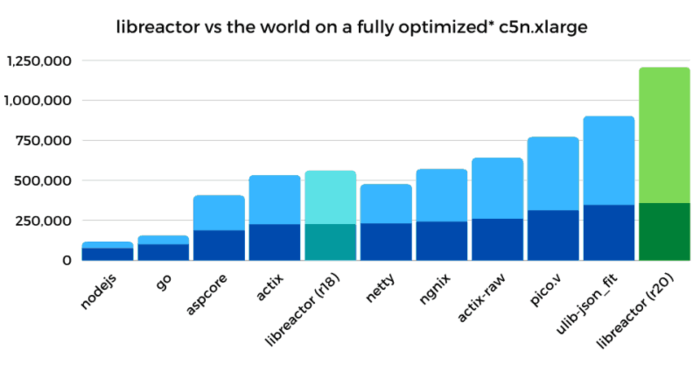
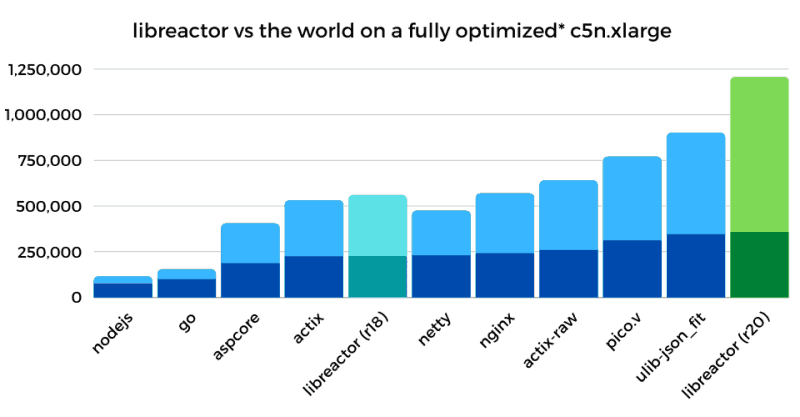
Опубликовано детальное руководство по тюнингу окружения Linux для достижения максимальной производительности обработки HTTP-запросов. Предложенные методы позволили поднять производительность обработчика JSON на основе библиотеки libreactor в окружении Amazon EC2 (4 vCPU) c 224 тысяч запросов API в секунду при штатных настройках Amazon Linux 2 с ядром 4.14 до 1.2 млн запросов в секунду после проведения оптимизации (прирост 436%), а также привели к сокращению задержек при обработке запросов на 79%. Предложенные методы не специфичны для libreactor и работают при использовании других http-серверов, включая nginx, Actix, Netty и Node.js (libreactor использовался в тестах, так как решение на его основе показало лучшую производительность).
Основные оптимизации:
Источник статьи: https://www.opennet.ru/opennews/art.shtml?num=55186
Основные оптимизации:
- Оптимизация кода libreactor. В качестве основы был использован вариант R18 из набора Techempower, который был улучшен путём удаления кода для ограничения числа используемых ядер CPU (оптимизация позволила ускорить работу на 25-27%), сборки в GCC с опциями "-O3" (прирост 5-10%) и "-march-native" (5-10%), замены вызовов read/write на recv/send (5-10%) и снижения накладных расходов при использовании pthreads (2-3%). Общий прирост производительности после оптимизации кода составил 55%, а пропускная способность возросла с 224k req/s до 347k req/s.
- Отключение защиты от уязвимостей, вызванных спекулятивным выполнением инструкций. Использование параметров при загрузке ядра "nospectre_v1 nospectre_v2 pti=off mds=off tsx_async_abort=off" позволило поднять производительность на 28%, а пропускная способность возросла с 347k req/s до 446k req/s. В отдельности прирост от параметра "nospectre_v1" (защита от Spectre v1 + SWAPGS) составил 1-2%, "nospectre_v2" (защита от Spectre v2) - 15-20%, "pti=off" (Spectre v3/Meltdown) - 6%, "mds=off tsx_async_abort=off" (MDS/Zombieload и TSX Asynchronous Abort) - 6%. Оставлены без изменения настройки для защиты от атак L1TF/Foreshadow (l1tf=flush), iTLB multihit, Speculative Store Bypass и SRBDS, которые не влияли на производительность, так как не пересекались с тестируемой конфигурацией (например, специфичны для KVM, вложенной виртуализации и других моделей CPU).
- Отключение механизмов аудита и блокировки системных вызовов при помощи команды "auditctl -a never,task" и указания опции "--security-opt seccomp=unconfined" при запуске контейнера docker. Общий прирост производительности составил 11%, а пропускная способность возросла с 446k req/s до 495k req/s.
- Отключение iptables/netfilter через выгрузку связанных с ними модулей ядра. К идее отключить межсетевой экран, который не использовался в специфичном серверном решении, подтолкнули результаты профилирования, судя по которым на выполнение функции nf_hook_slow уходило 18% времени. Отмечается, что nftables работает более эффективно, чем iptables, но в Amazon Linux продолжает использоваться iptables. После отключения iptables прирост производительности составил 22%, а пропускная способность возросла с 495k req/s до 603k req/s.
- Снижение миграции обработчиков между разными ядрами CPU для повышения эффективности использования процессорного кэша. Оптимизация была произведена как на уровне привязки процессов libreactor к ядрам CPU (CPU Pinning), так и через закрепление сетевых обработчиков ядра (Receive Side Scaling). Например, выполнено отключение irqbalance и явное выставление привязок очередей к CPU в /proc/irq/$IRQ/smp_affinity_list. Для использования одного и того же ядра CPU для обработки процесса libreactor и сетевой очереди входящих пакетов задействован собственный BPF-обработчик, подключённый через установку флага SO_ATTACH_REUSEPORT_CBPF при создании сокета. Для привязки к CPU очередей исходящих пакетов изменены настройки /sys/class/net/eth0/queues/tx-<n>/xps_cpus. Общий прирост производительности составил 38%, а пропускная способность возросла с 603k req/s до 834k req/s.
- Оптимизация обработки прерываний и использование полинга (polling). Включение режима adaptive-rx в драйвере ENA и манипуляции с sysctl net.core.busy_read позволили поднять производительность на 28% (пропускная способность возросла с 834k req/s до 1.06M req/s, а задержки снизились с 361μs до 292μs).
- Отключение системных сервисов, приводящих к лишним блокировкам в сетевом стеке. Отключение dhclient и установка IP-адреса вручную привела к повышению производительности на 6%, а пропускная способность возросла с 1.06M req/s до 1.12M req/s. Причина влияния dhclient на производительность в анализе трафика с использованием raw-сокета.
- Борьба со Spin Lock. Перевод сетевого стека в режим "noqueue" через sysctl "net.core.default_qdisc=noqueue" и "tc qdisc replace dev eth0 root mq" привёл к приросту производительности на 2%, а пропускная способность возросла с 1.12M req/s до 1.15M req/s.
- Финальные мелкие оптимизации, такие как отключение GRO (Generic Receive Offload) командой "ethtool -K eth0 gro off" и замена алгоритма контроля за перегрузкой cubic на reno при помощи sysctl "net.ipv4.tcp_congestion_control=reno". Общий прирост производительности составил 4%. Пропускная способность возросла с 1.15M req/s до 1.2M req/s.
- Отдельный запуск libreactor не отличался в производительности от запуска в контейнере. Не оказали влияния замена writev на send, увеличение maxevents в epoll_wait, эксперименты с версиями и флагами GCC (эффект был заметен только для флагов "-O3" и "-march-native").
- Не повлияло на производительность обновление ядра Linux до версий 4.19 и 5.4, использование планировщиков SCHED_FIFO и SCHED_RR, манипуляции с sysctl kernel.sched_min_granularity_ns, kernel.sched_wakeup_granularity_ns, transparent_hugepages=never, skew_tick=1 и clocksource=tsc.
- В драйвере ENA не повлияло включение режимов Offload (segmentation, scatter-gather, rx/tx checksum), сборка с флагом "-O3" и применение параметров ena.rx_queue_size и ena.force_large_llq_header.
- Не привели к повышению производительности изменения в сетевом стеке:
- Отключение IPv6: ipv6.disable=1
- Отключение VLAN: modprobe -rv 8021q
- Отключение проверки источника пакета
- net.ipv4.conf.all.rp_filter=0
- net.ipv4.conf.eth0.rp_filter=0
- net.ipv4.conf.all.accept_local=1 (негативный эффект)
- net.ipv4.tcp_sack=0
- net.ipv4.tcp_dsack=0
- net.ipv4.tcp_mem/tcp_wmem/tcp_rmem
- net.core.netdev_budget
- net.core.dev_weight
- net.core.netdev_max_backlog
- net.ipv4.tcp_slow_start_after_idle=0
- net.ipv4.tcp_moderate_rcvbuf=0
- net.ipv4.tcp_timestamps=0
- net.ipv4.tcp_low_latency=1
- SO_PRIORITY
- TCP_NODELAY
Источник статьи: https://www.opennet.ru/opennews/art.shtml?num=55186