Эта статья написана потому, что я бы хотел иметь такую статью перед глазами, когда развертывал кластер по документации. Сразу хочу сказать, что не являюсь экспертом в K8S, однако имел опыт с развертыванием продуктовых установок DC/OS (экосистемы, основанной на Apache Mesos). Долгое время K8S меня отпугивал тем, что, при попытке его изучения, тебя закидывают кучей концепций и терминов, отчего мозг взрывается.
Тем не менее, у меня возникла задача настроить отказоустойчивый Bare Metal кластер для комплексного приложения, в связи с чем и возникла данная статья. В процессе руководства я затрону следующие аспекты:
Сначала рассмотрим узловую топологию кластера, в котором мы будем развертывать K8S. Это упрощенная топология, без лишних деталей.
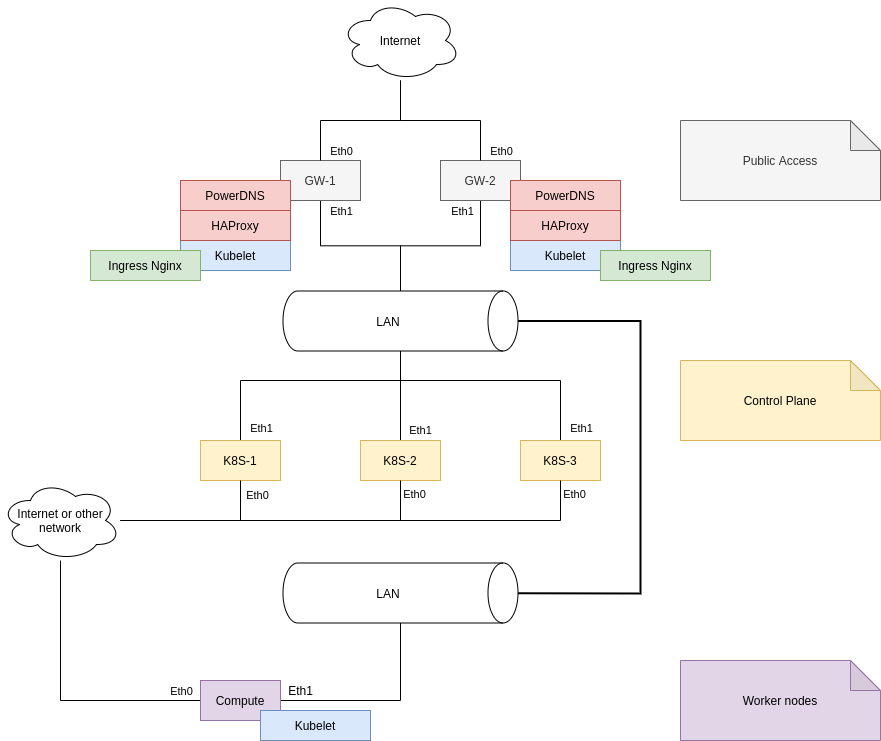
Отличительной особенностью в моем кластере является то, что у всех узлов имеется два сетевых интерфейся - на eth0 всегда находится публичный адрес, а на eth1 - адрес из сети 10.120.0.0/16.
Хочу отметить, что свой кластер я развертывал с помощью Ansible, но в качестве упрощения не буду в статье демонстрировать playbook-и, ориентируясь на настройку руками. Итак, приступим.
Базовая настройка pdns-recursor на gw-1, gw-2 включает указание следующих директив:
allow-from=10.120.0.0/8, 127.0.0.0/8
etc-hosts-file=/etc/hosts.resolv
export-etc-hosts=on
export-etc-hosts-search-suffix=cluster
Сам файл /etc/hosts.resolv генерируется с помощью ansible и выглядит следующим образом:
# Ansible managed
10.120.29.231 gw-1 gw-1
10.120.28.23 gw-2 gw-2
10.120.29.32 video-accessors-1 video-accessors-1
10.120.29.226 video-accessors-2 video-accessors-2
10.120.29.153 mongo-1 mongo-1
10.120.29.210 mongo-2 mongo-2
10.120.29.220 mongo-3 mongo-3
10.120.28.172 compute-1 compute-1
10.120.28.26 compute-2 compute-2
10.120.29.70 compute-3 compute-3
10.120.28.127 zk-1 zk-1
10.120.29.110 zk-2 zk-2
10.120.29.245 zk-3 zk-3
10.120.28.21 minio-1 minio-1
10.120.28.25 minio-2 minio-2
10.120.28.158 minio-3 minio-3
10.120.28.122 minio-4 minio-4
10.120.29.187 k8s-1 k8s-1
10.120.28.37 k8s-2 k8s-2
10.120.29.204 k8s-3 k8s-3
10.120.29.135 kafka-1 kafka-1
10.120.29.144 kafka-2 kafka-2
10.120.28.130 kafka-3 kafka-3
10.120.29.194 clickhouse-1 clickhouse-1
10.120.28.66 clickhouse-2 clickhouse-2
10.120.28.61 clickhouse-3 clickhouse-3
10.120.29.244 app-1 app-1
10.120.29.228 app-2 app-2
10.120.29.33 prometeus prometeus
10.120.29.222 manager manager
10.120.29.187 k8s-cp
Шаблон Ansible для генерации конфига
Далее необходимо сделать так, чтобы все узлы вместо DNS-рекурсоров, получаемых из настроек DHCP, использовали данные DNS-ы. В Ubuntu 18.04 используется systemd-resolved, поэтому необходимо подсунуть ему требуемые серверы gw-1, gw-2. Для этого создадим на каждом хосте кластера конфигурационный файл systemd, переопределяющий поведение systemd-resolved, разместив его по пути /etc/systemd/network/0-eth0.network:
[Match]
Name=eth0
[Network]
DHCP=ipv4
DNS=10.120.28.23 10.120.29.231
Domains=cluster
[DHCP]
UseDNS=false
UseDomains=false
Делает он следующее: для инструкций DHCP, полученных через eth0 будут игнорироваться DNS-серверы и поисковые домены, определенные на DHCP-сервере. Вместо этого будут использоваться серверы 10.120.28.23, 10.120.29.231 и поисковый домен *.cluster.
После создания данного файла требуется перезагрузить узел или сетевую подсистему узла, поскольку простой перезапуск systemd-resolved не инициирует повторное получение данных по DHCP. Я перезагружаю хост полностью для того, чтобы убедиться в корректном поведении при старте узла.
При успешной инициализации systemd-resolve --status выдаст следующий листинг:
Global
DNSSEC NTA: 10.in-addr.arpa
16.172.in-addr.arpa
168.192.in-addr.arpa
17.172.in-addr.arpa
18.172.in-addr.arpa
19.172.in-addr.arpa
20.172.in-addr.arpa
21.172.in-addr.arpa
22.172.in-addr.arpa
23.172.in-addr.arpa
24.172.in-addr.arpa
25.172.in-addr.arpa
26.172.in-addr.arpa
27.172.in-addr.arpa
28.172.in-addr.arpa
29.172.in-addr.arpa
30.172.in-addr.arpa
31.172.in-addr.arpa
corp
d.f.ip6.arpa
home
internal
intranet
lan
local
private
test
Link 3 (eth1)
Current Scopes: none
LLMNR setting: yes
MulticastDNS setting: no
DNSSEC setting: no
DNSSEC supported: no
Link 2 (eth0)
Current Scopes: DNS
LLMNR setting: yes
MulticastDNS setting: no
DNSSEC setting: no
DNSSEC supported: no
DNS Servers: 10.120.28.23
10.120.29.231
DNS Domain: cluster
Это действие необходимо выполнить на всех узлах кластера. При корректном выполнении каждый узел сможет выполнить ping gw-1, ping gw-1.cluster и получить ответ от данных узлов по внутренним ip-адресам.
sudo -- sh -c "swapoff -a && sed -i '/ swap / s/^/#/' /etc/fstab"
Для пущей уверенности удалите swap-раздел с помощью fdisk.
В простейшем случае, вам требуется обеспечить работоспособность multicast, поскольку VXLAN использует multicast-группы, для своей работы. Если multicast - не ваш вариант, но вы хотите использовать провайдер, основанный на VXLAN, можно настроить работу VXLAN через BGP или другими способами. Однако, сможет ли жить с этим выбранный вами провайдер сетевой инфраструктуры Kubernetes - это большой вопрос. В общем, Flannel поддерживает VXLAN через multicast. В моем случае это VXLAN+multicast over VXLAN+multicast over Ethernet, поскольку в моей сети виртуальные машины имеют VXLAN-бэкбон, работающий поверх Ethernet с использованием multicast - так тоже работает.
В /etc/modules добавьте br_netfilter, overlay.
Выполните modprobe br_netfilter && modprobe overlay, чтобы загрузить модули.
В /etc/sysctl.conf добавьте:
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
Выполните sysctl -p для применения изменений.
sudo apt-get update
sudo apt install containerd
sudo sh -- -c "containerd config default | tee /etc/containerd/config.toml"
sudo service containerd restart
sudo apt-get update && sudo apt-get install -y apt-transport-https curl
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
kubeadm init --pod-network-cidr=10.244.0.0/16 \
--control-plane-endpoint=k8s-cp \
--apiserver-advertise-address=10.120.29.187
Для Flannel категорически важно использовать --pod-network-cidr=10.244.0.0/16. С другим адресным пространством для POD-ов K8S он не запустится.
Важный аргумент --api-server-advertise-address. Он влияет не только на api-server, но и на Etcd, что нигде не описано, но принципиально важно для корректной работоспособности отказоустойчивой топологии. Если ничего не указать, то kubeadm возьмет адрес с той сети, в которой находится шлюз по-умолчанию, что не всегда верно. В моем случае это приводит к тому, что Etcd стартует на публичном интерфейсе, а кластер Etcd хочет работать по публичной сети, что требует открытия дополнительных портов и создает возможность атаки на эту службу. Это меня не устраивает.
Если этот адрес не задать корректно, то Flannel тоже не сможет инициализироваться, будет падать с ошибками, что не может связаться с Control Plane (будет использовать тот же IP-адрес из сети со шлюзом по умолчанию для связи).
В общем, этот параметр привносит много геморроя и ведет к некорректной работе всего, что только может некорректно работать.
Теперь, если все указано верно, то Kubeadm развернет K8S на данном узле. Я рекомендую выполнить перезагрузку узла для того, чтобы убедиться что Control Plane стартует как надо. Убедитесь в этом, запросив список выполняемых задач после перезагрузки узла:
ps xa | grep -E '(kube-apiserver|etcd|kube-proxy|kube-controller-manager|kube-scheduler)'
Теперь надо скопировать настройки конфигурации для доступа администратора к кластеру в домашний каталог. Это делается для того, чтобы утилита kubectl работала с конфигурационным файлом по стандартному пути:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Для проверки работоспособности kubectl запросите задачи, выполняемые на настроенном узле посредством команды kubectl get pods --all-namespaces. Вы должны получить вывод, примерно соответствующий следующему:
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system etcd-k8s-1 1/1 Running 0 2d23h
kube-system kube-apiserver-k8s-1 1/1 Running 0 2d23h
kube-system kube-controller-manager-k8s-1 1/1 Running 1 2d23h
kube-system kube-scheduler-k8s-1 1/1 Running 1 2d23h
Я рекомендую посмотреть вывод этой команды еще пару раз, с перерывом 1 минуту, чтобы убедиться, что RESTARTS не растут, а статус Running.
Сам Kubernetes никакой сети не предоставляет, делегируя это плагинам CNI. Мы будем использовать простой CNI - Flannel. Его установка производится следующей командой:
kubectl apply -f https://github.com/coreos/flannel/raw/master/Documentation/kube-flannel.yml
Опять же, выполните kubectl get pods --all-namespaces несколько раз, чтобы убедиться, что Flannel выполняется без ошибок и RESTARTS не растут. Если что-то пошло не так, посмотрите журнал событий Flannel следующим способом (только используйте настоящее имя POD-а Flannel):
kubectl logs -n kube-system kube-flannel-ds-xn2j9
Если ошибок нет, можно двигаться дальше. Теперь вы можете подключить два других узла Control Plane с помощью команд, выполненной на каждом из них:
# ssh k8s-2
sudo kubeadm join k8s-cp:6443 --apiserver-advertise-address=10.120.28.37 --token tfqsms.kiek2vk129tpf0b7 --discovery-token-ca-cert-hash sha256:0c446bfabcd99aae7e650d110f8b9d6058cac432078c4fXXXXX6055b4bd --control-plane
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# ssh k8s-3
sudo kubeadm join k8s-cp:6443 --apiserver-advertise-address=10.120.29.204 --token tfqsms.kiek2vk129tpf0b7 --discovery-token-ca-cert-hash sha256:0c446bfabcd99aae7e650d110f8b9d6058cac432078c4fXXXXXec6055b4bd --control-plane
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Если вдруг --token "протух", используйте команду kubeadm token create, чтобы сгенерировать новый.
После подключения узла смотрите внимательно за состоянием Etcd:
kubectl get pods --all-namespaces | grep etcd
kube-system etcd-k8s-1 1/1 Running 0 2d23h
kube-system etcd-k8s-2 1/1 Running 1 2d22h
kube-system etcd-k8s-3 1/1 Running 1 2d22h
Состояние должно быть Running, увеличение счетчика перезагрузок не должно происходить. Команда kubectl get pods --all-namespaces должна отображать трехкратный набор процессов на всех узлах Control Plane:
NAME READY STATUS RESTARTS AGE
coredns-74ff55c5b-h2zjq 1/1 Running 0 2d23h
coredns-74ff55c5b-n6b49 1/1 Running 0 2d23h
etcd-k8s-1 1/1 Running 0 2d23h
etcd-k8s-2 1/1 Running 1 2d22h
etcd-k8s-3 1/1 Running 1 2d22h
kube-apiserver-k8s-1 1/1 Running 0 2d23h
kube-apiserver-k8s-2 1/1 Running 1 2d22h
kube-apiserver-k8s-3 1/1 Running 1 2d22h
kube-controller-manager-k8s-1 1/1 Running 1 2d23h
kube-controller-manager-k8s-2 1/1 Running 1 2d22h
kube-controller-manager-k8s-3 1/1 Running 1 2d22h
kube-flannel-ds-2f6d5 1/1 Running 0 2d3h
kube-flannel-ds-2p5vx 1/1 Running 0 2d3h
kube-flannel-ds-4ng99 1/1 Running 3 2d22h
kube-proxy-22jpt 1/1 Running 0 2d3h
kube-proxy-25rxn 1/1 Running 0 2d23h
kube-proxy-2qp8r 1/1 Running 0 2d3h
kube-scheduler-k8s-1 1/1 Running 1 2d23h
kube-scheduler-k8s-2 1/1 Running 1 2d22h
kube-scheduler-k8s-3 1/1 Running 1 2d22h
Следующим шагом настроим отказоустойчивый IP-адрес, который будет использоваться для доступа к Control Plane.
sudo systemctl enable corosync
sudo systemctl enable pacemaker
Я придерживаюсь такого мнения, что корневые компоненты или работают или не надо их использовать, в /etc/rc.local прописывать эти службы не хотелось.
В итоге, я познакомился со специализированным решением по предоставлению отказоустойчивого IP-адреса kube-vip, разработанным специально для Kubernetes. Для его запуска нам понадобится создать три манифеста, каждый для запуска kube-vip на одном из узлов Control Plane:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
name: kube-vip-cp-k8s-1 # поменять имя, соответственно узлу
namespace: kube-system
spec:
nodeName: k8s-1 # будет запускаться именно на этом узле
containers:
- args:
- start
env:
- name: vip_arp
value: "true"
- name: vip_interface
value: eth1
- name: vip_leaderelection
value: "true"
- name: vip_leaseduration
value: "5"
- name: vip_renewdeadline
value: "3"
- name: vip_retryperiod
value: "1"
- name: vip_address
value: 10.120.0.1 # указать реальный IP, который будет использоваться
image: plndr/kube-vip:0.3.1 # проверить актуальную версию
imagePullPolicy: Always
name: kube-vip-cp
resources: {}
securityContext:
capabilities:
add:
- NET_ADMIN
- SYS_TIME
volumeMounts:
- mountPath: /etc/kubernetes/admin.conf
name: kubeconfig
- mountPath: /etc/ssl/certs
name: ca-certs
readOnly: true
hostNetwork: true
volumes:
- hostPath:
path: /etc/kubernetes/admin.conf
name: kubeconfig
- hostPath:
path: /etc/ssl/certs
name: ca-certs
status: {}
Данный манифест необходимо сформировать для каждого из серверов Control Plane и применить все:
kubectl apply -f cluster_config/vip-{1,2,3}.yml
В результате вы должны получить три нормально выполняющихся POD-а, каждый на своем узле, при этом адрес 10.120.0.1 должен нормально пинговаться. Проверьте, что только один из kube-vip владеет IP с помощью arping:
sudo arping 10.120.0.1
ARPING 10.120.0.1
42 bytes from 1e:01:17:00:01:22 (10.120.0.1): index=0 time=319.476 usec
42 bytes from 1e:01:17:00:01:22 (10.120.0.1): index=1 time=306.360 msec
42 bytes from 1e:01:17:00:01:22 (10.120.0.1): index=2 time=349.666 usec
Чем хорош kube-vip? Он не только предоставляет отказоустойчивый IP, но и определяет когда сервер на хосте, где он выполняется, становится недоступен, переставая балансировать на него трафик.
Теперь, когда kube-vip предоставляет отказоустойчивый доступ к Kubernetes необходимо на хостах-рекурсорах gw-1, gw-2 в /etc/hosts.resolv обновить записи для k8s-cp:
10.120.0.1 k8s-cp
Выполните перезагрузку pdns-recursor командой sudo service pdns-recursor restart и проверьте, что k8s-cp отвечает со всех узлов IP адресом 10.120.0.1. Проверьте, что kubectl все еще корректно работает с новой записью для k8s-cp.
На данном этапе у нас есть реализация отказоустойчивого Control Plane K8S. Я рекомендую несколько раз поочередно перезагружать k8s-{1,2,3}, чтобы проверить, что кластер остается в работоспособном состоянии.
Все эти узлы в кластер можно добавить следующим образом:
kubeadm token create --print-join-command
kubeadm join k8s-cp:6443 --token rn0s5p.y6waq1t6y2y6z9vw --discovery-token-ca-cert-hash sha256:0c446bfabcd99aae7e650d110f8b9d6058cac432078c4fXXXe22ec6055b4bd
# ssh gw-1
sudo kubeadm join k8s-cp:6443 --token rn0s5p.y6waq1t6y2y6z9vw --discovery-token-ca-cert-hash sha256:0c446bfabcd99aae7e650d110f8b9d6058cac432078c4fXXXe22ec6055b4bd
# ssh gw-2
...
# ssh compute-1
После добавления kubectl get pds --all-namespaces должен показать расширенный набор выполняющихся POD-ов, а kubectl get nodes должен вывести все узлы кластера:
kubectl get nodes
NAME STATUS ROLES AGE VERSION
compute-1 Ready compute 2d23h v1.20.2
gw-1 Ready gateway 2d4h v1.20.2
gw-2 Ready gateway 2d4h v1.20.2
k8s-1 Ready control-plane,master 2d23h v1.20.2
k8s-2 Ready control-plane,master 2d23h v1.20.2
k8s-3 Ready control-plane,master 2d23h v1.20.2
Теперь можно задать узлам роли, для того, чтобы иметь возможность использовать их при развертывании приложений. В листинге выше роли уже заданы, поскольку он сделан с рабочего кластера.
kubectl label node gw-1 node-role.kubernetes.io/gateway=true
kubectl label node gw-2 node-role.kubernetes.io/gateway=true
kubectl label node compute-1 node-role.kubernetes.io/compute=true
# если надо удалить роль
kubectl label node compute-1 node-role.kubernetes.io/compute-
kubectl get nodes --output wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
compute-1 Ready compute 3d v1.20.2 10.120.28.172 <none> Ubuntu 18.04.5 LTS 4.15.0-135-generic containerd://1.3.3
gw-1 Ready gateway 2d4h v1.20.2 10.120.29.231 <none> Ubuntu 18.04.5 LTS 4.15.0-135-generic containerd://1.3.3
gw-2 Ready gateway 2d4h v1.20.2 10.120.28.23 <none> Ubuntu 18.04.5 LTS 4.15.0-135-generic containerd://1.3.3
k8s-1 Ready control-plane,master 3d v1.20.2 10.120.29.187 <none> Ubuntu 18.04.5 LTS 4.15.0-135-generic containerd://1.3.3
k8s-2 Ready control-plane,master 2d23h v1.20.2 10.120.28.37 <none> Ubuntu 18.04.5 LTS 4.15.0-135-generic containerd://1.3.3
k8s-3 Ready control-plane,master 2d23h v1.20.2 10.120.29.204 <none> Ubuntu 18.04.5 LTS 4.15.0-135-generic containerd://1.3.3
Собственно, назначить этот External IP можно только через API, при этом он сбрасывается самим Kubernetes время от времени и требует постоянной установки. В общем, это неудобно и использоваться нормально не может.
Я читал длинную переписку на GitHub, которая закончилась ничем вразумительным, еще советуют использовать metallb, который тоже непонятно в каком состоянии. Как итог, я решил просто завести Nginx Ingress, используя hostNetworking, поскольку это обеспечивает привязку данного Ingress с адресам 0.0.0.0:443, 0.0.0.0:80 и решает мою задачу.
Собственно, манифест для запуска Nginx Ingress выглядит так:
Очень большой фрагмент YAML
Запустив его с помощью kubectl apply -f nginx-ingress.yaml, мы получим два POD-а Nginx, выполняющихся на узлах gw-1, gw-2 и слушающих 443-й и 80-й порты:
kubectl get pods --all-namespaces | grep nginx
ingress-nginx ingress-nginx-admission-create-4mm9m 0/1 Completed 0 46h
ingress-nginx ingress-nginx-admission-patch-7jkwg 0/1 Completed 2 46h
ingress-nginx ingress-nginx-controller-b966cf6cd-7kpzm 1/1 Running 1 46h
ingress-nginx ingress-nginx-controller-b966cf6cd-ckl97 1/1 Running 0 46h
На узлах gw-1, gw-2:
sudo netstat -tnlp | grep -E ' 443|80)'
443|80)'
tcp 0 0 0.0.0.0:443 0.0.0.0:* LISTEN 2661/nginx: master
tcp 0 0 0.0.0.0:443 0.0.0.0:* LISTEN 2661/nginx: master
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 2661/nginx: master
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 2661/nginx: master
tcp6 0 0 :::443 :::* LISTEN 2661/nginx: master
tcp6 0 0 :::443 :::* LISTEN 2661/nginx: master
tcp6 0 0 :::80 :::* LISTEN 2661/nginx: master
tcp6 0 0 :::80 :::* LISTEN 2661/nginx: master
Можно постучаться на публичные адреса gw-1, gw-2 по 80-му порту и получить приветственную страницу Nginx. Далее, Вы можете использовать публичные адреса gw-1, gw-2 для создания записей DNS, использования в CDN и т.п.
Протестировать работу inress можно, создав сервис, на который Ingress будет проксировать трафик (взято отсюда) - echo1.yaml:
apiVersion: v1
kind: Service
metadata:
name: echo1
spec:
ports:
- port: 80
targetPort: 5678
selector:
app: echo1
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: echo1
spec:
selector:
matchLabels:
app: echo1
replicas: 2
template:
metadata:
labels:
app: echo1
spec:
containers:
- name: echo1
image: hashicorp/http-echo
args:
- "-text=echo1"
ports:
- containerPort: 5678
Выполните данный манифест с помощью kubectl apply -f echo1.yaml. Теперь создадим правило Ingress (ingress-echo1.yaml):
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: echo-ingress
spec:
rules:
- host: echo1.example.com
http:
paths:
- backend:
serviceName: echo1
servicePort: 80
Выполним данный манифест kubectl apply -f ingress-echo1.yaml. Теперь, если на локальном компьютере в /etchosts внести запись для echo1.example.com:
127.0.0.1 localhost
127.0.1.1 manager
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
X.Y.Z.C echo1.example.com
То можно получить проксирование трафика через Nginx Ingress. Проверим с помощью curl:
curl echo1.example.com
echo1
kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0/aio/deploy/recommended.yaml
Dashboard имеет ряд ограничений, например, он не работает через http, если обращение осуществляется не с localhost. В целом, не рекомендуется как-либо предоставлять доступ к Dashboard извне кластера через Ingress. Кроме того, Dashboard использует встроенную систему RBAC Kubernetes, поэтому требуется создать пользователя и дать ему права на Dashboard.
Инструкция взята с этой страницы. Создадим аккаунт:
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
EOF
Определим роль пользователя:
cat <<EOF | kubectl apply -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
EOF
Получим токен, с помощью которого пользователь сможет войти в Dashboard:
kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}"
Если на вашей машине уже настроен kubect и есть $HOME/.kube/config, а сама машина "видит" k8s-cp, то вы можете запустить kubectl proxy и получить доступ к Dashboard по ссылке: http://localhost:8001/api/v1/namesp...d/services/https:kubernetes-dashboard:/proxy/.
Если же ваша машина с браузером находится вне кластера, то переходим к следующему шагу, где мы настроим проброс API Kubernetes наружу через HAProxy.
defaults
# mode is inherited by sections that follow
mode tcp
frontend k8s
# receives traffic from clients
bind :6443
default_backend kubernetes
backend kubernetes
# relays the client messages to servers
server k8s k8s-cp:6443
Теперь вы можете обратиться к API K8S извне, указав в /etc/hosts своей локальной машины адрес gw-1 или gw-2 в качестве k8s-cp. Вам должны быть доступны с локальной машины все команды kubectl, включая kubectl proxy:
kubectl proxy
Starting to serve on 127.0.0.1:8001
После этого можно открыть в браузере http://localhost:8001/api/v1/namesp...d/services/https:kubernetes-dashboard:/proxy/ и насладиться видом приглашения авторизации Dashboard K8S:
Вводим токен для ранее созданного пользователя Dasboard, полученный с помощью:
kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}"
eyJhbGciOiJSUzI1NiIsImtpZCI6IlFkcGxwMTN2YlpyNS1TOTYtUnVYdsfadfsdjfksdlfjm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLWd6anprIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiJjM2RiOWFkMS0yYjdmLTQ3YTYtOTM3My1hZWI2ZjJkZjk0NTAiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.ht-RyqLXY4UzBnxIzJcnQn8Kk2iHWZzKVeAjUhKkJ-vOAtyqBu50rExgiRWsEHWfJp1p9xN8sXFKg62FFFbHWftPf6PmwfcBK2lXPy6OL9OaooP17WJVn75KKXIZHPWLO9VmRXPB1S-v2xFuG_J8jHB8pZHJlFjp4zIXfB--QwhrxeoTt5zv3CfXCl1_VYgCoqaxRsa7e892-vtMijBo7EZfJiyuAUQr_TsAIDY3zOWFJeHbwPFWzL_1fF9Y2o3r0pw7hYZHUoI8Z-3hbfOi10QBRyQlNZTMFSh7Z38RRbV1tw2ZmMvgSQyHa9TZFy2kYik6VnugNB2cilamo_b7hg
и переходим на главный экран Dashboard:
Источник статьи: https://habr.com/ru/post/540220/
Тем не менее, у меня возникла задача настроить отказоустойчивый Bare Metal кластер для комплексного приложения, в связи с чем и возникла данная статья. В процессе руководства я затрону следующие аспекты:
- корректная установка K8S с помощью kubeadm на узлах с несколькими NIC;
- реализация отказоустойчивого Control Plane с доступом по общему IP и DNS-имени;
- реализация Ingress контроллера на базе Nginx на выделенных узлах с доступом из публичной сети;
- проброс K8S API в публичную сеть;
- доступ к K8S Dashboard UI с компьютера администратора.
Сначала рассмотрим узловую топологию кластера, в котором мы будем развертывать K8S. Это упрощенная топология, без лишних деталей.
Отличительной особенностью в моем кластере является то, что у всех узлов имеется два сетевых интерфейся - на eth0 всегда находится публичный адрес, а на eth1 - адрес из сети 10.120.0.0/16.
В случае использования Enterprise решений с сегментами вне управления K8S, машины с несколькими сетевыми картами и доступом к ним из разных сетей - достаточно рядовая история, поэтому данная модель развертывания вполне может встретиться, к примеру, Ceph может предоставляться узлам по отдельной высокоскоростной сети или VLAN-у.Стоит отметить, что K8S исключительно проще настраивать в том случае, когда машины имеют по одному NIC. Если ваша инфраструктура позволяет вам использовать машины с одним сетевым устройством и иметь внешний балансировщик нагрузки - однозначно так необходимо делать.
В случае моей инфраструктуры такая топология хотя и в принципе возможна, но я понял насколько K8S проще настроить при использовании машин с одной NIC уже после того, как начал развертывание, поэтому решил "победить" проблемы, в рамках текущей топологии, сохранив преимущества доступа к каждой машине напрямую из связанных сетей.
Kubeadm при развертывании служб считает, что что правильный IP-адрес - это тот, который находится в той же сети, где шлюз "по-умолчанию", если это поведение не переопределить, ничего хорошего не выйдет.
Хочу отметить, что свой кластер я развертывал с помощью Ansible, но в качестве упрощения не буду в статье демонстрировать playbook-и, ориентируясь на настройку руками. Итак, приступим.
Замена DNS-рекурсора
Я хочу обеспечить доступность всех узлов кластера через DNS-имена по внутренним IP-адресам, сохранив доступность разрешения обычных имен узлов в интернете. Для этого, на серверах gw-1, gw-2 я разверну pdns-recursor и укажу его в качестве рекурсора на всех узлах кластера.Базовая настройка pdns-recursor на gw-1, gw-2 включает указание следующих директив:
allow-from=10.120.0.0/8, 127.0.0.0/8
etc-hosts-file=/etc/hosts.resolv
export-etc-hosts=on
export-etc-hosts-search-suffix=cluster
Сам файл /etc/hosts.resolv генерируется с помощью ansible и выглядит следующим образом:
# Ansible managed
10.120.29.231 gw-1 gw-1
10.120.28.23 gw-2 gw-2
10.120.29.32 video-accessors-1 video-accessors-1
10.120.29.226 video-accessors-2 video-accessors-2
10.120.29.153 mongo-1 mongo-1
10.120.29.210 mongo-2 mongo-2
10.120.29.220 mongo-3 mongo-3
10.120.28.172 compute-1 compute-1
10.120.28.26 compute-2 compute-2
10.120.29.70 compute-3 compute-3
10.120.28.127 zk-1 zk-1
10.120.29.110 zk-2 zk-2
10.120.29.245 zk-3 zk-3
10.120.28.21 minio-1 minio-1
10.120.28.25 minio-2 minio-2
10.120.28.158 minio-3 minio-3
10.120.28.122 minio-4 minio-4
10.120.29.187 k8s-1 k8s-1
10.120.28.37 k8s-2 k8s-2
10.120.29.204 k8s-3 k8s-3
10.120.29.135 kafka-1 kafka-1
10.120.29.144 kafka-2 kafka-2
10.120.28.130 kafka-3 kafka-3
10.120.29.194 clickhouse-1 clickhouse-1
10.120.28.66 clickhouse-2 clickhouse-2
10.120.28.61 clickhouse-3 clickhouse-3
10.120.29.244 app-1 app-1
10.120.29.228 app-2 app-2
10.120.29.33 prometeus prometeus
10.120.29.222 manager manager
10.120.29.187 k8s-cp
Шаблон Ansible для генерации конфига
Далее необходимо сделать так, чтобы все узлы вместо DNS-рекурсоров, получаемых из настроек DHCP, использовали данные DNS-ы. В Ubuntu 18.04 используется systemd-resolved, поэтому необходимо подсунуть ему требуемые серверы gw-1, gw-2. Для этого создадим на каждом хосте кластера конфигурационный файл systemd, переопределяющий поведение systemd-resolved, разместив его по пути /etc/systemd/network/0-eth0.network:
[Match]
Name=eth0
[Network]
DHCP=ipv4
DNS=10.120.28.23 10.120.29.231
Domains=cluster
[DHCP]
UseDNS=false
UseDomains=false
Делает он следующее: для инструкций DHCP, полученных через eth0 будут игнорироваться DNS-серверы и поисковые домены, определенные на DHCP-сервере. Вместо этого будут использоваться серверы 10.120.28.23, 10.120.29.231 и поисковый домен *.cluster.
После создания данного файла требуется перезагрузить узел или сетевую подсистему узла, поскольку простой перезапуск systemd-resolved не инициирует повторное получение данных по DHCP. Я перезагружаю хост полностью для того, чтобы убедиться в корректном поведении при старте узла.
При успешной инициализации systemd-resolve --status выдаст следующий листинг:
Global
DNSSEC NTA: 10.in-addr.arpa
16.172.in-addr.arpa
168.192.in-addr.arpa
17.172.in-addr.arpa
18.172.in-addr.arpa
19.172.in-addr.arpa
20.172.in-addr.arpa
21.172.in-addr.arpa
22.172.in-addr.arpa
23.172.in-addr.arpa
24.172.in-addr.arpa
25.172.in-addr.arpa
26.172.in-addr.arpa
27.172.in-addr.arpa
28.172.in-addr.arpa
29.172.in-addr.arpa
30.172.in-addr.arpa
31.172.in-addr.arpa
corp
d.f.ip6.arpa
home
internal
intranet
lan
local
private
test
Link 3 (eth1)
Current Scopes: none
LLMNR setting: yes
MulticastDNS setting: no
DNSSEC setting: no
DNSSEC supported: no
Link 2 (eth0)
Current Scopes: DNS
LLMNR setting: yes
MulticastDNS setting: no
DNSSEC setting: no
DNSSEC supported: no
DNS Servers: 10.120.28.23
10.120.29.231
DNS Domain: cluster
Это действие необходимо выполнить на всех узлах кластера. При корректном выполнении каждый узел сможет выполнить ping gw-1, ping gw-1.cluster и получить ответ от данных узлов по внутренним ip-адресам.
Отключение раздела подкачки
Выполняется на всех узлах. Kubernetes не хочет работать при наличии разделов подкачки на узлах. Для их отключения вы можете воспользоваться следующим однострочником:sudo -- sh -c "swapoff -a && sed -i '/ swap / s/^/#/' /etc/fstab"
Для пущей уверенности удалите swap-раздел с помощью fdisk.
Внесение изменений в сетевые настройки ядра
Выполняется на всех узлах. Я буду использовать Flannel - простейший оверлейный сетевой плагин для K8S. Обратите внимание, что довольно много сетевых плагинов используют VXLAN. Это накладывает определенные особенности для сетевой инфраструктуры.В простейшем случае, вам требуется обеспечить работоспособность multicast, поскольку VXLAN использует multicast-группы, для своей работы. Если multicast - не ваш вариант, но вы хотите использовать провайдер, основанный на VXLAN, можно настроить работу VXLAN через BGP или другими способами. Однако, сможет ли жить с этим выбранный вами провайдер сетевой инфраструктуры Kubernetes - это большой вопрос. В общем, Flannel поддерживает VXLAN через multicast. В моем случае это VXLAN+multicast over VXLAN+multicast over Ethernet, поскольку в моей сети виртуальные машины имеют VXLAN-бэкбон, работающий поверх Ethernet с использованием multicast - так тоже работает.
В /etc/modules добавьте br_netfilter, overlay.
Выполните modprobe br_netfilter && modprobe overlay, чтобы загрузить модули.
В /etc/sysctl.conf добавьте:
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward = 1
Выполните sysctl -p для применения изменений.
Установка Сontainerd
Выполняется на всех узлах. Kubernetes рекомендует использовать Containerd (впрочем, новые версии Docker тоже используют Containerd), поэтому установим его:sudo apt-get update
sudo apt install containerd
sudo sh -- -c "containerd config default | tee /etc/containerd/config.toml"
sudo service containerd restart
Установим kubeadm, kubelet, kubectl
Выполняется на всех узлах. Здесь прям из руководства по установке K8S:sudo apt-get update && sudo apt-get install -y apt-transport-https curl
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
deb https://apt.kubernetes.io/ kubernetes-xenial main
EOF
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
sudo apt-mark hold kubelet kubeadm kubectl
Инициализация узлов Control Plane
Выполняется на узлах, которые будут обслуживать Control Plane K8S - в моем случае k8s-{1,2,3}. Здесь уже есть нюансы, специфичные для моего развертывания:kubeadm init --pod-network-cidr=10.244.0.0/16 \
--control-plane-endpoint=k8s-cp \
--apiserver-advertise-address=10.120.29.187
Для Flannel категорически важно использовать --pod-network-cidr=10.244.0.0/16. С другим адресным пространством для POD-ов K8S он не запустится.
Здесь Вы должны указать тот DNS или IP, который будет использоваться для связи всех шурушков K8S-а с Control Plane. Я решил использовать доменное имя k8s-cp, привязанное к отказоустойчивому ip-адресу 10.120.0.1 (см. далее, на текущий момент, k8s-cp указывает на один из серверов Control Plane: 10.120.29.187 k8s-cp).--control-plane-endpoint string Specify a stable IP address or DNS name for the control plane.
Важный аргумент --api-server-advertise-address. Он влияет не только на api-server, но и на Etcd, что нигде не описано, но принципиально важно для корректной работоспособности отказоустойчивой топологии. Если ничего не указать, то kubeadm возьмет адрес с той сети, в которой находится шлюз по-умолчанию, что не всегда верно. В моем случае это приводит к тому, что Etcd стартует на публичном интерфейсе, а кластер Etcd хочет работать по публичной сети, что требует открытия дополнительных портов и создает возможность атаки на эту службу. Это меня не устраивает.
Если этот адрес не задать корректно, то Flannel тоже не сможет инициализироваться, будет падать с ошибками, что не может связаться с Control Plane (будет использовать тот же IP-адрес из сети со шлюзом по умолчанию для связи).
В общем, этот параметр привносит много геморроя и ведет к некорректной работе всего, что только может некорректно работать.
Теперь, если все указано верно, то Kubeadm развернет K8S на данном узле. Я рекомендую выполнить перезагрузку узла для того, чтобы убедиться что Control Plane стартует как надо. Убедитесь в этом, запросив список выполняемых задач после перезагрузки узла:
ps xa | grep -E '(kube-apiserver|etcd|kube-proxy|kube-controller-manager|kube-scheduler)'
Теперь надо скопировать настройки конфигурации для доступа администратора к кластеру в домашний каталог. Это делается для того, чтобы утилита kubectl работала с конфигурационным файлом по стандартному пути:
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Для проверки работоспособности kubectl запросите задачи, выполняемые на настроенном узле посредством команды kubectl get pods --all-namespaces. Вы должны получить вывод, примерно соответствующий следующему:
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system etcd-k8s-1 1/1 Running 0 2d23h
kube-system kube-apiserver-k8s-1 1/1 Running 0 2d23h
kube-system kube-controller-manager-k8s-1 1/1 Running 1 2d23h
kube-system kube-scheduler-k8s-1 1/1 Running 1 2d23h
Я рекомендую посмотреть вывод этой команды еще пару раз, с перерывом 1 минуту, чтобы убедиться, что RESTARTS не растут, а статус Running.
Сам Kubernetes никакой сети не предоставляет, делегируя это плагинам CNI. Мы будем использовать простой CNI - Flannel. Его установка производится следующей командой:
kubectl apply -f https://github.com/coreos/flannel/raw/master/Documentation/kube-flannel.yml
Опять же, выполните kubectl get pods --all-namespaces несколько раз, чтобы убедиться, что Flannel выполняется без ошибок и RESTARTS не растут. Если что-то пошло не так, посмотрите журнал событий Flannel следующим способом (только используйте настоящее имя POD-а Flannel):
kubectl logs -n kube-system kube-flannel-ds-xn2j9
Если ошибок нет, можно двигаться дальше. Теперь вы можете подключить два других узла Control Plane с помощью команд, выполненной на каждом из них:
# ssh k8s-2
sudo kubeadm join k8s-cp:6443 --apiserver-advertise-address=10.120.28.37 --token tfqsms.kiek2vk129tpf0b7 --discovery-token-ca-cert-hash sha256:0c446bfabcd99aae7e650d110f8b9d6058cac432078c4fXXXXX6055b4bd --control-plane
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
# ssh k8s-3
sudo kubeadm join k8s-cp:6443 --apiserver-advertise-address=10.120.29.204 --token tfqsms.kiek2vk129tpf0b7 --discovery-token-ca-cert-hash sha256:0c446bfabcd99aae7e650d110f8b9d6058cac432078c4fXXXXXec6055b4bd --control-plane
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
Если вдруг --token "протух", используйте команду kubeadm token create, чтобы сгенерировать новый.
После подключения узла смотрите внимательно за состоянием Etcd:
kubectl get pods --all-namespaces | grep etcd
kube-system etcd-k8s-1 1/1 Running 0 2d23h
kube-system etcd-k8s-2 1/1 Running 1 2d22h
kube-system etcd-k8s-3 1/1 Running 1 2d22h
Состояние должно быть Running, увеличение счетчика перезагрузок не должно происходить. Команда kubectl get pods --all-namespaces должна отображать трехкратный набор процессов на всех узлах Control Plane:
NAME READY STATUS RESTARTS AGE
coredns-74ff55c5b-h2zjq 1/1 Running 0 2d23h
coredns-74ff55c5b-n6b49 1/1 Running 0 2d23h
etcd-k8s-1 1/1 Running 0 2d23h
etcd-k8s-2 1/1 Running 1 2d22h
etcd-k8s-3 1/1 Running 1 2d22h
kube-apiserver-k8s-1 1/1 Running 0 2d23h
kube-apiserver-k8s-2 1/1 Running 1 2d22h
kube-apiserver-k8s-3 1/1 Running 1 2d22h
kube-controller-manager-k8s-1 1/1 Running 1 2d23h
kube-controller-manager-k8s-2 1/1 Running 1 2d22h
kube-controller-manager-k8s-3 1/1 Running 1 2d22h
kube-flannel-ds-2f6d5 1/1 Running 0 2d3h
kube-flannel-ds-2p5vx 1/1 Running 0 2d3h
kube-flannel-ds-4ng99 1/1 Running 3 2d22h
kube-proxy-22jpt 1/1 Running 0 2d3h
kube-proxy-25rxn 1/1 Running 0 2d23h
kube-proxy-2qp8r 1/1 Running 0 2d3h
kube-scheduler-k8s-1 1/1 Running 1 2d23h
kube-scheduler-k8s-2 1/1 Running 1 2d22h
kube-scheduler-k8s-3 1/1 Running 1 2d22h
Следующим шагом настроим отказоустойчивый IP-адрес, который будет использоваться для доступа к Control Plane.
Отказоустойчивый IP и DNS имя
В моем случае было три варианта:- Keepalived;
- Pacemaker;
- kube-vip.
sudo systemctl enable corosync
sudo systemctl enable pacemaker
Я придерживаюсь такого мнения, что корневые компоненты или работают или не надо их использовать, в /etc/rc.local прописывать эти службы не хотелось.
В итоге, я познакомился со специализированным решением по предоставлению отказоустойчивого IP-адреса kube-vip, разработанным специально для Kubernetes. Для его запуска нам понадобится создать три манифеста, каждый для запуска kube-vip на одном из узлов Control Plane:
apiVersion: v1
kind: Pod
metadata:
creationTimestamp: null
name: kube-vip-cp-k8s-1 # поменять имя, соответственно узлу
namespace: kube-system
spec:
nodeName: k8s-1 # будет запускаться именно на этом узле
containers:
- args:
- start
env:
- name: vip_arp
value: "true"
- name: vip_interface
value: eth1
- name: vip_leaderelection
value: "true"
- name: vip_leaseduration
value: "5"
- name: vip_renewdeadline
value: "3"
- name: vip_retryperiod
value: "1"
- name: vip_address
value: 10.120.0.1 # указать реальный IP, который будет использоваться
image: plndr/kube-vip:0.3.1 # проверить актуальную версию
imagePullPolicy: Always
name: kube-vip-cp
resources: {}
securityContext:
capabilities:
add:
- NET_ADMIN
- SYS_TIME
volumeMounts:
- mountPath: /etc/kubernetes/admin.conf
name: kubeconfig
- mountPath: /etc/ssl/certs
name: ca-certs
readOnly: true
hostNetwork: true
volumes:
- hostPath:
path: /etc/kubernetes/admin.conf
name: kubeconfig
- hostPath:
path: /etc/ssl/certs
name: ca-certs
status: {}
Данный манифест необходимо сформировать для каждого из серверов Control Plane и применить все:
kubectl apply -f cluster_config/vip-{1,2,3}.yml
В результате вы должны получить три нормально выполняющихся POD-а, каждый на своем узле, при этом адрес 10.120.0.1 должен нормально пинговаться. Проверьте, что только один из kube-vip владеет IP с помощью arping:
sudo arping 10.120.0.1
ARPING 10.120.0.1
42 bytes from 1e:01:17:00:01:22 (10.120.0.1): index=0 time=319.476 usec
42 bytes from 1e:01:17:00:01:22 (10.120.0.1): index=1 time=306.360 msec
42 bytes from 1e:01:17:00:01:22 (10.120.0.1): index=2 time=349.666 usec
Чем хорош kube-vip? Он не только предоставляет отказоустойчивый IP, но и определяет когда сервер на хосте, где он выполняется, становится недоступен, переставая балансировать на него трафик.
Теперь, когда kube-vip предоставляет отказоустойчивый доступ к Kubernetes необходимо на хостах-рекурсорах gw-1, gw-2 в /etc/hosts.resolv обновить записи для k8s-cp:
10.120.0.1 k8s-cp
Выполните перезагрузку pdns-recursor командой sudo service pdns-recursor restart и проверьте, что k8s-cp отвечает со всех узлов IP адресом 10.120.0.1. Проверьте, что kubectl все еще корректно работает с новой записью для k8s-cp.
На данном этапе у нас есть реализация отказоустойчивого Control Plane K8S. Я рекомендую несколько раз поочередно перезагружать k8s-{1,2,3}, чтобы проверить, что кластер остается в работоспособном состоянии.
Добавление узла Worker-а
В нашей топологии предполагается использование двух узлов gw-1, gw-2, на которых будет размещен Nginx Ingress и один узел общего назначения (compute-1).Все эти узлы в кластер можно добавить следующим образом:
kubeadm token create --print-join-command
kubeadm join k8s-cp:6443 --token rn0s5p.y6waq1t6y2y6z9vw --discovery-token-ca-cert-hash sha256:0c446bfabcd99aae7e650d110f8b9d6058cac432078c4fXXXe22ec6055b4bd
# ssh gw-1
sudo kubeadm join k8s-cp:6443 --token rn0s5p.y6waq1t6y2y6z9vw --discovery-token-ca-cert-hash sha256:0c446bfabcd99aae7e650d110f8b9d6058cac432078c4fXXXe22ec6055b4bd
# ssh gw-2
...
# ssh compute-1
После добавления kubectl get pds --all-namespaces должен показать расширенный набор выполняющихся POD-ов, а kubectl get nodes должен вывести все узлы кластера:
kubectl get nodes
NAME STATUS ROLES AGE VERSION
compute-1 Ready compute 2d23h v1.20.2
gw-1 Ready gateway 2d4h v1.20.2
gw-2 Ready gateway 2d4h v1.20.2
k8s-1 Ready control-plane,master 2d23h v1.20.2
k8s-2 Ready control-plane,master 2d23h v1.20.2
k8s-3 Ready control-plane,master 2d23h v1.20.2
Теперь можно задать узлам роли, для того, чтобы иметь возможность использовать их при развертывании приложений. В листинге выше роли уже заданы, поскольку он сделан с рабочего кластера.
Назначение ролей узлам
Роль можно присвоить просто:kubectl label node gw-1 node-role.kubernetes.io/gateway=true
kubectl label node gw-2 node-role.kubernetes.io/gateway=true
kubectl label node compute-1 node-role.kubernetes.io/compute=true
# если надо удалить роль
kubectl label node compute-1 node-role.kubernetes.io/compute-
Настройка Ingress
Сейчас все готово для того, чтобы можно было выполнить развертывание Nginx Ingress на узлах gw-1, gw-2. Воспользуемся манифестом Nginx Ingress, но внесем в него ряд изменений:- запускать будем с сетью hostNetwork;
- запускать будем в виде Deployment с фактором масштабирования "2";
- запускать будем на узлах с ролью gateway.
kubectl get nodes --output wide
NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
compute-1 Ready compute 3d v1.20.2 10.120.28.172 <none> Ubuntu 18.04.5 LTS 4.15.0-135-generic containerd://1.3.3
gw-1 Ready gateway 2d4h v1.20.2 10.120.29.231 <none> Ubuntu 18.04.5 LTS 4.15.0-135-generic containerd://1.3.3
gw-2 Ready gateway 2d4h v1.20.2 10.120.28.23 <none> Ubuntu 18.04.5 LTS 4.15.0-135-generic containerd://1.3.3
k8s-1 Ready control-plane,master 3d v1.20.2 10.120.29.187 <none> Ubuntu 18.04.5 LTS 4.15.0-135-generic containerd://1.3.3
k8s-2 Ready control-plane,master 2d23h v1.20.2 10.120.28.37 <none> Ubuntu 18.04.5 LTS 4.15.0-135-generic containerd://1.3.3
k8s-3 Ready control-plane,master 2d23h v1.20.2 10.120.29.204 <none> Ubuntu 18.04.5 LTS 4.15.0-135-generic containerd://1.3.3
Собственно, назначить этот External IP можно только через API, при этом он сбрасывается самим Kubernetes время от времени и требует постоянной установки. В общем, это неудобно и использоваться нормально не может.
Я читал длинную переписку на GitHub, которая закончилась ничем вразумительным, еще советуют использовать metallb, который тоже непонятно в каком состоянии. Как итог, я решил просто завести Nginx Ingress, используя hostNetworking, поскольку это обеспечивает привязку данного Ingress с адресам 0.0.0.0:443, 0.0.0.0:80 и решает мою задачу.
Собственно, манифест для запуска Nginx Ingress выглядит так:
Очень большой фрагмент YAML
Запустив его с помощью kubectl apply -f nginx-ingress.yaml, мы получим два POD-а Nginx, выполняющихся на узлах gw-1, gw-2 и слушающих 443-й и 80-й порты:
kubectl get pods --all-namespaces | grep nginx
ingress-nginx ingress-nginx-admission-create-4mm9m 0/1 Completed 0 46h
ingress-nginx ingress-nginx-admission-patch-7jkwg 0/1 Completed 2 46h
ingress-nginx ingress-nginx-controller-b966cf6cd-7kpzm 1/1 Running 1 46h
ingress-nginx ingress-nginx-controller-b966cf6cd-ckl97 1/1 Running 0 46h
На узлах gw-1, gw-2:
sudo netstat -tnlp | grep -E '
443|80)'tcp 0 0 0.0.0.0:443 0.0.0.0:* LISTEN 2661/nginx: master
tcp 0 0 0.0.0.0:443 0.0.0.0:* LISTEN 2661/nginx: master
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 2661/nginx: master
tcp 0 0 0.0.0.0:80 0.0.0.0:* LISTEN 2661/nginx: master
tcp6 0 0 :::443 :::* LISTEN 2661/nginx: master
tcp6 0 0 :::443 :::* LISTEN 2661/nginx: master
tcp6 0 0 :::80 :::* LISTEN 2661/nginx: master
tcp6 0 0 :::80 :::* LISTEN 2661/nginx: master
Можно постучаться на публичные адреса gw-1, gw-2 по 80-му порту и получить приветственную страницу Nginx. Далее, Вы можете использовать публичные адреса gw-1, gw-2 для создания записей DNS, использования в CDN и т.п.
Протестировать работу inress можно, создав сервис, на который Ingress будет проксировать трафик (взято отсюда) - echo1.yaml:
apiVersion: v1
kind: Service
metadata:
name: echo1
spec:
ports:
- port: 80
targetPort: 5678
selector:
app: echo1
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: echo1
spec:
selector:
matchLabels:
app: echo1
replicas: 2
template:
metadata:
labels:
app: echo1
spec:
containers:
- name: echo1
image: hashicorp/http-echo
args:
- "-text=echo1"
ports:
- containerPort: 5678
Выполните данный манифест с помощью kubectl apply -f echo1.yaml. Теперь создадим правило Ingress (ingress-echo1.yaml):
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: echo-ingress
spec:
rules:
- host: echo1.example.com
http:
paths:
- backend:
serviceName: echo1
servicePort: 80
Выполним данный манифест kubectl apply -f ingress-echo1.yaml. Теперь, если на локальном компьютере в /etchosts внести запись для echo1.example.com:
127.0.0.1 localhost
127.0.1.1 manager
# The following lines are desirable for IPv6 capable hosts
::1 localhost ip6-localhost ip6-loopback
ff02::1 ip6-allnodes
ff02::2 ip6-allrouters
X.Y.Z.C echo1.example.com
То можно получить проксирование трафика через Nginx Ingress. Проверим с помощью curl:
curl echo1.example.com
echo1
Установка K8S Dashboard
Для установки Dashboard необходимо выполнить следующую команду:kubectl apply -f https://raw.githubusercontent.com/kubernetes/dashboard/v2.0.0/aio/deploy/recommended.yaml
Dashboard имеет ряд ограничений, например, он не работает через http, если обращение осуществляется не с localhost. В целом, не рекомендуется как-либо предоставлять доступ к Dashboard извне кластера через Ingress. Кроме того, Dashboard использует встроенную систему RBAC Kubernetes, поэтому требуется создать пользователя и дать ему права на Dashboard.
Инструкция взята с этой страницы. Создадим аккаунт:
cat <<EOF | kubectl apply -f -
apiVersion: v1
kind: ServiceAccount
metadata:
name: admin-user
namespace: kubernetes-dashboard
EOF
Определим роль пользователя:
cat <<EOF | kubectl apply -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: admin-user
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cluster-admin
subjects:
- kind: ServiceAccount
name: admin-user
namespace: kubernetes-dashboard
EOF
Получим токен, с помощью которого пользователь сможет войти в Dashboard:
kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}"
Если на вашей машине уже настроен kubect и есть $HOME/.kube/config, а сама машина "видит" k8s-cp, то вы можете запустить kubectl proxy и получить доступ к Dashboard по ссылке: http://localhost:8001/api/v1/namesp...d/services/https:kubernetes-dashboard:/proxy/.
Если же ваша машина с браузером находится вне кластера, то переходим к следующему шагу, где мы настроим проброс API Kubernetes наружу через HAProxy.
Доступ к API K8S из внешней сети
На узлах gw-1, gw-2 необходимо установить haproxy. После установки измените конфигурационный файл /etc/haproxy/haproxy.cfg так, чтобы далее секции defaults он выглядел следующим образом:defaults
# mode is inherited by sections that follow
mode tcp
frontend k8s
# receives traffic from clients
bind :6443
default_backend kubernetes
backend kubernetes
# relays the client messages to servers
server k8s k8s-cp:6443
Теперь вы можете обратиться к API K8S извне, указав в /etc/hosts своей локальной машины адрес gw-1 или gw-2 в качестве k8s-cp. Вам должны быть доступны с локальной машины все команды kubectl, включая kubectl proxy:
kubectl proxy
Starting to serve on 127.0.0.1:8001
После этого можно открыть в браузере http://localhost:8001/api/v1/namesp...d/services/https:kubernetes-dashboard:/proxy/ и насладиться видом приглашения авторизации Dashboard K8S:
Вводим токен для ранее созданного пользователя Dasboard, полученный с помощью:
kubectl -n kubernetes-dashboard get secret $(kubectl -n kubernetes-dashboard get sa/admin-user -o jsonpath="{.secrets[0].name}") -o go-template="{{.data.token | base64decode}}"
eyJhbGciOiJSUzI1NiIsImtpZCI6IlFkcGxwMTN2YlpyNS1TOTYtUnVYdsfadfsdjfksdlfjm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlcm5ldGVzLWRhc2hib2FyZCIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJhZG1pbi11c2VyLXRva2VuLWd6anprIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQubmFtZSI6ImFkbWluLXVzZXIiLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC51aWQiOiJjM2RiOWFkMS0yYjdmLTQ3YTYtOTM3My1hZWI2ZjJkZjk0NTAiLCJzdWIiOiJzeXN0ZW06c2VydmljZWFjY291bnQ6a3ViZXJuZXRlcy1kYXNoYm9hcmQ6YWRtaW4tdXNlciJ9.ht-RyqLXY4UzBnxIzJcnQn8Kk2iHWZzKVeAjUhKkJ-vOAtyqBu50rExgiRWsEHWfJp1p9xN8sXFKg62FFFbHWftPf6PmwfcBK2lXPy6OL9OaooP17WJVn75KKXIZHPWLO9VmRXPB1S-v2xFuG_J8jHB8pZHJlFjp4zIXfB--QwhrxeoTt5zv3CfXCl1_VYgCoqaxRsa7e892-vtMijBo7EZfJiyuAUQr_TsAIDY3zOWFJeHbwPFWzL_1fF9Y2o3r0pw7hYZHUoI8Z-3hbfOi10QBRyQlNZTMFSh7Z38RRbV1tw2ZmMvgSQyHa9TZFy2kYik6VnugNB2cilamo_b7hg
и переходим на главный экран Dashboard:
Вместо заключения
Как я писал в начале статьи, у меня уже есть опыт развертывания систем управления контейнерами на базе Docker, Apache Mesos (DC/OS). Тем не менее, документация Kubernetes мне показалась сложной, запутанной и фрагментарной. Чтобы получить текущий результат я прошерстил довольном много сторонних руководств, Issue GitHub и, конечно, документацию Kubernetes. Надеюсь, что данное руководство поможет вам сэкономить свое время.Источник статьи: https://habr.com/ru/post/540220/