Проверяем, была ли инициализирована наша hmap. Если нет, вызываем панику. Частая ошибка у новичков — объявлять переменную без использования make и пытаться записать в неё ключ/значение.
Шаг 2. Получаем key — указатель на структуру, в которой хранится адрес ключа "apple".
// go/SDK/cmd/runtime/string.go
type stringStruct struct {
str unsafe.Pointer
len int
}
func stringStructOf(sp *string) *stringStruct {
return (*stringStruct) (unsafe.Pointer(sp))
}
unsafe.Pointer используется как указатель на данные любого типа.
Шаг 3. Получаем hash ключа "apple" и выделяем память для нашего бакета, если не делали этого в makemap.
Переходим в следующий блок, который начинается с лейбла goto — again.
func mapassign_faststr(t *maptype, h *hmap, s string) unsafe Pointer {
// ...more code
again:
1 bucket := hash & bucketMask(h. B)
// ...more code
2 b := (*bmap) (add(h.buckets, bucket*uintptr(t.BucketSize)))
3 top := tophash(hash)
4 var insertb *bmap
var inserti uintptr
var insertk unsafe.Pointer
// ...more code
}
Шаг 1. Рассчитываем, в какой бакет будем записывать данные. В основе большинства расчетов лежат битовые операции.
// bucketMask returns 1<<b - 1, optimized for code generation.
func bucketMask(b uint8) uintptr {
return bucketShift(b) - 1
}
Функция возвращает результат операции 1 << b - 1.
Оператор << осуществляет битовый сдвиг влево. К примеру, у нас есть выражение 5 << 3. Это означает, что мы хотим сдвинуть число 5 на 3 бита влево. В этом случае:
- Представляем число 5 в двоичной системе и получаем 101.
- Выполняем сдвиг 101 на 3 бита влево и получаем 101000.
- Переводим полученное число 101000 в десятичную систему и получаем 40.
- 1 в двоичной системе равно 1.
- Выполняем сдвиг 1 на 0 бит влево и получаем 1.
- Вычитаем 1 из 1 и получаем 0.
- 5 в двоичной системе равно 101.
- 3 в двоичной системе равно 011.
- Выполняем операцию 101 & 011 и получаем 001.
- Приводим 001 к десятичной системе и получаем 1.
Шаг 2. Переходим к получению *bmap.
h.buckets — это ячейка памяти, от которой начинается бакет.
bucket — индекс бакета.
t.BucketSize=272 — размер бакета в байтах.
Функция add представляет собой простое сложение с приведением типов.
// runtime/stubs.go
func add(p unsafe.Pointer, x uintptr) unsafe.Pointer {
return unsafe.Pointer(uintptr(p) + x)
}
Если проигнорировать приведение типов и подставить значения, получим упрощенное выражение:
После выполнения следующего кода мы получим ячейку памяти. В ней хранится структура со списком верхних байтов хэша для ключей текущего бакета.
Шаг 3. Рассчитываем верхний байт по hash от "apple".
func tophash(hash uintptr) uint8 {
top := uint8(hash >> (goarch.PtrSize*8 - 8))
if top < minTopHash { // minTopHash = 5
top += minTopHash
}
return top
}
Рассмотрим работу tophash.
Для ключа "apple" значение hash=3661323553996174279, а goarch.PtrSize равно 8 для 64-битной системы. Получаем следующий код:
Здесь >> обозначает побитовый сдвиг вправо.
Число 3661323553996174279 в двоичной системе равно 11001011001111101000100101111110110011101101100111001111000111.
Делаем сдвиг на 56 бит вправо: 110010
Шаг 4. Инициализируем переменные для вставки. insertb — это ячейка в памяти, с которой начинается список верхних байтов. inserti — указывает, под каким индексом добавлять верхний байт, ключ и значение. insertk — это ячейка в памяти, с которой начинается список ключей.
После инициализации переходим к следующему блоку, который начинается с лейбла bucketloop. В этом блоке определяются insertb и inserti (пока рассмотрим без переполнения):
func mapassign_faststr(t *maptype, h *hmap, s string) unsafe.Pointer {
// ...more code
bucketloop:
for {
1 for i := uintptr(0); i < bucketCnt; i++ {
2 if b.tophash != top {
3 if isEmpty(b.tophash) && insertb == nil {
insertb = b
inserti = i
}
4 if b.tophash == emptyRest {
break bucketloop
}
continue
}
5 k := (*stringStruct)(add(unsafe.Pointer(b), dataOffset+i*2*goarch.PtrSize))
if k.len != key.len {
continue
}
if k.str != key.str && !memequal(k.str, key.str, uintptr(key.len)) {
continue
}
inserti = i
insertb = b
k.str = key.str
goto done
}
//...more code
}
//...more code
done:
//...more code
}
Для определения индекса свободной ячейки мы проходимся в цикле от 0 до длины бакета (шаг 1). На каждой итерации (шаг 2) мы проверяем наличие верхнего байта хэша.
Если такой байт существует и b.tophash == top, мы переходим к шагу 5, где сравниваем текущий ключ с ключом, уже находящимся в бакете. Если они не равны, продолжаем поиск свободной ячейки для вставки и переходим к следующей итерации. Если ключи равны, мы получаем inserti и insertb и выходим из цикла с помощью goto done.
Если условие на шаге 2 выполняется, мы переходим к шагу 3 и проверяем, является ли ячейка по индексу i пустой или нет. Если она пустая, сохраняем insertb и inserti и переходим к шагу 4, где проверяем, пустые следующие ячейки или нет. Если остальные ячейки пустые, то мы прерываем наш поиск через break bucketloop и переходим к следующему этапу.
Отличие шага 3 от шага 4 — в том, что на шаге 3 мы проверяем пустоту только текущей ячейки, а на шаге 4 мы проверяем и остальные ячейки. Это нужно, чтобы убедиться, что в бакете нет ключа с таким же значением.
Далее мы переходим к сохранению нашего верхнего байта хэш ключа, ключа и увеличению счётчика элементов в мапе:
func mapassign_faststr(t *maptype, h *hmap, s string) unsafe.Pointer {
// ...more code
bucketloop:
for {...}
// ...more code
1 insertb.tophash[inserti&(bucketCnt-1)] = top
2 insertk = add(unsafe.Pointer(insertb), dataOffset+inserti*2*goarch.PtrSize)
// store new key at insert position
3 *((*stringStruct)(insertk)) = *key
h.count++
// ...more code
done:
4 elem := add(unsafe.Pointer(insertb), dataOffset+bucketCnt*2*goarch.PtrSize+inserti*uintptr(t.ValueSize))
// ...more code
5 return elem
}
На шаге 1 мы также видим логическое сравнение «И», через которое определяем, куда сохранить наш верхний байт хэша. После этого переходим к шагу 2, где вычисляем ячейку для вставки ключа.
unsafe.Pointer(insertb) — начальная ячейка, от которой выполняется расчёт ячейки для вставки.
dataOffset — это размер списка верхних байтов хэшей, равный 8 байтам (1 байт на каждый верхний байт хэша).
goarch.PtrSize — 8 для 64-битной системы.
Если отбросить приведение типов и подставить значения, получаем упрощённое выражение:
Далее переходим к сохранению ключа (шаг 3) в соответствующую ячейку insertk.
После выполняем аналогичные шаги для получения ячейки вставки значения (шаг 4).
t.ValueSize=16 — размер значения в байтах.
Если отбросить приведение типов и подставить значения, получаем упрощённое выражение:
В конце (шаг 5) возвращается место в памяти, где будет лежать наше значение.
Пример расчета бакета
Теперь мы знаем, как рассчитать ячейку для верхнего байта хэша, ключа и значения.Наши выражения:
Получается, что ячейка для верхнего байта хэша, значения и ключа зависит от ячейки памяти, с которой начинается наш бакет. h.buckets. inserti указывает, под каким индексом мы будем добавлять верхний байт, ключ и значение. bucket — номер бакета.
Давайте рассмотрим, как выглядят бакеты в Go на практике, задав начальные условия:
h.buckets=1000 — начальный адрес, где располагаются бакеты. Количество бакетов — 1 (bucket=0). t.BucketSize=272 — размер бакета в байтах.
Тогда наши выражения приобретают такой вид:
Обратим внимание, что insertb и h.buckets совпадают. Это означает, что наш список верхних байт находится в начале бакета.
У нас есть inserti в диапазоне от 0 до 7. Размер массива верхних байт хэшей составляет 8 байт, а размер ключа и значения — 16 байт.
Тогда для inserti = 0 получаем:
Тогда для inserti = 1 получаем:
После проведения расчёта для 8 элементов мы обнаружили, что массив верхних байтов хэшей расположен в начале бакета, за которым следуют ключи, а затем значения. Также в конце бакета находится блок overflow — о нём мы поговорим подробнее в следующем разделе. Таким образом, размер нашего бакета составляет 272 байта.
Такая структура используется для упрощения поиска по бакету и получения наших значений с помощью битовых операций.
Переполнение бакетов
Мы рассмотрели, как заполняется один бакет. Но что произойдёт, когда нам понадобится записать еще одну пару в заполненный бакет? В Go используются два подхода, которые сводятся к увеличению количества бакетов:1. Увеличение общего количества бакетов и перераспределение пар по этим бакетам.
2. Создание бакета, на который даём ссылку в заполненный бакет. Если понадобится записать в заполненный, то мы запишем в тот, на который есть ссылка.
Увеличение количества бакетов в Go и распределение существующих пар называется эвакуацией. Принятие решения о выполнении эвакуации зависит от значения load factor, — это среднее заполнение бакетов. В Go значение loadFactor равно 6.5, — это означает, что процесс эвакуации начинается, когда средняя заполняемость бакетов достигает 6.5 или 80% для бакета с размером 8. Также на выполнение эвакуации в Go влияет количество связанных бакетов.
Разработчики Go оставили в комментариях результаты вычислений, по которым выбрали 6,5.
При эвакуации количество бакетов увеличивается в два раза. Текущие пары с топхэшами распределяются по этим бакетам.
Чтобы понять, как расположены бакеты в памяти, можно воспользоваться нашими упрощёнными формулами и произвести расчет для двух бакетов.
Мы увидим, что бакеты хранятся один за другим:
А эвакуация будет происходить так:
Но что, если наше распределение неравномерное? Например, у нас есть 4 бакета: в первом бакете — 5 элементов, во втором — 8, в третьем — 4 и в четвёртом — 1. Тогда мы получаем load factor = (5 + 8 + 4 + 1) / 4 = 4,5. Но мы хотим записать элемент и согласно нашим вычислениям он должен быть во втором бакете. Тогда нам поможет создание связанного бакета — overflow в Go.
Создаём новый бакет и даём на него ссылку в заполненный второй бакет. Так мы сформируем связанный список.
Теперь перейдем к записи нашей пары с переполнением. Часть кода мы уже разобрали ранее.
// ...more code
again:
bucket := hash & bucketMask(h.B)
1 if h.growing() {
growWork_faststr(t, h, bucket)
}
b := (*bmap)(add(h.buckets, bucket*uintptr(t.BucketSize)))
top := tophash(hash)
var insertb *bmap
var inserti uintptr
var insertk unsafe.Pointer
bucketloop:
for {
for i := uintptr(0); i < bucketCnt; i++ {
2 if b.tophash != top {
if isEmpty(b.tophash) && insertb == nil {
insertb = b
inserti = i
}
if b.tophash == emptyRest {
break bucketloop
}
continue
}
k := (*stringStruct)(add(unsafe.Pointer(b), dataOffset+i*2*goarch.PtrSize))
if k.len != key.len {
continue
}
if k.str != key.str && !memequal(k.str, key.str, uintptr(key.len)) {
continue
}
inserti = i
insertb = b
k.str = key.str
goto done
}
3 ovf := b.overflow(t)
if ovf == nil {
break
}
b = ovf
}
// If we hit the max load factor or we have too many overflow buckets,
// and we're not already in the middle of growing, start growing.
4 if !h.growing() && (overLoadFactor(h.count+1, h.B) || tooManyOverflowBuckets(h.noverflow, h.B)) {
hashGrow(t, h)
goto again
}
5 if insertb == nil {
insertb = h.newoverflow(t, b)
inserti = 0
}
6 insertb.tophash[inserti&(bucketCnt-1)] = top
insertk = add(unsafe.Pointer(insertb), dataOffset+inserti*2*goarch.PtrSize)
//...more code
done:
//...more code
У нас есть пара «ключ-значение», которую мы хотим записать в заполненный бакет.
Мы получили bucket, bmap и верхний байт хэша (top) в блоке again. Функция h.growing() на шаге 1 возвращает нам статус — растёт бакет в данный момент или нет. Пока мапа у нас не растёт и h.growing() вернёт false. После этого мы переходим к if b.tophash != top (шаг 2). Для лучшего понимания предполагаем, что все наши верхние байты хэшей разные, это условие верно и мы выполняем его. Но внутренние проверки будут ложными, потому что бакет полный. В результате итерация прерывается при continue, и мы переходим к шагу 3.
На нём получаем адрес нашего overflow бакета:
func (b *bmap) overflow(t *maptype) *bmap {
return *(**bmap)(add(unsafe.Pointer(b), uintptr(t.BucketSize)-goarch.PtrSize))
}
// uintptr(t.BucketSize)-goarch.PtrSize = 272 - 8 = 264
Мы видим, что overflow занимает последние 8 байт в бакете. В этот момент у нас нет связанного бакета, поэтому ovf=nil, и мы выходим из цикла с помощью break.
Затем переходим к шагу 4, где проверяем, что наша мапа не растёт и выполняется одно из условий: превышение коэффициента заполнения или наличие большого количества связанных бакетов.
С этого шага начинается разветвление: создание связанного списка или начало эвакуации.
Создание связанного списка
Если создаётся переполненный (overflow) бакет, мы не выполняем условие на шаге 4 и переходим к условию if insertb == nil (шаг 5).Здесь проверка возвращает значение true, так как на шаге 2 мы не записали insertb. Далее создаём новый бакет в функции newoverflow (метод упростил для лучшего понимания):
func (h *hmap) newoverflow(t *maptype, b *bmap) *bmap {
var ovf *bmap
ovf = (*bmap)(newobject(t.Bucket))
b.setoverflow(t, ovf)
return ovf
}
func (b *bmap) setoverflow(t *maptype, ovf *bmap) {
*(**bmap)(add(unsafe.Pointer(b), uintptr(t.BucketSize)-goarch.PtrSize)) = ovf
}
После создания бакета заполняем верхний байт хэша, key и value согласно тому же алгоритму, что и при обычной записи (шаге 6 и далее см. Запись в мапу).
Если в следующий раз захотим найти адрес и индекс вставки, то проходимся по первому заполненному бакету, понимаем, что весь бакет заполнен, переходим к шагу 3. На нём получаем ссылку на связанный бакет, переприсваиваем значение b=ovf и ищем место для вставки в этом связанном бакете.
Эвакуация
При эвакуации мы также выходим из бесконечного цикла и переходим к шагу 4. Условие считается верным, когда мапа не эвакуируется в данный момент и выполняется одно из условий: достижение коэффициента заполнения или большое количество связанных списков. Если условие верно, вызываем функцию hashGrow(t, h), внутри неё изменяем параметры мапы и выделяем память под новое количество бакетов.func hashGrow(t *maptype, h *hmap) {
// ... more code
oldbuckets := h.buckets
newbuckets, nextOverflow := makeBucketArray(t, h.B+bigger, nil)
// ... more code
h.B += bigger
h.flags = flags
h.oldbuckets = oldbuckets
h.buckets = newbuckets
// ... more code
}
После hashGrow(t, h) переходим к инструкции goto again, которая переводит нас в блок again. Здесь на шаге 1 условие истинно, так как на прошлом шаге мы записали в oldbuckets предыдущий бакет.
func (h *hmap) growing() bool {
return h.oldbuckets != nil
}
Внутри условия вызывается метод growWork_faststr(t, h, bucket), в котором начинается перераспределение верхних байтов хэшей, ключей и значений в новый бакет. За один вызов growWork_faststr может происходить перераспределение до двух бакетов. Они перераспределяются вместе с overflow. Эвакуация происходит инкрементально и выполняется при записи и удалении ключей. Реальный пример:
Эвакуация становится одной из причин, почему мы не можем обратиться к ключу по адресу, так как мы не можем предсказать, в каком месте будет находиться наша пара. Возможно, она уже находится в новом бакете, а возможно, еще в старом. Кроме того, ясно, что процесс эвакуации данных не является бесплатным, и чтобы избежать его, можно заранее определить количество элементов в нашей мапе.
myMap := make(map[string]string, 1000)
Если вы скажете, сколько элементов будет на этапе создания мапы, выделится нужное количество бакетов под это количество элементов и тогда вы избежите эвакуации.
Чтение из мапы
В Go можно получить значение двумя способами:- Получение только значения:
name := m["apple"]
Вызывается функция func mapaccess1_faststr(t *maptype, h *hmap, ky string) unsafe.Pointer - Получение значения и параметра, обозначающего существование этого ключа в мапе.
name, ok := m["apple"]
Вызывается функция func mapaccess2_faststr(t *maptype, h *hmap, ky string) (unsafe.Pointer, bool)
func mapaccess1_faststr(t *maptype, h *hmap, ky string) unsafe.Pointer {
// ...more code
1 if h == nil || h.count == 0 {
return unsafe.Pointer(&zeroVal[0])
}
// ...more code
2 key := stringStructOf(&ky)
if h.B == 0 {
// ...more code
return unsafe.Pointer(&zeroVal[0])
}
dohash:
3 hash := t.Hasher(noescape(unsafe.Pointer(&ky)), uintptr(h.hash0))
m := bucketMask(h.B)
4 b := (*bmap)(add(h.buckets, (hash&m)*uintptr(t.BucketSize)))
5 if c := h.oldbuckets; c != nil {
// ...more code
oldb := (*bmap)(add(c, (hash&m)*uintptr(t.BucketSize)))
if !evacuated(oldb) {
b = oldb
}
}
top := tophash(hash)
6 for ; b != nil; b = b.overflow(t) {
for i, kptr := uintptr(0), b.keys(); i < bucketCnt; i, kptr = i+1, add(kptr, 2*goarch.PtrSize) {
7 k := (*stringStruct)(kptr)
if k.len != key.len || b.tophash != top {
continue
}
if k.str == key.str || memequal(k.str, key.str, uintptr(key.len)) {
return add(unsafe.Pointer(b), dataOffset+bucketCnt*2*goarch.PtrSize+i*uintptr(t.ValueSize))
}
}
}
8 return unsafe.Pointer(&zeroVal[0])
}
На шаге 1 мы проверяем, инициализирована ли хэшмапа и содержит ли она записи. Если нет, то просто возвращаем нулевое значение для нашего типа.
На втором шаге получаем адрес структуры ключа. Как она устроена, можно посмотреть ранее в функции assign. Затем переходим к проверке количества бакетов. Если h.B = 0, это означает, что у нас 1 бакет (помним про логарифм). Если условие верно, ищем ключ в единственном бакете. Если не находим, возвращаем нулевое значение для нашего типа.
Рассмотрим подробнее поиск по двум бакетам.
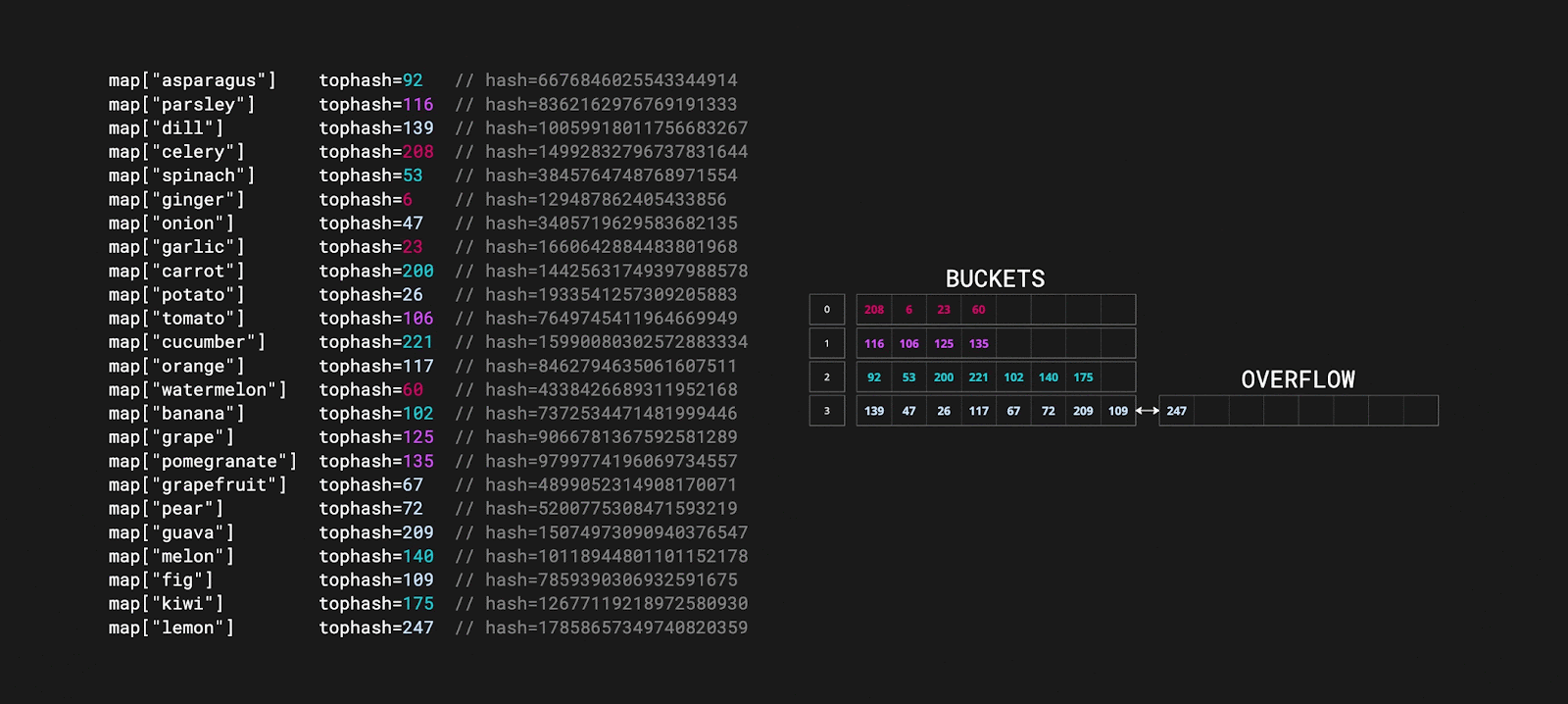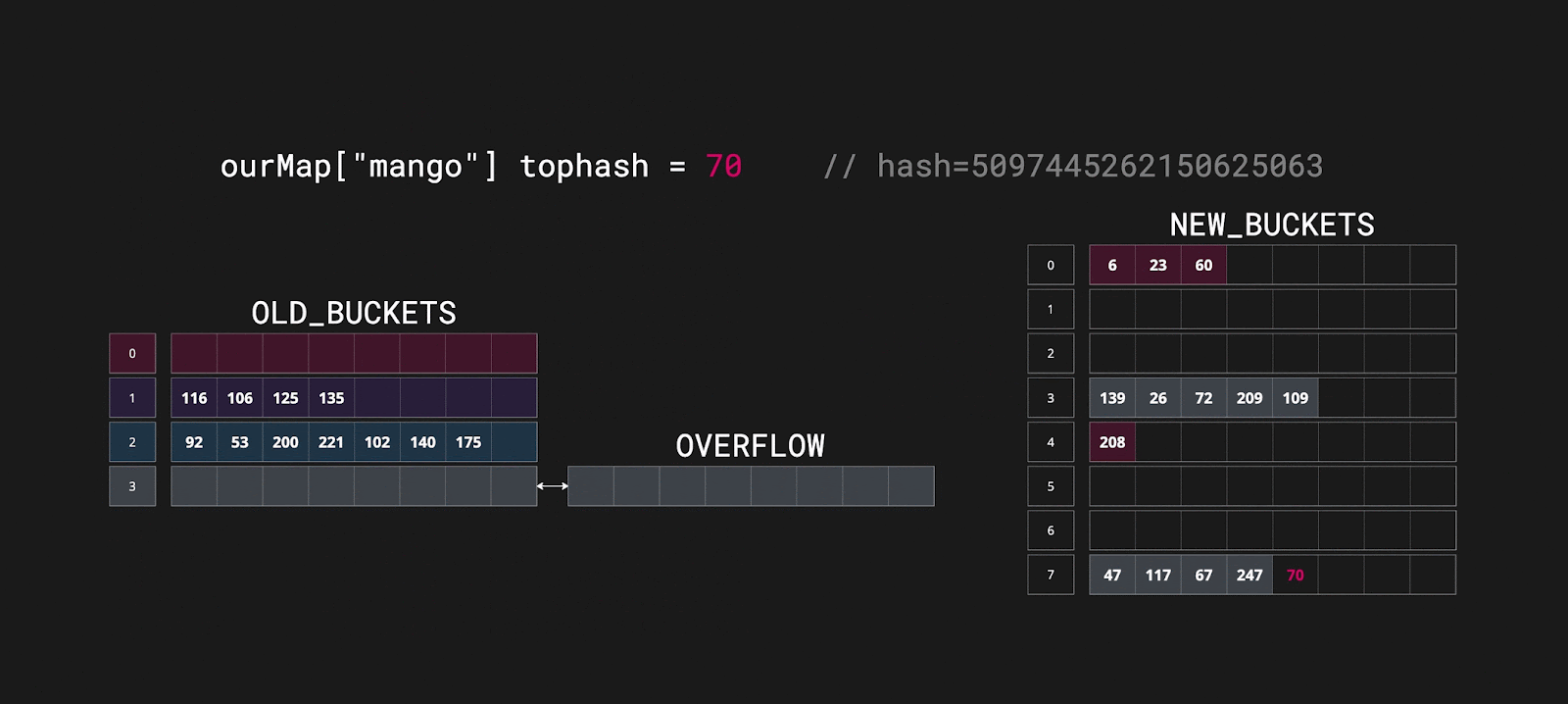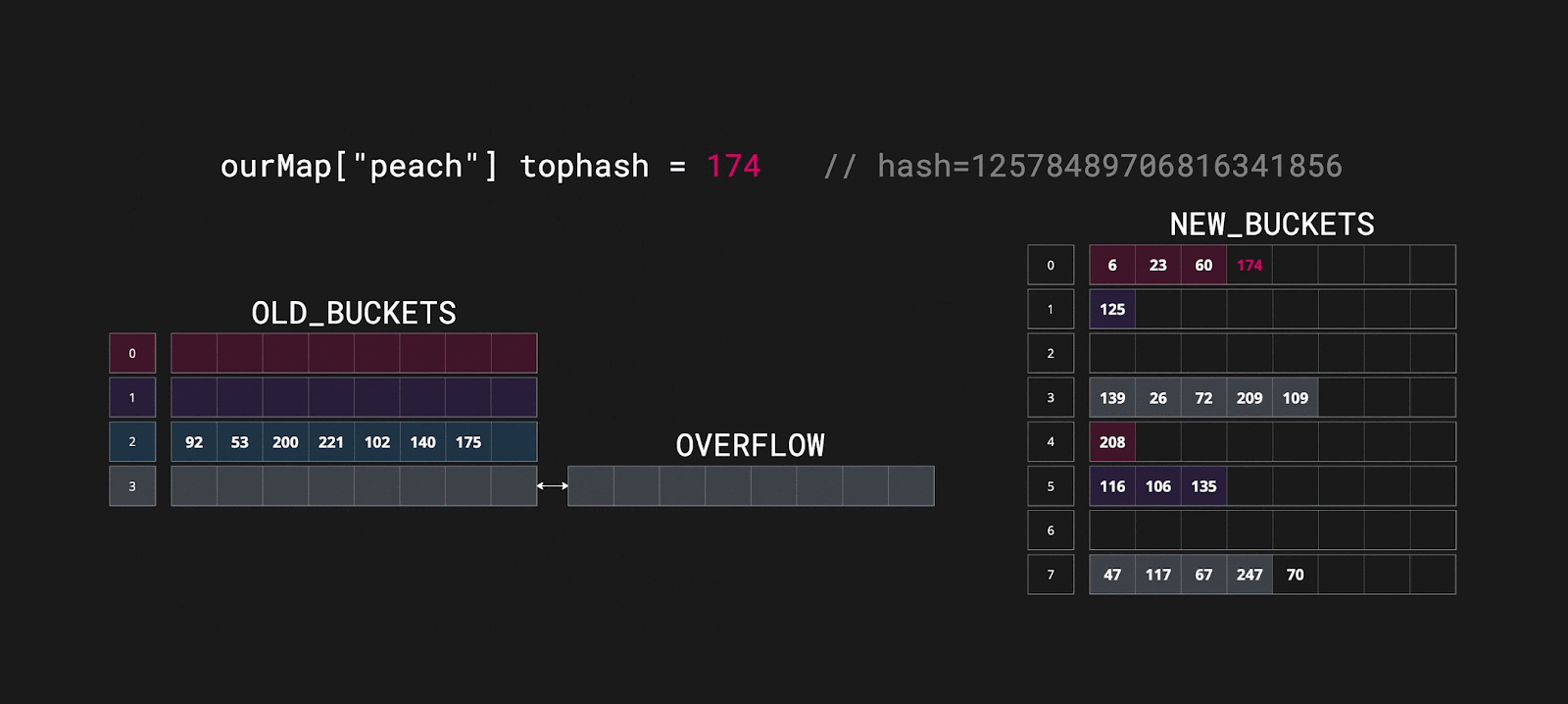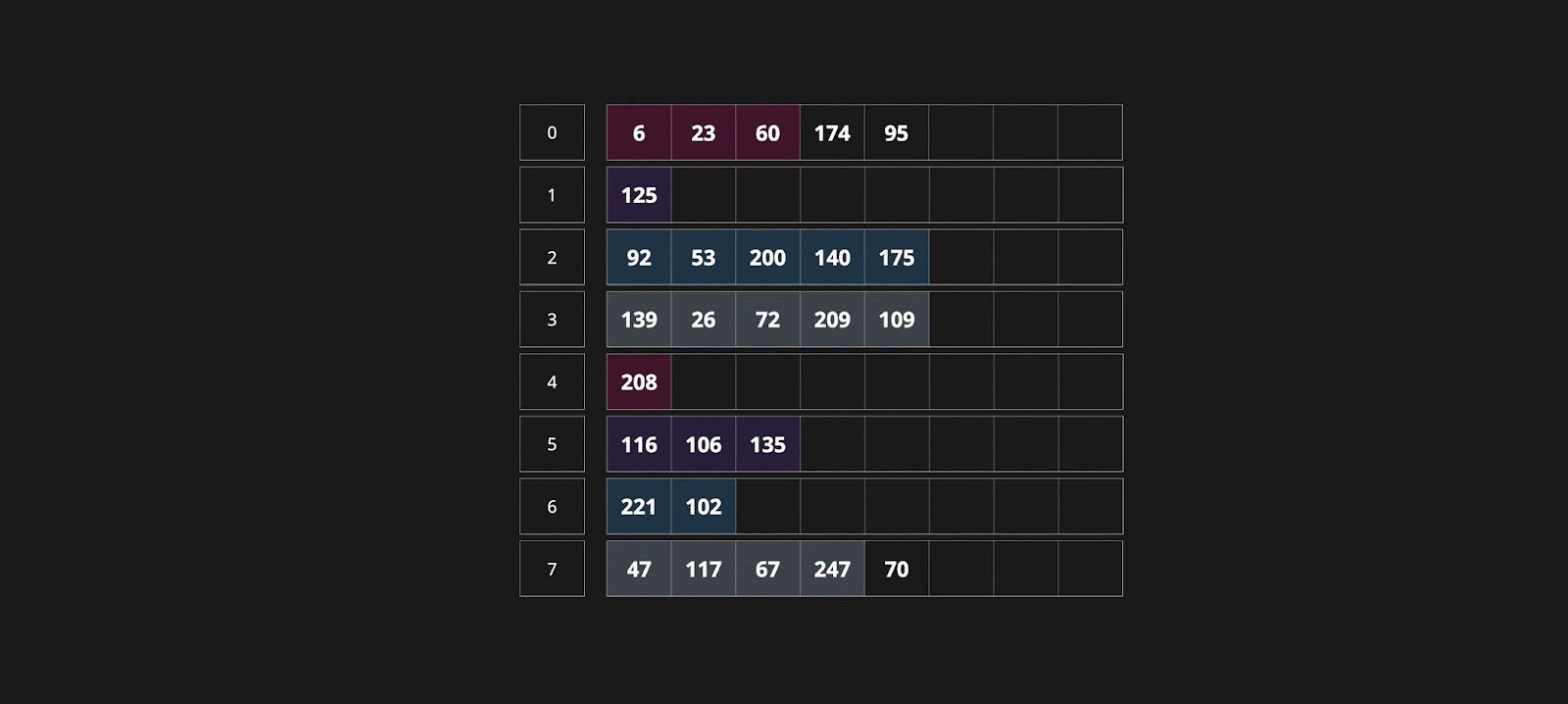
У нас есть два бакета, поэтому h.B = 1. Ниже представлены ключи, которые находятся в каждом бакете и их хэш:
Bucket 0 | | Bucket 1 | |
key | hash | key | hash |
"apple 0" | 18181302390444278678 | "apple 1" | 11280555957917037065 |
"apple 4" | 16499847109860801832 | "apple 2" | 17367488952475712717 |
"apple 5" | 10456081677947574620 | "apple 3" | 13693750386711854567 |
"apple 6" | 12140854452082777592 | "apple 7" | 7760656414049467263 |
"apple 9" | 7829506238846544754 | "apple 8" | 16674080395332218175 |
"apple 10" | 3232182299567472732 | | |
"apple 11" | 11891753136885307068 | | |
а := ourMap["apple 7"]
Начнём с шага 3. Таким же образом, как и при assign’е, мы получаем хэш нашего ключа. Дальше переходим к битовой маске (подробнее можно посмотреть при assign):
На шаге 4 на основе битовой маски определяем, в каком бакете находится наш хэш.
m=1 , t.BucketSize=272 , h.buckets=1000 , hash для “apple 7” = 7760656414049467263.
- Приводим число 7760656414049467263 к двоичной системе и получаем 110101110110011011000111110010000001111010001100111101101111111.
- Сравниваем полученное число с 1 при помощи операции побитового И: 110101110110011011000111110010000001111010001100111101101111111 & 1.
Результат равен 1. hash&m = 1. - Теперь у нас есть индекс нашего бакета. Но зная только начальный адрес всех бакетов, мы можем вычислить адрес нужного бакета относительно начальной точки. Для этого прибавляем к начальной точке нужную длину. Нужная длина определяется как размер бакетов, умноженный на их количество. В нашем случае мы хотим пропустить нулевой бакет и перейти к следующему. Поэтому получаем следующее упрощенное выражение (без приведения типов):
После получения нужного бакета, на шаге 5 проверяем, есть ли бакеты, из которых происходила эвакуация. Если есть h.oldbuckets — это означает, что эвакуация мапы = всех старых бакетов еще не завершена. Тогда надо проверить, эвакуировался ли бакет, полученный на прошлом шаге. Если нет, то продолжаем искать значение по нему.
На следующем шаге мы вычисляем верхний байт хэша. Это цикл, который сначала выполняет поиск по текущему бакету и если есть связанные — ещё и по ним:
for i, kptr := uintptr(0), b.keys(); i < bucketCnt; i, kptr = i+1, add(kptr, 2*goarch.PtrSize) {
// ...more code
}
Его можно упростить в следующий:
kptr := b.keys()
for i := uintptr(0); i < bucketCnt; i = i+1 {
// ...more code
kptr = add(kptr, 2*goarch.PtrSize)
}
b.key() — получение адреса в памяти, где находятся ключи для пар. Адрес ключей совпадает с адресом первого ключа. Если бакет начинается с ячейки 1000, то b.key() вернет 1008, пропуская верхние байты хэшов.
kptr = add(kptr, 2goarch.PtrSize) — сдвиг на следующий ключ
Фактически, этот цикл сводится к перебору всех ключей в бакете.
Внутри цикла мы приводим указатель на адрес ключа к нужному типу (шаг 7). Затем сравниваем длину ключа, для которого ищем значение, с длиной ключа из бакета, и сравниваем наши топ хэши.
После этого либо находим нужный ключ и возвращаем нужное значение, либо переходим к другому ключу из бакета или связанного бакета. Если в результате нужный ключ не нашёлся, возвращаем нулевое значение для нашего типа (шаг 8).
Вывод
Мы в подробностях рассмотрели, как работают мапы в Go. Изучили процесс записи и чтения данных в мапы, обсудили проблему переполнения и эвакуации элементов, даже до уровня отдельных битов. Внимательно рассмотрели важность передачи количества элементов при создании мапы и поняли, почему нельзя обращаться к ключу или значению по адресу.
Мапы в Go: уровень Pro
В мире программирования часто встречаются две структуры данных: массивы, или списки; и мапы — словари или объекты. В этой статье рассмотрим, как устроены мапы в языке Go и как это реализовано в коде....
habr.com