Продукт стартапа Datafold — платформа для мониторинга аналитических данных. Они подключаются к хранилищам данных и ETL и BI-системам, помогая дата-сайентистам и инженерам отслеживать потоки данных, их качество и аномалии
И однажды стартап решил поменять стек. Как так случилось? Это же затраты и все возникающие при этом сложности переезда. Но если хочешь получить короткий, эргономичный, хорошо читаемый код, приходится идти на жертвы. Но давайте по порядку.
Алекс Морозов, co-founder & CTO в компании Datafold, рассказал, как они переехали с Flask на FastAPI и поделился собственным опытом такого переезда. Это не только то, что пишут в документации, а конкретные проблемы, с которыми они столкнулись при переезде, и как они их обошли. На примерах посмотрим, что стоит сделать, а каких решений лучше избегать.

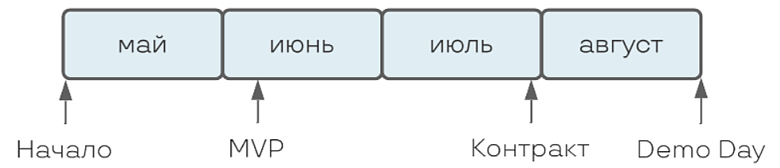
Полтора года назад стартап Datafold прошел в Ycombinator, ведущий акселератор для небольших компаний. Это значило, что у них было 4 месяца, чтобы показать результат, и 1-2 месяца — чтобы написать MVP.
У фаундеров не было глубокой экспертизы в веб-разработке — до этого они занимались Data Engineering и системным программированием. Поэтому они решили стартовать с готового проекта и на его базе построить нужный функционал. Рассмотрев несколько вариантов, остановились на Redash — он оказался очень близок по тематике. У него те же самые аналитические базы, подключение и стандартный User Management. К тому же у Redash лицензия MIT, то есть разработчики разрешают использовать код даже в закрытых форках. И наконец, это современный Single Page Application.

Хэндлер получает данные, достает их из тела запроса как JSON, валидирует и конвертирует поля. То есть для простых вещей требуется очень много кода. А если еще хочется получать толковые сообщения об ошибках (например, поле не того типа или нужное поле отсутствует), то boilerplate выходит еще в несколько раз больше.
Есть несколько вариантов, упростить и ускорить конвертацию и валидацию. Например, можно использовать JSON-схему, но тогда date/datetime все равно придется парсить руками. Ещё вариант — использовать модули pydantic или marshmallow, которые в Redash не употреблялись.
Дальше видно, что привязка роутов делается позже, в отдельном месте. Хотя лучше было бы сделать её декоратором сразу на хэндлере. В хэндлере объявляется переменная idx, и её тип дублируется в роуте.
Кроме того, вся логика сдвинута на 2 отступа, что кажется мелочью. Но в реальном коде может быть, например, контекстный менеджер, exception handling, цикл, пара вложенных if/else. Ещё по сути ничего не написано, а код уже размазывается об правую границу экрана. И лишний второй отступ хорошо в этом помогает.
Ещё Flask-RESTful ничего не знает о типах данных, и поэтому не может экспортировать схему в каком-либо машиночитаемом формате. C автодокументацией тоже проблемы. Flask-RESTful находится в режиме поддержки и не развивается, хотя есть более современные форки.
Или вот еще одна часть, которая вызывает трение — Flask-SQLAlchemy:

Есть стандартный интерфейс для выборок данных SQLAlchemy, с которым все знакомы. Flask-SQLAlchemy добавляет урезанный вариант выборок, который короче на десяток символов. Такая экономия хороша для CRUD-бэкэндов. Но если вы делаете что-то более сложное, то вдобавок к урезанному интерфейсу приходится использовать и стандартный. Получающаяся смесь того не стоит. Ещё надо добавить, что на всех моделях резервируется слово «query», которое в области Data Engineering используется везде, и приходится выдумывать для него синонимы.
Использование Flask-SQLAlchemy в проекте Datafold-а приводило к циклическим зависимостям: для инициализации приложения надо было достать конфигурацию из БД, а чтобы достать что-то из БД через Flask-SQLAlchemy, нужно инициализированное приложение. Это можно решить некрасивыми хаками, но за них приходится платить понятностью кода.
Есть ещё один момент — Flask-SQLAlchemy использует scoped-сессии БД. То есть в начале каждого запроса кладет сессию в thread-locals, и потом каждый раз магически достает её оттуда. Когда дело выходит за пределы http-хэндлеров, то становится удобнее передавать сессию в явном виде. Хотя это, во многом, дело вкуса. До той поры, когда в воркерах Celery вам приходится инициализировать приложение Flask, чтобы бизнес-логика могла работать с базой из воркеров.
На фронтенде тоже возникали проблемы. При использовании React + JS были постоянные ошибки типов в рантайме. А поскольку все данные передаются по приложению с помощью Object (в Python аналог передача словарями), то местами сложно понять, с каким типом данных имеешь дело. Поэтому проект решили переводить на React + TypeScript. При этом интерфейсные типы в TS переносились из API бэкэнда руками. Из-за переноса вручную часто получался рассинхрон, и снова возникали ошибки в рантайме.
Надо было искать более подходящее решение, поэтому начали прорабатывать другие варианты и остановились на FastAPI.

Здесь мы видим несколько положительных моментов.
Валидация делается с помощью pydantic, надо только определить модель (CiRun) и задать типы полей. Всё остальное: парсинг, валидацию, handling и формирование текста ошибок pydantic делает сам, спасая от boilerplate.Также, FastAPI позволяет избавиться от проблемы с дублированием аннотации типов в URL. Здесь тип достаточно указать только в одном месте. А ещё теперь в коде один отступ!
Сомнительно выглядит то, что возвращаемый тип указан не в аннотации метода, а в декораторе. Но если подумать, то это резонно — часто нужно возвращать типы в обертках, например с нестандартными HTTP-статусами.
Например, как сгенерировать описание интерфейса для TypeScript:
$ curl https://localhost:8000/openapi.json >openapi.json
$ npx openapi-typescript schema.json --output schema.ts
Если генерацию типов выполнять во время билда, то проблема синхронизации между фронтом и бэком решается.
Часто с производительностью смешивают поддержку async. Если она вдруг нужна, то хэндлер просто декларируется как async и в нем пишется асинхронный код как обычно:
@router.post('/api/...')
async def ci_run_async(...):
...
Тут стоит заметить, что async реально нужен только в небольшом количестве случаев, например если вы используете вебсокеты, или long-polling. В случае Datafold внутренняя асинхронность FastAPI только доставляла проблемы.
Сначала начали убирать модули, которые можно было убрать на рабочем Flask. Заменили Flask-Migrate на стандартный alembic, flask.cli на click, а для Flask—SQLAlchemy сделали затычку. Подставили атрибут Model.query на все модели, чтобы не разрушать интерфейс выборок, иначе пришлось бы сразу рефакторить 90% кода.
После этого они вставили FastAPI-сервер непосредственно перед Flask. Запросы сначала приходили на него, а он передавал их дальше Flask:
fastapi_app.mount(
"/api",
WSGIMiddleware(flask_app, workers=10)
)
Аутентификацию нужно было делать по cookie и по токенам. Для этого на базе имеющихся в FastAPI классов пришлось написать немного кода и тщательно его проверить.
Процесс перехода ещё продолжается. Сейчас они конвертируют эндпоинты и везде добавляют Pydantic, но основные результаты уже достигнуты.
У FastAPI все асинхронно, включая middleware — он сделан надстройкой над асинхронным сервером Starlette. Это приводит к определенным проблемам в синхронных хэндлерах. Например, при интеграции с GitHub нужно уметь считать HMAC тела запроса, чтобы проверять, что запрос пришел именно от GitHub, а не откуда-то еще.
Напрашивается очевидный код, который достает тело Request:
@router.post('/api/...')
def ci_run(request: Request):
body = request.body()
Но так это не работает, потому что функция request.body() возвращает корутину, а не данные, и её надо выполнять на асинхронном event loop. Что так просто из синхронного кода не сделать. Чтобы обойти эту проблему, можно сделать отдельную асинхронную функцию, которая достает тело запроса из request:
async def get_body(request: Request):
return await request.body()
@router.post('/api/...')
def ci_run(body=Depends(get_body)):
pass
Дальше в хэндлер FastAPI эта функция включается как dependency. FastAPI перед вызовом функции резолвит все зависимости. Поскольку это делается в асинхронном контексте, get_body() правильно отрабатывает, и синхронному хэндлеру на вход передается уже тело самого запроса. Точно также можно делать и с формами, и с JSON-ом в теле запроса.
В юнит-тестах body можно передавать в явном виде, без каких-либо хитрых моков.
Может показаться, что можно просто написать обычную выборку:

Но так делать нельзя, потому что заблокируются все корутины event loop-а, пока выборка не выполнится. Что увеличит задержку для всех остальных корутин, сделает её плохо предсказуемой, и полностью уберет конкурентность.
Можно попробовать сделать обычную связку, которую делают, когда из async-кода вызывают sync-код (run_in_executor).

При этом выборка запустится в thread-пуле, и создаст впечатление, что все будет хорошо. Но, скорее всего, не будет, потому что треды thread-пула запускаются без контекста, который управляет соединениями SQLAlchemy. Запросить сессию БД из отсутствующего контекста очевидно не получится. Что показывает, что неявное имеет тенденцию приводить к неприятным сюрпризам.
Решить это можно, написав wrapper, который создаст ScopedSession, и внутри ScopedSession уже делать выборку:
async def graphql_resolver():
def wrap():
with ScopedSession():
return session.query(DataSource).all()
objs = await (
asyncio.get_event_loop().run_in_executor(
None, wrap
)
)
Ещё одна проблема, которая дошла до прода, была связана с запуском FastAPI. В документации в качестве http-сервера рекомендуется использовать Uvicorn (асинхронный аналог Gunicorn). При этом, в качестве последней линии защиты от утечки памяти, в проекте сделали перезапуск рабочих процессов. Например, после 1000 реквестов, рабочий процесс перезапускается и освобождает всю память. Проблема в том, что Uvicorn останавливает старый процесс, но новый не запускает. В результате все процессы останавливаются, и сервер по факту перестает работать. В проде это было обнаружено через 20 минут после выкатки, и оперативно починено.
Чтобы обойти эту проблему, можно использовать в качестве супервизора Gunicorn, с плагином Uvicorn. В этой конфигурации Gunicorn отвечает за менеджмент рабочих процессов, а Uvicorn работает внутри воркеров и обрабатывает запросы:
gunicorn \
--worker-class uvicorn.workers.UvicornWorker \
...

 habr.com
habr.com
И однажды стартап решил поменять стек. Как так случилось? Это же затраты и все возникающие при этом сложности переезда. Но если хочешь получить короткий, эргономичный, хорошо читаемый код, приходится идти на жертвы. Но давайте по порядку.
Алекс Морозов, co-founder & CTO в компании Datafold, рассказал, как они переехали с Flask на FastAPI и поделился собственным опытом такого переезда. Это не только то, что пишут в документации, а конкретные проблемы, с которыми они столкнулись при переезде, и как они их обошли. На примерах посмотрим, что стоит сделать, а каких решений лучше избегать.
Полтора года назад стартап Datafold прошел в Ycombinator, ведущий акселератор для небольших компаний. Это значило, что у них было 4 месяца, чтобы показать результат, и 1-2 месяца — чтобы написать MVP.
У фаундеров не было глубокой экспертизы в веб-разработке — до этого они занимались Data Engineering и системным программированием. Поэтому они решили стартовать с готового проекта и на его базе построить нужный функционал. Рассмотрев несколько вариантов, остановились на Redash — он оказался очень близок по тематике. У него те же самые аналитические базы, подключение и стандартный User Management. К тому же у Redash лицензия MIT, то есть разработчики разрешают использовать код даже в закрытых форках. И наконец, это современный Single Page Application.
Почему решили менять стек
В Redash всё от начала и до конца было построено на Flask: адаптеры sqlalchemy, миграции alembic, REST, auth, rate-limiters, CSRF, etc и даже CLI!. А фронтенд сделан на стандартной комбинации React и JS. Например, код типичного хэндлера Flask-RESTful:
Хэндлер получает данные, достает их из тела запроса как JSON, валидирует и конвертирует поля. То есть для простых вещей требуется очень много кода. А если еще хочется получать толковые сообщения об ошибках (например, поле не того типа или нужное поле отсутствует), то boilerplate выходит еще в несколько раз больше.
Есть несколько вариантов, упростить и ускорить конвертацию и валидацию. Например, можно использовать JSON-схему, но тогда date/datetime все равно придется парсить руками. Ещё вариант — использовать модули pydantic или marshmallow, которые в Redash не употреблялись.
Дальше видно, что привязка роутов делается позже, в отдельном месте. Хотя лучше было бы сделать её декоратором сразу на хэндлере. В хэндлере объявляется переменная idx, и её тип дублируется в роуте.
Кроме того, вся логика сдвинута на 2 отступа, что кажется мелочью. Но в реальном коде может быть, например, контекстный менеджер, exception handling, цикл, пара вложенных if/else. Ещё по сути ничего не написано, а код уже размазывается об правую границу экрана. И лишний второй отступ хорошо в этом помогает.
Ещё Flask-RESTful ничего не знает о типах данных, и поэтому не может экспортировать схему в каком-либо машиночитаемом формате. C автодокументацией тоже проблемы. Flask-RESTful находится в режиме поддержки и не развивается, хотя есть более современные форки.
Или вот еще одна часть, которая вызывает трение — Flask-SQLAlchemy:
Есть стандартный интерфейс для выборок данных SQLAlchemy, с которым все знакомы. Flask-SQLAlchemy добавляет урезанный вариант выборок, который короче на десяток символов. Такая экономия хороша для CRUD-бэкэндов. Но если вы делаете что-то более сложное, то вдобавок к урезанному интерфейсу приходится использовать и стандартный. Получающаяся смесь того не стоит. Ещё надо добавить, что на всех моделях резервируется слово «query», которое в области Data Engineering используется везде, и приходится выдумывать для него синонимы.
Использование Flask-SQLAlchemy в проекте Datafold-а приводило к циклическим зависимостям: для инициализации приложения надо было достать конфигурацию из БД, а чтобы достать что-то из БД через Flask-SQLAlchemy, нужно инициализированное приложение. Это можно решить некрасивыми хаками, но за них приходится платить понятностью кода.
Есть ещё один момент — Flask-SQLAlchemy использует scoped-сессии БД. То есть в начале каждого запроса кладет сессию в thread-locals, и потом каждый раз магически достает её оттуда. Когда дело выходит за пределы http-хэндлеров, то становится удобнее передавать сессию в явном виде. Хотя это, во многом, дело вкуса. До той поры, когда в воркерах Celery вам приходится инициализировать приложение Flask, чтобы бизнес-логика могла работать с базой из воркеров.
На фронтенде тоже возникали проблемы. При использовании React + JS были постоянные ошибки типов в рантайме. А поскольку все данные передаются по приложению с помощью Object (в Python аналог передача словарями), то местами сложно понять, с каким типом данных имеешь дело. Поэтому проект решили переводить на React + TypeScript. При этом интерфейсные типы в TS переносились из API бэкэнда руками. Из-за переноса вручную часто получался рассинхрон, и снова возникали ошибки в рантайме.
Надо было искать более подходящее решение, поэтому начали прорабатывать другие варианты и остановились на FastAPI.
Сравнение с FastAPI
Код того же самого хэндлера с FastAPI будет выглядеть так:
Здесь мы видим несколько положительных моментов.
Валидация делается с помощью pydantic, надо только определить модель (CiRun) и задать типы полей. Всё остальное: парсинг, валидацию, handling и формирование текста ошибок pydantic делает сам, спасая от boilerplate.Также, FastAPI позволяет избавиться от проблемы с дублированием аннотации типов в URL. Здесь тип достаточно указать только в одном месте. А ещё теперь в коде один отступ!
Сомнительно выглядит то, что возвращаемый тип указан не в аннотации метода, а в декораторе. Но если подумать, то это резонно — часто нужно возвращать типы в обертках, например с нестандартными HTTP-статусами.
FastAPI — OpenAPI / Swagger
Поскольку FastAPI «знает» формат данных на входе и на выходе эндпоинта, он может выдать полную схему API в виде JSON-а. Ее можно скачать curl’ом с работающей системы или экспортировать напрямую из Python кода. На выходе получается описание схемы в JSON в формате Open API / Swagger, который уже можно конвертировать в структуры и boilerplate вызовов для разных языков.Например, как сгенерировать описание интерфейса для TypeScript:
$ curl https://localhost:8000/openapi.json >openapi.json
$ npx openapi-typescript schema.json --output schema.ts
Если генерацию типов выполнять во время билда, то проблема синхронизации между фронтом и бэком решается.
FastAPI async
Одной из ключевых фич FastAPI заявляется высокая производительность. Но для Datafold это не было важно. Хоть их SaaS-ом пользуется большое количество компаний, из-за предметной области тут нет речи о тысячах запросов в секунду.Часто с производительностью смешивают поддержку async. Если она вдруг нужна, то хэндлер просто декларируется как async и в нем пишется асинхронный код как обычно:
@router.post('/api/...')
async def ci_run_async(...):
...
Тут стоит заметить, что async реально нужен только в небольшом количестве случаев, например если вы используете вебсокеты, или long-polling. В случае Datafold внутренняя асинхронность FastAPI только доставляла проблемы.
Переход
Поскольку у стартапа не было возможности остановить разработку и переконвертировать всё за пару-тройку недель, они делали переход частями, перенося их в прод небольшими батчами. Пришлось заменить около десятка плагинов Flask: аутентификацию, rate limiter, Flask-SQLAlchemy и другие. Поэтому, когда стал понятен масштаб, они сделали дополнительный Proof Of Concept, чтобы проверить, что FastAPI точно заделиверит по своим обещаниям.Сначала начали убирать модули, которые можно было убрать на рабочем Flask. Заменили Flask-Migrate на стандартный alembic, flask.cli на click, а для Flask—SQLAlchemy сделали затычку. Подставили атрибут Model.query на все модели, чтобы не разрушать интерфейс выборок, иначе пришлось бы сразу рефакторить 90% кода.
После этого они вставили FastAPI-сервер непосредственно перед Flask. Запросы сначала приходили на него, а он передавал их дальше Flask:
fastapi_app.mount(
"/api",
WSGIMiddleware(flask_app, workers=10)
)
Аутентификацию нужно было делать по cookie и по токенам. Для этого на базе имеющихся в FastAPI классов пришлось написать немного кода и тщательно его проверить.
Процесс перехода ещё продолжается. Сейчас они конвертируют эндпоинты и везде добавляют Pydantic, но основные результаты уже достигнуты.
Проблемы sync/async
Теперь о проблемах, с которыми столкнулись в Datafold при переходе.У FastAPI все асинхронно, включая middleware — он сделан надстройкой над асинхронным сервером Starlette. Это приводит к определенным проблемам в синхронных хэндлерах. Например, при интеграции с GitHub нужно уметь считать HMAC тела запроса, чтобы проверять, что запрос пришел именно от GitHub, а не откуда-то еще.
Напрашивается очевидный код, который достает тело Request:
@router.post('/api/...')
def ci_run(request: Request):
body = request.body()
Но так это не работает, потому что функция request.body() возвращает корутину, а не данные, и её надо выполнять на асинхронном event loop. Что так просто из синхронного кода не сделать. Чтобы обойти эту проблему, можно сделать отдельную асинхронную функцию, которая достает тело запроса из request:
async def get_body(request: Request):
return await request.body()
@router.post('/api/...')
def ci_run(body=Depends(get_body)):
pass
Дальше в хэндлер FastAPI эта функция включается как dependency. FastAPI перед вызовом функции резолвит все зависимости. Поскольку это делается в асинхронном контексте, get_body() правильно отрабатывает, и синхронному хэндлеру на вход передается уже тело самого запроса. Точно также можно делать и с формами, и с JSON-ом в теле запроса.
В юнит-тестах body можно передавать в явном виде, без каких-либо хитрых моков.
Проблемы с SQLAlchemy
В проекте использовали GraphQL фрэймворк Ariadne, который построен на async, что имеет некоторый смысл — сервер GraphQL ориентирован на сбор данных из множества источников, и поэтому из них желательно собирать данные одновременно, чтобы уменьшить суммарное время ответа. Одним из таких источников в проекте Datafold является PostgreSQL со всеми моделями приложения на SQLAlchemy. Но в версии 1.3 SQLAlchemy аsync не поддерживается. Поэтому надо было либо мигрировать на версию 1.4, которая уже поддерживала async, либо как-то это обходить в async эндпоинтах.Может показаться, что можно просто написать обычную выборку:
Но так делать нельзя, потому что заблокируются все корутины event loop-а, пока выборка не выполнится. Что увеличит задержку для всех остальных корутин, сделает её плохо предсказуемой, и полностью уберет конкурентность.
Можно попробовать сделать обычную связку, которую делают, когда из async-кода вызывают sync-код (run_in_executor).
При этом выборка запустится в thread-пуле, и создаст впечатление, что все будет хорошо. Но, скорее всего, не будет, потому что треды thread-пула запускаются без контекста, который управляет соединениями SQLAlchemy. Запросить сессию БД из отсутствующего контекста очевидно не получится. Что показывает, что неявное имеет тенденцию приводить к неприятным сюрпризам.
Решить это можно, написав wrapper, который создаст ScopedSession, и внутри ScopedSession уже делать выборку:
async def graphql_resolver():
def wrap():
with ScopedSession():
return session.query(DataSource).all()
objs = await (
asyncio.get_event_loop().run_in_executor(
None, wrap
)
)
Другие проблемы
При переходе возникали и другие проблемы. Те самые ScopedSession сначала не до конца написали корректно, поэтому в некоторых случаях соединения к базе оставались открытыми, что выловили при тестировании.Ещё одна проблема, которая дошла до прода, была связана с запуском FastAPI. В документации в качестве http-сервера рекомендуется использовать Uvicorn (асинхронный аналог Gunicorn). При этом, в качестве последней линии защиты от утечки памяти, в проекте сделали перезапуск рабочих процессов. Например, после 1000 реквестов, рабочий процесс перезапускается и освобождает всю память. Проблема в том, что Uvicorn останавливает старый процесс, но новый не запускает. В результате все процессы останавливаются, и сервер по факту перестает работать. В проде это было обнаружено через 20 минут после выкатки, и оперативно починено.
Чтобы обойти эту проблему, можно использовать в качестве супервизора Gunicorn, с плагином Uvicorn. В этой конфигурации Gunicorn отвечает за менеджмент рабочих процессов, а Uvicorn работает внутри воркеров и обрабатывает запросы:
gunicorn \
--worker-class uvicorn.workers.UvicornWorker \
...
Результат
После переезда с Flask на FastAPI код проекта стал более кратким, эргономичным и хорошо читаемым. Появилась возможность документации API, экспорта его структуры и автоматической генерации типов. В эндпоинтах API из-за использования pydantic стало значительно меньше boilerplate и автоматически появились качественные сообщения об ошибках валидации входных данных.
Почему наш стартап переехал с Flask на FastAPI
Продукт стартапа Datafold — платформа для мониторинга аналитических данных. Они подключаются к хранилищам данных и ETL и BI-системам, помогая дата-сайентистам и инженерам отслеживать потоки данных, их...
habr.com