1. Актуальность
На современных заводах, а часто и на достаточно больших поездах и пароходах активно используются сети передачи данных. При этом во многих случаях передаваемая информация достаточно критична для того, чтобы задуматься о её защите. Для этого применяются средства обеспечения сетевой безопасности. А для применения таких средств надо как минимум знать, что за узлы представлены в защищаемой сети, по каким адресам они расположены и как взаимодействуют со своими соседями.И в этой статье предлагается один из методов определения типа сетевых узлов с помощью новомодных методов машинного обучения.
Казалось бы – для удалённого определения типа узла придумано множество инструментов, и один из самых известных – Nmap. Зачем нужно изобретать велосипед? Но дело в том, что популярные инструменты используют активное сканирование, которое не всегда допустимо в промышленных сетях. Излишне надоедливый сканер, опрашивающий сетевой узел исключительно из добрых побуждений, может стать причиной сбоя в ПЛК, для которого каждый лишний сетевой пакет - повод надолго задуматься или уйти в перезагрузку.
Кроме того, существующие инструменты предполагают ограниченный набор классов, на которые разделяются узлы исследуемой сети, и использование предопределённых правил, а значит любой объект, который в правилах не описан, останется нераспознанным. Описываемый метод лишён этого недостатка. Ну и в качестве приятного бонуса – с его помощью можно не только проводить инвентаризацию, но и с той или иной точностью выявлять аномалии в информационном взаимодействии сетевых узлов.
В случае невозможности использования инструментов, предполагающих активное сканирование, описание всех сетевых узлов (а как иначе? – нужно ведь знать, что защищаем) требует длительного ручного труда. Для автоматизации этой операции предлагается использовать метод определения класса узла по сформированному профилю его сетевого трафика, не требующий взаимодействия с сетью и сохраняющий целостность защищаемой системы.
2. Идея
Идея метода похожа на идеологию IDS: слушаем весь трафик и запоминаем. Весь трафик делим на потоки – соединения между узлами с уникальными адресами по уникальному набору сетевых протоколов разных уровней. Затем для каждого узла считаем, насколько часто он использует тот или иной набор протоколов, и формируем вектор признаков из этих чисел. Используя размеченные узлы из тренировочной выборки и методы AutoML, подбираем оптимальную архитектуру модели, после чего обучаем её.Готовой модели подаём на вход вектора признаков неразмеченных узлов и получаем ответы – их предполагаемые типы. Всё, узлы размечены.
Для выявления аномалий нужно ещё меньше данных. Описанным выше методом формируем вектора признаков для узлов. Поскольку в этом случае будем использовать метод обучения без учителя (классификация по заранее неизвестному числу классов) – определяем оптимальное количество кластеров и разделяем узлы на них. Используя номера кластеров как ответы, обучаем нейронную сеть на имеющихся данных. Далее, при обнаружении новых потоков, обновляем вектора признаков узлов и предсказываем их класс нейронкой. Если класс совпал с ранее записанным – всё в порядке, если нет –
3. Математика (формальная модель)
Математику иногда называют универсальным языком науки. Попытаемся перевести на него идею определения сетевого класса узла по его трафику, а заодно конкретизируем некоторые моменты.На вход модель получает сетевой трафик защищаемой системы. Набор сетевых пакетов, использующих одинаковые протоколы на всех задействованных сетевых уровнях и направленных от одного сетевого адреса к другому, назовём потоком. Поток Flow описывается вектором характеристик
длина которого numProto зависит от количества вложенных сетевых протоколов, присутствующих в пакете.
Таким образом, весь набор потоков Flows длиной lenFlows описывается набором характеристик

длина которого numProto зависит от количества вложенных сетевых протоколов, присутствующих в пакете.
Таким образом, весь набор потоков Flows длиной lenFlows описывается набором характеристик


В качестве идентификатора каждого сетевого узла host из множества классифицируемых сетевых узлов Hosts длиной lenHosts используется набор адресов источника на всех numProto уровнях сетевой модели. Количество уровней адресации numProto соответствует количеству вложенных протоколов:


Основные характеристики узла – количество потоков host.num_flows, относящихся к нему, и используемые в этих потоках протоколы. Для каждого узла описывается вектор характеристик

длина которого host.numKnown.Proto соответствует общему количеству известных протоколов всех уровней во всём массиве потоков, а каждый элемент frequency характеризуется числом от 0 до 1, зависящим от количества потоков, относящихся к этому узлу и имеющих в своём составе соответствующий протокол.
Узел имеет набор ярлыков

каждый из которых характеризует его принадлежность к одному из классов. Группы классов формируются независимо по двум признакам: роль узла (например, ПЛК, АРМ, АСО, …), операционная система (Windows XP, Windows 7, Linux Ubuntu, Linux CentOS, …).
Также узел характеризуется долей потоков, связывающих его с узлами определённых классов host.connectedWith.
Для описания узла в формате, пригодном для анализа моделями машинного обучения, важные характеристики сводятся в характеристический вектор узла host.vector. В него также могут быть добавлена другая информация об узлах host.some_inf. Объединённая с информацией о частоте использования протоколов, она является профилем трафика узла host.vector = {host.proto,host.some_inf}, или характеристическим вектором.
Исходные данные

для модели представляются в виде набора характеристических векторов узлов.
Для обучения модели необходима априорная информация о классах узлов, поэтому необходимо задать каждый из

То есть дамп трафика должен состоять из набора потоков, для всех входных данных (адресов источника, для каждого узла

в которых заранее известен ответ – тип узла label.

Имеющийся трафик с размеченными узлами делится на две части: тренировочную и тестовую. Сначала модель обучается на тренировочной выборке, имея в качестве ответов значения параметра host.label, известные для всех узлов. Затем модель выполняет распознание узлов из тестовой выборки, и по результатам сравнения предсказанных host.labelPredicted и заранее размеченных host.label классов с помощью некоторых метрик оценивается качество работы модели. Если оно удовлетворяет заданным требованиям, то модель сохраняется, в противном случае структура модели или её гиперпараметры меняются, и цикл из обучения, тестирования и изменения модели повторяется до тех пор, пока не будет достигнуто достаточное качество предсказания.

А теперь рассмотрим вторую задачу: выявление аномалий в сетевом трафике. Для этого из существующего набора потоков Flows выделяются характеристические вектора host.vector, которые затем с помощью модели-кластеризатора разделяются на группы, и каждому узлу задаётся класс host.label в соответствии с номером группы, в которой он оказался. Таким образом, всё многомерное пространство, чья размерность равна длине характеристического вектора host.vector, становится разделённым на множество областей, количество которых равно количеству кластеров. Одновременно для кластеризации используется модель иерархического кластеризатора. Сформированное ей разделение сохраняется для использования на следующем шаге.
При появлении новой группы потоков Flows характеристические вектора узлов host.vector обновляются и подаются на вход модели. Результаты работы модели сохраняются в свойство host.new_label соответствующего узла и сравниваются с известными классами узлов host.label. Если обнаруживается расхождение
,")
то оно считается аномалией. Потоки Flows, которые его вызвали (которые изменили характеристический вектор этого узла host.vector), считаются инициаторами аномалии, и передаются оператору как потенциально опасные, также указывается host, поведение которого было отмечено как аномальное. Для определения критичности аномалии используется сформированной иерархической моделью разделение узлов: критичность перехода узла из одной группы в другую равна кофенетическому расстоянию (длине пути от одного узла до другого по ветвям в иерархии) между аномальным узлом и его новым ближайшим соседом.
Если расхождения между известными и полученными вновь классами отсутствуют
,")
то модель заново обучается, используя в качестве входных данных обновлённые характеристические вектора узлов host.vector (происходит переразметка многомерного пространства), и переходит в режим ожидания следующего набора потоков. Одновременно строится и новое иерархическое разделение. Считается, что аномального поведения в этот раз не выявлено.

Описанная формальная модель позволяет решать задачу определения классификационных признаков и выявления аномалий в поведении сетевых узлов.
4. Реализация
Для получения потоков из трафика использован модуль DPI продукта CyberLympha DATAPK. Затем из потоков формируются характеристические вектора с помощью самописного скрипта на Python.Для подбора оптимальной архитектуры моделей использован один из методов автоматизированного машинного обучения – TPOT, реализованный в одноимённом модуле для Python.
В результате работы подобран ансамбль, состоящий из двух блоков, объединённых методом стэкинга. Первый блок – также ансамбль объединённых методом стэкинга моделей К-соседей. При этом ответы моделей нижних уровней являются дополнительными признаками для моделей верхнего уровня.

Второй блок – модель наивного байесовского классификатора с минимальным сглаживанием.

Для реализации моделей выбранной архитектуры использована библиотека sklearn.
В задаче выявления аномалий используется метод DBSCAN для исходной кластеризации, библиотека SciPy для иерархической кластеризации и нейронная сеть для определения классификации узлов по группам.
5. Результаты
Имеющихся данных пока недостаточно, чтобы оценить точность работы разработанных модулей. В перспективе, когда продукт дойдёт до стадии опытной эксплуатации, можно будет хвастаться цифрами. При тестировании на имеющихся данных (разумеется, не на тех, которые были в обучающей выборке) зафиксирована мера F1 точности в 80% (см. Таблица 5.1). Также придуман чит – для тех случаев, в которых модель не уверена в принимаемом решении, допускается предлагать пользователю на выбор два наиболее вероятных класса. В этом случае F1-мера растёт до 95-98%, а количество таких случаев в сравнении с объёмом всей выборки невелико, поэтому такой вариант кажется предпочтительным.Таблица 5.1 – Точность работы классификатора.
| Тип класса | Точность | Полнота | F1-мера |
| Роли узлов (АРМ, ПЛК, Сервер, …) | 0.81 | 0.8 | 0.81 |
| Операционная система (WinXP, Win8, LinuxCentOS, ...) | 0.86 | 0.8 | 0.78 |
Предположим, что всего в сети предприятия активны 4 узла: ПЛК, SCADA и два АРМ. При этом ПЛК общается со SCADA-сервером, используя Modbus (на нижних уровнях – Ethernet, IPv4 и TCP), SCADA с АРМ №2 – используя HTTP с тем же набором протоколов нижнего уровня, а с АРМ №2 – ещё и по SSH. Карта потоков нарисована на рисунке ниже.

Составим таблицу частот использования протоколов на каждом уровне OSI каждым из узлов:
Таблица 5.2 – Частоты использования протоколов узлами
| Признак \ Узел | ПЛК | SCADA | АРМ №1 | АРМ №2 | |
| Протокол\Тип узла | ПЛК | SCADA | АРМ | АРМ | |
| L2 | Ethernet | 1 | 1 | 1 | 1 |
| L3 | IPv4 | 1 | 1 | 1 | 1 |
| L4 | TCP | 1 | 1 | 1 | 1 |
| L5 | Modbus | 1 | 0.25 | 0 | 0 |
| HTTP | 0 | 0.5 | 0.5 | 1 | |
| SSH | 0 | 0.25 | 0.5 | 0 |
ПЛК = [1, 1, 1, 1, 0, 0]; SCADA = [1, 1, 1, 0.25, 0.5, 0.25];
АРМ№1 = [1, 1, 1, 0, 0.5, 0.5]; АРМ№2 = [1, 1, 1, 0, 1, 0]
Видно, что первые элементы векторов одинаковы для всех классов, поэтому они не будут учтены при обучении модели. Важными будут только последние элементы.
Сохраним полученные вектора:
samples = [
[1, 1, 1, 1, 0, 0],
[1, 1, 1, 0.25, 0.5, 0.25],
[1, 1, 1, 0, 0.5, 0.5],
[1, 1, 1, 0, 1, 0]
]
И истинные классы для каждого примера:
answers = [
'PLC',
'SCADA',
'ARM',
'ARM'
]
Создадим простую модель – например, возьмём метод опорных векторов (описанная в статье модель не успеет обучиться на таком малом количестве примеров).
from sklearn import svm
model = svm.SVC(kernel='poly', degree=3)
model.fit(samples, answers)
Теперь проверим, как наша модель работает на новых данных. Предположим, что в сети появился ещё один АРМ – но не совсем такой, как два исходных, а используемый исключительно для управления SCADA-сервером. Пусть он генерирует только потоки с SSH трафиком. Тогда схема сети будет такая:

Появление нового узла приведёт не только к добавлению одного вектора признаков, но и к изменению векторов признаков тех узлов, с которыми он взаимодействует. В нашем случае это SCADA: частота использования SSH увеличится, остальных протоколов – уменьшится.
Таблица 5.3 – Частоты использования протоколов узлами после появления нового узла
| Признак \ Узел | ПЛК | SCADA | АРМ №1 | АРМ №2 | АРМ №3 | |
| Протокол\Тип узла | ПЛК | SCADA | АРМ | АРМ | ? | |
| L2 | Ethernet | 1 | 1 | 1 | 1 | 1 |
| L3 | IPv4 | 1 | 1 | 1 | 1 | 1 |
| L4 | TCP | 1 | 1 | 1 | 1 | 1 |
| L5 | Modbus | 1 | 0.2 | 0 | 0 | 0 |
| HTTP | 0 | 0.4 | 0.5 | 1 | 0 | |
| SSH | 0 | 0.4 | 0.5 | 0 | 1 |
unknown_node_vector = [
[1, 1, 1, 0, 0, 1]
]
И выполним предсказание с помощью обученной ранее модели:
model.predict(unknown_node_vector)
>>> array(['ARM'], dtype='<U5')
Видно, что в результате модель дала правильный ответ. В реальной работе сервиса используется большее количество узлов при обучении, больше признаков у каждого узла, но принцип работы описанный выше пример демонстрирует достаточно точно.
6. Актуальное состояние дел
Сейчас описываемый сервис реализован в виде прототипа. Если всё это заработает, то у отделов ИБ заявленных заводов и пароходов станет на одну боль (определение типов узлов в ручном режиме) меньше и появятся свободные руки для выполнения менее рутинных операций, что в целом повысит защищённость систем.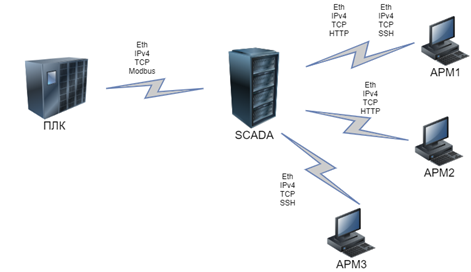
Определение классов сетевых узлов и выявление аномалий в их активности по сетевому трафику в пассивном режиме
1. Актуальность На современных заводах, а часто и на достаточно больших поездах и пароходах активно используются сети передачи данных. При этом во многих случаях передаваемая информация достаточно...
 habr.com
habr.com