Системы мониторинга — очень нужная для админа вещь, ведь они позволяют получать от сервисов метрики, которые:
С точки зрения WebRTC стриминга, нас интересует не только загрузка CPU, памяти и канала связи, но и то, сколько сейчас на сервере стримов и сколько к ним подключено зрителей, не снижается ли качество картинки при раздаче потока зрителям.
Кто-то возразит - зачем мне мониторинг, если все данные по WebRTC можно найти в Chrome, данные по серверу посмотреть на самом сервере, расчеты по возможным биллингам (на связь, аренду серверов и пр.) можно смотреть в личных кабинетах? Но представьте, что это все требуется отслеживать в реальном времени. И при этом вести активный стрим. Cогласитесь, не совсем удобно все это щелкать, можно и пропустить что-то важное.
Кроме наблюдений за параметрами, система мониторинга может помочь и в своевременном обнаружении, и даже устранении каких-либо типовых неисправностей во время работы.
Итак, система мониторинга — это абсолютный маст-хэв, осталось только выбрать конкретную "модель". Систем мониторинга на сегодняшний день существует огромное множество на любой вкус, цвет и кошелек. Давайте познакомимся с относительно молодой опенсорсной системой мониторинга - Prometheus.
По сути, Prometheus является открытой (Apache 2.0) time series СУБД, написанной на языке Go. И эта штука просто хранит ваши метрики. Интересной особенностью Prometheus является то, что он сам собирает метрики с заданного множества сервисов (делает pull). Prometheus состоит из отдельных компонентов, которые общаются друг с другом по http и настраивается в yaml-конфигах. Это не готовое решение в духе “plug & play”. Prometheus скорее набор инструментов, позволяющий сделать себе такой мониторинг, какой надо. О том, как настроить мониторинг WCS сервера и WebRTC стримов в Prometheus и пойдет речь в нашей статье.
Деградация стрима — это такое состояние видео-аудиопотока, при котором качество картинки и звука не удовлетворительно. Наблюдаются артефакты, фризы, заикания или рассинхронизация звука.
Оценить текущую загрузку процессора можно с помощью программы htop. Или top. Или mpstat. На скриншоте ниже htop:
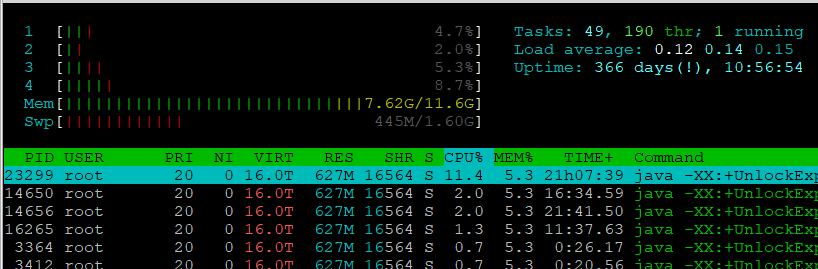
Обычно оценивается параметр Load average — среднее значение загрузки системы. Этот параметр, как правило, отображается в виде трёх значений, которые представляют собой усредненные данные о загрузке за последние 1, 5 и 15 минут. Чем меньше значение, тем лучше.
load average: 4.55 4.22 4.18
Например, такие значения для четырехъядерного процессора означает, что он работает на пределе своих возможностей в течении длительного времени (несколько часов) и такая работа обязательно приведет к деградации стримов.
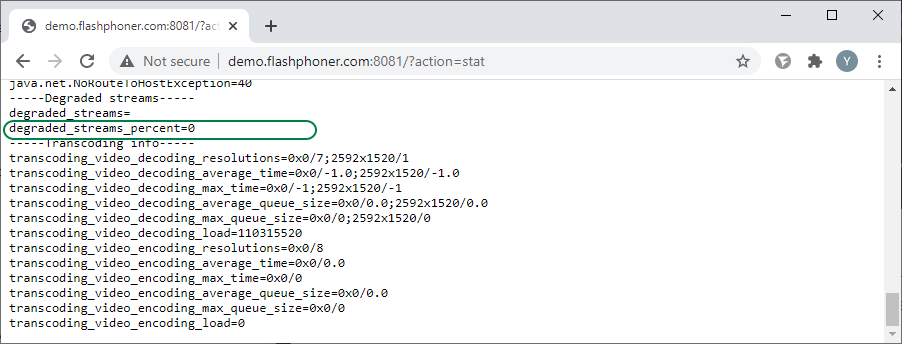
Найти значение degraded_streams_percent можно на странице статистики http://demo.flashphoner.com:8081/?action=stat (где demo.flashphoner.com - это адрес WCS-сервера.)
Следующие несколько метрик относятся к работе Java Virtual Machine:
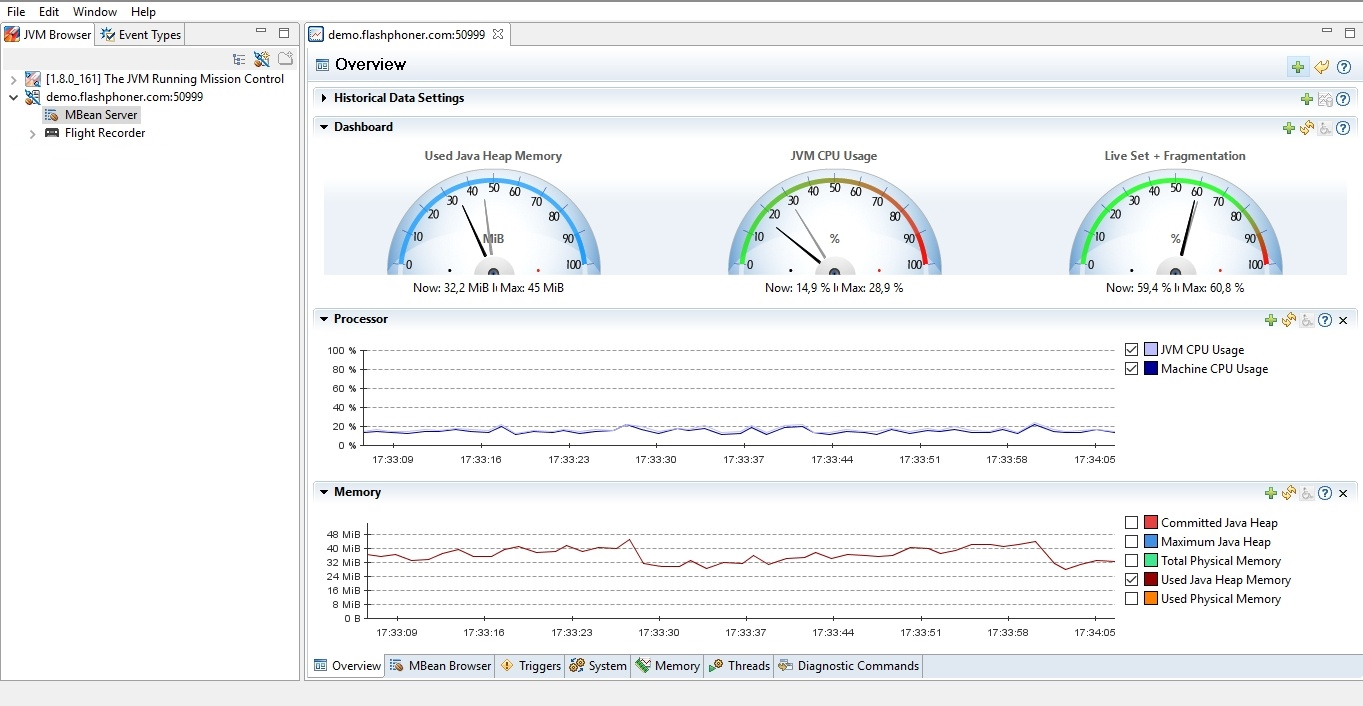
Отслеживать эти метрики можно при помощи инструмента Java Mission Control. Java Mission Control - это мощный инструмент для мониторинга и отладки Java-машины, который поставляется вместе с JDK и запускается на ПК пользователя (администратора).
Метрики очередей декодинга/энкодинга:
transcoding_video_decoding_max_queue_size
transcoding_video_encoding_max_queue_size
Метрики максимального времени декодинга/энкодинга
transcoding_video_decoding_max_time
transcoding_video_encoding_max_time
Эти метрики доступны на странице статистики:

Важная метрика для высоконагруженных серверов. Под каждый стрим выделяются порты. Если порты в диапазоне заканчиваются, добавление новых стримов на сервере будет вызывать ошибку.
Информацию по количеству портов можно найти на странице статистики:

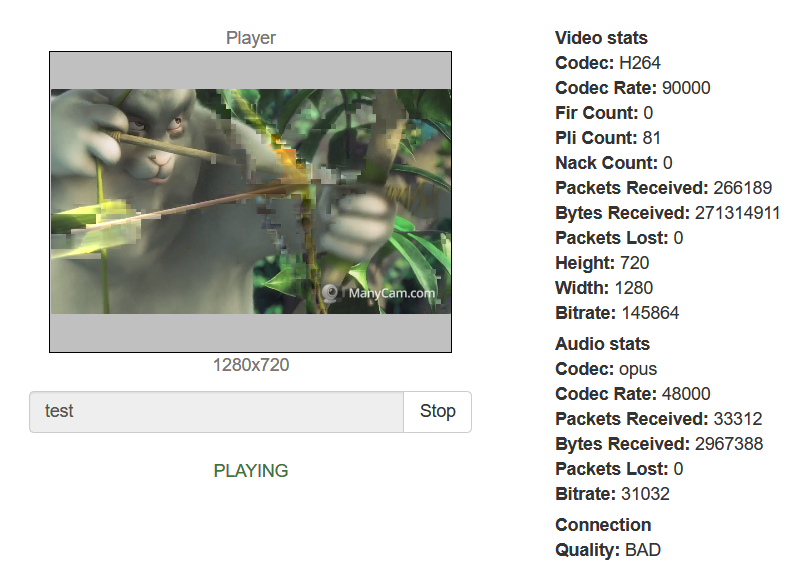
Важная метрика, имеющая также название lipsync (синхронизация губ и голоса в видео трансляциях). Рассинхронизация может быть вызвана разными причинами, начиная от некачественного источника потока и заканчивая проблемами производительности сервера. При рассинхронизации в 100 и более миллисекунд, человеческое ухо и глаз уже будут фиксировать непорядок. Метрика позволяет увидеть этот момент в цифрах, в миллисекундах для каждого стрима, положительное значение метрики показывает, что аудио в данный момент обгоняет видео, а отрицательное - что аудио отстает от видео.
На скриншоте ниже с синхронизацией аудио и видео в стримах все в пределах нормы. Метрика показывает значения от +2 до +79 миллисекунд.

Метрики:
native_resources.video_decoders
native_resources.video_encoders
На скриншоте ниже транскодирование не используется.
Метрики:
transcoding_video_decoding_load
transcoding_video_encoding_load

iptables -I INPUT 1 -p tcp --match multiport --dports 9090,9093,9094,9100 -j ACCEPT
iptables -A INPUT -p udp --dport 9094 -j ACCEPT
Если вы используете операционную систему на базе Red Hat, вероятно, по умолчанию, будет включена подсистема SELinux. Отключить ее можно при помощи команд
sudo setenforce 0
sudo sed -i 's/^SELINUX=.*/SELINUX=disabled/g' /etc/selinux/config
Теперь мы готовы к установке Prometheus и Grafana.
Скачать исходник можно с официальной страницы загрузки. Копируем ссылку на пакет для Linux и скачиваем при помощи wget:
wget https://github.com/prometheus/prome.../v2.21.0/prometheus-2.21.0.linux-amd64.tar.gz
Создаем каталоги, в которые скопируем файлы для Prometheus:
mkdir /etc/prometheus
mkdir /var/lib/prometheus
Распаковываем скачанный архив:
tar zxvf prometheus-*.linux-amd64.tar.gz
Переходим в каталог с распакованными файлами:
cd prometheus-*.linux-amd64
Распределяем файлы по каталогам:
cp prometheus promtool /usr/local/bin/
cp -r console_libraries consoles prometheus.yml /etc/prometheus
Создаем пользователя, от которого будем запускать систему мониторинга:
sudo useradd --no-create-home --shell /bin/false prometheus
Задаем владельца для каталогов, которые мы создали на предыдущем шаге:
sudo chown -R prometheus rometheus /etc/prometheus /var/lib/prometheus
rometheus /etc/prometheus /var/lib/prometheus
Задаем владельца для скопированных файлов:
sudo chown prometheusrometheus /usr/local/bin/{prometheus,promtool}
Настраиваем автозапуск Prometheus:
Создаем файл prometheus.service:
sudo nano /etc/systemd/system/prometheus.service
Размещаем в нем следующий текст:
[Unit]
Description=Prometheus Service
After=network.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/prometheus \
--config.file /etc/prometheus/prometheus.yml \
--storage.tsdb.path /var/lib/prometheus/ \
--web.console.templates=/etc/prometheus/consoles \
--web.console.libraries=/etc/prometheus/console_libraries
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
Перечитываем конфигурацию systemd:
sudo systemctl daemon-reload
Разрешаем автозапуск:
sudo systemctl enable prometheus
После создания автозапуска запускаем Prometheus, как службу:
sudo systemctl start prometheus
В браузере открываем http://<IP-адрес сервера>:9090, и, если все сделано правильно, попадаем в консоль системы мониторинга Prometheus. Пока что она бесполезна, но уже можно понажимать и посмотреть менюшки.
Итак, подключаем WCS к мониторингу. Открываем на редактирование файл настроек prometheus.yml
sudo nano /etc/prometheus/prometheus.yml
Добавляем в файл описание конфигурации мониторинга:
scrape_configs:
- job_name: 'flashphoner'
metrics_path: '/'
params:
action: [stat]
format: [prometheus]
static_configs:
- targets: ['WCS_address:8081']
где:
После изменения файла настроек prometheus.yml перезапускаем службу:
sudo systemctl restart prometheus
Возвращаемся к консоли Prometheus, выбираем пункт меню "Status => Targets":
И убеждаемся, что Prometheus получает данные от WCS (таргет в состоянии "UP"):
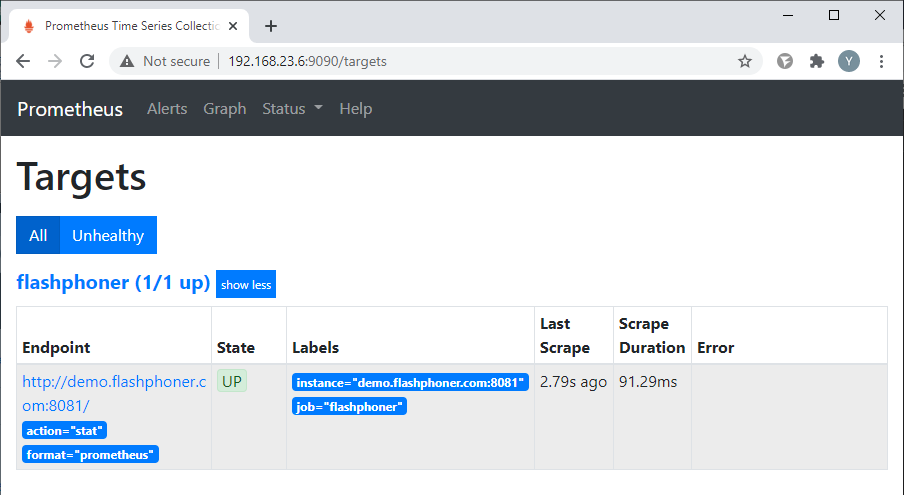
На этом все, с частью настройки мониторинга закончили. Переходим кводным процедурам настройке графиков.
Приступим.
Grafana также, как и Prometheus будем устанавливать вручную с помощью deb пакета. На https://grafana.com/grafana/download находим ссылку на свежий пакет и скачиваем его при помощи wget:
wget https://dl.grafana.com/oss/release/grafana_7.2.1_amd64.deb
Распаковываем:
sudo dpkg -i grafana_7.2.1_amd64.deb
Разрешаем автозапуск:
sudo systemctl enable grafana-server
Запускаем:
sudo systemctl start grafana-server
Открываем веб-интерфейс по адресу http://<IP-адрес сервера>:3000. Логин и пароль по умолчанию: admin/admin. При первом входе Grafana сразу предложит сменить пароль.
Меняем пароль и добавляем Prometheus в качестве источника данных:
Нажимаем кнопку "Add data source":
и выбираем Prometheus:
Указываем параметры для подключения. Достаточно указать адрес и порт Web интерфейса Prometheus для сохранения нажимаем кнопку Save & Test:
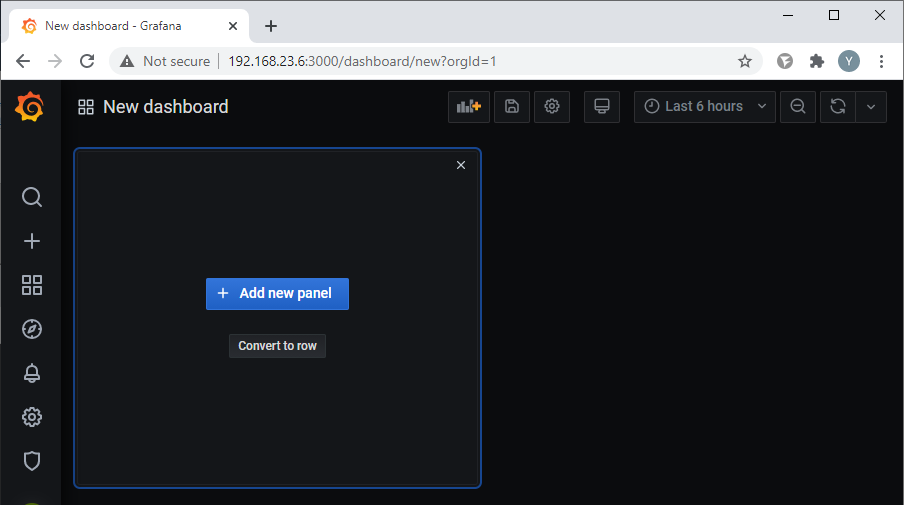
После успешного подключения создаем новую панель для графиков. Выбираем из меню в левой части окна Create - Dashboard:

Нажимаем кнопку "Add new panel":

На вкладке "Query" в качестве источника данных выбираем созданный ранее Prometheus(1) и выбираем из списка интересующие нас метрики (2):

Далее можно пройти по остальным пунктам, выбрав конкретные параметры и тип графика. После сохраняем настройку панели (3).
Задаем имя дашборда и сохраняем:
На скриншоте выше на графике отображаются все доступные метрики для stream_stats.
Можно сделать график для какой-то конкретной интересующей вас метрики. Для этого нужно указать ее название в поле "Metrics". Например, на скриншоте ниже мы выбрали метрику "Число входящих RTSP стримов" :

Теперь создадим графики для ключевых метрик, которые мы разбирали в начале этой статьи.
Строки для выбора метрики:
Процент деградировавших стримов:
degraded_streams_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="degraded_streams"}
degraded_streams_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="degraded_streams_percent"}
Java heap:
core_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="core_heap_memory_used"}
Использование физической памяти для Java:
core_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="core_java_freePhysicalMemorySize"}
core_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="core_java_totalPhysicalMemorySize"}
Очереди транскодеров и время транскодинга:
transcoding_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="transcoding_video_decoding_max_queue_size"}
transcoding_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="transcoding_video_encoding_max_queue_size"}
transcoding_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="transcoding_video_decoding_max_time"}
transcoding_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="transcoding_video_encoding_max_time"}
Количество свободных портов для стриминга:
port_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="ports_media_free"}
Синхронизация аудио и видео в стримах:
streams_stats{instance="demo.flashphoner.com:8081", job="flashphoner", name="s1", param="streams_synchronization"}
Количество открытых транскодеров:
native_resources{instance="demo.flashphoner.com:8081", job="flashphoner", param="native_resources.video_decoders"}
native_resources{instance="demo.flashphoner.com:8081", job="flashphoner", param="native_resources.video_encoders"}
Суммарная нагрузка на транскодеры:
transcoding_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="transcoding_video_encoding_load"}
transcoding_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="transcoding_video_decoding_load"}
Вид дашборда с графиками:
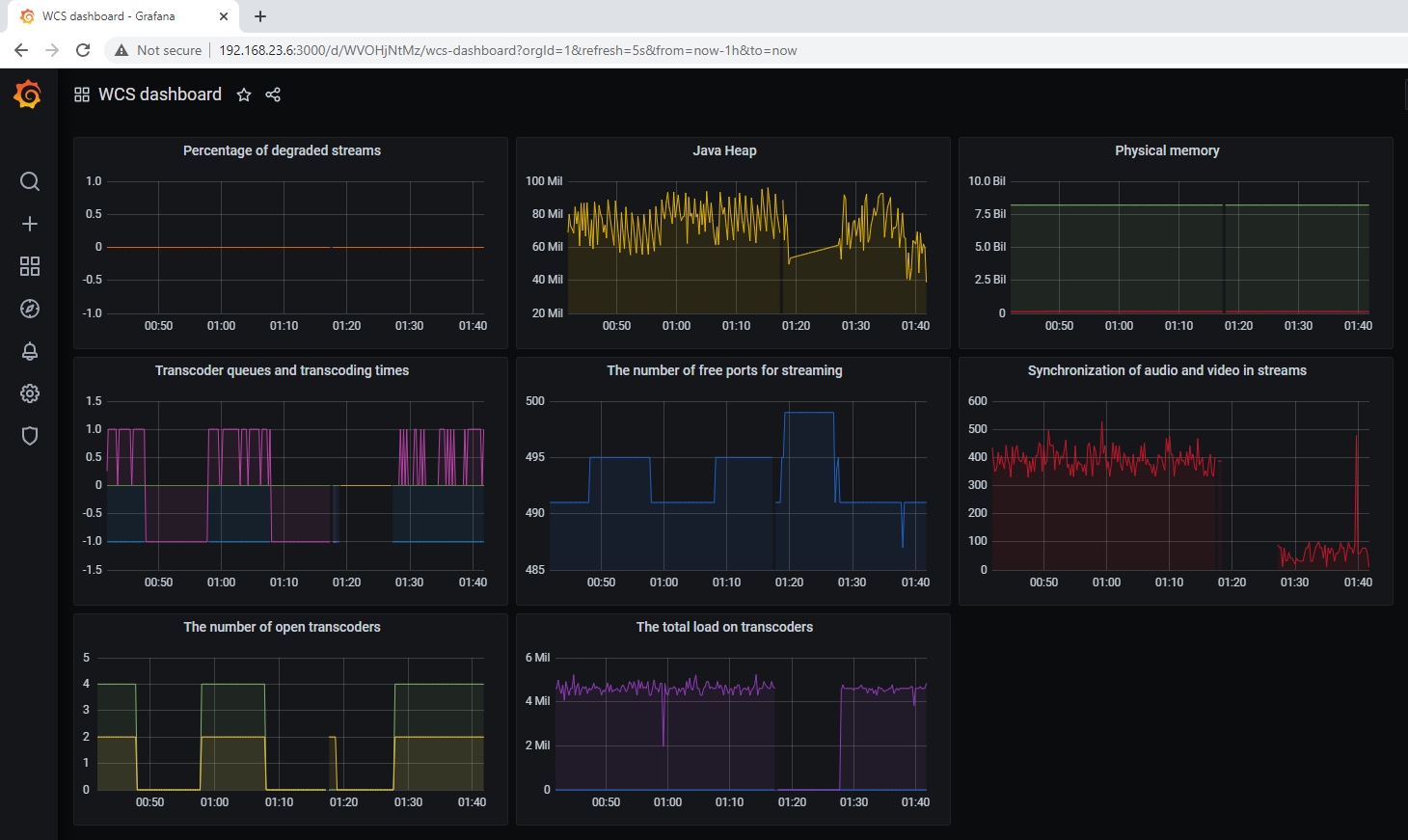
К сожалению, пока мы не получили все интересующие нас метрики. Метрик 10, а графиков удалось построить только 8. Давайте найдем недостающие графики — CPU и Java GC pause.
Например, так:
sudo firewall-cmd --zone=public --add-port=9100/tcp --permanent
Дальнейший процесс установки такой же, как у Prometheus.
Скачиваем node_exporter по ссылке с официальной страницы
wget https://github.com/prometheus/node_...v1.0.1/node_exporter-1.0.1.linux-amd64.tar.gz
Распаковываем скачанный архив:
tar zxvf node_exporter-*.linux-amd64.tar.gz
И переходим в каталог с распакованными файлами:
cd node_exporter-*.linux-amd64
Копируем исполняемый файл в bin:
cp node_exporter /usr/local/bin/
Создаем пользователя nodeusr:
sudo useradd --no-create-home --shell /bin/false nodeusr
Задаем владельца для исполняемого файла:
sudo chown -R nodeusr:nodeusr /usr/local/bin/node_exporter
Для настройки автозапуска в systemd создаем файл node_exporter.service:
nano /etc/systemd/system/node_exporter.service
Размещаем в нем следующий текст:
[Unit]
Description=Node Exporter Service
After=network.target
[Service]
User=nodeusr
Group=nodeusr
Type=simple
ExecStart=/usr/local/bin/node_exporter
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
Перечитываем конфигурацию systemd:
sudo systemctl daemon-reload
Разрешаем автозапуск:
sudo systemctl enable node_exporter
Запускаем службу:
sudo systemctl start node_exporter
Открываем веб-браузер и переходим по адресу http://<IP-адрес WCS сервера>:9100/metrics — мы увидим метрики, собранные node_exporter:
Теперь свяжем node_exporter на WCS с сервером Prometheus.
На сервере Prometheus открываем на редактирование конфигурационный файл prometheus.yml:
sudo nano /etc/prometheus/prometheus.yml
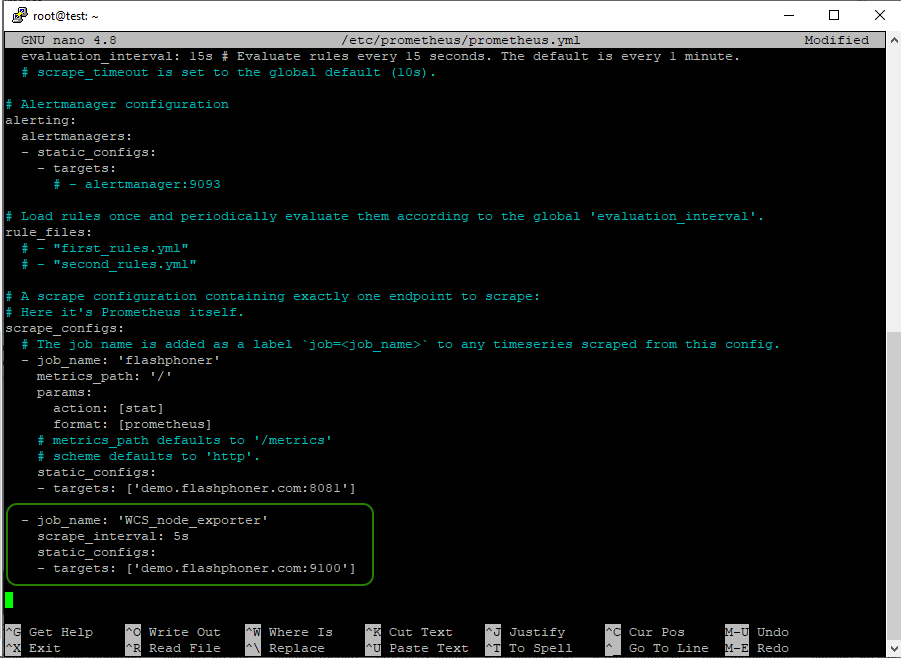
и добавляем новое задание для сбора данных от node_exporter на WCS. Будьте внимательны с отступами в yml файле:
- job_name: 'WCS_node_exporter'
scrape_interval: 5s
static_configs:
- targets: ['demo.flashphoner.com:9100']
После изменения файла настроек prometheus.yml перезапускаем службу:
sudo systemctl restart prometheus
Переходим к Grafana и добавляем на ранее созданный дашборд график для загрузки CPU:
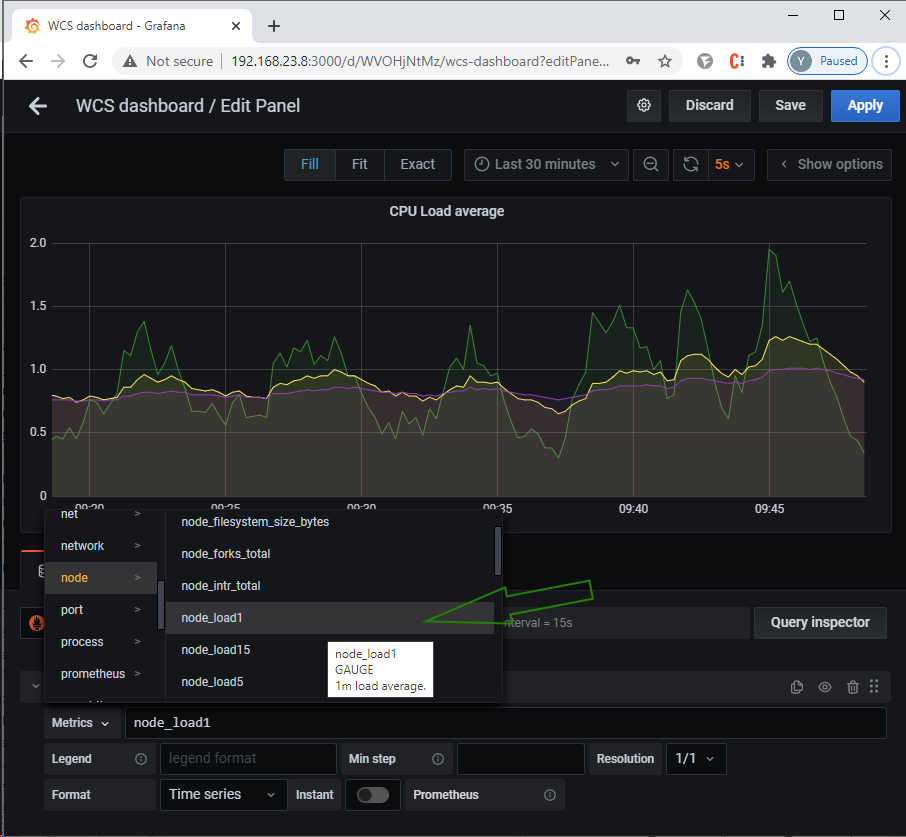
Метрики для CPU:
node_load1
node_load5
node_load15
Для включения этой функции нужно указать путь к файлу скрипта для сбора статистики в файле "flashphoner.properties", например, для файла custom_stats.sh расположенного в каталоге /usr/local/FlashphonerWebCallServer/bin можно прописать так:
custom_stats_script=custom_stats.sh
Если путь до файла скрипта у вас будет другой, то его нужно указать полностью:
custom_stats_script=/path/to/custom_stats.sh
Напишем скрипт, который соберет данные о паузах для работы сборщика мусора Java
#!/bin/bash
WCS_HOME="/usr/local/FlashphonerWebCallServer"
LAST_LOG=$(ls -t ${WCS_HOME}/logs/ | grep gc-core | head -1)
LOG="${WCS_HOME}/logs/${LAST_LOG}"
JAVA_VER=$(java -version 2>&1 | head -n 1 | awk -F '"' '{print $2}')
TYPE_GC="$(grep -Pv '^(#|$)' ${WCS_HOME}/conf/wcs-core.properties | grep -oE 'ConcMarkSweepGC|ZGC')"
#GC
if [[ $JAVA_VER != "1"[0-9]* ]]; then
gc_pause=$(grep 'Allocation Failure' $LOG | tail -1 | awk -F'->' '{print $3}' | sed -rn 's/([0-9]+)K\(([0-9]+)K\), ([0-9]+.[0-9]+).*/\3/p' | tr , . | awk '{printf "%f\n", $1 * 1000 }')
echo "gc_pause=$gc_pause"
#ZGC
elif [[ $JAVA_VER == "1"[0-9]* ]]; then
if [[ $TYPE_GC == "ConcMarkSweepGC" ]]; then
gc_pause=$(grep 'Allocation Failure' $LOG | tail -1 | awk '{print $8}' | sed 's/ms$//')
echo "gc_pause=$gc_pause"
fi
if [[ $TYPE_GC == "ZGC" ]]; then
gc_pause=$(grep '.*GC.*Pause' $LOG | awk -F 'Pause Mark Start|End|Relocate Start' '{print $2}' | tail -3 | sed 's/ms$//' | awk '{a=$1; getline;b=$1;getline;c=$1;getline;t=a+b+c;print t}')
echo "gc_pause=$gc_pause"
fi
fi
Этот скрипт запрашивает версию установленной в системе Java и, согласно этой информации, находит в логе строки с данными о паузах на сборку мусора для GС или ZGC и выводит это значение (в миллисекундах) в параметр "gc_pause".
Статистика, которую мы собрали с помощью внешнего скрипта, выводится на странице статистики http://demo.flashphoner.com:8081/?action=stat в секции "Custom info" :
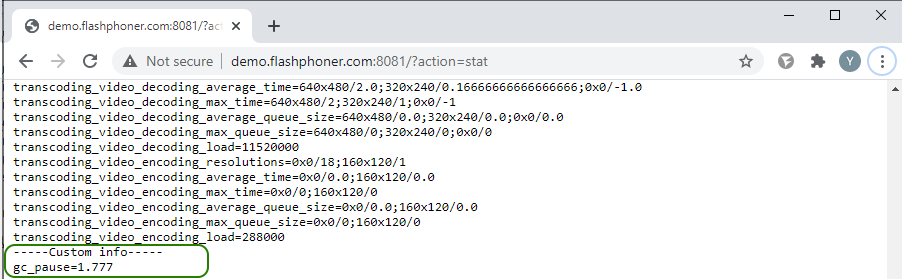
Откуда ее забирает ранее настроенная нами система мониторинга Prometheus.
Теперь добавим график для этой метрики на дашборд в Grafana:

Метрика для Java GC pause:
custom_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="gc_pause"}
Общий вид дашборда с графиками для мониторинга метрик работы WCS
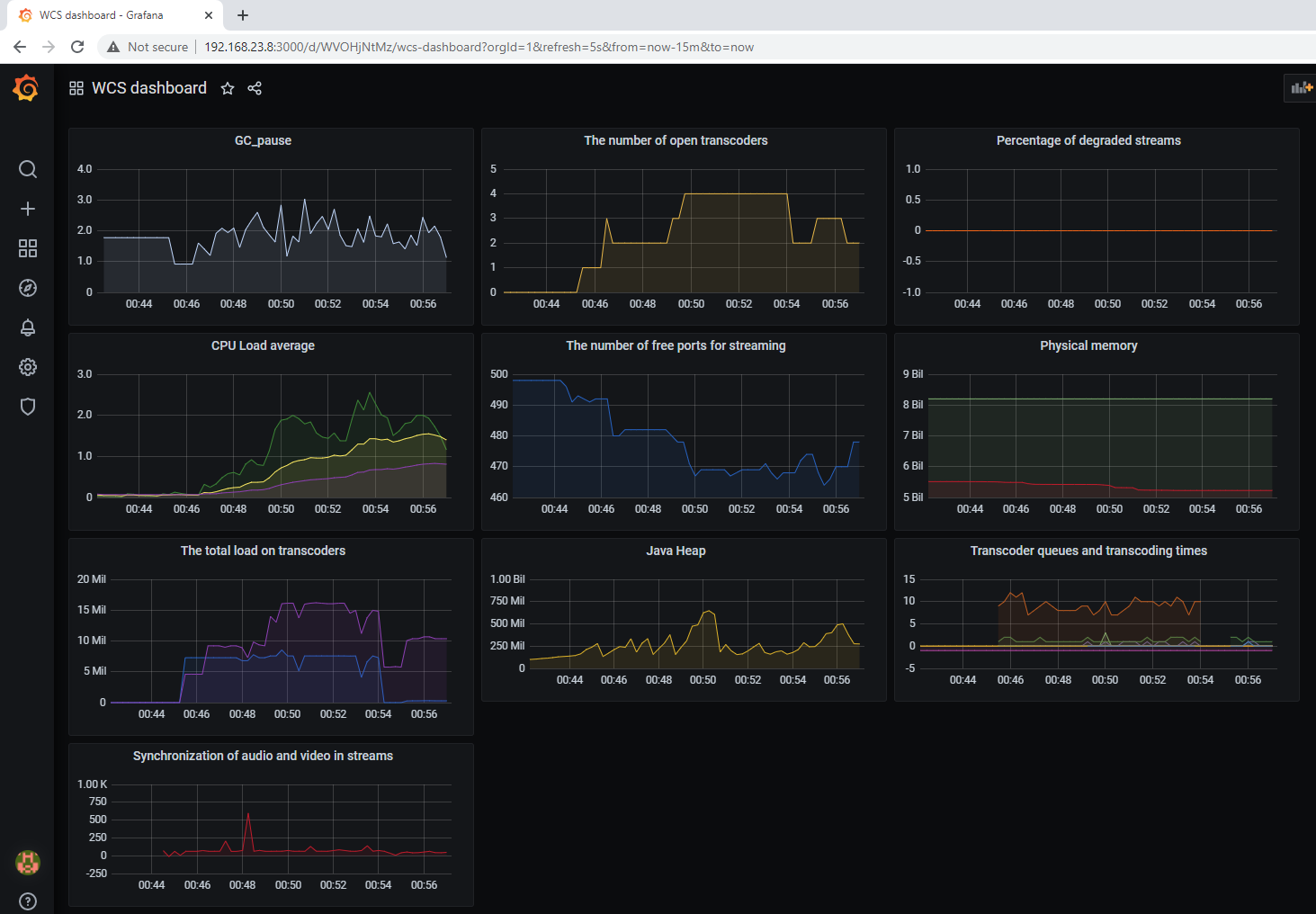
Мы собрали и построили графики для метрик работы сервера. Теперь рассмотрим, как можно построить графики для параметров конкретного стрима, который будет публиковаться на сервере.
/stream/metrics
в результате будет получен достаточно обширный список метрик. И, если с метриками типа "VIDEO_HEIGHT" , "VIDEO_WIDTH", "VIDEO_CODEC" и "AUDIO_CODEC" все понятно из их названий, то с другими метриками предлагаю познакомиться подробнее
Метрики "AUDIO_SYNC" и "VIDEO_SYNC" — это уже знакомая нам метрика синхронизации аудио и видео в опубликованных потоках.
Метрика "VIDEO_K_FRAMES" — Количество ключевых кадров (I-frames) видео. Ключевой кадр содержит всю информацию об изображении в кадре и никак не зависит от других кадров. Ключевые кадры имеют самую низкую степень сжатия. Если браузер отправляет ключевые кадры не равномерно, то это может приводить к фризам при воспроизведении потока. С этой метрикой тесно связана следующая:
Метрика "VIDEO_PLI" — Количество PLI-запросов на получение ключевых кадров от браузера. PLI может быть отправлен, когда получатель потока потерял полный кадр или несколько кадров. Большое количество PLI запросов свидетельствует о плохом канале.
Метрики "VIDEO_P_FRAMES" и "VIDEO_B_FRAMES" — Количество P-кадров (промежуточных) и B-кадров (двунаправленных) соответственно. Промежуточный кадр может ссылаться на блоки изображения в предыдущем ключевом или предыдущих промежуточных кадрах. Это позволяет делать промежуточные кадры по размеру меньше ключевых: в них записано меньше информации об изображении. Двунаправленный кадр также содержит не всё изображение. Но в отличие от промежуточного кадра, он может ссылаться и на последующие за ним кадры, вплоть до следующего промежуточного кадра: отсюда и происходит его название. Двунаправленные кадры занимают ещё меньше места, чем промежуточные. Способ декодирования двунаправленного кадра ещё сложнее, чем декодирование промежуточного кадра: сначала по описанной выше схеме декодируется следующий за двунаправленным промежуточный кадр; потом, используя информацию о соседних кадрах, декодируется двунаправленный кадр.
Получается, что чем чаще в потоке встречаются B кадры, тем больше ресурсов требуется на декодирование этого потока, что может отрицательно сказаться на качестве видео. Более того, браузеры не умеют корректно проигрывать B-фреймы, и, при наличии двунаправленных кадров, изображение будет подергиваться.
Метрики "AUDIO_RATE" и "VIDEO_RATE" показывают битрейт аудио или видео.
Метрика "VIDEO_FPS" — Частота кадров видео
И еще три метрики связанные с потерями пакетов на каналах связи:
"VIDEO_NACK" — Количество NACK-запросов. NACK — это способ для принимающей стороны указать, что она не получила определенный пакет или список пакетов.
"VIDEO_LOST" — Количество потерянных пакетов видео.
"AUDIO_LOST" — Количество потерянных пакетов аудио.
Большое количество NACK-запросов и потерянных пакетов так же означают проблемы с каналами связи. Проявляется это фризами в потоке, пропаданием звука и прочими неприятными штуками.
Перечисленные выше метрики для публикуемых потоков доступны и в веб-интерфейсе на странице статистики:

Метрики отображаются на странице статистики, если на сервере есть хотя бы один опубликованный поток. Теперь подключим их к сбору в Prometheus. Для этого, в файле настроек prometheus.yml,
sudo nano /etc/prometheus/prometheus.yml
добавляем новое задание для сбора данных по метрикам для стрима. Будьте внимательны с отступами в yml файле:
- job_name: 'stream_metrics'
metrics_path: '/'
params:
action: [stat]
format: [prometheus]
groups: [publish_streams]
static_configs:
- targets: ['demo.flashphoner.com:8081']
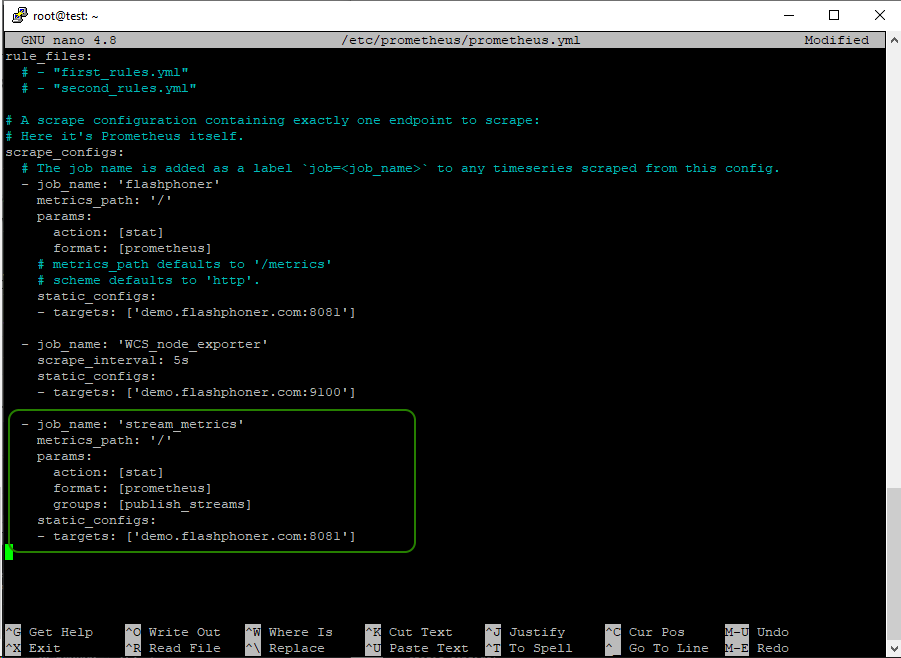
Сохраняем конфигурацию и перезапускаем Prometheus:
sudo systemctl restart prometheus
Переходим к Grafana. Предлагаю создать новую панель для графиков метрик стримов. Выбираем из меню в левой части окна Create - Dashboard
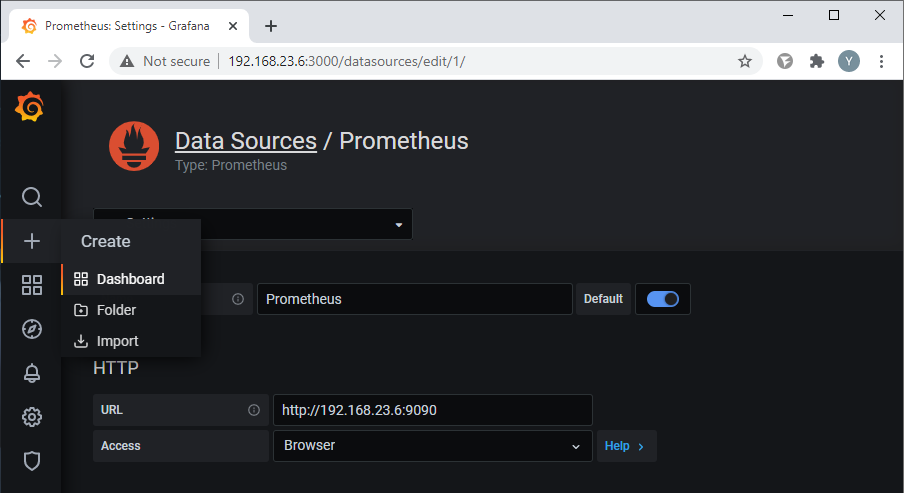
Нажимаем кнопку "Add new panel"
На вкладке "Query" в качестве источника данных выбираем Prometheus и выбираем из списка метрик publish => publish_streams:
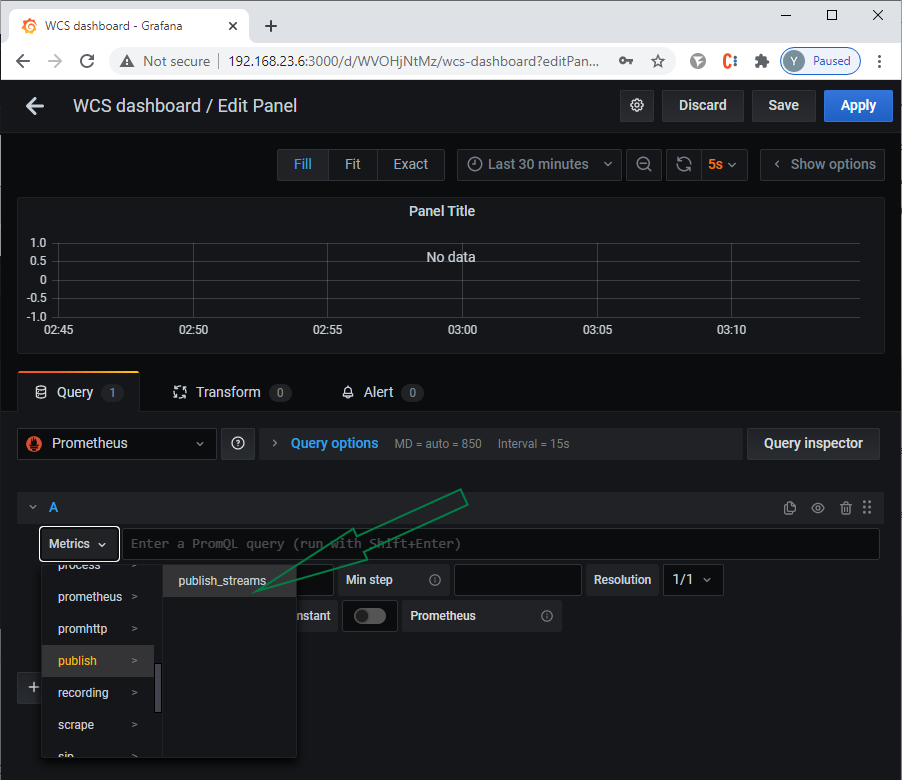
В результате получаем графики для всех доступных метрик для каждого опубликованного стрима. Для наглядности можно вывести интересующие метрики на отдельный график. Например, список метрик для опубликованного на demo.flashphoner.com потока с именем "stream1"
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="AUDIO_CODEC"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="AUDIO_LOST"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="AUDIO_RATE"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="AUDIO_SYNC"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_B_FRAMES"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_CODEC"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_FPS"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_HEIGHT"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_K_FRAMES"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_LOST"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_NACK"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_PLI"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_P_FRAMES"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_RATE"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_SYNC"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_WIDTH"}
Пример такого дашборда ниже:

Как видите Prometheus — инструмент достаточно любопытный и многообещающий. Наша статья не может претендовать на полноту описания этой системы мониторинга, потому что мы рассматривали только частный случай, применимо к мониторингу WCS и стримов. Например, Prometheus позволяет настраивать еще и алерты, чего мы не рассматривали. Но, прочитав эту статью, вы теперь знаете, зачем нужны Prometheus и Grafana, и сможете их успешно применить на практике.
Хорошего стриминга!
WCS на Amazon EC2 - Быстрое развертывание WCS на базе Amazon
WCS на DigitalOcean - Быстрое развертывание WCS на базе DigitalOcean
WCS в Docker - Запуск WCS как Docker контейнера
Документация по быстрому развертыванию и тестированию WCS сервера
Документация по мониторингу информации о нагрузке и ресурсах
Документация по организации мониторинга с помощью Prometheus

 habr.com
habr.com
- Дают представление о текущей нагрузке на сервер;
- Показывают здоров ли сервис, правильно ли он функционирует прямо сейчас?
С точки зрения WebRTC стриминга, нас интересует не только загрузка CPU, памяти и канала связи, но и то, сколько сейчас на сервере стримов и сколько к ним подключено зрителей, не снижается ли качество картинки при раздаче потока зрителям.
Кто-то возразит - зачем мне мониторинг, если все данные по WebRTC можно найти в Chrome, данные по серверу посмотреть на самом сервере, расчеты по возможным биллингам (на связь, аренду серверов и пр.) можно смотреть в личных кабинетах? Но представьте, что это все требуется отслеживать в реальном времени. И при этом вести активный стрим. Cогласитесь, не совсем удобно все это щелкать, можно и пропустить что-то важное.
Кроме наблюдений за параметрами, система мониторинга может помочь и в своевременном обнаружении, и даже устранении каких-либо типовых неисправностей во время работы.
Итак, система мониторинга — это абсолютный маст-хэв, осталось только выбрать конкретную "модель". Систем мониторинга на сегодняшний день существует огромное множество на любой вкус, цвет и кошелек. Давайте познакомимся с относительно молодой опенсорсной системой мониторинга - Prometheus.
По сути, Prometheus является открытой (Apache 2.0) time series СУБД, написанной на языке Go. И эта штука просто хранит ваши метрики. Интересной особенностью Prometheus является то, что он сам собирает метрики с заданного множества сервисов (делает pull). Prometheus состоит из отдельных компонентов, которые общаются друг с другом по http и настраивается в yaml-конфигах. Это не готовое решение в духе “plug & play”. Prometheus скорее набор инструментов, позволяющий сделать себе такой мониторинг, какой надо. О том, как настроить мониторинг WCS сервера и WebRTC стримов в Prometheus и пойдет речь в нашей статье.
Какие метрики будем отслеживать?
Качество потока, как уже неоднократно обсуждалось, величина не постоянная и зависит от многих факторов: это и нагрузка на сервер при наличии или отсутствии транскодинга, и использование TCP или UDP протоколов транспорта, и наличие потерь пакетов и/или NACK фидбеков и др. Все эти данные, для оценки качества потока, можно получать вручную из различных источников.Деградация стрима — это такое состояние видео-аудиопотока, при котором качество картинки и звука не удовлетворительно. Наблюдаются артефакты, фризы, заикания или рассинхронизация звука.
Метрика 1: CPU Load average
Если процессор загружен более чем на 80% и/или периодически загрузка CPU поднимается до 100%, это означает, что сервер перегружен и ему не хватает вычислительной мощности для выполнения рабочих операций, что обязательно повлечет за собой деградацию стримов.Оценить текущую загрузку процессора можно с помощью программы htop. Или top. Или mpstat. На скриншоте ниже htop:
Обычно оценивается параметр Load average — среднее значение загрузки системы. Этот параметр, как правило, отображается в виде трёх значений, которые представляют собой усредненные данные о загрузке за последние 1, 5 и 15 минут. Чем меньше значение, тем лучше.
load average: 4.55 4.22 4.18
Например, такие значения для четырехъядерного процессора означает, что он работает на пределе своих возможностей в течении длительного времени (несколько часов) и такая работа обязательно приведет к деградации стримов.
Метрика 2: Процент деградировавших стримов
Следующая метрика, которая напрямую связана с предыдущей: degraded_streams_percent — процент деградировавших стримов. Стрим деградирует, если сервер не успевает обрабатывать очередь этого стрима. Сервер работает многопоточно (multithreading). Видео данные публикуемого стрима помещаются в очередь, и отправка данных осуществляется отдельным тредом. В случае высокой нагрузки на CPU и нехватки производительности для кодирования/декодирования или при внутренних блокировках, эти очереди могут увеличиваться, а стримы деградировать. Поэтому процент деградировавших стримов — это важная метрика, которая сигнализирует о потере качества.Найти значение degraded_streams_percent можно на странице статистики http://demo.flashphoner.com:8081/?action=stat (где demo.flashphoner.com - это адрес WCS-сервера.)
Следующие несколько метрик относятся к работе Java Virtual Machine:
Метрика 3: Java GC pause
Время пауз при сборке мусора. Здесь, как и в случае с Load average, чем цифра меньше, тем лучше. 100 ms — очень плохо. Ситуацию, когда Java машина запускает сборщик мусора называют "Stop the world", а это значит, что ваше приложение будет полностью остановлено на то время пока работает сборка мусора. Все треды сервера будут остановлены на мгновение и этого достаточно для деградации стримов.Метрика 4: Java Heap
Размер используемой Heap памяти Java. Если он приближается к -Xmx и постоянно находится у этих значений, это означает постоянную работу сборщика мусора, как следствие, большой расход CPU, вероятную деградацию стримов, а также повышение вероятности появления ошибки "OutOfMemoryError", которая является сигналом о необратимом нарушении внутреннего состояния сервера. Если такая ошибка произошла хотя бы единожды, работоспособность сервера уже нарушена, поэтому рекомендуется перезапустить его. При появлении OutOfMemoryError, Java машина может остановить любой тред, нарушая тем самым работу сервера, хотя внешне сервер продолжит работать и обслуживать подключения.Метрика 5: Физическая память
Ограничение -Xmx для хип не гарантирует ограничения расхода физической памяти RES. Если под хип дали 16 GB, RES может занять 32 GB и более и это не всегда является утечкой памяти. Особенно на тяжелых сценариях микширования и транскодинга. Поэтому "реальную память" требуется обязательно мониторить и не допускать ее исчерпания, т.к. это приведет к завершению процесса сервера самой системой.Отслеживать эти метрики можно при помощи инструмента Java Mission Control. Java Mission Control - это мощный инструмент для мониторинга и отладки Java-машины, который поставляется вместе с JDK и запускается на ПК пользователя (администратора).
Метрика 6: Очереди транскодеров и время транскодинга
Транскодирование - отдельный сценарий с высокой загрузкой серверных ресурсов. В пункте 2 мы уже писали про Degraded streams. Так вот, это более поздняя метрика. В случае транскодеров, сначала метрики очередей транскодеров покажут превышения и только потом отреагирует Degraded streams. Метрики очередей транскодеров показывают количество фреймов, которое скопилось в очереди на декодинг/энкодинг. Фрейм - штука тяжелая, и 30 скопившихся фреймов означают 1 секунду задержки при фрейм рейте в 30 FPS. Время декодинга/энкодинга нам говорит о том, как быстро проходят соответствующие операции. Например, при 30 FPS, операция энкодинга одного фрейма должна занимать не более 1/30 секунды = 33 миллисекунды. В противном случае, транскодер не сможет поставлять фреймы вовремя, что приведет к порче стрима.Метрики очередей декодинга/энкодинга:
transcoding_video_decoding_max_queue_size
transcoding_video_encoding_max_queue_size
Метрики максимального времени декодинга/энкодинга
transcoding_video_decoding_max_time
transcoding_video_encoding_max_time
Эти метрики доступны на странице статистики:
Метрика 7: Количество свободных портов для стриминга
Метрика: ports_media_freeВажная метрика для высоконагруженных серверов. Под каждый стрим выделяются порты. Если порты в диапазоне заканчиваются, добавление новых стримов на сервере будет вызывать ошибку.
Информацию по количеству портов можно найти на странице статистики:
Метрика 8: Синхронизация аудио и видео в стримах
Метрика: streams_synchronizationВажная метрика, имеющая также название lipsync (синхронизация губ и голоса в видео трансляциях). Рассинхронизация может быть вызвана разными причинами, начиная от некачественного источника потока и заканчивая проблемами производительности сервера. При рассинхронизации в 100 и более миллисекунд, человеческое ухо и глаз уже будут фиксировать непорядок. Метрика позволяет увидеть этот момент в цифрах, в миллисекундах для каждого стрима, положительное значение метрики показывает, что аудио в данный момент обгоняет видео, а отрицательное - что аудио отстает от видео.
На скриншоте ниже с синхронизацией аудио и видео в стримах все в пределах нормы. Метрика показывает значения от +2 до +79 миллисекунд.
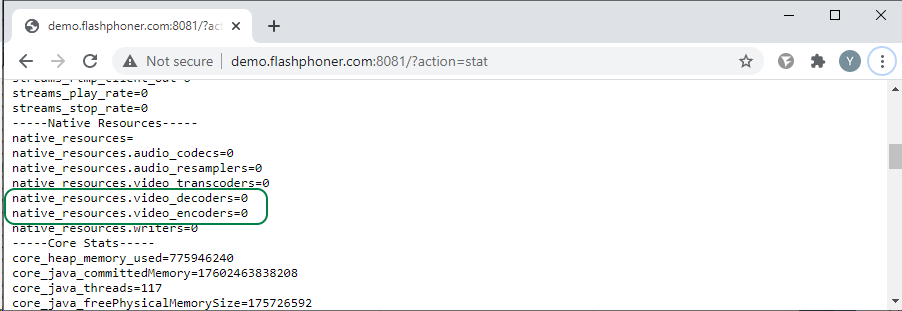
Метрика 9: Количество открытых транскодеров
Транскодеры, а именно энкодеры, оказывают максимальное влияние на загрузку сервера. Поэтому так важно контролировать их количество. Если ваш сценарий не предполагает использование транскодирования (например, стриминга без изменения разрешения), то количество decoders и encoders должно быть равно нулю.Метрики:
native_resources.video_decoders
native_resources.video_encoders
На скриншоте ниже транскодирование не используется.
Метрика 10: Суммарная нагрузка на транскодеры
Количество транскодеров - хорошая метрика, но два энкодера могут различаться на порядок в плане загрузки CPU. Например, кодирование потока 240p 15 FPS и 1080p 60 FPS. Поэтому для получения представления о нагрузке, важно учитывать не только количество энкодеров, а их вес. Вес энкодера равен: w x h x FPS, где w и h - разрешение картинки. В результате, метрика позволяет отобразить реальную загрузку сервера энкодерами, и один тяжеловесный энкодер может показать более высокую загрузку чем 10 легковесных.Метрики:
transcoding_video_decoding_load
transcoding_video_encoding_load
Подготовка к развертыванию мониторинга
Если у вас в системе используется файрволл, нужно открыть порты- TCP 9090 — http для сервера Prometheus;
- TCP 9093 — http для алерт менеджера;
- TCP и UDP 9094 — для алерт менеджера;
- TCP 9100 — для node_exporter;
- TCP 3000 — http для сервера Grafana.
iptables -I INPUT 1 -p tcp --match multiport --dports 9090,9093,9094,9100 -j ACCEPT
iptables -A INPUT -p udp --dport 9094 -j ACCEPT
Если вы используете операционную систему на базе Red Hat, вероятно, по умолчанию, будет включена подсистема SELinux. Отключить ее можно при помощи команд
sudo setenforce 0
sudo sed -i 's/^SELINUX=.*/SELINUX=disabled/g' /etc/selinux/config
Теперь мы готовы к установке Prometheus и Grafana.
Prometheus: установка и настройка
У Prometheus’а нет своих собственных репозиториев для популярных дистрибутивов, а официальные репозитории операционных систем, как правило, отстают от апстрима. Поэтому мы будем разбирать ручную установку. Этот способ подойдёт для любых дистрибутивов Linux под управлением systemd (Ubuntu, Debian, Centos, Arch и т.д.). Необходимо будет скачать исходник, создать пользователя, вручную скопировать нужные файлы, назначить права и создать юнит для автозапуска.Скачать исходник можно с официальной страницы загрузки. Копируем ссылку на пакет для Linux и скачиваем при помощи wget:
wget https://github.com/prometheus/prome.../v2.21.0/prometheus-2.21.0.linux-amd64.tar.gz
Создаем каталоги, в которые скопируем файлы для Prometheus:
mkdir /etc/prometheus
mkdir /var/lib/prometheus
Распаковываем скачанный архив:
tar zxvf prometheus-*.linux-amd64.tar.gz
Переходим в каталог с распакованными файлами:
cd prometheus-*.linux-amd64
Распределяем файлы по каталогам:
cp prometheus promtool /usr/local/bin/
cp -r console_libraries consoles prometheus.yml /etc/prometheus
Создаем пользователя, от которого будем запускать систему мониторинга:
sudo useradd --no-create-home --shell /bin/false prometheus
Задаем владельца для каталогов, которые мы создали на предыдущем шаге:
sudo chown -R prometheus
rometheus /etc/prometheus /var/lib/prometheusЗадаем владельца для скопированных файлов:
sudo chown prometheus
rometheus /usr/local/bin/{prometheus,promtool}Настраиваем автозапуск Prometheus:
Создаем файл prometheus.service:
sudo nano /etc/systemd/system/prometheus.service
Размещаем в нем следующий текст:
[Unit]
Description=Prometheus Service
After=network.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/prometheus \
--config.file /etc/prometheus/prometheus.yml \
--storage.tsdb.path /var/lib/prometheus/ \
--web.console.templates=/etc/prometheus/consoles \
--web.console.libraries=/etc/prometheus/console_libraries
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
Перечитываем конфигурацию systemd:
sudo systemctl daemon-reload
Разрешаем автозапуск:
sudo systemctl enable prometheus
После создания автозапуска запускаем Prometheus, как службу:
sudo systemctl start prometheus
В браузере открываем http://<IP-адрес сервера>:9090, и, если все сделано правильно, попадаем в консоль системы мониторинга Prometheus. Пока что она бесполезна, но уже можно понажимать и посмотреть менюшки.
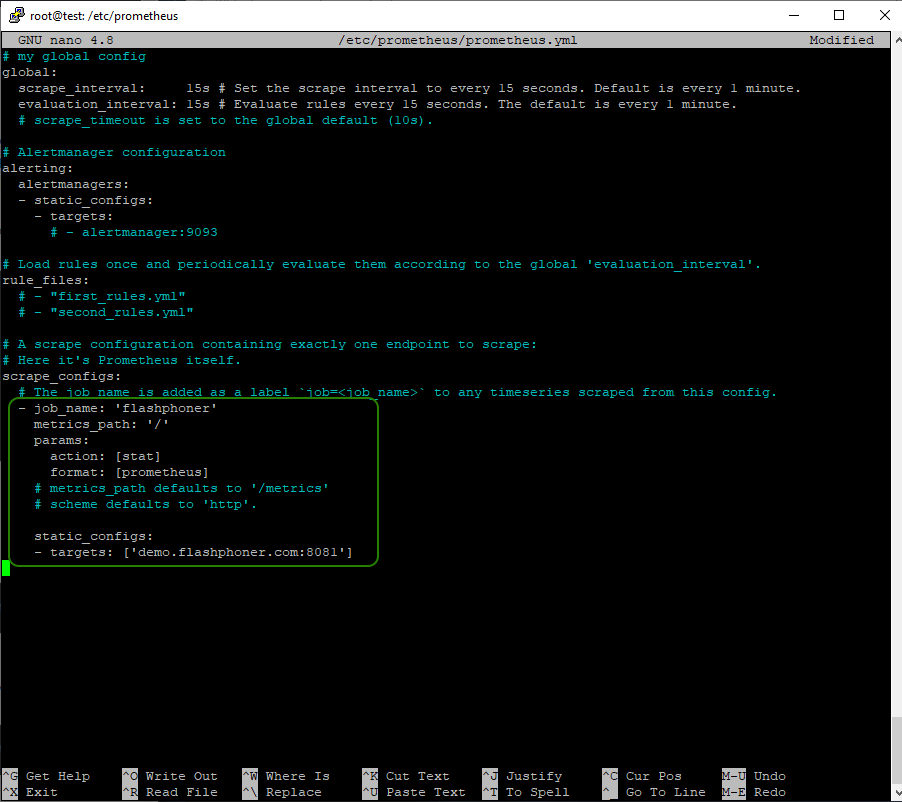
Итак, подключаем WCS к мониторингу. Открываем на редактирование файл настроек prometheus.yml
sudo nano /etc/prometheus/prometheus.yml
Добавляем в файл описание конфигурации мониторинга:
scrape_configs:
- job_name: 'flashphoner'
metrics_path: '/'
params:
action: [stat]
format: [prometheus]
static_configs:
- targets: ['WCS_address:8081']
где:
- WCS_address - адрес WCS сервера;
- 8081 - порт WCS сервера для вывода статистики.
После изменения файла настроек prometheus.yml перезапускаем службу:
sudo systemctl restart prometheus
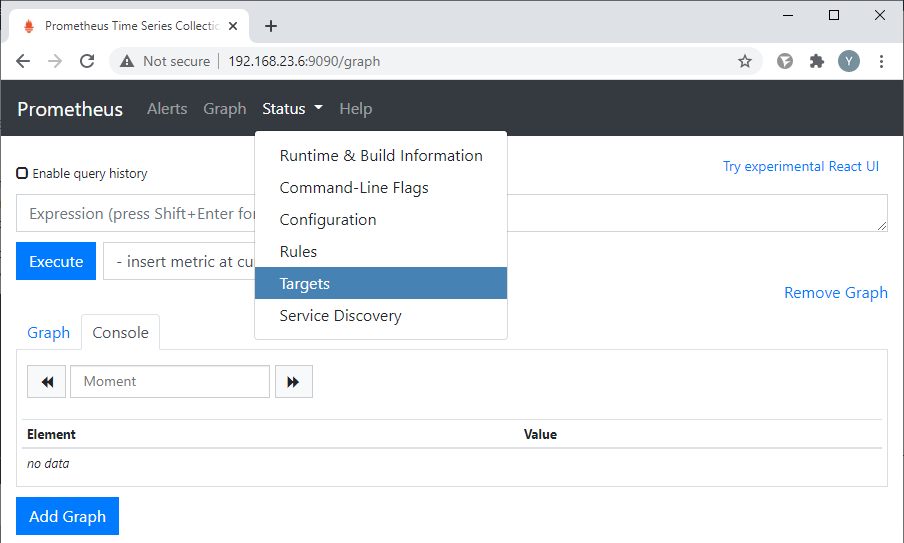
Возвращаемся к консоли Prometheus, выбираем пункт меню "Status => Targets":
И убеждаемся, что Prometheus получает данные от WCS (таргет в состоянии "UP"):
На этом все, с частью настройки мониторинга закончили. Переходим к
Grafana: установка и настройка
Grafana представляет собой веб-интерфейс к различным time series СУБД, таким, как Graphite, InfluxDB и Prometheus. В общем, Grafana может нарисовать красивые графики, используя информацию из Prometheus. Немного ранее мы видели, что у Prometheus есть и собственный веб-интерфейс, однако он предельно минималистичен и довольно неудобен. Поэтому даже сами разработчики Prometheus рекомендуют использовать Grafana. Ну, а кто мы такие, чтобы спорить с разработчиками?Приступим.
Grafana также, как и Prometheus будем устанавливать вручную с помощью deb пакета. На https://grafana.com/grafana/download находим ссылку на свежий пакет и скачиваем его при помощи wget:
wget https://dl.grafana.com/oss/release/grafana_7.2.1_amd64.deb
Распаковываем:
sudo dpkg -i grafana_7.2.1_amd64.deb
Разрешаем автозапуск:
sudo systemctl enable grafana-server
Запускаем:
sudo systemctl start grafana-server
Открываем веб-интерфейс по адресу http://<IP-адрес сервера>:3000. Логин и пароль по умолчанию: admin/admin. При первом входе Grafana сразу предложит сменить пароль.
Меняем пароль и добавляем Prometheus в качестве источника данных:
Нажимаем кнопку "Add data source":
и выбираем Prometheus:
Указываем параметры для подключения. Достаточно указать адрес и порт Web интерфейса Prometheus для сохранения нажимаем кнопку Save & Test:
После успешного подключения создаем новую панель для графиков. Выбираем из меню в левой части окна Create - Dashboard:
Нажимаем кнопку "Add new panel":
На вкладке "Query" в качестве источника данных выбираем созданный ранее Prometheus(1) и выбираем из списка интересующие нас метрики (2):
Далее можно пройти по остальным пунктам, выбрав конкретные параметры и тип графика. После сохраняем настройку панели (3).
Задаем имя дашборда и сохраняем:
На скриншоте выше на графике отображаются все доступные метрики для stream_stats.
Можно сделать график для какой-то конкретной интересующей вас метрики. Для этого нужно указать ее название в поле "Metrics". Например, на скриншоте ниже мы выбрали метрику "Число входящих RTSP стримов" :
Теперь создадим графики для ключевых метрик, которые мы разбирали в начале этой статьи.
Строки для выбора метрики:
Процент деградировавших стримов:
degraded_streams_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="degraded_streams"}
degraded_streams_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="degraded_streams_percent"}
Java heap:
core_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="core_heap_memory_used"}
Использование физической памяти для Java:
core_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="core_java_freePhysicalMemorySize"}
core_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="core_java_totalPhysicalMemorySize"}
Очереди транскодеров и время транскодинга:
transcoding_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="transcoding_video_decoding_max_queue_size"}
transcoding_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="transcoding_video_encoding_max_queue_size"}
transcoding_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="transcoding_video_decoding_max_time"}
transcoding_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="transcoding_video_encoding_max_time"}
Количество свободных портов для стриминга:
port_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="ports_media_free"}
Синхронизация аудио и видео в стримах:
streams_stats{instance="demo.flashphoner.com:8081", job="flashphoner", name="s1", param="streams_synchronization"}
Количество открытых транскодеров:
native_resources{instance="demo.flashphoner.com:8081", job="flashphoner", param="native_resources.video_decoders"}
native_resources{instance="demo.flashphoner.com:8081", job="flashphoner", param="native_resources.video_encoders"}
Суммарная нагрузка на транскодеры:
transcoding_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="transcoding_video_encoding_load"}
transcoding_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="transcoding_video_decoding_load"}
Вид дашборда с графиками:
К сожалению, пока мы не получили все интересующие нас метрики. Метрик 10, а графиков удалось построить только 8. Давайте найдем недостающие графики — CPU и Java GC pause.
Собираем метрики ОС
Для получения метрик от операционной системы в которой развернут WCS установим и настроим node_exporter. Поскольку, в нашем случае, WCS-сервер и Prometeus-сервер — это разные машины, необходимо открыть tcp-порт 9100 на WCS сервере.Например, так:
sudo firewall-cmd --zone=public --add-port=9100/tcp --permanent
Дальнейший процесс установки такой же, как у Prometheus.
Скачиваем node_exporter по ссылке с официальной страницы
wget https://github.com/prometheus/node_...v1.0.1/node_exporter-1.0.1.linux-amd64.tar.gz
Распаковываем скачанный архив:
tar zxvf node_exporter-*.linux-amd64.tar.gz
И переходим в каталог с распакованными файлами:
cd node_exporter-*.linux-amd64
Копируем исполняемый файл в bin:
cp node_exporter /usr/local/bin/
Создаем пользователя nodeusr:
sudo useradd --no-create-home --shell /bin/false nodeusr
Задаем владельца для исполняемого файла:
sudo chown -R nodeusr:nodeusr /usr/local/bin/node_exporter
Для настройки автозапуска в systemd создаем файл node_exporter.service:
nano /etc/systemd/system/node_exporter.service
Размещаем в нем следующий текст:
[Unit]
Description=Node Exporter Service
After=network.target
[Service]
User=nodeusr
Group=nodeusr
Type=simple
ExecStart=/usr/local/bin/node_exporter
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
Перечитываем конфигурацию systemd:
sudo systemctl daemon-reload
Разрешаем автозапуск:
sudo systemctl enable node_exporter
Запускаем службу:
sudo systemctl start node_exporter
Открываем веб-браузер и переходим по адресу http://<IP-адрес WCS сервера>:9100/metrics — мы увидим метрики, собранные node_exporter:
Теперь свяжем node_exporter на WCS с сервером Prometheus.
На сервере Prometheus открываем на редактирование конфигурационный файл prometheus.yml:
sudo nano /etc/prometheus/prometheus.yml
и добавляем новое задание для сбора данных от node_exporter на WCS. Будьте внимательны с отступами в yml файле:
- job_name: 'WCS_node_exporter'
scrape_interval: 5s
static_configs:
- targets: ['demo.flashphoner.com:9100']
После изменения файла настроек prometheus.yml перезапускаем службу:
sudo systemctl restart prometheus
Переходим к Grafana и добавляем на ранее созданный дашборд график для загрузки CPU:
Метрики для CPU:
node_load1
node_load5
node_load15
Если нет нужной метрики
В WCS существует возможность сбора статистики при помощи внешнего скрипта.Для включения этой функции нужно указать путь к файлу скрипта для сбора статистики в файле "flashphoner.properties", например, для файла custom_stats.sh расположенного в каталоге /usr/local/FlashphonerWebCallServer/bin можно прописать так:
custom_stats_script=custom_stats.sh
Если путь до файла скрипта у вас будет другой, то его нужно указать полностью:
custom_stats_script=/path/to/custom_stats.sh
Напишем скрипт, который соберет данные о паузах для работы сборщика мусора Java
#!/bin/bash
WCS_HOME="/usr/local/FlashphonerWebCallServer"
LAST_LOG=$(ls -t ${WCS_HOME}/logs/ | grep gc-core | head -1)
LOG="${WCS_HOME}/logs/${LAST_LOG}"
JAVA_VER=$(java -version 2>&1 | head -n 1 | awk -F '"' '{print $2}')
TYPE_GC="$(grep -Pv '^(#|$)' ${WCS_HOME}/conf/wcs-core.properties | grep -oE 'ConcMarkSweepGC|ZGC')"
#GC
if [[ $JAVA_VER != "1"[0-9]* ]]; then
gc_pause=$(grep 'Allocation Failure' $LOG | tail -1 | awk -F'->' '{print $3}' | sed -rn 's/([0-9]+)K\(([0-9]+)K\), ([0-9]+.[0-9]+).*/\3/p' | tr , . | awk '{printf "%f\n", $1 * 1000 }')
echo "gc_pause=$gc_pause"
#ZGC
elif [[ $JAVA_VER == "1"[0-9]* ]]; then
if [[ $TYPE_GC == "ConcMarkSweepGC" ]]; then
gc_pause=$(grep 'Allocation Failure' $LOG | tail -1 | awk '{print $8}' | sed 's/ms$//')
echo "gc_pause=$gc_pause"
fi
if [[ $TYPE_GC == "ZGC" ]]; then
gc_pause=$(grep '.*GC.*Pause' $LOG | awk -F 'Pause Mark Start|End|Relocate Start' '{print $2}' | tail -3 | sed 's/ms$//' | awk '{a=$1; getline;b=$1;getline;c=$1;getline;t=a+b+c;print t}')
echo "gc_pause=$gc_pause"
fi
fi
Этот скрипт запрашивает версию установленной в системе Java и, согласно этой информации, находит в логе строки с данными о паузах на сборку мусора для GС или ZGC и выводит это значение (в миллисекундах) в параметр "gc_pause".
Статистика, которую мы собрали с помощью внешнего скрипта, выводится на странице статистики http://demo.flashphoner.com:8081/?action=stat в секции "Custom info" :
Откуда ее забирает ранее настроенная нами система мониторинга Prometheus.
Теперь добавим график для этой метрики на дашборд в Grafana:
Метрика для Java GC pause:
custom_stats{instance="demo.flashphoner.com:8081", job="flashphoner", param="gc_pause"}
Общий вид дашборда с графиками для мониторинга метрик работы WCS
Мы собрали и построили графики для метрик работы сервера. Теперь рассмотрим, как можно построить графики для параметров конкретного стрима, который будет публиковаться на сервере.
Сбор метрик для WebRTC
Если выполнить REST запрос/stream/metrics
в результате будет получен достаточно обширный список метрик. И, если с метриками типа "VIDEO_HEIGHT" , "VIDEO_WIDTH", "VIDEO_CODEC" и "AUDIO_CODEC" все понятно из их названий, то с другими метриками предлагаю познакомиться подробнее
Метрики "AUDIO_SYNC" и "VIDEO_SYNC" — это уже знакомая нам метрика синхронизации аудио и видео в опубликованных потоках.
Метрика "VIDEO_K_FRAMES" — Количество ключевых кадров (I-frames) видео. Ключевой кадр содержит всю информацию об изображении в кадре и никак не зависит от других кадров. Ключевые кадры имеют самую низкую степень сжатия. Если браузер отправляет ключевые кадры не равномерно, то это может приводить к фризам при воспроизведении потока. С этой метрикой тесно связана следующая:
Метрика "VIDEO_PLI" — Количество PLI-запросов на получение ключевых кадров от браузера. PLI может быть отправлен, когда получатель потока потерял полный кадр или несколько кадров. Большое количество PLI запросов свидетельствует о плохом канале.
Метрики "VIDEO_P_FRAMES" и "VIDEO_B_FRAMES" — Количество P-кадров (промежуточных) и B-кадров (двунаправленных) соответственно. Промежуточный кадр может ссылаться на блоки изображения в предыдущем ключевом или предыдущих промежуточных кадрах. Это позволяет делать промежуточные кадры по размеру меньше ключевых: в них записано меньше информации об изображении. Двунаправленный кадр также содержит не всё изображение. Но в отличие от промежуточного кадра, он может ссылаться и на последующие за ним кадры, вплоть до следующего промежуточного кадра: отсюда и происходит его название. Двунаправленные кадры занимают ещё меньше места, чем промежуточные. Способ декодирования двунаправленного кадра ещё сложнее, чем декодирование промежуточного кадра: сначала по описанной выше схеме декодируется следующий за двунаправленным промежуточный кадр; потом, используя информацию о соседних кадрах, декодируется двунаправленный кадр.
Получается, что чем чаще в потоке встречаются B кадры, тем больше ресурсов требуется на декодирование этого потока, что может отрицательно сказаться на качестве видео. Более того, браузеры не умеют корректно проигрывать B-фреймы, и, при наличии двунаправленных кадров, изображение будет подергиваться.
Метрики "AUDIO_RATE" и "VIDEO_RATE" показывают битрейт аудио или видео.
Метрика "VIDEO_FPS" — Частота кадров видео
И еще три метрики связанные с потерями пакетов на каналах связи:
"VIDEO_NACK" — Количество NACK-запросов. NACK — это способ для принимающей стороны указать, что она не получила определенный пакет или список пакетов.
"VIDEO_LOST" — Количество потерянных пакетов видео.
"AUDIO_LOST" — Количество потерянных пакетов аудио.
Большое количество NACK-запросов и потерянных пакетов так же означают проблемы с каналами связи. Проявляется это фризами в потоке, пропаданием звука и прочими неприятными штуками.
Перечисленные выше метрики для публикуемых потоков доступны и в веб-интерфейсе на странице статистики:
Метрики отображаются на странице статистики, если на сервере есть хотя бы один опубликованный поток. Теперь подключим их к сбору в Prometheus. Для этого, в файле настроек prometheus.yml,
sudo nano /etc/prometheus/prometheus.yml
добавляем новое задание для сбора данных по метрикам для стрима. Будьте внимательны с отступами в yml файле:
- job_name: 'stream_metrics'
metrics_path: '/'
params:
action: [stat]
format: [prometheus]
groups: [publish_streams]
static_configs:
- targets: ['demo.flashphoner.com:8081']
Сохраняем конфигурацию и перезапускаем Prometheus:
sudo systemctl restart prometheus
Переходим к Grafana. Предлагаю создать новую панель для графиков метрик стримов. Выбираем из меню в левой части окна Create - Dashboard
Нажимаем кнопку "Add new panel"
На вкладке "Query" в качестве источника данных выбираем Prometheus и выбираем из списка метрик publish => publish_streams:
В результате получаем графики для всех доступных метрик для каждого опубликованного стрима. Для наглядности можно вывести интересующие метрики на отдельный график. Например, список метрик для опубликованного на demo.flashphoner.com потока с именем "stream1"
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="AUDIO_CODEC"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="AUDIO_LOST"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="AUDIO_RATE"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="AUDIO_SYNC"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_B_FRAMES"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_CODEC"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_FPS"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_HEIGHT"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_K_FRAMES"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_LOST"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_NACK"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_PLI"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_P_FRAMES"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_RATE"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_SYNC"}
publish_streams{instance="demo.flashphoner.com:8081", job="stream_metrics", name="stream1", param="VIDEO_WIDTH"}
Пример такого дашборда ниже:
Как видите Prometheus — инструмент достаточно любопытный и многообещающий. Наша статья не может претендовать на полноту описания этой системы мониторинга, потому что мы рассматривали только частный случай, применимо к мониторингу WCS и стримов. Например, Prometheus позволяет настраивать еще и алерты, чего мы не рассматривали. Но, прочитав эту статью, вы теперь знаете, зачем нужны Prometheus и Grafana, и сможете их успешно применить на практике.
Хорошего стриминга!
Ссылки
Наш демо серверWCS на Amazon EC2 - Быстрое развертывание WCS на базе Amazon
WCS на DigitalOcean - Быстрое развертывание WCS на базе DigitalOcean
WCS в Docker - Запуск WCS как Docker контейнера
Документация по быстрому развертыванию и тестированию WCS сервера
Документация по мониторингу информации о нагрузке и ресурсах
Документация по организации мониторинга с помощью Prometheus
Мониторинг WebRTC стримов с помощью Prometheus и Grafana
Системы мониторинга — очень нужная для админа вещь, ведь они позволяют получать от сервисов метрики, которые: Дают представление о текущей нагрузке на сервер; Показывают здоров ли сервис, правильно ли...
habr.com