Рассказ пойдет об одной новой, общедоступной Java/Kotlin библиотеке, для работы с русским языком. Она позволяет получить исходные формы + морфологическую информацию для большинства слов русского языка. Статья предназначена для тех, кто создает ботов, обрабатывает сообщения, занимается поиском и извлечением смысла текста. Для справки, ключевое отличие лемматизации от стеммизации (урезания до нормализованной формы) состоит в том, что лемма удовлятворяет правилам языка, например для слова "яблоками" леммой будет "яблоко", а не просто урезанный корень.
Лемма может быть и более сложной, например для слова люди, начальная форма – человек. В этой статье мы рассмотрим способ быстрого извлечения такой информации из морфологического словаря.
// в build.gradle.kts
repositories {
// (1) Подключим репозиторий jitpack
maven("https://jitpack.io")
}
dependencies {
// (2) Добавим зависимость от библиотеки
implementation("com.github.demidko:aot:2021.09.19")
}
import static java.lang.System.out;
import static com.github.demidko.aot.WordformMeaning.lookupForMeanings;
class Example {
public static void main(String[] args) {
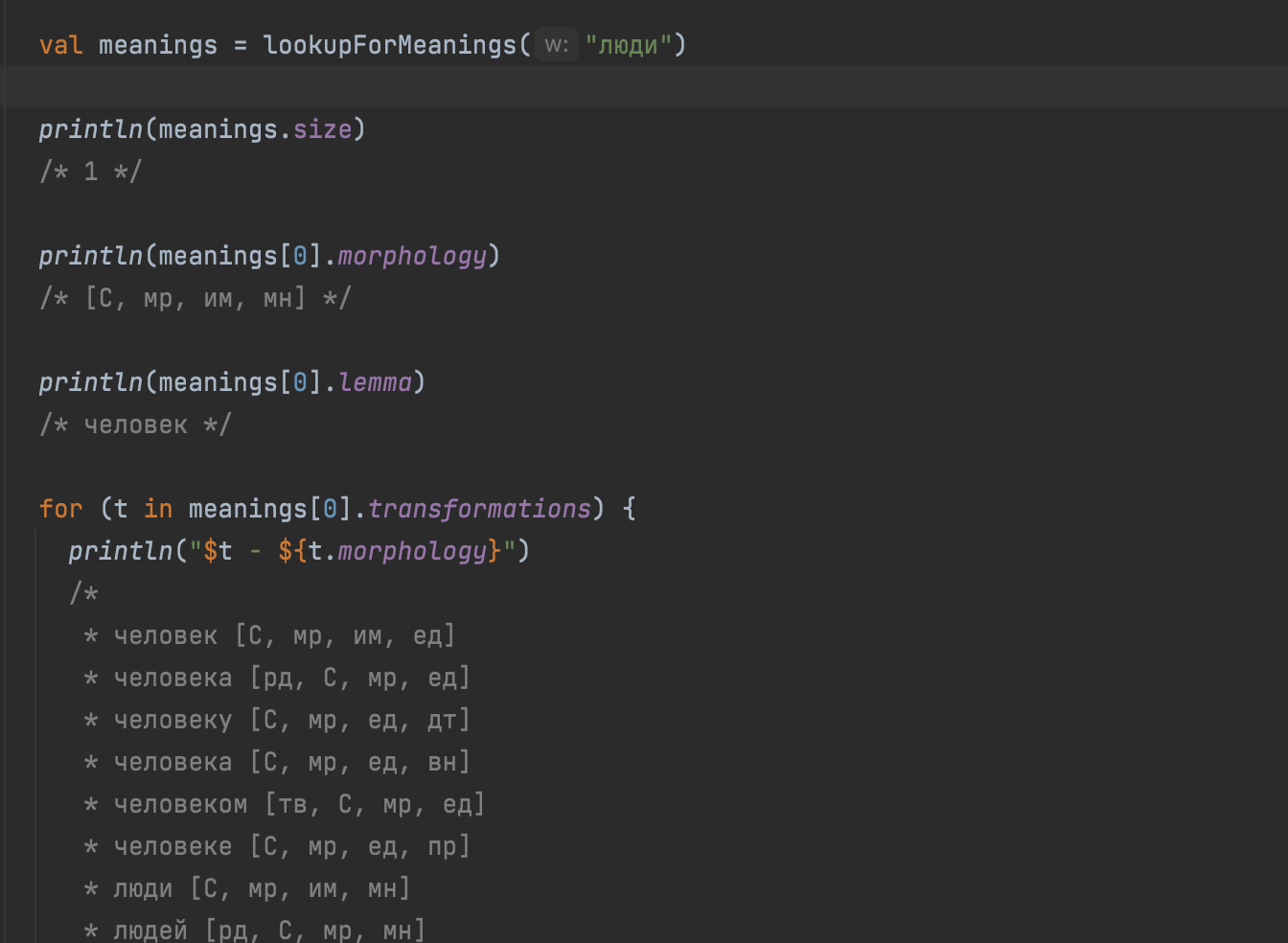
var meanings = lookupForMeanings("люди");
out.println(meanings.size());
/* 1 */
out.println(meanings.get(0).getMorphology());
/* [С, мр, им, мн] */
out.println(meanings.get(0).getLemma());
/* человек */
for (var t : meanings.get(0).getTransformations()) {
out.println(t.toString() + " " + t.getMorphology());
/*
* человек [С, мр, им, ед]
* человека [рд, С, мр, ед]
* человеку [С, мр, ед, дт]
* человека [С, мр, ед, вн]
* человеком [тв, С, мр, ед]
* человеке [С, мр, ед, пр]
* люди [С, мр, им, мн]
* людей [рд, С, мр, мн]
* человек [рд, С, мр, мн]
* людям [С, мр, мн, дт]
* человекам [С, мр, мн, дт]
* людей [С, мр, мн, вн]
* людьми [тв, С, мр, мн]
* человеками [тв, С, мр, мн]
* людях [С, мр, мн, пр]
* человеках [С, мр, мн, пр]
*/
}
}
}
Как видно, для каждого слова легко получить набор словоформ различных смыслов, после чего можно получать морфологическую информацию (род, падеж, склонение и т. п). Здесь может возникнуть вопрос, почему метод lookupForMeanings("...") возвращает набор словоформ, а не одну? Это сделано по причине наличия в русском языке коллизий словоформ разных смыслов, например "замок" это одновременно производная леммы "замокнуть" (под дождем например) и устройство для запирания дверей и строение. Так как одно и тоже слово является производной разных лемм, библиотека вернет список подходящих различных словоформ с разными морфологическими характеристиками.
_массив наборов морфологий_
морфология 1 # напр. [рд, С, мр, ед]
морфология 2 # напр. [С, мр, ед, дт]
...
морфология N # напр. [рд, С, мр, мн]
_массив всех строк_
строка 1 # напр. яблоками
строка 2 # напр. яблоко
...
строка N # напр. груша
_массив всех лемм с индексами преобразований в массиве строк и морфологий_
(индекс строки, индекс морфологии) (индекс строки, индекс морфологии)... (индекс строки, индекс морфологии) (индекс строки, индекс морфологии)
(индекс строки, индекс морфологии) (индекс строки, индекс морфологии)... (индекс строки, индекс морфологии) (индекс строки, индекс морфологии)
...
(индекс строки, индекс морфологии) (индекс строки, индекс морфологии)... (индекс строки, индекс морфологии) (индекс строки, индекс морфологии)
_словарь хешей (коллизии проверяются в рантайме, нет смысла отделяеть их во время компиляции, т. к. могут быть и внешние коллизии)_
хеш, индекс леммы, индекс леммы
хеш, индекс леммы, индекс леммы, индекс леммы
хеш, индекс леммы, индекс леммы, индекс леммы, индекс леммы
...
хеш, индекс леммы, индекс леммы, индекс леммы
(напр. хеш яблоки, индекс леммы яблоко)
После получения слова в методе lookupForMeanings("...") нам остается только нормализовать слово в lower case, прогнать через словарь хешей, считать все преобразования, и избавиться от коллизий хеша (если они есть).
https://github.com/demidko/aot
 habr.com
habr.com
Лемма может быть и более сложной, например для слова люди, начальная форма – человек. В этой статье мы рассмотрим способ быстрого извлечения такой информации из морфологического словаря.
Источник данных
В первую очередь, стоит выразить благодарность проекту AOT (автоматическая обработка текста) за морфологические словари русского языка. Библиотека содержит их с обновлениями бинарного формата и API, упрощенным подключением в Gradle и Maven проекты без сторонних зависимостей и быстрым (!) поиском.Преобразование данных
Так как оригинальные aot-словари в исходном текстовом виде достаточно неудобны для быстрого поиска, то они предварительно преобразуются в собственный бинарный формат (GitHub) при помощи компилятора написанного на Kotlin. Такое преобразование позволяет очень быстро загрузить словарь в память и осуществлять мгновенный поиск по нему. Конкретные бенчмарки загрузки словаря из бинарного формата будут отличаться для каждой машины, однако в среднем запуск при инициализации занимает около четырех секунд, после чего получение морфологии для любого слова работает также быстро как HashMap.Подключение библиотеки
Библиотека совместима с Java 8+, а также протестирована со всеми версиями Kotlin 1.5.*. В этом примере используется система сборки Gradle, примеры для Maven и других систем сборки столь же тривиальны и их можно посмотреть здесь.// в build.gradle.kts
repositories {
// (1) Подключим репозиторий jitpack
maven("https://jitpack.io")
}
dependencies {
// (2) Добавим зависимость от библиотеки
implementation("com.github.demidko:aot:2021.09.19")
}
Пример работы
Пример работы приводится для Java, однако библиотека также будет работать и с Kotlin:import static java.lang.System.out;
import static com.github.demidko.aot.WordformMeaning.lookupForMeanings;
class Example {
public static void main(String[] args) {
var meanings = lookupForMeanings("люди");
out.println(meanings.size());
/* 1 */
out.println(meanings.get(0).getMorphology());
/* [С, мр, им, мн] */
out.println(meanings.get(0).getLemma());
/* человек */
for (var t : meanings.get(0).getTransformations()) {
out.println(t.toString() + " " + t.getMorphology());
/*
* человек [С, мр, им, ед]
* человека [рд, С, мр, ед]
* человеку [С, мр, ед, дт]
* человека [С, мр, ед, вн]
* человеком [тв, С, мр, ед]
* человеке [С, мр, ед, пр]
* люди [С, мр, им, мн]
* людей [рд, С, мр, мн]
* человек [рд, С, мр, мн]
* людям [С, мр, мн, дт]
* человекам [С, мр, мн, дт]
* людей [С, мр, мн, вн]
* людьми [тв, С, мр, мн]
* человеками [тв, С, мр, мн]
* людях [С, мр, мн, пр]
* человеках [С, мр, мн, пр]
*/
}
}
}
Как видно, для каждого слова легко получить набор словоформ различных смыслов, после чего можно получать морфологическую информацию (род, падеж, склонение и т. п). Здесь может возникнуть вопрос, почему метод lookupForMeanings("...") возвращает набор словоформ, а не одну? Это сделано по причине наличия в русском языке коллизий словоформ разных смыслов, например "замок" это одновременно производная леммы "замокнуть" (под дождем например) и устройство для запирания дверей и строение. Так как одно и тоже слово является производной разных лемм, библиотека вернет список подходящих различных словоформ с разными морфологическими характеристиками.
Как это вообще работает?
Библиотека загружает из бинарного словаря особую структуру, HashDictionary (низкоуровневое API), которая после загрузки состоит из:_массив наборов морфологий_
морфология 1 # напр. [рд, С, мр, ед]
морфология 2 # напр. [С, мр, ед, дт]
...
морфология N # напр. [рд, С, мр, мн]
_массив всех строк_
строка 1 # напр. яблоками
строка 2 # напр. яблоко
...
строка N # напр. груша
_массив всех лемм с индексами преобразований в массиве строк и морфологий_
(индекс строки, индекс морфологии) (индекс строки, индекс морфологии)... (индекс строки, индекс морфологии) (индекс строки, индекс морфологии)
(индекс строки, индекс морфологии) (индекс строки, индекс морфологии)... (индекс строки, индекс морфологии) (индекс строки, индекс морфологии)
...
(индекс строки, индекс морфологии) (индекс строки, индекс морфологии)... (индекс строки, индекс морфологии) (индекс строки, индекс морфологии)
_словарь хешей (коллизии проверяются в рантайме, нет смысла отделяеть их во время компиляции, т. к. могут быть и внешние коллизии)_
хеш, индекс леммы, индекс леммы
хеш, индекс леммы, индекс леммы, индекс леммы
хеш, индекс леммы, индекс леммы, индекс леммы, индекс леммы
...
хеш, индекс леммы, индекс леммы, индекс леммы
(напр. хеш яблоки, индекс леммы яблоко)
После получения слова в методе lookupForMeanings("...") нам остается только нормализовать слово в lower case, прогнать через словарь хешей, считать все преобразования, и избавиться от коллизий хеша (если они есть).
Исходный код
Отправить issue или поставить звездочку можно здесь:https://github.com/demidko/aot
Обработка русского языка на Java
Рассказ пойдет об одной новой, общедоступной Java/Kotlin библиотеке, для работы с русским языком. Она позволяет получить исходные формы + морфологическую информацию для большинства слов русского...
habr.com