Как-то в процессе работы возник вопрос как на корпоративном домене в Яндексе выгрузить все контакты организации из адресной книги Яндекс.почты в файл .csv или .xls, чтобы было красиво и потом удобно работать с этими данными в MS Excel.
Оказывается, что стандартными средствами Яндекс.почты можно выгрузить только в Vcard формат, что мне совсем не подходит. Нужно потом его как-то конвертировать сторонними средствами. Такие попадались на просторах интернета, что совсем неудобно.
На помощь пришел Python.
C помощью библиотеки BeautifulSoup очень удобно и быстро парсить html и вынимать всю нужную нам информацию.
Для парсинга нам понадобится Python 3, библиотека BeautifulSoup и браузер с инспектором кода.
Для начала импортируем необходимые для работы библиотеки.
from bs4 import BeautifulSoup as BS
import re
import csv
В результате анализа кода страницы выявлено, что данные которые нам нужны спрятаны в тегах span с классами:

mail-AbookEntry-Contact - содержит имя контакта
mail-AbookEntry-Emails - содержит список Email-ов
mail-AbookEntry-Phones - телефоны
Сохраняем нашу веб страницу на диск в папку со скриптом, я назвал ее просто “contacts.html”. Если в адресной книге много контактов, то перед сохранением не забываем нажать “Показать все контакты” в конце страницы.
Открываем сохраненную страницу и получаем весь код внутри тегов span, сохраняя их в три списка:
with open('contacts.html', 'r', encoding='utf-8') as f:
html_str = f.read()
res = BS(html_str, features="lxml")
#список с именами
l_contacts = res.findAll('span', class_='mail-AbookEntry-Contact')
#список с Emailами
l_emails = res.findAll('span', class_='mail-AbookEntry-Emails')
#список с телефонами
l_phones = res.findAll('span', class_='mail-AbookEntry-Phones')
#Объединяем в один большой список с которым и будем дальше работать
l_res = list(zip(l_contacts, l_emails, l_phones))
Каждый элемент списка l_res это список с кусочками кода с нашей страницы, соответствующий строке с контактом.
 3 группы, которые содержит элемент-список результирующего списка l_res
3 группы, которые содержит элемент-список результирующего списка l_res
Пробегаем циклом по нашему списку l_res:
for i in l_res:
l_row_contact=[] #список, в который будут записываться данные о контакте (имя, емейлы, телефон) для записи в файл .csv
Так как i элемент это тоже список, содержащий группы, показанные выше на рисунке, то проходим по всем элементам этого списка.
for j in i:
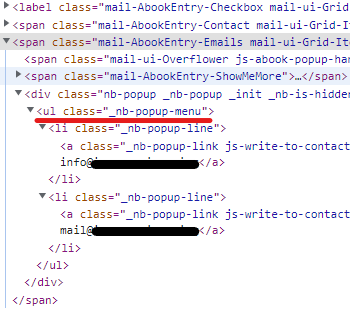
Может быть такое, что у контакта несколько Email-ов. В коде они хранятся в списке ul с классом _nb-popup-menu, а каждый email обернут в теги li и a.
 #Если существует список дополнительных емейлов у контакта, то извлекаем емейлы и сохраняем в список l_a
#Если существует список дополнительных емейлов у контакта, то извлекаем емейлы и сохраняем в список l_a
if j.find('ul', class_='_nb-popup-menu') is not None:
Для начала находим и получаем содержимое тегов li:
l_li = j.findAll('li', class_='_nb-popup-line')
l_a=[]
Пробегаем по каждому полученному li и извлекаем текст Email, обернутый в тег a с классом _nb-popup-link
for k in l_li:
if k.find('a', class_='_nb-popup-link') is not None:
l_a.append(k.find('a', class_='_nb-popup-link').text)
Добавляем к результирующему списку с данными о контакте строку с разделителями \r\n, чтобы в ячейке был перенос, если несколько email-ов.
l_row_contact.append('\r\n'.join(l_a))
#если доп списка нет, то просто извлекаем все данные по контакту
elif j.find('span', class_='mail-ui-Overflower') is not None:
l_row_contact.append(j.find('span', class_='mail-ui-Overflower').text)
В результате одного прохода мы получаем список со строками следующего формата:
[ ‘Имя контакта’, ‘Email_1\r\nEmail_2…Email_k’, ‘Телефон’ ]
#записываем строку с данными контакта в файл csv
with open('contacts.csv','a') as f:
file_writer = csv.writer(f, delimiter = ";", lineterminator="\r")
file_writer.writerow(['Имя', 'Emails', 'Телефон'])
file_writer.writerow(l_row_contact)
Я использую разделитель ‘;’ только, чтобы при открытии было красиво в Excel.
И так проходим по всему списку, дописывая в файл CSV строки с данными о контактах.
Если использовать разделитель ‘,’ и убрать дополнительные Email-ы в получившемся файле, то можно импортировать всё в Outlook.
Код проекта вы можете посмотреть и скачать на GitHub.

 habr.com
habr.com
Оказывается, что стандартными средствами Яндекс.почты можно выгрузить только в Vcard формат, что мне совсем не подходит. Нужно потом его как-то конвертировать сторонними средствами. Такие попадались на просторах интернета, что совсем неудобно.
На помощь пришел Python.
C помощью библиотеки BeautifulSoup очень удобно и быстро парсить html и вынимать всю нужную нам информацию.
Для парсинга нам понадобится Python 3, библиотека BeautifulSoup и браузер с инспектором кода.
Для начала импортируем необходимые для работы библиотеки.
from bs4 import BeautifulSoup as BS
import re
import csv
В результате анализа кода страницы выявлено, что данные которые нам нужны спрятаны в тегах span с классами:
mail-AbookEntry-Contact - содержит имя контакта
mail-AbookEntry-Emails - содержит список Email-ов
mail-AbookEntry-Phones - телефоны
Сохраняем нашу веб страницу на диск в папку со скриптом, я назвал ее просто “contacts.html”. Если в адресной книге много контактов, то перед сохранением не забываем нажать “Показать все контакты” в конце страницы.
Открываем сохраненную страницу и получаем весь код внутри тегов span, сохраняя их в три списка:
with open('contacts.html', 'r', encoding='utf-8') as f:
html_str = f.read()
res = BS(html_str, features="lxml")
#список с именами
l_contacts = res.findAll('span', class_='mail-AbookEntry-Contact')
#список с Emailами
l_emails = res.findAll('span', class_='mail-AbookEntry-Emails')
#список с телефонами
l_phones = res.findAll('span', class_='mail-AbookEntry-Phones')
#Объединяем в один большой список с которым и будем дальше работать
l_res = list(zip(l_contacts, l_emails, l_phones))
Каждый элемент списка l_res это список с кусочками кода с нашей страницы, соответствующий строке с контактом.
Пробегаем циклом по нашему списку l_res:
for i in l_res:
l_row_contact=[] #список, в который будут записываться данные о контакте (имя, емейлы, телефон) для записи в файл .csv
Так как i элемент это тоже список, содержащий группы, показанные выше на рисунке, то проходим по всем элементам этого списка.
for j in i:
Может быть такое, что у контакта несколько Email-ов. В коде они хранятся в списке ul с классом _nb-popup-menu, а каждый email обернут в теги li и a.
if j.find('ul', class_='_nb-popup-menu') is not None:
Для начала находим и получаем содержимое тегов li:
l_li = j.findAll('li', class_='_nb-popup-line')
l_a=[]
Пробегаем по каждому полученному li и извлекаем текст Email, обернутый в тег a с классом _nb-popup-link
for k in l_li:
if k.find('a', class_='_nb-popup-link') is not None:
l_a.append(k.find('a', class_='_nb-popup-link').text)
Добавляем к результирующему списку с данными о контакте строку с разделителями \r\n, чтобы в ячейке был перенос, если несколько email-ов.
l_row_contact.append('\r\n'.join(l_a))
#если доп списка нет, то просто извлекаем все данные по контакту
elif j.find('span', class_='mail-ui-Overflower') is not None:
l_row_contact.append(j.find('span', class_='mail-ui-Overflower').text)
В результате одного прохода мы получаем список со строками следующего формата:
[ ‘Имя контакта’, ‘Email_1\r\nEmail_2…Email_k’, ‘Телефон’ ]
#записываем строку с данными контакта в файл csv
with open('contacts.csv','a') as f:
file_writer = csv.writer(f, delimiter = ";", lineterminator="\r")
file_writer.writerow(['Имя', 'Emails', 'Телефон'])
file_writer.writerow(l_row_contact)
Я использую разделитель ‘;’ только, чтобы при открытии было красиво в Excel.
И так проходим по всему списку, дописывая в файл CSV строки с данными о контактах.
Если использовать разделитель ‘,’ и убрать дополнительные Email-ы в получившемся файле, то можно импортировать всё в Outlook.
Код проекта вы можете посмотреть и скачать на GitHub.
Парсинг контактов адресной книги Яндекс.почты в CSV на Python
Привет, Habr! Как-то в процессе работы возник вопрос как на корпоративном домене в Яндексе выгрузить все контакты организации из адресной книги Яндекс.почты в файл .csv или .xls, чтобы было красиво и...
habr.com