Меня зовут Богданов Илья, я работаю ведущим инженером в команде веб-разработки. Сегодня я вам расскажу как настроить стандартную библиотеку Golang так, чтобы избежать неожиданных ошибок в production.
Я программирую на Go более двух лет и за 2019 год выпустил в production пять микросервисов: от простых с одной задачей до сложных со своей доменной моделью и несколькими внешними зависимостями. До этого я четыре года программировал на C++, продолжаю увлекаться трехмерной графикой и микроконтроллерами. За это время было набито немало шишек и получено много опыта, которым я хочу с вами поделиться.
Моя статья ориентирована в основном на начинающих разработчиков, но ветераны Go тоже, вероятно, смогут узнать что-то новое.
Коротко, о чем будет статья:
Мы проверили на тестовом окружении, все работало как надо, никаких проблем и решили поехать в production.
db, err := sql.Open("mysql", "root:localhost/test")
if err != nil {
return err
}
defer db.Close()
_, err := db.Exec("...")
Скоро после релизов по утрам мы стали иногда получать ошибки соединения с базой или вовсе непонятный EOF.
failed to begin a transaction: invalid connection
unexpected EOF


 github.com
Пришлось обратиться к документации. Тип sql.DB имеет три метода для конфигурации.
github.com
Пришлось обратиться к документации. Тип sql.DB имеет три метода для конфигурации.
SetMaxOpenConns
Этот метод ограничивает максимальное количество соединений с базой. По-умолчанию там стоит ноль, то есть лимит отсутствует и сервис может устанавливать столько соединений с базой данных, сколько ему вздумается, в то время как ресурсы базы данных и микросервиса ограничены, поэтому ограничение определенно не помешает. Для выбора оптимального значения мы стали профилировать.
Воспользуемся встроенным в язык бенчмарком. В нем мы открываем соединение с базой, выставляем разные значения максимального числа соединений и начинаем в неё параллельно записывать строки по 255 символов. Результаты бенчмарка в таблице.
В левом столбце указано максимальное количество соединений, затем идет время, затраченное на каждую операцию вставки в наносекундах (соответственно, чем меньше, тем лучше), затем идет число байт оперативной памяти, выделенной для выполнения операции и число аллокаций на операцию. Последние два столбца нам не особо интересны, т. к. значения почти не меняются в зависимости от числа соединений.
Как мы видим, при одном соединении с базой данных производительность примерно в пять раз меньше, чем при неограниченном числе соединений. В данном случае оптимальным будет примерно 10 соединений, т. к. дальнейшее увеличение числа соединений не дает прироста производительности, выходящего за рамки погрешности.
Стоит учитывать, что эти данные получены на моей рабочей машине, где база данных располагается рядом с бенчмарком. Если база данных далеко, числа могут получиться совсем другие.
Но что же это получается, чем больше соединений, тем лучше? Зачем нам ограничивать количество соединений и потенциально терять производительность? А вот зачем.
[mysqld]
max_connections=10
Benchmark_MaxOpenConns20
Benchmark_MaxOpenConns20: main_test.go:69: Error 1040: Too many connections
Benchmark_MaxOpenConns20: main_test.go:69: Error 1040: Too many connections
Benchmark_MaxOpenConns20: main_test.go:69: Error 1040: Too many connections
...
-- FAIL: Benchmark_MaxOpenConns20
FAIL
Для симуляции проблемы я ограничил количество соединений со стороны базы данных (в моем случае это MySQL). В реальной системе такой лимит тоже стоит, просто он повыше, но учитывая, что время запроса будет гораздо выше, чем на локальной машине, а микросервисов, подключенных к одной базе, может быть несколько… упереться в лимит вполне реально.
Вернемся к нашим бенчмаркам: как только число соединений со стороны микросервиса превысило лимит базы данных, мы тут же упали с ошибкой. Это не повод бежать в настройки MySQL и бесконтрольно увеличивать количество соединений базы данных, ведь каждое соединение потребляет ресурсы не только на стороне микросервиса, но и на стороне базы данных. Если хотите в этом убедиться, можно поиграться с калькулятором потребления памяти MySQL с разным количеством соединений https://mysqlcalculator.com
SetMaxIdleConns
Второй метод позволяет ограничивать количество соединений, которые могут остаться открытыми, для повторного использования, после того как все запросы в очереди будут выполнены. Если установить этот параметр в 0, то соединения перестанут переиспользоваться и на каждый запрос будет создаваться новое. Пока не особо понятно, как это повлияет на производительность и стабильность. Значит, время побенчмаркать")
Точно такая же таблица, как и с прошлым методом, но вместо максимального числа соединений мы меняем число соединений для переиспользования (первый столбец). Как мы видим, если совсем уж сильно не ограничивать переиспользование соединений, то производительность не упадет (но обратите внимание: число и размер аллокаций при запрете переиспользования сильно возрастает — вот цена установления соединений). На самом деле эта настройка не оказывает такого сильного влияния, как остальные две, поэтому, если у вас не высоконагруженный сервис, её можно оставить в значении по умолчанию, то есть 2. Как мы видим, 2 — это оптимальное значение. А вот если сервис нагруженный, то спасет только собственный бенчмарк для выяснения подходящего значение.
SetConnMaxLifetime
Последняя настройка позволяет нам ограничивать время, в течение которого соединение можно переиспользовать. По её названию можно подумать, что она обрывает соединения, после того как время жизни соединения превысило лимит, но все хорошо: пока запрос выполняется, соединение не разорвется, оно просто не будет переиспользоваться для новых запросов. Вновь по умолчанию ограничение отсутствует, что позволяет соединениям висеть часами, днями, неделями… Естественно, мы хотим это время ограничить, ведь долгоживущие соединения опасны, т. к. они могут внезапно разорваться или висеть бесполезным грузом, сжирая ресурсы. А чтобы выбрать оптимальное значение, мы, конечно же, побенчмаркаем.
К счастью, чтобы получить хоть какую-то разницу в производительности, мне пришлось снизить ограничение ниже одной миллисекунды, что нереалистично и фактически аналогично запрету переиспользования соединения. Так что, даже поставив жесткий лимит на время жизни соединения, мы не просядем сильно по производительности.
Что же имеем в итоге?
В первую очередь оцените нагруженность сервиса. Если сервис должен постоянно обрабатывать тысячи запросов в секунду, то стоит увеличить максимальное количество соединений с БД, количество idle соединений и время жизни соединения. Также можно задуматься о выделенном инстансе базы данных для этого микросервиса. Если же микросервис не сильно нагружен, можно сэкономить ресурсы сервиса и базы и сократить число используемых соединений.
Во-вторых, проанализируйте конфигурацию базы данных: сколько она позволяет создать соединений (стоит оставить небольшой запас свободных соединений — около 5 шт.) на случай, если вы захотите подключиться из консоли + база данных не может мгновенно создать новое соединение взамен старого, будет небольшой период времени, когда существуют оба соединения, и тут вам запас пригодится).
Также можно воспользоваться методом Stats() у sql.DB, который вернет не только информацию о текущих соединениях, но и статистику по ожиданию соединений: сколько раз мы уткнулись в необходимость ожидания соединения и сколько времени потратили впустую, ожидая соединение. Можно вывести эту статистику во внутренний API и изредка мониторить
Ну и, наконец, читайте документацию к языку! В Go прекрасная документация как на сайте golang.org, так и в самом коде, не поленитесь почитать её для типов, которые вы используете.
Вот пример конфигурации для низконагруженного сервиса.
db, err := sql.Open("mysql", "root:localhost/test")
if err != nil {
return err
}
defer db.Close()
db.SetMaxOpenConns(25)
db.SetMaxIdleConns(2)
db.SetConnMaxLifetime(time.Minute)
_, err := db.Exec("...")
25 соединений более чем достаточно, соединения будем пересоздавать каждую минуту, а idle соединений оставим стандартное значение — 2. Мы дописали всего три строчки к тому коду, который был вначале, и улучшили надежность микросервиса!
И вновь он требует настройки для корректного функционирования. Что еще более странно, пакет httpвключает DefaultClient, содержащий значения по умолчанию и функции Get, Postи т. д., его использующие. Соответственно, с этими функциями мы ничего не сможем сконфигурировать, и они будут работать без таймаутов, и в production я бы не рекомендовал их использовать.
http.Client.Timeout — самый простой таймаут, распространяющийся на все время выполнения запроса: от установления соединения до завершения чтения тела ответа. Идеально подходит для вызова API. Если же нам нужно скачать файл или стримить данные, он нам не подходит, и для этих случаев нам пригодятся следующие таймауты.
net.Dialer.Timeout — ограничивает время нахождения хоста и установления HTTP-соединения. Пригодится, чтобы не висеть долго на запросе, если удаленный сервер не отвечает.
http.Transport.TLSHandshakeTimeout — если вы используете HTTPS (а стоит, если ваш сервис доступен снаружи), то этот таймаут позволит ограничить время на установление защищенного соединения. Если же вы не используете HTTPS (например, если ваш сервис доступен только внутри кластера), то этот параметр не используется.
http.Transport.ResponseHeaderTimeout — ограничивает время чтения заголовков ответа. Может быть полезен, чтобы не зависнуть при общении с сервисами, которые долго думают после получения запроса.
http.Transport.IdleConnTimeout может ограничивать длительность keep-alive соединений, но об этом я расскажу дальше.

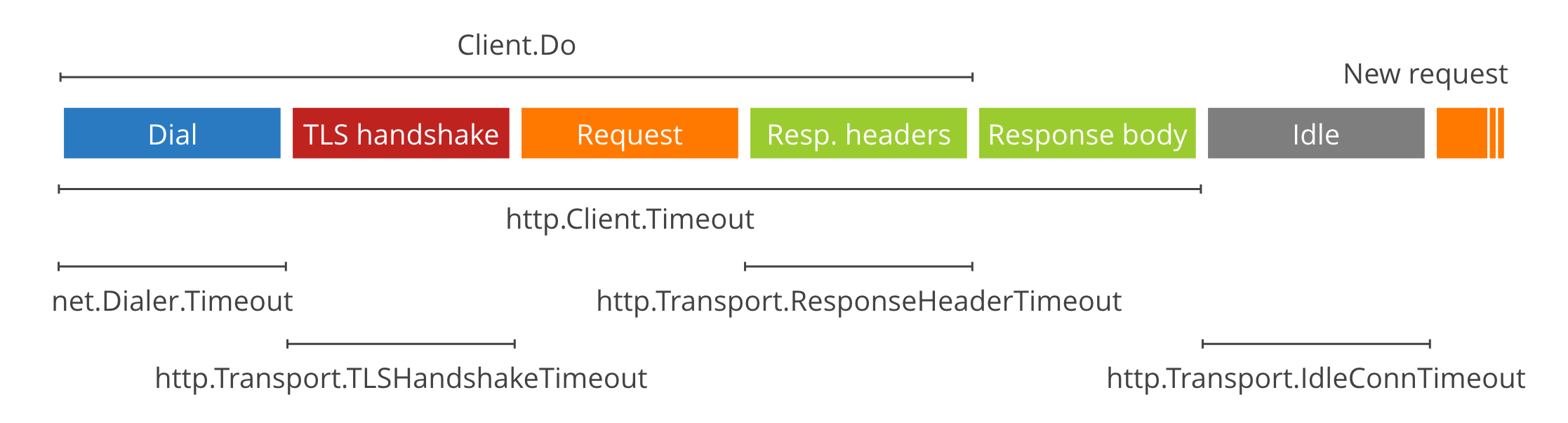
 blog.cloudflare.com
Как вы можете заметить на картинке, непокрытыми остались отправка запроса и получение тела ответа. Что же делать, если нам нужно передать или получить большой объем данных? Оставить передачу данных без таймаута опасно, ведь в случае, если удаленный сервис просто пропадет из сети, мы так и останемся висеть в процессе копирования. Чтобы этого избежать, нам нужно что-то более гибкое… например, динамический таймаут.
blog.cloudflare.com
Как вы можете заметить на картинке, непокрытыми остались отправка запроса и получение тела ответа. Что же делать, если нам нужно передать или получить большой объем данных? Оставить передачу данных без таймаута опасно, ведь в случае, если удаленный сервис просто пропадет из сети, мы так и останемся висеть в процессе копирования. Чтобы этого избежать, нам нужно что-то более гибкое… например, динамический таймаут.
c := &http.Client{}
resp, _ := c.Get("https://host.com")
defer resp.Body.Close()
timer := time.AfterFunc(5*time.Second, func() {
resp.Body.Close()
})
bodyBytes := make([]byte, 0)
for {
timer.Reset(5 * time.Second)
_, err = io.CopyN(bytes.NewBuffer(bodyBytes), resp.Body, 256)
if err == io.EOF {
break // данные закончились, выходим
} else if err != nil {
panic(err)
}
}
Что тут происходит? Сначала мы устанавливаем соединение и подготовимся к скачиванию файла. Далее настроим таймер на небольшой промежуток времени. Если таймер сработает, значит мы не успели вовремя получить свою порцию данных и нужно завершить операцию с ошибкой. Затем запустим бесконечный цикл, в котором будем считывать следующий кусок данных и сбрасывать таймер. Таким образом, мы ставим условие, что за каждые пять секунд мы должны скопировать по меньшей мере 256 байт или получить ошибку. Как только мы дочитали до конца, мы получим ошибку io.EOF и выйдем из бесконечного цикла
У этого подхода есть недостатки, а именно сниженная производительность, ведь теперь мы копируем не все данные разом, а кусками по 256 байт, но возможность быстро обнаружить сетевую ошибку может оказаться важнее. Что приоритетнее в вашем случае, решать вам.
Повторное использование соединений (Keep-Alive)
Также я хотел затронуть тему повторного использования соединений (Keep-Alive). Этот механизм позволяет открыть соединение с сервером один раз и посылать по нему несколько запросов, вместо того чтобы открывать новое соединение на каждый запрос. Особенно это полезно в случае использования HTTP-соединения, т. к. позволяет пропустить процесс handshake для всех запросов кроме первого. Что же нам предлагает Go по части переиспользования соединений?
За него отвечает тип http.Transport, который по умолчанию оставляет открытыми до 100 соединений с таймаутом 90 секунд. Т. е. после того как мы сделали запрос на какой-то сервер, соединение с ним останется в пуле http.Transport для повторного использования в течение 90 секунд. Это звучит разумно, и в общем случае менять не стоит.
При этом присутствует дополнительное ограничение на два соединения на хост (MaxIdleConnsPerHos), т. е. если вы общаетесь только с одним сервером или проводите нагрузочное тестирование микросервиса (при котором будет много запросов к одному серверу), то имеет смысл увеличить этот лимит, изменив свойство MaxIdleConnsPerHost. Но в общем случае так делать не стоит, чтобы не исчерпать весь пул keep-alive соединений на один хост
Также, исследуя эту тему при подготовке статьи, я наткнулся на утверждение, что Keep-Alive ломается, если тело ответа не было считано либо было не закрыто. Я сам не проверял, но в целом будет хорошей практикой всегда считывать тело ответа, даже если оно вам не нужно. Вот пример кода, как это можно сделать, — отправить в ioutil.Discard. А чтобы не писать так каждый раз, можно сделать обертку над клиентом, которая всегда будет читать тело ответа и корректно закрывать его.
res, err := client.Do(req)
io.Copy(ioutil.Discard, res.Body)
res.Body.Close()
Итак, мы разобрали настройки http.Client и готовы настроить его для использования в сервисе. Если ваш http.Client используется исключительно для вызовов API, которые не должны занимать много времени, можно поставить маленький таймаут на всю обработку запроса, к примеру пять секунд, и не заморачиваться тонкими настройками. Если же вы передаете большие объемы данных, либо обработка запроса может занять продолжительное время, или вы вообще стримите данные, то я рекомендую использовать динамический таймаут, а также установить Dialer.Timeout и ResponseHeaderTimeout
 blog.cloudflare.com
Но в некоторых случаях этого бывает недостаточно. К примеру, нам в одном из микросервисов было нужно проксировать скачивание и загрузку больших файлов, поэтому мы продолжаем копать дальше. Go предоставляет также следующие возможности для таймаутов:
blog.cloudflare.com
Но в некоторых случаях этого бывает недостаточно. К примеру, нам в одном из микросервисов было нужно проксировать скачивание и загрузку больших файлов, поэтому мы продолжаем копать дальше. Go предоставляет также следующие возможности для таймаутов:
Пример конфигурации для API:
srv := &http.Server{
ReadTimeout: 5 * time.Second,
WriteTimeout: 10 * time.Second,
IdleTimeout: 120 * time.Second,
}
Пример конфигурации для передачи файлов и стриминга:
srv := &http.Server{
ReadHeaderTimeout: 5 * time.Second,
IdleTimeout: 120 * time.Second,
}
А также стоит использовать динамический таймаут, чтобы не зависнуть в процессе передачи данных
В качестве бонуса я бы хотел рассказать о паре проблем, с которыми мы сталкиваемся при работе с микросервисами. Они не относятся напрямую к стандартной библиотеке Go, но, думаю, вам будет интересно.
В end2end тестах микросервиса никаких проблем первоначально не вылезло, и в тестовом окружении тоже все работало как надо, но затем запросы стали иногда валиться с ошибкой, что невозможно освободить лок, который мы не занимали. Это показалось нам очень странным (ведь в большинстве случаев этот же код работал без ошибок), и мы полезли читать документацию MySQL к этим функциям.
Оказалось, что эти локи привязаны к соединениям базы данных и если соединение разрывается, то и лок автоматически освобождается при разрыве соединения. И тут до нас дошло, что sql.DB — это пул соединений и в итоге захват и освобождение лока могут происходить в совершенно разных соединениях. Решением для нас оказалось перенести блокировку внутрь транзакции. В этом случае стандартная библиотека гарантирует, что все операции будут произведены на одном соединении, которое не будет разорвано между командами. Альтернативным решением было бы использовать выделенное соединение с помощью метода Conn(), но раз уж у нас уже использовались транзакции, мы воспользовались ими. Рассмотрим подробнее на примере кода:
var result int
err := db.Get(&result, “SELECT GET_LOCK(`lockname`, 60)”)
// execute some sql transaction
err := db.Get(&result, “SELECT RELEASE_LOCK(`lockname`)”)
if result != 1 {
panic(“cannot release a lock that is not acquired”)
}
А после исправления стало так:
tx, err := db.Begin()
var result int
err := tx.Get(&result, “SELECT GET_LOCK(`lockname`, 60)”)
// execute some sql commands
err := tx.Get(&result, “SELECT RELEASE_LOCK(`lockname`)”)
if result != 1 {
panic(“cannot release a lock that is not acquired”)
}
err := tx.Commit();
Раньше у нас сначала происходил захват лока при использовании соединения из пула, потом выполнение транзакции и освобождение лока. После исправления у нас сначала создается транзакция, затем в ней происходит захват лока и уже потом выполнение команд. А освобождение лока происходит перед закрытием транзакции. В итоге ошибки прекратились и блокировки работают как надо.
Оказалось, все просто: этот же официальный клиент предоставляет функцию NotifyClose, которая позволяет узнать, когда соединение с брокером разорвано и переподключится. Важно при этом пересоздать все каналы, очереди и т. д. на случай, если брокер потерял свои данные (хотя я все же советую настраивать брокер так, чтобы он не терял данные в случае падения). Также обратите внимание, что реконнект выполняется в цикле на случай, если брокер долго не встает, иначе ваш сервис попробует один раз присоединиться и сдастся, а вы получите неработающий микросервис.
func connect() err {
conn, err := amqp.Dial(“url”);
connErrorChan := conn.NotifyClose(make(chan *amqp.Error))
go processConnectErrors(connErrorChan)
return err
}
func processConnectErrors(ch chan *amqp.Error) {
err := <- ch
for {
err := connect()
if err != nil {
break
}
}
}
Вот так мы и решили эту проблему (было бы здорово, если бы в туториалах про этот нюанс упоминалось), а затем мы изменили логику общения с брокером так, чтобы сообщения, которые мы хотим отправить, сохранялись сначала в базу данных, а уже оттуда отправлялись в брокер отдельной горутиной. Но это уже тема для отдельной статьи.
Источник статьи: https://habr.com/ru/company/ispring/blog/560032/
Я программирую на Go более двух лет и за 2019 год выпустил в production пять микросервисов: от простых с одной задачей до сложных со своей доменной моделью и несколькими внешними зависимостями. До этого я четыре года программировал на C++, продолжаю увлекаться трехмерной графикой и микроконтроллерами. За это время было набито немало шишек и получено много опыта, которым я хочу с вами поделиться.
Моя статья ориентирована в основном на начинающих разработчиков, но ветераны Go тоже, вероятно, смогут узнать что-то новое.
Коротко, о чем будет статья:
- о том, как не ловить ошибки соединения с базой данных на production;
- http.Client и что не так с клиентом по умолчанию;
- http.Server и его подводные камни;
- и, наконец, рассмотрим пару занятных проблем, не связанных напрямую с настройкой стандартной библиотеки.
sql.DB
sql.DB — это пул соединений, которые могут открываться при отправке запросов и автоматически закрываться специальной горутиной. Пользоваться очень просто: открываем соединение, отправляем запросы, по завершении программы закрываем.Мы проверили на тестовом окружении, все работало как надо, никаких проблем и решили поехать в production.
db, err := sql.Open("mysql", "root:localhost/test")
if err != nil {
return err
}
defer db.Close()
_, err := db.Exec("...")
Скоро после релизов по утрам мы стали иногда получать ошибки соединения с базой или вовсе непонятный EOF.
failed to begin a transaction: invalid connection
unexpected EOF
ashleymcnamara/gophers
Gopher Artwork by Ashley McNamara. Contribute to ashleymcnamara/gophers development by creating an account on GitHub.
github.com
SetMaxOpenConns
Этот метод ограничивает максимальное количество соединений с базой. По-умолчанию там стоит ноль, то есть лимит отсутствует и сервис может устанавливать столько соединений с базой данных, сколько ему вздумается, в то время как ресурсы базы данных и микросервиса ограничены, поэтому ограничение определенно не помешает. Для выбора оптимального значения мы стали профилировать.
Воспользуемся встроенным в язык бенчмарком. В нем мы открываем соединение с базой, выставляем разные значения максимального числа соединений и начинаем в неё параллельно записывать строки по 255 символов. Результаты бенчмарка в таблице.
SetMaxOpenConns | ns/op | B/op | allocs/op |
| 1 | 497081 | 649 | 14 |
| 2 | 360376 | 650 | 14 |
| 3 | 251083 | 652 | 14 |
| 5 | 156420 | 652 | 14 |
| 10 | 110926 | 735 | 13 |
| 20 | 108629 | 719 | 12 |
| 0 | 110477 | 715 | 12 |
Как мы видим, при одном соединении с базой данных производительность примерно в пять раз меньше, чем при неограниченном числе соединений. В данном случае оптимальным будет примерно 10 соединений, т. к. дальнейшее увеличение числа соединений не дает прироста производительности, выходящего за рамки погрешности.
Стоит учитывать, что эти данные получены на моей рабочей машине, где база данных располагается рядом с бенчмарком. Если база данных далеко, числа могут получиться совсем другие.
Но что же это получается, чем больше соединений, тем лучше? Зачем нам ограничивать количество соединений и потенциально терять производительность? А вот зачем.
[mysqld]
max_connections=10
Benchmark_MaxOpenConns20
Benchmark_MaxOpenConns20: main_test.go:69: Error 1040: Too many connections
Benchmark_MaxOpenConns20: main_test.go:69: Error 1040: Too many connections
Benchmark_MaxOpenConns20: main_test.go:69: Error 1040: Too many connections
...
-- FAIL: Benchmark_MaxOpenConns20
FAIL
Для симуляции проблемы я ограничил количество соединений со стороны базы данных (в моем случае это MySQL). В реальной системе такой лимит тоже стоит, просто он повыше, но учитывая, что время запроса будет гораздо выше, чем на локальной машине, а микросервисов, подключенных к одной базе, может быть несколько… упереться в лимит вполне реально.
Вернемся к нашим бенчмаркам: как только число соединений со стороны микросервиса превысило лимит базы данных, мы тут же упали с ошибкой. Это не повод бежать в настройки MySQL и бесконтрольно увеличивать количество соединений базы данных, ведь каждое соединение потребляет ресурсы не только на стороне микросервиса, но и на стороне базы данных. Если хотите в этом убедиться, можно поиграться с калькулятором потребления памяти MySQL с разным количеством соединений https://mysqlcalculator.com
SetMaxIdleConns
Второй метод позволяет ограничивать количество соединений, которые могут остаться открытыми, для повторного использования, после того как все запросы в очереди будут выполнены. Если установить этот параметр в 0, то соединения перестанут переиспользоваться и на каждый запрос будет создаваться новое. Пока не особо понятно, как это повлияет на производительность и стабильность. Значит, время побенчмаркать
| SetMaxIdleConns | ns/op | B/op | allocs/op |
| 0 | 194023 | 6433 | 40 |
| 1 | 130755 | 1973 | 18 |
| 2 | 109399 | 709 | 12 |
| 5 | 106797 | 524 | 12 |
| 10 | 109346 | 524 | 12 |
SetConnMaxLifetime
Последняя настройка позволяет нам ограничивать время, в течение которого соединение можно переиспользовать. По её названию можно подумать, что она обрывает соединения, после того как время жизни соединения превысило лимит, но все хорошо: пока запрос выполняется, соединение не разорвется, оно просто не будет переиспользоваться для новых запросов. Вновь по умолчанию ограничение отсутствует, что позволяет соединениям висеть часами, днями, неделями… Естественно, мы хотим это время ограничить, ведь долгоживущие соединения опасны, т. к. они могут внезапно разорваться или висеть бесполезным грузом, сжирая ресурсы. А чтобы выбрать оптимальное значение, мы, конечно же, побенчмаркаем.
| SetConnMaxLifetime | ns/op | B/op | allocs/op |
| 100 μs | 613533 | 6465 | 42 |
| 1 ms | 537581 | 5340 | 37 |
| 10 ms | 172004 | 1130 | 15 |
| 100 ms | 129907 | 728 | 12 |
| 1 s | 130169 | 724 | 12 |
| 0 (unlimited) | 127519 | 712 | 12 |
Что же имеем в итоге?
- В стандартной конфигурации отсутствует лимит на количество соединений. Это значит, что микросервис может установить огромное количество соединений с базой данных, которые будут расходовать ресурсы и приводить к ошибкам, если база не способна поддерживать такое количество
- Соединения могут переиспользоваться после долгого простоя. Соединение, которое несколько часов или дней висело без запросов, может быть выбрано для очередного запроса, что может привести к нестабильной работе.
- База данных в одностороннем порядке закрывает соединения, по которым долгое время ничего не происходит, но в некоторых случаях сервис об этом не узнает и продолжает считать соединение активным. Именно это у нас и произошло.
- Ограничение времени жизни соединений и максимального их количества решает проблему, т. к. не позволяет скапливаться неиспользуемым соединениям.
В первую очередь оцените нагруженность сервиса. Если сервис должен постоянно обрабатывать тысячи запросов в секунду, то стоит увеличить максимальное количество соединений с БД, количество idle соединений и время жизни соединения. Также можно задуматься о выделенном инстансе базы данных для этого микросервиса. Если же микросервис не сильно нагружен, можно сэкономить ресурсы сервиса и базы и сократить число используемых соединений.
Во-вторых, проанализируйте конфигурацию базы данных: сколько она позволяет создать соединений (стоит оставить небольшой запас свободных соединений — около 5 шт.) на случай, если вы захотите подключиться из консоли + база данных не может мгновенно создать новое соединение взамен старого, будет небольшой период времени, когда существуют оба соединения, и тут вам запас пригодится).
Также можно воспользоваться методом Stats() у sql.DB, который вернет не только информацию о текущих соединениях, но и статистику по ожиданию соединений: сколько раз мы уткнулись в необходимость ожидания соединения и сколько времени потратили впустую, ожидая соединение. Можно вывести эту статистику во внутренний API и изредка мониторить
Ну и, наконец, читайте документацию к языку! В Go прекрасная документация как на сайте golang.org, так и в самом коде, не поленитесь почитать её для типов, которые вы используете.
Вот пример конфигурации для низконагруженного сервиса.
db, err := sql.Open("mysql", "root:localhost/test")
if err != nil {
return err
}
defer db.Close()
db.SetMaxOpenConns(25)
db.SetMaxIdleConns(2)
db.SetConnMaxLifetime(time.Minute)
_, err := db.Exec("...")
25 соединений более чем достаточно, соединения будем пересоздавать каждую минуту, а idle соединений оставим стандартное значение — 2. Мы дописали всего три строчки к тому коду, который был вначале, и улучшили надежность микросервиса!
http.Client
Этот тип используется для отправки HTTP, что позволяет как общаться с другими вашими сервисами через REST API, так и использовать внешние API, скачивать или заливать файлы и т. д.И вновь он требует настройки для корректного функционирования. Что еще более странно, пакет httpвключает DefaultClient, содержащий значения по умолчанию и функции Get, Postи т. д., его использующие. Соответственно, с этими функциями мы ничего не сможем сконфигурировать, и они будут работать без таймаутов, и в production я бы не рекомендовал их использовать.
http.Client.Timeout — самый простой таймаут, распространяющийся на все время выполнения запроса: от установления соединения до завершения чтения тела ответа. Идеально подходит для вызова API. Если же нам нужно скачать файл или стримить данные, он нам не подходит, и для этих случаев нам пригодятся следующие таймауты.
net.Dialer.Timeout — ограничивает время нахождения хоста и установления HTTP-соединения. Пригодится, чтобы не висеть долго на запросе, если удаленный сервер не отвечает.
http.Transport.TLSHandshakeTimeout — если вы используете HTTPS (а стоит, если ваш сервис доступен снаружи), то этот таймаут позволит ограничить время на установление защищенного соединения. Если же вы не используете HTTPS (например, если ваш сервис доступен только внутри кластера), то этот параметр не используется.
http.Transport.ResponseHeaderTimeout — ограничивает время чтения заголовков ответа. Может быть полезен, чтобы не зависнуть при общении с сервисами, которые долго думают после получения запроса.
http.Transport.IdleConnTimeout может ограничивать длительность keep-alive соединений, но об этом я расскажу дальше.
The complete guide to Go net/http timeouts
When writing an HTTP server or client in Go, timeouts are amongst the easiest and most subtle things to get wrong: there’s many to choose from, and a mistake can have no consequences for a long time, until the network glitches and the process hangs.
blog.cloudflare.com
c := &http.Client{}
resp, _ := c.Get("https://host.com")
defer resp.Body.Close()
timer := time.AfterFunc(5*time.Second, func() {
resp.Body.Close()
})
bodyBytes := make([]byte, 0)
for {
timer.Reset(5 * time.Second)
_, err = io.CopyN(bytes.NewBuffer(bodyBytes), resp.Body, 256)
if err == io.EOF {
break // данные закончились, выходим
} else if err != nil {
panic(err)
}
}
Что тут происходит? Сначала мы устанавливаем соединение и подготовимся к скачиванию файла. Далее настроим таймер на небольшой промежуток времени. Если таймер сработает, значит мы не успели вовремя получить свою порцию данных и нужно завершить операцию с ошибкой. Затем запустим бесконечный цикл, в котором будем считывать следующий кусок данных и сбрасывать таймер. Таким образом, мы ставим условие, что за каждые пять секунд мы должны скопировать по меньшей мере 256 байт или получить ошибку. Как только мы дочитали до конца, мы получим ошибку io.EOF и выйдем из бесконечного цикла
У этого подхода есть недостатки, а именно сниженная производительность, ведь теперь мы копируем не все данные разом, а кусками по 256 байт, но возможность быстро обнаружить сетевую ошибку может оказаться важнее. Что приоритетнее в вашем случае, решать вам.
Повторное использование соединений (Keep-Alive)
Также я хотел затронуть тему повторного использования соединений (Keep-Alive). Этот механизм позволяет открыть соединение с сервером один раз и посылать по нему несколько запросов, вместо того чтобы открывать новое соединение на каждый запрос. Особенно это полезно в случае использования HTTP-соединения, т. к. позволяет пропустить процесс handshake для всех запросов кроме первого. Что же нам предлагает Go по части переиспользования соединений?
За него отвечает тип http.Transport, который по умолчанию оставляет открытыми до 100 соединений с таймаутом 90 секунд. Т. е. после того как мы сделали запрос на какой-то сервер, соединение с ним останется в пуле http.Transport для повторного использования в течение 90 секунд. Это звучит разумно, и в общем случае менять не стоит.
При этом присутствует дополнительное ограничение на два соединения на хост (MaxIdleConnsPerHos), т. е. если вы общаетесь только с одним сервером или проводите нагрузочное тестирование микросервиса (при котором будет много запросов к одному серверу), то имеет смысл увеличить этот лимит, изменив свойство MaxIdleConnsPerHost. Но в общем случае так делать не стоит, чтобы не исчерпать весь пул keep-alive соединений на один хост
Также, исследуя эту тему при подготовке статьи, я наткнулся на утверждение, что Keep-Alive ломается, если тело ответа не было считано либо было не закрыто. Я сам не проверял, но в целом будет хорошей практикой всегда считывать тело ответа, даже если оно вам не нужно. Вот пример кода, как это можно сделать, — отправить в ioutil.Discard. А чтобы не писать так каждый раз, можно сделать обертку над клиентом, которая всегда будет читать тело ответа и корректно закрывать его.
res, err := client.Do(req)
io.Copy(ioutil.Discard, res.Body)
res.Body.Close()
Итак, мы разобрали настройки http.Client и готовы настроить его для использования в сервисе. Если ваш http.Client используется исключительно для вызовов API, которые не должны занимать много времени, можно поставить маленький таймаут на всю обработку запроса, к примеру пять секунд, и не заморачиваться тонкими настройками. Если же вы передаете большие объемы данных, либо обработка запроса может занять продолжительное время, или вы вообще стримите данные, то я рекомендую использовать динамический таймаут, а также установить Dialer.Timeout и ResponseHeaderTimeout
http.Server
Где клиент, там должен быть и сервер. Значит, посмотрим на http.Server. Он позволяет вашему сервису отвечать на HTTP-запросы: реализовывать API, отдавать и принимать файлы, отдавать статические страницы и много всего прочего. И как вы уже могли догадаться, в нем опять нет таймаутов. В этот раз стандартная библиотека нам предоставляет два варианта для ограничения запросов и один вариант для управления Keep-Alive.- ReadTimeout начинает отсчет с начала чтения заголовков запроса и заканчивает после завершения считывания тела запроса.
- WriteTimeout же отсчитывает с чтения тела запроса и заканчивает после возвращения ответа.
- IdleTimeout, как вы могли догадаться, отвечает за Keep-Alive.
The complete guide to Go net/http timeouts
When writing an HTTP server or client in Go, timeouts are amongst the easiest and most subtle things to get wrong: there’s many to choose from, and a mistake can have no consequences for a long time, until the network glitches and the process hangs.
blog.cloudflare.com
- http.TimeoutHandler Например, вы можете обернуть свой обработчик http.Handler в http.TimeoutHandler и он автоматически оборвет запрос с кодом 504, если ваш обработчик работал слишком долго. Это может быть полезно, если вы хотите чтобы часть ваших сервисов работала с маленьким таймаутов, а часть — с большим ручным таймаутом.
- ReadHeaderTimeout, который отслеживает время до окончания чтения заголовков запроса (в отличие от ReadTimeout, который включает в себя и чтение тела запроса). Он может быть полезен, если вам нужно прочитать большое тело запроса и вы не знаете, сколько это займет времени, и для тела собираетесь применять наш следующий вариант.
- Динамический таймаут. Так же, как мы использовали копирование по частям при работе с клиентом, мы можем отдавать данные кусками и на стороне сервера. Если клиент не успевает принять часть данных, можно считать это ошибкой.
- context.Context. Контекст с ограничением по времени, но это не особо удобно: в ответе на запрос, завершившийся по таймауту вы получите ошибку “context deadline exceeded” вместо ожидаемого таймаута, и вам придется руками преобразовывать эту ошибку для вашего API.
Пример конфигурации для API:
srv := &http.Server{
ReadTimeout: 5 * time.Second,
WriteTimeout: 10 * time.Second,
IdleTimeout: 120 * time.Second,
}
Пример конфигурации для передачи файлов и стриминга:
srv := &http.Server{
ReadHeaderTimeout: 5 * time.Second,
IdleTimeout: 120 * time.Second,
}
А также стоит использовать динамический таймаут, чтобы не зависнуть в процессе передачи данных
В качестве бонуса я бы хотел рассказать о паре проблем, с которыми мы сталкиваемся при работе с микросервисами. Они не относятся напрямую к стандартной библиотеке Go, но, думаю, вам будет интересно.
Пользовательские блокировки MySQL
Первая проблема всплыла недавно, когда мы решили использовать пользовательские блокировки MySQL в одном из микросервисов. Это команды GET_LOCK и RELEASE_LOCKВ end2end тестах микросервиса никаких проблем первоначально не вылезло, и в тестовом окружении тоже все работало как надо, но затем запросы стали иногда валиться с ошибкой, что невозможно освободить лок, который мы не занимали. Это показалось нам очень странным (ведь в большинстве случаев этот же код работал без ошибок), и мы полезли читать документацию MySQL к этим функциям.
Оказалось, что эти локи привязаны к соединениям базы данных и если соединение разрывается, то и лок автоматически освобождается при разрыве соединения. И тут до нас дошло, что sql.DB — это пул соединений и в итоге захват и освобождение лока могут происходить в совершенно разных соединениях. Решением для нас оказалось перенести блокировку внутрь транзакции. В этом случае стандартная библиотека гарантирует, что все операции будут произведены на одном соединении, которое не будет разорвано между командами. Альтернативным решением было бы использовать выделенное соединение с помощью метода Conn(), но раз уж у нас уже использовались транзакции, мы воспользовались ими. Рассмотрим подробнее на примере кода:
var result int
err := db.Get(&result, “SELECT GET_LOCK(`lockname`, 60)”)
// execute some sql transaction
err := db.Get(&result, “SELECT RELEASE_LOCK(`lockname`)”)
if result != 1 {
panic(“cannot release a lock that is not acquired”)
}
А после исправления стало так:
tx, err := db.Begin()
var result int
err := tx.Get(&result, “SELECT GET_LOCK(`lockname`, 60)”)
// execute some sql commands
err := tx.Get(&result, “SELECT RELEASE_LOCK(`lockname`)”)
if result != 1 {
panic(“cannot release a lock that is not acquired”)
}
err := tx.Commit();
Раньше у нас сначала происходил захват лока при использовании соединения из пула, потом выполнение транзакции и освобождение лока. После исправления у нас сначала создается транзакция, затем в ней происходит захват лока и уже потом выполнение команд. А освобождение лока происходит перед закрытием транзакции. В итоге ошибки прекратились и блокировки работают как надо.
Реконнект к AMQP
Вторая проблема произошла, когда нам понадобилось присоединиться к брокеру сообщений (в нашем случае RabbitMQ) из микросервиса. Мы использовали рекомендуемый официальным сайтом клиент, сделали все по туториалам и все работало, пока в один прекрасный день брокер на production не упал. Кластер, конечно, его поднял, но оказалось, что официальный клиент не производит автоматический реконнект и попытки микросервиса отправить сообщение в брокер приводили к ошибке. Мы перезапустили микросервис, чтобы он присоединился к свежесозданному брокеру, и начали исследовать, как решить эту проблему.Оказалось, все просто: этот же официальный клиент предоставляет функцию NotifyClose, которая позволяет узнать, когда соединение с брокером разорвано и переподключится. Важно при этом пересоздать все каналы, очереди и т. д. на случай, если брокер потерял свои данные (хотя я все же советую настраивать брокер так, чтобы он не терял данные в случае падения). Также обратите внимание, что реконнект выполняется в цикле на случай, если брокер долго не встает, иначе ваш сервис попробует один раз присоединиться и сдастся, а вы получите неработающий микросервис.
func connect() err {
conn, err := amqp.Dial(“url”);
connErrorChan := conn.NotifyClose(make(chan *amqp.Error))
go processConnectErrors(connErrorChan)
return err
}
func processConnectErrors(ch chan *amqp.Error) {
err := <- ch
for {
err := connect()
if err != nil {
break
}
}
}
Вот так мы и решили эту проблему (было бы здорово, если бы в туториалах про этот нюанс упоминалось), а затем мы изменили логику общения с брокером так, чтобы сообщения, которые мы хотим отправить, сохранялись сначала в базу данных, а уже оттуда отправлялись в брокер отдельной горутиной. Но это уже тема для отдельной статьи.
Выводы
- Не полагайтесь на стандартные конфигурации. Они созданы, чтобы вы могли быстро создать прототип, но для production их нужно хорошенько подготовить, особенно если ваш сервис доступен снаружи
- Читайте документацию и умные статьи. В Gо прекрасная документация к стандартной библиотеке, доступная как на сайте golang.org, так и в самом коде. Не ограничивайтесь простыми туториалами, ищите нюансы в документации и блогах крупных компаний
- Тестируйте и профилируйте микросервисы. Большинство проблем можно и нужно отловить до релиза с помощью end2end тестов, бенчмарков и нагрузочного тестирования.
Источник статьи: https://habr.com/ru/company/ispring/blog/560032/