Задача
Изначально задача была в построение коллажа из нескольких картинок размером 512x512px, которая свелась к задаче по копированию синей составляющей картинки image.RGBA в индекс цвета палитры в image.Paletted. Для целей исследования я упростил задачу до: надо скопировать синюю составляющую из картинки image.RGBA размером 512x512px в image.Paletted такого же размера.Решение с использованием методов пакета image выглядит так:
func BenchmarkCopySTD(b *testing.B) {
for i := 0; i < b.N; i++ {
for y := 0; y < imageHeight; y++ {
dstPixOffset := dstPaletted.PixOffset(0, y)
for x := 0; x < imageWidth; x++ {
_, _, b, _ := srcRGBA.At(x, y).RGBA()
dstPaletted.Pix[dstPixOffset+x] = uint8(b)
}
}
}
}
Оно долгое, много времени тратится на вызовы At(). Типы картинок нам известны, поэтому очевидное решение работать напрямую с пикселами:
func BenchmarkCopySliceElements(b *testing.B) {
for i := 0; i < b.N; i++ {
for y := 0; y < imageHeight; y++ {
srcPixOffset := srcRGBA.PixOffset(0, y)
dstPixOffset := dstPaletted.PixOffset(0, y)
for x := 0; x < imageWidth; x++ {
dstPaletted.Pix[dstPixOffset+x] = srcRGBA.Pix[srcPixOffset+x*4+1]
}
}
}
}
Сразу получаем большой буст:
BenchmarkCopySTD-16 1590 3730930 ns/op 1048600 B/op 262144 allocs/op
BenchmarkCopySliceElements-16 22778 260128 ns/op 0 B/op 0 allocs/op
Дальше начинается чёрная магия unsafe.
Избавляемся от Bounds Check
Если посмотреть на ассемблер, то можно сильно удивиться количеству операций необходимых для копирования одного элемента слайса в другой: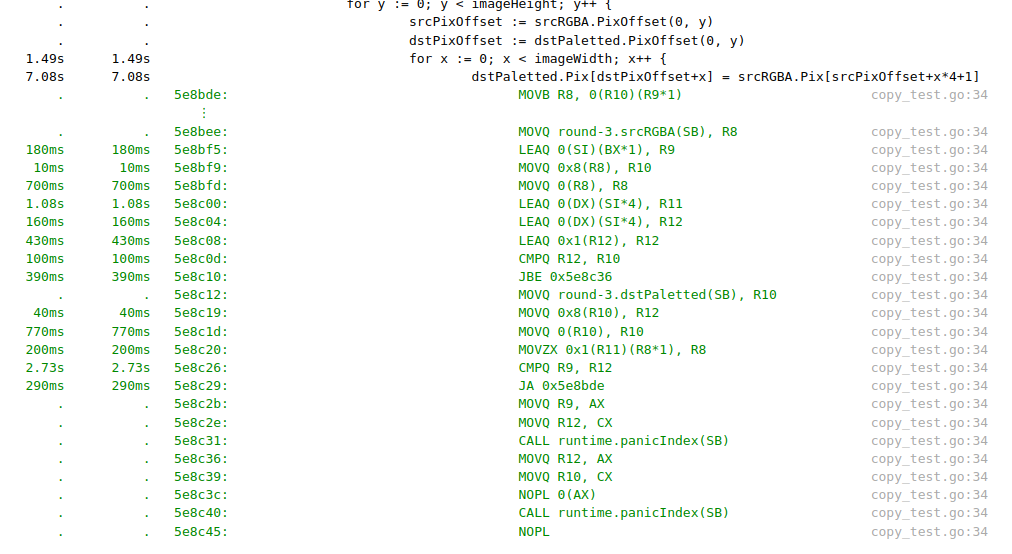
На самом деле это проверка на невыход за границы слайса. Её можно отключить глобально при компиляции, но в данном случае нам надо её отключить только в одном месте программы. Для этого нужно обращаться напрямую по адресу нужного элемента, вычислить который можно используя адрес нулевого элемента. Переписанный код выглядит так:
func BenchmarkCopyUnsafe(b *testing.B) {
for i := 0; i < b.N; i++ {
dstAddr := uintptr(unsafe.Pointer(&dstPaletted.Pix[0]))
srcAddr := uintptr(unsafe.Pointer(&srcRGBA.Pix[0]))
for y := 0; y < imageHeight; y++ {
srcPixOffset := srcRGBA.PixOffset(0, y)
dstPixOffset := dstPaletted.PixOffset(0, y)
for x := 0; x < imageWidth; x++ {
//dst.Pix[dstPixOffset+x] = src.Pix[srcPixOffset+x*4+1]
*(*uint8)((unsafe.Pointer)(dstAddr + uintptr(dstPixOffset+x))) = *(*uint8)((unsafe.Pointer)(srcAddr + uintptr(srcPixOffset+x*4+2)))
}
}
}
}
В строках (3) и (4) получаем адреса в памяти нулевых элементов, а дальше обращаемся к ним по смещению относительно адреса. Время на копирование сократилось в 2 раза:
BenchmarkCopySTD-16 1590 3730930 ns/op 1048600 B/op 262144 allocs/op
BenchmarkCopySliceElements-16 22778 260128 ns/op 0 B/op 0 allocs/op
BenchmarkCopyUnsafe-16 44539 131881 ns/op 0 B/op 0 allocs/op
Количество инструкций CPU сильно уменьшилось:
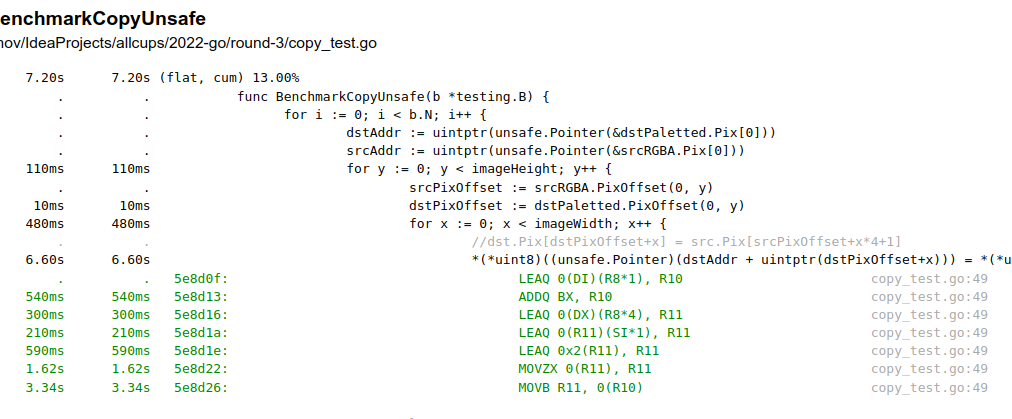
Такое решение было отправлено на конкурс, но количество инструкций меня всё ещё смущало и уже после конкурса я начал искать пути как это можно ускорить.
Избавляемся от сложной математики
Первое что бросается в глаза, это умножение. Плюс при работе с памятью напрямую можно не вычислять смещение, а просто жонглировать указателями:func BenchmarkCopyUnsafeV2(b *testing.B) {
for i := 0; i < b.N; i++ {
dstAddr := uintptr(unsafe.Pointer(&dstPaletted.Pix[0]))
srcAddr := uintptr(unsafe.Pointer(&srcRGBA.Pix[0])) + 2
for y := 0; y < imageHeight; y++ {
for x := 0; x < imageWidth; x++ {
*(*uint8)((unsafe.Pointer)(dstAddr)) = *(*uint8)((unsafe.Pointer)(srcAddr))
dstAddr++
srcAddr += 4
}
}
}
}
Время ещё сократилось в 1.5 раза:
BenchmarkCopySTD-16 1590 3730930 ns/op 1048600 B/op 262144 allocs/op
BenchmarkCopySliceElements-16 22778 260128 ns/op 0 B/op 0 allocs/op
BenchmarkCopyUnsafe-16 44539 131881 ns/op 0 B/op 0 allocs/op
BenchmarkCopyUnsafeV2-16 65779 88408 ns/op 0 B/op 0 allocs/op
Инструкций CPU осталось минимум:

Кажется что всё, быстрее быть не может, но ...
Loop unrolling
В какой-то момент я подумал, а чтобы сделал C++ компилятор с -O3 и это меня натолкнуло на мысль, почему Go не сделал оптимизацию "Размотка цикла"? Надо попробовать сделать руками:func BenchmarkCopyUnrolledLoop4(b *testing.B) {
for i := 0; i < b.N; i++ {
dstAddr := uintptr(unsafe.Pointer(&dstPaletted.Pix[0]))
srcAddr := uintptr(unsafe.Pointer(&srcRGBA.Pix[0]))
for y := 0; y < imageHeight; y++ {
for x := 0; x < imageWidth; x += 4 {
*(*uint8)((unsafe.Pointer)(dstAddr + 0)) = *(*uint8)((unsafe.Pointer)(srcAddr + 0))
*(*uint8)((unsafe.Pointer)(dstAddr + 1)) = *(*uint8)((unsafe.Pointer)(srcAddr + 4))
*(*uint8)((unsafe.Pointer)(dstAddr + 2)) = *(*uint8)((unsafe.Pointer)(srcAddr + 8))
*(*uint8)((unsafe.Pointer)(dstAddr + 3)) = *(*uint8)((unsafe.Pointer)(srcAddr + 12))
dstAddr += 4
srcAddr += 16
}
}
}
}
И это ускорило ещё на треть. На самом деле я попробовал разные количество операций за 1 цикл, включая все 512 px, но самый лучший результат, по крайней мере на моём CPU, показал вариант с 4 операциями:
BenchmarkCopySTD-16 1590 3730930 ns/op 1048600 B/op 262144 allocs/op
BenchmarkCopySliceElements-16 22778 260128 ns/op 0 B/op 0 allocs/op
BenchmarkCopyUnsafe-16 44539 131881 ns/op 0 B/op 0 allocs/op
BenchmarkCopyUnsafeV2-16 65779 88408 ns/op 0 B/op 0 allocs/op
BenchmarkCopyUnrolledLoop2-16 88812 66479 ns/op 0 B/op 0 allocs/op
BenchmarkCopyUnrolledLoop4-16 95296 58995 ns/op 0 B/op 0 allocs/op
BenchmarkCopyUnrolledLoop8-16 95563 62937 ns/op 0 B/op 0 allocs/op
BenchmarkCopyUnrolledLoop512-16 95064 62808 ns/op 0 B/op 0 allocs/op
Заключение
Кажется здесь мне можно остановиться, ускорение в 63 раза относительно вызова функций и в почти 4.5 раза относительно копированию элементов по индексам выглядит неплохо. Дальше можно попробовать поиграться с векторными командами, возможно в следующий раз. Но для желающих я сделал задачу на HighLoad.Fun, где можно попробовать свои силы и ещё ускорить код, причём не только на Go, но и на C++ или Rust.P.S. Ради интереса я спросил у ChatGPT как можно ускорить BenchmarkCopySliceElements, он предложил:
- Использовать горутины, в моём случае нерелевантно, т.к. остальные ядра CPU уже заняты той же работой для других картинок.
- Использовать SIMD, но работающего решения не предложил.
- Предложил использовать более быструю библиотеку для работы с картинками, но какую не сказал.
- После уточняющих вопросов, предложил развернуть цикл, но я и так это уже сделал.

Оптимизация доступа к элементам слайса в Go
Привет Хабр! В своей предыдущей статье про разбор кода победившего в VK Cup'22/23 я описывал как мне удалось ускорить копирование одной картинки в другую в 30 раз с помощью чёрной магии unsafe ....
 habr.com
habr.com