Привет, меня зовут Игорь и я работаю в команде Tarantool. При разработке мне часто требуется быстрое прототипирование приложений с базой данных, например, для тестирования кода или для создания MVP. Конечно же хочется, чтобы такой прототип требовал минимальных усилий по доработке, если вдруг будет решено пустить его в работу.
Мне не нравится тратить время на настройку SQL базы данных, думать, как управлять шардированием данных, тратить много времени на изучение интерфейсов коннекторов. Хочется просто написать несколько строчек кода и запустить его, чтобы все работало из коробки. В быстрой разработке распределенных приложений мне помогает Cartridge — фреймворк для управления кластерными приложениями на основе NoSQL базы данных Tarantool.
Сегодня я хочу рассказать о том, как можно быстро написать приложение на Cartridge, покрыть его тестами и запустить. Статья будет интересна всем, кто устал тратить много времени на прототипирование приложений, а также людям, которые хотят попробовать новую NoSQL технологию.
В статье вы узнаете о том, что такое Cartridge и познакомитесь с принципами написания кластерной бизнес-логики в нем.
Мы напишем кластерное приложение для хранения данных о сотрудниках некоторой компании, нас ждет:
Cartridge — это фреймворк для разработки кластерных приложений, он управляет несколькими инстансами NoSQL БД Tarantool и шардирует данные с помощью модуля vshard. Tarantool — это персистентая in-memory база данных, он очень быстрый за счет хранения данных в оперативной памяти, но при этом надежный — Tarantool сбрасывает все данные на жесткий диск и позволяет настроить репликацию, а Cartridge сам заботится о настройке узлов Tarantool и шардировании узлов кластера, так что все, что нужно разработчику — написать бизнес-логику приложений и произвести настройку фейловера.
Для этого нам понадобится cartridge-cli — это утилита для работы с картриджными приложениями. Она позволяет создавать приложение из шаблона, управлять локально запущенным кластером и подключаться к инстансам тарантула.
Установка на Debian или Ubuntu:
curl -L https://tarantool.io/fJPRtan/release/2.8/installer.sh | bash
sudo apt install cartridge-cli
Установка на CentOS, Fedora или ALT Linux:
curl -L https://tarantool.io/fJPRtan/release/2.8/installer.sh | bash
sudo yum install cartridge-cli
Установка на MacOS:
brew install tarantool
brew install cartridge-cli
Создадим шаблонное приложение с именем myapp:
cartridge create --name myapp
cd myapp
tree .
Получим структуру проекта примерно такого содержания:
myapp
├── app
│ └── roles
│ └── custom.lua
├── test
├── init.lua
├── myapp-scm-1.rockspec
На этом шаге вы уже получите готовое к работе hello world-приложение. Его можно запустить с помощью команд
cartridge build
cartridge start -d
cartridge replicasets setup --bootstrap-vshard
После этого по адресу localhost:8081/hello мы увидим hello-world.
Давайте теперь на основе шаблона напишем свое небольшое приложение — шардированное хранилище с HTTP API для наполнения и получения данных. Для этого нам потребуется понимание того, как пишется кластерная бизнес-логика в Cartridge.
В основе каждого кластерного приложения лежат роли — Lua-модули, в которых описывается бизнес-логика приложения. Например, это могут быть модули, которые занимаются хранением данных, предоставляют HTTP API или кэширует данные из Oracle. Роль назначается на набор инстансов, объединенных репликацией (репликасет) и включается на каждом из них. У разных репликасетов может быть разный набор ролей.
В cartridge есть кластерная конфигурация, которая хранится на каждом из узлов кластера. Там описывается топология, а также туда можно добавить конфигурацию, которой будет пользоваться ваша роль. Такую конфигурацию можно изменять в рантайме и влиять на поведение роли.
Каждая роль имеет структуру следующего вида:
return {
role_name = 'your_role_name',
init = init,
validate_config = validate_config,
apply_config = apply_config,
stop = stop,
rpc_function = rpc_function,
dependencies = {
'another_role_name',
},
}
В Cartridge есть несколько вариантов написания кластерных запросов:
Представим, что мы хотим кластер с одним роутером и с двумя группами стораджей по два инстанса. Такая топология характерна и для Redis Cluster, и для Mongodb кластера. Также в нашем кластере будет один инстанс — stateboard (в котором stateful-failover будет сохранять состояние текущих мастеров). Когда требуется повышенная надёжность, вместо stateboard лучше использовать кластер etcd.
Роутер будет распределять запросы по кластеру, а также управлять фейловером.

Нам потребуется написать две своих роли, одну для хранения данных, вторую для HTTP API.
В директории app/roles создаем два новых файла: app/roles/storage.lua и app/roles/api.lua
Опишем роль для хранения данных. В функции init мы создадим таблицу и индексы для нее, а в зависимости добавим crud-storage.
Если вы привыкли к SQL, то Lua-код в init-функции будет эквивалентен следующему псевдо-SQL коду:
CREATE TABLE employee(
bucket_id unsigned,
employee_id string,
name string,
department string,
position string,
salary unsigned
);
CREATE UNIQUE INDEX primary ON employee(employee_id);
CREATE INDEX bucket_id ON employee(bucket_id);
Добавим следующий код в файл app/roles/storage.lua :
local function init(opts)
-- в opts хранится признак, вызывается функция на мастере или на реплике
-- мы создаем таблицы только на мастере, на реплике они появятся автоматически
if opts.is_master then
-- Создаем таблицу с сотрудниками
local employee = box.schema.space.create('employee', {if_not_exists = true})
-- задаем формат
employee:format({
{name = 'bucket_id', type = 'unsigned'},
{name = 'employee_id', type = 'string', comment = 'ID сотрудника'},
{name = 'name', type = 'string', comment = 'ФИО сотрудника'},
{name = 'department', type = 'string', comment = 'Отдел'},
{name = 'position', type = 'string', comment = 'Должность'},
{name = 'salary', type = 'unsigned', comment = 'Зарплата'}
})
-- Создаем первичный индекс
employee:create_index('primary', {parts = {{field = 'employee_id'}},
if_not_exists = true })
-- Индекс по bucket_id, он необходим для шардирования
employee:create_index('bucket_id', {parts = {{field = 'bucket_id'}},
unique = false,
if_not_exists = true })
end
return true
end
return {
init = init,
-- <<< не забываем про зависимость от crud-storage
dependencies = {'cartridge.roles.crud-storage'},
}
Остальные функции из API роли нам не понадобятся — у нашей роли нет конфигурации и она не выделяет ресурсы, которые нужно очищать после завершения работы.
Нам понадобится вторая роль для наполнения таблиц данными и получения этих данных по запросу. Она будет обращаться к встроенному в Cartridge HTTP-серверу и иметь зависимость от crud-router.
Определим функцию для POST-запроса. В теле запроса будет приходить объект, который мы хотим записать в базу.
local function post_employee(request)
-- достаем объект из тела запроса
local employee = request:json()
-- записываем в БД
local _, err = crud.insert_object('employee', employee)
-- В случае ошибки пишем ее в лог и возвращаем 500
if err ~= nil then
log.error(err)
return {status = 500}
end
return {status = 200}
end
В GET-метод будет передаваться уровень зарплаты сотрудников и в качестве ответа мы будем возвращать JSON со списком сотрудников, которые имеют зарплату выше заданной.
SELECT employee_id, name, department, position, salary
FROM employee
WHERE salary >= @salary
local function get_employees_by_salary(request)
-- достаем query-параметр salary
local salary = tonumber(request:query_param('salary') or 0)
-- отбираем данные о сотрудниках
local employees, err = crud.select('employee', {{'>=', 'salary', salary}})
-- В случае ошибки пишем ее в лог и возвращаем 500
if err ~= nil then
log.error(err)
return { status = 500 }
end
-- в employees хранится список строк, удовлетворяющих условию и формат спейса
-- unflatten_rows нужна, чтобы преобразовать строку таблицы в таблицу вида ключ-значение
employees = crud.unflatten_rows(employees.rows, employees.metadata)
employees = fun.iter(employees):map(function(x)
return {
employee_id = x.employee_id,
name = x.name,
department = x.department,
position = x.position,
salary = x.salary,
}
end):totable()
return request:render({json = employees})
end
Теперь напишем init-функцию роли. Здесь мы обратимся к registry Cartridge для получения HTTP-сервера и используем его для назначения HTTP-эндпоинтов нашего приложения.
local function init()
-- получаем HTTP-сервер из registry Cartridge
local httpd = assert(cartridge.service_get('httpd'), "Failed to get httpd serivce")
-- прописываем роуты
httpd:route({method = 'GET', path = '/employees'}, get_employees_by_salary)
httpd:route({method = 'POST', path = '/employee'}, post_employee)
return true
end
Соберем все это вместе:
app/roles/api.lua
Опишем файл init.lua, который будет являться входной точкой приложения на Cartridge. В init-файле картриджа необходимо вызвать функцию cartridge.cfg() для настройки инстанса кластера.
cartridge.cfg(<opts>, <box_opts>)
#!/usr/bin/env tarantool
require('strict').on()
-- указываем путь для поиска модулей
if package.setsearchroot ~= nil then
package.setsearchroot()
end
-- конфигурируем Cartridge
local cartridge = require('cartridge')
local ok, err = cartridge.cfg({
roles = {
'cartridge.roles.vshard-storage',
'cartridge.roles.vshard-router',
'cartridge.roles.metrics',
-- <<< Добавляем crud-роли
'cartridge.roles.crud-storage',
'cartridge.roles.crud-router',
-- <<< Добавляем кастомные роли
'app.roles.storage',
'app.roles.api',
},
cluster_cookie = 'myapp-cluster-cookie',
})
assert(ok, tostring(err))
Последним шагом будет описание зависимостей нашего приложения в файле myapp-scm-1.rockspec.
package = 'myapp'
version = 'scm-1'
source = {
url = '/dev/null',
}
-- Добавляем зависимости
dependencies = {
'tarantool',
'lua >= 5.1',
'checks == 3.1.0-1',
'cartridge == 2.7.3-1',
'metrics == 0.11.0-1',
'crud == 0.8.0-1',
}
build = {
type = 'none';
}
Код приложения уже готов к запуску, но сначала мы напишем тесты и удостоверимся в его работоспособности.
Любое приложение нуждается в тестировании. Для unit-тестов хватит обычного luatest, но если вы хотите написать хороший интеграционный тест, вам поможет модуль cartridge.test-helpers. Он поставляется вместе с Cartridge и позволяет поднять в тестах кластер любого состава, который вам нужен.
local cartridge_helpers = require('cartridge.test-helpers')
-- создаем тестовый кластер
local cluster = cartridge_helpers.Cluster:new({
server_command = './init.lua', -- entrypoint тестового приложения
datadir = './tmp', -- директория для xlog, snap и других файлов
use_vshard = true, -- включение шардирования кластера
-- список репликасетов:
replicasets = {
{
alias = 'api',
uuid = cartridge_helpers.uuid('a'),
roles = {'app.roles.custom'}, -- список ролей, назначенных на репликасет
-- список инстансов в репликасете:
servers = {
{ instance_uuid = cartridge_helpers.uuid('a', 1), alias = 'api' },
...
},
},
...
}
})
Напишем вспомогательный модуль, который будем использовать в интеграционных тестах. В нем создается тестовый кластер из двух репликасетов, в каждом из которых будет по одному инстансу:
Код вспомогательного модуля:
test/helper.lua
Код интеграционного теста:
test/integration/api_test.lua
Остановите его:
cartridge stop
Удалите папку с данными:
rm -rf tmp/
Соберем приложение и установим зависимости:
cartridge build
./deps.sh
Запустим линтер:
.rocks/bin/luacheck .
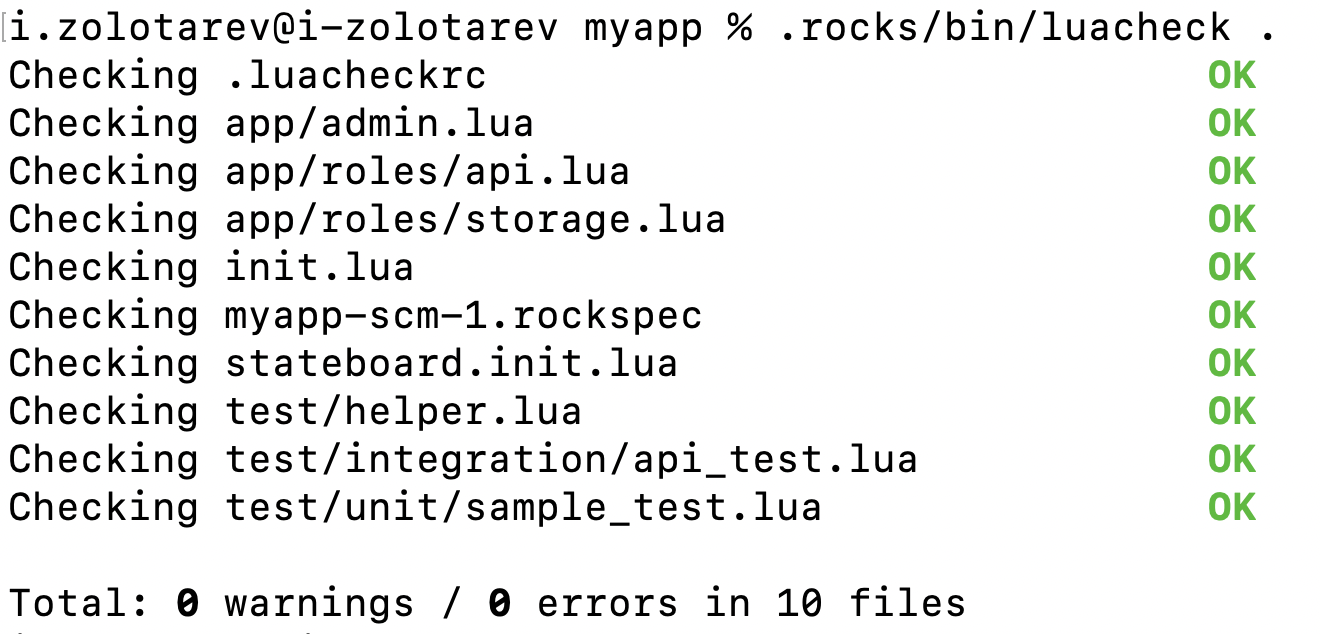
Запустим тесты с записью покрытия:
.rocks/bin/luatest --coverage

Сгенерируем отчеты по покрытию тестов и посмотрим на результат:
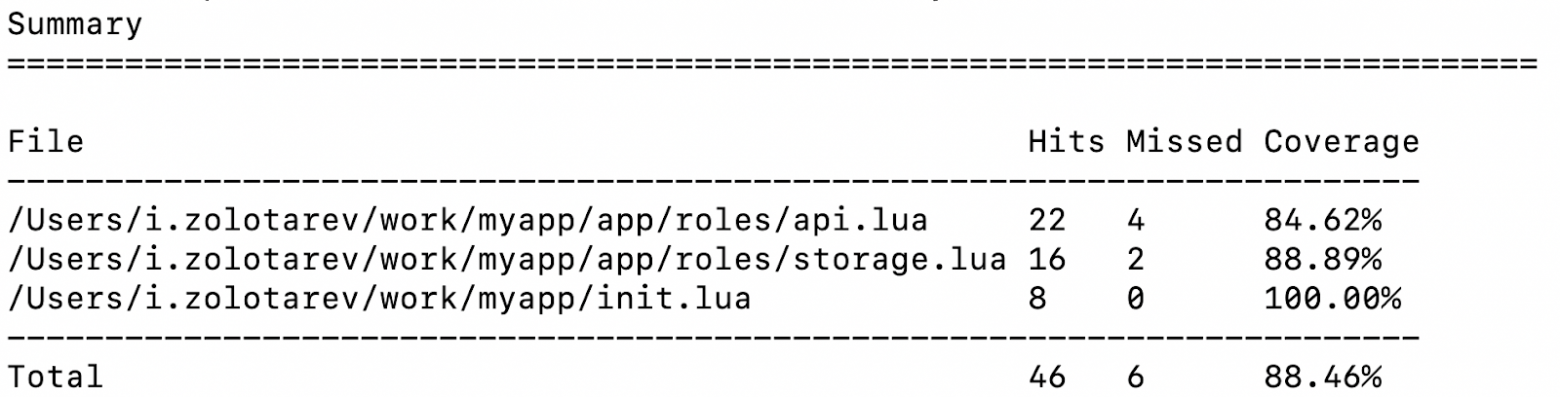
.rocks/bin/luacov .
grep -A999 '^Summary' tmp/luacov.report.out
Для локального запуска приложений можно воспользоваться cartridge-cli, но сначала нужно добавить написанные нами роли в replicasets.yml:
router:
instances:
- router
roles:
- failover-coordinator
- app.roles.api
all_rw: false
s-1:
instances:
- s1-master
- s1-replica
roles:
- app.roles.storage
weight: 1
all_rw: false
vshard_group: default
s-2:
instances:
- s2-master
- s2-replica
roles:
- app.roles.storage
weight: 1
all_rw: false
vshard_group: default
С параметрами запускаемых инстансов можно ознакомиться в instances.yml.
Запускаем кластер локально:
cartridge build
cartridge start -d
cartridge replicasets setup --bootstrap-vshard

Теперь мы можем зайти в webui и загрузить конфигурацию ролей, а также настроить фейловер. Чтобы настроить stateful failover, необходимо:
Давайте посмотрим на его работу. Сейчас в репликасете s-1 лидером является s1-master.
Остановим его:
cartridge stop s1-master
Лидер переключится на s1-replica:

Восстановим s1-master:
cartridge start -d s1-master
s1-master поднялся, но благодаря stateful-фейловеру лидером остается s1-replica:

Загрузим конфигурацию для роли cartridge.roles.metrics, для этого необходимо перейти на вкладку Code и создать файл metrics.yml следующего содержания:
export:
- path: '/metrics'
format: prometheus
- path: '/health'
format: health

После того, как мы нажмем на кнопку Apply, метрики будут доступны на каждом узле приложения по эндпоинту localhost:8081/metrics и появится health-check по адресу localhost:8081/health.
На этом базовая настройка небольшого приложения завершена: кластер готов к работе и теперь мы можем написать приложение, которое будет общаться с кластером с помощью HTTP API или через коннектор, а также можем расширять функциональность кластера.
Многим разработчикам не нравится тратить время на настройку базы данных. Нам хочется, чтобы все обязанности по управлению кластером взял на себя какой-нибудь фреймворк, а нам приходилось только писать код. Для решения этой проблемы я использую Cartridge — фреймворк, который управляет кластером из нескольких инстансов Tarantool.
В статье я рассказал:

 habr.com
habr.com
Мне не нравится тратить время на настройку SQL базы данных, думать, как управлять шардированием данных, тратить много времени на изучение интерфейсов коннекторов. Хочется просто написать несколько строчек кода и запустить его, чтобы все работало из коробки. В быстрой разработке распределенных приложений мне помогает Cartridge — фреймворк для управления кластерными приложениями на основе NoSQL базы данных Tarantool.
Сегодня я хочу рассказать о том, как можно быстро написать приложение на Cartridge, покрыть его тестами и запустить. Статья будет интересна всем, кто устал тратить много времени на прототипирование приложений, а также людям, которые хотят попробовать новую NoSQL технологию.
Содержание
В статье вы узнаете о том, что такое Cartridge и познакомитесь с принципами написания кластерной бизнес-логики в нем.
Мы напишем кластерное приложение для хранения данных о сотрудниках некоторой компании, нас ждет:
- Создание приложения из шаблона с cartridge-cli
- Описание своей бизнес-логики на Lua в кластерных ролях Cartridge
- Хранилище данных
- Пользовательское HTTP API
- Написание тестов
- Локальный запуск и настройка небольшого кластера
- Загрузка конфигурации
- Настройка фейловера
Cartridge
Cartridge — это фреймворк для разработки кластерных приложений, он управляет несколькими инстансами NoSQL БД Tarantool и шардирует данные с помощью модуля vshard. Tarantool — это персистентая in-memory база данных, он очень быстрый за счет хранения данных в оперативной памяти, но при этом надежный — Tarantool сбрасывает все данные на жесткий диск и позволяет настроить репликацию, а Cartridge сам заботится о настройке узлов Tarantool и шардировании узлов кластера, так что все, что нужно разработчику — написать бизнес-логику приложений и произвести настройку фейловера.
Преимущества Сartridge
- Шардирование и репликация из коробки
- Встроенный failover
- NoSQL язык кластерных запросов — CRUD
- Интеграционное тестирование всего кластера
- Управление кластером с помощью ansible
- Утилита для администрирования кластера
- Инструменты для мониторинга
Создаем первое приложение
Для этого нам понадобится cartridge-cli — это утилита для работы с картриджными приложениями. Она позволяет создавать приложение из шаблона, управлять локально запущенным кластером и подключаться к инстансам тарантула.
Установим Tarantool и cartridge-cli
Установка на Debian или Ubuntu:
curl -L https://tarantool.io/fJPRtan/release/2.8/installer.sh | bash
sudo apt install cartridge-cli
Установка на CentOS, Fedora или ALT Linux:
curl -L https://tarantool.io/fJPRtan/release/2.8/installer.sh | bash
sudo yum install cartridge-cli
Установка на MacOS:
brew install tarantool
brew install cartridge-cli
Создадим шаблонное приложение с именем myapp:
cartridge create --name myapp
cd myapp
tree .
Получим структуру проекта примерно такого содержания:
myapp
├── app
│ └── roles
│ └── custom.lua
├── test
├── init.lua
├── myapp-scm-1.rockspec
- init.lua — входная точка приложение на картридже, здесь прописывается конфигурация кластера и вызываются функции, которые должны будут выполнены на старте каждого узла приложения.
- в директории app/roles/ хранятся "роли", в которых описывается бизнес-логика приложения.
- myapp-scm-1.rockspec — файл для указания зависимостей
На этом шаге вы уже получите готовое к работе hello world-приложение. Его можно запустить с помощью команд
cartridge build
cartridge start -d
cartridge replicasets setup --bootstrap-vshard
После этого по адресу localhost:8081/hello мы увидим hello-world.
Давайте теперь на основе шаблона напишем свое небольшое приложение — шардированное хранилище с HTTP API для наполнения и получения данных. Для этого нам потребуется понимание того, как пишется кластерная бизнес-логика в Cartridge.
Пишем бизнес-логику в Cartridge
В основе каждого кластерного приложения лежат роли — Lua-модули, в которых описывается бизнес-логика приложения. Например, это могут быть модули, которые занимаются хранением данных, предоставляют HTTP API или кэширует данные из Oracle. Роль назначается на набор инстансов, объединенных репликацией (репликасет) и включается на каждом из них. У разных репликасетов может быть разный набор ролей.
В cartridge есть кластерная конфигурация, которая хранится на каждом из узлов кластера. Там описывается топология, а также туда можно добавить конфигурацию, которой будет пользоваться ваша роль. Такую конфигурацию можно изменять в рантайме и влиять на поведение роли.
Каждая роль имеет структуру следующего вида:
return {
role_name = 'your_role_name',
init = init,
validate_config = validate_config,
apply_config = apply_config,
stop = stop,
rpc_function = rpc_function,
dependencies = {
'another_role_name',
},
}
Жизненный цикл роли
- Инстанс запускается.
- Роль с именем role_name ждет запуска всех зависимых ролей, указанных в dependencies.
- Вызывается функция validate_config, которая проверяет валидность конфига роли.
- Вызывается функция инициализации роли init, в которой производятся действия, которые должны запускаться один раз на старте роли.
- Вызывается apply_config, которая применяет конфиг (если таковой имеется). validate_config и apply_config вызываются также при каждом изменении конфигурации роли.
- Роль попадает в registry, откуда будет доступна для других ролей на этом же узле с помощью
cartridge.service_get('your_role_name'). - Объявленные в роли функции будут доступны для вызова с других узлов с помощью
cartridge.rpc_call('your_role_name', 'rpc_function'). - Перед выключением или перезапуском роли запускется функция stop, которая завершает работу роли, например, удаляют созданные ролью файберы.
Кластерные NoSQL-запросы
В Cartridge есть несколько вариантов написания кластерных запросов:
- Вызовы функций через API vshard (это сложный способ, но зато очень гибкий):
vshard.router.callrw(bucket_id, 'app.roles.myrole.my_rpc_func', {...}) - Tarantool CRUD
- Простые вызовы функций crud.insert / get / replace / ...
- Ограниченная поддержка вычисления bucket_id
- Роли должны иметь зависимость от crud-router / crud-storage
Схема приложения
Представим, что мы хотим кластер с одним роутером и с двумя группами стораджей по два инстанса. Такая топология характерна и для Redis Cluster, и для Mongodb кластера. Также в нашем кластере будет один инстанс — stateboard (в котором stateful-failover будет сохранять состояние текущих мастеров). Когда требуется повышенная надёжность, вместо stateboard лучше использовать кластер etcd.
Роутер будет распределять запросы по кластеру, а также управлять фейловером.
Пишем свои роли
Нам потребуется написать две своих роли, одну для хранения данных, вторую для HTTP API.
В директории app/roles создаем два новых файла: app/roles/storage.lua и app/roles/api.lua
Хранилище данных
Опишем роль для хранения данных. В функции init мы создадим таблицу и индексы для нее, а в зависимости добавим crud-storage.
Если вы привыкли к SQL, то Lua-код в init-функции будет эквивалентен следующему псевдо-SQL коду:
CREATE TABLE employee(
bucket_id unsigned,
employee_id string,
name string,
department string,
position string,
salary unsigned
);
CREATE UNIQUE INDEX primary ON employee(employee_id);
CREATE INDEX bucket_id ON employee(bucket_id);
Добавим следующий код в файл app/roles/storage.lua :
local function init(opts)
-- в opts хранится признак, вызывается функция на мастере или на реплике
-- мы создаем таблицы только на мастере, на реплике они появятся автоматически
if opts.is_master then
-- Создаем таблицу с сотрудниками
local employee = box.schema.space.create('employee', {if_not_exists = true})
-- задаем формат
employee:format({
{name = 'bucket_id', type = 'unsigned'},
{name = 'employee_id', type = 'string', comment = 'ID сотрудника'},
{name = 'name', type = 'string', comment = 'ФИО сотрудника'},
{name = 'department', type = 'string', comment = 'Отдел'},
{name = 'position', type = 'string', comment = 'Должность'},
{name = 'salary', type = 'unsigned', comment = 'Зарплата'}
})
-- Создаем первичный индекс
employee:create_index('primary', {parts = {{field = 'employee_id'}},
if_not_exists = true })
-- Индекс по bucket_id, он необходим для шардирования
employee:create_index('bucket_id', {parts = {{field = 'bucket_id'}},
unique = false,
if_not_exists = true })
end
return true
end
return {
init = init,
-- <<< не забываем про зависимость от crud-storage
dependencies = {'cartridge.roles.crud-storage'},
}
Остальные функции из API роли нам не понадобятся — у нашей роли нет конфигурации и она не выделяет ресурсы, которые нужно очищать после завершения работы.
HTTP API
Нам понадобится вторая роль для наполнения таблиц данными и получения этих данных по запросу. Она будет обращаться к встроенному в Cartridge HTTP-серверу и иметь зависимость от crud-router.
Определим функцию для POST-запроса. В теле запроса будет приходить объект, который мы хотим записать в базу.
local function post_employee(request)
-- достаем объект из тела запроса
local employee = request:json()
-- записываем в БД
local _, err = crud.insert_object('employee', employee)
-- В случае ошибки пишем ее в лог и возвращаем 500
if err ~= nil then
log.error(err)
return {status = 500}
end
return {status = 200}
end
В GET-метод будет передаваться уровень зарплаты сотрудников и в качестве ответа мы будем возвращать JSON со списком сотрудников, которые имеют зарплату выше заданной.
SELECT employee_id, name, department, position, salary
FROM employee
WHERE salary >= @salary
local function get_employees_by_salary(request)
-- достаем query-параметр salary
local salary = tonumber(request:query_param('salary') or 0)
-- отбираем данные о сотрудниках
local employees, err = crud.select('employee', {{'>=', 'salary', salary}})
-- В случае ошибки пишем ее в лог и возвращаем 500
if err ~= nil then
log.error(err)
return { status = 500 }
end
-- в employees хранится список строк, удовлетворяющих условию и формат спейса
-- unflatten_rows нужна, чтобы преобразовать строку таблицы в таблицу вида ключ-значение
employees = crud.unflatten_rows(employees.rows, employees.metadata)
employees = fun.iter(employees):map(function(x)
return {
employee_id = x.employee_id,
name = x.name,
department = x.department,
position = x.position,
salary = x.salary,
}
end):totable()
return request:render({json = employees})
end
Теперь напишем init-функцию роли. Здесь мы обратимся к registry Cartridge для получения HTTP-сервера и используем его для назначения HTTP-эндпоинтов нашего приложения.
local function init()
-- получаем HTTP-сервер из registry Cartridge
local httpd = assert(cartridge.service_get('httpd'), "Failed to get httpd serivce")
-- прописываем роуты
httpd:route({method = 'GET', path = '/employees'}, get_employees_by_salary)
httpd:route({method = 'POST', path = '/employee'}, post_employee)
return true
end
Соберем все это вместе:
app/roles/api.lua
init.lua
Опишем файл init.lua, который будет являться входной точкой приложения на Cartridge. В init-файле картриджа необходимо вызвать функцию cartridge.cfg() для настройки инстанса кластера.
cartridge.cfg(<opts>, <box_opts>)
- <opts> — параметры кластера по умолчанию
- список доступных ролей (нужно указать все роли, даже перманентные, иначе они не появятся в кластере)
- параметры шардирования
- конфигурация WebUI
- и другое
- <box_opts> — параметры Tarantool по умолчанию (которые передаются в box.cfg{} инстанса)
#!/usr/bin/env tarantool
require('strict').on()
-- указываем путь для поиска модулей
if package.setsearchroot ~= nil then
package.setsearchroot()
end
-- конфигурируем Cartridge
local cartridge = require('cartridge')
local ok, err = cartridge.cfg({
roles = {
'cartridge.roles.vshard-storage',
'cartridge.roles.vshard-router',
'cartridge.roles.metrics',
-- <<< Добавляем crud-роли
'cartridge.roles.crud-storage',
'cartridge.roles.crud-router',
-- <<< Добавляем кастомные роли
'app.roles.storage',
'app.roles.api',
},
cluster_cookie = 'myapp-cluster-cookie',
})
assert(ok, tostring(err))
Последним шагом будет описание зависимостей нашего приложения в файле myapp-scm-1.rockspec.
package = 'myapp'
version = 'scm-1'
source = {
url = '/dev/null',
}
-- Добавляем зависимости
dependencies = {
'tarantool',
'lua >= 5.1',
'checks == 3.1.0-1',
'cartridge == 2.7.3-1',
'metrics == 0.11.0-1',
'crud == 0.8.0-1',
}
build = {
type = 'none';
}
Код приложения уже готов к запуску, но сначала мы напишем тесты и удостоверимся в его работоспособности.
Пишем тесты
Любое приложение нуждается в тестировании. Для unit-тестов хватит обычного luatest, но если вы хотите написать хороший интеграционный тест, вам поможет модуль cartridge.test-helpers. Он поставляется вместе с Cartridge и позволяет поднять в тестах кластер любого состава, который вам нужен.
local cartridge_helpers = require('cartridge.test-helpers')
-- создаем тестовый кластер
local cluster = cartridge_helpers.Cluster:new({
server_command = './init.lua', -- entrypoint тестового приложения
datadir = './tmp', -- директория для xlog, snap и других файлов
use_vshard = true, -- включение шардирования кластера
-- список репликасетов:
replicasets = {
{
alias = 'api',
uuid = cartridge_helpers.uuid('a'),
roles = {'app.roles.custom'}, -- список ролей, назначенных на репликасет
-- список инстансов в репликасете:
servers = {
{ instance_uuid = cartridge_helpers.uuid('a', 1), alias = 'api' },
...
},
},
...
}
})
Напишем вспомогательный модуль, который будем использовать в интеграционных тестах. В нем создается тестовый кластер из двух репликасетов, в каждом из которых будет по одному инстансу:
Код вспомогательного модуля:
test/helper.lua
Код интеграционного теста:
test/integration/api_test.lua
Запускаем тесты
Если вы уже запускали приложение
Остановите его:
cartridge stop
Удалите папку с данными:
rm -rf tmp/
Соберем приложение и установим зависимости:
cartridge build
./deps.sh
Запустим линтер:
.rocks/bin/luacheck .
Запустим тесты с записью покрытия:
.rocks/bin/luatest --coverage
Сгенерируем отчеты по покрытию тестов и посмотрим на результат:
.rocks/bin/luacov .
grep -A999 '^Summary' tmp/luacov.report.out
Локальный запуск
Для локального запуска приложений можно воспользоваться cartridge-cli, но сначала нужно добавить написанные нами роли в replicasets.yml:
router:
instances:
- router
roles:
- failover-coordinator
- app.roles.api
all_rw: false
s-1:
instances:
- s1-master
- s1-replica
roles:
- app.roles.storage
weight: 1
all_rw: false
vshard_group: default
s-2:
instances:
- s2-master
- s2-replica
roles:
- app.roles.storage
weight: 1
all_rw: false
vshard_group: default
С параметрами запускаемых инстансов можно ознакомиться в instances.yml.
Запускаем кластер локально:
cartridge build
cartridge start -d
cartridge replicasets setup --bootstrap-vshard
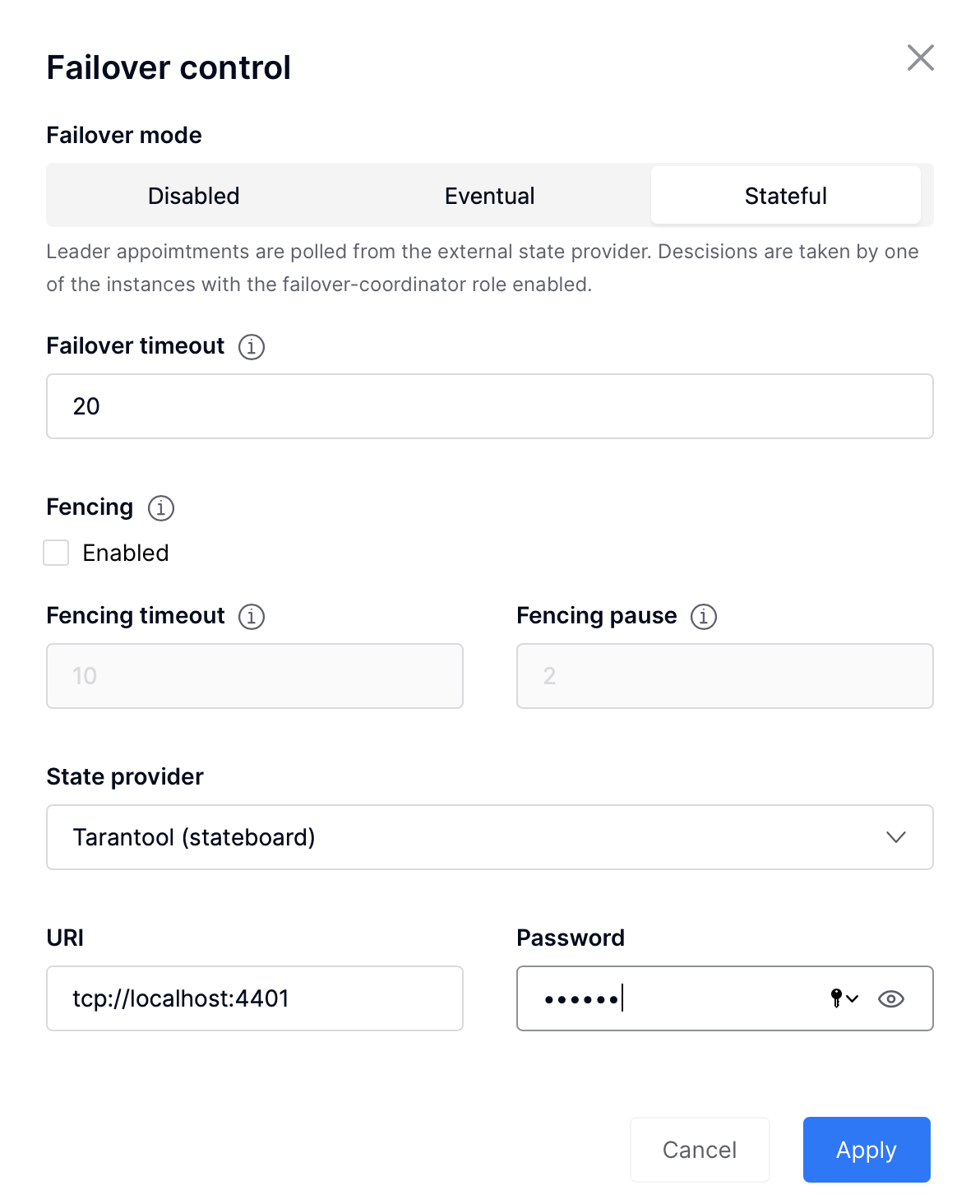
Теперь мы можем зайти в webui и загрузить конфигурацию ролей, а также настроить фейловер. Чтобы настроить stateful failover, необходимо:
- нажать на кнопку Failover
- выбрать stateful
- прописать адрес и пароль:
- localhost:4401
- passwd
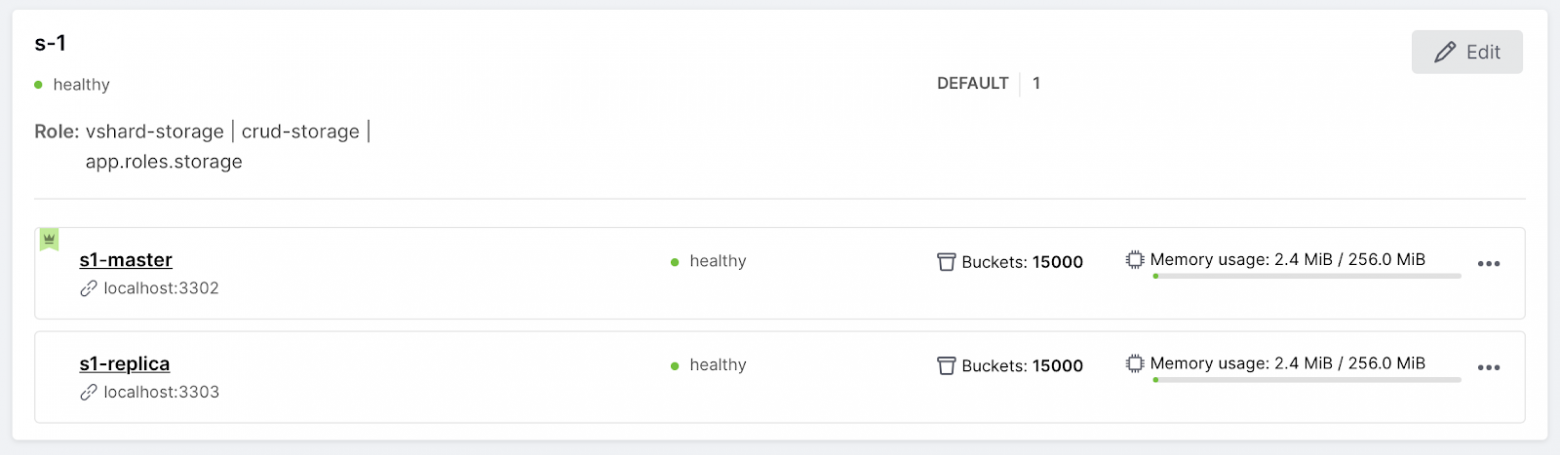
Давайте посмотрим на его работу. Сейчас в репликасете s-1 лидером является s1-master.
Остановим его:
cartridge stop s1-master
Лидер переключится на s1-replica:
Восстановим s1-master:
cartridge start -d s1-master
s1-master поднялся, но благодаря stateful-фейловеру лидером остается s1-replica:
Загрузим конфигурацию для роли cartridge.roles.metrics, для этого необходимо перейти на вкладку Code и создать файл metrics.yml следующего содержания:
export:
- path: '/metrics'
format: prometheus
- path: '/health'
format: health
После того, как мы нажмем на кнопку Apply, метрики будут доступны на каждом узле приложения по эндпоинту localhost:8081/metrics и появится health-check по адресу localhost:8081/health.
На этом базовая настройка небольшого приложения завершена: кластер готов к работе и теперь мы можем написать приложение, которое будет общаться с кластером с помощью HTTP API или через коннектор, а также можем расширять функциональность кластера.
Заключение
Многим разработчикам не нравится тратить время на настройку базы данных. Нам хочется, чтобы все обязанности по управлению кластером взял на себя какой-нибудь фреймворк, а нам приходилось только писать код. Для решения этой проблемы я использую Cartridge — фреймворк, который управляет кластером из нескольких инстансов Tarantool.
В статье я рассказал:
- как построить надежное кластерное приложение с помощью Cartridge и Tarantool,
- как написать код небольшого приложения для хранения информации о сотрудниках,
- как добавить тесты,
- как настроить кластер.
Пишем распределенное хранилище за полчаса
Привет, меня зовут Игорь и я работаю в команде Tarantool. При разработке мне часто требуется быстрое прототипирование приложений с базой данных, например, для тестирования кода или для создания MVP....
habr.com