В декабре 2020 года я завершил работать в научном институте и сразу же увлёкся задачей добычи данных из соцсетей, в частности из Инстаграма. Прежде я работал только с готовыми данными, поэтому мне всегда было интересно, как эти данные можно добывать. За несколько дней до Нового Года я написал достаточно базовую статью про то как парсить Инст. В первых числах января мне написал заказчик и попросил сделать для него масштабный парсер инстаграма, который был бы способен делать более 10.000 запросов в сутки.
С тех пор прошло уже больше полугода, за которые я набил всевозможные шишки в данной области и написал промышленный парсер, который способен делать сотни тысяч, если не миллионы запросов в сутки.
В рамках данной статьи я хочу рассказать про путь развития своего Pet-Project в потенциально мощный и серьёзный инструмент. Впереди вас ждёт увлекательное путешествие от хранения данных в простых Json-ах на жестком диске сервера, до облачной базы данных и автоматической инициализации cron расписания запуска процессов внутри докер контейнера, поехали!
Задача была следующая. Дана группа пользователей (несколько тысяч), необходимо в режиме реального времени отслеживать, как они ставят лайки друг другу. То есть собирать лайки, которые пользователи из выбранной группы ставят внутри этой группы, и отдавать эту информацию в виде "потока лайков" в стандартизированном виде.
Далее эти лайки должны "копироваться" в блокчейн VIZ, чтобы инстаграмеры не просто так лайкали друг друга, а получали цифровой социальный капитал. Впрочем, этой частью сервиса занимались специалисты на стороне заказчика.
Ориентировочное количество лайков, которое моя система должна была собирать в день - порядка 10.000. Чувствуете масштаб?

Да, как вы ещё не раз убедитесь в процессе чтения, я люблю всё структурировать, поэтому ниже список разделов этой статьи:
Для начала предлагаю освежить в памяти, каким образом можно получить открытые данные из Инстаграма.
Если кратко, то я использовал библиотеку на питоне, которая извлекает данные путём отправления запросов к неофициальному API инстаграмма. Есть множество библиотек, работающих таким образом. В своём проекте я использовал instagrapi, пожалуй самую современную и удобную библиотеку.
Что такое неофициальное API инстаграма
Если кратко, то неофициальное API притворяется приложением Инстаграм на андроиде и в шапке запроса прописывает свои специальные плюшечки, сигнатуры и всякое прочее, почитать больше про то как работают запросы к API можно тут.
В начале разработки промышленного парсера я создал новый аккаунт в инстаграме, подписался на пару своих друзей и начал активно исследовать пропускной канал такого метода «добычи данных».
К моему огорчению, разработчики инстаграмма создали ряд инструментов, препятствующих безграничной выкачке данных. И после серии запросов аккаунт, через который проводятся запросы, банится. Особенно, Инстаграмм банит за периодические запросы, между которыми небольшая разница во времени, то есть когда очевидно, что эти действия производятся алгоритмом.
К слову, для себя я установил, что придерживаясь следующего подхода, вероятность аккаунта быть забаненным - минимальна:
Разобрались с тем, как проводить запросы с одного аккаунта. Дальше необходимо понять, как организовать параллельную работу группы аккаунтов.

«Параллельное программирование» - рано или поздно большинству разработчиков приходится столкнуться с этим страшным зверем. К сожалению, в моём вузе (МФТИ) курсы по параллельному программированию были крайне примитивными и не давали необходимого уровня экспертизы для создания крупных систем для продакшена.
Передо мной стояла задача организовать параллельный асинхронный процесс добычи данных несколькими исполнителями.
Мне пришла на ум следующая концепция - ввести два типа процессов:
Аккаунты для проведения запросов я планировал создавать вручную, но в итоге пришел к тому, что проще их купить, примерно 12 рублей за штуку - не такая высокая цена).
Стыдно даже рассказывать, с чего я начал, но раз уж пообещал повествование про свой путь, то дерзайте. Начинал я с крайне примитивного подхода в виде хранения данных в json на жестком диске. То есть исполнители получали задание в формате json файла со специальным названием, соответствующим исполнителю, делали необходимые запросы, и затем процесс менеджер собирал результаты работы в один большой json файл.
Достаточно быстро я понял, что такая схема работы выглядит уж больно криво и костыльно и без какой-нибудь базы данных мне не обойтись.
 Костыльное решение
Костыльное решение
Мне не хотелось разбираться со сложными базами данных и с SQL, так как это чрезмерно затянуло бы процесс разработки. Благо, мои партнёры по веб студии, молодые и заряженные ребята, подсказали мне продвинутый стек разработки. В частности меня познакомили с Firebase Realtime Database, сервисом компании Google, созданным для упрощения процесса разработки приложений. Представьте себе, NO SQL облачная база данных, доступная из любой точки мира, где есть интернет.
Прежде я писал про то, как "поженить" Firebase Realtime Database и Телеграм ботов. Тут можно почитать про основы работы с этой базой даных.
Основными преимуществами такой базы данных для меня было то, что все данные в ней хранятся в виде json дерева и то, что интерфейс взаимодействия с ней выглядит максимально просто. И что это всё работает с моим любимым питоном! (Python Firebase SDK). Во многом, помочь разобраться с базой данных мне помог этот туториал.
Прежде чем интегрировать новую для меня технологию в серьёзный проект я начал с «игрушечного проекта» (Да, Pet Project внутри Pet Project) и интегрировал Realtime Database в моего телеграмм бота, который делает синтаксический анализ предложений. Он был сделан в рамках другого моего проекта и там была необходимость запоминать предложения, на которых алгоритм работает плохо.
Что за проект
(Спойлер - что за проект) Тут я писал про то, что у нас за театральная постановка, к сожалению на данный момент её развитие приостановлено, так как я старался закончить мой вуз, параллельно работать и каким-то чудом не вылететь. А бот делает следующее - на вход он получает предложение, а на выходе даёт синтаксическое дерево для этого предложения и несколько вариантов «обрезки» дерева.
На нынешнем этапе обрезка работает достаточно просто и зачастую падает для сложных предложений. Однако дерево строится в большинстве случаев.
Основу этой архитектуры я придумал за один продуктивный вечер где-то в начале марта, расслаблено программируя с бокальчиком вина (а потом уже и с бутылкой). Впоследствии я добавлял некоторые коллекции и разделы для более эффективной работы системы, либо для более гибкой её настройки.
Начнём с самых базовых структур, которые я использовал в этом проекте
User
user = {
'last_check': время последней проверки пользователя,
'last_post_published': время публикации самого свежего поста,
'likes_given': кол-во лайков, которое пользователь
отдал внутри нашей базы пользователей,
'pk': идентификатор пользователя в инстаграме ,
'posts_published': [media_id] - массив идентификаторов
постов, опубликованных пользователем,
'username': юзернейм
}
Пример
user = {
'last_check': 1615762467.122444,
'last_post_published': 1615203615.0,
'likes_given': 0,
'pk': 1764766994,
'posts_published': [
'2503859905240423283_1764766994',
'2507722254816718688_1764766994',
'2512069674769873900_1764766994',
'2519219162844397865_1764766994',
'2524923983303827750_1764766994'],
'username': 'purplefront'
}
Post
post = {
"owner_id" : идентификатор владельца поста,
"media_id" : идентификатор поста,
"made_at" : время когда пост был выложен,
"last_check" : время последней проверки поста нашей системой,
"likes" : [like] - массив лайков
}
Пример
post = {
'last_check': 0,
'made_at': 1601198622,
'media_id': '2407350984285396491_3301663934',
'owner_id': 3301663934,
'likes' : [...]
}
Ноль в last_check означает что пост ещё ни разу не был проверен.
Стоит отметить, что в post.likes хранятся в принципе все лайки оставленные под постом (то есть не только внутри нашей базы данных).
Также стоит отметить, что никакое API инстаграмма, даже самое продвинутое и хакерское не отдает больше 999 лайков для поста.
Если на посте больше 999 лайков, то будут отданы 999 некоторых лайков из всех (при этом нигде нет гарантии, что это будут 999 последних лайков).
Like
like = {
'from': id пользователя, отдавшего лайк,
'media_id': id поста где стоит лайк,
'to': id пользователя, получившего лайк
}
Пример
like = {
'from': 28266009338,
'media_id': '2417619399940064811_1398989479',
'to': 1398989479
}
Коллекции
В корневом разделе базы данных Firebase Realtime Database хранится 6 коллекций (6 корневых разделов).
Данная структура хранит в себе все конфигурационные данные, необходимые для сбора лайков и добавления новых постов.
Сбор лайков может вестись параллельно и асинхронно несколькими исполнителями.
Конфигурационный файл исполнителя:
executor_config = {
'password': Пароль аккаунта исполнителя,
'proxy': SOCKS5 proxy,
'settings_dict': {...} - набор настроек для авторизации по куки
и прочей магии,
'username': Юзернейм аккаунта исполнителя,
'last_login_log' : Лог последней авторизации
}
Более детально:
executor_config = {
'password': 'pwd',
'proxy': 'socks5://username assword@iport',
assword@iport',
'settings_dict': {...},
'username': 'usrnm'
}
Last Login Log
Лог последней авторизации в случае успеха имеет вид
last_login_log = {
'success' : True или False,
'time' : время последней авторизации
}
В случае неспеха
last_login_log = {
'success' : False,
'time' : время последней авторизации,
'last_json' : последний ответ Instagram API,
}
last_json - Последний ответ Instagram API, по нему можно понять что пошло не так во время последнего запроса.
Settings Dict
Конфигурация API исполнителя. Содерджит в себе куки файл для более удобной авторизации (и менее опасной с точки зрения потенциальной возможности бана аккаунта).
Пример для купленного аккаунта (обфусцированный). Такой объект генерируется во время первой авторизации.
setting_dict = {
'cookies': {
'csrftoken': 'QyefK9cqhyDKy7am3jKTV9FYRZh8C7gz',
'ds_user_id': '48413308476',
'mid': 'UJ9R2QABAAFpOzAnLMnXsuUjXDJK',
'rur': 'FRC',
'sessionid': '46412238876%3A9QSzIu5ZPScFoF%3A16'
},
'device_settings': {
'android_release': '8.0.0',
'android_version': 26,
'app_version': '169.3.0.30.135',
'cpu': 'qcom',
'device': 'MI 5s',
'dpi': '640dpi',
'manufacturer': 'Xiaomi',
'model': 'capricorn',
'resolution': '1440x2560',
'version_code': '264009049'
},
'last_login': 1615811040.3808167,
'user_agent': 'Instagram 169.3.0.30.135 Android (26/8.0.0; 640dpi; 1440x2560; Xiaomi; MI 5s; capricorn; qcom; en_US; 264009049)',
'uuids': {
'advertising_id': 'dt80b3f5-a2eb-4231-b153-86afc1b43077',
'client_session_id': 'd2b680ee-c090-4378-9276-abf1315b020b',
'device_id': 'android-67b586a78efb9ce2',
'phone_id': '76b47u54-af9f-4cb6-a269-2eaef8055619',
'uuid': '776d5de7-6274-42c5-8554-d9f638720c77'
}
}
Как любил говорить мой любимый преподаватель по программированию: «Разделяй и властвуй». Стараюсь придерживаться этого принципа. В инстаграме лайки имеют смысл только в контексте постов, на которые они были поставлены. Поэтому наша задача может быть разбита на две подзадачи:
Алгоритм работы процесса исполнителя выглядит следующим образом:
Таким образом, у каждого исполнителя есть свой диапазон индексов в базе данных пользователей. У каждого пользователя есть идентификаторы опубликованных им постов. Также, у некоторых частей базы данных есть флаги блокировки, когда эту часть бд меняет процесс менеджер.
Вырезка из документации касательно оркестрирования.
users_split - это массив содержащий в себе разбиения базы данных пользователей между разными аккаунтами исполнителями
users_split = {
'begin_i' : - начало области работы (индекс),
'end_i' : - конец области работы (индекс)
}
Раз в несколько часов происходит перераспределение диапазонов индексов между исполнителями. Это нужно для того, чтобы минимизировать влияние заблокированных аккаунтов. Эта функция называется normalize_executors_split
Балансировка оркестрирования
Для улучшения процесса обработки баз данных была реализована балансировка оркестрирвоания
По расписанию (напр. раз в день) crontab запускает процесс-менеджер, который сортирует users_database по параметру last_check
Пользователи, которые не были проверены дольше всех, помещаются в специальную приоритетную очередь
top_users_to_fetch - как раз такая приоритетная очередь
top_users_to_fetch_count - размер этой очереди (этот параметр можно менять)
normalize_split
normalize_split- процесс перераспределения диапазонов индексов пользователей между исполнителями. Диапазоны перемешиваются случайным образом, после чего распределяются между исполнителями. Данный процесс запускается каждый час.
Изначальную базу пользователей я решил брать с университетских кластеров пользователей. Делал я это следующим образом (да, я люблю списки).
Коммерческое предложение: Да, если меня читают товарищи таргетологи, то обязательно напишите мне, потому что вам ведь что-то похожее нужно для анализа аудитории? Я как раз планирую сделать сервис, который бы на базе нескольких аккаунтов схожей тематики выдавал бы их активную аудиторию.
manager - процесс для менеджмента системы.
Алгоритм работы следующий:
manage_cluster - процесс уплотнения или расширения кластера (в зависимости от параметров)
Для увеличения связности базы данных пользователей раз в определенный промежуток времени запускается процесс, отсеивающий малоактивных пользователей и добавляющий пользователей активных (которые еще не в базе данных).
В облачной базе даных в разделе executors/cluster есть два параметра, влияющих на процесс формирования кластера.
 Воображаемый вождь шаманов
Воображаемый вождь шаманов
Не буду вас томить и сразу покажу как выглядел мой Dockerfile, скажу честно, я несколько дней гуглил как завести crontab внутри докера и только где-то по задворкам иностранных форумов мне удалось собрать крупицы знаний, которые позволили мне "завести" всё это.
FROM ubuntu:latest
ENV DEBIAN_FRONTEND=noninteractive
RUN apt-get update \
&& apt-get install -y python3-pip python3-dev \
&& apt-get install -y tmux htop cron nano rsyslog\
&& cd /usr/local/bin \
&& ln -s /usr/bin/python3 python \
&& pip3 install --upgrade pip
COPY requirements.txt /tmp/
RUN pip install -r /tmp/requirements.txt
COPY crontab_config /tmp/
RUN crontab /tmp/crontab_config
CMD service rsyslog start && service cron start && \
tail -f /var/log/syslog
В файле crontab_config всего одна прекрасная строчка, которая вызывала процесс сборки файла с расписанием на базе данных в облачной базе данных. В результате получался файлик в 100 с чем-то строчек.
MAILTO=""
*/1 * * * * python3 /main/make_crontab_file.py >> /main/crontab.log
Как выглядел мой crontab файл
make_crontab_file - процесс создания конфигурационного crontab файла на базе параметров облачной базы данных и установки его внутрь докер контейнера.
Создаваемый конфигурационный файл зависит от параметров, находящихся внутри раздела crontab в облачной базе данных.
Алгоритм работы следующий:
В структуре tasks_log хранятся логи, описывающие результат работы каждого запроса каждого исполнителя.
tasks_log = {
'0': [task_log] массив логов для исполнителя
с идентификатором exec_id = 0,
'1': [task_log] для exec_id = 1,
...
'n': [task_log] для exec_id = n,
}
где каждый task_log имеет вид
task_log = {
'type' : тип запроса: 'user' или 'post',
'success' : True или False,
'time' : время запроса,
'payload' : идентификатор пользователя или поста,
в зависимости от запроса
}
в случае неуспеха task_log.payload имеет вид
task_log.payload = {
'type' : тип запроса,
'success' : False,
'time' : время запроса,
'payload' : идентификатор поста или пользователя,
'last_json' : ответ API Инстаграм
}
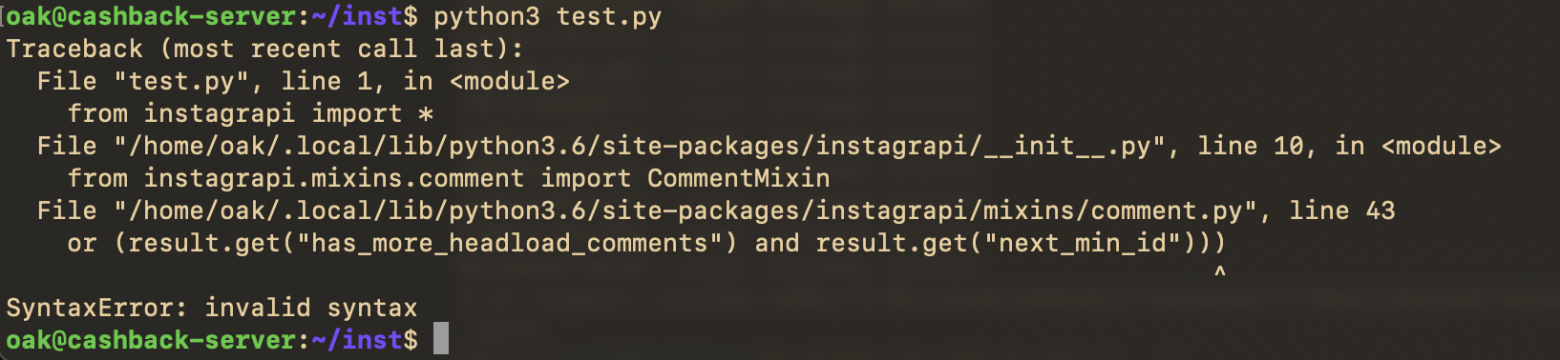
В своей прошлой статье я использовал instabot, однако сейчас этот сервис уже не подерживаетя. Поэтому нынешний парсер базируется на instagrapi - мощный и надёжный сервис, рекомендасьон.
Проблемка с нынешней версией сервиса
На момент написания статьи у данная библиотека имеет версию 1.9.13. В данной версии кроется коварная ошибка, которая, впрочем, достаточно просто чинится.
Кто-то просто забыл убрать строчку в 43й строке. Просто убираем скобочку и всё работает.
Прокси
Достаточно важный элемент данного проекта — это группа прокси, которые я использовал. Для каждого аккаунта у меня было своё уникальное прокси.
В своём проекте я использовал сервис webshare. Я взял 100 прокси, что стоило мне 2.75$ в месяц. Этот сервис я использовал и для других своих проектов, так что рекомендасьон.
 Статистика использования прокси по моему проекту
Статистика использования прокси по моему проекту
Аккаунты в Instagram
Как я уже ранее упоминал, аккаунты инстаграмма у меня покупные. Никакого криминала, я брал самые простые и дешёвые автореги, они стоят примерно по 12 рублей за штуку. Вот и вот примеры бирж, на них много разных продавцов. Прежде чем покупать "большую котлету" аккаунтов, советую брать штучек по 10 на пробу и смотреть насколько они живучие. Если вдруг возниктут какие-то трудности с указанными ранее биржами, то другие такие биржи гуглятся по запросу: "Аккаунты Инстаграм авторег купить".
Делать такой проект было достаточно сложно, но при этом очень интересно! Хочу сказать, что я многому научился: поближе познакомился с докером, разобрался с Firebase Realtime Database, умудрился даже выйти за её бесплатный тарифный план - оборот данных в месяц в моей базе данных достигает порядка 20 гигобайт. Ну и конечно же, преисполнился в работе с неофициальным API инстаграма. За это я и люблю интересные заказы на фрилансе, помимо денег получаешь ещё и ценные знания.
Чтобы не перегружать и без того уже внушительных размеров статью я оставил некоторые детали за кадром. Так например, к этому проекту прилагалось API, которое отдавало лайки по запросу за промежуток времени. Возможно, я ещё вернусь и допишу про этот проект позже. Сейчас же я хочу обсудить его потенциально будущее.
 410 WEB
410 WEB
Последние несколько месяцев, в рамках своего Digital агенства, я достаточно плотно занимаюсь проектами так или иначе связанными с Digital Marketing. Насколько мне известно, достаточно часто возникает задача выкачки аудитории с нескольких инстаграмм профилей со схожей семантикой. Так вот, мой парсер позволяет выкачивать не просто аудиторию, а брать сразу самую активную, которая ставит лайки и оставляет комментарии. Так что, специалисты в области Инстаграм, жду обратной связи от вас, нужно ли вам такое; потому что я планирую упаковать свой бэкенд в полноценный сервис.
P.S.
Если вдруг вам настолько понравилась моя статья, что вы захотели со мной поработать, то прошу, моё Digital агенство - 410 Web. На протяжении двух лет мы с ребятами делаем для вас огромные онлайн магазины на десятки тысяч позиций, масштабные комплексные решения для бизнеса со всевозможными интеграциями, например с 1С, с популярными CRM системами и даже с ресторанным IIKO. Более того, мы занимаемся не только сайтами - мы разрабатываем маркетинговые стратегии нашим заказчикам, прорабатываем айдентику брендов, а также занимаемся рекламой и продвижением в соцсетях.

И да, в будущем планирую писать не только про программирование, например, у меня есть несколько сумасшедших маркетинговых идей для разных областей бизнеса, которые мне не терпится попробовать. Так что Stay Tuned.

 habr.com
habr.com
С тех пор прошло уже больше полугода, за которые я набил всевозможные шишки в данной области и написал промышленный парсер, который способен делать сотни тысяч, если не миллионы запросов в сутки.
В рамках данной статьи я хочу рассказать про путь развития своего Pet-Project в потенциально мощный и серьёзный инструмент. Впереди вас ждёт увлекательное путешествие от хранения данных в простых Json-ах на жестком диске сервера, до облачной базы данных и автоматической инициализации cron расписания запуска процессов внутри докер контейнера, поехали!
Ещё немного занудства
Во многом, я пишу эту статью для того чтобы проследить и "отрефлексировать" проделанный мной путь. Потому что я люблю учиться, а самый лучший способ приобретать данные - через практику, в бою. Написание своеобразного публичного отчёта в конце позволяет мне отследить чему я научился, а также по полному ощутить завершённость и полезность моей работы.Какую задачу я решал?
Сразу после написания первой статьи, ко мне обратился заказчик с вопросом, смогу ли я извлекать из инстаграмма данные о том, как пользователи обмениваются лайками.Задача была следующая. Дана группа пользователей (несколько тысяч), необходимо в режиме реального времени отслеживать, как они ставят лайки друг другу. То есть собирать лайки, которые пользователи из выбранной группы ставят внутри этой группы, и отдавать эту информацию в виде "потока лайков" в стандартизированном виде.
Далее эти лайки должны "копироваться" в блокчейн VIZ, чтобы инстаграмеры не просто так лайкали друг друга, а получали цифровой социальный капитал. Впрочем, этой частью сервиса занимались специалисты на стороне заказчика.
Ориентировочное количество лайков, которое моя система должна была собирать в день - порядка 10.000. Чувствуете масштаб?
Каким образом я её решал
Ознакомившись с требованиями заказчика я понял, что через один аккаунт много данных достать не получится, то есть каким-то образом необходимо разбивать процесс добычи данных на группу аккаунтов - добытчиков. Именно с этой мысли и начинается моё увлекательное приключение.Да, как вы ещё не раз убедитесь в процессе чтения, я люблю всё структурировать, поэтому ниже список разделов этой статьи:
- Принцип майнинга данных из инстаграмма с помощью одного аккаунта, какие ограничения на это есть.
- Каким образом можно распаралелить процесс извлечения данных на несколько исполнителей (Vanilla подход).
- Как распаралелить процесс, но уже по-крупному. Переход от локальных баз данных к облачным.
- Архитектура получившейся облачной базы данных (Firebase Realtime Databasse).
- Оркестрирование процессов или как сделать так, чтобы всё работало параллельно и не сломалось.
- Вычисление активной аудитории профиля в Инстаграм, создание кластера активных пользователей и его уплотнение.
- Как я делал расписание процессов. Некоторая магия и танцы с бубном вокруг докера и crontab.
- Логи + облачная база данных.
- Полезные ссылки (API Instagram, прокси сервис, биржа аккаунтов инстаграм)
- Outro + Размышления о будущем проекта.
Для начала предлагаю освежить в памяти, каким образом можно получить открытые данные из Инстаграма.
А как вообще доставать данные, Recap
Во многом, на этот вопрос отвечает моя первая, максимально базовая статья (это чтобы вы не листали наверх в поисках ссылки).Если кратко, то я использовал библиотеку на питоне, которая извлекает данные путём отправления запросов к неофициальному API инстаграмма. Есть множество библиотек, работающих таким образом. В своём проекте я использовал instagrapi, пожалуй самую современную и удобную библиотеку.
Что такое неофициальное API инстаграма
Если кратко, то неофициальное API притворяется приложением Инстаграм на андроиде и в шапке запроса прописывает свои специальные плюшечки, сигнатуры и всякое прочее, почитать больше про то как работают запросы к API можно тут.
В начале разработки промышленного парсера я создал новый аккаунт в инстаграме, подписался на пару своих друзей и начал активно исследовать пропускной канал такого метода «добычи данных».
К моему огорчению, разработчики инстаграмма создали ряд инструментов, препятствующих безграничной выкачке данных. И после серии запросов аккаунт, через который проводятся запросы, банится. Особенно, Инстаграмм банит за периодические запросы, между которыми небольшая разница во времени, то есть когда очевидно, что эти действия производятся алгоритмом.
К слову, для себя я установил, что придерживаясь следующего подхода, вероятность аккаунта быть забаненным - минимальна:
- Не более 150 запросов в день с одного аккаунта.
- Добавить стохастчность во временные промежутки между запросами (например, sleep на рандомный промежуток времени).
- Делать запросы разного типа (то есть, например, не только получение лайков для поста, но и просмотр подписчиков).
Разобрались с тем, как проводить запросы с одного аккаунта. Дальше необходимо понять, как организовать параллельную работу группы аккаунтов.
Vanila подход к распараллеливанию
На 150 запросах в день далеко не уедешь, надо что-то придумывать. В самом начале я подумал: "подержите моё пиво, я проходил параллельное программирование в вузе". Так начинается новая глава моего повествования.
«Параллельное программирование» - рано или поздно большинству разработчиков приходится столкнуться с этим страшным зверем. К сожалению, в моём вузе (МФТИ) курсы по параллельному программированию были крайне примитивными и не давали необходимого уровня экспертизы для создания крупных систем для продакшена.
Передо мной стояла задача организовать параллельный асинхронный процесс добычи данных несколькими исполнителями.
Мне пришла на ум следующая концепция - ввести два типа процессов:
- Процессы - исполнители: получают задание, делают запросы к API Инстаграмма, полученные в результате данные записывают в свои локальные базы данных.
- Процесс - менеджер: назначает задания исполнителям, агрегирует данные, собранные исполнителями, в одном месте и затем выделяет лайки внутри общей базы данных.
Аккаунты для проведения запросов я планировал создавать вручную, но в итоге пришел к тому, что проще их купить, примерно 12 рублей за штуку - не такая высокая цена).
Стыдно даже рассказывать, с чего я начал, но раз уж пообещал повествование про свой путь, то дерзайте. Начинал я с крайне примитивного подхода в виде хранения данных в json на жестком диске. То есть исполнители получали задание в формате json файла со специальным названием, соответствующим исполнителю, делали необходимые запросы, и затем процесс менеджер собирал результаты работы в один большой json файл.
Достаточно быстро я понял, что такая схема работы выглядит уж больно криво и костыльно и без какой-нибудь базы данных мне не обойтись.
База данных, Firebase Realtime Database
«Базы данных» - другой страшный зверь, снящийся в ужасных кошмарах начинающим разработчикам. Проблем добавляет ещё и то, что мало в каких вузах хорошо раскрывают тему работы с базами даных. Не видел еще ни одного российского студента, который был бы доволен качеством преподавания баз данных (вполне возможно что зря грешу и это у меня такая выборка, я просто только закончил бакалавриват мфти и не понял зачем оно мне было нужно).Мне не хотелось разбираться со сложными базами данных и с SQL, так как это чрезмерно затянуло бы процесс разработки. Благо, мои партнёры по веб студии, молодые и заряженные ребята, подсказали мне продвинутый стек разработки. В частности меня познакомили с Firebase Realtime Database, сервисом компании Google, созданным для упрощения процесса разработки приложений. Представьте себе, NO SQL облачная база данных, доступная из любой точки мира, где есть интернет.
Прежде я писал про то, как "поженить" Firebase Realtime Database и Телеграм ботов. Тут можно почитать про основы работы с этой базой даных.
Основными преимуществами такой базы данных для меня было то, что все данные в ней хранятся в виде json дерева и то, что интерфейс взаимодействия с ней выглядит максимально просто. И что это всё работает с моим любимым питоном! (Python Firebase SDK). Во многом, помочь разобраться с базой данных мне помог этот туториал.
Прежде чем интегрировать новую для меня технологию в серьёзный проект я начал с «игрушечного проекта» (Да, Pet Project внутри Pet Project) и интегрировал Realtime Database в моего телеграмм бота, который делает синтаксический анализ предложений. Он был сделан в рамках другого моего проекта и там была необходимость запоминать предложения, на которых алгоритм работает плохо.
Что за проект
(Спойлер - что за проект) Тут я писал про то, что у нас за театральная постановка, к сожалению на данный момент её развитие приостановлено, так как я старался закончить мой вуз, параллельно работать и каким-то чудом не вылететь. А бот делает следующее - на вход он получает предложение, а на выходе даёт синтаксическое дерево для этого предложения и несколько вариантов «обрезки» дерева.
На нынешнем этапе обрезка работает достаточно просто и зачастую падает для сложных предложений. Однако дерево строится в большинстве случаев.
Архитектура БД
Далее будет достаточно сухой технический модуль про то, какая в итоге архитектура базы данных у меня получилась. Большая часть технических деталей этой статьи была написаны на базе документации, которую я писал для заказчика в рамках этого проекта (прекрасный лайфхак - пишешь подробную и понятную документацию, а потом делаешь на её базе статью).Основу этой архитектуры я придумал за один продуктивный вечер где-то в начале марта, расслаблено программируя с бокальчиком вина (а потом уже и с бутылкой). Впоследствии я добавлял некоторые коллекции и разделы для более эффективной работы системы, либо для более гибкой её настройки.
Начнём с самых базовых структур, которые я использовал в этом проекте
User
user = {
'last_check': время последней проверки пользователя,
'last_post_published': время публикации самого свежего поста,
'likes_given': кол-во лайков, которое пользователь
отдал внутри нашей базы пользователей,
'pk': идентификатор пользователя в инстаграме ,
'posts_published': [media_id] - массив идентификаторов
постов, опубликованных пользователем,
'username': юзернейм
}
Пример
user = {
'last_check': 1615762467.122444,
'last_post_published': 1615203615.0,
'likes_given': 0,
'pk': 1764766994,
'posts_published': [
'2503859905240423283_1764766994',
'2507722254816718688_1764766994',
'2512069674769873900_1764766994',
'2519219162844397865_1764766994',
'2524923983303827750_1764766994'],
'username': 'purplefront'
}
Post
post = {
"owner_id" : идентификатор владельца поста,
"media_id" : идентификатор поста,
"made_at" : время когда пост был выложен,
"last_check" : время последней проверки поста нашей системой,
"likes" : [like] - массив лайков
}
Пример
post = {
'last_check': 0,
'made_at': 1601198622,
'media_id': '2407350984285396491_3301663934',
'owner_id': 3301663934,
'likes' : [...]
}
Ноль в last_check означает что пост ещё ни разу не был проверен.
Стоит отметить, что в post.likes хранятся в принципе все лайки оставленные под постом (то есть не только внутри нашей базы данных).
Также стоит отметить, что никакое API инстаграмма, даже самое продвинутое и хакерское не отдает больше 999 лайков для поста.
Если на посте больше 999 лайков, то будут отданы 999 некоторых лайков из всех (при этом нигде нет гарантии, что это будут 999 последних лайков).
Like
like = {
'from': id пользователя, отдавшего лайк,
'media_id': id поста где стоит лайк,
'to': id пользователя, получившего лайк
}
Пример
like = {
'from': 28266009338,
'media_id': '2417619399940064811_1398989479',
'to': 1398989479
}
Коллекции
В корневом разделе базы данных Firebase Realtime Database хранится 6 коллекций (6 корневых разделов).
- all_likes - все собранные внутри нашей базы данных лайки пользователей, состоит из объектов like.
- likes_stream - Real Time поток лайков, разнесённый по разным исполнителям (доступ производится по индексам исполнителей). Очищается раз в 6 часов.
- posts_storage - все собранные посты, состоит из объектов post. Посты хранятся по их ключам media_id.
- users_database - все собранные пользователи, состоит из объектов user, обычный массив.
- executors - основная логика сбора лайков, см. Раздел Executors.
- tasks_log - Основная логика логов (см. Раздел Логи, будет в конце статьи).
Данная структура хранит в себе все конфигурационные данные, необходимые для сбора лайков и добавления новых постов.
Сбор лайков может вестись параллельно и асинхронно несколькими исполнителями.
- block - True / False. Если True, то работа всех исполнителей приостанавливается до момента возведения этого флага обратно в False. Необходимо для блокировки записи в базу данных во время внесения в неё каких-либо изменений.
- cluster - конфигурационные параметры для динамического расширения или уплотнения кластера пользователей. (см. раздел Работа с кластером) (также ближе к концу статьи)
- configs - конфигурационные файлы исполнителей (см. Раздел Executor Configs)
- count - количество исполнителей
- crontab - расписание запуска процессов (см. раздел Crontab)
- date_to_cut - дата и время в формате timestamp, все посты ранее этого времени добавляться в систему не будут
- likes_strem_block - True / False. Если True, то заполнение потока лайков приостанавливается до момента возведения этого флага обратно в False. Необходимо для блокировки записи в likes_stream во время её очистки.
- users_split - разбивка пользователей между исполнителями. Более подробно в разделе про Оркестрирование.
- top_users_to_fetch ( top_users_to_fetch_count) - приоритетная очередь из пользователей (состоит из пользователей, которых система давно не обрабатывала)
Конфигурационный файл исполнителя:
executor_config = {
'password': Пароль аккаунта исполнителя,
'proxy': SOCKS5 proxy,
'settings_dict': {...} - набор настроек для авторизации по куки
и прочей магии,
'username': Юзернейм аккаунта исполнителя,
'last_login_log' : Лог последней авторизации
}
Более детально:
executor_config = {
'password': 'pwd',
'proxy': 'socks5://username
assword@iport','settings_dict': {...},
'username': 'usrnm'
}
Last Login Log
Лог последней авторизации в случае успеха имеет вид
last_login_log = {
'success' : True или False,
'time' : время последней авторизации
}
В случае неспеха
last_login_log = {
'success' : False,
'time' : время последней авторизации,
'last_json' : последний ответ Instagram API,
}
last_json - Последний ответ Instagram API, по нему можно понять что пошло не так во время последнего запроса.
Settings Dict
Конфигурация API исполнителя. Содерджит в себе куки файл для более удобной авторизации (и менее опасной с точки зрения потенциальной возможности бана аккаунта).
Пример для купленного аккаунта (обфусцированный). Такой объект генерируется во время первой авторизации.
setting_dict = {
'cookies': {
'csrftoken': 'QyefK9cqhyDKy7am3jKTV9FYRZh8C7gz',
'ds_user_id': '48413308476',
'mid': 'UJ9R2QABAAFpOzAnLMnXsuUjXDJK',
'rur': 'FRC',
'sessionid': '46412238876%3A9QSzIu5ZPScFoF%3A16'
},
'device_settings': {
'android_release': '8.0.0',
'android_version': 26,
'app_version': '169.3.0.30.135',
'cpu': 'qcom',
'device': 'MI 5s',
'dpi': '640dpi',
'manufacturer': 'Xiaomi',
'model': 'capricorn',
'resolution': '1440x2560',
'version_code': '264009049'
},
'last_login': 1615811040.3808167,
'user_agent': 'Instagram 169.3.0.30.135 Android (26/8.0.0; 640dpi; 1440x2560; Xiaomi; MI 5s; capricorn; qcom; en_US; 264009049)',
'uuids': {
'advertising_id': 'dt80b3f5-a2eb-4231-b153-86afc1b43077',
'client_session_id': 'd2b680ee-c090-4378-9276-abf1315b020b',
'device_id': 'android-67b586a78efb9ce2',
'phone_id': '76b47u54-af9f-4cb6-a269-2eaef8055619',
'uuid': '776d5de7-6274-42c5-8554-d9f638720c77'
}
}
Оркестрирование процессов
Разобрались с облачной базой данных (Если вы ещё не разобрались, то обязательно разберитесь, почитайте туториалы, уж очень классная штука). Теперь необходимо понять, как правильно использовать её для организации процесса майнинга данных группой аккаунтов.Как любил говорить мой любимый преподаватель по программированию: «Разделяй и властвуй». Стараюсь придерживаться этого принципа. В инстаграме лайки имеют смысл только в контексте постов, на которые они были поставлены. Поэтому наша задача может быть разбита на две подзадачи:
- Держать актуальной базу постов, выложенных пользователями
- Держать актуальной мини базу лайков для каждого поста
Алгоритм работы процесса исполнителя выглядит следующим образом:
- Процесс запускается по расписанию (про расписание будет отдельный раздел).
- Логинится в аккаунт инстаграмма, используя при этом своё прокси (SOCKS5).
- Случайным образом выбирает действие. Чтобы действия не были сильно похожи на действия робота. Исполнитель либо делает запрос на новые посты пользователя, либо на новые лайки, либо совершает случайное действие (лайк, посмотреть коменты, посмотреть подписчиков), либо вообще отдыхает.
- Случайным образом выбирает индекс пользователя из соответствующего ему диапазона индексов.
- Получает из облачной базы данных нынешнюю запись (будь это пост или пользователь).
- Проводит запрос к Инстаграму.
- Проверяет, изменились ли данные, если изменились, то обновляет запись в облачной базе данных.
- Если действие было собрать новые лайки и на посте оказались новые лайки, то исполнитель выгружает новые лайки в облачную базу данных. Это необходимо чтобы поток лайков был в режиме реального времени. Исполнитель добавляет в облачную базу данных только лайки пользователей из базы пользователей. База идентификаторов пользователей хранится в виде json файла на сервере и обновляется раз в несколько часов.
Таким образом, у каждого исполнителя есть свой диапазон индексов в базе данных пользователей. У каждого пользователя есть идентификаторы опубликованных им постов. Также, у некоторых частей базы данных есть флаги блокировки, когда эту часть бд меняет процесс менеджер.
Вырезка из документации касательно оркестрирования.
users_split - это массив содержащий в себе разбиения базы данных пользователей между разными аккаунтами исполнителями
users_split = {
'begin_i' : - начало области работы (индекс),
'end_i' : - конец области работы (индекс)
}
Раз в несколько часов происходит перераспределение диапазонов индексов между исполнителями. Это нужно для того, чтобы минимизировать влияние заблокированных аккаунтов. Эта функция называется normalize_executors_split
Балансировка оркестрирования
Для улучшения процесса обработки баз данных была реализована балансировка оркестрирвоания
По расписанию (напр. раз в день) crontab запускает процесс-менеджер, который сортирует users_database по параметру last_check
Пользователи, которые не были проверены дольше всех, помещаются в специальную приоритетную очередь
top_users_to_fetch - как раз такая приоритетная очередь
top_users_to_fetch_count - размер этой очереди (этот параметр можно менять)
normalize_split
normalize_split- процесс перераспределения диапазонов индексов пользователей между исполнителями. Диапазоны перемешиваются случайным образом, после чего распределяются между исполнителями. Данный процесс запускается каждый час.
Уплотнение кластера пользователей
Одной из задач в данном проекте было постоянное уплотнение кластера пользователей на базе их активности внутри кластера пользователей. То есть те кто ставит много лайков пользователям которые есть в нашей базе даных - остаётся, те кто ставит мало лайков - выбывает.Изначальную базу пользователей я решил брать с университетских кластеров пользователей. Делал я это следующим образом (да, я люблю списки).
- Я брал несколько самых популярных университетских аккаунтов в инстаграме.
- Для каждого аккаунта получал идентификаторы последних 20 постов.
- Выкачивал все лайки для этих постов.
- Для каждого пользователя, поставившего лайк считал суммарное количество лайков, которое он поставил на эти 20 постов.
- Добавлял в свою базу пользователей тех, кто поставил N > 4 лайков (варьируемый параметр, я экспериментировал).
Коммерческое предложение: Да, если меня читают товарищи таргетологи, то обязательно напишите мне, потому что вам ведь что-то похожее нужно для анализа аудитории? Я как раз планирую сделать сервис, который бы на базе нескольких аккаунтов схожей тематики выдавал бы их активную аудиторию.
manager - процесс для менеджмента системы.
Алгоритм работы следующий:
- Устанавливается блок работы всех исполнителей + ожидание в 80 секунд, чтобы все процессы успели заблокироваться. (если блок уже установлен - то происходит ожидание)
- Загрузка всей базы данных пользователей и базы данных постов
- Проставление пользователям количества лайков, которое они отдали внутри базы данных
- Сбор всех лайков, поставленных внутри базы данных. Загрузка всех лайков в облачную базу данных
- Перераспределение диапазонов индексов пользователей между исполнителями (normalize_executors_split)
- Балансировка оркестрирования (choose_top_users_to_fetch)
- Сохранение всех баз данных локально
- Сброс блока
manage_cluster - процесс уплотнения или расширения кластера (в зависимости от параметров)
Для увеличения связности базы данных пользователей раз в определенный промежуток времени запускается процесс, отсеивающий малоактивных пользователей и добавляющий пользователей активных (которые еще не в базе данных).
В облачной базе даных в разделе executors/cluster есть два параметра, влияющих на процесс формирования кластера.
- REMAIN_FRACTION - доля пользователей, которые остаются после такой "чистки" (доля от текущего размера базы данных пользователей
- ADD_FRACTION доля пользователей, которые добавляются (доля от текущего размера базы данных пользователей
- Устанавливается блок работы всех исполнителей + ожидание в 80 секунд, чтобы все процессы успели заблокироваться. (если блок уже установлен - то происходит ожидание 10 минут).
- Загрузка всей базы данных пользователей и базы данных постов.
- Для каждого пользователя вычисляется количество лайков, которое они отдали внутри базы данных.
- Пользователи сортируются по количеству лайков, поставленных внутри базы данных. Затем оставляется доля самых активных пользователей (от нынешнего количества пользователей внутри базы даных), равная REMAIN_FRACTION (число от 0 до 1).
- Для каждого пользователя, поставившего лайк на пост, который есть в нашей, уже очищенной, базе данных также вычисляется суммарное количество лайков, которое они поставили пользователям внутри базы данных.
- Эти пользователи также сортируются по количеству поставленных ими лайков. После чего в базу данных добавляется доля пользователей равная ADD_FRACTION (имеется ввиду доля от нынешнего количества пользователей внутри базы даных).
- Происходит обновление коллекции all_likes.
- Затем запускается перераспределение диапазонов индексов пользователей между исполнителями (normalize_executors_split).
- Сброс блока.
Расписание процессов
Значимой частью этого проекта, его безусловным сердцем, является логика запуска процессов по расписанию. Где-то внутри меня сидит бунтарь, которому постоянно хочется хардкора, поэтому расписание процессов я делал внутри докер контейнера с помощью crontab. Более того, конфигурационный файл crontab внутри докера постоянно синхронизируется с облачной базой данных. Когда я продумывал всю эту архитектуру я, безусловно, представлял себя вождём шаманов, совершающим некое таинство.
Не буду вас томить и сразу покажу как выглядел мой Dockerfile, скажу честно, я несколько дней гуглил как завести crontab внутри докера и только где-то по задворкам иностранных форумов мне удалось собрать крупицы знаний, которые позволили мне "завести" всё это.
FROM ubuntu:latest
ENV DEBIAN_FRONTEND=noninteractive
RUN apt-get update \
&& apt-get install -y python3-pip python3-dev \
&& apt-get install -y tmux htop cron nano rsyslog\
&& cd /usr/local/bin \
&& ln -s /usr/bin/python3 python \
&& pip3 install --upgrade pip
COPY requirements.txt /tmp/
RUN pip install -r /tmp/requirements.txt
COPY crontab_config /tmp/
RUN crontab /tmp/crontab_config
CMD service rsyslog start && service cron start && \
tail -f /var/log/syslog
В файле crontab_config всего одна прекрасная строчка, которая вызывала процесс сборки файла с расписанием на базе данных в облачной базе данных. В результате получался файлик в 100 с чем-то строчек.
MAILTO=""
*/1 * * * * python3 /main/make_crontab_file.py >> /main/crontab.log
Как выглядел мой crontab файл
make_crontab_file - процесс создания конфигурационного crontab файла на базе параметров облачной базы данных и установки его внутрь докер контейнера.
Создаваемый конфигурационный файл зависит от параметров, находящихся внутри раздела crontab в облачной базе данных.
Алгоритм работы следующий:
- Из облачной базы данных подгружаются параметры формирующие расписание.
- Создается текстовый файл, содержащий комманды для системной утилиты crontab.
- С помощью os.system() вызывается команда установки конфигурационного файла внутрь докер контейнера.
Логи
Я посчитал важным сделать красивые и адекватные логи, поэтому их я также сохранял в облачную базу даных, что оказалось очень удобно. На базе логов, хранящихся в таком формате можно сделать, например, Телеграм бота, который по запросу будет присылать отчёт по успешности выполненных запросов и анализировать самые часто встречающиеся проблемы.В структуре tasks_log хранятся логи, описывающие результат работы каждого запроса каждого исполнителя.
tasks_log = {
'0': [task_log] массив логов для исполнителя
с идентификатором exec_id = 0,
'1': [task_log] для exec_id = 1,
...
'n': [task_log] для exec_id = n,
}
где каждый task_log имеет вид
task_log = {
'type' : тип запроса: 'user' или 'post',
'success' : True или False,
'time' : время запроса,
'payload' : идентификатор пользователя или поста,
в зависимости от запроса
}
в случае неуспеха task_log.payload имеет вид
task_log.payload = {
'type' : тип запроса,
'success' : False,
'time' : время запроса,
'payload' : идентификатор поста или пользователя,
'last_json' : ответ API Инстаграм
}
Что ещё я использовал в проекте, полезные ссылки
Неофициальное API инстаграммаВ своей прошлой статье я использовал instabot, однако сейчас этот сервис уже не подерживаетя. Поэтому нынешний парсер базируется на instagrapi - мощный и надёжный сервис, рекомендасьон.
Проблемка с нынешней версией сервиса
На момент написания статьи у данная библиотека имеет версию 1.9.13. В данной версии кроется коварная ошибка, которая, впрочем, достаточно просто чинится.
Кто-то просто забыл убрать строчку в 43й строке. Просто убираем скобочку и всё работает.
Прокси
Достаточно важный элемент данного проекта — это группа прокси, которые я использовал. Для каждого аккаунта у меня было своё уникальное прокси.
В своём проекте я использовал сервис webshare. Я взял 100 прокси, что стоило мне 2.75$ в месяц. Этот сервис я использовал и для других своих проектов, так что рекомендасьон.
Аккаунты в Instagram
Как я уже ранее упоминал, аккаунты инстаграмма у меня покупные. Никакого криминала, я брал самые простые и дешёвые автореги, они стоят примерно по 12 рублей за штуку. Вот и вот примеры бирж, на них много разных продавцов. Прежде чем покупать "большую котлету" аккаунтов, советую брать штучек по 10 на пробу и смотреть насколько они живучие. Если вдруг возниктут какие-то трудности с указанными ранее биржами, то другие такие биржи гуглятся по запросу: "Аккаунты Инстаграм авторег купить".
Outro + Будущее проекта
В результате почти что 3х месяцев работы над этим проектом мне удалось написать надёжный и масштабируемый парсер, который уже более 2х месяцев бесперебойно работает на серверах заказчика и каждый день отправляет на сервера Инстаграм примерно по 15.000 запросов. При желании, закупив ещё аккаунтов и грамотно прописав docker-compose, число запросов в день может быть увеличено до 150.000 или ещё того больше.Делать такой проект было достаточно сложно, но при этом очень интересно! Хочу сказать, что я многому научился: поближе познакомился с докером, разобрался с Firebase Realtime Database, умудрился даже выйти за её бесплатный тарифный план - оборот данных в месяц в моей базе данных достигает порядка 20 гигобайт. Ну и конечно же, преисполнился в работе с неофициальным API инстаграма. За это я и люблю интересные заказы на фрилансе, помимо денег получаешь ещё и ценные знания.
Чтобы не перегружать и без того уже внушительных размеров статью я оставил некоторые детали за кадром. Так например, к этому проекту прилагалось API, которое отдавало лайки по запросу за промежуток времени. Возможно, я ещё вернусь и допишу про этот проект позже. Сейчас же я хочу обсудить его потенциально будущее.
Последние несколько месяцев, в рамках своего Digital агенства, я достаточно плотно занимаюсь проектами так или иначе связанными с Digital Marketing. Насколько мне известно, достаточно часто возникает задача выкачки аудитории с нескольких инстаграмм профилей со схожей семантикой. Так вот, мой парсер позволяет выкачивать не просто аудиторию, а брать сразу самую активную, которая ставит лайки и оставляет комментарии. Так что, специалисты в области Инстаграм, жду обратной связи от вас, нужно ли вам такое; потому что я планирую упаковать свой бэкенд в полноценный сервис.
P.S.
Если вдруг вам настолько понравилась моя статья, что вы захотели со мной поработать, то прошу, моё Digital агенство - 410 Web. На протяжении двух лет мы с ребятами делаем для вас огромные онлайн магазины на десятки тысяч позиций, масштабные комплексные решения для бизнеса со всевозможными интеграциями, например с 1С, с популярными CRM системами и даже с ресторанным IIKO. Более того, мы занимаемся не только сайтами - мы разрабатываем маркетинговые стратегии нашим заказчикам, прорабатываем айдентику брендов, а также занимаемся рекламой и продвижением в соцсетях.
И да, в будущем планирую писать не только про программирование, например, у меня есть несколько сумасшедших маркетинговых идей для разных областей бизнеса, которые мне не терпится попробовать. Так что Stay Tuned.
Парсинг Instagram в промышленных масштабах
В декабре 2020 года я завершил работать в научном институте и сразу же увлёкся задачей добычи данных из соцсетей, в частности из Инстаграма. Прежде я работал только с готовыми данными, поэтому мне...
habr.com