Обычно в кодовой базе крупных проектов есть более и менее важные фрагменты. Бывают ситуации, когда разработчику необходимо знать, какие части кода важнее других. Например, если на улучшение проекта дается фиксированное время или нужно выяснить, какие модули популярной библиотеки используются чаще.
Сейчас готовых средств для ранжирования кода по важности нет. Поэтому студентка второго курса программы «Прикладная математика и информатика» Олеся Субботина решила написать такой плагин в рамках проектной работы по Java.
Как статический и динамический анализ кода помогают оценить его важность, какой анализ показывает лучшие результаты, и как вообще был реализован плагин, читайте под катом.

Я Олеся Субботина, студентка второго курса бакалавриата «Прикладная математика и информатика» в Питерской Вышке.
Интересного олимпиадного прошлого у меня нет, потому что до поступления в университет я не занималась программированием от слова совсем. Моим максимумом были задания ЕГЭ на Pascal. Так что в начале учебы пришлосьстрадать очень много работать, но сейчас, в конце второго курса, я чувствую себя довольно комфортно и стабильно.
В прошлом году, во время работы над командным проектом по С++, я занималась написанием графического приложения. И когда этой зимой пришло время задуматься над темой курсовой работы по Java, я решила, что хочу попробовать себя в чём-то совсем другом, более низкоуровневом, сделать свой небольшой вклад в сферу разработки. Поэтому в начале весеннего семестра я оставила заявку на участие в проекте «Ранжирование фрагментов кода по важности». Руководителем проекта был Сергей Александрович Резник, senior developer в компании Kofax. Для участия я сделала небольшое тестовое задание, успешно прошла собеседование и в итоге начала работу над проектом.
Обычно в кодовой базе крупных проектов есть более и менее важные фрагменты. Под фрагментами здесь можно понимать разные вещи: классы, методы, пакеты. Суть проекта состояла в том, что эти фрагменты нужно проранжировать по важности, по строгому критерию и автоматически.
Важность — довольно широкое понятие. В моём случае более важными считаются те фрагменты кода, которые чаще всего используется, и те, от которых зависит много других значимых частей. А за фрагменты кода в реализации проекта я принимаю методы и классы.
Опишу некоторые возможные применения описанной идеи:
По-своему оценить значимость кода могут измерители покрытия, такие как Jacoco и Jcov. Специфика проведенного на их основе анализа состоит в том, что они, например, тоже могут отследить часто вызываемые методы, но при этом, в отличие от моей реализации, не учитывают значимость частей кода, которые их вызывают. Также существуют профайлеры, то есть сборщики характеристик работы программы. Одними из самых известных являются JProfiler и YourKit. Но они больше нацелены на измерение времени, потребляемой памяти и на обнаружение узких мест программы. Исходя из этих данных, конечно, можно оценить значимость кода, однако сделать это корректно будет довольно сложно.
Так что работа над проектом была разбита на следующие подзадачи:

Первым делом я реализовала статический анализ кода. Это анализ, основанный исключительно на обработке исходного кода программы и происходящий без ее реального выполнения.
За метрику ранжирования руководитель проекта предложил взять ранжирование по методам классов, поэтому далее при реализации я отслеживала связи только между методами. И статический анализ я проводила как раз с целью получения этих зависимостей.
Во время анализа я проходилась по коду заданного проекта и собирала информацию, какие методы где вызываются, чтобы далее построить граф, описывающий эти зависимости. Для реализации мне понадобилось поверхностно изучить устройство байткода Java и поработать с библиотекой ASM, которая предназначена для анализа, генерации и модификации байткода.
Работа с ASM была нетривиальной, потому что эта библиотека основана на паттерне, который называется визитор. По сути это шаблон проектирования, описывающий операцию, которая выполняется над объектами других классов. То есть существует класс — визитор, который содержит методы для работы с каждой из конкретных реализаций некоторой пользовательской абстракции. А каждая конкретная реализация содержит метод, который передаёт себя соответствующему методу класса-посетителя. Из-за этого паттерна работать с ASM было очень непривычно.
Но в итоге я просто расширила библиотечные классы, которые обходят классы и методы заданного проекта. И добилась того, что при вызове посещающих классы и методы функций в специальном контейнере собиралась нужная мне информация.
public class FirstClass {
public static void secondClassCaller() {
for (int i = 0; i < 3; i++) {
SecondClass.someMethod();
}
}
public static void uselessMethod() {
System.out.println(“This is a useless method”);
}
}
public class SecondClass {
public static void someMethod() {
System.out.println(“Method from the second class has been called”);
}
}
Вы можете видеть очень простую реализацию двух классов. Метод первого класса secondClassCaller вызывает метод someMethod из второго класса. Следовательно, secondClassCaller — родитель someMethod. А метод uselessMethod существует отдельно от всего: у него нет ни родителей, ни детей. Граф, построенный на основе этих двух классов, показан ниже.
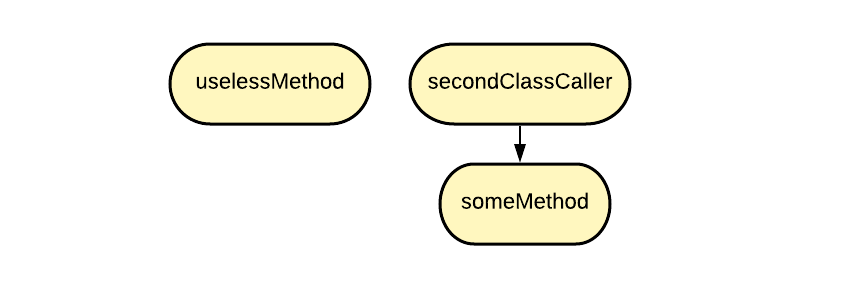
На этом графе я запустила известный алгоритм Pagerank. Это алгоритм ссылочного ранжирования, основанный на вычислении веса объекта путем подсчета важности ссылающихся на него сущностей.
 Источник: Delante
Источник: Delante
В итоге на выходе алгоритма я получила статически отсортированный список методов. Но методов в проектах может быть очень-очень много, поэтому я сгруппировала их по классам и вернула пользователю отсортированный по важности список классов проекта. На этом с реализацией статического анализа я закончила.
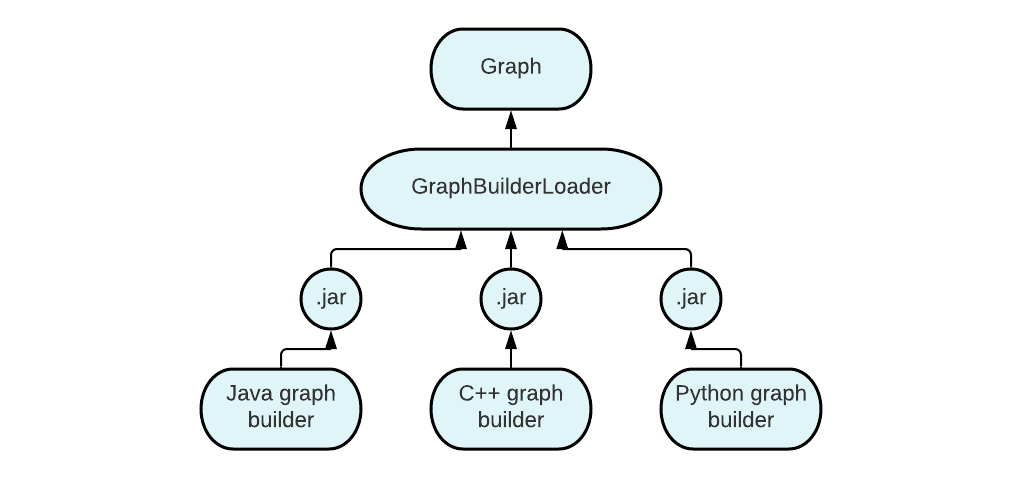
На схеме ниже показан пример работы этой идеи. У пользователя есть три своих класса для построения графов: для Java, C++ и Python. Любой из них он может собрать в jar-ник и передать классу, отвечающему за загрузку построителей — GraphBuilderLoader. В этом классе и произойдет создание графа (Graph) через нужного построителя.
Далее я оформила проект как плагин для gradle, чтобы человек, которому интересно ранжировать код, подключал его к своему проекту и получал отчёты. Написанный ранее построитель графов для Java я тоже вынесла в плагин. Созданием плагина я занималась впервые, это было довольно интересно и местами сложно. В процессе я немножко познакомилась с Kotlin и со спецификой работы с системой сборки Gradle. В итоге я получила полноценный расширяемый gradle-плагин.

Для запуска такого анализа нужно как-то модифицировать исходный код исследуемого проекта, чтобы получить возможность собирать в нём информацию. Для модификации кода (а точнее байткода) я воспользовалась библиотекой Javaassist, предназначенной для инструментирования байткода. С её помощью я отслеживала инструкции байткода, такие как invokevirtual и invokeinterface. Они дают информацию о том, какой метод был вызван в рантайме в том или ином месте кода. В каждое место в байткоде, где встречалась интересная мне инструкция, я вставила вызов метода, который регистрирует в специальном контейнере пару, определяющую «кто кого в этом месте вызвал». В итоге я получила новую скомпилированную версию проекта уже с модифицированным кодом.
Пример модифицированного кода может выглядеть так:
BytecodeInsertion.toInsert("ru.hse.projects.maze.Launcher", "ru.hse.projects.maze.MazeSolver", "invokevirtual"); // добавленная строчка
mazeSolverInstance.readInput(); // строчка исходного кода класса Launcher
Здесь посредством вызова функции toInsert из класса «сборщика информации» BytecodeInsertion я зарегистрирую нужную мне информацию. А именно: «В классе ru.hse.projects.maze.Launcher происходит вызов метода класса ru.hse.projects.maze.MazeSolver».
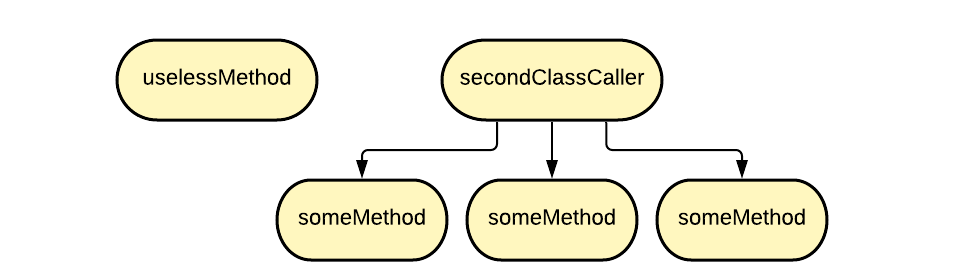
Граф, представленный ниже, отражает наиболее важное и ощутимое отличие динамического анализа от статического.
В примере кода, который я давала ранее, метод someMethod вызывался в функции secondClassCaller в цикле for 3 раза. Статический анализ просто зашел в код secondClassCaller, увидел, что там вызывается someMethod, и добавил его к детям secondClassCaller. А вот динамический анализ знает, сколько именно раз был вызван тот или иной метод и учитывает это количество при выдаче начальных приоритетов для алгоритма Pagerank. Условно говоря, эти выставленные приоритеты как бы говорят о том, что у secondClassCaller есть три ребенка типа someMethod. Это и показано на схеме ниже.
На построенном графе я снова запустила Pagerank, аналогично получив на выходе ранжированный список классов.
Мы с руководителем проекта обсудили возможные проблемы, возникающие при динамическом анализе. Для некоторых из них он предложил решения, которые я не успела реализовать из-за нехватки времени. Но все же осталось несколько проблем, красивых решений для которых быстро придумать не удалось. Например, некорректно обрабатываются некоторые вызовы системных классов. А именно, не решена проблема с тем, что в коде отслеживаются вызовы только для пользовательских классов. И, может быть, в проекте пользователя есть класс, который имплементит какой-то системный интерфейс. Тогда в инструкции байткода о вызове метода в этом месте будет прописан вызов метода системного класса, а не пользовательского, и я его просто проигнорирую.
Также есть проблема с отсутствием в пользовательском проекте зависимости от класса «сборщика информации». Заключается она в том, что при инструментировании байткода мне понадобилось вставлять вызов метода из класса-сборщика в файлы пользовательского проекта, который о существовании это класса ничего не знает. Поэтому просто так код не скомпилируется. Пока что для решения этой проблемы от пользователя требуется руками прописать импорты класса-сборщика в файлы своего проекта, предварительно добавив в проект зависимость от этого класса, и только потом проводить инструментирование байткода. Но есть и более красивое решение: использовать отдельный класслоадер для взаимодействия с пользовательским проектом, предварительно загрузив класс-сборщик ByteCodeInsertion.
Видно, что по сравнению с экспертной оценкой, динамический анализ оказался более точным. Это ожидаемо: он учитывает количество раз, которое тот или иной метод был вызван в рантайме. А вот статический анализ, к примеру, переоценил важность класса Launcher, отвечающего за запуск проекта. Это произошло потому, что в Launcher-e вызываются важные методы из классов, стоящих выше в иерархии, поэтому и ему самому по транзитивности был присвоен довольно высокий рейтинг.

Также отмечу, что я запускала плагин и на других, более крупных проектах. Например, на части тестового фреймворка JUnit, с которым я частично знакома. Поэтому на нём тоже была возможность успешно провести некоторого рода экспертную оценку.
Хочется отметить, что расширяемость плагина является важным отличием этого проекта от возможных аналогов. Ведь благодаря тому, что построение и анализ графа не зависят друг от друга, в будущем можно будет адаптироваться под разные языки программирования, метрики ранжирования и под разные представления графа.
Ну и, конечно, есть несколько вариантов дополнения и улучшения проекта в будущем, это:
Спасибо за чтение!
Источник статьи: https://habr.com/ru/company/hsespb/blog/567332/
Сейчас готовых средств для ранжирования кода по важности нет. Поэтому студентка второго курса программы «Прикладная математика и информатика» Олеся Субботина решила написать такой плагин в рамках проектной работы по Java.
Как статический и динамический анализ кода помогают оценить его важность, какой анализ показывает лучшие результаты, и как вообще был реализован плагин, читайте под катом.
О себе и выборе проекта
Всем привет!Я Олеся Субботина, студентка второго курса бакалавриата «Прикладная математика и информатика» в Питерской Вышке.
Интересного олимпиадного прошлого у меня нет, потому что до поступления в университет я не занималась программированием от слова совсем. Моим максимумом были задания ЕГЭ на Pascal. Так что в начале учебы пришлось
В прошлом году, во время работы над командным проектом по С++, я занималась написанием графического приложения. И когда этой зимой пришло время задуматься над темой курсовой работы по Java, я решила, что хочу попробовать себя в чём-то совсем другом, более низкоуровневом, сделать свой небольшой вклад в сферу разработки. Поэтому в начале весеннего семестра я оставила заявку на участие в проекте «Ранжирование фрагментов кода по важности». Руководителем проекта был Сергей Александрович Резник, senior developer в компании Kofax. Для участия я сделала небольшое тестовое задание, успешно прошла собеседование и в итоге начала работу над проектом.
Ранжирование по важности — зачем это нужно?
Для начала хочу рассказать, кто кого ранжирует, и зачем это все вообще нужно.Обычно в кодовой базе крупных проектов есть более и менее важные фрагменты. Под фрагментами здесь можно понимать разные вещи: классы, методы, пакеты. Суть проекта состояла в том, что эти фрагменты нужно проранжировать по важности, по строгому критерию и автоматически.
Важность — довольно широкое понятие. В моём случае более важными считаются те фрагменты кода, которые чаще всего используется, и те, от которых зависит много других значимых частей. А за фрагменты кода в реализации проекта я принимаю методы и классы.
Опишу некоторые возможные применения описанной идеи:
- Первый пример: нам дается фиксированное время на улучшение проекта. В такой ситуации целесообразно понять, какие участки кода более важные, и начать работать с ними, а менее важные отложить на потом.
- Второй, более конкретный пример: допустим, у нас на руках есть крупная популярная библиотека, и нам хочется узнать, какие её модули чаще всего используются в сторонних проектах. Для этого можно взять набор крупных проектов, выявить наиболее важные их фрагменты и проанализировать, какие части нашей библиотеки чаще всего в них используются.
- Ну и, конечно, ранжирование по важности может применяться для сбора статистики о проектах.
Существующие аналоги
Идея этого проекта возникла у моего руководителя как раз за неимением готовых средств для ранжирования кода по важности, поэтому точных аналогов проекта нет. Тем не менее, существует множество смежных инструментов.По-своему оценить значимость кода могут измерители покрытия, такие как Jacoco и Jcov. Специфика проведенного на их основе анализа состоит в том, что они, например, тоже могут отследить часто вызываемые методы, но при этом, в отличие от моей реализации, не учитывают значимость частей кода, которые их вызывают. Также существуют профайлеры, то есть сборщики характеристик работы программы. Одними из самых известных являются JProfiler и YourKit. Но они больше нацелены на измерение времени, потребляемой памяти и на обнаружение узких мест программы. Исходя из этих данных, конечно, можно оценить значимость кода, однако сделать это корректно будет довольно сложно.
Цель работы
Основная цель моей работы — написать расширяемый gradle плагин с возможностью проведения нескольких вариантов анализа кода. И, исходя из результатов анализа, предоставить пользователю список ранжированных по важности фрагментов кода заданного им проекта.Так что работа над проектом была разбита на следующие подзадачи:
- реализация статического анализа кода;
- оформление проекта в виде плагина для gradle;
- реализация динамического анализа кода.
Статический анализ
Первым делом я реализовала статический анализ кода. Это анализ, основанный исключительно на обработке исходного кода программы и происходящий без ее реального выполнения.
За метрику ранжирования руководитель проекта предложил взять ранжирование по методам классов, поэтому далее при реализации я отслеживала связи только между методами. И статический анализ я проводила как раз с целью получения этих зависимостей.
Во время анализа я проходилась по коду заданного проекта и собирала информацию, какие методы где вызываются, чтобы далее построить граф, описывающий эти зависимости. Для реализации мне понадобилось поверхностно изучить устройство байткода Java и поработать с библиотекой ASM, которая предназначена для анализа, генерации и модификации байткода.
Работа с ASM была нетривиальной, потому что эта библиотека основана на паттерне, который называется визитор. По сути это шаблон проектирования, описывающий операцию, которая выполняется над объектами других классов. То есть существует класс — визитор, который содержит методы для работы с каждой из конкретных реализаций некоторой пользовательской абстракции. А каждая конкретная реализация содержит метод, который передаёт себя соответствующему методу класса-посетителя. Из-за этого паттерна работать с ASM было очень непривычно.
Но в итоге я просто расширила библиотечные классы, которые обходят классы и методы заданного проекта. И добилась того, что при вызове посещающих классы и методы функций в специальном контейнере собиралась нужная мне информация.
Построение графа зависимостей и Pagerank
На основе полученных при статическом анализе данных я построила граф зависимостей между методами. Чтобы лучше понять, как именно строился граф, предлагаю посмотреть на пример ниже:public class FirstClass {
public static void secondClassCaller() {
for (int i = 0; i < 3; i++) {
SecondClass.someMethod();
}
}
public static void uselessMethod() {
System.out.println(“This is a useless method”);
}
}
public class SecondClass {
public static void someMethod() {
System.out.println(“Method from the second class has been called”);
}
}
Вы можете видеть очень простую реализацию двух классов. Метод первого класса secondClassCaller вызывает метод someMethod из второго класса. Следовательно, secondClassCaller — родитель someMethod. А метод uselessMethod существует отдельно от всего: у него нет ни родителей, ни детей. Граф, построенный на основе этих двух классов, показан ниже.
На этом графе я запустила известный алгоритм Pagerank. Это алгоритм ссылочного ранжирования, основанный на вычислении веса объекта путем подсчета важности ссылающихся на него сущностей.
В итоге на выходе алгоритма я получила статически отсортированный список методов. Но методов в проектах может быть очень-очень много, поэтому я сгруппировала их по классам и вернула пользователю отсортированный по важности список классов проекта. На этом с реализацией статического анализа я закончила.
Плагин — архитектура
Мой анализ работает только для Java, но было бы хорошо оставить сторонним разработчикам возможность расширить проект и в идеале достичь инвариантности относительно языка программирования. Поэтому следующим шагом я реализовала класс, который занимался загрузкой пользовательских классов для построения графа. Другими словами, я предоставила разработчику возможность самостоятельно реализовать построение графа зависимостей, собрать реализацию в jar-файл и указать его при запуске проекта. Тогда нужный класс, отвечающий за построение графов, будет загружен через classloader и создание графа осуществится через него. Чтобы пользовательский построитель графов получилось корректно внедрить в проект, я задала на него требования и прописала их в специальном интерфейсе для построителя графов. Пользовательский класс должен его имплементить.На схеме ниже показан пример работы этой идеи. У пользователя есть три своих класса для построения графов: для Java, C++ и Python. Любой из них он может собрать в jar-ник и передать классу, отвечающему за загрузку построителей — GraphBuilderLoader. В этом классе и произойдет создание графа (Graph) через нужного построителя.
Далее я оформила проект как плагин для gradle, чтобы человек, которому интересно ранжировать код, подключал его к своему проекту и получал отчёты. Написанный ранее построитель графов для Java я тоже вынесла в плагин. Созданием плагина я занималась впервые, это было довольно интересно и местами сложно. В процессе я немножко познакомилась с Kotlin и со спецификой работы с системой сборки Gradle. В итоге я получила полноценный расширяемый gradle-плагин.
Инструментирование байткода
На самом деле, для решения подобных задач статический анализ используется довольно редко, особенно для языков, в которых есть динамический полиморфизм. Так происходит потому, что на этапе статического анализа невозможно понять, какой именно наследник класса в том или ином месте может применяться. А в Java есть еще и часто используемый reflection, который статическим анализом поймать очень непросто. Поэтому для более корректного анализа лучше применять динамический анализ кода, то есть анализ программы, который проводится в момент ее исполнения. У меня как раз осталось достаточно свободного времени, чтобы дополнительно сделать еще один масштабный блок проекта. И мы с руководителем решили, что стоит попробовать реализовать динамический анализ.
Для запуска такого анализа нужно как-то модифицировать исходный код исследуемого проекта, чтобы получить возможность собирать в нём информацию. Для модификации кода (а точнее байткода) я воспользовалась библиотекой Javaassist, предназначенной для инструментирования байткода. С её помощью я отслеживала инструкции байткода, такие как invokevirtual и invokeinterface. Они дают информацию о том, какой метод был вызван в рантайме в том или ином месте кода. В каждое место в байткоде, где встречалась интересная мне инструкция, я вставила вызов метода, который регистрирует в специальном контейнере пару, определяющую «кто кого в этом месте вызвал». В итоге я получила новую скомпилированную версию проекта уже с модифицированным кодом.
Пример модифицированного кода может выглядеть так:
BytecodeInsertion.toInsert("ru.hse.projects.maze.Launcher", "ru.hse.projects.maze.MazeSolver", "invokevirtual"); // добавленная строчка
mazeSolverInstance.readInput(); // строчка исходного кода класса Launcher
Здесь посредством вызова функции toInsert из класса «сборщика информации» BytecodeInsertion я зарегистрирую нужную мне информацию. А именно: «В классе ru.hse.projects.maze.Launcher происходит вызов метода класса ru.hse.projects.maze.MazeSolver».
Динамический анализ
Для сбора информации на модифицированной версии пользователь должен качественно прогнать свой код, например запустив тесты. В процессе работы программы все вызванные в рантайме методы будут зарегистрированы в специальном контейнере. На основе полученных при запуске программы данных я снова построила граф зависимостей.Граф, представленный ниже, отражает наиболее важное и ощутимое отличие динамического анализа от статического.
В примере кода, который я давала ранее, метод someMethod вызывался в функции secondClassCaller в цикле for 3 раза. Статический анализ просто зашел в код secondClassCaller, увидел, что там вызывается someMethod, и добавил его к детям secondClassCaller. А вот динамический анализ знает, сколько именно раз был вызван тот или иной метод и учитывает это количество при выдаче начальных приоритетов для алгоритма Pagerank. Условно говоря, эти выставленные приоритеты как бы говорят о том, что у secondClassCaller есть три ребенка типа someMethod. Это и показано на схеме ниже.
На построенном графе я снова запустила Pagerank, аналогично получив на выходе ранжированный список классов.
Проблемы динамического анализа
Отмечу, что поскольку эта часть проекта была дополнительной, динамический анализ пока что требует доработки.Мы с руководителем проекта обсудили возможные проблемы, возникающие при динамическом анализе. Для некоторых из них он предложил решения, которые я не успела реализовать из-за нехватки времени. Но все же осталось несколько проблем, красивых решений для которых быстро придумать не удалось. Например, некорректно обрабатываются некоторые вызовы системных классов. А именно, не решена проблема с тем, что в коде отслеживаются вызовы только для пользовательских классов. И, может быть, в проекте пользователя есть класс, который имплементит какой-то системный интерфейс. Тогда в инструкции байткода о вызове метода в этом месте будет прописан вызов метода системного класса, а не пользовательского, и я его просто проигнорирую.
Также есть проблема с отсутствием в пользовательском проекте зависимости от класса «сборщика информации». Заключается она в том, что при инструментировании байткода мне понадобилось вставлять вызов метода из класса-сборщика в файлы пользовательского проекта, который о существовании это класса ничего не знает. Поэтому просто так код не скомпилируется. Пока что для решения этой проблемы от пользователя требуется руками прописать импорты класса-сборщика в файлы своего проекта, предварительно добавив в проект зависимость от этого класса, и только потом проводить инструментирование байткода. Но есть и более красивое решение: использовать отдельный класслоадер для взаимодействия с пользовательским проектом, предварительно загрузив класс-сборщик ByteCodeInsertion.
Сравнение полученных результатов
На скрине ниже можно увидеть три оценки анализа небольшого проекта: статическую, динамическую и экспертную.Видно, что по сравнению с экспертной оценкой, динамический анализ оказался более точным. Это ожидаемо: он учитывает количество раз, которое тот или иной метод был вызван в рантайме. А вот статический анализ, к примеру, переоценил важность класса Launcher, отвечающего за запуск проекта. Это произошло потому, что в Launcher-e вызываются важные методы из классов, стоящих выше в иерархии, поэтому и ему самому по транзитивности был присвоен довольно высокий рейтинг.
Также отмечу, что я запускала плагин и на других, более крупных проектах. Например, на части тестового фреймворка JUnit, с которым я частично знакома. Поэтому на нём тоже была возможность успешно провести некоторого рода экспертную оценку.
Подведем итог
За время работы над проектом я создала расширяемый gradle-плагин, в котором присутствует возможность проведения статического и динамического анализов кода. В результате, после построения графа зависимостей методов и ранжирования его через алгоритм Pagerank, пользователь получает список ранжированных по важности классов заданного им проекта.Хочется отметить, что расширяемость плагина является важным отличием этого проекта от возможных аналогов. Ведь благодаря тому, что построение и анализ графа не зависят друг от друга, в будущем можно будет адаптироваться под разные языки программирования, метрики ранжирования и под разные представления графа.
Ну и, конечно, есть несколько вариантов дополнения и улучшения проекта в будущем, это:
- доработка динамического анализа,
- расширение плагина, достижение инвариантности относительно языка программирования,
- добавление метрик ранжирования,
- ускорение и оптимизации
Спасибо за чтение!
Источник статьи: https://habr.com/ru/company/hsespb/blog/567332/