Чтобы уверенно пересечь незнакомую местность, можно или двигаться быстрее, или подыскивать удобную дорожку. Другими словами, слишком пристальное внимание к скорости как таковой может вас притормозить. То же касается и разработки программного обеспечения.
В нашей лаборатории примерно с 2010 года бушуют противоречивые дебаты, которые сводятся к следующему вопросу:
Так что да, обычный Python намного медленнее, чем Fortran.
Однако это сравнение не имеет особого смысла, поскольку использование Python в научных вычислениях зависит не от Python как такового. В данном случае Python используется в качестве связующего слоя, опираясь на скомпилированные оптимизированные пакеты, которые он интегрирует для выполнения намеченных вычислений. Наиболее распространенным пакетом для научных вычислений, вероятно, является NumPy – эта аббревиатура означает Numerical Python. Как следует из названия, именно с помощью этого пакета, а не на обычном Python обрабатываются численные данные. Вся тяжелая работа выполняется за кулисами, при помощи скомпилированных процедур на C/C++ или Fortran. По сути, Python используется для того, чтобы указать быстрой процедуре правильное направление (т. е. правильный адрес памяти), и не более того.
Поэтому для оценки производительности научных вычислений нужен именно такой подход. Следующая диаграмма дана в качестве примера и позволяет убедиться, , что NumPy на 2 порядка быстрее, чем чистый Python. Как видите, существуют и другие пакеты, которые можно применить при необходимости, если требуется еще сильнее сократить издержки.
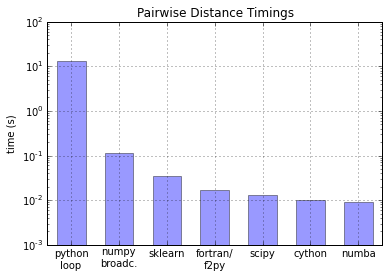
Так можно сократить издержки интерпретируемого подхода на 2–3 порядка, приближая его по скорости к тому же классу решений, что реализуются на компилируемых языках. скомпилированным решениям. Конечно, существуют и более точные сравнения, подробнее ознакомиться с ними можно вот тут.
При правильном использовании Python работает лишь немного медленнее, чем скомпилированный код.
Ладно, как бы то ни было, новичкам Python нравится больше, чем Fortran. Это также обусловлено многими прикладными возможностями, не связанными с наукой, особенно разработкой , веб-приложений. В нашем деле не этими вещами руководствуются при принятии решений. Гораздо важнее – приспособленность задачи к высокопроизводительным вычислениям (HPC).
Программы для HPC сегодня опираются на широкий спектр подходов, включая традиционные монолитные скомпилированные базы кода (в основном на Fortran и C++), подходы с генерацией кода (также известные как DSL) и гибридные интерпретируемые/компилируемые подходы. Последняя категория в настоящее время включает несколько серьезных ведущих игроков, в частности, FEniCS, которые, как было показано, хорошо масштабируются, от нескольких сотен до десятков тысяч обычных и даже графических процессоров.
Однако, насколько известно авторам данной статьи, ни один из претендентов, включая попытки Python / HPC, не наработал достаточно широкого сообщества и не достиг зрелости, чтобы захватить лидерство на глобальной сцене HPC. Так что на данный момент, вероятно, надежнее поставить на оба варианта:
Несколько лет спустя, примерно в 2016 году, Боб переписал тот же инструмент на Python. Взялся он за это по той простой причине, что в течение нескольких лет его младшие коллеги многое делали на Python. Между тем, их результаты на Fortran и Tcl/Tk постоянно разочаровывали его. В частности, Projector на Fortran никто, кроме Боба практически не понимал и, соответственно, поддерживать его оставалось только Бобу.
Боб расценивал Python как хлопотный язык где ни единого отступа пропустить нельзя считал его уделом всякой шпаны, которая всегда норовит затравить тебя «это не по-питонски» — и при этом смотреть на тебя как прозревший на слепого. Короче говоря, он был взбешен…
Боб заморочился, но впихнул эти 1,5 тысячи строк кода Fortran, в NumPy (и немного в SciPy) – а ведь какого труда и скольких лет стоило полностью проверить этот код. Инструмент Projector проецирует тысячи многоперфорационных отверстий, покрывающих поверхность жаровой трубы, вкладыша камеры сгорания на оболочку сложной 3D-формы, состоящей из миллионов многоугольников. Можете себе представить, насколько это трудоемкая задача.

Некоторое время спустя Боб обнаружил, что после того, как он поместил структуры данных в NumPy, в таких пакетах, как SciPy, ему стали доступны многие уже готовые и оптимизированные функции, облегчающие решение задачи. Просматривая документацию, он нашел несколько полезных инструментов для обращения с 3D-точками, включая интеллектуальное представление данных, называемое K-d-дерево. Реализация была настолько проста, что за полдня н ней можно было протестировать дюжину проекционных потоков задач, закончив простой проекцией возвратно-поступательного движения с двумя объектами SciPy Kdtree, одним для представления сетчатой оболочки и одним для представления сверл.
Возможно, это открытие так и осталось бы на компьютере Боба, если бы он не оформил код в дистрибутив, который можно было распространять среди конечных пользователей. В данном случае это были инженеры, работающие над кластерами HPC, где контейнеры до сих пор редкость редки, установка системы – медленный и кропотливый процесс, ложащийся на плечи IT-отдела, а доступа в Интернет нет. Таким образом, несмотря на то, что у Python определенно не лучшим образом организован конвейер распространения, Боб был очень доволен, что распространение интерпретируемого кода (к счастью, базовые скомпилированные библиотеки, такие как NumPy, имелись в наличии прямо в этих кластерах) оказалось очень простым, и весь продакшен-код удалось быстро заменить..
Затем пришло время сравнить две версии: работающую на основе простого перебора (Fortran) и на основе KD-дерева (Python / NumPy / SciPy). Боб выбрал большой репрезентативный тестовый пример:
") . KDTree – это структура данных, предназначенная для поиска именно такого рода, со сложностью O(log). А когда n у вас равно 1 миллиарду, применяемые алгоритмы гораздо важнее, чем простая производительность языка.
. KDTree – это структура данных, предназначенная для поиска именно такого рода, со сложностью O(log). А когда n у вас равно 1 миллиарду, применяемые алгоритмы гораздо важнее, чем простая производительность языка.
Так что да, Fortran был бы быстрее для той же реализации. Программисты с достаточными базовыми навыками в информатике могут здесь оскорбиться: разве проблема не в том, что Боб просто должен знать базовые структуры данных своего языка? Так и есть, но Боб, как и многие люди, которые полагаются на научные вычисления, не является экспертом в области информатики. У него докторская степень в области численного моделирования сжимаемых турбулентных реактивных потоков. Это уже достаточно обширные знания, которые нужно как-то выразить на уровне программного обеспечения. Боб, как и многие другие, не потратил пару лет на изучение информатики как таковой. И он никогда бы не попробовал этот алгоритм, если бы цеплялся за Fortran (он должен был это сделать, как предложил в своем комментарии Ivan Pribec , но он этого не сделал, и в этом суть). Пробуксовка, возникшая в связи с изучением новых алгоритмов и структур данных в экосистеме Fortran, оказалась просто слишком велика.
По определению, более высокоуровневый язык позволит проводить больше исследований. В случае Боба первоначальная версия программы на Fortran работала как часы. Не было особой необходимости ломать реализацию, вставлять дерево локализации (octree или kd tree) и смотреть, насколько удастся упростить точечный трафарет, не жертвуя результатом. Другими словами, инвестиции намечались серьезные, но никакой отдачи они не гарантировали. Переходя на Python, удалось, образно говоря, «сократить первый взнос». Конечно, если наилучший алгоритм известен заранее или у вас много человеко-часов, то сравнительно низкоуровневый язык будет работать быстрее, но в реальной жизни такое случается редко.
Приведу цитату авторитетного программиста, Стива Макконнела. Она подтверждает, что , эта проблема всплывает во многих дискуссиях о сравнении высокоуровневыз и низкоуровневых языков:
Однако, как вы узнаете на любом курсе по алгоритмам и как показано в исследованном выше практическом случае, скорость ничего не значит, если подобранный вами алгоритм не подходит для решения задачи. И чтобы такой алгоритм уверенно подобрать, иногда нужно немного сбросить скорость, чтобы взамен приобрести гибкость.
Поэтому в следующий раз, когда подыщете инструмент для программирования научных вычислений, спросите себя: а в самом ли деле я смогу выбрать и реализовать эффективный алгоритм для него? Если сможете, то компилируемый язык обеспечит вам наилучшую производительность. Если нет, то стоит потратить немного времени на изучение гибкого языка, который высвободит вам время для освоения алгоритмов. Именно при помощи качественных алгоритмов вы можете добиться молниеносного функционирования вашего инструмента.
ДИСКЛЕЙМЕР: Тысяча извинений; возможно, этот текст, получился довольно несправедливым по отношению к современному Fortran. Он действительно посвящен «нашему» внутрикорпоративному подходу к Fortran, а мы отягощены многолетним багажом унаследованного кода, буквально миллионами не слишком современных инструкций Fortran и душными правилами обращения с кластерами HPC, где ты сам не администрируешь сеть и не имеешь выхода в Интернет. Следите за свежими дискуссиями о современном Fortran, читайте Fortran Discourse
Этот пост спровоцировал долгую дискуссию в сообществе Fortran. Читателю настоятельно рекомендуется просмотреть эту дискуссию в выделенной ветке.

 habr.com
habr.com
В нашей лаборатории примерно с 2010 года бушуют противоречивые дебаты, которые сводятся к следующему вопросу:
Формулировки расплывчаты, что способствует клановой розни между пользователями, обусловленной в большей степени привычками, чем основанные на объективных оценках двух подходов. Давайте попробуем обозначить некоторые основы для достижения взаимопонимания, конкретизировав этот вопрос.«Почему все больше и больше научных вычислений, критичных по времени, ранее выполнявшихся на Fortran, теперь пишутся на Python, более медленном языке?»
«Python, более медленный язык»
Python имеет репутацию медленного языка, то есть, он работает значительно медленнее, чем компилируемые языки, такие как Fortran, C или Rust. Если вы слышали такое, вы не одиноки: просто погуглите «почему Python медленный» — и получите кучу страниц по этой теме. Проблема восходит к фундаментальному аспекту Python: это интерпретируемый язык. Это влечет значительные издержки при выполнении каждой инструкции, что приводит к замедлению масштабных вычислений. Это было бы справедливо для любого интерпретируемого языка, в том числе, например, для Perl или Ruby.Так что да, обычный Python намного медленнее, чем Fortran.
Однако это сравнение не имеет особого смысла, поскольку использование Python в научных вычислениях зависит не от Python как такового. В данном случае Python используется в качестве связующего слоя, опираясь на скомпилированные оптимизированные пакеты, которые он интегрирует для выполнения намеченных вычислений. Наиболее распространенным пакетом для научных вычислений, вероятно, является NumPy – эта аббревиатура означает Numerical Python. Как следует из названия, именно с помощью этого пакета, а не на обычном Python обрабатываются численные данные. Вся тяжелая работа выполняется за кулисами, при помощи скомпилированных процедур на C/C++ или Fortran. По сути, Python используется для того, чтобы указать быстрой процедуре правильное направление (т. е. правильный адрес памяти), и не более того.
Поэтому для оценки производительности научных вычислений нужен именно такой подход. Следующая диаграмма дана в качестве примера и позволяет убедиться, , что NumPy на 2 порядка быстрее, чем чистый Python. Как видите, существуют и другие пакеты, которые можно применить при необходимости, если требуется еще сильнее сократить издержки.
Так можно сократить издержки интерпретируемого подхода на 2–3 порядка, приближая его по скорости к тому же классу решений, что реализуются на компилируемых языках. скомпилированным решениям. Конечно, существуют и более точные сравнения, подробнее ознакомиться с ними можно вот тут.
При правильном использовании Python работает лишь немного медленнее, чем скомпилированный код.
«Все больше и больше»
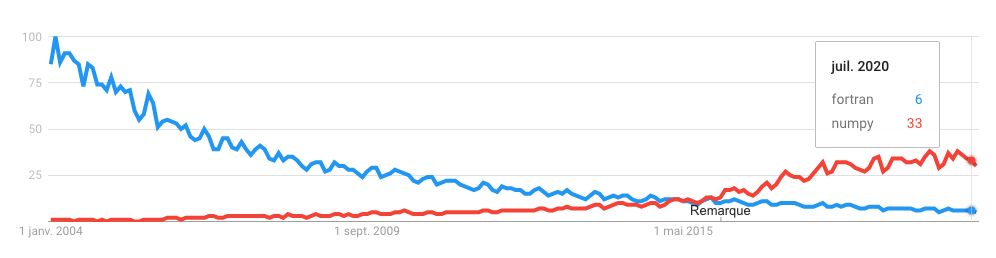
Можно ли измерить популярность? Одним из ее индикаторов являются показатели Google trends по запросам «fortran» и «numpy». Fortran действительно медленно сдает позиции и отстает от NumPy с 2015 года. Однако отнеситесь к этой цифре с недоверием, поскольку растущий интерес к NumPy обусловлен сильной зависимостью молодых программистов и разработчиков Python в целом от веб-ресурсов.
Ладно, как бы то ни было, новичкам Python нравится больше, чем Fortran. Это также обусловлено многими прикладными возможностями, не связанными с наукой, особенно разработкой , веб-приложений. В нашем деле не этими вещами руководствуются при принятии решений. Гораздо важнее – приспособленность задачи к высокопроизводительным вычислениям (HPC).
Вычисления, критичные по времени
Конкуренция между программными подходами относительно высокопроизводительных вычислений никогда не была такой ожесточенной, как сегодня. Одна конкретная проблема возникает из-за устройства среды HPC, которая очень специфична, поэтому софт общего назначения под нее не оптимизируют. В качестве примера возьмем контейнерную технологию (например, Docker), которая уже повсеместно распространилась во многих софтверных конфигурациях, но по-прежнему довольно сырая в контексте HPC. Это также справедливо для определенных языков, таких как Rust, которые тепло восприняты в сообществе C / C++, но по-прежнему имеют недостаточно полноценную библиотечную экосистему для НРС.Программы для HPC сегодня опираются на широкий спектр подходов, включая традиционные монолитные скомпилированные базы кода (в основном на Fortran и C++), подходы с генерацией кода (также известные как DSL) и гибридные интерпретируемые/компилируемые подходы. Последняя категория в настоящее время включает несколько серьезных ведущих игроков, в частности, FEniCS, которые, как было показано, хорошо масштабируются, от нескольких сотен до десятков тысяч обычных и даже графических процессоров.
Однако, насколько известно авторам данной статьи, ни один из претендентов, включая попытки Python / HPC, не наработал достаточно широкого сообщества и не достиг зрелости, чтобы захватить лидерство на глобальной сцене HPC. Так что на данный момент, вероятно, надежнее поставить на оба варианта:
- поддержание наших флагманских баз кода Fortran / C++ / C на плаву. Дедовские активы.
- обкатка нескольких из этих новых подходов (например, на основе Python) в прикладных контекстах.
Есть ли у Python шансы с ними потягаться?
До сих пор вполне оправдан был бы вопрос:Хороший вопрос! И все же, в некоторых ситуациях питонщики готовы поспорить, что «скорость» не всегда определяется на примере реализации одного и того же алгоритма, только на разных языках. Чтобы понять почему, рассмотрим пример.«Fortran очень быстр и хорошо подходит для платформ с HPC. Python немного медленнее, требует изучить сразу несколько многоуровневых пакетов и не всегда уместен в контексте научных вычислений. С какой стати кому-то переходить на Python?»
История пользователя: один и тот же автор, два языка
В Cerfacs примерно в 2010 году был разработан инструмент под названием Projector. Написан он был программистом, работающим только на Fortran. Давайте назовем его Бобом.Несколько лет спустя, примерно в 2016 году, Боб переписал тот же инструмент на Python. Взялся он за это по той простой причине, что в течение нескольких лет его младшие коллеги многое делали на Python. Между тем, их результаты на Fortran и Tcl/Tk постоянно разочаровывали его. В частности, Projector на Fortran никто, кроме Боба практически не понимал и, соответственно, поддерживать его оставалось только Бобу.
Боб расценивал Python как хлопотный язык где ни единого отступа пропустить нельзя считал его уделом всякой шпаны, которая всегда норовит затравить тебя «это не по-питонски» — и при этом смотреть на тебя как прозревший на слепого. Короче говоря, он был взбешен…
Боб заморочился, но впихнул эти 1,5 тысячи строк кода Fortran, в NumPy (и немного в SciPy) – а ведь какого труда и скольких лет стоило полностью проверить этот код. Инструмент Projector проецирует тысячи многоперфорационных отверстий, покрывающих поверхность жаровой трубы, вкладыша камеры сгорания на оболочку сложной 3D-формы, состоящей из миллионов многоугольников. Можете себе представить, насколько это трудоемкая задача.
Некоторое время спустя Боб обнаружил, что после того, как он поместил структуры данных в NumPy, в таких пакетах, как SciPy, ему стали доступны многие уже готовые и оптимизированные функции, облегчающие решение задачи. Просматривая документацию, он нашел несколько полезных инструментов для обращения с 3D-точками, включая интеллектуальное представление данных, называемое K-d-дерево. Реализация была настолько проста, что за полдня н ней можно было протестировать дюжину проекционных потоков задач, закончив простой проекцией возвратно-поступательного движения с двумя объектами SciPy Kdtree, одним для представления сетчатой оболочки и одним для представления сверл.
Возможно, это открытие так и осталось бы на компьютере Боба, если бы он не оформил код в дистрибутив, который можно было распространять среди конечных пользователей. В данном случае это были инженеры, работающие над кластерами HPC, где контейнеры до сих пор редкость редки, установка системы – медленный и кропотливый процесс, ложащийся на плечи IT-отдела, а доступа в Интернет нет. Таким образом, несмотря на то, что у Python определенно не лучшим образом организован конвейер распространения, Боб был очень доволен, что распространение интерпретируемого кода (к счастью, базовые скомпилированные библиотеки, такие как NumPy, имелись в наличии прямо в этих кластерах) оказалось очень простым, и весь продакшен-код удалось быстро заменить..
Затем пришло время сравнить две версии: работающую на основе простого перебора (Fortran) и на основе KD-дерева (Python / NumPy / SciPy). Боб выбрал большой репрезентативный тестовый пример:
- 1 миллиард клеток;
- 10 миллионов мультиперфорированных граничных узлов;
- 18 тысяч отверстий.
Сравниваем скорость и гибкость
Что здесь произошло на самом деле? Что ж, основная операция Projector включает в себя поиск точек в трехмерном облаке точек. Программа на Fortran решила задачу, просмотрев массив облака точек, такой поиск имеет сложность O. KDTree – это структура данных, предназначенная для поиска именно такого рода, со сложностью O(log). А когда n у вас равно 1 миллиарду, применяемые алгоритмы гораздо важнее, чем простая производительность языка.Так что да, Fortran был бы быстрее для той же реализации. Программисты с достаточными базовыми навыками в информатике могут здесь оскорбиться: разве проблема не в том, что Боб просто должен знать базовые структуры данных своего языка? Так и есть, но Боб, как и многие люди, которые полагаются на научные вычисления, не является экспертом в области информатики. У него докторская степень в области численного моделирования сжимаемых турбулентных реактивных потоков. Это уже достаточно обширные знания, которые нужно как-то выразить на уровне программного обеспечения. Боб, как и многие другие, не потратил пару лет на изучение информатики как таковой. И он никогда бы не попробовал этот алгоритм, если бы цеплялся за Fortran (он должен был это сделать, как предложил в своем комментарии Ivan Pribec , но он этого не сделал, и в этом суть). Пробуксовка, возникшая в связи с изучением новых алгоритмов и структур данных в экосистеме Fortran, оказалась просто слишком велика.
По определению, более высокоуровневый язык позволит проводить больше исследований. В случае Боба первоначальная версия программы на Fortran работала как часы. Не было особой необходимости ломать реализацию, вставлять дерево локализации (octree или kd tree) и смотреть, насколько удастся упростить точечный трафарет, не жертвуя результатом. Другими словами, инвестиции намечались серьезные, но никакой отдачи они не гарантировали. Переходя на Python, удалось, образно говоря, «сократить первый взнос». Конечно, если наилучший алгоритм известен заранее или у вас много человеко-часов, то сравнительно низкоуровневый язык будет работать быстрее, но в реальной жизни такое случается редко.
Приведу цитату авторитетного программиста, Стива Макконнела. Она подтверждает, что , эта проблема всплывает во многих дискуссиях о сравнении высокоуровневыз и низкоуровневых языков:
«Программисты, использующие языки высокого уровня, достигают более высокой производительности и создают более качественный код, чем программисты, работающие с языками низкого уровня. Утверждается, что при работе с такими языками, как C++, Java, Smalltalk и Visual Basic, производительность труда программистов, а также надежность, простота и понятность программ в 5–15 раз выше, чем при использовании низкоуровневых языков, таких как ассемблер и C (Brooks, 1987; Jones, 1998; Boehm, 2000). Избавившись от необходимости проводить праздничную церемонию каждый раз, когда оператор языка C делает то, что было задумано» ”.
― Стив Макконнелл, Code Complete.
Основные выводы
В мире компьютерных наук много внимания уделяется скорости выполнения по сравнению с рабочим временем программиста, необходимым для выполнения задачи. В научных вычислениях существует сильная тенденция переоценивать важность времени выполнения, поэтому основное внимание уделяется скорости.Однако, как вы узнаете на любом курсе по алгоритмам и как показано в исследованном выше практическом случае, скорость ничего не значит, если подобранный вами алгоритм не подходит для решения задачи. И чтобы такой алгоритм уверенно подобрать, иногда нужно немного сбросить скорость, чтобы взамен приобрести гибкость.
Поэтому в следующий раз, когда подыщете инструмент для программирования научных вычислений, спросите себя: а в самом ли деле я смогу выбрать и реализовать эффективный алгоритм для него? Если сможете, то компилируемый язык обеспечит вам наилучшую производительность. Если нет, то стоит потратить немного времени на изучение гибкого языка, который высвободит вам время для освоения алгоритмов. Именно при помощи качественных алгоритмов вы можете добиться молниеносного функционирования вашего инструмента.
ДИСКЛЕЙМЕР: Тысяча извинений; возможно, этот текст, получился довольно несправедливым по отношению к современному Fortran. Он действительно посвящен «нашему» внутрикорпоративному подходу к Fortran, а мы отягощены многолетним багажом унаследованного кода, буквально миллионами не слишком современных инструкций Fortran и душными правилами обращения с кластерами HPC, где ты сам не администрируешь сеть и не имеешь выхода в Интернет. Следите за свежими дискуссиями о современном Fortran, читайте Fortran Discourse
Этот пост спровоцировал долгую дискуссию в сообществе Fortran. Читателю настоятельно рекомендуется просмотреть эту дискуссию в выделенной ветке.
Парадоксальный рост популярности Python в научных вычислениях
Чтобы уверенно пересечь незнакомую местность, можно или двигаться быстрее, или подыскивать удобную дорожку. Другими словами, слишком пристальное внимание к скорости как таковой может вас притормозить....
habr.com