Каждый, кто работал с большими кластерами, знает: данные все время растут. Рано или поздно перед разработчиками распределенных систем встает задача масштабирования. Сейчас найти место для хранения данных не проблема, но как быть с доработкой и настройкой приложений? Доработки можно избежать, если заранее заложить в систему возможность масштабирования. Можно разделить узлы приложения по типу выполняемой функциональности и развёртывать только то, что необходимо.
Меня зовут Игорь, я работаю в команде Tarantool. У нас большой опыт разработки высоконагруженных продуктов, например, систем хранения данных для крупных ритейлеров или операторов сотовой связи. Сегодня я расскажу о принципах масштабирования наших кластеров и покажу типовой пример. Будет интересно всем, кто работает с большими данными и задумывается о масштабировании.
Это дополненная версия доклада, который я рассказывал на SaintHighload++ 2021.

Роутер — первое, что проходят клиентские запросы, попадая в кластер. Это узел, который перенаправляет входящие запросы на другие узлы. Именно роутер связывает клиентов с их данными.

Далее запросы от клиентов попадают с помощью роутера в другую категорию элементов кластера — хранилища. Они хранят данные, записывают и отдают их по запросу от роутера.

Каждый узел кластера выполняет свою роль, то есть определенную логику. При масштабировании кластера мы можем добавить в него новый узел приложения и назначить ему одну из доступных ролей. Например, если нам понадобится увеличить место для хранения данных, мы можем добавить узел с ролью «хранилище». Другие хранилища сами позаботятся о том, как перераспределить данные на новый узел, а роутер начнет отправлять к нему запросы.
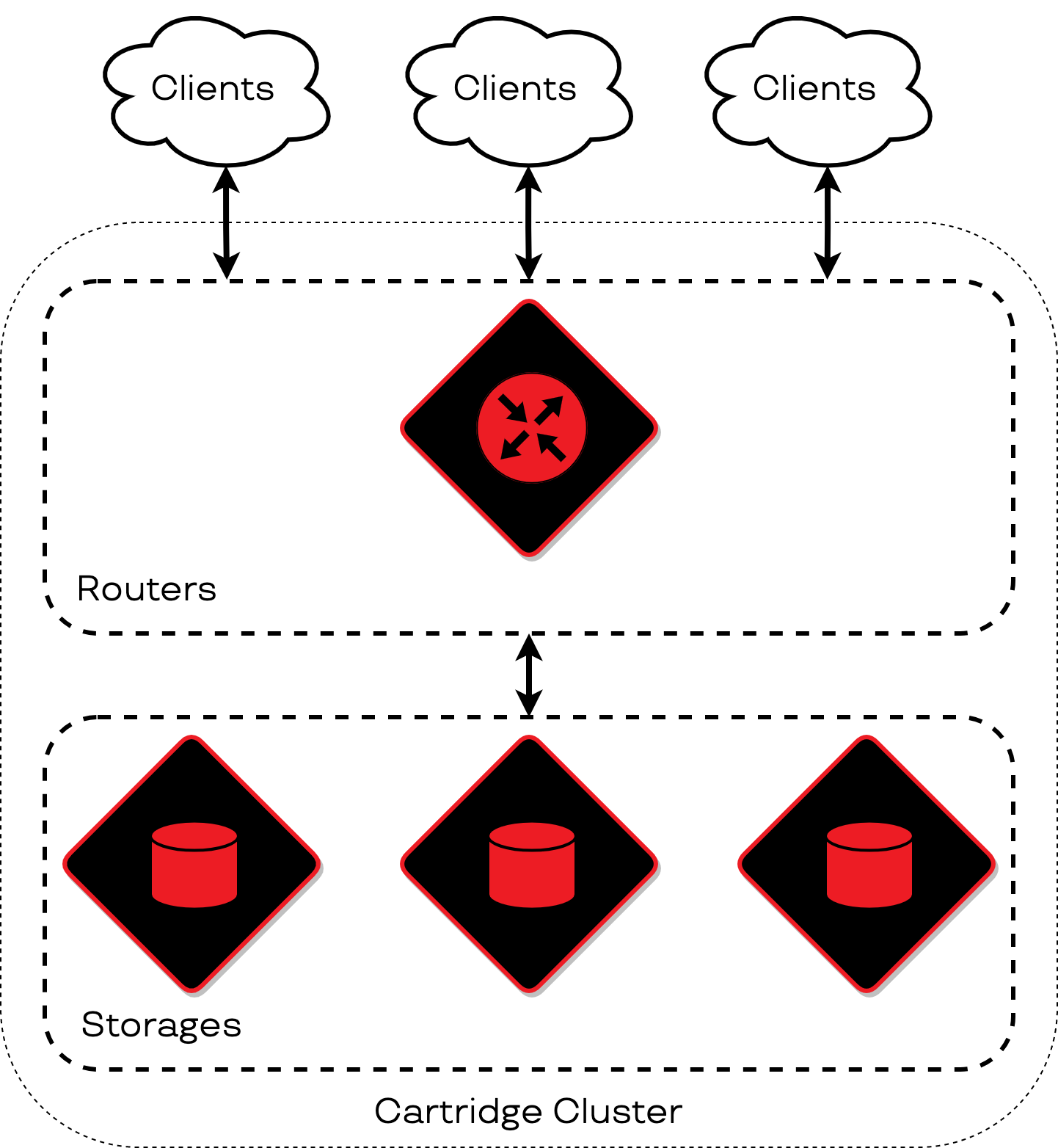
Аналогично и с роутерами. Если нам потребуется увеличить количество узлов, на которые клиенты будут отправлять запросы, мы должны добавить в кластер новый узел с ролью «роутер» и позаботиться о том, чтобы запросы проходили через него тоже. Роутеры при этом являются равнозначными и будут пересылать запросы на все хранилища.

Следующим важным элементом кластера будет failover-coordinator. Это узел кластера, который заботится о доступности других узлов на запись. Состояние кластера при этом он будет записывать во внешнее хранилище, которое называется state-provider. Оно должно быть независимым от остального кластера и удовлетворять требованиям к надежности.

Кластер может быть расширен узлами с новыми ролями. Например, при работе с кластером нам понадобится реплицировать данные из внешнего хранилища. Для этого необходимо добавить узел, выполняющий такую логику. Он будет связываться с внешним хранилищем и отправлять данные на роутеры, чтобы распределить их по кластеру.

Для создания кластера мы можем воспользоваться Cartridge.
Давайте теперь посмотрим, что лежит в основе Cartridge.

Пример настройки репликации на мастере:
box.cfg{
listen = 3301,
read_only = false,
replication = {
'127.0.0.1:3301',
'127.0.0.1:3302',
},
}
И на реплике:
box.cfg{
listen = 3302,
read_only = true,
replication = {
'127.0.0.1:3301',
'127.0.0.1:3302',
},
}
Vshard оперирует двумя понятиями — vshard.storage и vshard.router. В хранилищах находятся бакеты с данными, также они обеспечивают ребалансировку данных в случае появления новых экземпляров. А роутеры используются для отправки запросов к узлам хранения данных.
В vshard нужно на каждом узле настраивать роутеры и хранилища. При расширении кластера на vshard нужно либо изменять код приложения, либо писать обёртку вокруг vshard, она будет сама настраивать экземпляры при каждом добавлении узлов.
Пример конфигурирования vshard на экземплярах Tarantool:
local sharding = {
['aaaaaaaa-0000-4000-a000-000000000000'] = {
replicas = {
['aaaaaaaa-0000-4000-a000-000000000011'] = {
name = 'storage',
master = true,
uri = "sharding ass@127.0.0.1:30011"
ass@127.0.0.1:30011"
},
}
}
}
vshard.storage.cfg(
{
bucket_count = 3000,
sharding = sharding,
...
},
'aaaaaaaa-0000-4000-a000-000000000011'
)
vshard.router.cfg({sharding = sharding,})
Какая может быть функциональность у ролей?
role_name = 'custom-role',
init = init,
validate_config = validate_config,
apply_config = apply_config,
stop = stop,
dependencies = {
'another-role',
},
}
Каждая роль имеет стандартный API:
Встроенные роли:
Рассмотрим пример. Пусть мы написали свою роль custom-storage, в которой описано создание таблиц данных. Она будет зависеть от crud-storage, чтобы мы могли воспользоваться упрощенными интерфейсами для получения и записи данных в наше хранилище. При этом crud-storage уже зависит от роли vshard-storage, что позволяет нам не заботиться о том, как наши данные шардируются. В коде это выглядит вот так:
app/roles/custom-storage.lua
return {
role_name = 'custom-storage',
dependencies = {
'crud-storage',
},
}
cartridge/roles/crud-storage.lua
return {
role_name = 'crud-storage',
dependencies = {
'vshard-storage',
},
}
Cartridge гарантирует порядок запуска ролей. Значит в роли custom-storage мы можем пользоваться всеми возможностями ролей vshard-storage и crud-storage и не бояться, что они еще не проинициализированы.

tarantool ./init.lua
local ok, err = cartridge.cfg({
roles = {
'cartridge.roles.vshard-storage',
'cartridge.roles.vshard-router',
'cartridge.roles.metrics',
'app.roles.custom’,
},
... -- cartridge opts
}, {
... -- tarantool opts
})

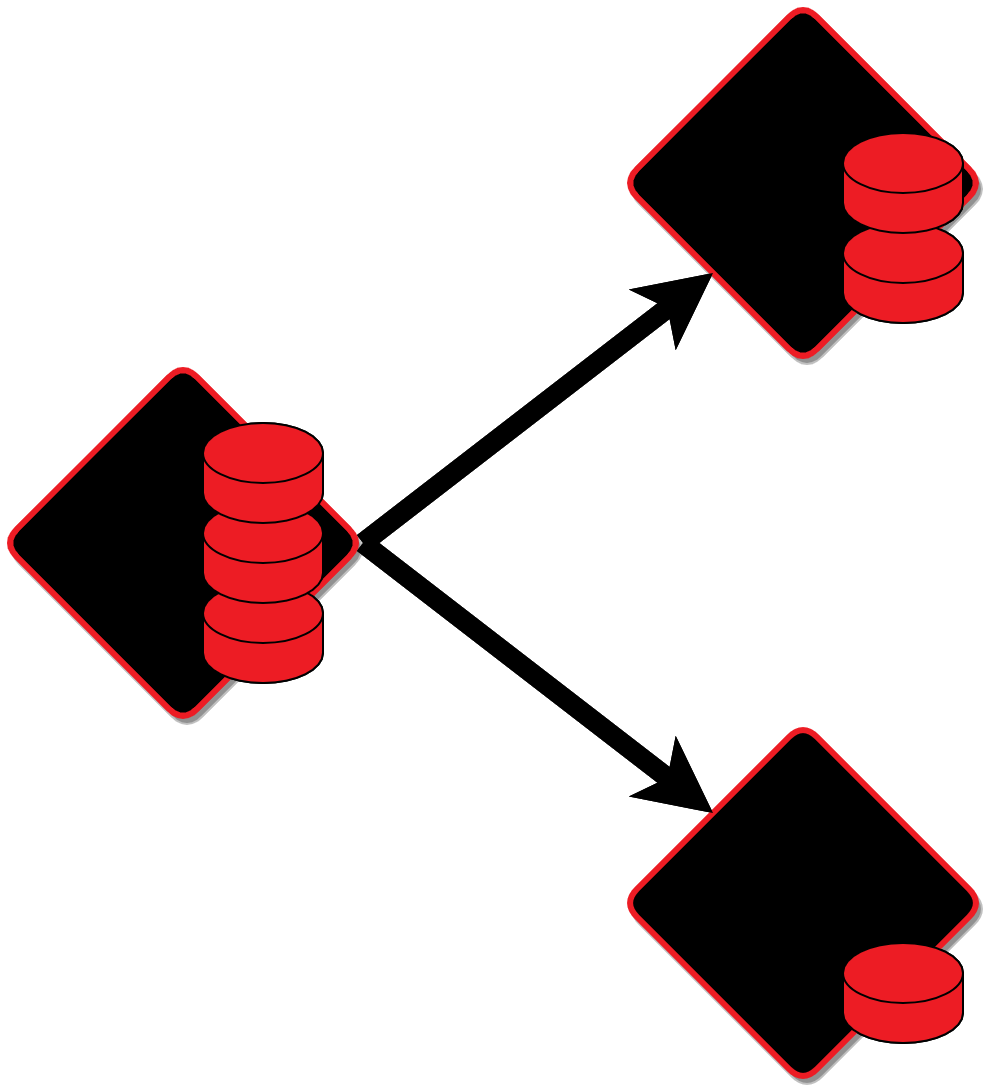
Новые реплики добавляем, когда нужно дополнительное резервирование, например, появился новый резервный ЦОД. Или когда хотим увеличить доступность наборов реплик на чтение, например, если большая часть запросов на чтение отправляется на реплику.

Добавляем новые шарды, когда на экземплярах память заполняется на 60-80 %. Можно и раньше, если видим на графиках потребления памяти постоянный рост и можем прогнозировать время, когда место закончится.
Роутеры добавляем, если видим пиковую нагрузку CPU около 80-100 %, а также по бизнес-метрикам. Например, увеличилось число пользователей у кластера, выросла нагрузка.
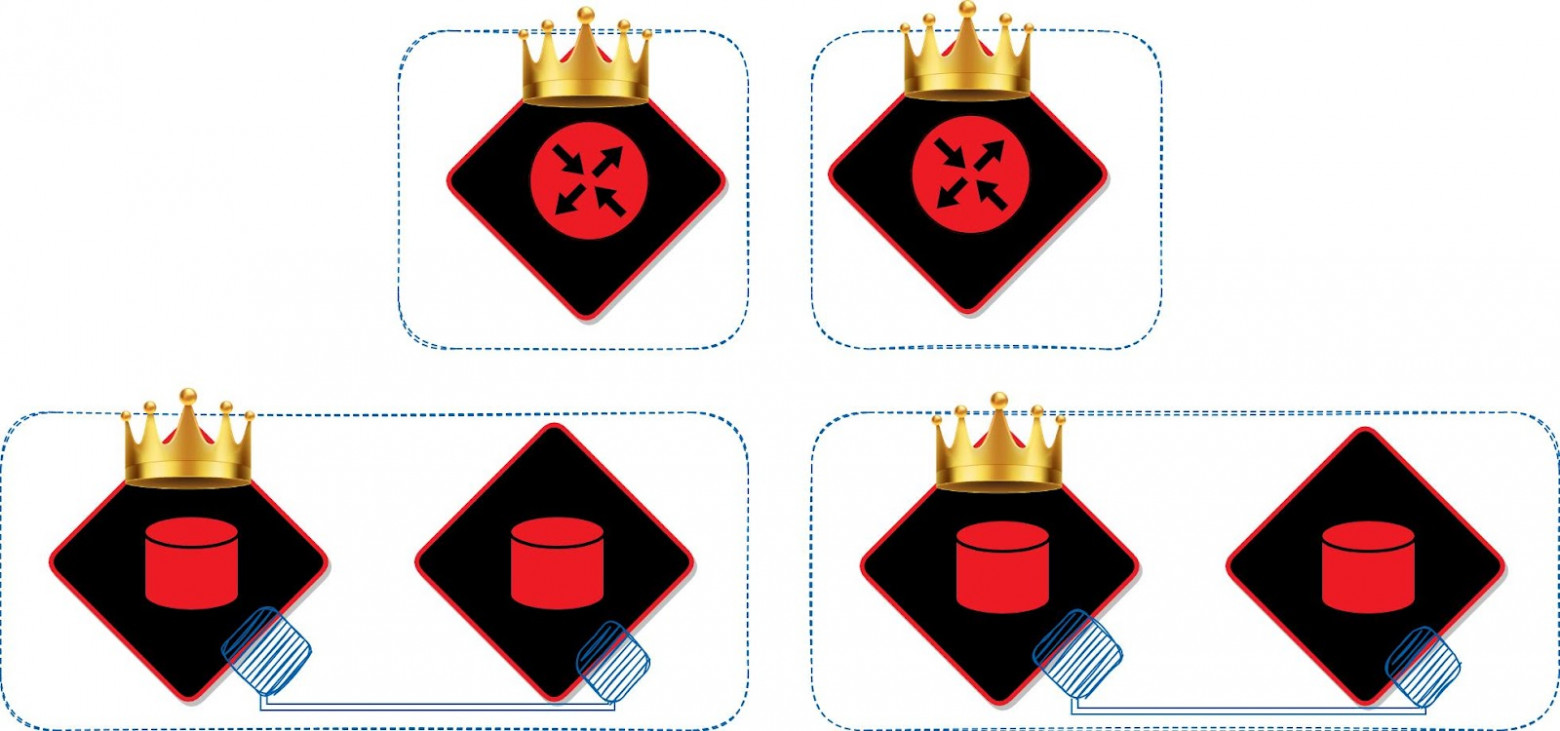
Добавляем новые роли, если меняется или дополняется бизнес-логика приложений, или если вдруг нужен дополнительный мониторинг. Например, можно включить в кластер модули metrics или tracing.
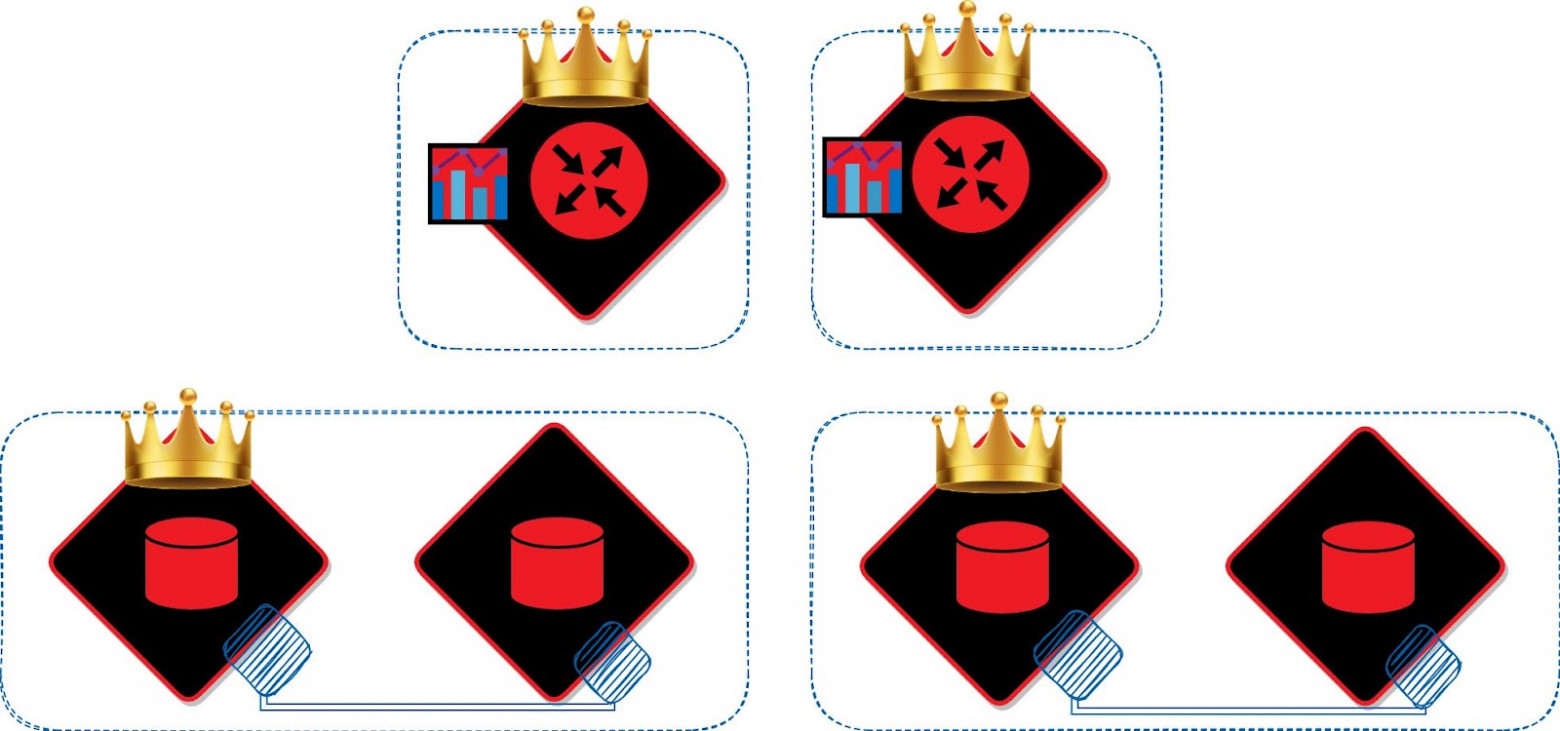
Нужно отметить, что добавлять в кластер новые экземпляры можно без изменения кода, как и включать существующие роли на имеющихся наборах реплик. Но при добавлении новых ролей, которые раньше отсутствовали в кластере, нужно добавить их в init.lua и перезапустить приложение.
Помимо этого, необходимо помнить, что любому экземпляру в кластере можно назначить несколько ролей. Любой экземпляр может одновременно быть и роутером, и хранилищем, и репликатором, а также выполнять любую кастомную логику.
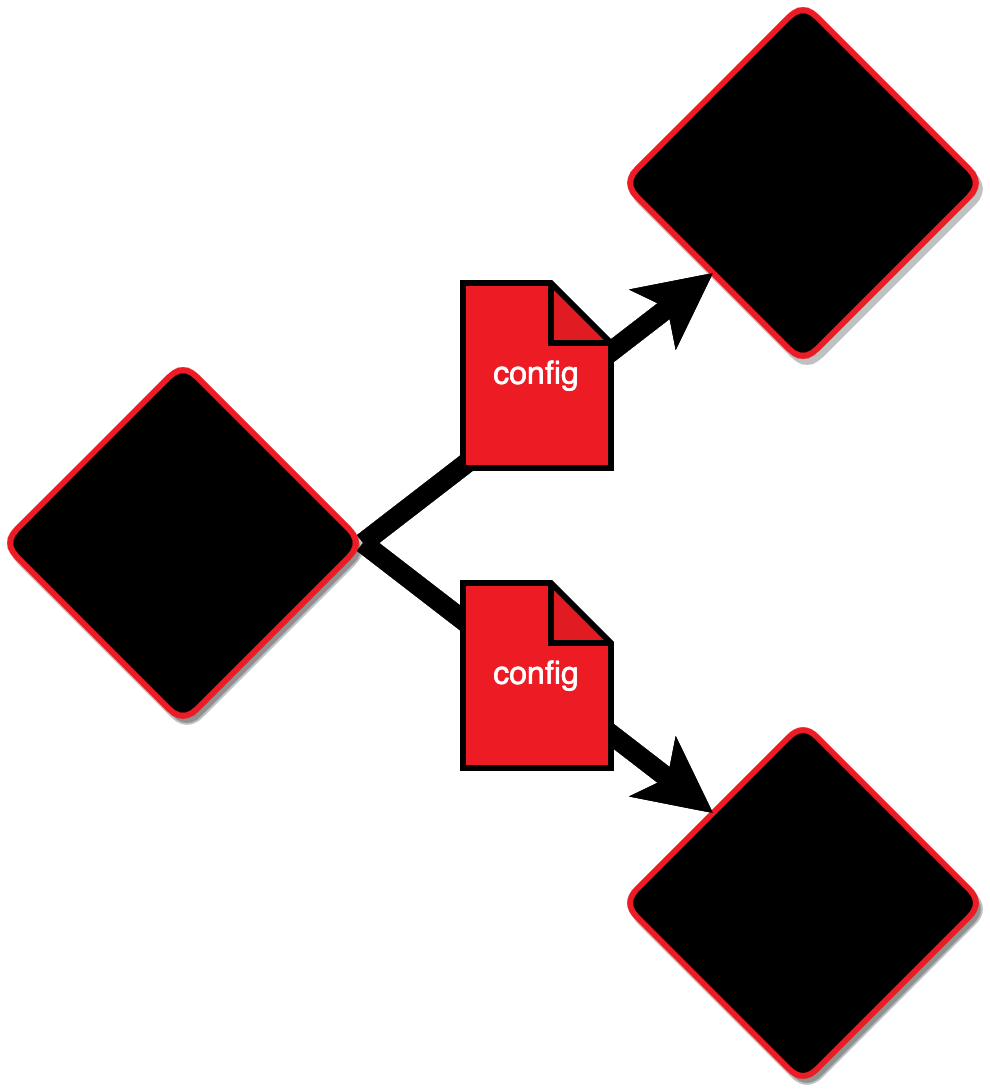
Давайте посмотрим на механизм распространения новой конфигурации. Пусть на одном из узлов она поменялась, и после этого конфигурация распространится на все остальные экземпляры.

Каждый экземпляр, получивший изменения конфигурации, вызовет свои функции validate_config, чтобы проверить, можно ли применить полученную конфигурацию. Если вдруг хотя бы один из экземпляров не сможет провалидировать измененную конфигурацию, она будет отменена на всех остальных экземплярах, а пользователь, который пытался её применить, получит ошибку.
Если же конфигурация была валидной, то Cartridge дожидается, пока каждый из инстансов в кластере скажет, что проверка validate_config завершилась успешно и конфигурацию можно применять.

Теперь Cartridge выполнит все функции apply_config и применит новую конфигурацию на каждом экземпляре приложения. Она будет сохранена на диске взамен старой конфигурации.

Но если вдруг во время применения конфигурации что-то пошло не так и стадия apply_config выполнилась с ошибкой, Cartridge выведет в WebUI информацию об этом и предложит переприменить конфигурацию.
Failover-coordinator следит за тем, чтобы в наборе реплик был доступен хотя бы один мастер.
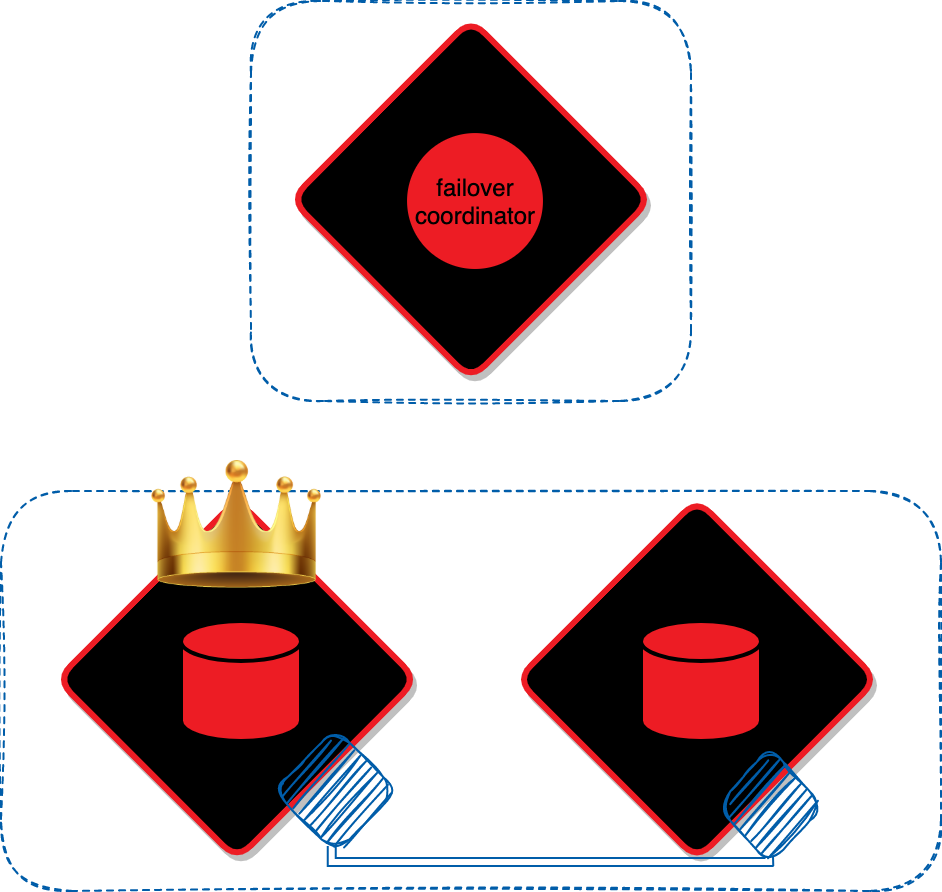
Если вдруг мастер в наборе упадет или перестанет отвечать на запросы, failover-coordinator узнает об этом и назначит одну из реплик в том же наборе мастером.

При этом информация о том, кто является текущим мастером, будет сохранена во внешнем хранилище. Теперь даже если старый мастер вернется в рабочее состояние, принимать запросы на запись он уже не сможет. Новый мастер будет оставаться таковым до тех пор, пока он сам не упадет или не перестанет быть доступен для запросов.


 habr.com
habr.com
Меня зовут Игорь, я работаю в команде Tarantool. У нас большой опыт разработки высоконагруженных продуктов, например, систем хранения данных для крупных ритейлеров или операторов сотовой связи. Сегодня я расскажу о принципах масштабирования наших кластеров и покажу типовой пример. Будет интересно всем, кто работает с большими данными и задумывается о масштабировании.
Это дополненная версия доклада, который я рассказывал на SaintHighload++ 2021.
Задача
При разработке высоконагруженных приложений с данными нам нужно решить три задачи:- Масштабируемость. Наращиваем данные и бизнес-логику.
- Надежность. Нужны резервные узлы для доступа к данным. Нужен механизм, который делает кластер всегда доступным для записи, даже в случае отказа некоторых узлов.
- Поддерживаемость. Нужны инструменты для управления и мониторинга. Нужно расширять кластер без изменения кода приложения
Архитектура кластера
Любой кластер всегда начинается с его клиентов — приложений или систем, которые будут взаимодействовать с кластером, писать туда данные и читать их.
Роутер — первое, что проходят клиентские запросы, попадая в кластер. Это узел, который перенаправляет входящие запросы на другие узлы. Именно роутер связывает клиентов с их данными.
Далее запросы от клиентов попадают с помощью роутера в другую категорию элементов кластера — хранилища. Они хранят данные, записывают и отдают их по запросу от роутера.
Каждый узел кластера выполняет свою роль, то есть определенную логику. При масштабировании кластера мы можем добавить в него новый узел приложения и назначить ему одну из доступных ролей. Например, если нам понадобится увеличить место для хранения данных, мы можем добавить узел с ролью «хранилище». Другие хранилища сами позаботятся о том, как перераспределить данные на новый узел, а роутер начнет отправлять к нему запросы.
Аналогично и с роутерами. Если нам потребуется увеличить количество узлов, на которые клиенты будут отправлять запросы, мы должны добавить в кластер новый узел с ролью «роутер» и позаботиться о том, чтобы запросы проходили через него тоже. Роутеры при этом являются равнозначными и будут пересылать запросы на все хранилища.
Следующим важным элементом кластера будет failover-coordinator. Это узел кластера, который заботится о доступности других узлов на запись. Состояние кластера при этом он будет записывать во внешнее хранилище, которое называется state-provider. Оно должно быть независимым от остального кластера и удовлетворять требованиям к надежности.
Кластер может быть расширен узлами с новыми ролями. Например, при работе с кластером нам понадобится реплицировать данные из внешнего хранилища. Для этого необходимо добавить узел, выполняющий такую логику. Он будет связываться с внешним хранилищем и отправлять данные на роутеры, чтобы распределить их по кластеру.
Для создания кластера мы можем воспользоваться Cartridge.
Cartridge
Это фреймворк для разработки кластерных приложений. Cartridge сам управляет кластером и заботится о шардировании, позволяет описывать бизнес-логику и схемы данных с помощью механизма ролей, имеет failover, который позаботится о доступности экземпляров приложения на запись. Для Cartridge создано множество дополнительных инструментов, которые можно встраивать в CI/CD-конвейеры и использовать для администрирования запущенного кластера. Также для Cartridge написана Ansible-роль, имеются модуль для интеграционного тестирования, утилита для создания приложения из шаблона и локального запуска кластера, есть модуль для сбора метрик и инфопанель для Grafana.Давайте теперь посмотрим, что лежит в основе Cartridge.
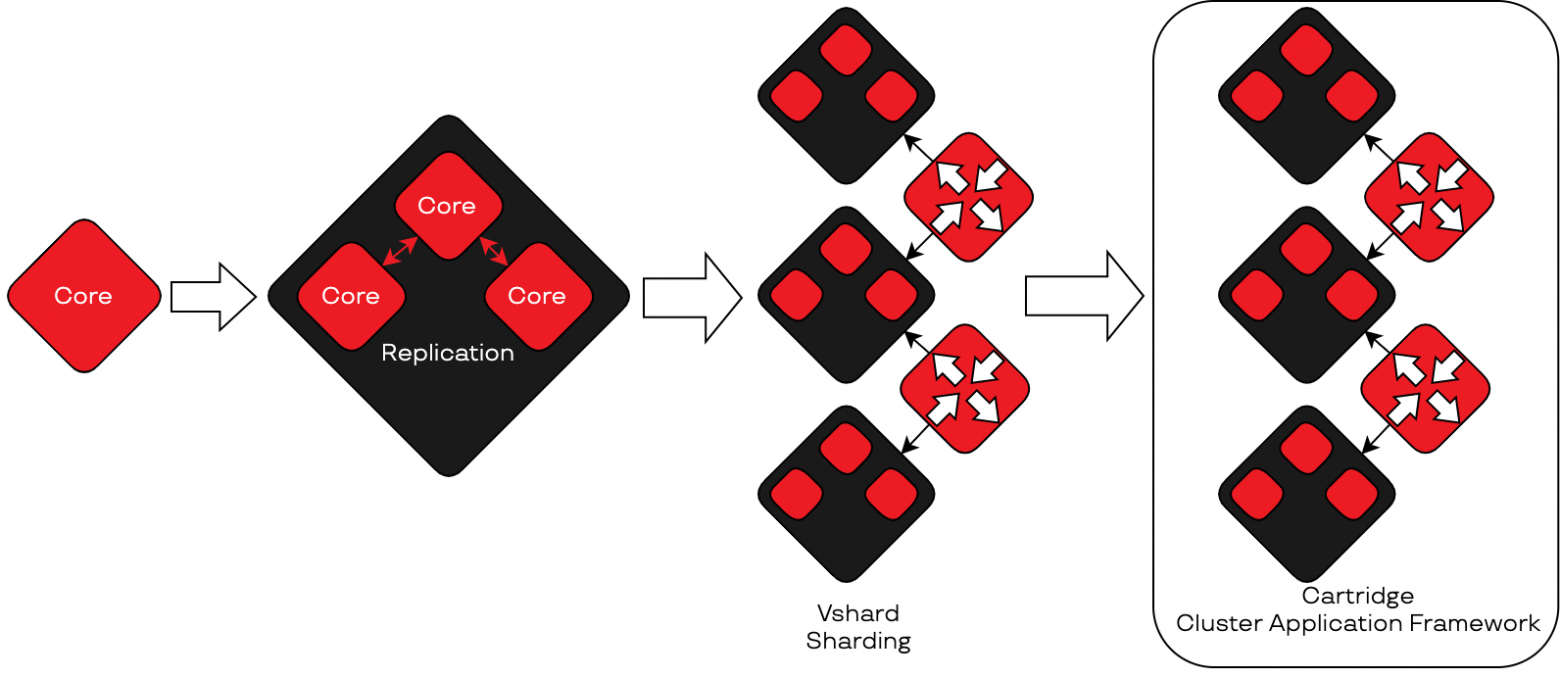
Tarantool
Cartridge — это фреймворк на базе нескольких экземпляров Tarantool, платформы для in-memory вычислений. Она одновременно является и in-memory базой данных, и сервером приложений, написанным на Lua. Tarantool очень быстрый за счет хранения данных в оперативной памяти, но при этом надежный. Он обеспечивает сброс снепшотов с данными на диск, позволяет настроить репликацию и шардирование.Репликация
Экземпляры Tarantool можно объединить в набор реплик (replica set) — это узлы, связанные между собой асинхронной репликацией. При настройке можно указать, на каком экземпляре данные будут доступны только на чтение. Те экземпляры, которые могут писать данные, мы будем называть «мастерами», а остальные — «репликами».
Пример настройки репликации на мастере:
box.cfg{
listen = 3301,
read_only = false,
replication = {
'127.0.0.1:3301',
'127.0.0.1:3302',
},
}
И на реплике:
box.cfg{
listen = 3302,
read_only = true,
replication = {
'127.0.0.1:3301',
'127.0.0.1:3302',
},
}
Шардирование
В Tarantool есть специальный модуль для шардирования данных — vshard. Он позволяет разделить ваши данные на куски, которые будут храниться на разных узлах приложения.Vshard оперирует двумя понятиями — vshard.storage и vshard.router. В хранилищах находятся бакеты с данными, также они обеспечивают ребалансировку данных в случае появления новых экземпляров. А роутеры используются для отправки запросов к узлам хранения данных.
В vshard нужно на каждом узле настраивать роутеры и хранилища. При расширении кластера на vshard нужно либо изменять код приложения, либо писать обёртку вокруг vshard, она будет сама настраивать экземпляры при каждом добавлении узлов.
Пример конфигурирования vshard на экземплярах Tarantool:
local sharding = {
['aaaaaaaa-0000-4000-a000-000000000000'] = {
replicas = {
['aaaaaaaa-0000-4000-a000-000000000011'] = {
name = 'storage',
master = true,
uri = "sharding
ass@127.0.0.1:30011"},
}
}
}
vshard.storage.cfg(
{
bucket_count = 3000,
sharding = sharding,
...
},
'aaaaaaaa-0000-4000-a000-000000000011'
)
vshard.router.cfg({sharding = sharding,})
Собираем всё вместе
Доступная в Tarantool функциональность является основой для Cartridge. Чтобы построить кластер, нам нужно взять несколько экземпляров Tarantool, настроить между ними репликацию, затем добавить шардирование и автоматизировать добавление новых узлов. Помимо этого, Cartridge предоставляет еще несколько возможностей, недоступных в ванильном Tarantool:- Фейловер.
- Автоматическая настройка шардирования при добавлении новых узлов.
- WebUI для мониторинга кластера.
Роли экземпляров в Cartridge
До этого я уже показал, что каждый экземпляр в кластере выполняет свою роль. Роли в Cartridge — это Lua-модули со специальным API, которые служат для описания бизнес-логики приложения.Какая может быть функциональность у ролей?
- Хранилище, в котором будут создаваться таблицы для данных.
- HTTP-API для клиентов.
- Репликация данных из внешнего источника.
- Сбор метрик или цепочек вызовов, отслеживание работоспособности экземпляров.
- Исполнение любой другой кастомной логики, написанной на Lua.
API
return {role_name = 'custom-role',
init = init,
validate_config = validate_config,
apply_config = apply_config,
stop = stop,
dependencies = {
'another-role',
},
}
Каждая роль имеет стандартный API:
- В init-функции производятся действия для начальной настройки роли.
- validate_config проверяет валидность конфигурации.
- apply_config применяет конфигурацию.
- В stop производятся действия для отключении роли.
Готовые роли
В Cartridge существует несколько готовых ролей, некоторые из них доступны из коробки, а некоторые ставятся вместе с другими модулями.Встроенные роли:
- vshard—router. Направляет запросы к узлам хранения данных.
- vshard—storage. Хранит и контролирует бакеты с данными.
- failover—coordinator. Управляет фейловером в кластере.
- metrics. Собирает метрики приложений.
- crud—storage и crud—router. Упрощают взаимодействие с шардированными спейсами.
Зависимости между ролями
Зависимости между ролями — важнейший механизм, который лежит в основе всех приложений на Cartridge. Роль будет запущена только после успешной инициализации других ролей, от которых она зависит. Это означает, что каждая роль может использовать функции из других ролей, если они будут указаны в списке dependencies.Рассмотрим пример. Пусть мы написали свою роль custom-storage, в которой описано создание таблиц данных. Она будет зависеть от crud-storage, чтобы мы могли воспользоваться упрощенными интерфейсами для получения и записи данных в наше хранилище. При этом crud-storage уже зависит от роли vshard-storage, что позволяет нам не заботиться о том, как наши данные шардируются. В коде это выглядит вот так:
app/roles/custom-storage.lua
return {
role_name = 'custom-storage',
dependencies = {
'crud-storage',
},
}
cartridge/roles/crud-storage.lua
return {
role_name = 'crud-storage',
dependencies = {
'vshard-storage',
},
}
Cartridge гарантирует порядок запуска ролей. Значит в роли custom-storage мы можем пользоваться всеми возможностями ролей vshard-storage и crud-storage и не бояться, что они еще не проинициализированы.
Entrypoint
Входной точкой каждого экземпляра в кластере Cartridge является файл init.lua. В нем обязательно должна быть вызвана функция cartridge.cfg — в нее передается список ролей, доступных в кластере, а также дефолтные настройки Cartridge и Tarantool. init-файл может быть запущен как из консоли с помощью Tarantool, так и с помощью cartridge-cli или systemd/supervisord.tarantool ./init.lua
local ok, err = cartridge.cfg({
roles = {
'cartridge.roles.vshard-storage',
'cartridge.roles.vshard-router',
'cartridge.roles.metrics',
'app.roles.custom’,
},
... -- cartridge opts
}, {
... -- tarantool opts
})
Масштабирование с помощью ролей
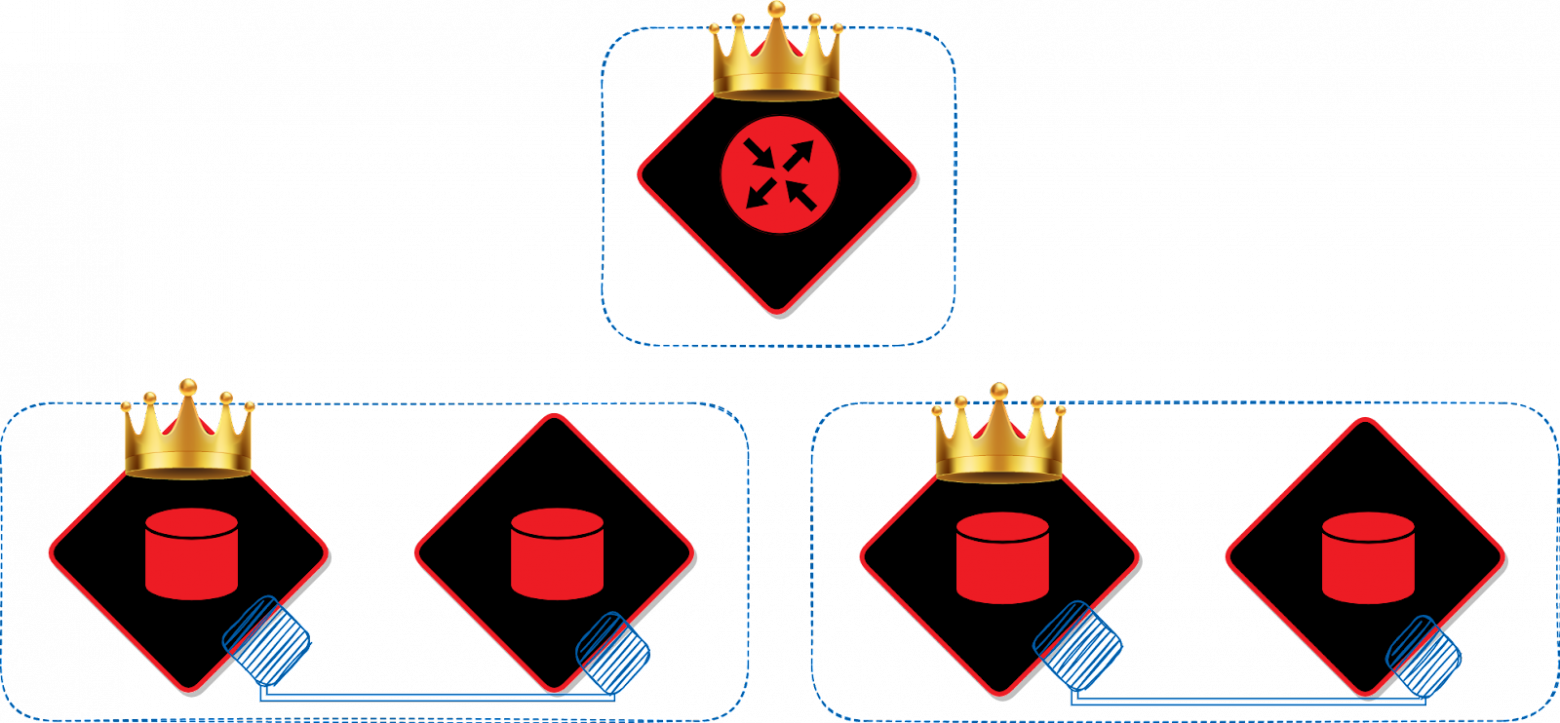
Рассмотрим типовой сценарий масштабирования. Пусть у нас есть кластер из двух экземпляров: у одного роль «роутер», у другого «хранилище».
Новые реплики добавляем, когда нужно дополнительное резервирование, например, появился новый резервный ЦОД. Или когда хотим увеличить доступность наборов реплик на чтение, например, если большая часть запросов на чтение отправляется на реплику.
Добавляем новые шарды, когда на экземплярах память заполняется на 60-80 %. Можно и раньше, если видим на графиках потребления памяти постоянный рост и можем прогнозировать время, когда место закончится.
Роутеры добавляем, если видим пиковую нагрузку CPU около 80-100 %, а также по бизнес-метрикам. Например, увеличилось число пользователей у кластера, выросла нагрузка.
Добавляем новые роли, если меняется или дополняется бизнес-логика приложений, или если вдруг нужен дополнительный мониторинг. Например, можно включить в кластер модули metrics или tracing.
Нужно отметить, что добавлять в кластер новые экземпляры можно без изменения кода, как и включать существующие роли на имеющихся наборах реплик. Но при добавлении новых ролей, которые раньше отсутствовали в кластере, нужно добавить их в init.lua и перезапустить приложение.
Помимо этого, необходимо помнить, что любому экземпляру в кластере можно назначить несколько ролей. Любой экземпляр может одновременно быть и роутером, и хранилищем, и репликатором, а также выполнять любую кастомную логику.
Кластерная конфигурация
Кластерная конфигурация — основной способ управления кластером, там хранится топология, настройки vshard, которые передаются в vshard.storage.cfg и vshard.router.cfg, а также настройки кастомных ролей. Полная конфигурация хранится на каждом экземпляре приложения. Cartridge гарантирует, что на всех узлах в любой момент времени конфигурация будет идентична.Давайте посмотрим на механизм распространения новой конфигурации. Пусть на одном из узлов она поменялась, и после этого конфигурация распространится на все остальные экземпляры.
Каждый экземпляр, получивший изменения конфигурации, вызовет свои функции validate_config, чтобы проверить, можно ли применить полученную конфигурацию. Если вдруг хотя бы один из экземпляров не сможет провалидировать измененную конфигурацию, она будет отменена на всех остальных экземплярах, а пользователь, который пытался её применить, получит ошибку.
Если же конфигурация была валидной, то Cartridge дожидается, пока каждый из инстансов в кластере скажет, что проверка validate_config завершилась успешно и конфигурацию можно применять.
Теперь Cartridge выполнит все функции apply_config и применит новую конфигурацию на каждом экземпляре приложения. Она будет сохранена на диске взамен старой конфигурации.
Но если вдруг во время применения конфигурации что-то пошло не так и стадия apply_config выполнилась с ошибкой, Cartridge выведет в WebUI информацию об этом и предложит переприменить конфигурацию.
Failover
У нас есть репликация и мы знаем, что наши данные никуда не пропадут, но также нам нужно, чтобы приложения всё время были доступны на запись. В Cartridge для этого существует фейловер. Для его работы в кластере должны быть экземпляры с ролью failover-coordinator, которые будут управлять переключением мастеров. Еще нужен state-provider, в котором хранится список текущих мастеров. Сейчас поддерживаются два режима state-provider’a: etcd или отдельный экземпляр Tarantool, который называется stateboard.Failover-coordinator следит за тем, чтобы в наборе реплик был доступен хотя бы один мастер.
Если вдруг мастер в наборе упадет или перестанет отвечать на запросы, failover-coordinator узнает об этом и назначит одну из реплик в том же наборе мастером.
При этом информация о том, кто является текущим мастером, будет сохранена во внешнем хранилище. Теперь даже если старый мастер вернется в рабочее состояние, принимать запросы на запись он уже не сможет. Новый мастер будет оставаться таковым до тех пор, пока он сам не упадет или не перестанет быть доступен для запросов.
Инструменты
А как вообще поддерживать Cartridge? Для этого есть богатый инструментарий:- cartridge-cli для создания приложения из шаблона, локального запуска, подключения к экземплярам и вызова функций администрирования.
- Для тестирования есть cartridge.test-helpers, который позволяет создавать в интеграционных тестах кластер любого состава.
- Для мониторинга есть WebUI, который позволяет узнать о некоторых проблемах с помощью Cartridge Issues и починить часть из них с помощью Suggestions; существует пакет metrics и дашборд для Grafana.
- Развёртывание выполняется с помощью ansible-cartridge, она позволяет добавлять новые экземпляры в кластер, обновлять существующие и многое другое.
Cartridge в проде
Cartridge хорошо зарекомендовал себя в эксплуатации. Наши заказчики пользуются им уже как минимум три года. Вот немного статистики по использованию Cartridge:- > 100 витрин в проде: кеши и мастер-хранилища.
- От нескольких МБ до нескольких ТБ.
- От 4 до 500 экземпляров в кластере.
- Мастеры и реплики в разных ЦОДах.
- CI/CD-конвейер, общий для всех приложений в рамках одного контура.
- Общие модули и роли в проектах.
Итоги
Я рассказал о принципах масштабирования кластеров, а также про:- механизм ролей в Cartridge;
- распределенную конфигурацию приложений;
- отказоустойчивость с помощью фейловера;
- статистику использования Cartridge в проде.
Масштабируем кластеры без лишних усилий
Каждый, кто работал с большими кластерами, знает: данные все время растут. Рано или поздно перед разработчиками распределенных систем встает задача масштабирования. Сейчас найти место для хранения...
habr.com