В этой статье я расскажу про то, как можно организовать отказоустойчивое взаимодействие с внешними сервисами. Тема актуальная, очень часто из-за недоступности какого-то одного компонента может пострадать вся система.
О чем статья:
REST API - популярный протокол межсервисного взаимодействия, однако, у него есть недостаток: он является синхронным. Поэтому каждый раз, когда клиент посылает запрос, он вынужден ждать ответ. Когда сервисы для обработки запроса общаются синхронно, это приводит к тому, что доступность системы снижается.

Для того, чтобы понять почему так происходит рассмотрим пример создания заказов.
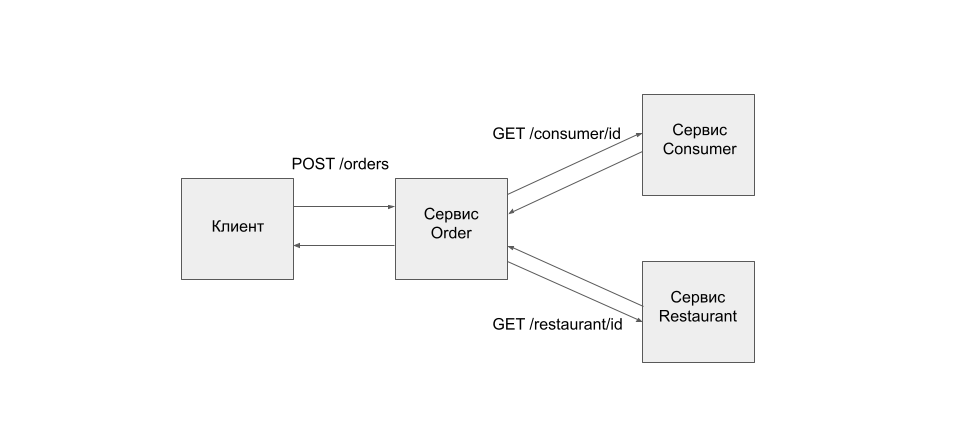
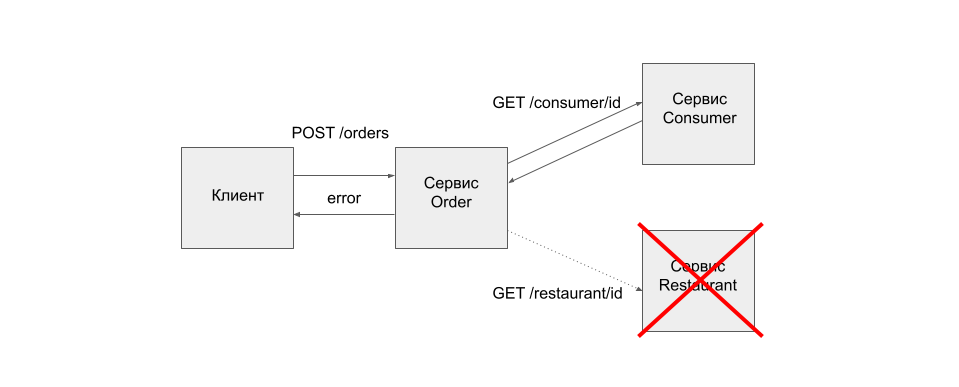
Предположим, у нас есть сервис Order, который использует REST API для создания заказов. Он взаимодействует с сервисами Consumer и Restaurant, которые также используют синхронный REST API. Пользователь для создания заказа посылает запрос сервису Order, сервис Order получает информацию о заказчике в сервисе Consumer, получает информацию о ресторане в сервисе Restaurant, валидирует данные, создает заказ, возвращает ответ клиенту. В данном случае система будет доступна, если будут доступны все компоненты. Если какой-то из компонентов окажется недоступен, то операция успешно завершиться не сможет. Клиент получит сообщение об ошибке.
С математической точки зрения доступность операции создания заказа равна произведению доступности компонентов в ней участвующих. И не может превышать доступность каждого из её компонентов, то есть в данном случае, если доступность сервиса Restaurant 50%, то доступность сценария, в котором участвует сервис Restaurant не может быть более 50%. Даже, если доступность одного компонента 99,5%, что довольно высоко, то доступность операции будет ниже, а именно 98,5%.
99,5%*99,5%*99,5%=98,5%
С ростом числа компонентов, доступность будет снижаться.
99,5%*99,5%*99,5%*99,5%*99,5%=97,5%
Если сервис Order сделает все запросы параллельно и примется ждать, это не увеличит его доступность, но время ответа клиенту может сократиться.
Синхронное взаимодействие популярно из-за:

Клиент делает запрос сервису Order, сервис Order асинхронно обменивается данными с другими сервисами и возвращает асинхронный ответ клиенту.
При такой схеме клиент с сервисом общаются в асинхронном стиле через канал передачи данных и ни один из участников взаимодействия не блокируется в ожидании ответа от другого сервиса. Такая система получается очень устойчивой, потому что, если какой-то из сервисов откажет, то каналы будут буферизировать сообщения. Рано или поздно сервис восстановится и обработает запросы.
Данная схема обеспечивает слабую связанность компонентов, потому что сервисы работают через каналы передачи данных. Они не знают ничего про своих получателей и им достаточно только отправить сообщения в нужный канал.
Среди плюсов асинхронного API можно выделить высокую доступность приложения, отсутствие синхронного времени ожидания ответа, слабую связанность.
При этом асинхронное API сложнее в реализации, тестировании, отладке, в нем отсутствует внешнее синхронное API, который может потребоваться например сервису Order для того, чтобы взаимодействовать с внешним клиентом. Архитектура клиента может просто не быть готова к тому, что есть только асинхронные вызовы.
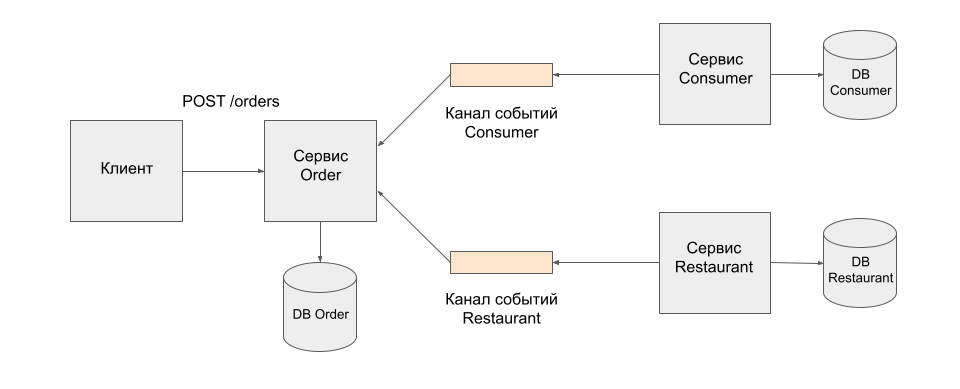
Альтернативным способом снижения количества синхронного взаимодействия является репликация данных. Сервис может хранить копии данных, которые ему нужны для обработки запроса. Например, сервис Order может хранить проекцию данных сервиса Consumer и Restaurant. Сервис Consumer и Restaurant публикуют события, когда их локальные данные меняются, а сервис Order на них подписывается и обновляет локальную реплику данных. При таком подходе, когда клиент посылает запрос на создание заказа, сервис Order не делает никаких синхронных вызовов другим клиентам, он берет все данные из своей локальной базы.
Система получается достаточно устойчивой, потому что если один из сервисов окажется недоступным, сервис Order все равно сможет создать заказ, так как данные у него хранятся локально.
У данного подхода тоже есть минусы, он обеспечивает итоговую согласованность данных (eventual consistency). Так как для того чтобы синхронизировать данные, используются асинхронные события, то в сервисе Order данные по пользователям из сервиса Consumer могут отставать. Может получиться такая ситуация, что пришел запрос, заказчик уже есть в сервисе Consumer, но данные еще не пришли в сервис Order и запрос валидацию не проходит.
Итак, какие же у данного подхода плюсы: В ряде случаев этот подход может быть очень хорош.

Клиент посылает запрос на создание заказа, сервис order создает заказ в статусе “в ожидании” и возвращает идентификатор заказа клиенту. Все это он делает синхронно, а затем посылает асинхронное сообщение сервису Consumer и сервису Restaurant. Когда сообщение обрабатывается в сервисе Consumer, сервис Consumer валидирует данные и возвращает ответ сервису Order. Далее обрабатывается событие в сервисе Restaurant, он так же валидирует данные и возвращает ответ сервису Order. Сервис Order меняет статус заказа на “проверен”. Такой подход также обеспечивает слабую связанность компонентов и высокую отказоустойчивость. При создании заказа не посылается никакие синхронные запросы. В случае если один из компонентов окажется недоступным, то канал также буферизирует сообщения. Когда получатель будет доступен, все сообщения обработаются, заказ будет создан.
Данный подход чем-то напоминает сагу на основе оркестарции. Сага — это паттерн межсервисного взаимодействия, состоит он из локальных транзакций. При выполнении локальной транзакции порождаются события/команды, которые в дальнейшем также порождают выполнение следующей локальной саги.
Сложности подхода “Ответ клиенту до полной обработки”:
Может возникнуть вопрос “А где же внешние сервисы?”
На самом деле правила, которые применимы к повышению отказоустойчивости системы при взаимодействии с внешними сервисами, такие же как и при взаимодействии с внутренними сервисами. Однако здесь могут быть ограничения:

Можно создать заказ синхронно, а затем синхронно послать данные на сервис Analytics.
Здесь может быть несколько проблем.
Сервис Analytics может оказаться недоступным, тогда непонятно, что делать с заказом: нам либо нужно отменить создание заказа и вернуть ошибку, либо же мы игнорируем недоступность сервиса Analytics, тогда в этом случае теряется часть данных.

Допустим мы выбираем второй сценарий, так как считаем, что логирование никак не должно влиять на функционал нашего сервиса. Возникает другая проблема: что, если сервис Analytics будет проявлять высокую латентность, то есть долго обрабатывать запросы, в этом случае наше время ответа клиенту тоже возрастет. И даже может получиться так, что заказ будет создан, но так как запрос сервис Analytics обрабатывал долго, клиент получил ответит со статусом 504, хотя заказ был успешно создан.

Следует также учесть, что запросы должны обрабатываться быстро, если они будут обрабатывать медленно, то у нашего сервиса на PHP могут возникнуть проблемы. Например, можно упереться в ограничение очереди запросов PHP-FPM. Либо часть запросов в очереди просто отваливается по тайм-ауту, потому что они не дождались обработки, так как PHP-FPM долго обрабатывает запросы. Либо может закончиться пул соединений с базой данных.
PHP фреймворки при выполнении запросов открывают соединения с базой данных, это соединение продолжает висеть на протяжении всего цикла обработки запроса. Чем дольше обрабатывается запрос, тем дольше это соединение остаётся открытым. Поэтому, если возникнет большая нагрузка на приложение, то мы можем получить отказ в обслуживании.
По умолчанию HTTP клиент (например Guzzle) никак не ограничивает по времени свои запросы. Очевидно, что нужно время запроса ограничить тайм-аутом. Какой тайм-аут выбрать лучше? Если выберем слишком маленький, то часть данных мы можем потерять. Если большой, то ситуация может не измениться. Если мы выберем в секунду, то проблемы с отказоустойчивостью у нас могут все равно остаться, если у нас высоконагруженное приложение. Какие же здесь есть варианты? Можно заменить синхронное взаимодействие, на асинхронное. Например, можно изолировать синхронный вызов к внешнему сервису с помощью асинхронной очереди команд или запросов.

В данном случае команда — это действие по сохранению данных сервиса Analytics.
Можно сделать по-другому. На каждую команду сделать свой Worker и их запускать параллельно. Получится так, что каждый Worker будет занимать соединение с базой данных и на N клиентских запросов, будет создано N воркеров. Таким образом соединения с базой данных будут расходоваться еще быстрее, что может быть критично.
В случае с очередью команд, такой проблемы не возникает.

Команды выполняются последовательно. Worker один и занимает одно соединение с базой данных, если даже команда обрабатывается долго, то в этом случае пул соединений с базой данных не будет исчерпан.

Рассмотрим, как можно реализовать асинхронное взаимодействие.
Клиент присылает запрос на создание заказа. Создаётся заказ и вместе с ним создаётся команда по логированию данных в сервис аналитики. При публикации команды в базу данных она сохраняется в одной транзакции с заказом. Далее команда ретранслируется в брокер сообщений и возвращается ответ клиенту. Сохранять команду в базу нужно, если необходимо гарантировать доставку данных в сервис аналитики. Этот подход называется transactional outbox.
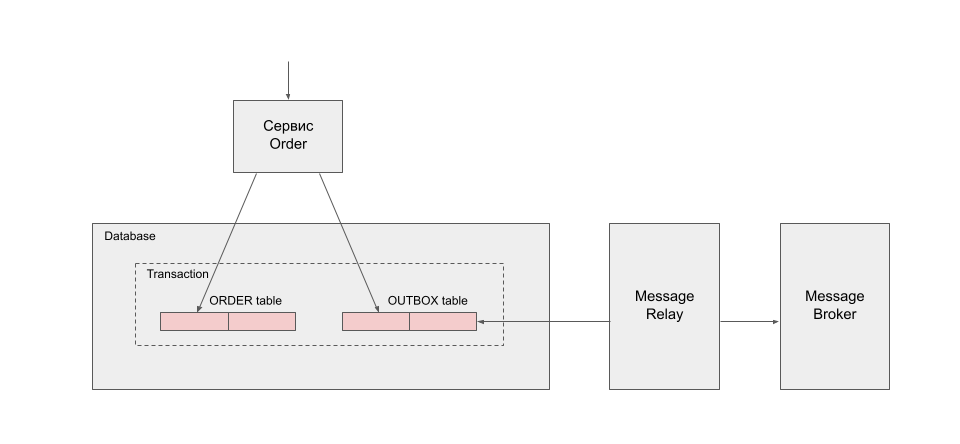
С изменением модели в базу данных в отдельную таблицу (OUTBOX) сохраняются сообщения, события или команды. Дальше эти сообщения ретранслируются в брокер сообщений. Способов ретрансляции может быть множество: синхронный вызов после того как данные были сохранены либо это может быть асинхронный воркер, который в фоне вытаскивает новые команды и просто их перенаправляет в брокер сообщений или какой-то другой способ. Дальше брокер сообщений доставляет сообщение получателю.
Если сделать по-другому, например, сохранить заказ в базу данных, затем попытаться опубликовать команду сразу в брокер сообщений, то в этом случае, если брокер сообщений окажется недоступен, мы переходим в ситуацию синхронного взаимодействия. Нам нужно будет отменять заказ, либо мы теряем часть данных.

После того, как команды попадут в брокер сообщений, они обработаются последовательно. В рамках выполнения команды можно послать синхронный запрос к внешнему сервису, этот синхронный вызов не будет влиять на наше приложение. После того, как данные будут переданы, команда завершится.

В случае если сервис Analytics недоступен, данные переданы не будут, команда просто повторится позднее. Таким образом можно изолировать взаимодействие с внешними сервисами в асинхронном обработчике и внешний сервис не будет влиять на работу нашего приложения.
Подведем итог.
Способы повышения отказоустойчивости:

И напоследок хочу посоветовать книгу “Микросервисы. Паттерны разработки и рефакторинга” Крис Ричардсон. В ней хорошо расписаны теоретические вопросы, касающиеся синхронного и асинхронного взаимодействия, команд, очередей, саг и многое другое.

 habr.com
habr.com
О чем статья:
- Синхронное и асинхронное взаимодействие;
- Зависимость доступности от использования синхронного взаимодействия;
- Способы избавления от синхронного взаимодействия;
- Избавление от синхронного взаимодействия с внешними сервисами в PHP.
REST API - популярный протокол межсервисного взаимодействия, однако, у него есть недостаток: он является синхронным. Поэтому каждый раз, когда клиент посылает запрос, он вынужден ждать ответ. Когда сервисы для обработки запроса общаются синхронно, это приводит к тому, что доступность системы снижается.
Для того, чтобы понять почему так происходит рассмотрим пример создания заказов.
Предположим, у нас есть сервис Order, который использует REST API для создания заказов. Он взаимодействует с сервисами Consumer и Restaurant, которые также используют синхронный REST API. Пользователь для создания заказа посылает запрос сервису Order, сервис Order получает информацию о заказчике в сервисе Consumer, получает информацию о ресторане в сервисе Restaurant, валидирует данные, создает заказ, возвращает ответ клиенту. В данном случае система будет доступна, если будут доступны все компоненты. Если какой-то из компонентов окажется недоступен, то операция успешно завершиться не сможет. Клиент получит сообщение об ошибке.
С математической точки зрения доступность операции создания заказа равна произведению доступности компонентов в ней участвующих. И не может превышать доступность каждого из её компонентов, то есть в данном случае, если доступность сервиса Restaurant 50%, то доступность сценария, в котором участвует сервис Restaurant не может быть более 50%. Даже, если доступность одного компонента 99,5%, что довольно высоко, то доступность операции будет ниже, а именно 98,5%.
99,5%*99,5%*99,5%=98,5%
С ростом числа компонентов, доступность будет снижаться.
99,5%*99,5%*99,5%*99,5%*99,5%=97,5%
Если сервис Order сделает все запросы параллельно и примется ждать, это не увеличит его доступность, но время ответа клиенту может сократиться.
Синхронное взаимодействие популярно из-за:
- простоты реализации
- удобства тестирования
- простоты отладки.
- снижение отказоустойчивости приложения
- увеличение времени ответа клиенту
- высокая связанность.
Клиент делает запрос сервису Order, сервис Order асинхронно обменивается данными с другими сервисами и возвращает асинхронный ответ клиенту.
При такой схеме клиент с сервисом общаются в асинхронном стиле через канал передачи данных и ни один из участников взаимодействия не блокируется в ожидании ответа от другого сервиса. Такая система получается очень устойчивой, потому что, если какой-то из сервисов откажет, то каналы будут буферизировать сообщения. Рано или поздно сервис восстановится и обработает запросы.
Данная схема обеспечивает слабую связанность компонентов, потому что сервисы работают через каналы передачи данных. Они не знают ничего про своих получателей и им достаточно только отправить сообщения в нужный канал.
Среди плюсов асинхронного API можно выделить высокую доступность приложения, отсутствие синхронного времени ожидания ответа, слабую связанность.
При этом асинхронное API сложнее в реализации, тестировании, отладке, в нем отсутствует внешнее синхронное API, который может потребоваться например сервису Order для того, чтобы взаимодействовать с внешним клиентом. Архитектура клиента может просто не быть готова к тому, что есть только асинхронные вызовы.
Альтернативным способом снижения количества синхронного взаимодействия является репликация данных. Сервис может хранить копии данных, которые ему нужны для обработки запроса. Например, сервис Order может хранить проекцию данных сервиса Consumer и Restaurant. Сервис Consumer и Restaurant публикуют события, когда их локальные данные меняются, а сервис Order на них подписывается и обновляет локальную реплику данных. При таком подходе, когда клиент посылает запрос на создание заказа, сервис Order не делает никаких синхронных вызовов другим клиентам, он берет все данные из своей локальной базы.
Система получается достаточно устойчивой, потому что если один из сервисов окажется недоступным, сервис Order все равно сможет создать заказ, так как данные у него хранятся локально.
У данного подхода тоже есть минусы, он обеспечивает итоговую согласованность данных (eventual consistency). Так как для того чтобы синхронизировать данные, используются асинхронные события, то в сервисе Order данные по пользователям из сервиса Consumer могут отставать. Может получиться такая ситуация, что пришел запрос, заказчик уже есть в сервисе Consumer, но данные еще не пришли в сервис Order и запрос валидацию не проходит.
Итак, какие же у данного подхода плюсы: В ряде случаев этот подход может быть очень хорош.
- отсутствие синхронных вызовов при обработке запроса
- слабая связанность
- дублирование данных
- eventual consistency. Так как синхронизация данных происходит в сервисах не мгновенно, то состояния сущностей в сервисах могут отличаться: данные в сервисе, хранящем проекцию могут отставать.
Клиент посылает запрос на создание заказа, сервис order создает заказ в статусе “в ожидании” и возвращает идентификатор заказа клиенту. Все это он делает синхронно, а затем посылает асинхронное сообщение сервису Consumer и сервису Restaurant. Когда сообщение обрабатывается в сервисе Consumer, сервис Consumer валидирует данные и возвращает ответ сервису Order. Далее обрабатывается событие в сервисе Restaurant, он так же валидирует данные и возвращает ответ сервису Order. Сервис Order меняет статус заказа на “проверен”. Такой подход также обеспечивает слабую связанность компонентов и высокую отказоустойчивость. При создании заказа не посылается никакие синхронные запросы. В случае если один из компонентов окажется недоступным, то канал также буферизирует сообщения. Когда получатель будет доступен, все сообщения обработаются, заказ будет создан.
Данный подход чем-то напоминает сагу на основе оркестарции. Сага — это паттерн межсервисного взаимодействия, состоит он из локальных транзакций. При выполнении локальной транзакции порождаются события/команды, которые в дальнейшем также порождают выполнение следующей локальной саги.
Сложности подхода “Ответ клиенту до полной обработки”:
- сложность реализации
- сложность тестирования
- сложность отладки
- сложный клиент
Может возникнуть вопрос “А где же внешние сервисы?”
На самом деле правила, которые применимы к повышению отказоустойчивости системы при взаимодействии с внешними сервисами, такие же как и при взаимодействии с внутренними сервисами. Однако здесь могут быть ограничения:
- У внешнего сервиса может отсутствовать асинхронное API
- Отсутствует контроль. Если внешний сервис оказался недоступен, а архитектура вашего приложения завязана на синхронный обмен с вашим сервисом, то ваше приложение может быть также недоступно или какие-то сценарии его использования могут быть недоступны
- Внешняя сеть. Логично, что внешнее приложение находится во внешней сети, может даже находиться на большом географическом расстоянии, что может накладывать также дополнительные расходы на взаимодействие с ним. Поэтому взаимодействие с внешним сервисом нужно минимизировать и изолировать. Рассмотрим на примере, каким образом это можно сделать.
Можно создать заказ синхронно, а затем синхронно послать данные на сервис Analytics.
Здесь может быть несколько проблем.
Сервис Analytics может оказаться недоступным, тогда непонятно, что делать с заказом: нам либо нужно отменить создание заказа и вернуть ошибку, либо же мы игнорируем недоступность сервиса Analytics, тогда в этом случае теряется часть данных.
Допустим мы выбираем второй сценарий, так как считаем, что логирование никак не должно влиять на функционал нашего сервиса. Возникает другая проблема: что, если сервис Analytics будет проявлять высокую латентность, то есть долго обрабатывать запросы, в этом случае наше время ответа клиенту тоже возрастет. И даже может получиться так, что заказ будет создан, но так как запрос сервис Analytics обрабатывал долго, клиент получил ответит со статусом 504, хотя заказ был успешно создан.
Следует также учесть, что запросы должны обрабатываться быстро, если они будут обрабатывать медленно, то у нашего сервиса на PHP могут возникнуть проблемы. Например, можно упереться в ограничение очереди запросов PHP-FPM. Либо часть запросов в очереди просто отваливается по тайм-ауту, потому что они не дождались обработки, так как PHP-FPM долго обрабатывает запросы. Либо может закончиться пул соединений с базой данных.
PHP фреймворки при выполнении запросов открывают соединения с базой данных, это соединение продолжает висеть на протяжении всего цикла обработки запроса. Чем дольше обрабатывается запрос, тем дольше это соединение остаётся открытым. Поэтому, если возникнет большая нагрузка на приложение, то мы можем получить отказ в обслуживании.
По умолчанию HTTP клиент (например Guzzle) никак не ограничивает по времени свои запросы. Очевидно, что нужно время запроса ограничить тайм-аутом. Какой тайм-аут выбрать лучше? Если выберем слишком маленький, то часть данных мы можем потерять. Если большой, то ситуация может не измениться. Если мы выберем в секунду, то проблемы с отказоустойчивостью у нас могут все равно остаться, если у нас высоконагруженное приложение. Какие же здесь есть варианты? Можно заменить синхронное взаимодействие, на асинхронное. Например, можно изолировать синхронный вызов к внешнему сервису с помощью асинхронной очереди команд или запросов.
В данном случае команда — это действие по сохранению данных сервиса Analytics.
Можно сделать по-другому. На каждую команду сделать свой Worker и их запускать параллельно. Получится так, что каждый Worker будет занимать соединение с базой данных и на N клиентских запросов, будет создано N воркеров. Таким образом соединения с базой данных будут расходоваться еще быстрее, что может быть критично.
В случае с очередью команд, такой проблемы не возникает.
Команды выполняются последовательно. Worker один и занимает одно соединение с базой данных, если даже команда обрабатывается долго, то в этом случае пул соединений с базой данных не будет исчерпан.
Рассмотрим, как можно реализовать асинхронное взаимодействие.
Клиент присылает запрос на создание заказа. Создаётся заказ и вместе с ним создаётся команда по логированию данных в сервис аналитики. При публикации команды в базу данных она сохраняется в одной транзакции с заказом. Далее команда ретранслируется в брокер сообщений и возвращается ответ клиенту. Сохранять команду в базу нужно, если необходимо гарантировать доставку данных в сервис аналитики. Этот подход называется transactional outbox.
С изменением модели в базу данных в отдельную таблицу (OUTBOX) сохраняются сообщения, события или команды. Дальше эти сообщения ретранслируются в брокер сообщений. Способов ретрансляции может быть множество: синхронный вызов после того как данные были сохранены либо это может быть асинхронный воркер, который в фоне вытаскивает новые команды и просто их перенаправляет в брокер сообщений или какой-то другой способ. Дальше брокер сообщений доставляет сообщение получателю.
Если сделать по-другому, например, сохранить заказ в базу данных, затем попытаться опубликовать команду сразу в брокер сообщений, то в этом случае, если брокер сообщений окажется недоступен, мы переходим в ситуацию синхронного взаимодействия. Нам нужно будет отменять заказ, либо мы теряем часть данных.
После того, как команды попадут в брокер сообщений, они обработаются последовательно. В рамках выполнения команды можно послать синхронный запрос к внешнему сервису, этот синхронный вызов не будет влиять на наше приложение. После того, как данные будут переданы, команда завершится.
В случае если сервис Analytics недоступен, данные переданы не будут, команда просто повторится позднее. Таким образом можно изолировать взаимодействие с внешними сервисами в асинхронном обработчике и внешний сервис не будет влиять на работу нашего приложения.
Подведем итог.
Способы повышения отказоустойчивости:
- Репликация данных, например, на основе асинхронных событий
- Асинхронное взаимодействие или саги
- Изолировать внешний сервис. Например, можно изолировать в асинхронном обработчике синхронный вызов, если во внешнем сервисе нет асинхронного API
- Transactional outbox. Используется для гарантии доставки данных во внешний сервис
- Не забываем про тайм-ауты. HTTP-клиент по умолчанию не выставляет никакой тайм-аут, про это часто забывают и часто это является более распространенной ошибкой, которая приводит к проблемам
И напоследок хочу посоветовать книгу “Микросервисы. Паттерны разработки и рефакторинга” Крис Ричардсон. В ней хорошо расписаны теоретические вопросы, касающиеся синхронного и асинхронного взаимодействия, команд, очередей, саг и многое другое.
Отказоустойчивое взаимодействие с внешними сервисами
В этой статье я расскажу про то, как можно организовать отказоустойчивое взаимодействие с внешними сервисами. Тема актуальная, очень часто из-за недоступности какого-то одного компонента может...
habr.com