Я Роман Ананьев, NoSQL/Kafka-инженер в Авито. В этом материале расскажу, как мы попробовали использовать брокер сообщений Apache Kafka в трёх дата-центрах и что из этого получилось.
Сначала пробегусь по архитектуре Kafka, потому что она играет роль в репликации между кластерами. Затем коснусь самих способов репликации и расскажу о двух инструментах для неё: MirrorMaker и uReplicator. Основная часть статьи — про нашу реализацию Kafka cluster federation и то, как Kafka размазана на несколько дата-центров.
Устройство кластера. Zookeeper хранит метаданные кластера и пользователей, а также координирует кластер. Он отвечает за выбор контроллера, хранит конфигурации топиков и партиций, а также хранит список входящих в кластер брокеров и следит за их доступностью.
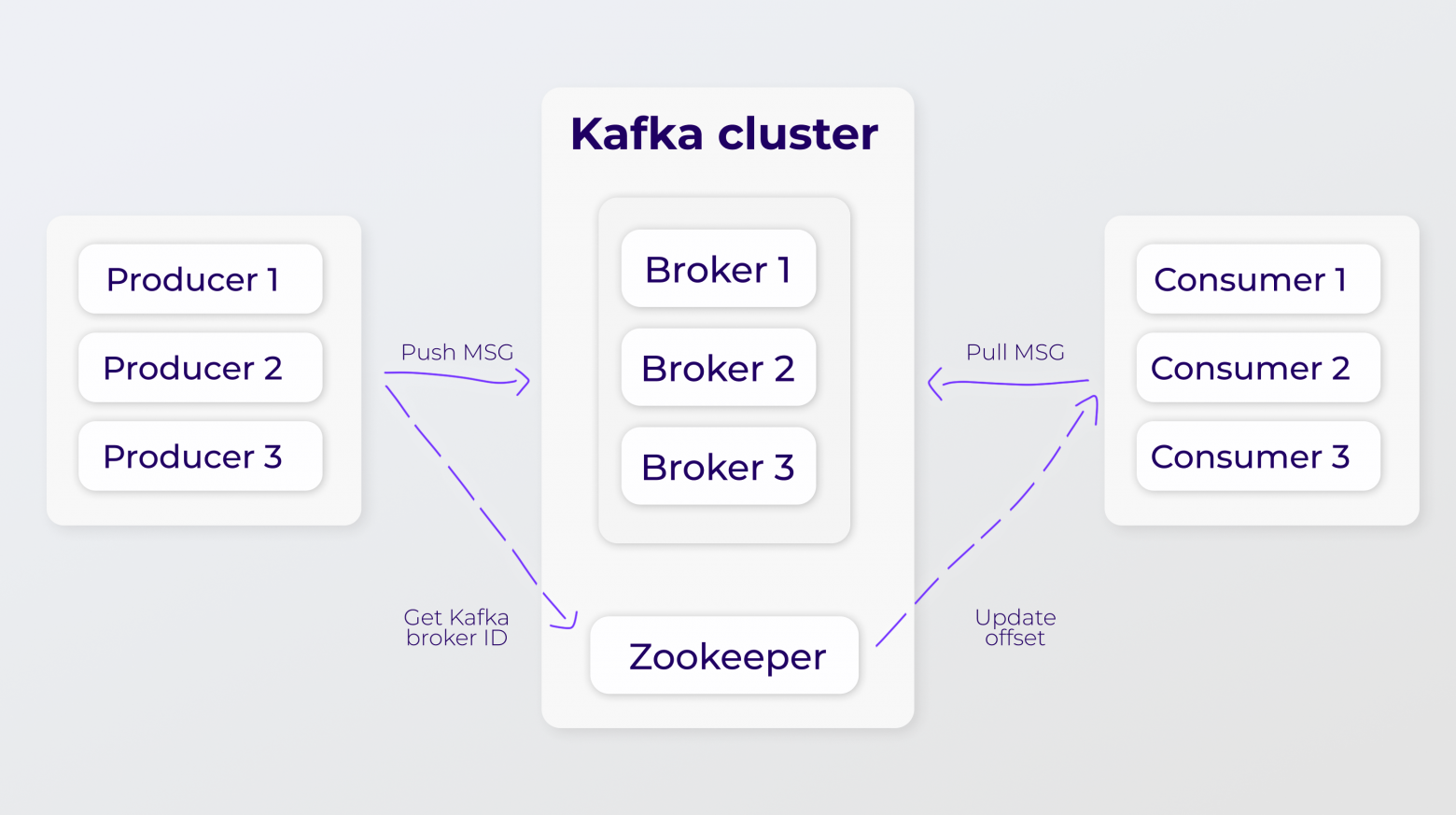
Kafka только принимает, хранит и отдаёт данные. Логика того, как писать и читать, реализована на стороне умных клиентов, которые в терминологии Kafka называются продюсерами и консьюмерами. Сама же Kafka, или Message Broker, довольно проста.
Устройство топика. Брокеры — это атомарная структура кластера, а на брокерах хранятся топики. Топики — это абстрактные структуры, которые делятся на партиции. Именно в партициях лежат данные. Партиции распределяются между брокерами по round robin паттерну, чтобы было удобно хранить реплики и гарантировать отказоустойчивость, если одна из реплик партиции станет недоступной.
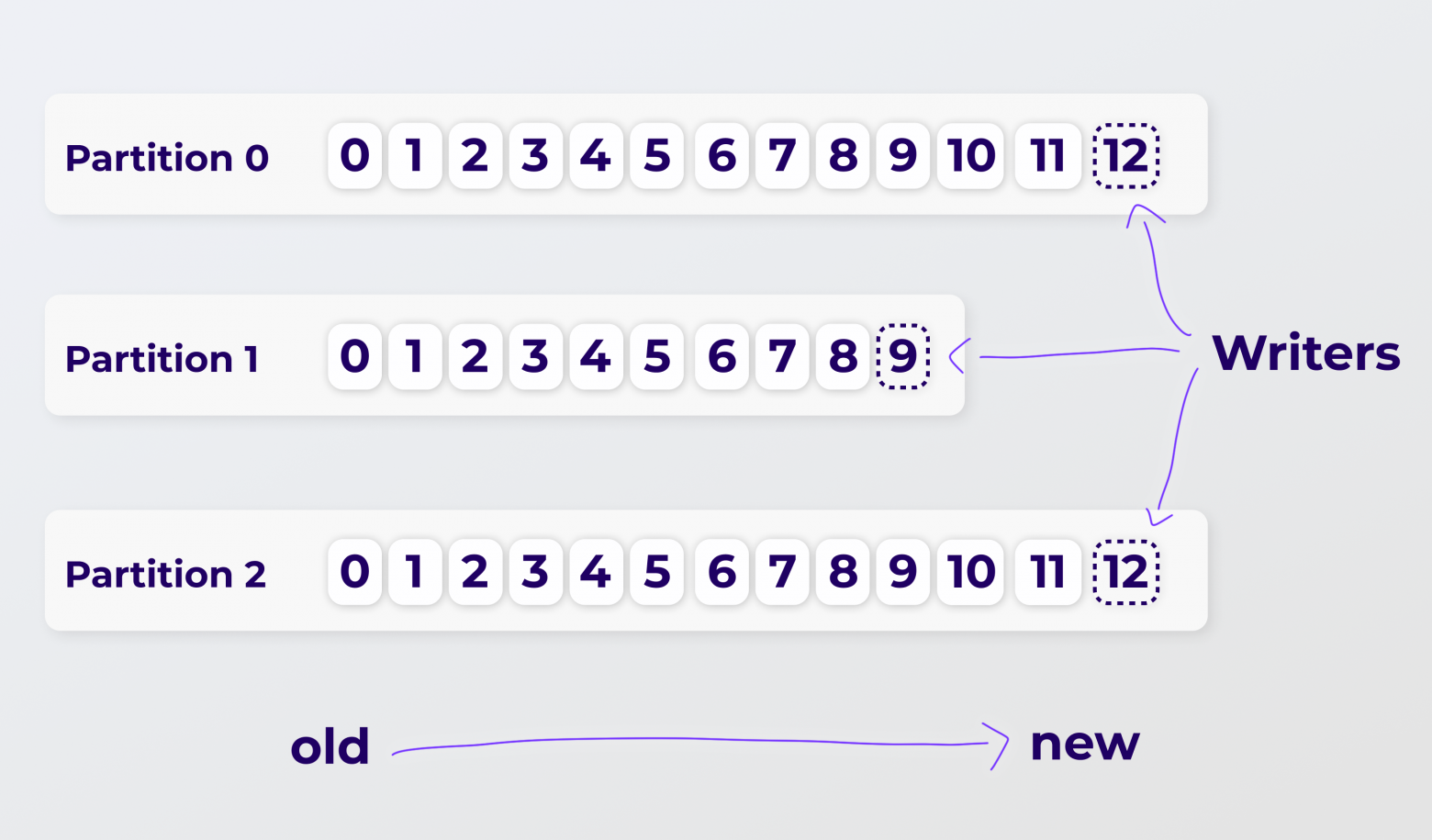
Записанные в партицию сообщения имеют порядковый номер. Это в терминологии Кафки — offset, или, для простоты, айдишник. В рамках одной партиции offset уникален, и в каждой партиции он стартует с нуля.
Консьюмеры. Консьюмер — это умный клиент, который читает сообщения из Kafka. Набор консьюмеров — это консьюмер-группа.
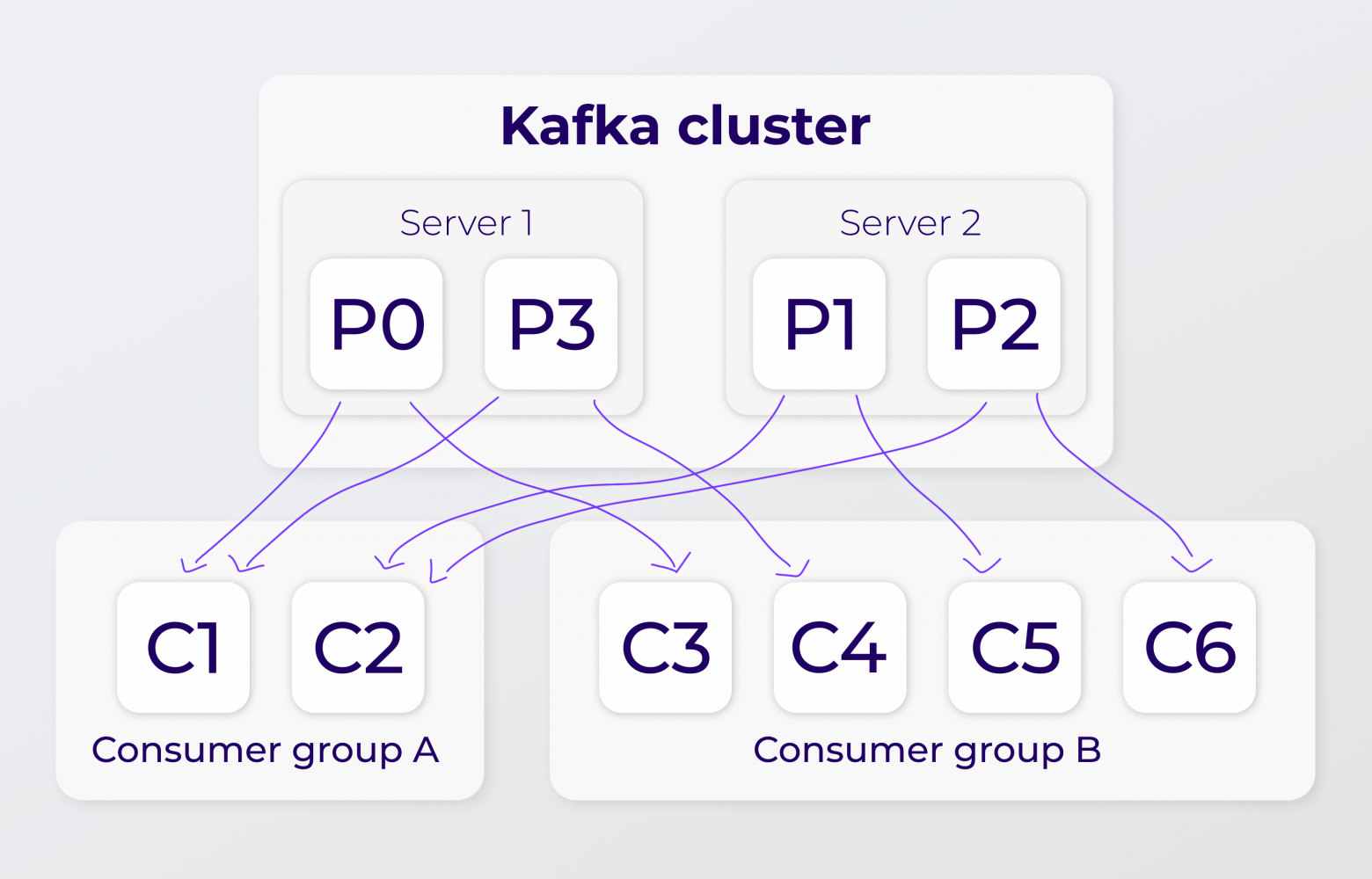
В идеале консьюмеру хочется читать сообщения, имея возможность остановиться по какой-то причине, и затем продолжать чтение с того же места. Как раз для этого в чат входит offset и возможность его запоминания для консьюмер-группы, в рамках которой наш консьюмер находится. Из партиции в данный момент времени может читать только один консьюмер из группы. А консьюмер-групп на одну партицию может быть навешано почти сколько угодно, насколько хватит мощностей.
Продюсеры. Продюсеры — это те клиенты, что пишут данные в кластер Kafka. Они тоже довольно умные, но в рамках репликации не так важно, как они устроены.
Почитать подробнее про продюсеры и архитектуру Kafka можно в нашей статье «Kafka и микросервисы: обзор».
Встроенного механизма для репликации у Kafka как такового нет. Но есть внешние утилиты, бесплатные и платные, например:
Я не буду обозревать всё, что есть на рынке и что позволяет реплицироваться между кластерами Kafka. Расскажу лишь про бесплатные инструменты, которые успел пощупать, пока мы настраивали свою вариацию Kafka cluster federation.
MirrorMaker 2 (ММ2). ММ2 — утилита, которая идёт в комплекте с Kafka. Технически это набор коннекторов для фреймворка Kafka Connect:

При репликации важна особенность ММ2, что он по умолчанию добавляет префикс для каждого кластера Kafka, между которыми работает, и добавляет его к имени топика. Префикс нужен, чтобы не было бесконечной петли репликации при сценарии active-active.
Это можно обойти, используя кастомную политику наименования топиков. Она не написана для ММ2 из коробки, но на просторах сети хватает примеров, как такую сделать. Например, есть реализация безпрефиксной политики от Amazon. При ней топик реплицируется один в один, но в таком варианте доступным остаётся только active-standby сценарий. Как раз наш случай.
И при active-standby сценарии есть ещё одна заметная для нас проблема. Когда active-кластер падает, и standby принимает на себя роль active, а затем бывший active-кластер возвращается в строй, то направление репликации не меняется обратно автоматически. Реверс-режим нужно делать руками или огораживать автоматизацией, чтобы он сработал.
uReplicator от Uber. uReplicator — отдельное приложение, а не коннекторы, как ММ2. Он состоит из набора приложений под капотом.
Во-первых, это Zookeeper, который также хранит метаданные о кластерах, топиках, партициях и консьюмерах, а также о прогрессе репликации данных. Во-вторых, Apache Helix. Это cluster management фреймворк, который заведует тем, как воркер uReplicator-а ассайнится на партиции, какой оффсет из партиций забирать, как балансить нагрузку между воркерами при добавлении партиций и когда добавлять новые воркеры, если нагрузка или число партиций возросли. А чтобы читать и писать из кластеров Kafka, Helix запускает обычные кафковские JAVA-консьюмеры в режиме, когда они цепляются напрямую на партиции, минуя создание консьюмер-групп. Консьюмеры это умеют, но нужно ручное управление оффсетами, которым заведуют Helix совместно с Zookeeper.
uReplicator умеет в actice-standby и active-active сценарии. При этом он не добавляет по умолчанию префиксов у топиков: каждый топик реплицируется с тем же именем. Но это отлично подходит для active-standby, а чтобы active-active заработал, нужен маппинг топиков и whitelist. Это конфигурация для репликатора, которая включает в себя topic-mapping, куда нужно прописать точное соответствие имен топиков на целевом кластере и кластере-источнике. Тогда uReplicator точно будет знать, какие топики куда реплицировать, и они не будут пересекаться. Тем самым получается круговая репликация.

В отличие от ММ2, uReplicator не умеет:
Kafka эту раскинули на три дата-центра, когда они появились, сделав единым широким кластером. DataBus при этом тоже стал работать в нескольких дата-центрах. И всё было хорошо до того момента, пока какой-нибудь из дата-центров не отключался.
И теперь графики, как мы любим, где видно, что же именно при отключении нам не понравилось. Верхний график — это produce time, который возникал на DataBus и Kafka 2.7 под ним при отключении одного дата-центра и, соответственно, одного из наборов брокеров в этом ДЦ. Здесь видно, как на 10 минут выключили и включили дата-центр обратно. По идее, всё должно быть нормально, но эти 10 минут шёл ребаланс и leader election. И в этот момент с реплик оставшихся в доступе дата-центров, можно было читать (нижний график), но писать нельзя:
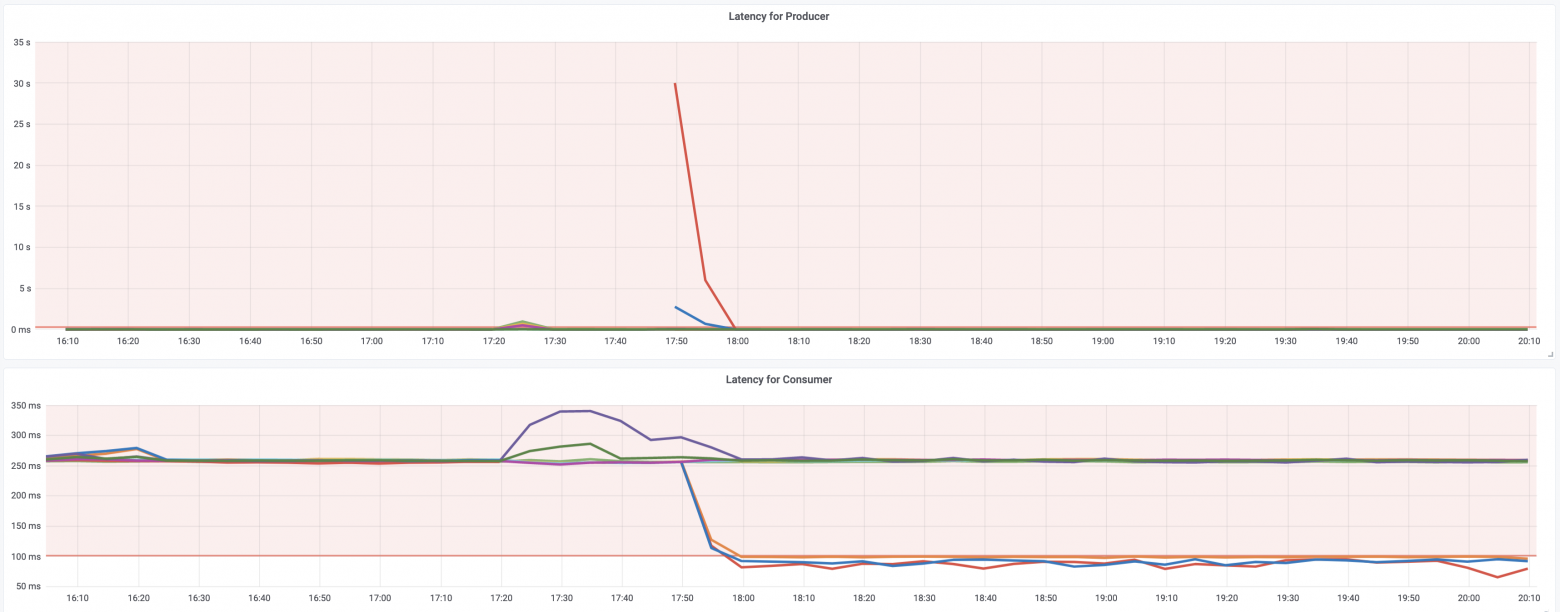
Почему возник такой тайминг? Вот графики по числу партиций, лидером которых является брокер, и по времени того как сходились и расходились ISR при отключении/включении дата-центра. А это как раз 10 минут:
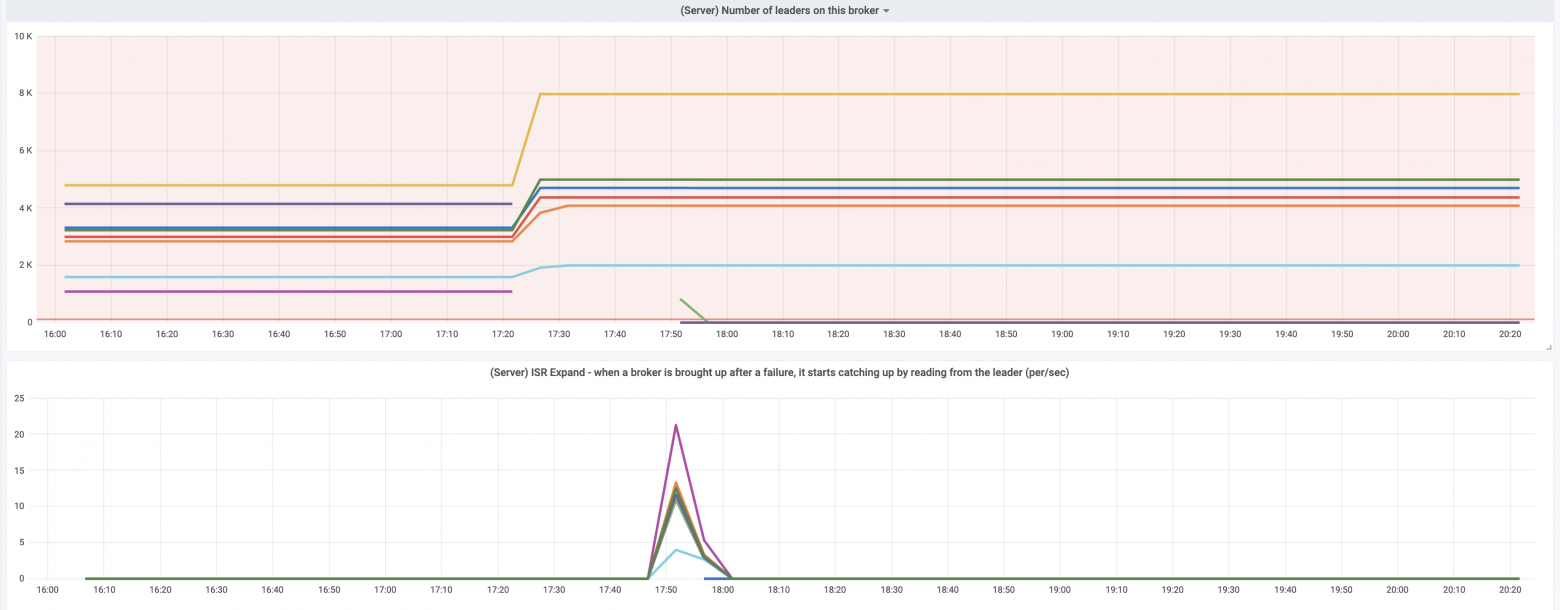
Число топиков растёт, число партиций растёт, и leader election при отключении и включении дата-центра обратно будет происходить всегда и будет только расти при увеличении числа партиций. И в это время всегда будет задержка на produce, потому что выбираются новые лидеры для них.
Мы задумались, как это победить. Наш итоговый вариант — создание федерации Кафка-кластеров.
Все сервисы в каждом дата-центре Авито обращаются к DataBus, работающему в этом ДЦ. Затем этот DataBus пишет в свой локальный writable cluster Kafka. Такие writable-кластеры находятся в каждом дата-центре, но между собой они не связаны и о существовании друг друга не знают. Суммарно запись идёт в три потока — ибо три дата-центра и значит три writable-кластера. Затем репликаторы (их также три — по одному в каждом ДЦ) забирают данные из этих кластеров и пишут в широкий read-only кластер Kafka, растянутый на все дата-центры, из которого DataBus уже вычитывает данные.
Наглядная схемка федерации:
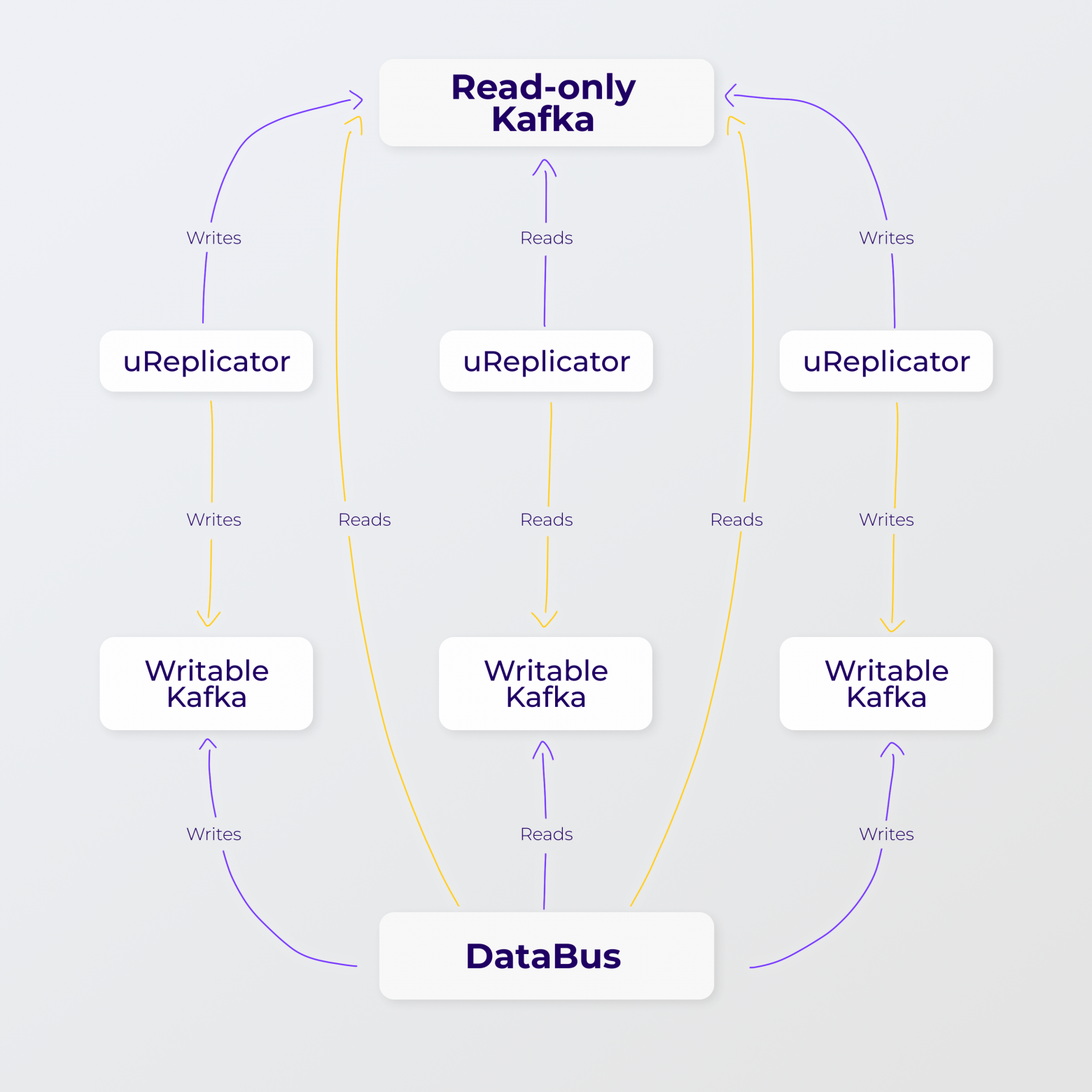
То есть в Kafka cluster federation три отдельных кластера на запись и общий на чтение. Из каждого кластера на запись настроена репликация в кластер на чтение. При отключении одного writable-кластера, нагрузку принимают оставшиеся. Для каждого из трёх кластеров на запись поднят свой репликатор. Репликаторы о существовании друг друга не знают.
Kafka cluster federation мы делали на следующих ресурсах, на примере для одного дата-центра:
Строить федерацию мы начали с использованием ММ2, но не взлетело. И причину этого можно наблюдать на следующем графике:

Провалы с трафиком на чтение возникают, когда во writable-кластерах Kafka появляется новый топик. В этот момент репликация данных в ММ2 останавливается. Раз репликации нет, то и читать нечего, поэтому чтение замирает на какое-то время. Мы хотели победить produce, а в итоге нашли приключений ещё и на consume: ведь когда топики создаются, надо ждать, пока ММ2 разбалансится.
Почему ММ2 так себя повёл? График latency при репликации сообщений отображает предыдущую картинку:

Верхний овал — это latency 10-15 секунд, что в нашем сценарии даже вполне подходило для вновь созданных топиков. Во время этого процесса всё стабильно: новый топик создался, мы начали в него писать, ММ2 его подхватил, начал читать, затем создал на другом кластере, и начал в него писать. Но почему же тогда возникает нижний овал, когда все остальные топики увеличивают latency в репликации от 2 до 5 секунд и, соответственно, чтение на это время невозможно?
Дело в том, что ММ2 — это коннектор Kafka Connect. Kafka Connect — это фреймворк, у коннектора ММ2 есть таски, как впрочем и у любого коннектора для Kafka Connect. Детальнее про это можно посмотреть в моём докладе.
Число тасков, которые и гоняют данные при репликации, — элемент параллелизма у коннекторов, и это число задаётся в конфигурации коннектора. На каждую таску назначается свой набор партиций, которые в рамках этой таски и реплицируются. А добавление топика для коннектора ММ2 означает изменение в его конфигурации. Изменение же конфигурации автоматически приводит к инкрементальному ребалансу тасков на число воркеров Kafka Connect, чтобы равномерно распределить таски по ним. На время этого ребаланса тасков всё замирает. В общем круто, пока не меняется конфигурация коннектора.
В итоге мы получаем следующий расклад: когда конфигурация коннектора меняется, то начинается релоад её обновленной версии и ребаланс тасков, чтобы заново раскидать таски по воркерам Kafka Connect. А так как добавление новых топиков провоцирует изменение конфигурации коннектора, а также конфигурации тасков, то такой ребаланс будет наблюдаться при каждом добавлении нового топика.
Казалось бы, можно сделать в лоб: поставить, допустим, 100 000 тасков и заранее предусмотреть рост числа партиций на год вперёд, чтобы было по партиции на таску. Тогда добавление новых топиков не затронет текущие за счёт инкрементального ребаланса, и они будут продолжать работать. Но нет: ребаланс всё равно идёт, потому что конфигурация у коннектора меняется в любой случае. А это триггерит релоад её обновленной версии, в которой есть новый топик, затем ребаланс всего коннектора и новый реассайн всех тасков среди воркеров. А такой реассайн — это остановка репликации.
По этой причине ММ2 нам не подошёл, и мы посмотрели в сторону uReplicator.
И вот график метрики consume у uReplicator:
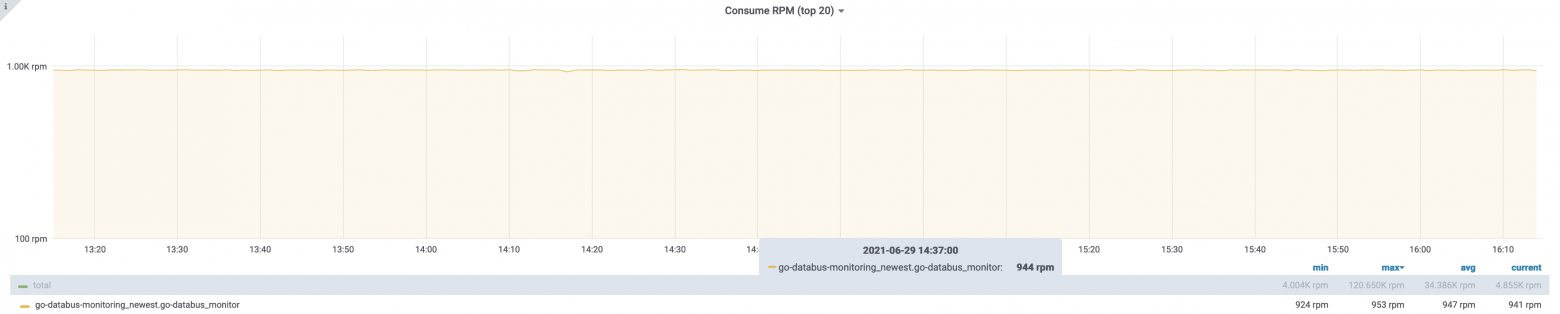
Репликация идёт постоянно, неважно, какие новые топики добавляются и когда.
Вот как выглядит latency в случае uReplicator. Верхний график — это офсет-лаг, то есть лаг того, сколько ещё надо дореплицировать из исходного кластера в целевой. А нижний график — это latency именно по времени репликации сообщений:
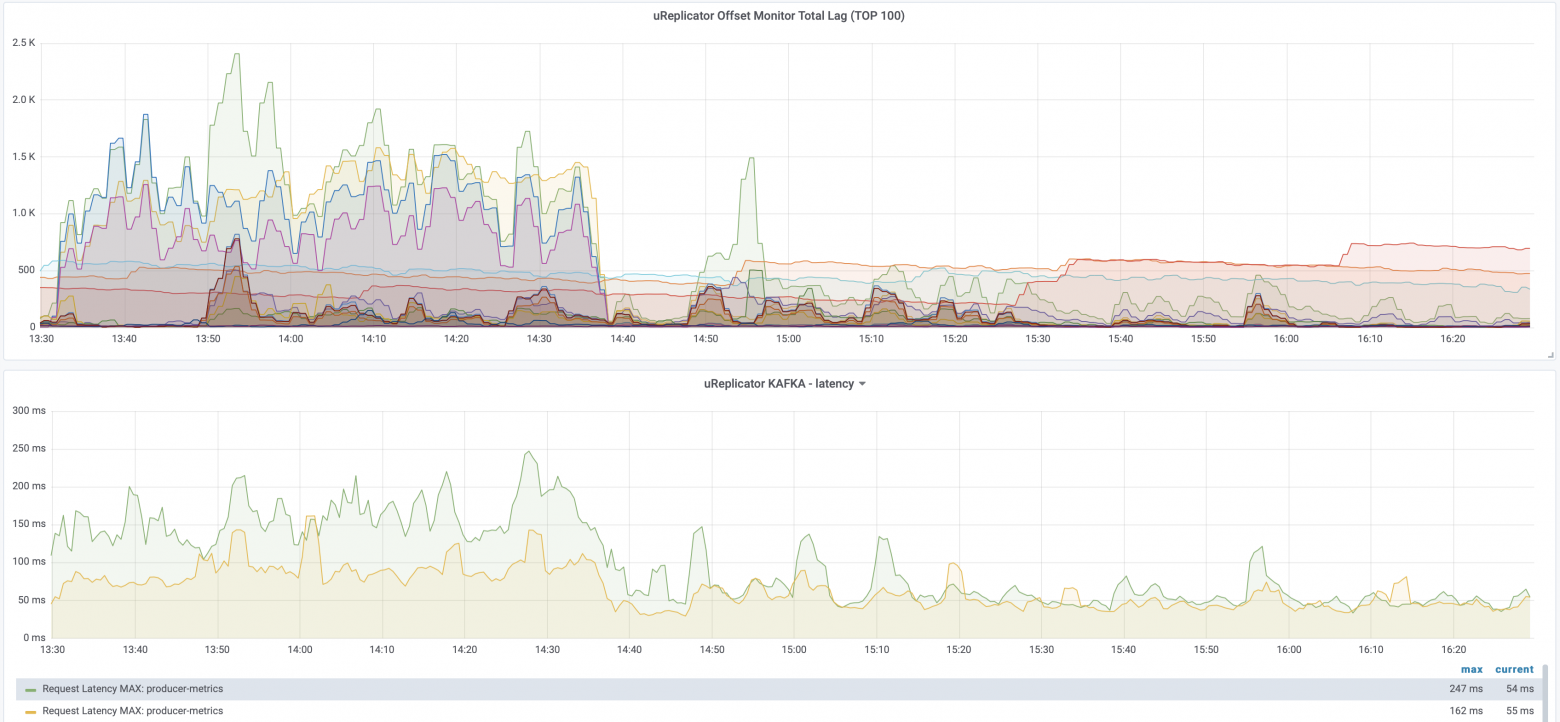
Заметная расчёска слева была во время, когда активно добавлялись новые топики. Это отражалось на времени репликации для уже имеющихся топиков. Когда же новые топики перестали добавляться так активно или стали добавляться заметно реже, то время репликации для остальных топиков никак на это не реагировало. Дело в том, что uReplicator при добавлении топиков лишь инициализировал под капотом новых воркеров на основе Helix-клиентов, которые подхватывали эти топики для репликации и не затрагивали остальных работающих воркеров. Latency на запись не страдала, и репликация не останавливалась.
Попутно нам понадобилось допилить несколько дополнительных вещей, чтобы включить uReplicator в нужный нам сценарий успешно. Например, тот же мониторинг, но мы с этим справились.
Здесь напомню, что наш сценарий — однонаправленная репликация active-standby из трёх дата-центров и, следовательно, трёх маленьких кластеров Kafka, доступных только на запись, в единый широкий кластер Kafka, доступный только на чтение. И это в целом классическая задача при репликции. Нам не нужно было синхронизировать оффсеты, не нужно было менять и синхронизировать конфигурацию топиков и ACL. Всё потому, что над этим всем есть абстракция в виде DataBus.
У uReplicator есть недостатки. Он не умеет создавать топики, поэтому пришлось написать собственную тулу Kassistant, которая создаёт их во всех кластерах Kafka, как только в DataBus пришла задача создать топик. Также uReplicator не умеет переключаться обратно автоматически при сценарии active-standby, если active отключился и через некоторое время вернулся в строй. В нашем случае это и не было нужно, но если делать универсальный active-standby с обратным переключением, придётся что-то придумывать. Из мониторинга же uReplicator умеет в Graphite, но не умеет в VictoriaMetrics и Prometheus.
При этом в наш набор требований uReplicator лёг успешно, поэтому выбор и пал на него. И основной его плюс для нас в том, как он ведёт себя при автосоздании топиков в кластерах Кафки: если бы автосоздания не было, то ММ2 тоже бы отлично подошёл. Сама по себе репликация у ММ2 происходит даже быстрее, чем у uReplicator, если смотреть на RTT. Правда, когда он не ребалансится.
В целом оба эти инструмента подходят для определённых сценариев. В нашем случае ММ2 не выстрелил из-за возникновения ребаланса при добавлении топика и появлении проблемы при репликации данных из-за этого. А с uReplicator при этом же сценарии всё получилось. Теперь отказ дата-центра, хоть одного, хоть двух, происходит без всяких последствий. Запись не останавливается.

 habr.com
habr.com
Сначала пробегусь по архитектуре Kafka, потому что она играет роль в репликации между кластерами. Затем коснусь самих способов репликации и расскажу о двух инструментах для неё: MirrorMaker и uReplicator. Основная часть статьи — про нашу реализацию Kafka cluster federation и то, как Kafka размазана на несколько дата-центров.
Архитектура Apache Kafka
Кластер Kafka — это набор Kafka-брокеров. Каждый брокер — это отдельный хост, который развернут на железе или в контейнере.Устройство кластера. Zookeeper хранит метаданные кластера и пользователей, а также координирует кластер. Он отвечает за выбор контроллера, хранит конфигурации топиков и партиций, а также хранит список входящих в кластер брокеров и следит за их доступностью.
Kafka только принимает, хранит и отдаёт данные. Логика того, как писать и читать, реализована на стороне умных клиентов, которые в терминологии Kafka называются продюсерами и консьюмерами. Сама же Kafka, или Message Broker, довольно проста.
Устройство топика. Брокеры — это атомарная структура кластера, а на брокерах хранятся топики. Топики — это абстрактные структуры, которые делятся на партиции. Именно в партициях лежат данные. Партиции распределяются между брокерами по round robin паттерну, чтобы было удобно хранить реплики и гарантировать отказоустойчивость, если одна из реплик партиции станет недоступной.
Записанные в партицию сообщения имеют порядковый номер. Это в терминологии Кафки — offset, или, для простоты, айдишник. В рамках одной партиции offset уникален, и в каждой партиции он стартует с нуля.
Консьюмеры. Консьюмер — это умный клиент, который читает сообщения из Kafka. Набор консьюмеров — это консьюмер-группа.
В идеале консьюмеру хочется читать сообщения, имея возможность остановиться по какой-то причине, и затем продолжать чтение с того же места. Как раз для этого в чат входит offset и возможность его запоминания для консьюмер-группы, в рамках которой наш консьюмер находится. Из партиции в данный момент времени может читать только один консьюмер из группы. А консьюмер-групп на одну партицию может быть навешано почти сколько угодно, насколько хватит мощностей.
Продюсеры. Продюсеры — это те клиенты, что пишут данные в кластер Kafka. Они тоже довольно умные, но в рамках репликации не так важно, как они устроены.
Почитать подробнее про продюсеры и архитектуру Kafka можно в нашей статье «Kafka и микросервисы: обзор».
Репликация и бесплатные инструменты для неё
Перейдём к тому, что такое Kafka с репликацией. Технически, реплицировать топики можно и в рамках одного кластера, и в межкластерном варианте. Я сосредоточусь на втором, потому что такой была наша задача.Встроенного механизма для репликации у Kafka как такового нет. Но есть внешние утилиты, бесплатные и платные, например:
- MirrorMaker — бесплатный.
- uReplicator — бесплатный.
- Confluent Replicator — платный.
Я не буду обозревать всё, что есть на рынке и что позволяет реплицироваться между кластерами Kafka. Расскажу лишь про бесплатные инструменты, которые успел пощупать, пока мы настраивали свою вариацию Kafka cluster federation.
MirrorMaker 2 (ММ2). ММ2 — утилита, которая идёт в комплекте с Kafka. Технически это набор коннекторов для фреймворка Kafka Connect:
- Source-коннектор гоняет данные из исходного кластера в целевой.
- Heartbeat-коннектор проверяет доступность кластеров.
- Сheckpoint-коннектор направляет чек-пойнтами информацию об офсетах консьюмер-групп, забирая из системного топика consumer offsets.
При репликации важна особенность ММ2, что он по умолчанию добавляет префикс для каждого кластера Kafka, между которыми работает, и добавляет его к имени топика. Префикс нужен, чтобы не было бесконечной петли репликации при сценарии active-active.
Это можно обойти, используя кастомную политику наименования топиков. Она не написана для ММ2 из коробки, но на просторах сети хватает примеров, как такую сделать. Например, есть реализация безпрефиксной политики от Amazon. При ней топик реплицируется один в один, но в таком варианте доступным остаётся только active-standby сценарий. Как раз наш случай.
И при active-standby сценарии есть ещё одна заметная для нас проблема. Когда active-кластер падает, и standby принимает на себя роль active, а затем бывший active-кластер возвращается в строй, то направление репликации не меняется обратно автоматически. Реверс-режим нужно делать руками или огораживать автоматизацией, чтобы он сработал.
uReplicator от Uber. uReplicator — отдельное приложение, а не коннекторы, как ММ2. Он состоит из набора приложений под капотом.
Во-первых, это Zookeeper, который также хранит метаданные о кластерах, топиках, партициях и консьюмерах, а также о прогрессе репликации данных. Во-вторых, Apache Helix. Это cluster management фреймворк, который заведует тем, как воркер uReplicator-а ассайнится на партиции, какой оффсет из партиций забирать, как балансить нагрузку между воркерами при добавлении партиций и когда добавлять новые воркеры, если нагрузка или число партиций возросли. А чтобы читать и писать из кластеров Kafka, Helix запускает обычные кафковские JAVA-консьюмеры в режиме, когда они цепляются напрямую на партиции, минуя создание консьюмер-групп. Консьюмеры это умеют, но нужно ручное управление оффсетами, которым заведуют Helix совместно с Zookeeper.
uReplicator умеет в actice-standby и active-active сценарии. При этом он не добавляет по умолчанию префиксов у топиков: каждый топик реплицируется с тем же именем. Но это отлично подходит для active-standby, а чтобы active-active заработал, нужен маппинг топиков и whitelist. Это конфигурация для репликатора, которая включает в себя topic-mapping, куда нужно прописать точное соответствие имен топиков на целевом кластере и кластере-источнике. Тогда uReplicator точно будет знать, какие топики куда реплицировать, и они не будут пересекаться. Тем самым получается круговая репликация.
В отличие от ММ2, uReplicator не умеет:
- реплицировать конфиги топиков;
- автоматически создавать топики на кластерах Kafka;
- переносить ACL;
- согласовывать конфигурации топиков на одном кластере и на другом.
Kafka cluster federation в Авито
Kafka cluster federation появилась потому, что нам нужно было гарантировать непрерывную запись через внутреннюю шину DataBus при отключении любого из наших дата-центров или даже нескольких. DataBus — это шина и при этом абстракция над Kafka. В Авито DataBus используют для общения между собой все сервисы, для них это единая точка входа. Там свой протокол и формат данных, но под капотом это Apache Kafka.Kafka эту раскинули на три дата-центра, когда они появились, сделав единым широким кластером. DataBus при этом тоже стал работать в нескольких дата-центрах. И всё было хорошо до того момента, пока какой-нибудь из дата-центров не отключался.
И теперь графики, как мы любим, где видно, что же именно при отключении нам не понравилось. Верхний график — это produce time, который возникал на DataBus и Kafka 2.7 под ним при отключении одного дата-центра и, соответственно, одного из наборов брокеров в этом ДЦ. Здесь видно, как на 10 минут выключили и включили дата-центр обратно. По идее, всё должно быть нормально, но эти 10 минут шёл ребаланс и leader election. И в этот момент с реплик оставшихся в доступе дата-центров, можно было читать (нижний график), но писать нельзя:
Почему возник такой тайминг? Вот графики по числу партиций, лидером которых является брокер, и по времени того как сходились и расходились ISR при отключении/включении дата-центра. А это как раз 10 минут:
Число топиков растёт, число партиций растёт, и leader election при отключении и включении дата-центра обратно будет происходить всегда и будет только расти при увеличении числа партиций. И в это время всегда будет задержка на produce, потому что выбираются новые лидеры для них.
Мы задумались, как это победить. Наш итоговый вариант — создание федерации Кафка-кластеров.
Все сервисы в каждом дата-центре Авито обращаются к DataBus, работающему в этом ДЦ. Затем этот DataBus пишет в свой локальный writable cluster Kafka. Такие writable-кластеры находятся в каждом дата-центре, но между собой они не связаны и о существовании друг друга не знают. Суммарно запись идёт в три потока — ибо три дата-центра и значит три writable-кластера. Затем репликаторы (их также три — по одному в каждом ДЦ) забирают данные из этих кластеров и пишут в широкий read-only кластер Kafka, растянутый на все дата-центры, из которого DataBus уже вычитывает данные.
Наглядная схемка федерации:
То есть в Kafka cluster federation три отдельных кластера на запись и общий на чтение. Из каждого кластера на запись настроена репликация в кластер на чтение. При отключении одного writable-кластера, нагрузку принимают оставшиеся. Для каждого из трёх кластеров на запись поднят свой репликатор. Репликаторы о существовании друг друга не знают.
Kafka cluster federation мы делали на следующих ресурсах, на примере для одного дата-центра:
| MirrorMaker 2 | uReplicator | |
| Контейнеры | 5 | 13: Manager — 2 Controller — 3 Workers — 8 |
| CPU | 10 | 4 |
| RAM | 25 GB | 8 GB |
| Read-only кластер Kafka | |
| Топиков на кластер | 1000 |
| Партиций на кластер | 15 000 |
| Брокеров на кластер | 9 |
| Write-only кластер Kafka | |
| Топиков на кластер | 1000 |
| Партиций на кластер | 15 000 |
| Брокеров на кластер | 3 |
Строить федерацию мы начали с использованием ММ2, но не взлетело. И причину этого можно наблюдать на следующем графике:
Провалы с трафиком на чтение возникают, когда во writable-кластерах Kafka появляется новый топик. В этот момент репликация данных в ММ2 останавливается. Раз репликации нет, то и читать нечего, поэтому чтение замирает на какое-то время. Мы хотели победить produce, а в итоге нашли приключений ещё и на consume: ведь когда топики создаются, надо ждать, пока ММ2 разбалансится.
Почему ММ2 так себя повёл? График latency при репликации сообщений отображает предыдущую картинку:
Верхний овал — это latency 10-15 секунд, что в нашем сценарии даже вполне подходило для вновь созданных топиков. Во время этого процесса всё стабильно: новый топик создался, мы начали в него писать, ММ2 его подхватил, начал читать, затем создал на другом кластере, и начал в него писать. Но почему же тогда возникает нижний овал, когда все остальные топики увеличивают latency в репликации от 2 до 5 секунд и, соответственно, чтение на это время невозможно?
Дело в том, что ММ2 — это коннектор Kafka Connect. Kafka Connect — это фреймворк, у коннектора ММ2 есть таски, как впрочем и у любого коннектора для Kafka Connect. Детальнее про это можно посмотреть в моём докладе.
Число тасков, которые и гоняют данные при репликации, — элемент параллелизма у коннекторов, и это число задаётся в конфигурации коннектора. На каждую таску назначается свой набор партиций, которые в рамках этой таски и реплицируются. А добавление топика для коннектора ММ2 означает изменение в его конфигурации. Изменение же конфигурации автоматически приводит к инкрементальному ребалансу тасков на число воркеров Kafka Connect, чтобы равномерно распределить таски по ним. На время этого ребаланса тасков всё замирает. В общем круто, пока не меняется конфигурация коннектора.
В итоге мы получаем следующий расклад: когда конфигурация коннектора меняется, то начинается релоад её обновленной версии и ребаланс тасков, чтобы заново раскидать таски по воркерам Kafka Connect. А так как добавление новых топиков провоцирует изменение конфигурации коннектора, а также конфигурации тасков, то такой ребаланс будет наблюдаться при каждом добавлении нового топика.
Казалось бы, можно сделать в лоб: поставить, допустим, 100 000 тасков и заранее предусмотреть рост числа партиций на год вперёд, чтобы было по партиции на таску. Тогда добавление новых топиков не затронет текущие за счёт инкрементального ребаланса, и они будут продолжать работать. Но нет: ребаланс всё равно идёт, потому что конфигурация у коннектора меняется в любой случае. А это триггерит релоад её обновленной версии, в которой есть новый топик, затем ребаланс всего коннектора и новый реассайн всех тасков среди воркеров. А такой реассайн — это остановка репликации.
По этой причине ММ2 нам не подошёл, и мы посмотрели в сторону uReplicator.
И вот график метрики consume у uReplicator:
Репликация идёт постоянно, неважно, какие новые топики добавляются и когда.
Вот как выглядит latency в случае uReplicator. Верхний график — это офсет-лаг, то есть лаг того, сколько ещё надо дореплицировать из исходного кластера в целевой. А нижний график — это latency именно по времени репликации сообщений:
Заметная расчёска слева была во время, когда активно добавлялись новые топики. Это отражалось на времени репликации для уже имеющихся топиков. Когда же новые топики перестали добавляться так активно или стали добавляться заметно реже, то время репликации для остальных топиков никак на это не реагировало. Дело в том, что uReplicator при добавлении топиков лишь инициализировал под капотом новых воркеров на основе Helix-клиентов, которые подхватывали эти топики для репликации и не затрагивали остальных работающих воркеров. Latency на запись не страдала, и репликация не останавливалась.
Попутно нам понадобилось допилить несколько дополнительных вещей, чтобы включить uReplicator в нужный нам сценарий успешно. Например, тот же мониторинг, но мы с этим справились.
Здесь напомню, что наш сценарий — однонаправленная репликация active-standby из трёх дата-центров и, следовательно, трёх маленьких кластеров Kafka, доступных только на запись, в единый широкий кластер Kafka, доступный только на чтение. И это в целом классическая задача при репликции. Нам не нужно было синхронизировать оффсеты, не нужно было менять и синхронизировать конфигурацию топиков и ACL. Всё потому, что над этим всем есть абстракция в виде DataBus.
У uReplicator есть недостатки. Он не умеет создавать топики, поэтому пришлось написать собственную тулу Kassistant, которая создаёт их во всех кластерах Kafka, как только в DataBus пришла задача создать топик. Также uReplicator не умеет переключаться обратно автоматически при сценарии active-standby, если active отключился и через некоторое время вернулся в строй. В нашем случае это и не было нужно, но если делать универсальный active-standby с обратным переключением, придётся что-то придумывать. Из мониторинга же uReplicator умеет в Graphite, но не умеет в VictoriaMetrics и Prometheus.
При этом в наш набор требований uReplicator лёг успешно, поэтому выбор и пал на него. И основной его плюс для нас в том, как он ведёт себя при автосоздании топиков в кластерах Кафки: если бы автосоздания не было, то ММ2 тоже бы отлично подошёл. Сама по себе репликация у ММ2 происходит даже быстрее, чем у uReplicator, если смотреть на RTT. Правда, когда он не ребалансится.
В целом оба эти инструмента подходят для определённых сценариев. В нашем случае ММ2 не выстрелил из-за возникновения ребаланса при добавлении топика и появлении проблемы при репликации данных из-за этого. А с uReplicator при этом же сценарии всё получилось. Теперь отказ дата-центра, хоть одного, хоть двух, происходит без всяких последствий. Запись не останавливается.
Выводы
Подведу краткий итог:- uReplicator хорош в простом варианте репликации, когда речь идёт о сценарии active-standby.
- Если нужно реплицировать постоянный список топиков, то выбор скорее за ММ2. Его проще настроить и запустить.
- ММ2 почти не имеет альтернативы среди бесплатных решений, когда дело касается переноса конфигурации топиков, офсета для консьюмер-групп и ACL.
- При отключении одного из трёх дата-центров оба решения ведут себя адекватно и справляются с нагрузкой. При возвращении дата-центра в строй тоже.
- Если главная цель — это latency при статичном наборе топиков, то ММ2 показывает себя даже лучше.
- Серверных ресурсов ММ2 потребляет больше.
- Всё ситуативно. Выбирайте инструменты по своим требованиям и реалиям.
Межкластерная репликация Apache Kafka между тремя дата-центрами
Я Роман Ананьев, NoSQL/Kafka-инженер в Авито. В этом материале расскажу, как мы попробовали использовать брокер сообщений Apache Kafka в трёх дата-центрах и что из этого получилось. Сначала пробегусь...
habr.com