Группа исследователей из Виргинского и Калифронийского университетов представила новый вид атаки на микроархитектурные структуры процессоров Intel и AMD, выявленный в ходе обратного инжиниринга недокументированных возможностей CPU. Предложенный метод атаки связан с применением в процессорах промежуточного кэша микроопераций (micro-op cache), который может использоваться для извлечения сведений, освевших в ходе спекулятивного выполнения инструкций.
В целях оптимизации процессор начинает выполнять некоторые инструкции в спекулятивном режиме, не дожидаясь выполнения предыдущих вычислений, и если потом определяет, что предсказание не оправдалось, откатывает операцию в исходное состояние, но обработанные в процессе спекулятивного выполнения данные оседают в кэше, содержимое которого можно определить.
Отмечается, что новый метод заметно опережает по производительности атаку Spectre v1, затрудняет обнаружение атаки и не блокируется существующими методами защиты от атак по сторонним каналам, разработанным для блокирования уязвимостей, вызванных спекулятивным выполнением инструкций (например, применение инструкции LFENCE блокирует утечку на последних стадиях спекулятивного выполнения, но не защищает от утечки через микроархитектерные структуры).
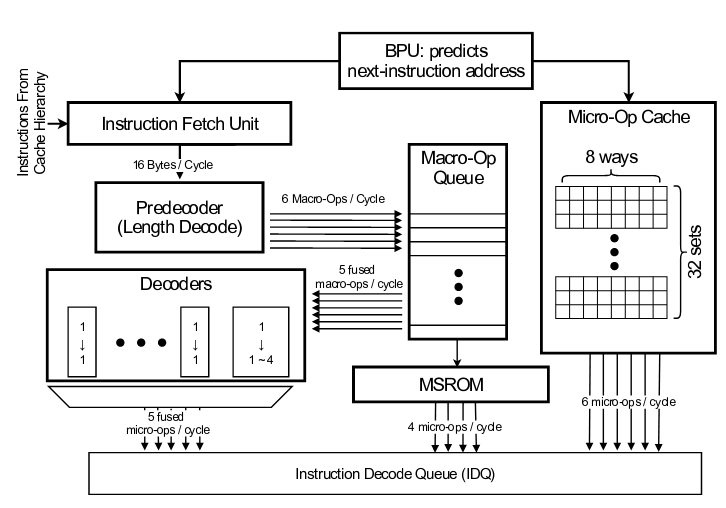
Метод затрагивает модели процессоров Intel и AMD, выпускаемые с 2011 года, включая серии Intel Skylake и AMD Zen. Современные CPU разбивают сложные процессорные инструкции на более простые RISC-подобные микрооперации, которые кэшируются в отдельном кэше. Данный кеш кардинально отличается от кэшей более высокого уровня, недоступен напрямую и выступает в роли потокового буфера для быстрого доступа к результатам декодирования CISC-инструкций в RISC-микроинструкции. Тем не менее, исследователи нашли способ для создания условий, возникающих при конфликте доступа к кэшу и позволяющих судить о содержимом кэша микроопераций путём анализа отличий во времени выполнения тех или иных действий.
Кэш микроопераций в процессорах Intel сегментирован в привязке к потокам CPU (Hyper-Threading), в то время как в процессорах AMD Zen применяется общий кэш, что создаёт условия для утечки данных не только в рамках одного потока выполнения, но и между разными потоками в SMT (возможна утечка данных между кодом, выполняемым на разных логических ядрах CPU).
При организации варианта атаки Spectre с использованием кэша микроопераций исследователям удалось добиться производительности в 965.59 Kbps при уровне ошибок 0.22% и 785.56 Kbps при использовании коррекции ошибок при организации утечки в рамках одного адресного пространства и уровня привилегий. При утечке, охватывающей разные уровни привилегий (между ядром и пространством пользователя), производительность составила 85.2 Kbps при добавлении коррекции ошибок и 110.96 Kbps при уровне ошибок в 4%. При атаке на процессоры AMD Zen, создающей утечку между разными логическими ядрами CPU, производительность составила 250 Kbps при уровне ошибок 5.59% и 168.58 Kbps при коррекции ошибок. По сравнению с классическим методом Spectre v1 новая атака оказалась быстрее в 2.6 раза.
Предполагается, что для защиты от атаки на кэш микроопераций потребуется внесение изменений, снижающих производительность сильнее, чем при включении защиты от атак Spectre. В качестве оптимального компромисса предлагается блокировать подобные атаки не путём отключения кэширования, а на уровне мониторинга аномалий и определения состояний кэша, типичных для атак.
Исследователями предложен базовый метод для определения изменений в кэше микроопераций и несколько сценариев атак, позволяющих создавать скрытые каналы передачи данных и использовать уязвимый код для организации утечки конфиденциальных данных, как в рамках одного процесса (например, для организации утечки данных процесса при выполнении стороннего кода в движках с JIT и в виртуальных машинах), так и между ядром и процессами в пространстве пользователя.
Как и в атаках Spectre для организации утечки из ядра или других процессов требуется выполнение на стороне процессов-жертв определённой последовательности команд (гаджетов), приводящей к спекулятивному выполнению инструкций. В ядре Linux найдено около 100 подобных гаджетов, которые будут удалены, но периодически находят обходные методы для их генерации, например, связанные с запуском в ядре специально оформленных BPF-программ.
Источник статьи: https://www.opennet.ru/opennews/art.shtml?num=55066
В целях оптимизации процессор начинает выполнять некоторые инструкции в спекулятивном режиме, не дожидаясь выполнения предыдущих вычислений, и если потом определяет, что предсказание не оправдалось, откатывает операцию в исходное состояние, но обработанные в процессе спекулятивного выполнения данные оседают в кэше, содержимое которого можно определить.
Отмечается, что новый метод заметно опережает по производительности атаку Spectre v1, затрудняет обнаружение атаки и не блокируется существующими методами защиты от атак по сторонним каналам, разработанным для блокирования уязвимостей, вызванных спекулятивным выполнением инструкций (например, применение инструкции LFENCE блокирует утечку на последних стадиях спекулятивного выполнения, но не защищает от утечки через микроархитектерные структуры).
Метод затрагивает модели процессоров Intel и AMD, выпускаемые с 2011 года, включая серии Intel Skylake и AMD Zen. Современные CPU разбивают сложные процессорные инструкции на более простые RISC-подобные микрооперации, которые кэшируются в отдельном кэше. Данный кеш кардинально отличается от кэшей более высокого уровня, недоступен напрямую и выступает в роли потокового буфера для быстрого доступа к результатам декодирования CISC-инструкций в RISC-микроинструкции. Тем не менее, исследователи нашли способ для создания условий, возникающих при конфликте доступа к кэшу и позволяющих судить о содержимом кэша микроопераций путём анализа отличий во времени выполнения тех или иных действий.
Кэш микроопераций в процессорах Intel сегментирован в привязке к потокам CPU (Hyper-Threading), в то время как в процессорах AMD Zen применяется общий кэш, что создаёт условия для утечки данных не только в рамках одного потока выполнения, но и между разными потоками в SMT (возможна утечка данных между кодом, выполняемым на разных логических ядрах CPU).
При организации варианта атаки Spectre с использованием кэша микроопераций исследователям удалось добиться производительности в 965.59 Kbps при уровне ошибок 0.22% и 785.56 Kbps при использовании коррекции ошибок при организации утечки в рамках одного адресного пространства и уровня привилегий. При утечке, охватывающей разные уровни привилегий (между ядром и пространством пользователя), производительность составила 85.2 Kbps при добавлении коррекции ошибок и 110.96 Kbps при уровне ошибок в 4%. При атаке на процессоры AMD Zen, создающей утечку между разными логическими ядрами CPU, производительность составила 250 Kbps при уровне ошибок 5.59% и 168.58 Kbps при коррекции ошибок. По сравнению с классическим методом Spectre v1 новая атака оказалась быстрее в 2.6 раза.
Предполагается, что для защиты от атаки на кэш микроопераций потребуется внесение изменений, снижающих производительность сильнее, чем при включении защиты от атак Spectre. В качестве оптимального компромисса предлагается блокировать подобные атаки не путём отключения кэширования, а на уровне мониторинга аномалий и определения состояний кэша, типичных для атак.
Исследователями предложен базовый метод для определения изменений в кэше микроопераций и несколько сценариев атак, позволяющих создавать скрытые каналы передачи данных и использовать уязвимый код для организации утечки конфиденциальных данных, как в рамках одного процесса (например, для организации утечки данных процесса при выполнении стороннего кода в движках с JIT и в виртуальных машинах), так и между ядром и процессами в пространстве пользователя.
Как и в атаках Spectre для организации утечки из ядра или других процессов требуется выполнение на стороне процессов-жертв определённой последовательности команд (гаджетов), приводящей к спекулятивному выполнению инструкций. В ядре Linux найдено около 100 подобных гаджетов, которые будут удалены, но периодически находят обходные методы для их генерации, например, связанные с запуском в ядре специально оформленных BPF-программ.
Источник статьи: https://www.opennet.ru/opennews/art.shtml?num=55066