Представьте, что команда инженеров всю ночь перетаскивала в продакшен новую систему, запускала ее, утром сделала свои первые заказы и даже получила их. Они еще не знают, что случится через 10 минут, поэтому полны радости и надежд. Но потом приходит пользовательский трафик — и взрываются чаты и мониторинги…
Но давайте по порядку. Меня зовут Александр Клюшкин. Я работаю в Самокате, и на нашем примере расскажу о сложностях перехода на новый стек. Зачем и кому это может понадобиться?

Самокат — это доставка различных товаров, в том числе продуктов питания с очень коротким SLA в 15 минут. Мы строим новый слой городской инфраструктуры, который поможет перемещать товары в пространстве практически мгновенно.
Когда я пришел в компанию, у нас был монолит на Python, который на самом деле был написан для совершенно других нужд. Только маленькая часть этой кодовой базы использовалась для организации бизнес-процессов. Сама компания переживала этап взрывного экспоненциального роста. На этом фоне было сильно заметно отставание разработки от бизнеса: разработка не могла поставлять фичи в продакшн с той скоростью, с которой это было нужно бизнесу.
Почему так происходило? Инженеры + инструменты = успех. На самом деле формула сложнее, но я упростил ее до двух компонент. Чтобы быстро и эффективно разрабатывать, нужны:
Во-вторых, у нас действительно были технические проблемы, связанные со стабильностью и производительностью. Мы стали думать, как нам разогнать перформанс разработки. Так у нас появилась идея, не попробовать ли сменить стек.
Конечно, ускорить найм, чтобы в нужном объеме нанимать кандидатов за счет более широкого рынка. И начать быстрее разрабатывать, благодаря экосистеме технологического стека, которая имела бы все нужные компоненты для продуктовой разработки — их можно было бы просто подключать и использовать.
Стали смотреть, какие варианты есть. На рынке много языков, но от одних мы отказались из-за высокой конкуренции за профильных кандидатов, а от других — из-за сложности и специфичности языка.
Сначала мы обратили внимание на Golang. Хотя на тот момент Golang был молодым и быстро развивался, на рынке уже были продукты от больших компаний, доказавшие, что это состоятельный подход. Но мы тогда ещё были довольно маленькой компанией и понимали, что с этими ребятами побороться за кандидатов не сможем, поэтому стали искать дальше.
Следующий наш выбор пал на Kotlin. Это до сих пор стильный, модный, молодёжный язык с огромным комьюнити, где можно найти ответ практически на любой вопрос. В нем учтены многие недостатки других языков. Он не тащит за собой (пока, во всяком случае) шлейфа проблем, которые сдерживают его развитие. Он позволяет писать меньше кода (копипасты, бойлерплейты и т.д.), что механически экономит время. Меньше нажатий на кнопки, меньше чтения кода, а значит — меньше багов.
К тому же у него есть большое преимущество в найме, потому что конвертация из Java-разработчиков в Kotlin-разработчиков очень проста. Это увеличивало охват рынка кандидатов, с которыми мы могли бы работать. Мы решили использовать Kotlin для бэкенда и, когда определились с языком, стали думать, как реализовать остальное.
Среди плюсов такого подхода — простота и отсутствие необходимости содержать две команды разработки. Для больших компаний преимущества сомнительные, но для маленьких вполне значимые.
Правда, минусов значительно больше. Самый главный — остановка развития бизнеса! Мы бы не разрабатывали новые бизнес-фичи, что в условиях роста — путь в никуда. Думаю, все слышали истории, когда компания два года что-то переписывала, откладывая релиз, а потом проект закрылся. Всё потому, что рынок уже изменился настолько, что продукт в таком виде больше не нужен или не нужен вообще.
Помимо всего прочего, мы не могли спрогнозировать результат, поэтому начали обдумывать другие варианты и подошли к параллельной разработке.
Такие минусы нас тоже не устраивали, поэтому мы рассмотрели третий вариант.
У такого варианта есть явные плюсы: каждая задача начинает нести бизнес-ценность, что позволяет их легко приоритизировать. А самое главное — мы постоянно создаем добавочную стоимость для нашего бизнеса. Главное помнить, что распил старой платформы — не самоцель.
Но без минусов, конечно, тоже не обошлось. Этот подход очень сложный с точки зрения проектирования, потому что постоянно заставляет вас думать об ограничениях старой системы и учитывать их при разработке новой архитектуры. Это влияет на стоимость и скорость разработки. Но самое главное ограничение, в том, что постепенным замещением (в режиме совместимости) перенести весь функционал со старого стека не получится по многим причинам, в первую очередь из-за стоимости разработки или кардинальных отличий доменной модели. В какой-то момент всё равно придется переключаться на один из двух предыдущих путей.
Тем не менее мы выбрали именно этот путь, потому что он лучше всего синхронизировался с нашими задачами. И начали подбирать практики разработки.
Если этого не сделать, то после набора команд будет два варианта развития событий. Инициативные ребята принесут что-то свое — то что умеют, знают и любят. А не очень инициативные будут ждать, пока к ним кто-то придет и расскажет, что делать. И в первом варианте вы, в лучшем случае, получите много разных технологий, и вам придется в них разбираться и как-то поддерживать. Но второй вариант будет гораздо хуже, когда у вас таким образом сложатся совершенно несовместимые технологии. Например, когда два сервиса на уровне библиотек не могут друг с другом взаимодействовать посредством поставляемых библиотек или требуют разных способов деплоя.
На старте, во всяком случае в нашей ситуации, нам приходилось постоянно усиливать разные части продукта в зависимости от приоритетов. Нам хорошо помогла ротация, когда мы для помощи новой команде переводили туда людей из старой. Им не приходилось тратить время на разбор каких-то инженерных вещей, так как они уже технически знали, что делать (надо было лишь погрузиться в бизнес-контекст, немного разобраться и они уже могли приносить пользу проекту).
Такие ротации помогают и в будущем, потому что людям со временем надоедает тот продукт, с которым они работают, и они хотят попробовать что-то другое.
В самом начале разработки все разработчики и команды будут решать одни и те же проблемы. Чтобы не решать их несколько раз в рамках разных команд, это можно распараллелить: команда А решает свою часть проблем, команда В — другую, а далее обмениваться накопленной экспертизой и инструментарием.
Под платформой я понимаю некоторый шаблон. Если вы работали с Maven, то в его терминах это — архетип, который описывает структуру проекта: какие есть модули, за что они отвечают, зачем они нужны. Это набор библиотек для решения базовых потребностей, для интеграции с БД, Kafka, системой журналирования и логирования, мониторингами, CI и т.д.:

Если говорить про микросервисную архитектуру, то, чтобы избежать проблем с устареванием версий, удобно иметь источник правды и вносить в эту платформу (шаблон) любые изменения, автоматически перенося их в новые сервисы и обновляя в старых.
Если ничего этого не сделать в самом начале, а дать командам построить свои продукты, выехать в продакшн, отловить какие-то баги, всё починить и всё для себя разработать — в дальнейшем у них не будет мотивации для обобщения, хотя такие задачи будут приходить. Например, от ИБ придет задача внедрения SAST или эксплуатация захочет изменить порядок развёртывания — и все команды будут еще раз решать эти задачи, а вы потратите столько времени, сколько команд у вас есть. Но это можно сделать один раз в одной платформе, и все получат эти изменения.
Первый вариант — ленивая миграция. В новый сервис приходит запрос и проверяет, есть ли у него необходимые данные для обработки. Если нет, то забирает их из старой системы, сохраняет себе и с ними уже работает. Если придет повторный запрос, он уже ничего запрашивать не будет, а сразу начнет работать с локальной копией.
В этом подходе есть один минус: он не гарантирует, что мы заберем все данные. Например, пользователь делает заказ раз в полгода, и его данные могли не перенестись.
Второй вариант более сложный — дорабатываем старую систему, учим ее обходить весь набор данных и перемещать в новую систему.
Для этого мы использовали Kafka. Новая система забирала данные из топиков, раскладывала в целевые структуры и начинала с ними работать. Этот способ сложно тестировать, особенно в нашем случае, когда старая система — это сильно связанный legacy монолит, который уже никто не помнит. Тестирование будет занимать очень много времени, да и разработка тоже.
Поэтому мы научили наш новый сервис работать с обеими базами данных. В рамках периодической задачи он ходил в старую БД, забирал оттуда данные и перекладывал в новую базу.
После того как мы научились мигрировать данные, пора было переключать процессы.
Поэтому пришлось использовать классический паттерн адаптера — у нас был сервис, который конвертировал старый API в набор новых API. Это хороший вариант, кроме одного момента — от этих адаптеров надо в какой-то момент избавляться. Для этого тоже есть несколько подходов.
Первый очень контексто-зависимый: мы делаем синхронизации, обратную совместимость, тратим много времени, при этом еще доделываем старую систему. Для нас это было очень дорого. Именно поэтому мы пошли решительным путем переключения с простоем (и без отката).
В специфике нашего бизнеса есть момент, который позволяет нам выводить систему в поддержку. Клиентский трафик поступает примерно с 8 до 23 часов, просто потому что склады так работают. Поэтому после полуночи, когда заканчиваются все асинхронные процессы, у нас есть возможность остановить клиентский трафик и сделать обновления. Мы этим активно пользовались — на ночь останавливали старую часть системы, поднимали новую, а потом фичетоглингом и\или деплоями переключали всех клиентов на новые end-point'ы.
Большой минус этого подхода — нельзя откатиться, потому что в новой системе данные могут быть модифицированы, а в старой их нет. Откат приведёт к тому, что часть данных может потеряться, в том числе и платежи.
У нас, чтобы найти информацию по какому-то процессу, достаточно написать в общий чат, и туда подключатся ребята из техподдержки и маркетинга, а также юристы и эксплуатация. Так создавались рабочие группы, в которых можно было быстро восстановить, что происходило. И в какой-то момент мы дошли до неделимого функционала.
Мы сразу сказали, что не будем двигать скоуп и откатываться, потому что откат приведет к сдвигу этого плана минимум на неделю. Но будем максимально стараться чинить то, что будет ломаться.
Минусы пути пиратов:
На нашем пиратском пути такого нельзя было допустить, тем более потому что на это наложатся неправильные оценки или забытые процессы. Именно поэтому мы использовали подход строгой приоритизации. Если без этой задачи прямо сейчас мы не умрем, то кладем её в конец бэклога. Правда, такой подход невозможен без непрерывного диалога с бизнесом. Потому что он должен четко понимать, что для него важно, а что — нет.
Это позволило нам без задержек следовать пути пиратов. Но мы не забывали про его минусы. Понимая, что на старте у нас точно будут проблемы, мы заложили много ресурсов на мониторинг и сверки.
Помимо него мы использовали подход сверок — это количественное сравнение сущностей в разных системах. Например, в подсистеме приема заказов мы проверяли, какое количество заказов туда поступило. В подсистеме сборки доставки заказов — сколько в ней имеется заказов. А в модулях оплаты и эквайринга мы сверяли, что все эти цифры совпадают.
Для сверки действует правило: чем больше, тем лучше. Это позволяет четко локализовать проблему. Но надо понимать, что если у вас распределенная архитектура, то может быть дрифт в данных и нужно правильно настроить алертинг, чтобы не было ошибочных срабатываний.

Как все это выглядело? Ждем, пока закончится клиентский трафик (заказы), и закрываем внешний доступ к мобильному приложению, останавливаем остатки старой системы, поднимаем новую и идем по плану. По таймингу всё получается хорошо. Прогоняем тестовые сценарии — естественно, находим пару багов и чиним. В семь утра 18 августа открываемся миру. Так выглядела команда инженеров, которая переключила продакшен.

Но через 10 минут пришел пользовательский трафик… и всё обрушилось. Чаты и мониторинги взорвались, коммуникации с бизнесом — тоже. Мобильное приложение больше не принимало заказы:

Мониторинг показал, что проблема с одной из подсистем, а именно — с бонусным движком. Там был некритичный функционал, поэтому его не протестировали на нагрузку, но он и уронил базу данных. Починить его было несложно: сделали фикс, переподключили и всё заработало. Были, правда еще проблемы со сторонними сервисами, но не с работой нашей системы.
Поэтому мы успешно переехали и все поставленные перед собой задачи выполнили.
Сменить стек в сжатые сроки нам помогло использование общей платформы: фиксация списка технологий, конвенции, общие библиотеки в самом начале и последующая строгая приоритезация задач. Это, как и поминутный план с проверяющим, сильно экономит время и облегчает работу всех инженеров. А исключение обидных ошибок позволяет сохранять темп и мотивацию.
Очень важно, чтобы любое действие, которое вы делаете, так или иначе несло ценность для бизнеса. Если бизнес не будет развиваться, то никакие технологии вам не помогут — технологии ради технологий никому не нужны. При этом не бойтесь решительных действий. Новую функциональность мы делаем классическим Agile, но продолжаем пропагандировать путь пиратов. Если вас что-то ограничивает от дальнейшего развития — технология, процесс или еще что-то — рубите узлы, чтобы быстро и качественно прыгнуть вперед.

 habr.com
habr.com
Но давайте по порядку. Меня зовут Александр Клюшкин. Я работаю в Самокате, и на нашем примере расскажу о сложностях перехода на новый стек. Зачем и кому это может понадобиться?
Самокат — это доставка различных товаров, в том числе продуктов питания с очень коротким SLA в 15 минут. Мы строим новый слой городской инфраструктуры, который поможет перемещать товары в пространстве практически мгновенно.
Когда я пришел в компанию, у нас был монолит на Python, который на самом деле был написан для совершенно других нужд. Только маленькая часть этой кодовой базы использовалась для организации бизнес-процессов. Сама компания переживала этап взрывного экспоненциального роста. На этом фоне было сильно заметно отставание разработки от бизнеса: разработка не могла поставлять фичи в продакшн с той скоростью, с которой это было нужно бизнесу.
Почему так происходило? Инженеры + инструменты = успех. На самом деле формула сложнее, но я упростил ее до двух компонент. Чтобы быстро и эффективно разрабатывать, нужны:
- Квалифицированные инженеры в нужном количестве;
- Эффективные инструменты, которые позволят сосредоточиться на реализации бизнес-логики и как можно меньше времени тратить на интеграции с инфраструктурой, тулинг и утилитарные штуки.
Во-вторых, у нас действительно были технические проблемы, связанные со стабильностью и производительностью. Мы стали думать, как нам разогнать перформанс разработки. Так у нас появилась идея, не попробовать ли сменить стек.
Цели и варианты замены стека
Мы поставили себе несколько задач. Пересмотреть доменную модель и под неё переработать архитектуру системы, попутно переехав на сервис-ориентированный подход (SOA). А еще мы хотели изменить организационную структуру и перейти от одного отдела разработки к кросс-функциональным продуктовым командам, чтобы можно было горизонтально масштабировать разработку, просто выделяя новый продукт и нанимая туда команду.Конечно, ускорить найм, чтобы в нужном объеме нанимать кандидатов за счет более широкого рынка. И начать быстрее разрабатывать, благодаря экосистеме технологического стека, которая имела бы все нужные компоненты для продуктовой разработки — их можно было бы просто подключать и использовать.
Стали смотреть, какие варианты есть. На рынке много языков, но от одних мы отказались из-за высокой конкуренции за профильных кандидатов, а от других — из-за сложности и специфичности языка.
Сначала мы обратили внимание на Golang. Хотя на тот момент Golang был молодым и быстро развивался, на рынке уже были продукты от больших компаний, доказавшие, что это состоятельный подход. Но мы тогда ещё были довольно маленькой компанией и понимали, что с этими ребятами побороться за кандидатов не сможем, поэтому стали искать дальше.
Следующий наш выбор пал на Kotlin. Это до сих пор стильный, модный, молодёжный язык с огромным комьюнити, где можно найти ответ практически на любой вопрос. В нем учтены многие недостатки других языков. Он не тащит за собой (пока, во всяком случае) шлейфа проблем, которые сдерживают его развитие. Он позволяет писать меньше кода (копипасты, бойлерплейты и т.д.), что механически экономит время. Меньше нажатий на кнопки, меньше чтения кода, а значит — меньше багов.
К тому же у него есть большое преимущество в найме, потому что конвертация из Java-разработчиков в Kotlin-разработчиков очень проста. Это увеличивало охват рынка кандидатов, с которыми мы могли бы работать. Мы решили использовать Kotlin для бэкенда и, когда определились с языком, стали думать, как реализовать остальное.
Выбор пути
Сначала мы рассмотрели классический путь.Остановка разработки
Останавливаем разработку старой системы, нанимаем команду инженеров и начинаем переписывать в целевом стеке и на целевой архитектуре. А когда всё будет готово, мы переключимся на новую систему.Среди плюсов такого подхода — простота и отсутствие необходимости содержать две команды разработки. Для больших компаний преимущества сомнительные, но для маленьких вполне значимые.
Правда, минусов значительно больше. Самый главный — остановка развития бизнеса! Мы бы не разрабатывали новые бизнес-фичи, что в условиях роста — путь в никуда. Думаю, все слышали истории, когда компания два года что-то переписывала, откладывая релиз, а потом проект закрылся. Всё потому, что рынок уже изменился настолько, что продукт в таком виде больше не нужен или не нужен вообще.
Помимо всего прочего, мы не могли спрогнозировать результат, поэтому начали обдумывать другие варианты и подошли к параллельной разработке.
Параллельная разработка
Рядом со старой командой сажаем новую, чтобы не останавливать разработку для бизнеса. Но две команды разработки — это довольно дорого. Не говоря уже, что скорость новой команды должна быть выше текущей, а на выходе мы снова получаем непонятный результат.Такие минусы нас тоже не устраивали, поэтому мы рассмотрели третий вариант.
Постепенное замещение
Стараемся делать весь новый функционал в целевой архитектуре (целевом стеке). А процессы, которые остаются на старой системе, переносим в режиме работы с техдолгом.У такого варианта есть явные плюсы: каждая задача начинает нести бизнес-ценность, что позволяет их легко приоритизировать. А самое главное — мы постоянно создаем добавочную стоимость для нашего бизнеса. Главное помнить, что распил старой платформы — не самоцель.
Но без минусов, конечно, тоже не обошлось. Этот подход очень сложный с точки зрения проектирования, потому что постоянно заставляет вас думать об ограничениях старой системы и учитывать их при разработке новой архитектуры. Это влияет на стоимость и скорость разработки. Но самое главное ограничение, в том, что постепенным замещением (в режиме совместимости) перенести весь функционал со старого стека не получится по многим причинам, в первую очередь из-за стоимости разработки или кардинальных отличий доменной модели. В какой-то момент всё равно придется переключаться на один из двух предыдущих путей.
Тем не менее мы выбрали именно этот путь, потому что он лучше всего синхронизировался с нашими задачами. И начали подбирать практики разработки.
Адаптация стека
Для постепенного замещения мы должны были пройти несколько этапов:- Зафиксировать технологии;
- Договориться о конвенциях;
- Договориться об инженерных практиках;
- Разработать общую платформу сервисов.
Технологии
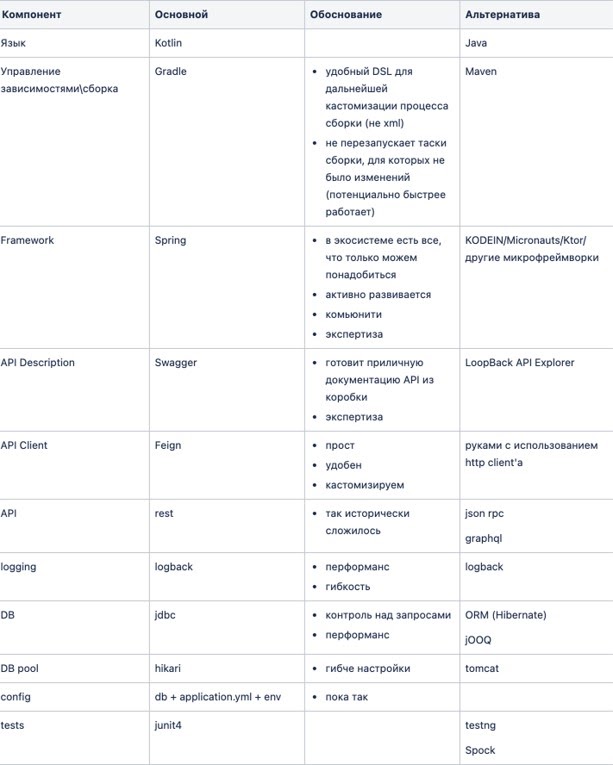
Помимо Kotlin и Spring мы зафиксировали основные технологии: библиотеки для работы с БД, сетевыми запросами, с логированием, описанием API и т.д.:
Если этого не сделать, то после набора команд будет два варианта развития событий. Инициативные ребята принесут что-то свое — то что умеют, знают и любят. А не очень инициативные будут ждать, пока к ним кто-то придет и расскажет, что делать. И в первом варианте вы, в лучшем случае, получите много разных технологий, и вам придется в них разбираться и как-то поддерживать. Но второй вариант будет гораздо хуже, когда у вас таким образом сложатся совершенно несовместимые технологии. Например, когда два сервиса на уровне библиотек не могут друг с другом взаимодействовать посредством поставляемых библиотек или требуют разных способов деплоя.
Конвенции
После технологий стоит сразу договориться о конвенциях. Иначе в начале разработки будут возникать недопонимания. Чтобы к ним постоянно не возвращаться и не тратить время, лучше зафиксировать договоренности в Confluence и отстроить процесс обсуждения конвенций.На старте, во всяком случае в нашей ситуации, нам приходилось постоянно усиливать разные части продукта в зависимости от приоритетов. Нам хорошо помогла ротация, когда мы для помощи новой команде переводили туда людей из старой. Им не приходилось тратить время на разбор каких-то инженерных вещей, так как они уже технически знали, что делать (надо было лишь погрузиться в бизнес-контекст, немного разобраться и они уже могли приносить пользу проекту).
Такие ротации помогают и в будущем, потому что людям со временем надоедает тот продукт, с которым они работают, и они хотят попробовать что-то другое.
Инженерные практики
Естественно, нужно договориться об инженерных практиках: как вы покрываете ваш сервис тестами, что тестируете, как проходит ревью сервиса, какие подходы к архитектуре используете и т.д. Это нужно по той же причине — чтобы новые ребята, которые приходят, во-первых, не тратили время на придумывание чего-то своего, во-вторых, чтобы у вас не было множества различных практик.Платформа сервиса
О практиках лучше подумать в самом начале, пока ещё мало сервисов и маленькая кодовая база. На старте вы, очевидно, будете делать что-то не так, совершая какие-то ошибки. И пока база маленькая, можно быстро маневрировать и всё исправлять.В самом начале разработки все разработчики и команды будут решать одни и те же проблемы. Чтобы не решать их несколько раз в рамках разных команд, это можно распараллелить: команда А решает свою часть проблем, команда В — другую, а далее обмениваться накопленной экспертизой и инструментарием.
Под платформой я понимаю некоторый шаблон. Если вы работали с Maven, то в его терминах это — архетип, который описывает структуру проекта: какие есть модули, за что они отвечают, зачем они нужны. Это набор библиотек для решения базовых потребностей, для интеграции с БД, Kafka, системой журналирования и логирования, мониторингами, CI и т.д.:
Если говорить про микросервисную архитектуру, то, чтобы избежать проблем с устареванием версий, удобно иметь источник правды и вносить в эту платформу (шаблон) любые изменения, автоматически перенося их в новые сервисы и обновляя в старых.
Если ничего этого не сделать в самом начале, а дать командам построить свои продукты, выехать в продакшн, отловить какие-то баги, всё починить и всё для себя разработать — в дальнейшем у них не будет мотивации для обобщения, хотя такие задачи будут приходить. Например, от ИБ придет задача внедрения SAST или эксплуатация захочет изменить порядок развёртывания — и все команды будут еще раз решать эти задачи, а вы потратите столько времени, сколько команд у вас есть. Но это можно сделать один раз в одной платформе, и все получат эти изменения.
Проблемы при переносе
Технологии мы зафиксировали, подход выбрали и пора было уже мигрировать на новый стек. Напомню, мы новый функционал делали на целевой системе, и в рамках работы с техдолгом переносили всё на новую систему. И первое, с чем вы столкнетесь — это миграция данных.Миграция данных
Никто не хочет потерять историю заказов пользователя или его учетную запись. А значит, данные надо полностью перенести из старой системы в новую. Для этого мы использовали несколько подходов.Первый вариант — ленивая миграция. В новый сервис приходит запрос и проверяет, есть ли у него необходимые данные для обработки. Если нет, то забирает их из старой системы, сохраняет себе и с ними уже работает. Если придет повторный запрос, он уже ничего запрашивать не будет, а сразу начнет работать с локальной копией.
В этом подходе есть один минус: он не гарантирует, что мы заберем все данные. Например, пользователь делает заказ раз в полгода, и его данные могли не перенестись.
Второй вариант более сложный — дорабатываем старую систему, учим ее обходить весь набор данных и перемещать в новую систему.
Для этого мы использовали Kafka. Новая система забирала данные из топиков, раскладывала в целевые структуры и начинала с ними работать. Этот способ сложно тестировать, особенно в нашем случае, когда старая система — это сильно связанный legacy монолит, который уже никто не помнит. Тестирование будет занимать очень много времени, да и разработка тоже.
Поэтому мы научили наш новый сервис работать с обеими базами данных. В рамках периодической задачи он ходил в старую БД, забирал оттуда данные и перекладывал в новую базу.
Для подобных задач в целом существуют готовы ETL решения, но нам они не подходили из-за сложной логики трансформации данных (вспомним, что мы не просто переезжали на новый стек, но и полностью меняли доменную модель). Так как мы уже знали Kotlin — и у нас на нем были сервисы — гораздо проще было написать эту логику там, чем адаптировать новый инструмент.“Внимание! Это очень грязный хак. Пожалуйста, не используйте его в продакшене, только в исключительных ситуациях”.
После того как мы научились мигрировать данные, пора было переключать процессы.
Перенос процессов на новые сервисы
У переноса процессов тоже есть несколько подходов. Самый простой — это техника подражания. Мы делаем новый сервис с таким же API, как у старой системы, и на балансировщике перенаправляем запросы в новую систему. Правда, так мы делали очень редко, потому что API подвергся жесткому рефакторингу и в старом виде больше не был нам нужен.Поэтому пришлось использовать классический паттерн адаптера — у нас был сервис, который конвертировал старый API в набор новых API. Это хороший вариант, кроме одного момента — от этих адаптеров надо в какой-то момент избавляться. Для этого тоже есть несколько подходов.
Первый очень контексто-зависимый: мы делаем синхронизации, обратную совместимость, тратим много времени, при этом еще доделываем старую систему. Для нас это было очень дорого. Именно поэтому мы пошли решительным путем переключения с простоем (и без отката).
В специфике нашего бизнеса есть момент, который позволяет нам выводить систему в поддержку. Клиентский трафик поступает примерно с 8 до 23 часов, просто потому что склады так работают. Поэтому после полуночи, когда заканчиваются все асинхронные процессы, у нас есть возможность остановить клиентский трафик и сделать обновления. Мы этим активно пользовались — на ночь останавливали старую часть системы, поднимали новую, а потом фичетоглингом и\или деплоями переключали всех клиентов на новые end-point'ы.
Большой минус этого подхода — нельзя откатиться, потому что в новой системе данные могут быть модифицированы, а в старой их нет. Откат приведёт к тому, что часть данных может потеряться, в том числе и платежи.
Отсутствие документации
Это другая проблема, с которой все сталкиваются. Не буду много о ней говорить. Есть несколько вариантов её решения, и один из них — открытая общая коммуникация. Очень важно, чтобы у вас по рабочим процессам не было приватных чатов и большого объема приватного общения.У нас, чтобы найти информацию по какому-то процессу, достаточно написать в общий чат, и туда подключатся ребята из техподдержки и маркетинга, а также юристы и эксплуатация. Так создавались рабочие группы, в которых можно было быстро восстановить, что происходило. И в какой-то момент мы дошли до неделимого функционала.
Неделимый функционал
Перенести неделимый функционал с помощью постепенного замещения — дорого. Например, меняя архитектуру при переезде на Kotlin, мы поменяли систему работы с адресами и перешли на координаты, а еще поменяли систему хранения каталога. Вроде бы это не связано между собой, но в заказе нужны товары из каталога, а также — данные пользователя с адресом. То есть эти три фичи завязаны друг на друга. И нам оставалось либо поддерживать любые изменения в двух структурах данных (старой и новой) и тратить на это колоссальное время, либо сделать решительный шаг. Мы выбрали последний и назвали его путём пиратов.Путь пиратов
Это экстремально быстрый скачок, который позволил бы нам заменить всю старую систему на новую. Мы договорились с бизнесом, что откладываем все остальные задачи на 2 месяца (максимальный срок, который бизнес был готов выделить) и занимаемся только этим.Мы сразу сказали, что не будем двигать скоуп и откатываться, потому что откат приведет к сдвигу этого плана минимум на неделю. Но будем максимально стараться чинить то, что будет ломаться.
Минусы пути пиратов:
- Остановка разработки новых фич;
- Высокий темп для команды инженеров;
- Что-то забудется, неправильно оценится и это придется выкинуть;
- На старте точно что-нибудь сломается.
- Больше никакого legacy;
- Отказ от SaaS экономил деньги;
- Целевая архитектура;
- Возможность масштабировать разработку так, как нам нужно.
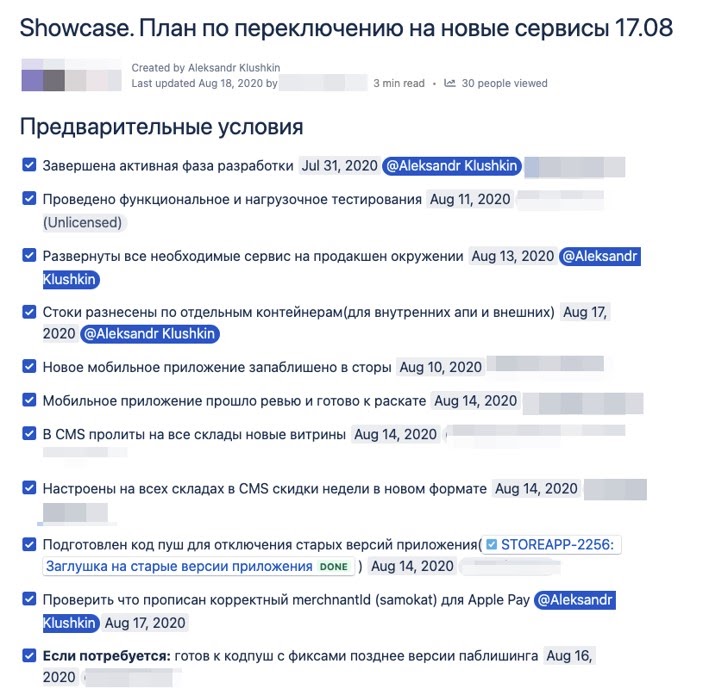
План
Для начала мы отправились в 17 августа, и начали методом обратного планирования продумывать, что нам надо сделать. Думаю, все писали планы. Тут главное — зафиксировать артефакты, которые надо получить, кто ответственен за определенный шаг и когда этот шаг должен быть сделан. А дальше остается настроить синхронизацию и жёстко контролировать выполнение плана:
Фокусировка
Всем известна проблема, что кто-то обязательно придёт и скажет: «Есть задача на 2 часа, давай ее быстро сделаем, она очень нужна и важна». Обычно это приводит к тому, что вы меняете контекст и теряете фокусировку, а задачи, которые стоили дешево, растягиваются на недели.На нашем пиратском пути такого нельзя было допустить, тем более потому что на это наложатся неправильные оценки или забытые процессы. Именно поэтому мы использовали подход строгой приоритизации. Если без этой задачи прямо сейчас мы не умрем, то кладем её в конец бэклога. Правда, такой подход невозможен без непрерывного диалога с бизнесом. Потому что он должен четко понимать, что для него важно, а что — нет.
Это позволило нам без задержек следовать пути пиратов. Но мы не забывали про его минусы. Понимая, что на старте у нас точно будут проблемы, мы заложили много ресурсов на мониторинг и сверки.
Мониторинг и сверки
На бизнес-мониторинге останавливаться не буду. Если у вас его по какой-то причине нет — его просто надо настроить.Помимо него мы использовали подход сверок — это количественное сравнение сущностей в разных системах. Например, в подсистеме приема заказов мы проверяли, какое количество заказов туда поступило. В подсистеме сборки доставки заказов — сколько в ней имеется заказов. А в модулях оплаты и эквайринга мы сверяли, что все эти цифры совпадают.
Для сверки действует правило: чем больше, тем лучше. Это позволяет четко локализовать проблему. Но надо понимать, что если у вас распределенная архитектура, то может быть дрифт в данных и нужно правильно настроить алертинг, чтобы не было ошибочных срабатываний.
Переключение
Когда подготовка подошла к финишу, мы поняли, что у нас примерно 6 часов на переключение (с полуночи до утра, пока не поступают заказы). Из-за ночных работ, стресса и усталости (два месяца интенсивной подготовки работ) могут произойти обидные ошибки: не туда нажал, не то сделал, не там посмотрел. Поэтому мы разработали поминутный план, где было четко расписано: действие и ответственный, который следит за всем процессом и записывает проблемы, и, главное, контролирующий — кто будет проверять факт выполнения каждого шага:План Б
Еще мы разработали план на тот случай, если все-таки придется откатываться. Мы решили, что сделаем это только в том случае, если не поднимемся в течение суток. Детально план не прорабатывали, наметили только верхнеуровневые направления, понимая, что все решения все равно будем принимать в моменте.Распределение сил
Естественно, все эти работы невозможны без людей. Но ребята и так уже устали, а после переключения будут выжаты полностью. Поэтому мы планировали работу сразу на следующие 2 дня и распределяли силы. Часть ребят поехала в офис заниматься работами по переключению, а часть осталась отсыпаться, чтобы утром помочь уже с теми проблемами, которые могут возникнуть на продакшене:
Как все это выглядело? Ждем, пока закончится клиентский трафик (заказы), и закрываем внешний доступ к мобильному приложению, останавливаем остатки старой системы, поднимаем новую и идем по плану. По таймингу всё получается хорошо. Прогоняем тестовые сценарии — естественно, находим пару багов и чиним. В семь утра 18 августа открываемся миру. Так выглядела команда инженеров, которая переключила продакшен.
Но через 10 минут пришел пользовательский трафик… и всё обрушилось. Чаты и мониторинги взорвались, коммуникации с бизнесом — тоже. Мобильное приложение больше не принимало заказы:
Мониторинг показал, что проблема с одной из подсистем, а именно — с бонусным движком. Там был некритичный функционал, поэтому его не протестировали на нагрузку, но он и уронил базу данных. Починить его было несложно: сделали фикс, переподключили и всё заработало. Были, правда еще проблемы со сторонними сервисами, но не с работой нашей системы.
Поэтому мы успешно переехали и все поставленные перед собой задачи выполнили.
Выводы
Что мы получили после смены стека? Мы избавились от legacy и старых систем, которые тормозили наше развитие. За девять месяцев масштабировали команду инженеров с 10 человек до 100 и перешли от отдела разработки к шести кросс-функциональным продуктовым командам. При этом старых инженеров успешно конвертировали в новый стек.Сменить стек в сжатые сроки нам помогло использование общей платформы: фиксация списка технологий, конвенции, общие библиотеки в самом начале и последующая строгая приоритезация задач. Это, как и поминутный план с проверяющим, сильно экономит время и облегчает работу всех инженеров. А исключение обидных ошибок позволяет сохранять темп и мотивацию.
Очень важно, чтобы любое действие, которое вы делаете, так или иначе несло ценность для бизнеса. Если бизнес не будет развиваться, то никакие технологии вам не помогут — технологии ради технологий никому не нужны. При этом не бойтесь решительных действий. Новую функциональность мы делаем классическим Agile, но продолжаем пропагандировать путь пиратов. Если вас что-то ограничивает от дальнейшего развития — технология, процесс или еще что-то — рубите узлы, чтобы быстро и качественно прыгнуть вперед.
Меняем стек на продакшене в сжатые сроки
Представьте, что команда инженеров всю ночь перетаскивала в продакшен новую систему, запускала ее, утром сделала свои первые заказы и даже получила их. Они еще не знают, что случится через 10 минут,...
habr.com