Очень неприятная ситуация для DBA: «что-то происходит с СУБД, но что именно — нет информации». Первый и иногда достаточный способ избежать неопределенности — всегда иметь полную информацию о нештатных ситуациях в работе СУБД на текущий период и в истории. Для решения этой в общем то стандартной задачи и нужно мониторить и анализировать лог СУБД. PostgreSQL в данном случае не исключение.
К рассмотрению предлагается один из способов мониторинга ошибок СУБД PostgreSQL и получением итоговой информации, используя Zabbix. Данная статья не tutorial и не roadmap, скорее как эскиз для обмена мнениями с коллегами.
Способ мониторинга СУБД очень простой — постоянный парсинг лога СУБД и оповещение о появлении ошибки.
В основе сервисного скрипта, который выполняется по cron положена очень простая конструкция:
cat $log_file | grep -E 'FATAL|ВАЖНО|PANIC|ПАНИКА|ERROR|ОШИБКА'
Данную конструкцию можно выполнять используя возможности агента Zabbix, но в этом случае есть несколько моментов:
Поэтому используется несколько другой способ — агент Zabbix не выполняет парсинг лога СУБД, а всего лишь считывает значение метрики из файлов, которые формируются простым скриптом bash по расписанию cron:
# ERROR | ОШИБКА
cat $log_file | grep -E 'ERROR|ОШИБКА' | wc -l > /tmp/error.count
# FATAL | ВАЖНО
cat $log_file | grep -E 'FATAL|ВАЖНО' | wc -l > /tmp/fatal.count
# PANIC | ПАНИКА
cat $log_file | grep -E 'PANIC|ПАНИКА' | wc -l > /tmp/panic.count
В результате — не нужны никакие дополнительных настроек для работы агента Zabbix, да и накладные расходы на получение данных — минимальны.
Для более углубленного анализа, для некоторых кодов ошибок можно и нужно сформировать отдельные файлы:
#Класс 53 — Нехватка ресурсов
cat $log_file | grep -E 'FATAL|ВАЖНО|PANIC|ПАНИКА|ERROR|ОШИБКА' | grep -E ' 53000\|| 53100\|| 53200\|| 53400\|| 53500\|' | wc -l > /tmp/error53.count
# Класс 58 — Ошибка системы (ошибка, внешняя по отношению к PostgreSQL)
cat $log_file | grep -E 'FATAL|ВАЖНО|PANIC|ПАНИКА|ERROR|ОШИБКА' | grep -E ' 58000\|| 58030\|| 58P01\|| 58P02\|' | wc -l > /tmp/error58.count
# Класс<h3></h3> XX — Внутренняя ошибка
cat $log_file | grep -E 'FATAL|ВАЖНО|PANIC|ПАНИКА|ERROR|ОШИБКА' | grep -E ' XX000\|| XX001\|| XX002\|' | wc -l > /tmp/errorXX.count
Для оперативного реагирования на ошибки — можно и нужно настроить стандартное оповещение Zabbix:
Problem started at HH:MI:SS on YYYY.DD.MM
Problem name: ERRORXX
Host: ХХХ
...
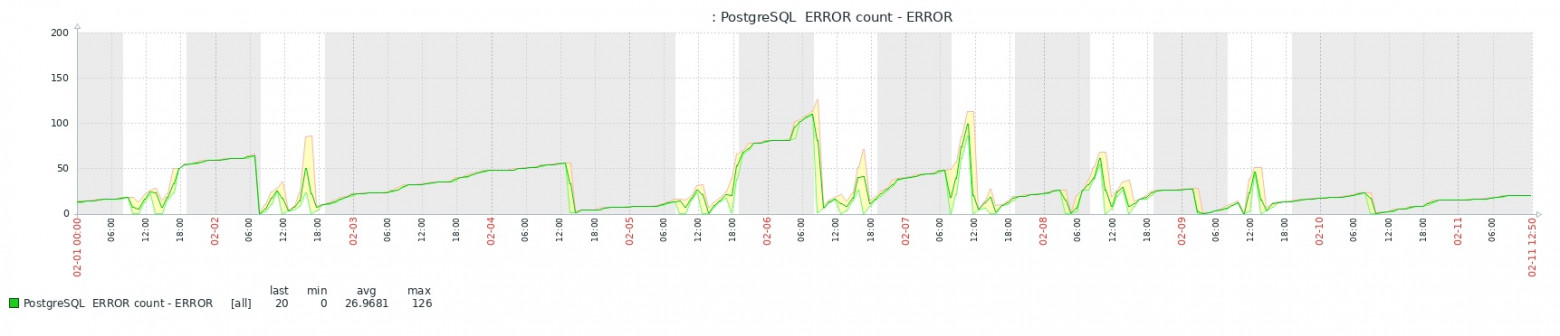
В результате добавления метрик Zabbix получается вполне доступная для оперативного и исторического анализа картина:


Развитием идея является парсинг и анализ части(или всего) лога СУБД для получения сводного отчета по кодам ошибок:
Класс 25 — Неверное состояние транзакции:48
Класс 42 — Ошибка синтаксиса или нарушение правила доступа:453
Класс 57 — Вмешательство оператора:186
...

 habr.com
habr.com
К рассмотрению предлагается один из способов мониторинга ошибок СУБД PostgreSQL и получением итоговой информации, используя Zabbix. Данная статья не tutorial и не roadmap, скорее как эскиз для обмена мнениями с коллегами.
Мониторинг ошибок СУБД
Способ мониторинга СУБД очень простой — постоянный парсинг лога СУБД и оповещение о появлении ошибки.
В основе сервисного скрипта, который выполняется по cron положена очень простая конструкция:
cat $log_file | grep -E 'FATAL|ВАЖНО|PANIC|ПАНИКА|ERROR|ОШИБКА'
Данную конструкцию можно выполнять используя возможности агента Zabbix, но в этом случае есть несколько моментов:
- Агент Zabbix должен иметь доступ на чтение к папке лога СУБД
- Агент Zabbix имеет ограничения по timeout и в случае повышенной нагрузки на сервер и аварийной ситуации с инфраструктурой могут быть пробелы в мониторинга. А как раз в таких сценариях мониторинг ошибок особенно важен.
Поэтому используется несколько другой способ — агент Zabbix не выполняет парсинг лога СУБД, а всего лишь считывает значение метрики из файлов, которые формируются простым скриптом bash по расписанию cron:
# ERROR | ОШИБКА
cat $log_file | grep -E 'ERROR|ОШИБКА' | wc -l > /tmp/error.count
# FATAL | ВАЖНО
cat $log_file | grep -E 'FATAL|ВАЖНО' | wc -l > /tmp/fatal.count
# PANIC | ПАНИКА
cat $log_file | grep -E 'PANIC|ПАНИКА' | wc -l > /tmp/panic.count
В результате — не нужны никакие дополнительных настроек для работы агента Zabbix, да и накладные расходы на получение данных — минимальны.
Для более углубленного анализа, для некоторых кодов ошибок можно и нужно сформировать отдельные файлы:
#Класс 53 — Нехватка ресурсов
cat $log_file | grep -E 'FATAL|ВАЖНО|PANIC|ПАНИКА|ERROR|ОШИБКА' | grep -E ' 53000\|| 53100\|| 53200\|| 53400\|| 53500\|' | wc -l > /tmp/error53.count
# Класс 58 — Ошибка системы (ошибка, внешняя по отношению к PostgreSQL)
cat $log_file | grep -E 'FATAL|ВАЖНО|PANIC|ПАНИКА|ERROR|ОШИБКА' | grep -E ' 58000\|| 58030\|| 58P01\|| 58P02\|' | wc -l > /tmp/error58.count
# Класс<h3></h3> XX — Внутренняя ошибка
cat $log_file | grep -E 'FATAL|ВАЖНО|PANIC|ПАНИКА|ERROR|ОШИБКА' | grep -E ' XX000\|| XX001\|| XX002\|' | wc -l > /tmp/errorXX.count
Для оперативного реагирования на ошибки — можно и нужно настроить стандартное оповещение Zabbix:
Problem started at HH:MI:SS on YYYY.DD.MM
Problem name: ERRORXX
Host: ХХХ
...
Метрики Zabbix
В результате добавления метрик Zabbix получается вполне доступная для оперативного и исторического анализа картина:
Итог
Развитием идея является парсинг и анализ части(или всего) лога СУБД для получения сводного отчета по кодам ошибок:
Класс 25 — Неверное состояние транзакции:48
Класс 42 — Ошибка синтаксиса или нарушение правила доступа:453
Класс 57 — Вмешательство оператора:186
...
Один из методов мониторинга и анализа ошибок СУБД
Очень неприятная ситуация для DBA: «что-то происходит с СУБД, но что именно — нет информации». Первый и иногда достаточный способ избежать неопределенности — всегда иметь полную информацию о нештатных...
habr.com